【ICCV 2023】通过学习采样来学习上采样
文章目录
- 一、论文信息
- 二、论文概要
- 三、实验动机
- 四、创新之处
- 五、实验分析
- 六、核心代码
- 源代码
- 七、实验总结
一、论文信息
- 论文题目:Learning to Upsample by Learning to Sample
- 中文题目:通过学习采样来学习上采样
- 论文链接:点击跳转
- 代码链接:点击跳转
- 作者:Wenze Liu (刘文泽)、Hao Lu (卢昊)、Hongtao Fu (傅洪涛)、Zhiguo Cao (曹志国)
- 单位:华中科技大学,人工智能与自动化学院
- 核心速览:DySample 提出一种 基于采样的动态上采样方法,避开了 CARAFE、FADE、SAPA 等方法中的复杂动态卷积。无需高分辨率引导特征,也无需 CUDA 自定义算子。参数量、FLOPs、显存占用、推理延迟均大幅下降。在五大密集预测任务(语义分割、目标检测、实例分割、全景分割、单目深度估计)中均超越现有上采样器。
二、论文概要
-
研究问题: 上采样是密集预测模型(分割/检测/深度估计)的关键环节,常见的 NN / 双线性插值过于固定,卷积/动态卷积上采样(如 CARAFE、FADE)则效率低下。
-
提出方法: DySample 将上采样重新表述为 点采样 (point sampling),通过学习偏移量来决定采样点,而不是生成动态卷积核。
-
主要贡献:
- 提出采样点生成器,逐步优化采样点初始化、偏移范围、分组策略等。
- 构建 DySample 系列(DySample, DySample+, DySample-S, DySample-S+)。
- 证明其能在保持轻量的同时实现 SOTA 性能。
三、实验动机
- 动态卷积上采样(CARAFE/FADE/SAPA)虽然性能好,但存在:
-
需要高分辨率引导特征,应用场景受限;
-
自定义 CUDA 实现,工程成本高;
-
计算/存储开销大,推理慢。
- 动机: 寻找一种 既动态又高效 的上采样器,能替代双线性插值,作为通用插件应用到各种密集预测模型中。
四、创新之处
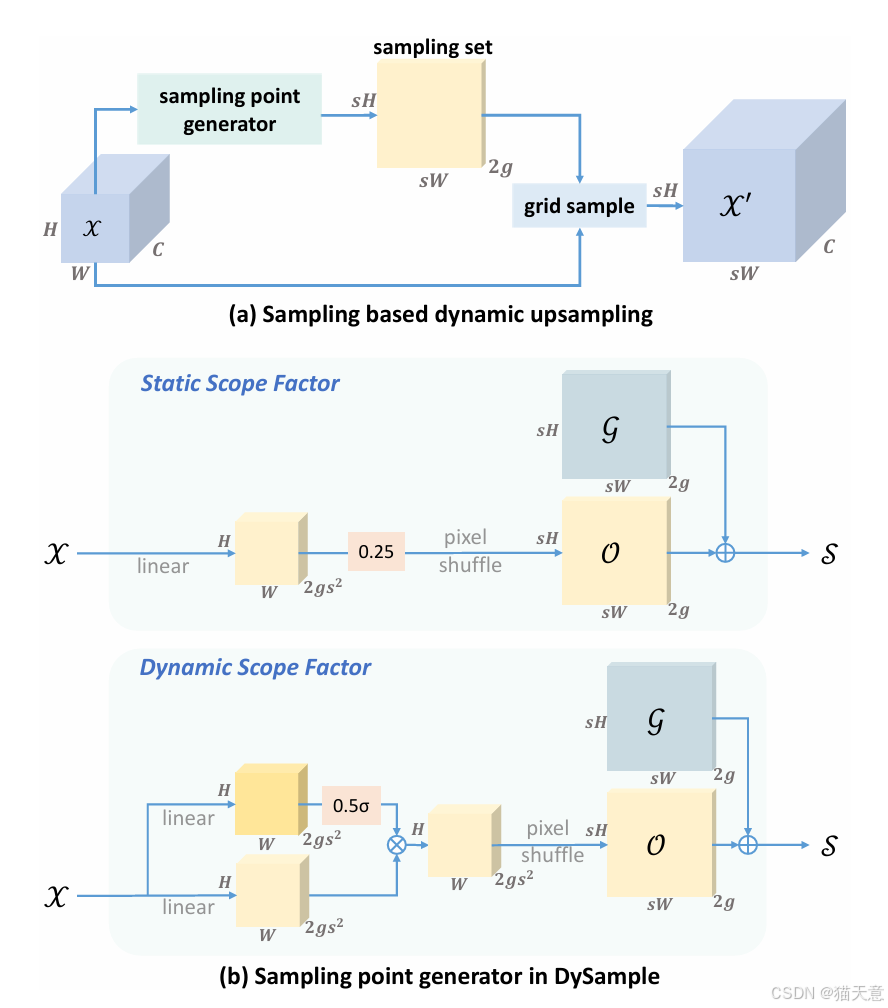
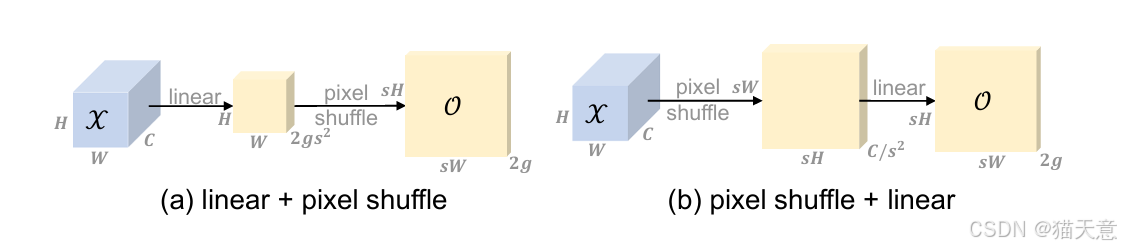
-
回归采样本质:不再生成卷积核,而是生成偏移点进行 grid sample。
-
采样点优化:提出最近邻初始化 → 双线性初始化,减少边界错乱。
-
偏移范围约束:静态范围因子(0.25)+ 动态范围因子,避免采样点重叠。
-
分组机制:通道分组采样,提高表达能力。
-
高效实现:完全基于 PyTorch 原生函数,无需 CUDA,推理速度接近双线性插值(6.2ms vs 1.6ms, 在 256×120×120 特征上)。
五、实验分析
-
任务覆盖: 语义分割(ADE20K)、目标检测与实例分割(MS COCO)、全景分割(MS COCO)、深度估计(NYU Depth V2)。
-
结果亮点:
SegFormer-B1 上 mIoU 43.58(超越 CARAFE 42.82,FADE 43.06,SAPA-B 43.20)。
MaskFormer (Swin-B/L) 上 mIoU 提升 1.21 和 0.80。
Faster R-CNN (R50) 上 AP 38.7,超过 CARAFE/FADE 等。
Mask R-CNN 上 bbox AP 39.6,segm AP 35.7,均超越其他方法。
Panoptic FPN 上 PQ 提升 +1.2 (R50) / +0.8 (R101)。
DepthFormer 上 δ<1.25 提升至 0.878(比 bilinear 高 0.05)。
- 复杂度分析(图8,第6页):
DySample 系列在 FLOPs、参数、显存、训练时间、推理延迟上均远低于 CARAFE/FADE/SAPA。
六、核心代码
源代码
import torch
import torch.nn as nn
import torch.nn.functional as Fdef normal_init(module, mean=0, std=1, bias=0):if hasattr(module, 'weight') and module.weight is not None:nn.init.normal_(module.weight, mean, std)if hasattr(module, 'bias') and module.bias is not None:nn.init.constant_(module.bias, bias)def constant_init(module, val, bias=0):if hasattr(module, 'weight') and module.weight is not None:nn.init.constant_(module.weight, val)if hasattr(module, 'bias') and module.bias is not None:nn.init.constant_(module.bias, bias)class DySample(nn.Module):def __init__(self, in_channels, scale=2, style='lp', groups=4, dyscope=False):super().