Paimon系列:IDEA环境读写Paimon表
本文基于 Apache Flink 1.16 和 Apache Paimon 1.0.1,详细介绍如何配置 Paimon 环境、创建和使用追加表(Append-Only Table)与主键表(Primary-Key Table)的特点和使用。
一. IDEA 环境准备
下载官方paimon-1.0.1版本,本地编译选择对应的flink版本
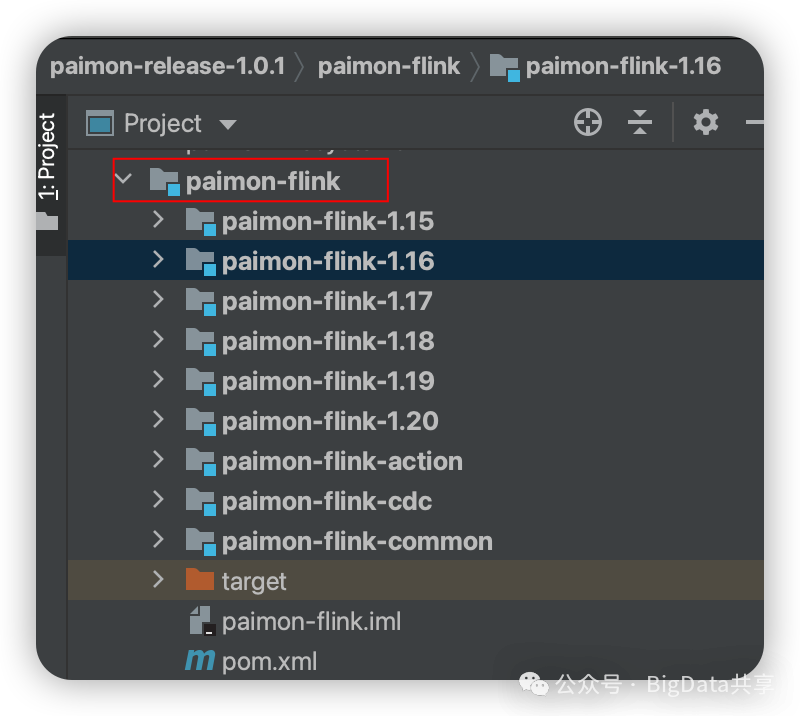
把对应的jar包安装到本地仓库:
mvn install:install-file -DgroupId=org.apache.paimon -DartifactId=paimon-flink-1.16 -Dversion=1.0.1 -Dpackaging=jar -Dfile=paimon-flink-1.16-1.0.1.jar在工程里引用对应的依赖
<dependency><groupId>org.apache.paimon</groupId><artifactId>paimon-flink-1.16</artifactId><version>1.0.1</version><scope>provided</scope></dependency>
二. 追加表
1. 追加表(Append Only Table) 特点
追加表是 Apache Paimon 中没有定义主键的表类型,默认情况下,表如果未指定主键,就被视为追加表。这种表主要用于追加数据的场景,类似于日志数据同步或不需要频繁更新的数据湖存储。
特点:
1.1. 无主键:追加表不定义主键,因此无法直接通过主键进行数据更新或删除操作。
1.2. 分为Scalable 表 和 Queue 表:Scalable 表没有桶的概念,无需考虑数据顺序、无需对数据进行hash partitioning;Queue 表按 bucket-key 分发,每个分桶中数据的消费顺序与数据写入Paimon表的顺序一致;
2. Scalable Table 的创建和写入
创建基本本地文件的 Paimon catalog,无主键表,定义 'bucket' = '-1'
/*** @author BigData共享*/public class AppendTable {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(10000l);env.getCheckpointConfig().setCheckpointStorage(new MemoryStateBackend(20 * 1024 * 1024));TableEnvironment tableEnv = StreamTableEnvironment.create(env);// 创建 paimon catalogtableEnv.executeSql("CREATE CATALOG paimon_catalog WITH (\n" +" 'type'='paimon',\n" +" 'warehouse'='file:///tmp/paimon'\n" +")");tableEnv.executeSql("USE CATALOG paimon_catalog");// 创建 scalable tabletableEnv.executeSql("CREATE TABLE IF NOT EXISTS scalable_table (\n" +" word STRING,\n" +" dt STRING\n" +") PARTITIONED BY (dt) with (\n" +" 'bucket' = '-1'\n" +")");tableEnv.executeSql("CREATE TEMPORARY TABLE IF NOT EXISTS word_table (\n" +" id INT,\n" +" word STRING\n" +") WITH (\n" +" 'connector' = 'datagen',\n" +" 'fields.id.kind' = 'random',\n" +" 'fields.id.min' = '1',\n" +" 'fields.id.max' = '100',\n" +" 'fields.word.length' = '1'\n" +")");// 插入数据tableEnv.executeSql("INSERT INTO scalable_table SELECT word, '20250816' FROM word_table");env.execute();}}
