Ceph用户管理与cephFS分布式存储实战
🌟ceph集群用户管理
用户格式及权限说明
ceph的用户格式"TYPEID.USERID"
TYPEID:
指定的是用户类型。
包括内置组件用户(mon,mds,rgw,osd,mgr)和普通用户(client)。
USERID:
就是用户名,可以是数字,比如表示ods的第0块磁盘,对应的是"ods.0",
也可以是字符串,比如管理员用户,对应的是"client.admin"。
当然,用户可以自定义USERID,比如"client.jason",“client.yinzhengjie”。
每个用户都可以授权,使用caps字段关联。授权的格式"allow 权限"
常用的权限
- r:读权限
- w: 写权限
- x: 执行权限,可以调用方法(这些方法可能存在读写等操作),还可以执行mon的auth等相关命令。
- *: 拥有rwx等权限。
- class-read: 拥有x能力的子集,授予用户调用类读取方法的能力。
- class-write: 拥有x能力的子集,授予用户调用类写入方法的能力。
- profile osd: 授予用户一某个OSD身份连接到其他OSD或监视器的权限,可以获取OSD的状态信息。
- profile mds: 授予用户以某个MDS身份连接到其他MDS或监视器的权限,可以获取mds的状态信息。
- profile bootstrap-osd: 授予用于引导OSD的权限,在部署时候产生。
- profile bootstrap-mds: 授予用于引导元数据服务器的权限,在部署时候产生。
关于更多权限信息请参考官网:
https://docs.ceph.com/en/latest/rados/operations/user-management/#authorization-capabilities
https://docs.ceph.com/en/nautilus/rados/operations/user-management/
查看内置的用户
参考链接:
https://docs.ceph.com/en/nautilus/rados/operations/user-management/#get-a-user
查看指定用户
[root@ceph141 ~]# ceph auth get client.admin
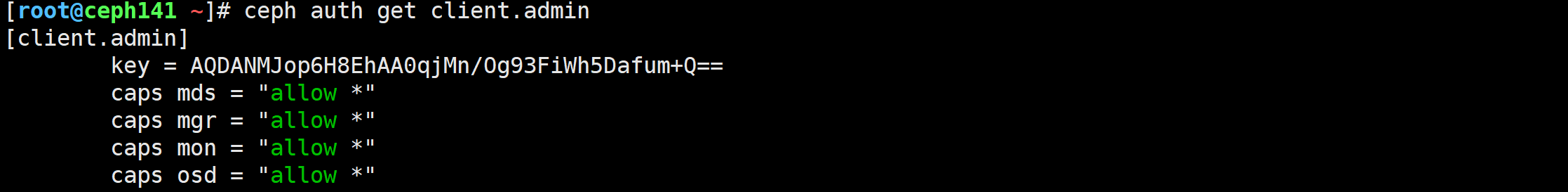
查看所有用户
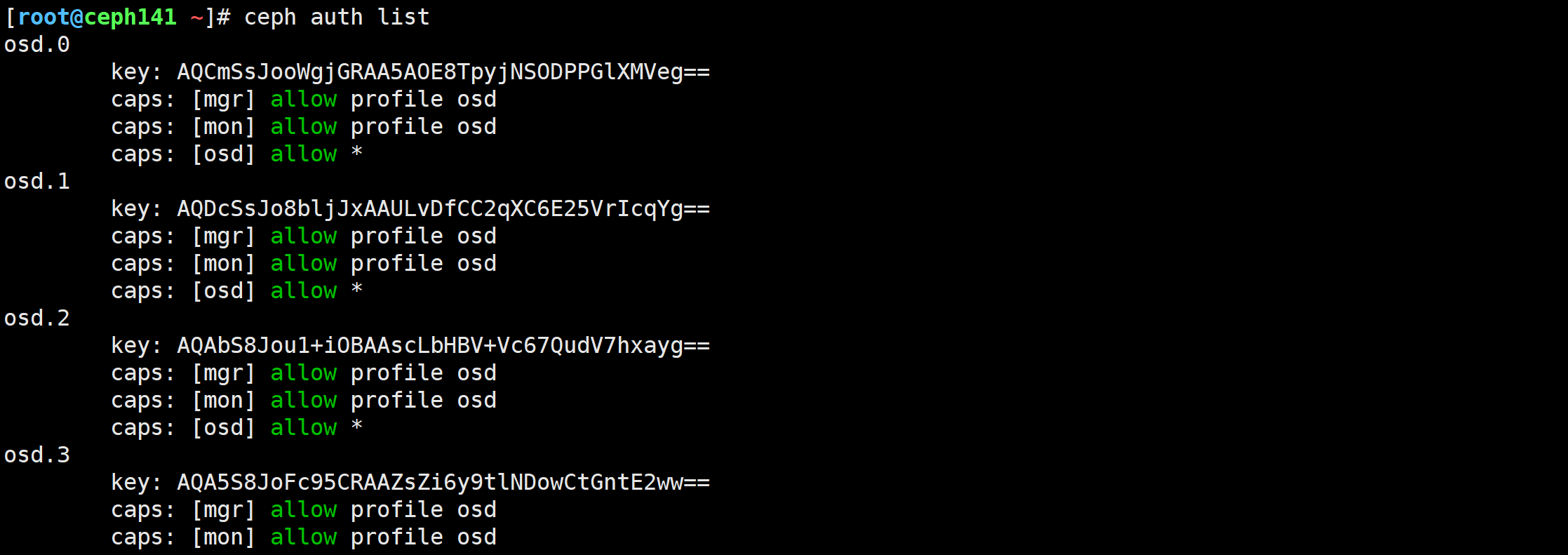
[root@ceph141 ~]# ceph auth list
三种方式自定义普通用户
参考链接:
https://docs.ceph.com/en/nautilus/rados/operations/user-management/#add-a-user
“ceph auth add” 创建用户
[root@ceph141 ~]# ceph auth add client.linux mon 'allow r' osd 'allow rwx pool=zhubaolin'
added key for client.linux
[root@ceph141 ~]# ceph auth get client.linux

"ceph auth get-or-create"创建用户
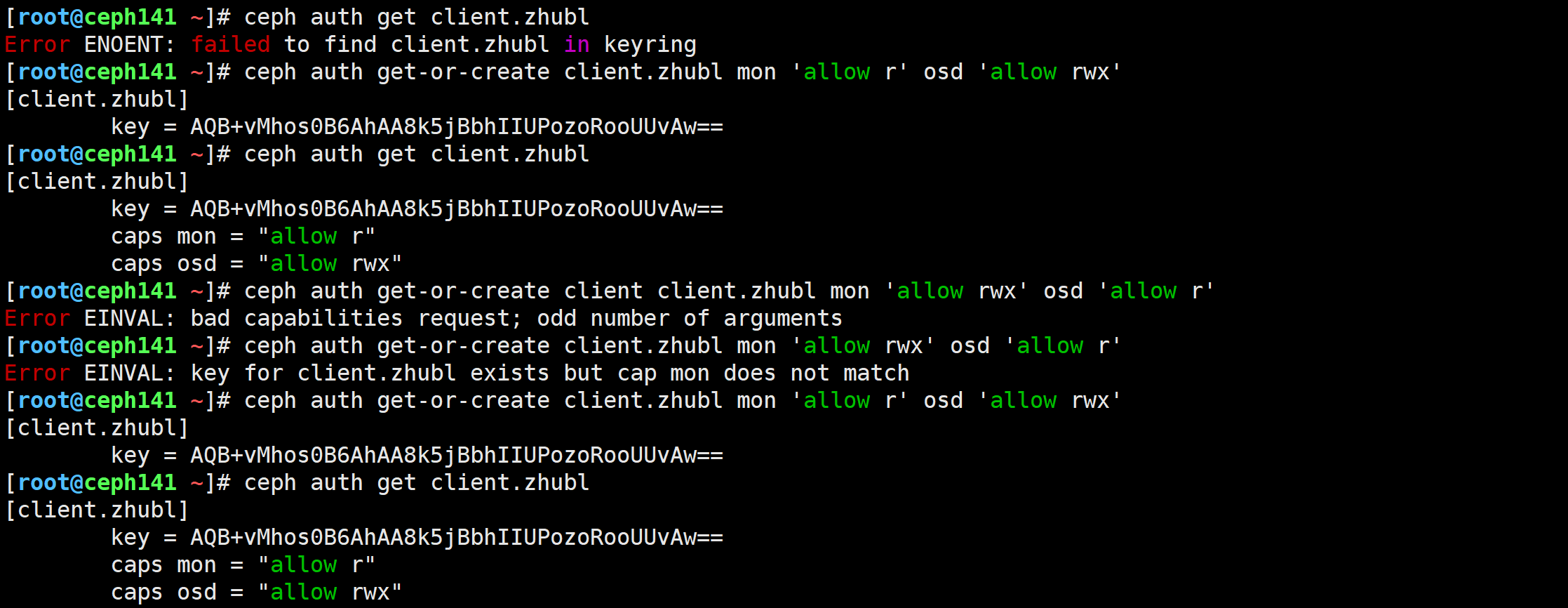
[root@ceph141 ~]# ceph auth get client.zhubl
Error ENOENT: failed to find client.zhubl in keyring# 如果用户不存在则直接创建并返回认证信息
[root@ceph141 ~]# ceph auth get-or-create client.zhubl mon 'allow r' osd 'allow rwx'# 如果用户已存在,直接获取用户不会创建,早期版本会报错,但19.2.1不会报错
[root@ceph141 ~]# ceph auth get-or-create client.zhubl mon 'allow r' osd 'allow rwx'
"ceph auth get-or-create-key"创建用户
# 注意,用户是不存在的
[root@ceph141 ~]# ceph auth get client.k8s
Error ENOENT: failed to find client.k8s in keyring# 创建用户并返回KEY
[root@ceph141 ~]# ceph auth get-or-create-key client.k8s mon 'allow r' osd 'allow rwx'
AQA+vchoHKDoDBAATluWZi/04eGzI3RfgwrvCw==

"ceph auth print-key"打印已经存在用户的KEY
[root@ceph141 ~]# ceph auth get client.zhubl2025
Error ENOENT: failed to find client.zhubl2025 in keyring
[root@ceph141 ~]# ceph auth get client.zhubl
[client.zhubl]key = AQB+vMhos0B6AhAA8k5jBbhIIUPozoRooUUvAw==caps mon = "allow r"caps osd = "allow rwx"
[root@ceph141 ~]# ceph auth print-key client.zhubl;echo
AQB+vMhos0B6AhAA8k5jBbhIIUPozoRooUUvAw==
[root@ceph141 ~]# ceph auth print-key client.zhubl2025
Error ENOENT: don't have client.zhubl2025