__init__()self.scale = scaleself.style = styleself.groups = groupsassert style in ['lp', 'pl']if style == 'pl':assert in_channels >= scale ** 2 and in_channels % scale ** 2 == 0assert in_channels >= groups and in_channels % groups == 0if style == 'pl':in_channels = in_channels // scale ** 2out_channels = 2 * groupselse:out_channels = 2 * groups * scale ** 2self.offset = nn.Conv2d(in_channels, out_channels, 1)normal_init(self.offset, std=0.001)if dyscope:self.scope = nn.Conv2d(in_channels, out_channels, 1, bias=False)constant_init(self.scope, val=0.)self.register_buffer('init_pos', self._init_pos())def _init_pos(self):h = torch.arange((-self.scale + 1) / 2, (self.scale - 1) / 2 + 1) / self.scalereturn torch.stack(torch.meshgrid([h, h])).transpose(1, 2).repeat(1, self.groups, 1).reshape(1, -1, 1, 1)def sample(self, x, offset):B, _, H, W = offset.shapeoffset = offset.view(B, 2, -1, H, W)coords_h = torch.arange(H) + 0.5coords_w = torch.arange(W) + 0.5coords = torch.stack(torch.meshgrid([coords_w, coords_h])).transpose(1, 2).unsqueeze(1).unsqueeze(0).type(x.dtype).to(x.device)normalizer = torch.tensor([W, H], dtype=x.dtype, device=x.device).view(1, 2, 1, 1, 1)coords = 2 * (coords + offset) / normalizer - 1coords = F.pixel_shuffle(coords.view(B, -1, H, W), self.scale).view(B, 2, -1, self.scale * H, self.scale * W).permute(0, 2, 3, 4, 1).contiguous().flatten(0, 1)return F.grid_sample(x.reshape(B * self.groups, -1, H, W), coords, mode='bilinear',align_corners=False, padding_mode="border").view(B, -1, self.scale * H, self.scale * W)def forward_lp(self, x):if hasattr(self, 'scope'):offset = self.offset(x) * self.scope(x).sigmoid() * 0.5 + self.init_poselse:offset = self.offset(x) * 0.25 + self.init_posreturn self.sample(x, offset)def forward_pl(self, x):x_ = F.pixel_shuffle(x, self.scale)if hasattr(self, 'scope'):offset = F.pixel_unshuffle(self.offset(x_) * self.scope(x_).sigmoid(), self.scale) * 0.5 + self.init_poselse:offset = F.pixel_unshuffle(self.offset(x_), self.scale) * 0.25 + self.init_posreturn self.sample(x, offset)def forward(self, x):if self.style == 'pl':return self.forward_pl(x)return self.forward_lp(x)if __name__ == '__main__':x = torch.rand(2, 64, 4, 7)dys = DySample(64)print(dys(x).shape)
七、实验总结
-
DySample 证明了 “学习采样点”比“学习卷积核”更高效。
-
在多个密集预测任务上实现了 精度和效率双赢。
-
无需复杂 CUDA,部署友好。
-
局限性:边界质量(bIoU)稍逊于 FADE/SAPA 这类带高分辨率引导的上采样器。