kaggle-NeurIPS - Open Polymer Prediction 2025-0.069
相关理论与技术
RDKit分子特征
核心思想
RDKit是一个开源的计算化学工具包,广泛应用于药物发现、化学信息学和材料科学等领域。其核心思想是将分子的线性字符串表示如SMILES,转化为结构化的分子对象,并基于化学规则与图论算法,计算出一系列能够定量描述分子物理化学性质和结构的特征,即分子描述符。
关键特征
本研究从SMILES字符串中提取了25类关键的分子描述符,用于表征聚合物的基本结构特性。这些描述符及其代表的物理化学意义如下表2.1所示:
表2. 1 各个分子描述符含义
| 特征 | 中文名称 | 含义 |
| MolWt | 分子量 | 分子量越大,链缠结越严重,Tg和熔融温度可能升高,机械强度增强。 |
| MolLogP | 脂水分配系数的对数 | 反映分子亲脂性或疏水性。亲脂性强的分子可能堆砌更紧密,影响聚合物密度。 |
| NumHAcceptors | 氢键受体数量 | 氢键受体越多,分子间可形成的氢键越多,分子间作用力越强,可能提高 Tg 和结晶度。 |
| NumHDonors | 氢键供体数量 | 供体越多,分子间氢键作用越强,聚合物刚性增加,Tg升高。 |
| NumRotatableBonds | 可自由旋转的单键数量 | 数量越多,分子链柔性越好,链段运动更自由,通常Tg降低。 |
| TPSA | 拓扑极性表面积 | 反映分子极性大小。TPSA越大,极性越强,聚合物可能更易吸水。 |
| NumRings | 分子中所有环的总数 | 环结构增加分子刚性,环数量越多,聚合物Tg和热稳定性可能越高。 |
| HeavyAtomCount | 重原子数量 | 反映分子大小和复杂度。重原子越多,分子链可能越刚硬。 |
| NumValenceElectrons | 价电子总数 | 影响分子的电子云分布和化学反应性。 |
| NumAromaticRings | 芳香环数量 | 芳香环因共轭作用具有强刚性,数量越多,聚合物链段运动越困难。 |
| FractionCSP3 | sp³杂化碳占总碳原子的比例 | 比例越高,分子饱和程度越高,链柔性越好;比例低则刚性强。 |
| NumAliphaticCarbocycles | 脂肪族碳环数量 | 脂肪族碳环刚性弱于芳香环,但仍限制链旋转,适度增加聚合物Tg。 |
| NumAliphaticHeterocycles | 脂肪族杂环数量 | 杂原子引入极性,环结构增加刚性,综合影响分子间作用力和Tg。 |
| NumAromaticCarbocycle | 芳香族碳环数量 | 兼具芳香环的刚性和杂原子的极性,增强分子间作用力。 |
| NumAromaticCarbocycle | 分子中环的总数 | 反映环结构对分子刚性的整体贡献,环越多,聚合物链刚性越强。 |
| RingCount | 含N-H或O-H键的基团数量 | 直接关联分子间氢键能力,数量越多,氢键作用越强。 |
| NHOHCount | 脂肪族碳环数量 | 同NumAliphaticCarbocycles,从另一函数角度表征脂肪族碳环对刚性的贡献。 |
| NOCount | 含N或O原子的基团数量 | 反映分子极性的整体水平,N/O越多,极性越强。 |
| NumAliphaticCarbocycles2 | 脂肪族碳环数量 | 同NumAliphaticCarbocycles,从另一函数角度表征脂肪族碳环对刚性的贡献。 |
| NumAliphaticHeterocycles2 | 脂肪族杂环数量 | 与NumAliphaticHeterocycles一致,从另一函数角度重复表征。 |
| NumAromaticCarbocycles2 | 芳香族碳环数量 | 强化芳香碳环对刚性的贡献表征。 |
| NumAromaticHeterocycles2 | 芳香族杂环数量 | 补充表征芳香杂环的刚性和极性影响。 |
| NumSaturatedCarbocycles | 饱和碳环数量 | 饱和环刚性弱于芳香环,但比链状结构强,适度增加聚合物Tg。 |