修改用户权限,直接覆盖权限
参考链接:
https://docs.ceph.com/en/nautilus/rados/operations/user-management/#modify-user-capabilities
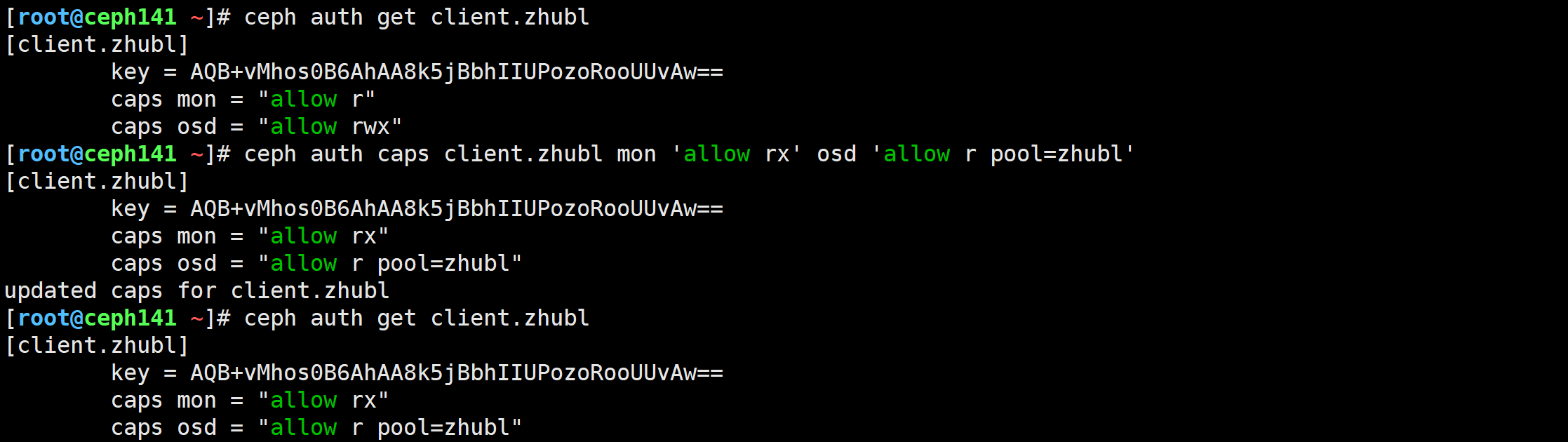
[root@ceph141 ~]# ceph auth caps client.zhubl mon 'allow rx' osd 'allow r pool=zhubl'
删除用户
参考链接:
https://docs.ceph.com/en/nautilus/rados/operations/user-management/#delete-a-user
[root@ceph141 ~]# ceph auth get client.zhubl
[client.zhubl]key = AQB+vMhos0B6AhAA8k5jBbhIIUPozoRooUUvAw==caps mon = "allow rx"caps osd = "allow r pool=zhubl"
[root@ceph141 ~]# ceph auth del client.zhubl
[root@ceph141 ~]# ceph auth get client.zhubl
Error ENOENT: failed to find client.zhubl in keyring
[root@ceph141 ~]#

🌟ceph用户的备份和恢复
参考链接:
https://docs.ceph.com/en/nautilus/rados/operations/user-management/#get-a-user
https://docs.ceph.com/en/nautilus/rados/operations/user-management/#import-a-user-s
创建测试用户
[root@ceph141 ~]# ceph auth add client.zhubl2025 mon 'allow rwx' osd 'allow r pool=zhubaolin-rbd'
added key for client.zhubl2025

三种方式导出用户到文件,用于模拟备份
先创建一个600的权限文件,然后再导入内容(官方推荐)
[root@ceph141 ~]# ceph-authtool --create-keyring ceph.client.zhubl2025.keyring[root@ceph141 ~]# ceph auth get client.zhubl2025 -o ceph.client.zhubl2025.keyring

直接导出到文件,但是文件的权限是644
[root@ceph141 ~]# ceph auth export client.zhubl2025 -o zhubl2025.keyring

直接重定向到文件,权限默认为644
[root@ceph141 ~]# ceph auth get client.zhubl2025 > myuser.keyring

删除用户
[root@ceph141 ~]# ceph auth del client.zhubl2025

导入用户,用于模拟恢复
[root@ceph141 ~]# ceph auth import -i ceph.client.zhubl2025.keyring
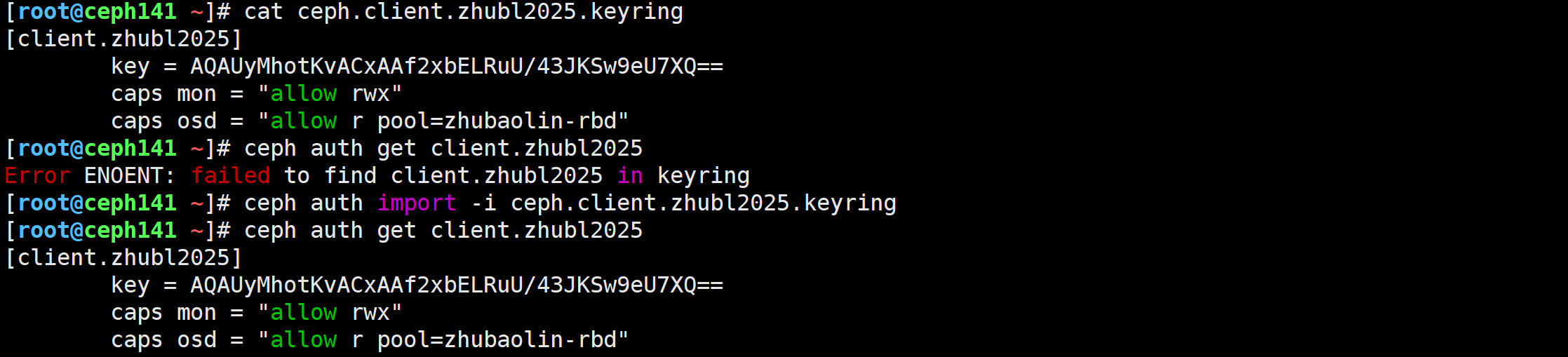
🌟导出授权文件并验证用户权限
服务端测试验证
[root@ceph141 ~]# ceph osd pool create zhubaolin-rbd
[root@ceph141 ~]# ceph osd pool application enable zhubaolin-rbd rbd
[root@ceph141 ~]# rbd create -s 2G zhubaolin-rbd/xixi
[root@ceph141 ~]# rbd create -s 4G zhubaolin-rbd/haha[root@ceph141 ~]# ceph osd pool create linux
[root@ceph141 ~]# ceph osd pool application enable linux rbd
[root@ceph141 ~]# rbd create -s 2G linux/hehe
[root@ceph141 ~]# rbd create -s 3G linux/heihei
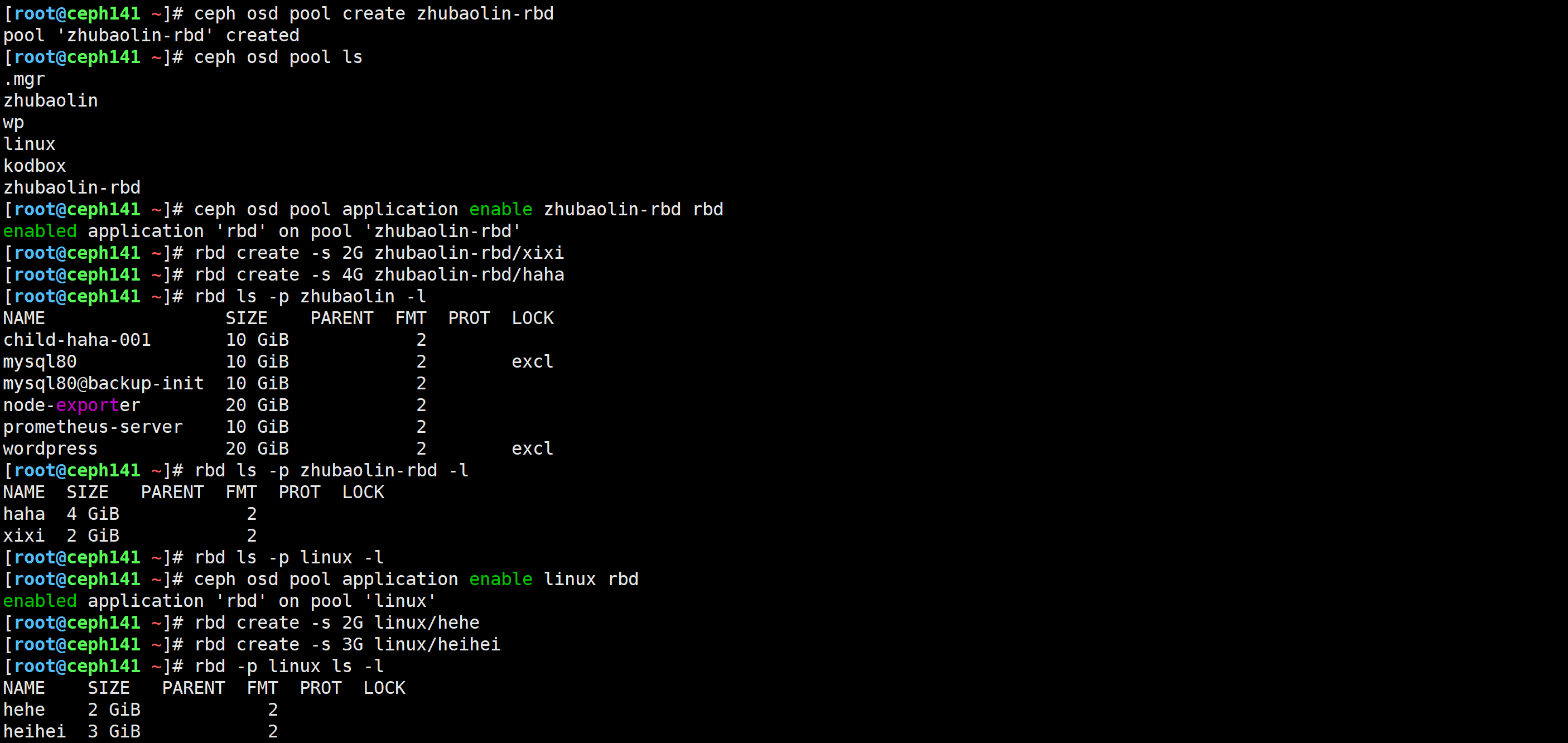
创建用户
[root@ceph141 ~]# ceph auth get-or-create client.k3s mon 'allow r' osd 'allow * pool=zhubaolin-rbd'

导出用户授权文件,钥匙环(keyring)
[root@ceph141 ~]# ceph auth export client.k3s -o ceph.client.k3s.keyring
[root@ceph141 ~]# cat ceph.client.k3s.keyring
[client.k3s]key = AQCPyshoUSaiKBAA2pCctPZu00MHmSdviPe9FQ==caps mon = "allow r"caps osd = "allow * pool=zhubaolin-rbd"

拷贝授权文件前,观察客户端是否有查看集群的权限
[root@prometheus-server31 ~]# rm -f /etc/ceph/ceph.c*
[root@prometheus-server31 ~]# ceph -s
Error initializing cluster client: ObjectNotFound('RADOS object not found (error calling conf_read_file)')

将授权文件拷贝到客户端
[root@ceph141 ~]# scp ceph.client.k3s.keyring /etc/ceph/ceph.conf 10.0.0.31:/etc/ceph