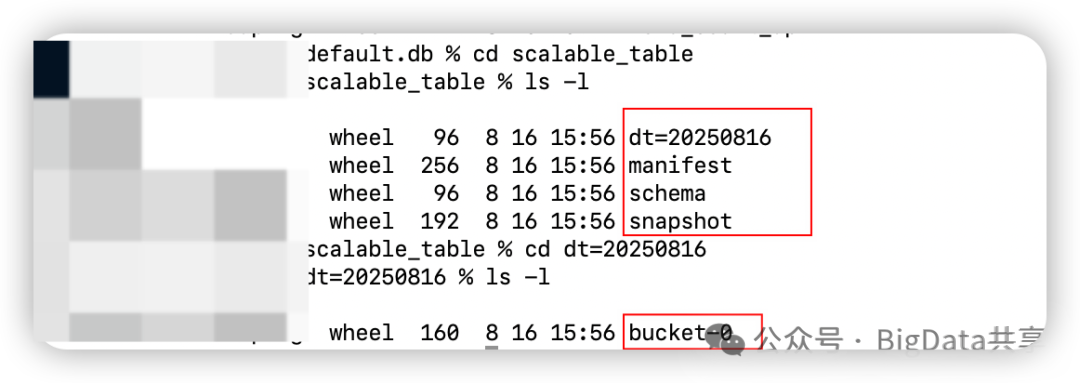
创建对应的元数据文件,mainfest,schema, snapshot 和对应的分区数据 dt=20250816
3. Queue 的创建和写入
创建基本本地文件的 Paimon catalog,无主键表,定义 'bucket' = '3', 'bucket-key' = 'id'
/*** @author BigData共享*/public class AppendTable {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(10000l);env.getCheckpointConfig().setCheckpointStorage(new MemoryStateBackend(20 * 1024 * 1024));TableEnvironment tableEnv = StreamTableEnvironment.create(env);// 创建 paimon catalogtableEnv.executeSql("CREATE CATALOG paimon_catalog WITH (\n" +" 'type'='paimon',\n" +" 'warehouse'='file:///tmp/paimon'\n" +")");tableEnv.executeSql("USE CATALOG paimon_catalog");// 创建 queue tabletableEnv.executeSql("CREATE TABLE IF NOT EXISTS queue_table (\n" +" id INT,\n" +" word STRING,\n" +" dt STRING\n" +") PARTITIONED BY (dt) with (\n" +" 'bucket' = '3',\n" +" 'bucket-key' = 'id'\n" +")");tableEnv.executeSql("CREATE TEMPORARY TABLE IF NOT EXISTS word_table (\n" +" id INT,\n" +" word STRING\n" +") WITH (\n" +" 'connector' = 'datagen',\n" +" 'fields.id.kind' = 'random',\n" +" 'fields.id.min' = '1',\n" +" 'fields.id.max' = '100',\n" +" 'fields.word.length' = '1'\n" +")");// 插入数据tableEnv.executeSql("INSERT INTO queue_table SELECT id, word, '20250816' FROM word_table");env.execute();}}
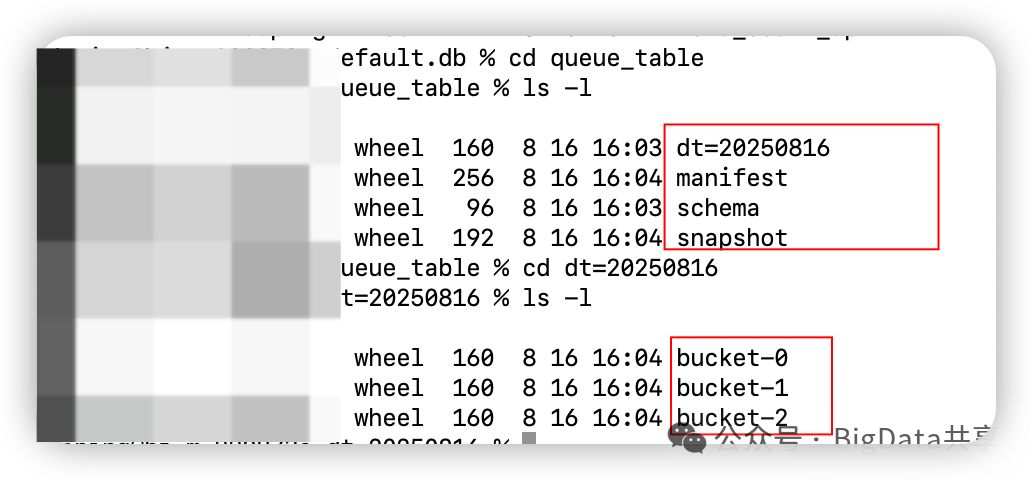
创建对应的元数据文件,mainfest,schema, snapshot 和对应的分区数据 dt=20250816,分桶数据:bucket-0, bucket-1, bucket-2
三. Primary-Key 表
1. Primary-Key Table(主键表)特点
主键表是 Apache Paimon 中定义了主键的表类型,支持高效的 upsert 操作和变更日志生成,适合需要实时更新和复杂数据处理的应用场景。
特点:
1.1. 主键约束:主键由一组列组成,保证每条记录的唯一性。Paimon 在每个 bucket 内按主键排序,优化基于主键的查询性能。
1.2. 支持 upsert 语义:支持插入、更新和删除操作,适合处理动态变化的数据(如数据库的 binlog)。
1.3. 合并引擎:主键表通过合并引擎(Merge Engine)处理具有相同主键的记录,支持以下类型:Deduplicate/Partial Update/Aggregation/First Row。