| NumSaturatedHeterocycles | 饱和杂环数量 | 饱和杂环的杂原子引入极性,环结构提供一定刚性。 |
| NumSaturatedRings | 饱和环总数 | 综合反映所有饱和环对分子刚性的贡献。 |
优势分析
与直接从原始数据中学习特征相比,使用RDKit计算分子描述符的可解释性强,因为每个描述符都有明确的物理化学意义,便于分析特征与目标属性之间的关系。以及计算效率高,描述符的计算速度快,为模型提供了低成本的特征输入。由于规则的计算受随机性的影响较小,所以特征输出也稳定。
ChemBERTa模型
核心思想
ChemBERTa是一种基于Transformer架构的预训练语言模型,其核心思想是将SMILES字符串视为一种“化学语言”,通过自监督学习的方式在大规模分子数据集上进行预训练,从而学习分子结构的深层语义表示。模型通过掩盖SMILES中的部分token并进行预测,从而学会理解原子、官能团及其上下文关系。
数学模型
自注意力机制是Transformer架构的核心组件,其数学表达式为:
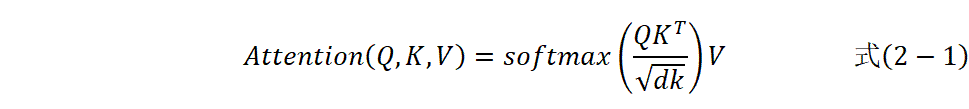
其中![]() 、
、![]() 、
、![]() 分别表示查询、键和值矩阵,
分别表示查询、键和值矩阵,![]() 是键向量的维度。
是键向量的维度。
多头注意力机制允许模型同时关注来自不同表示子空间的信息。
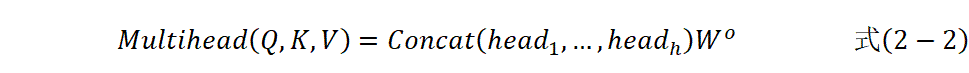
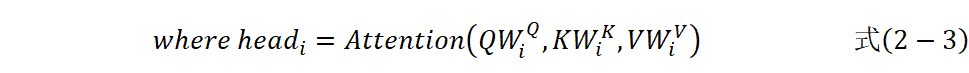
ChemBERTa采用掩码语言模型作为预训练目标
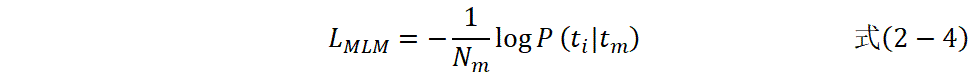
其中![]() 是被掩盖的token数量;
是被掩盖的token数量;
![]() 是被掩盖token的真实值;
是被掩盖token的真实值;
![]() 是序列中所有未被覆盖的token。
是序列中所有未被覆盖的token。
优势分析
ChemBERTa凭借预训练机制具备强大的上下文感知能力,能够深度理解分子结构中原子、官能团的排列关系及相互作用,有效捕捉传统方法难以识别的长程依赖特征。其迁移学习特性显著,通过在大规模分子数据集上的预训练,模型已习得通用的分子结构表示规律,当应用于特定下游任务时,只需少量标注数据即可快速适配,大幅降低了模型训练的样本需求。同时,作为端到端处理模型,它能直接从SMILES字符串中自主提取特征,省去了繁琐的人工特征设计环节,既减少了领域知识依赖,又避免了人为特征选择可能带来的偏差。
自编码器
核心思想
自编码器是一种无监督的神经网络模型,旨在学习数据的高效表示。通过编码器将高维输入压缩到低维潜空间,再通过解码器进行重建。
数学模型
编码过程:
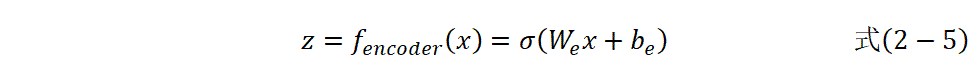
其中,![]() 是输入特征向量、
是输入特征向量、![]() 是编码权重矩阵、
是编码权重矩阵、![]() 是编码器偏置向量、
是编码器偏置向量、![]() 是激活函数。
是激活函数。
解码过程:
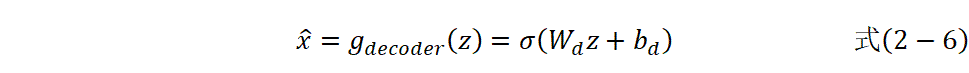
损失函数:
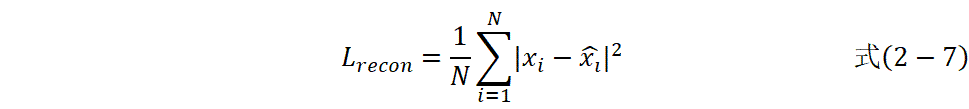
改进的自编码器结构,本研究采用深度编码器结构增强特征提取能力。
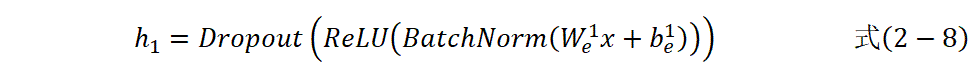

-
-
-
- 优势分析
-
-
自编码器具有高效的特征降维能力,能在保留关键信息的前提下,将高维输入压缩为低维潜变量表示,减少数据冗余和计算负担,凸显隐藏在高维数据中的核心模式。具备强大的特征融合能力,可整合不同来源的特征信息如RDKit描述符与ChemBERTa嵌入特征,通过非线性变换挖掘特征间的深层关联,生成更全面的综合表征。通过无监督学习特性使其能充分利用大量无标签数据进行训练,无需依赖昂贵的标注信息,既降低了对数据标注的依赖,又能从原始数据中自主学习数据分布规律,增强模型的泛化能力。
多任务学习
核心思想
MTL是一种归纳迁移学习方法,通过同时学习多个相关任务,共享模型表示,从而提高每个任务的泛化性能和学习效率。