验证权限
[root@prometheus-server31 ~]# ceph -s --user k3s[root@prometheus-server31 ~]# rbd -p zhubaolin-rbd ls -l --user k3s[root@prometheus-server31 ~]# rbd -p zhubaolin-rbd ls -l --id k3s
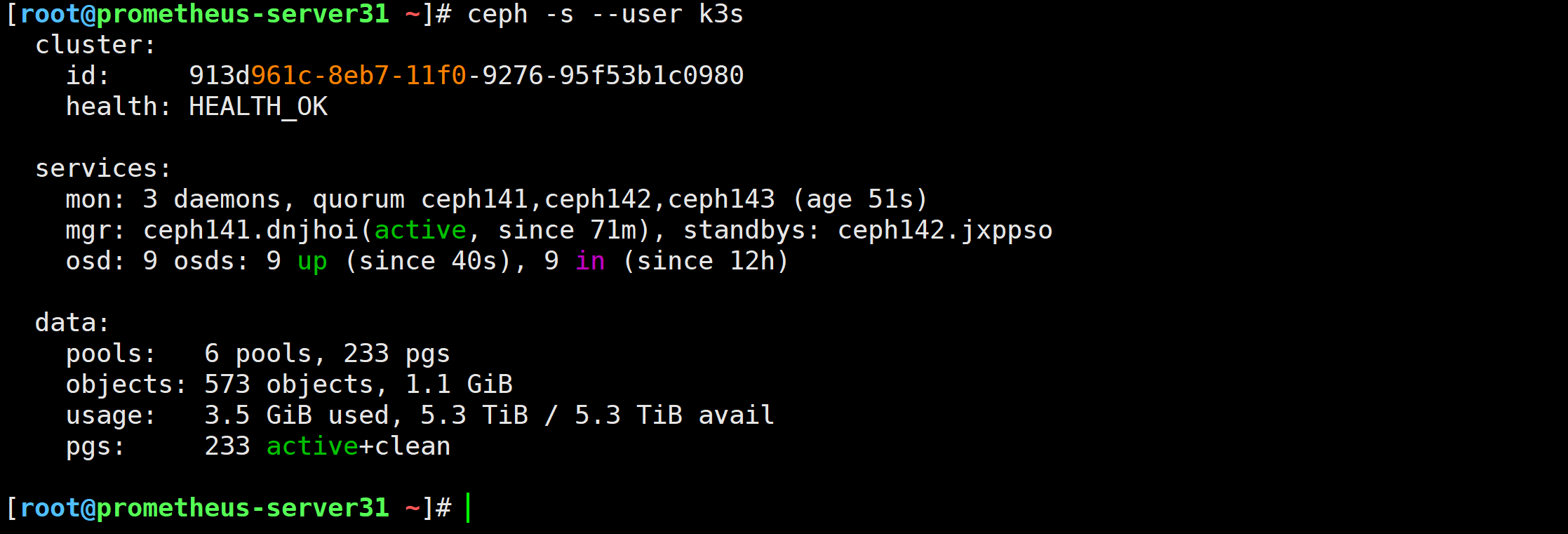
官方已经弃用–user,建议使用–id选项
授权文件加载顺序总结
默认去找以下文件
- /etc/ceph/ceph.client.k3s.keyring
- /etc/ceph/ceph.keyring
- /etc/ceph/keyring
- /etc/ceph/keyring.bin
如果不使用–id选项,默认为–id admin
- /etc/ceph/ceph.client.admin.keyring
- /etc/ceph/ceph.keyring
- /etc/ceph/keyring
- /etc/ceph/keyring.bin
对于认证文件不能随便起名字
而是需要遵循上述2条的规范文件命名,否则ceph不识别用户的配置文件
客户端在连接ceph集群时,仅需要读取keyring文件中的KEY值
其他caps字段会被忽视。也就是说,对于文件中只要保留key值依旧是有效的
🌟cephFS基础知识
CephFS概述
RBD提供了远程磁盘挂载的问题,但无法做到多个主机共享一个磁盘,如果有一份数据很多客户端都要读写该怎么办呢?这时CephFS作为文件系统解决方案就派上用场了。
CephFS是POSIX兼容的文件系统,它直接使用Ceph存储集群来存储数据。Ceph文件系统于Ceph块设备,同时提供S3和Swift API的Ceph对象存储或者原生库(librados)的实现机制稍显不同。
CephFS支持内核模块或者fuse方式访问,如果宿主机没有安装ceph模块,则可以考虑使用fuse方式访问。可以通过"modinfo ceph"来检查当前宿主机是否有ceph相关内核模块。
[root@ceph141 ~]# modinfo ceph
推荐阅读:
https://docs.ceph.com/en/reef/architecture/#ceph-file-system
https://docs.ceph.com/en/reef/cephfs/#ceph-file-system
CephFS架构原理
CephFS需要至少运行一个元数据服务器(MDS)守护进程(ceph-mds),此进程管理与CephFS上存储文件相关的元数据信息。