1.4. 分桶模式:
- 动态分桶(bucket = -1):自动调整分桶数量,不支持多 Flink 作业并发写入。
- 固定分桶(bucket = <num>):指定固定分桶数量,支持并发写入,但需确保主键包含所有分区键以避免跨分区更新。
1.5. Changelog 生成:支持生成完整的变更日志(INSERT、UPDATE、DELETE),通过 changelog-producer 配置:none/input/lookup/full-compaction。
2. Primary-Key 的创建和写入
创建基本本地文件的 Paimon catalog,定义分区键 PRIMARY KEY (dt, id) NOT ENFORCED;
/*** @author BigData共享*/public class PrimaryKeyTable {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(10000l);env.getCheckpointConfig().setCheckpointStorage(new MemoryStateBackend(20 * 1024 * 1024));TableEnvironment tableEnv = StreamTableEnvironment.create(env);tableEnv.getConfig().set("table.exec.sink.upsert-materialize", "NONE");// 创建 paimon catalogtableEnv.executeSql("CREATE CATALOG paimon_catalog WITH (\n" +" 'type'='paimon',\n" +" 'warehouse'='file:///tmp/paimon'\n" +")");tableEnv.executeSql("USE CATALOG paimon_catalog");// 创建 primary-key tabletableEnv.executeSql("CREATE TABLE IF NOT EXISTS primary_key_table (\n" +" id INT,\n" +" word STRING,\n" +" dt STRING,\n" +" PRIMARY KEY (dt, id) NOT ENFORCED\n" +")\n" +"PARTITIONED BY (dt) with (\n" +" 'bucket' = '-1'\n" +")");tableEnv.executeSql("CREATE TEMPORARY TABLE IF NOT EXISTS word_table (\n" +" id INT,\n" +" word STRING\n" +") WITH (\n" +" 'connector' = 'datagen',\n" +" 'fields.id.kind' = 'random',\n" +" 'fields.id.min' = '1',\n" +" 'fields.id.max' = '100',\n" +" 'fields.word.length' = '1'\n" +")");// 插入数据tableEnv.executeSql("INSERT INTO primary_key_table (SELECT id, word, '20250816' FROM word_table UNION SELECT id, word, '20250817' FROM word_table)");env.execute();}}
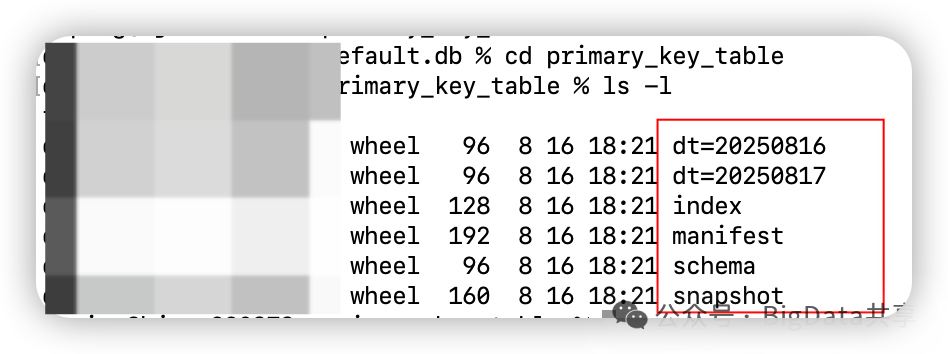
创建对应的元数据文件,mainfest,schema, snapshot,需要注意的是,下面元数据文件中多了个index文件; 对应的分区数据 dt=20250816,dt=20250817
3. 使用注意事项
多个insert into table_xx 语句写入同一张表会有问题,可以先把多条select 语句 union 后再插入;或者表新增参数:'write-only'='true',然后再单独启动一个Dedicated Compaction Job。
后面的文章会对主键表的特性做详细分析。