数学模型
MTL的优化目标可以表示为最小化加权损失函数,如式(2-11)。
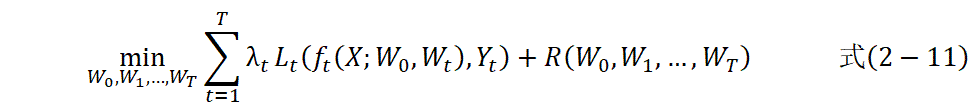
T是任务数量,本研究中T为5;
![]() 是共享参数;
是共享参数;
![]() 是第t个任务的特定参数;
是第t个任务的特定参数;
![]() 是第t个任务的损失函数;
是第t个任务的损失函数;
![]() 是第t个任务的权重;
是第t个任务的权重;
![]() 是正则化项分析。
是正则化项分析。
该目标函数旨在同时优化所有任务的预测性能,并通过权重![]() 和共享参数
和共享参数 ![]() 实现任务间的知识迁移与平衡。
实现任务间的知识迁移与平衡。
对于共享参数和任务特定参数采用不同的梯度更新策略:
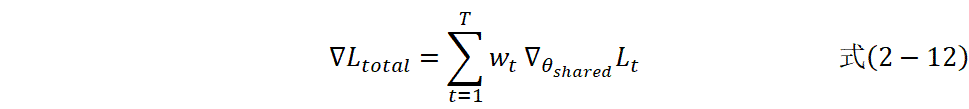
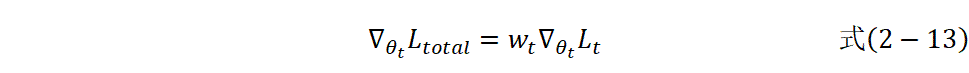
本研究采用AdamW优化器进行参数更新:

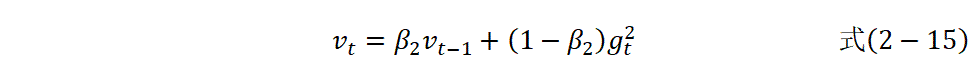
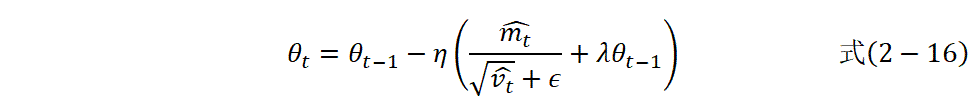
其中,![]() 是一阶动量估计、
是一阶动量估计、![]() 是二阶动量估计、
是二阶动量估计、 是动量衰减率、
是动量衰减率、![]() 是当前时间步的梯度、
是当前时间步的梯度、![]() 是学习率、
是学习率、![]() 是权重衰减系数、
是权重衰减系数、![]() 是数值稳定项。
是数值稳定项。
优势分析
MTL通过任务间的协同优化展现出显著优势。模型通过共享参数学习通用表示,这种参数共享机制天然限制了模型复杂度,减少了对单一任务训练数据的过拟合风险,使模型在小样本场景下仍能保持稳定性能。数据效率大幅提升,借助相关任务间的知识迁移,模型可将从数据丰富任务中习得的规律迁移到数据稀缺任务,有效缓解数据不足问题,提升整体学习效率。特征学习更具鲁棒性,模型被迫学习对所有任务均有价值的通用特征,而非仅适用于单一任务的特异性特征,这种特征表示更贴近数据本质,泛化能力更强。计算效率显著提高,通过一次模型前向传播即可同时完成多个任务的预测,相比独立训练多个单任务模型,大幅节省了计算资源和训练时间。
关键技术
本项目涉及的核心技术与工具包括:
表2. 2 关键技术
| 技术栈 | 版本 | 用途 |
| PyTorch | 2.0.1 | 深度学习框架 |
| Transformers | 4.37.0 | 预训练模型加载 |
| RDKit | 2022.09.5 | 化学信息学工具包 |
| scikit-learn | 1.2.2 | 用于数据预处理 |
| Pandas | 2.0.3 | 数据清洗、整合 |
| Numpy | 1.24.3 | 高效数值计算 |
| Seaborn | 3.7.1 | 数据可视化 |
| Tqdm | 4.66.1 | 用于进度条显示 |
| GPU T4×2 | 16GB VRAM | 训练加速 |
数据预处理
数据描述
本次竞赛使用的数据来自NeurIPS Open Polymer Prediction 2025竞赛公开数据集,该数据集旨在通过以SMILES字符串表示的聚合物的化学结构预测其关键物理化学性质,包括Tg、FFV、Tc、Density、Rg,以加速可持续材料的开发。
需预测的5种物理化学性质的含义如表3.1所示。
表3. 1 标签的物理化学含义
| 性质 | 中文名称(单位及范围) | 含义 |
| Tg | 玻璃化转变温度(℃) | 指聚合物从玻璃态转变为高弹态的临界温度,是决定材料使用范围的关键参数。 |
| FFV | 分数游离体积(0-1) | 反映分子堆积的紧密程度,与材料的扩散性、透气性等密切相关。 |
| Tc | 热导率( W/(m・K)) | 衡量材料传递热量的能力,是热管理材料设计的核心指标。 |
| Density | 反映单位体积的质( g/cm³) | 反映单位体积的质量,与材料的强度、成本等直接相关。 |
| Rg | 回转半径(Å) | 描述聚合物分子链的空间尺寸,与材料的柔韧性、溶解性等相关。 |