MDS(MetaData Server))虽然称为元数据服务,但是它却不存储任何元数据信息,它存在的目的仅仅是让我们rados集群提供存储接口。
客户端在访问文件接口时,首先链接到MDS上,在MDS到内存里面维持元数据的索引信息,从而间接找到去哪个数据节点读取数据。这一点和HDFS文件系统类似。
CephFS和NFS对比
相较于NFS来说,它主要有以下特点优势:
1.底层数据冗余的功能,底层的roados提供了基本数据冗余功能,因此不存在NFS的单点故障因素;
2.底层roados系统有N个存储节点组成,所以数据的存储可以分散I/O,吞吐量较高;
3.底层roados系统有N个存储节点组成,所以ceph提供的扩展性要相当的高;
🌟cephFS的一主一从架构部署
推荐阅读: https://docs.ceph.com/en/reef/cephfs/createfs/
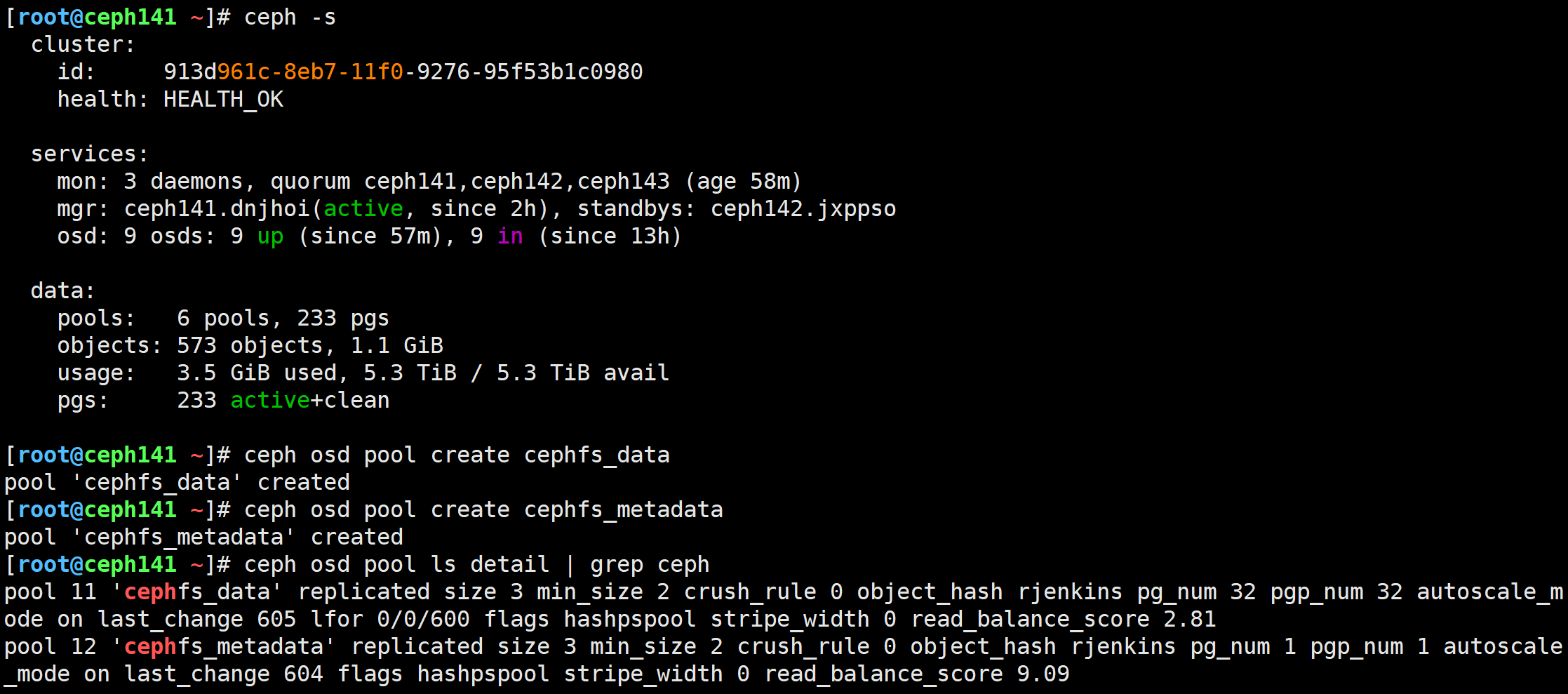
创建两个存储池分别用于存储mds的元数据和数据
[root@ceph141 ~]# ceph osd pool create cephfs_data
pool 'cephfs_data' created
[root@ceph141 ~]# ceph osd pool create cephfs_metadata
pool 'cephfs_metadata' created
创建一个文件系统,名称为"zhubaolin-cephfs"
[root@ceph141 ~]# ceph fs new zhubaolin-cephfs cephfs_metadata cephfs_data
[root@ceph141 ~]# ceph osd pool get cephfs_data bulk# 标记'cephfs_data'存储池为大容量
[root@ceph141 ~]# ceph osd pool set cephfs_data bulk true
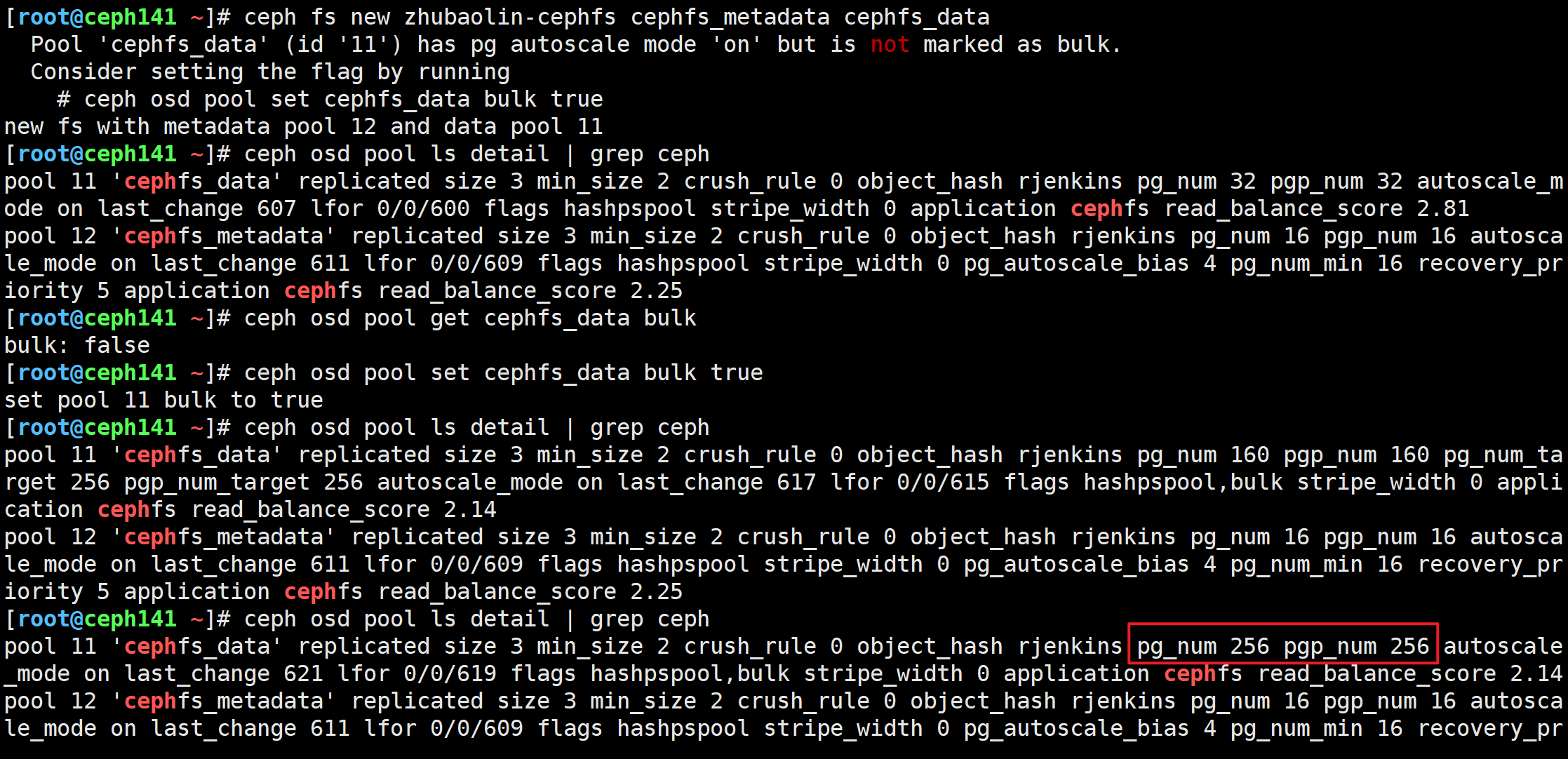
注意观察pg的数量,有点延迟,需要等待一段30s左右
查看创建的文件系统
[root@ceph141 ~]# ceph fs ls
[root@ceph141 ~]# ceph mds stat
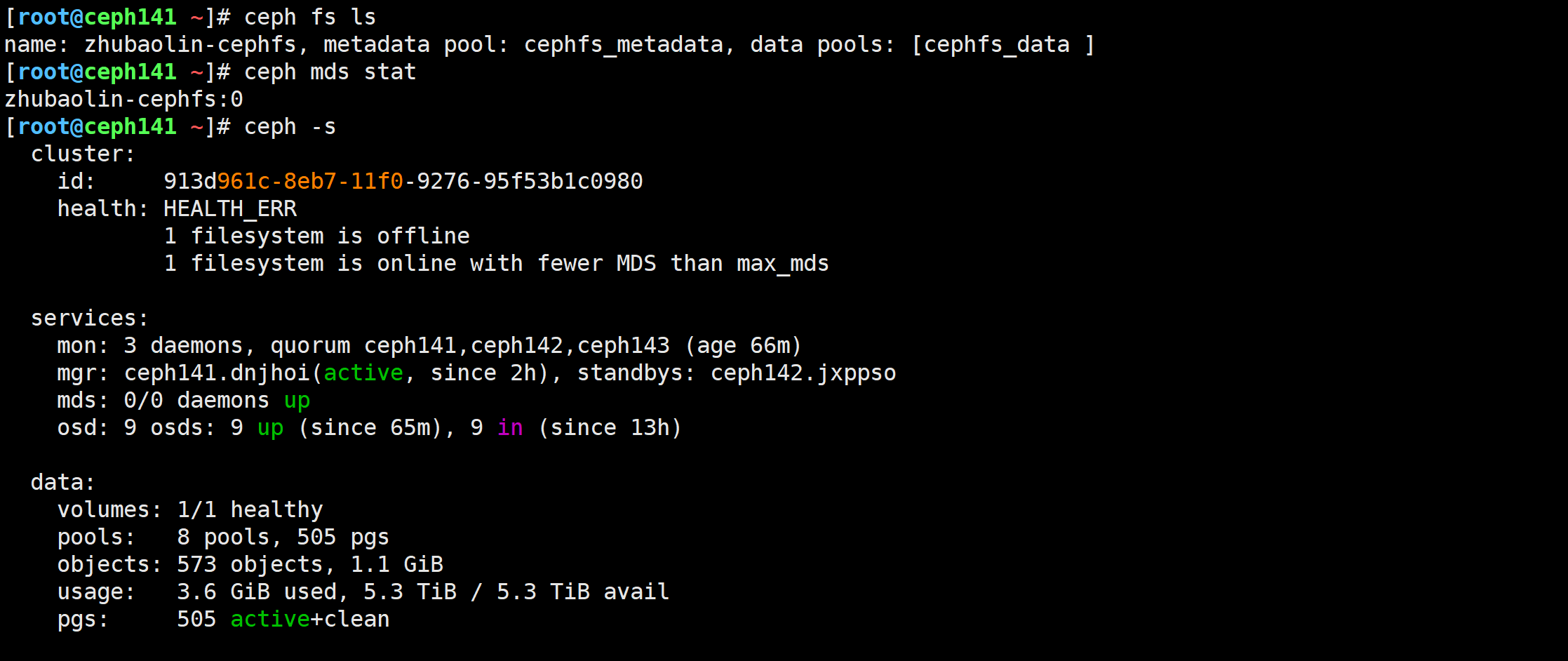
应用mds的文件系统
[root@ceph141 ~]# ceph orch apply mds zhubaolin-cephfs
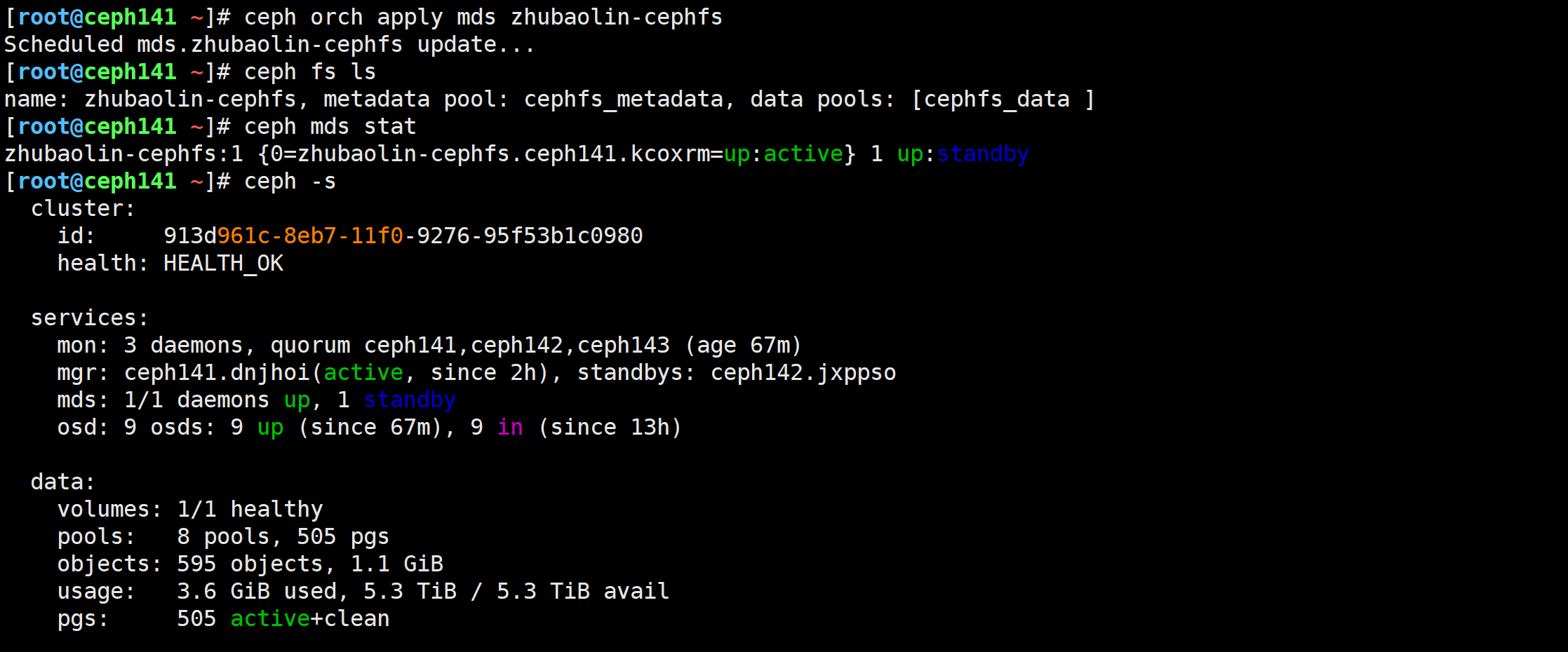
查看cephFS集群的详细信息
[root@ceph141 ~]# ceph fs status zhubaolin-cephfs