数据集包含训练集、测试集及补充训练数据,所有数据均来自主办方圣母大学的分子动力学模拟结果,经过标准化处理后开源发布。
各个数据集基本信息如表3.2所示。
表3. 2 数据集基本信息
| 数据集 | 形状 | 特征 |
| Train | (7973,7) | Id、SMILES、Tg、FFV、Tc、Density、Rg |
| Test | (3,2) | Id、SMILES |
| Dataset1 | (874,2) | SMILES、TC_mean |
| Dataset2 | (7208,1) | SMILES |
| Dataset3 | (46,2) | SMILES、Tg |
| Dataset4 | (862,2) | SMILES、FFV |
读取数据,查看所有数据集的形状、并初步统计缺失率,代码如下:
def load_data():try:train_df=pd.read_csv('/kaggle/input/neurips-open-polymer-prediction-2025/train.csv')test_df=pd.read_csv('/kaggle/input/neurips-open-polymer-prediction-2025/test.csv')dataset1=pd.read_csv('/kaggle/input/neurips-open-polymer-prediction-2025/train_supplement/dataset1.csv')dataset2=pd.read_csv('/kaggle/input/neurips-open-polymer-prediction-2025/train_supplement/dataset2.csv')dataset3=pd.read_csv('/kaggle/input/neurips-open-polymer-prediction-2025/train_supplement/dataset3.csv')dataset4=pd.read_csv('/kaggle/input/neurips-open-polymer-prediction-2025/train_supplement/dataset4.csv')print("训练集形状:", train_df.shape)print("测试集形状:", test_df.shape)print("补充数据集形状:")print(f"dataset1: {dataset1.shape}")print(f"dataset2: {dataset2.shape}")print(f"dataset3: {dataset3.shape}")print(f"dataset4: {dataset4.shape}")missing_rates = {}target_cols = ['Tg', 'FFV', 'Tc', 'Density', 'Rg']for col in target_cols:missing_rate = train_df[col].isnull().sum() / len(train_df) * 100missing_rates[col] = missing_rateprint(f"{col}缺失率: {missing_rate:.2f}%")print("\n训练集基本信息:")print(train_df.info())print("\n测试集基本信息:")print(test_df.info())return train_df, test_df, dataset1, dataset2, dataset3, dataset4, missing_ratestrain_df, test_df, dataset1, dataset2, dataset3, dataset4, missing_rates = load_data()代码展示结果如图3.1。

图3. 1 数据集基本信息-代码运行结果
从上述数据分析和可视化分析可知,有4个标签的缺失值都大于90%,如图3.2。
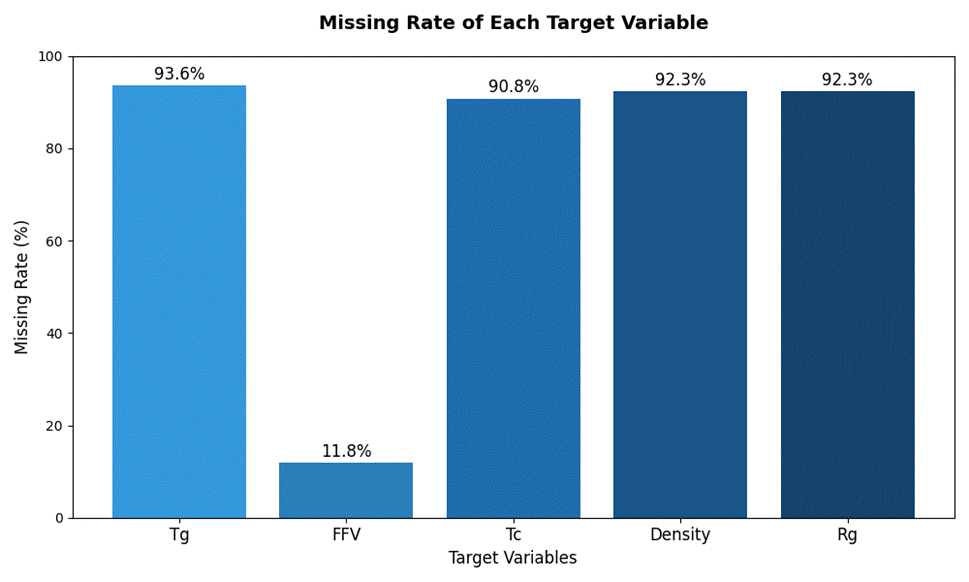
图3. 2样本标签缺失率