添加多个mds服务器
可跳过,就算添加了也会自动移除一个备用的节点,貌似仅允许一个备用的服务器
[root@ceph141 ~]# ceph orch daemon add mds zhubaolin-cephfs ceph141
🌟cephFS的一主一从架构高可用验证
查看cephFS集群的详细信息
[root@ceph141 ~]# ceph fs status zhubaolin-cephfs

直接关机(ceph142)
[root@ceph142 ~]# shutdown -h now
查看cephFS集群状态
需要等待30s左右才能看到效果
[root@ceph141 ~]# ceph fs status zhubaolin-cephfs

查看集群状态
[root@ceph141 ~]# ceph -s
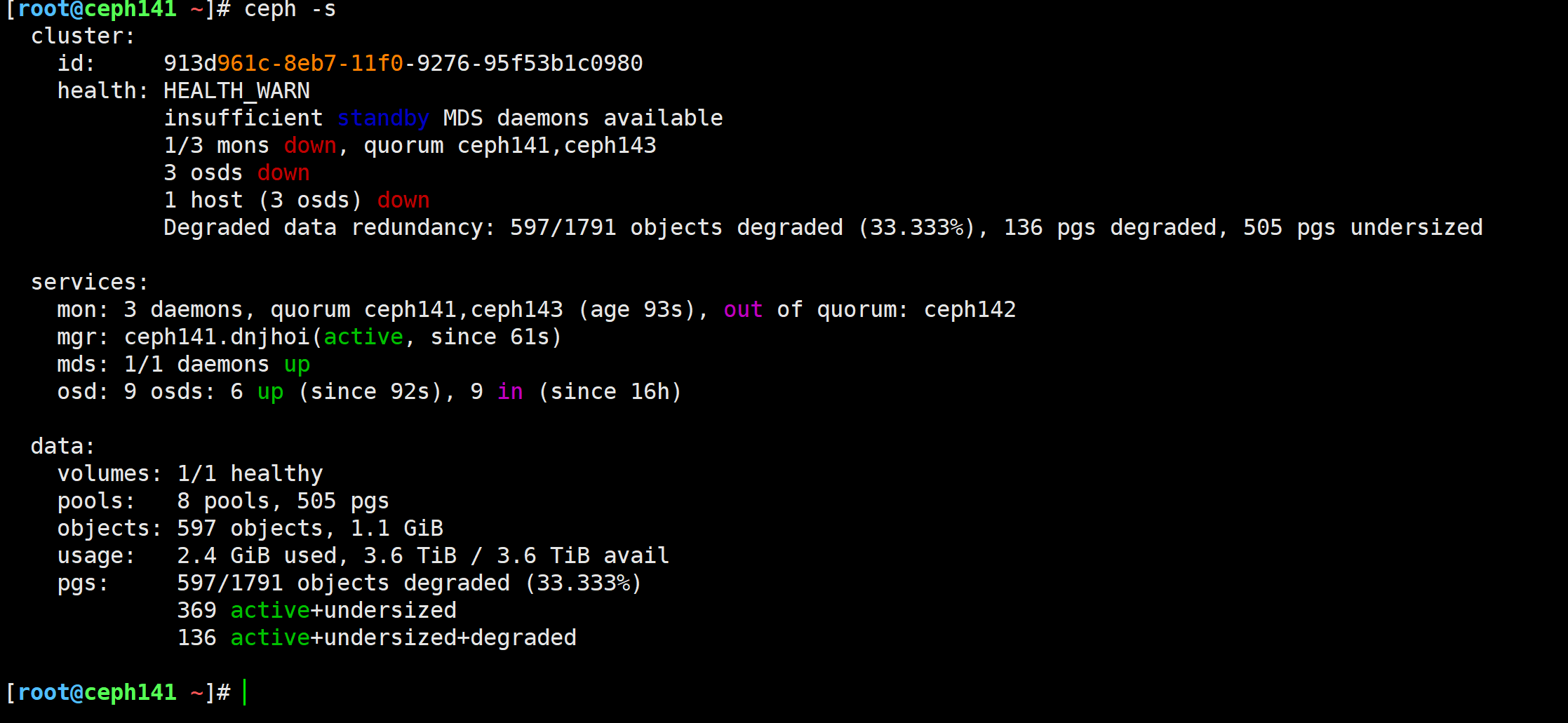
启动ceph142节点后,再次观察集群状态
ceph -s
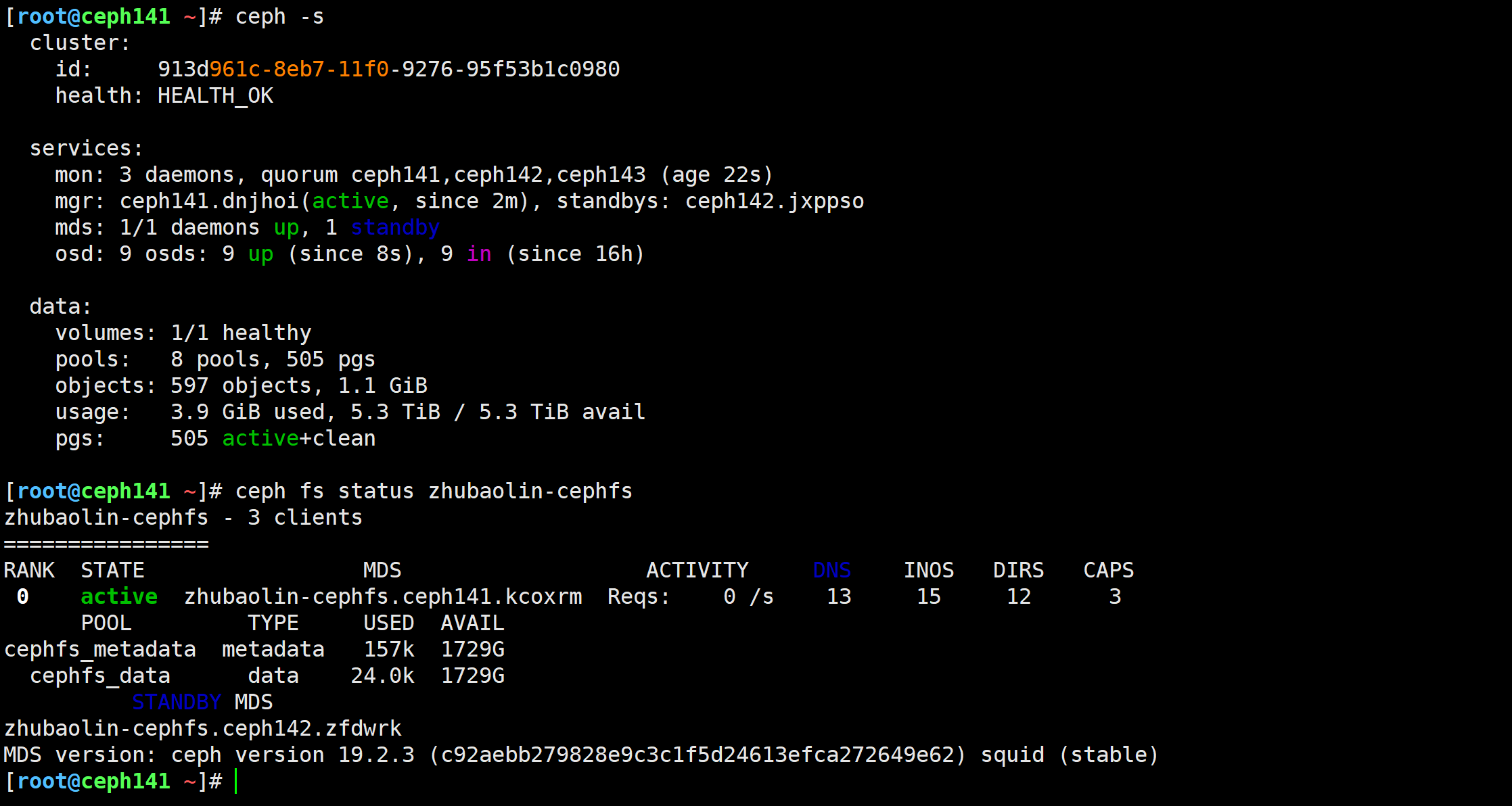
🌟cephfs的客户端之借助内核ceph模块挂载
参考链接:
https://docs.ceph.com/en/latest/cephfs/mount-using-kernel-driver/#which-kernel-version
关于secretfile选项说明如下:
secretfile在ceph内核模块中是不支持的,但是fuse目前还是支持该模块的。
如果你出现报错: 'ceph: Unknown parameter ‘secretfile’'就说明当前的ceph版本不再支持secretfile功能啦~。
目前对于ceph 19.2.2版本而言,是无法使用secretfile的。
但是早期版本是支持secretfile功能的,毕竟在ceph 14.2.22版本中是可以正常使用的。
其中使用’modinfo ceph’就能看到起支持ceph模块的方式挂载,如果内核地域4.x-版本,则需要考虑使用fuse模块实现。
管理节点创建用户并导出钥匙环和key文件
创建用户并授权
[root@ceph141 ~]# ceph auth add client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rwx'
added key for client.cephfs

导出认证信息
[root@ceph141 ~]# ceph auth print-key client.cephfs > cephfs.key
基于KEY进行挂载,无需拷贝秘钥文件
查看本地文件
[root@ceph141 ~]# cat cephfs.key
AQBc38holtwgCRAA2nlqhhIMb/J2BbUYhHVSQQ==
创建挂载点
[root@ceph141 ~]# mkdir /data[root@ceph141 ~]# mount -t ceph 10.0.0.141:6789,10.0.0.142:6789,10.0.0.143:6789:/ /data -o name=cephfs,secret=AQBc38holtwgCRAA2nlqhhIMb/J2BbUYhHVSQQ==
尝试写入测试数据
[root@ceph141 ~]# cp /etc/os-release /etc/fstab /data/
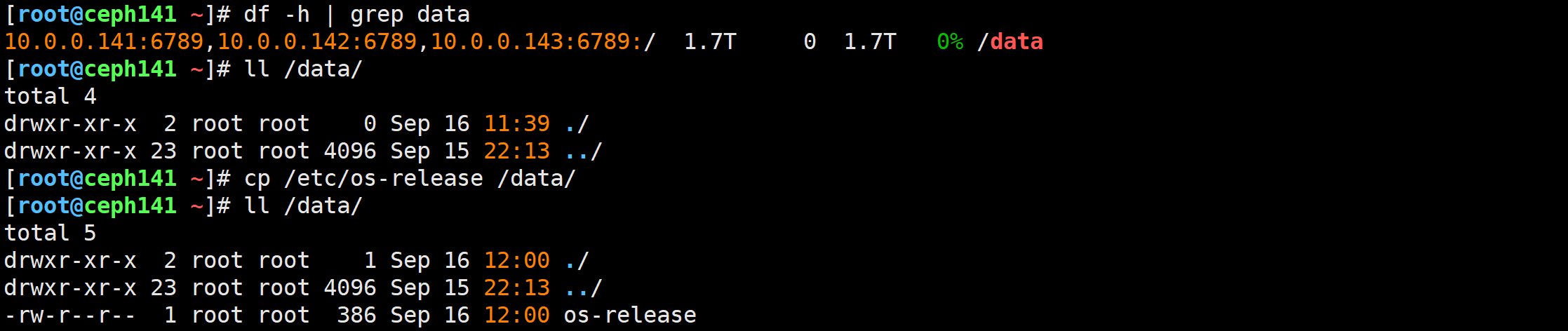
42节点挂载测试
挂载设备
[root@ceph142 ~]# mkdir /data
[root@ceph142 ~]# mount -t ceph 10.0.0.141:6789,10.0.0.142:6789,10.0.0.143:6789:/ /data -o name=cephfs,secret=AQBc38holtwgCRAA2nlqhhIMb/J2BbUYhHVSQQ==