如图3.3,从缺失值模式热图中可知,横坐标是标签,纵坐标是样本,样本标签呈现模块化缺失的规律,缺失以连续块状为主。
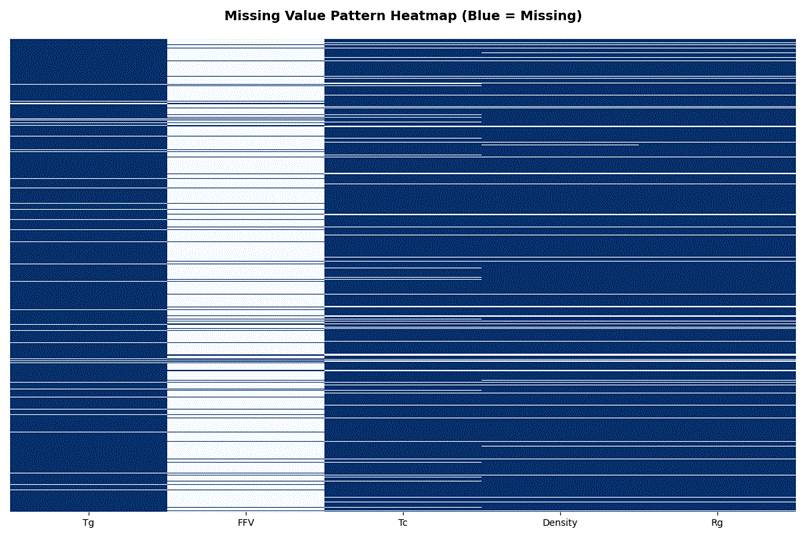
图3. 3 缺失值模式热图
如图3.4,从相关性热图可知,呈现正相关的Tc、Density、Rg三者的缺失相关性极高,意味着当其中一个变量缺失时,另外两个也大概率缺失。Tg与FFV呈现负相关,即Tg缺失时,FFV可能存在;FFV缺失时,Tg可能存在,呈现非此即彼的互斥关系。呈现低相关性的Tg与Tc、Density、Rg,以及FFV与Tc、Density、Rg的相关性均接近0,说明这两组的缺失几乎独立。
因此推测样本标签的缺失是故意缺失,而非数据质量问题。如果这种缺失不是随机误差或测量失误导致的,而是包含了人为设计的规则,那么这些规则本身可能隐含着数据的内在逻辑。所以最后对数据处理得出的结论就是,不盲目填充缺失,而是保留其缺失结构。
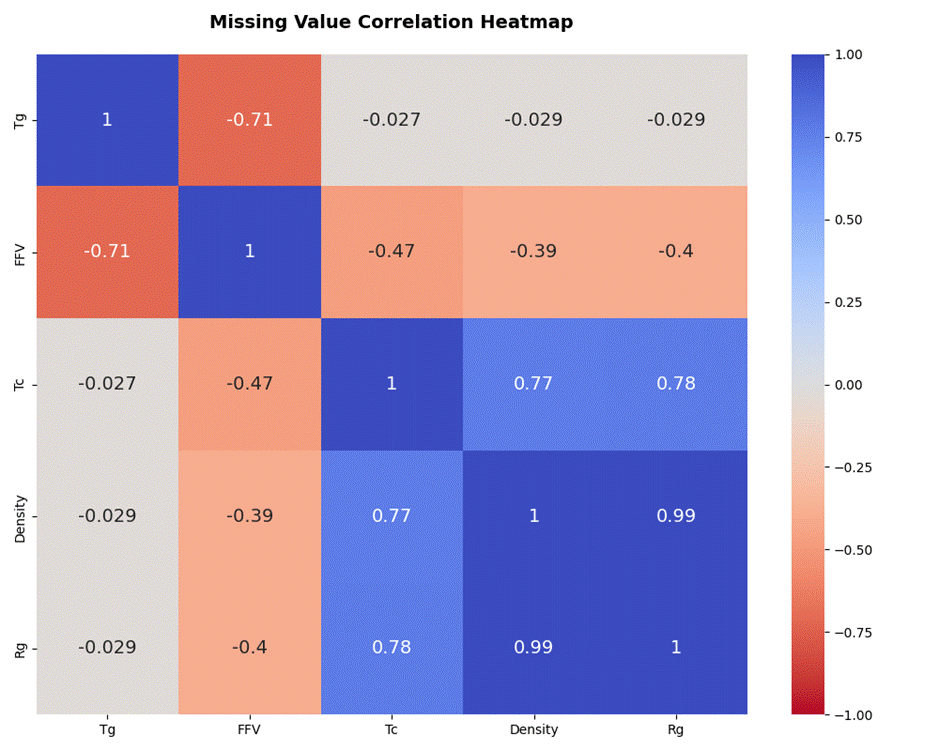
图3. 4 缺失值相关性热图
缺失值可视化代码如下:
def visualize_missing_data(train_df):print("\n=== Missing Value Visualization ===")target_cols = ['Tg', 'FFV', 'Tc', 'Density', 'Rg']missing_rates = [train_df[col].isnull().sum() / len(train_df) * 100 for col in target_cols]plt.figure(figsize=(10, 6))bars = plt.bar(range(len(target_cols)), missing_rates,color=['#3498db', '#2980b9', '#1f6dad', '#195688', '#14446b'])plt.xlabel('Target Variables', fontsize=12)plt.ylabel('Missing Rate (%)', fontsize=12)plt.title('Missing Rate of Each Target Variable', fontsize=14, pad=20, fontweight='bold')plt.xticks(range(len(target_cols)), target_cols, fontsize=12)for i, bar in enumerate(bars):height = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2., height + 0.5,f'{missing_rates[i]:.1f}%', ha='center', va='bottom', fontsize=12)plt.ylim(0, 100)plt.tight_layout()plt.savefig('missing_rates.png')plt.show()plt.figure(figsize=(12, 8))missing_matrix = train_df[target_cols].isnull().astype(int)sns.heatmap(missing_matrix, cbar=False, cmap='Blues', yticklabels=False)plt.title('Missing Value Pattern Heatmap (Blue = Missing)', fontsize=14, pad=20, fontweight='bold')plt.tight_layout()plt.savefig('missing_pattern_heatmap.png')plt.show()plt.figure(figsize=(10, 8))missing_corr = missing_matrix.corr()sns.heatmap(missing_corr, annot=True, cmap='coolwarm_r', center=0, vmin=-1, vmax=1,annot_kws={"size": 