写入测试数据
[root@ceph142 ~]# cp /etc/hosts /data/
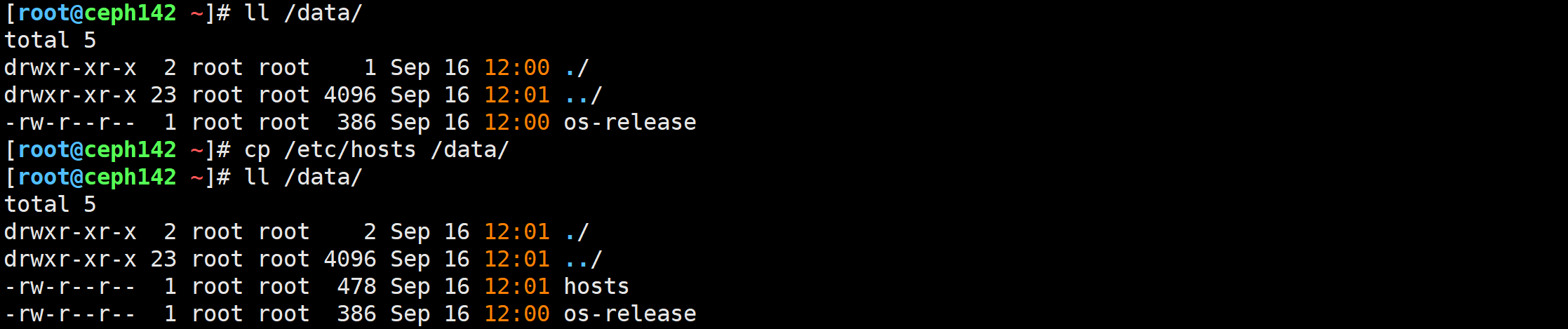
其他客户端查看
🌟cephfs的客户端之基于用户空间fuse方式访问
参考链接: https://docs.ceph.com/en/latest/cephfs/mount-using-fuse/
FUSE概述
对于某些操作系统来说,它没有提供对应的ceph内核模块,我们还需要使用CephFS的话,可以通过FUSE方式来实现。
FUSE英文全称为:“Filesystem in Userspace”,工作在用户空间,这意味着ceph-fuse挂载的性能不如内核(ceph)驱动程序挂载,但它们更容易管理和升级。
用于非特权用户能够无需操作内核而创建文件系统,但需要单独安装"ceph-fuse"程序包,ceph-fuse可以作为CephFS内核驱动程序的替代品来挂载CephFS文件系统。
ceph-fuse一般用于较低的Linux 4.X- 内核。
安装ceph-fuse程序包
[root@node-exporter43 ~]# apt -y install ceph-fuse
创建挂载点
[root@node-exporter43 ~]# mkdir -pv /zhubaolin/cephfs
拷贝认证文件
[root@ceph141 ~]# ceph auth export client.cephfs -o ceph.client.cephfs.keyring
[root@ceph141 ~]# cat ceph.client.cephfs.keyring
[client.cephfs]key = AQBc38holtwgCRAA2nlqhhIMb/J2BbUYhHVSQQ==caps mds = "allow rw"caps mon = "allow r"caps osd = "allow rwx"
[root@ceph141 ~]# scp ceph.client.cephfs.keyring 10.0.0.43:~
使用ceph-fuse工具挂载cephFS
[root@node-exporter43 ~]# ceph-fuse -n client.cephfs -m 10.0.0.141:6789,10.0.0.142:6789,10.0.0.143:6789 /zhubaolin/cephfs/ -c /root/ceph.client.cephfs.keyring

写入测试数据
[root@node-exporter43 ~]# cp /etc/hostname /zhubaolin/cephfs/
其他节点查看数据是否存在

🌟cephFS两种方式开机自动挂载实战
基于rc.local脚本方式开机自动挂载
推荐,就算执行失败,并不会导致系统无法启动~
修改启动脚本
vim /etc/rc.local
#!/bin/bashmount -t ceph 10.0.0.141:6789,10.0.0.142:6789,10.0.0.143:6789:/ /data -o name=cephfs,secret=AQBc38holtwgCRAA2nlqhhIMb/J2BbUYhHVSQQ==
添加执行权限
chmod +x /etc/rc.local
重启服务器
reboot
测试验证
df -h | grep data
基于fstab文件进行开机自动挂载
修改fstab的配置文件
vim /etc/fstab
10.0.0.141:6789,10.0.0.142:6789,10.0.0.143:6789:/ /data ceph name=cephfs,secret=AQBc38holtwgCRAA2nlqhhIMb/J2BbUYhHVSQQ==,noatime,_netdev 0 2
测试验证
mount -a
df -h | grep /data
查看cephfs现有的目录结构
[root@node-exporter42 ~]# tree /data/
/data/
├── haha
│ ├── hostname
│ └── hosts
└── xixi├── hosts└── os-release -> ../usr/lib/os-release
开机挂载测试
[root@node-exporter41 ~]# tail -1 /etc/fstab
10.0.0.141:6789,10.0.0.142:6789,10.0.0.143:6789:/xixi /mnt ceph name=cephfs,secret=AQBc38holtwgCRAA2nlqhhIMb/J2BbUYhHVSQQ==,noatime,_netdev 0 2
[root@node-exporter41 ~]#
[root@node-exporter41 ~]# mount -a
[root@node-exporter41 ~]#
[root@node-exporter41 ~]# df -h | grep mnt
10.0.0.141:6789,10.0.0.142:6789,10.0.0.143:6789:/xixi 1.7T 0 1.7T 0% /mnt
[root@node-exporter41 ~]#
[root@node-exporter41 ~]# ll /mnt/
total 5
drwxr-xr-x 2 root root 2 Sep 16 14:57 ./
drwxr-xr-x 21 root root 4096 Sep 5 10:01 ../
-rw-r--r-- 1 root root 226 Sep 16 14:57 hosts
lrwxrwxrwx 1 root root 21 Feb 14 2024 os-release -> ../usr/lib/os-release
[root@node-exporter41 ~]#
🌟ceph集群的维护命令
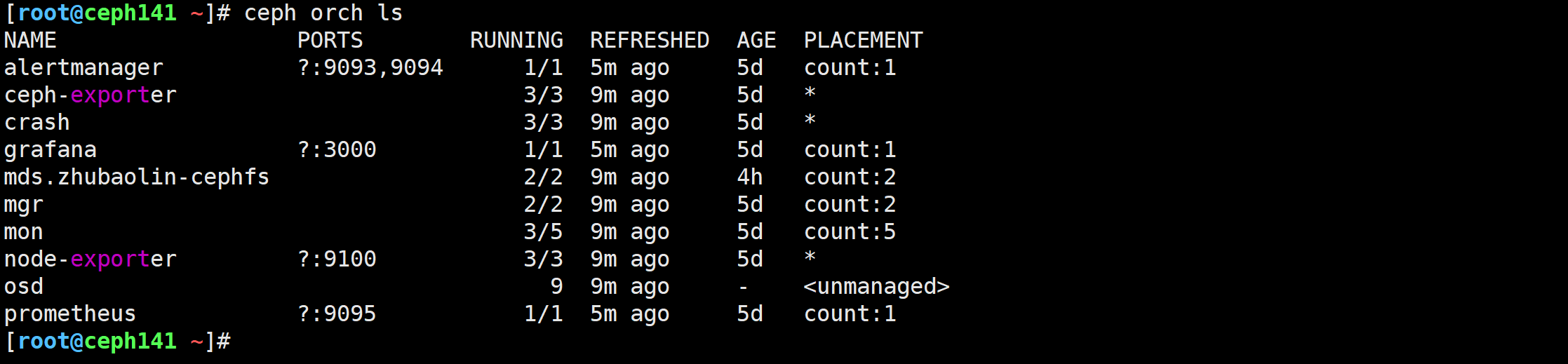
查看集群的架构
[root@ceph141 ~]# ceph orch ls
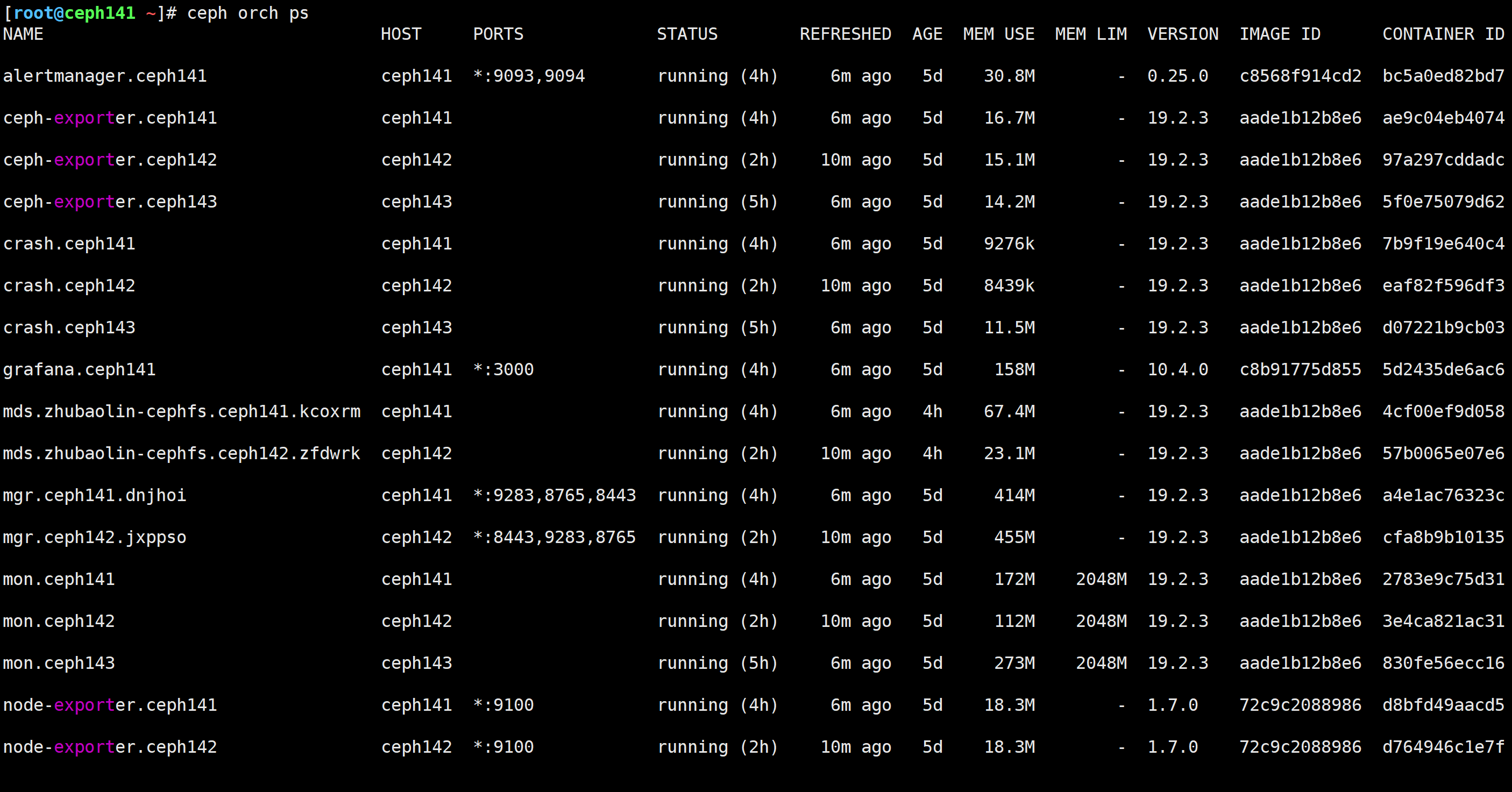
查看ceph集群的守护进程
[root@ceph141 ~]# ceph orch ps
查看指定节点的守护进程
[root@ceph141 ~]# ceph orch ps ceph143

重启指定节点守护进程服务
[root@ceph141 ~]# ceph orch daemon restart node-exporter.ceph143
[root@ceph141 ~]# ceph orch ps ceph143