14})plt.title('Missing Value Correlation Heatmap', fontsize=14, pad=20, fontweight='bold')plt.tight_layout()plt.savefig('missing_correlation_heatmap.png')plt.show()print("\nExplanation of Missing Value Correlation:")print("Positive values: Two variables tend to be missing simultaneously")print("Negative values: When one variable is missing, the other tends to be non-missing")print("Values close to 0: No obvious relationship between missing patterns")虽然训练集有大量的规律缺失的现象,但是还有补充数据可用。
补充数据dataset1、3、4分别含有一个标签。如图3.5、3.6,dataset1与训练集有737个交集数据,dataset3、4无交集数据,dataset2是无标签数据,但是样本量较多,与训练集交集也较多。
由上述分析结果,可考虑使用补充数据dataset1、3、4补充训练集,datasset2的7208个样本可以用于后续分析其内在聚合物规律。
因此在数据处理中的做法,可以考虑先补充再扩充。
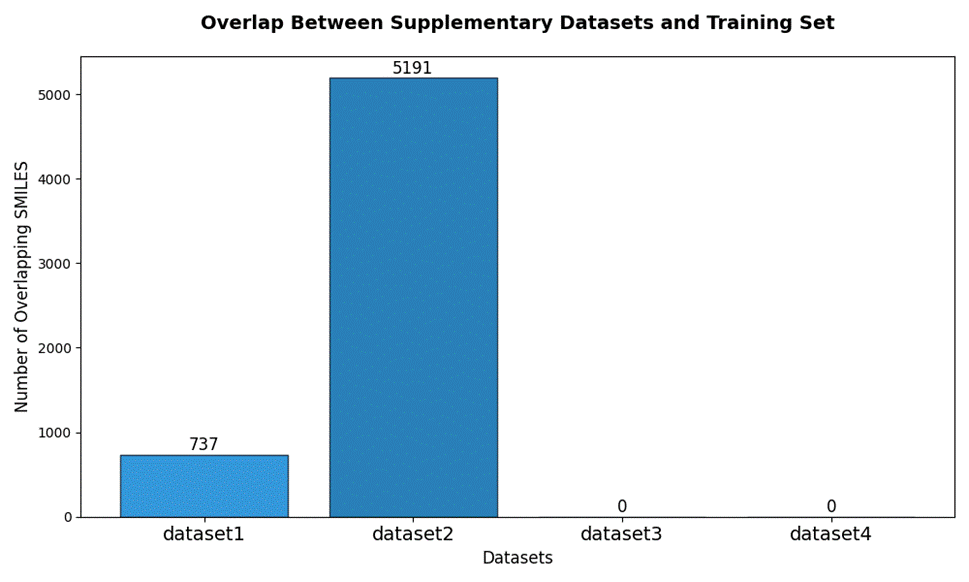
图3. 5 补充数据与训练集交集个数展示
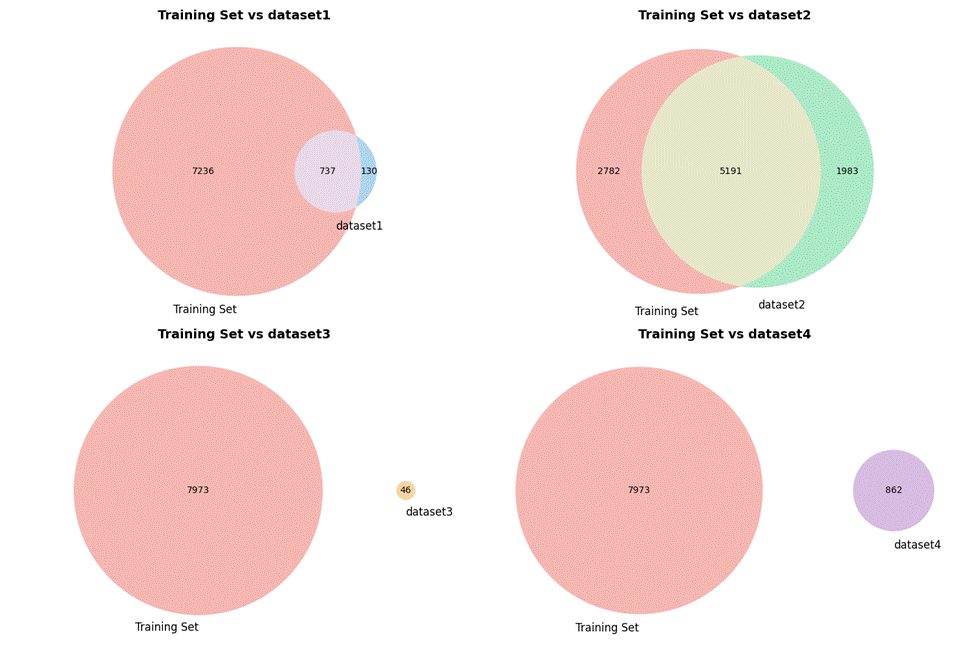
图3. 6 所有数据集韦恩图
可视化补充数据与训练集数据交集代码如下:
def visualize_dataset_overlaps(train_df, dataset1, dataset2, dataset3, dataset4):print("\n=== Dataset Overlap Visualization ===")train_smiles = set(train_df['SMILES'])ds1_smiles = set(dataset1['SMILES'])ds2_smiles = set(dataset2['SMILES'])ds3_smiles = set(dataset3['SMILES'])ds4_smiles = set(dataset4['SMILES'])overlaps = {'dataset1': len(train_smiles & ds1_smiles),'dataset2': len(train_smiles & ds2_smiles),'dataset3': len(train_smiles & ds3_smiles),'dataset4': len(train_smiles & ds4_smiles)}colors = ['#3498db', '#2980b9', '#1f6dad', '#195688']plt.figure(figsize=(10, 6))bars = plt.bar(range(len(overlaps)), list(overlaps.values()), color=colors, edgecolor='#2c3e50')plt.xlabel('Datasets', fontsize=12)plt.ylabel('Number of Overlapping SMILES', fontsize=12)plt.title('Overlap Between Supplementary Datasets and Training Set',fontsize=14, pad=20, fontweight='bold')plt.xticks(range(len(overlaps)), list(overlaps.keys()), fontsize=14)for