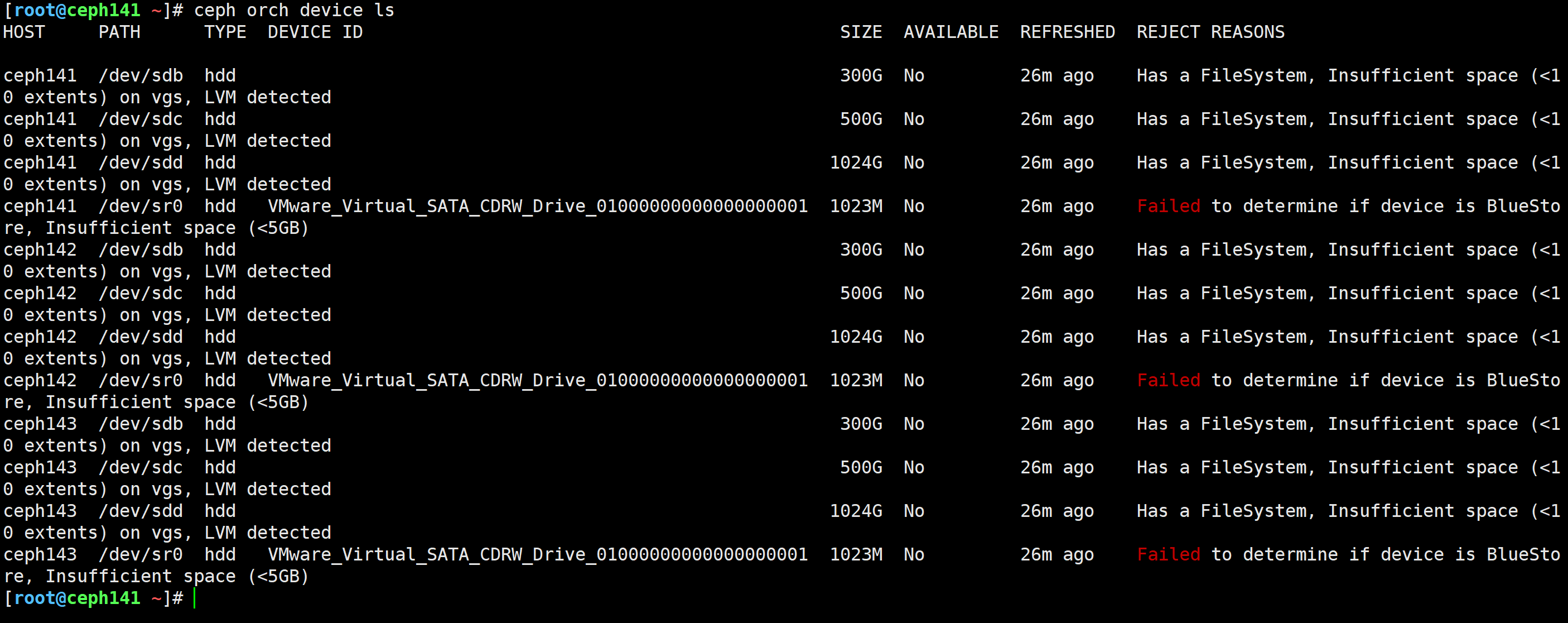
查看主机有哪些设备列表
[root@ceph141 ~]# ceph orch device ls
查看集群有哪些主机列表
[root@ceph141 ~]# ceph orch host ls

报告配置的后端及其状态
[root@ceph141 ~]# ceph orch status
[root@ceph141 ~]# ceph orch status --detail --format json

检查服务版本与可用和目标容器
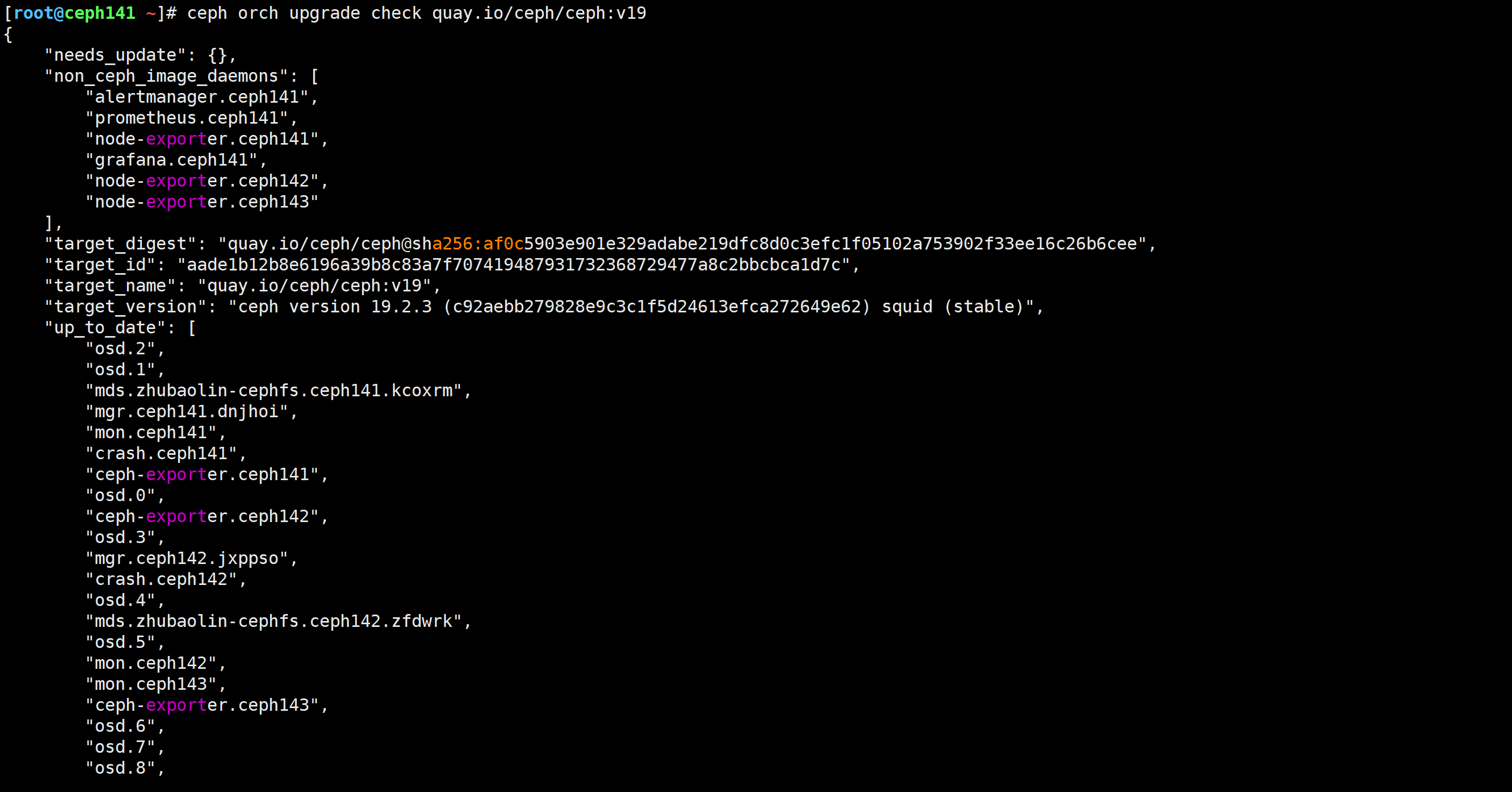
[root@ceph141 ~]# docker image ls