i, bar in enumerate(bars):height = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2., height + 5,f'{list(overlaps.values())[i]}',ha='center', va='bottom', fontsize=12)plt.tight_layout()plt.savefig('dataset_overlaps.png')plt.show()try:from matplotlib_venn import venn2plt.figure(figsize=(15, 10)venn_colors = [('#e74c3c', '#3498db'), # dataset1: 红色系与蓝色系('#e74c3c', '#2ecc71'), # dataset2: 红色系与绿色系('#e74c3c', '#f39c12'), # dataset3: 红色系与橙色系('#e74c3c', '#9b59b6') # dataset4: 红色系与紫色系]plt.subplot(2, 2, 1)venn2([train_smiles, ds1_smiles], ('Training Set', 'dataset1'),set_colors=venn_colors[0])plt.title('Training Set vs dataset1', fontsize=14, fontweight='bold')plt.subplot(2, 2, 2)venn2([train_smiles, ds2_smiles], ('Training Set', 'dataset2'),set_colors=venn_colors[1])plt.title('Training Set vs dataset2', fontsize=14, fontweight='bold')plt.subplot(2, 2, 3)venn2([train_smiles, ds3_smiles], ('Training Set', 'dataset3'),set_colors=venn_colors[2])plt.title('Training Set vs dataset3', fontsize=14, fontweight='bold')plt.subplot(2, 2, 4)venn2([train_smiles, ds4_smiles], ('Training Set', 'dataset4'),set_colors=venn_colors[3])plt.title('Training Set vs dataset4', fontsize=14, fontweight='bold')plt.tight_layout()plt.savefig('dataset_venn_diagrams.png')plt.show()except ImportError:print("matplotlib_venn not installed, skipping Venn diagrams")return overlaps# print("步骤3: 可视化数据集重叠")overlaps = visualize_dataset_overlaps(train_df, dataset1, dataset2, dataset3, dataset4)前面都是考虑的数据的质量问题,下面分析标签的内在规律。
从图3.7中可以看出每个目标属性都呈现明显的集中趋势,反映了高分子材料在这些性能上的集中范围,但也存在少数离群样本,可能对应特殊结构或成分的高分子。其中Tg主要集中在0-200区间,呈单峰分布,少数样本Tg可达 500 左右。FFV集中在0.3-0.45区间,高 FFV(>0.5)的样本极少。Tc分布较宽0.1-0.5,峰值在0.2-0.3附近,反映材料结晶特性的多样性。Density集中在0.8-1.2区间,符合常见高分子材料的密度范围,高值(>1.6)样本极少。Rg主要在10-25区间,呈单峰分布,反映多数高分子的分子链尺寸或聚集态结构处于该范围。