[root@ceph141 ~]# ceph orch upgrade check quay.io/ceph/ceph:v19
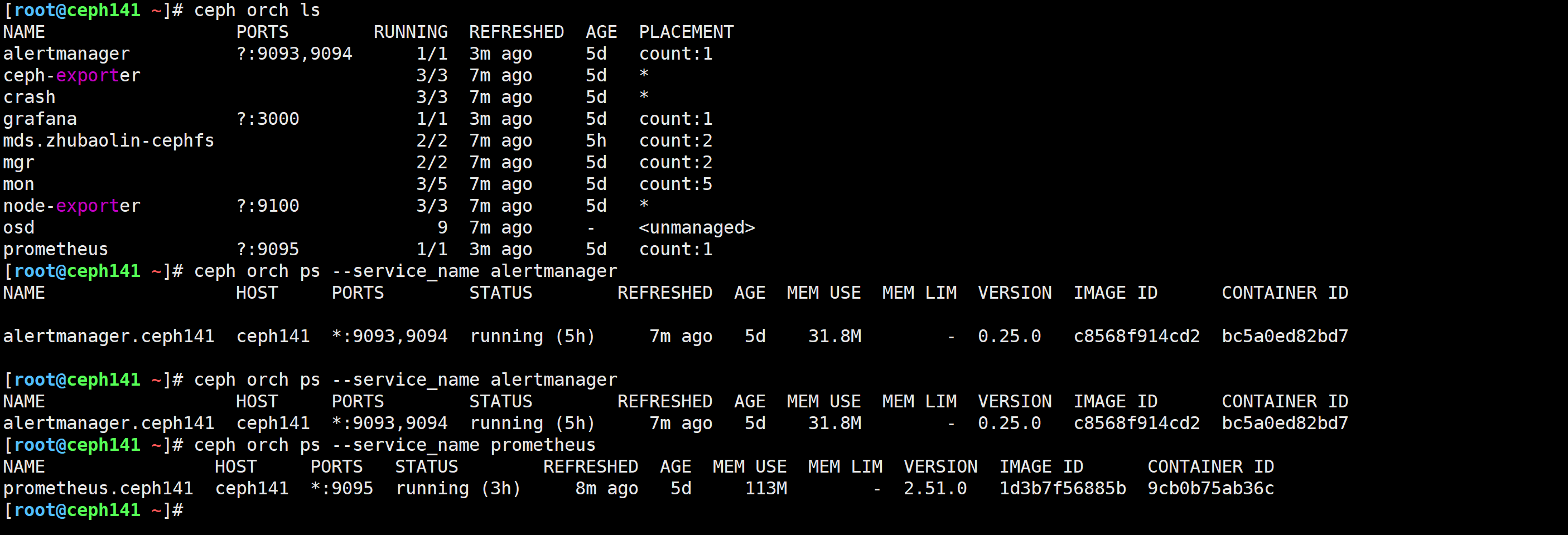
查看指定服务的信息
[root@ceph141 ~]# ceph orch ps --service_name alertmanager
[root@ceph141 ~]# ceph orch ps --service_name prometheus
🌟Prometheus监控ceph集群实战
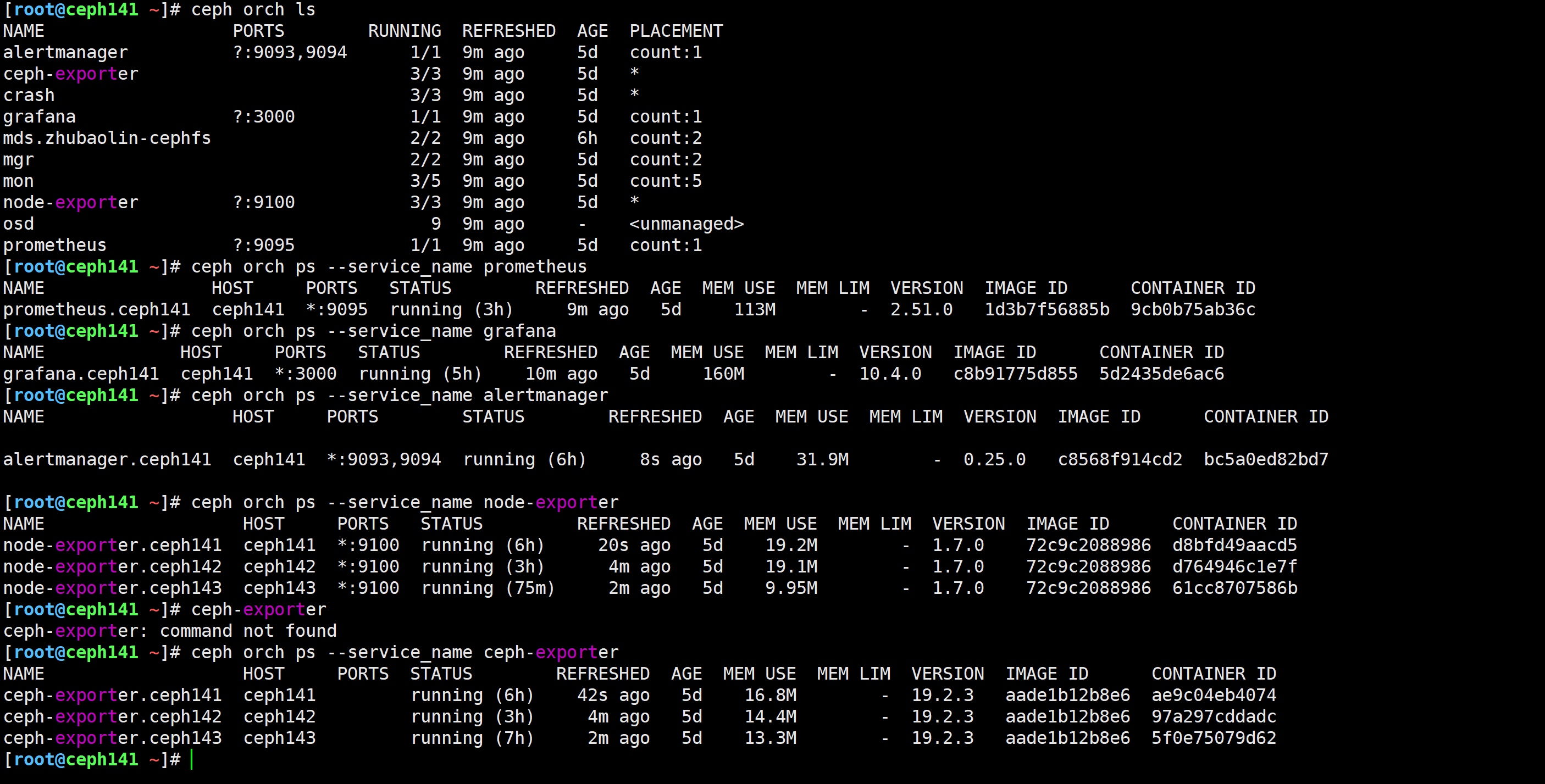
查看集群的架构
[root@ceph141 ~]# ceph orch ls
温馨提示:
不难发现,有grafana,alertmanager,ceph-exporter,Prometheus等组件默认都是安装好的,说白了,无需手动安装。
所以,基于cephadm方式部署的环境,可以直接使用Prometheus监控。若使用的ceph-deploy方式部署,则需要手动配置各组件。
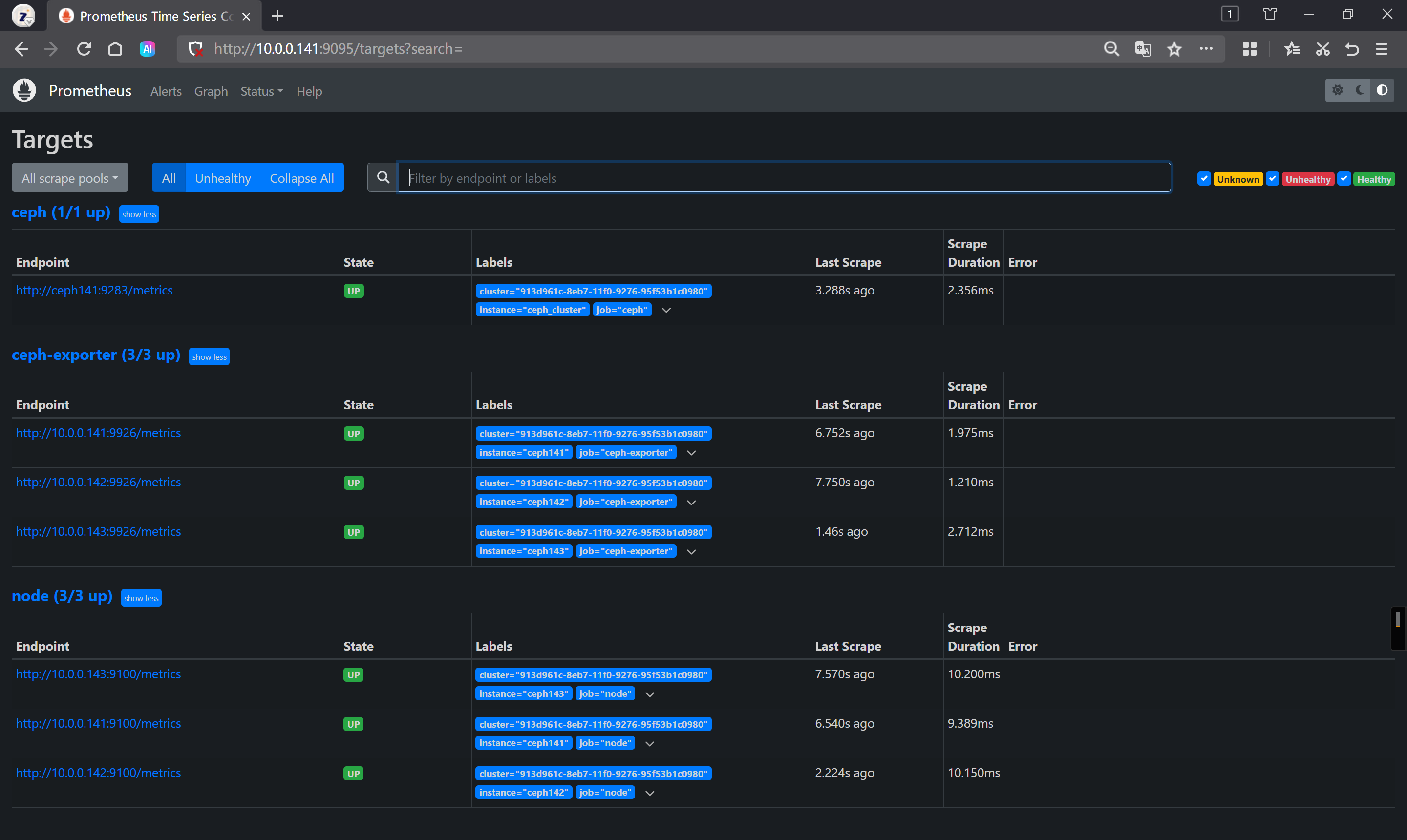
查看Prometheus的WEbUI
http://10.0.0.141:9095/targets?search=
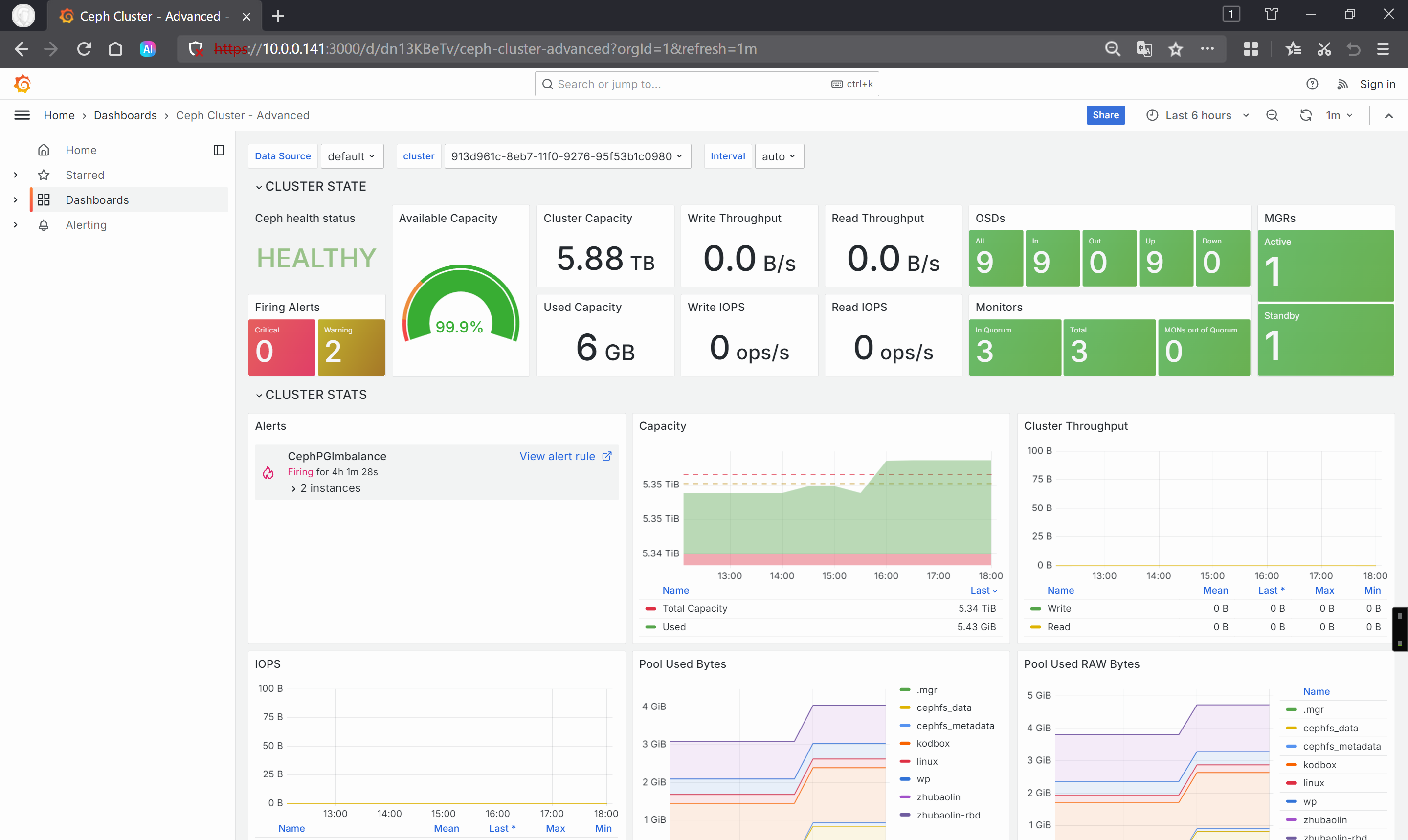
查看grafana的WebUI
https://10.0.0.141:3000/d/dn13KBeTv/ceph-cluster-advanced?orgId=1&refresh=1m
查看node-exporter
http://10.0.0.141:9100/metrics
查看alertmanger
http://10.0.0.141:9093/#/status
自实现Prometheus监控参考链接
推荐阅读:
https://github.com/digitalocean/ceph_exporter
https://github.com/blemmenes/radosgw_usage_exporter
查看ceph集群的mgr模块列表
[root@ceph141 ~]# ceph mgr module ls

启用模块(可选操作)
[root@ceph141 ~]# ceph mgr module enable zabbix