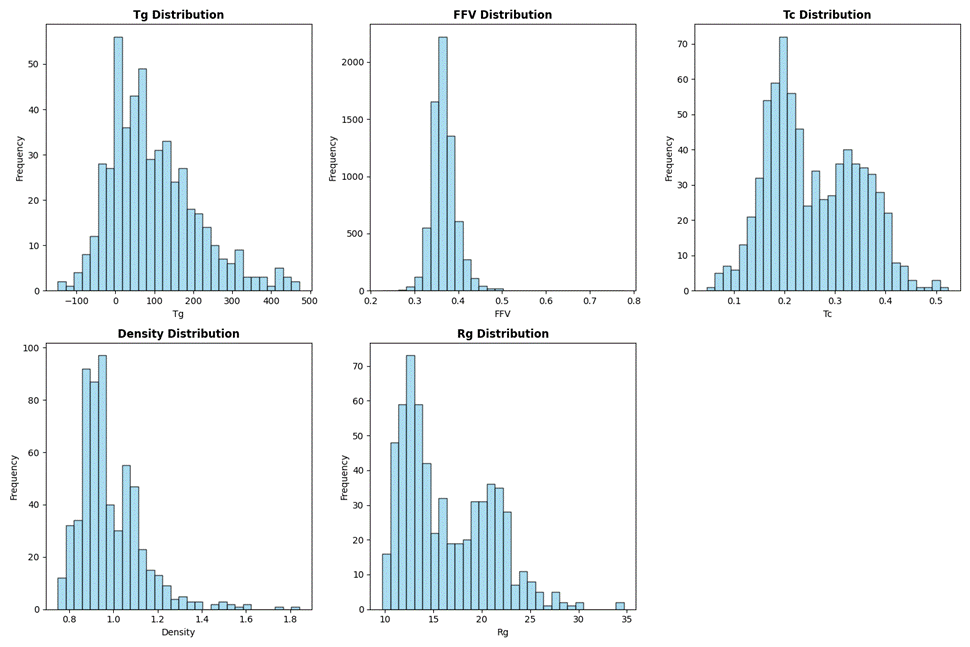
图3. 7 标签数据分布
从图3.8标签相关性热图分析可知Tc与Rg是正相关,相关系数为0.55,说明结晶温度越高,回转半径越大。
Tc与Density是负相关,相关系数为-0.49,则说明结晶温度越高,密度往往越低。
Tg与Tc是弱相关。
热图中出现了白块,即FFV与Tg的相关性没有计算出来,这是因为在上述图3.4的缺失值相关性分析中,FFV与Tg的缺失率是呈现强负相关,即FFV缺失时,Tg很可能存在,而Tg存在时,FFV又缺失了,因此FFV与Tg同时存在的样本较少,导致缺乏足够的共同样本支撑相关性的计算。
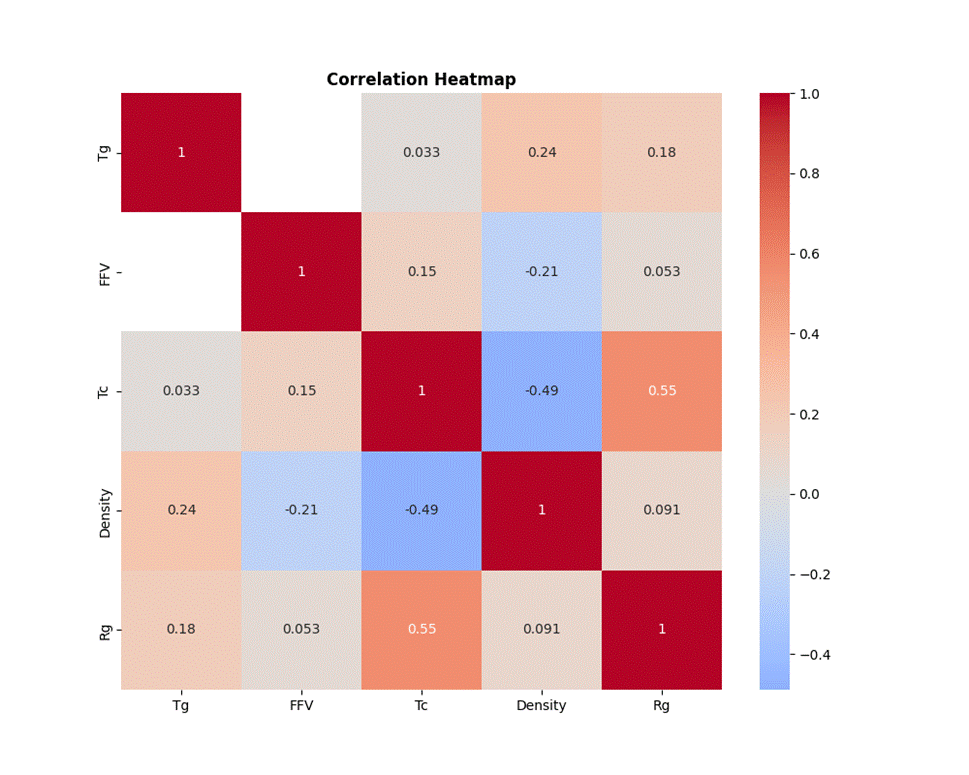
图3. 8 标签相关性热图
对训练集标签分布和相关性的可视化如下:
def visualize_data_distributions(train_df):target_cols = ['Tg', 'FFV', 'Tc', 'Density', 'Rg']fig, axes = plt.subplots(2, 3, figsize=(15, 10))axes = axes.flatten()for i, col in enumerate(target_cols):if col in train_df.columns:non_null_data = train_df[col].dropna()if len(non_null_data) > 0:axes[i].hist(non_null_data,bins=30,alpha=0.7, color='skyblue', edgecolor='black')axes[i].set_title(f'{col}Distribution', fontweight='bold')axes[i].set_xlabel(col)axes[i].set_ylabel('Frequency')for j in range(i+1, len(axes)):fig.delaxes(axes[j])plt.tight_layout()plt.savefig('target_distributions.png')plt.show()numeric_cols = train_df.select_dtypes(include=[np.number]).columns.tolist()numeric_cols = [col for col in numeric_cols if col in target_cols and train_df[col].notnull().sum() > 10]if len(numeric_cols) > 1:plt.figure(figsize=(10, 8))correlation_matrix = train_df[numeric_cols].corr()sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)plt.title('Correlation Heatmap', fontweight='bold')plt.savefig('correlation_heatmap.png')plt.show()visualize_data_distributions(train_df)-
-
-
数据清洗
-
-
根据上述对训练集数据和补充数据的缺失值和标签分布的分析,进行如下的数据清洗与整合。
利用补充数据集对训练集标签的补充、从补充数据中筛选出原始训练集没有包含的SMILES作为新样本进行样本扩充、过滤无效样本即完全没有标签的数据、整合无标签数据用于后续训练自编码器。
清洗之后对有效样本的统计如下图3.9、3.10、3.11。
虽然清洗前后数据的部分标签的缺失率相对增加这是因为总样本扩张而出现的变化,但总样本规模和有效样本的绝对数量有所提升。
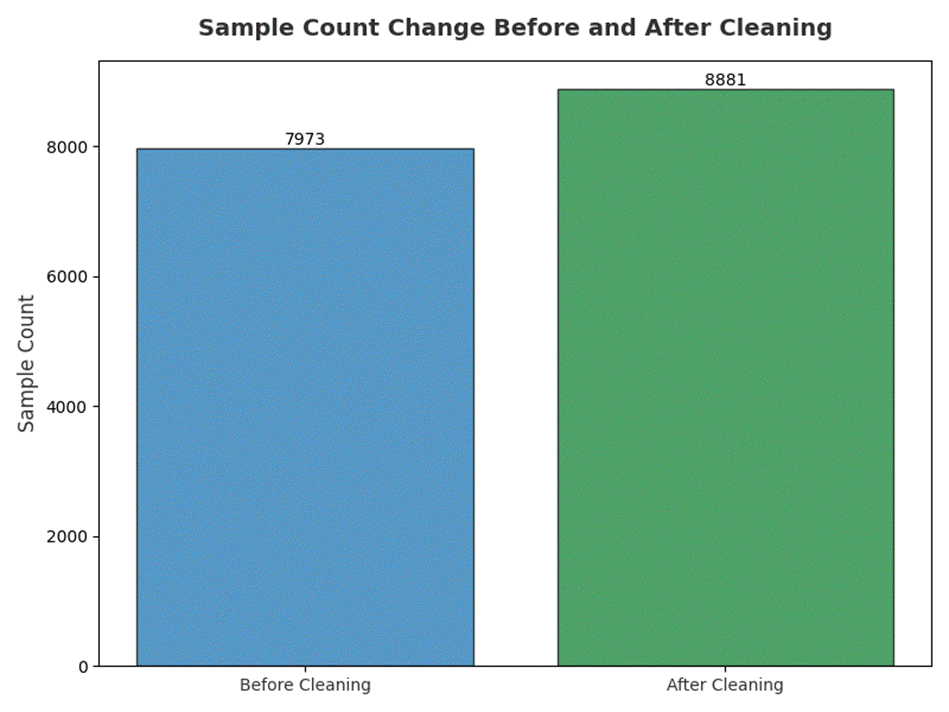
图3. 9 有效样本数量清洗前后对比
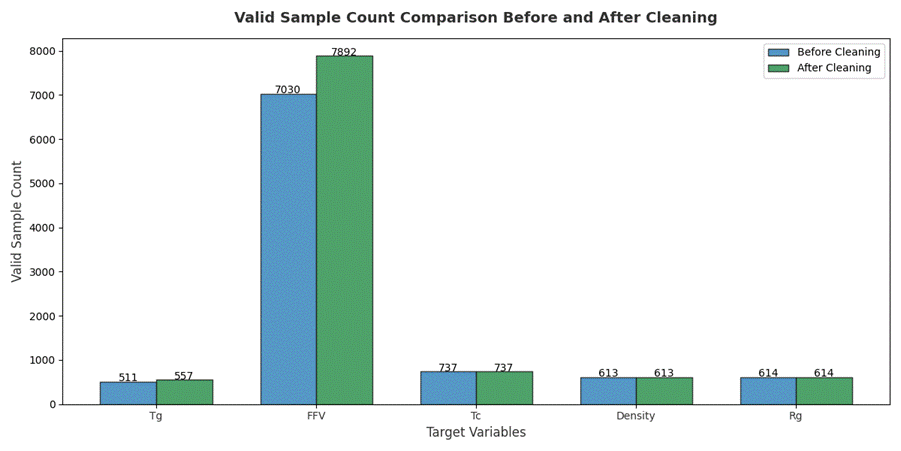
图3. 10 各个标签有效样本数量清洗前后对比
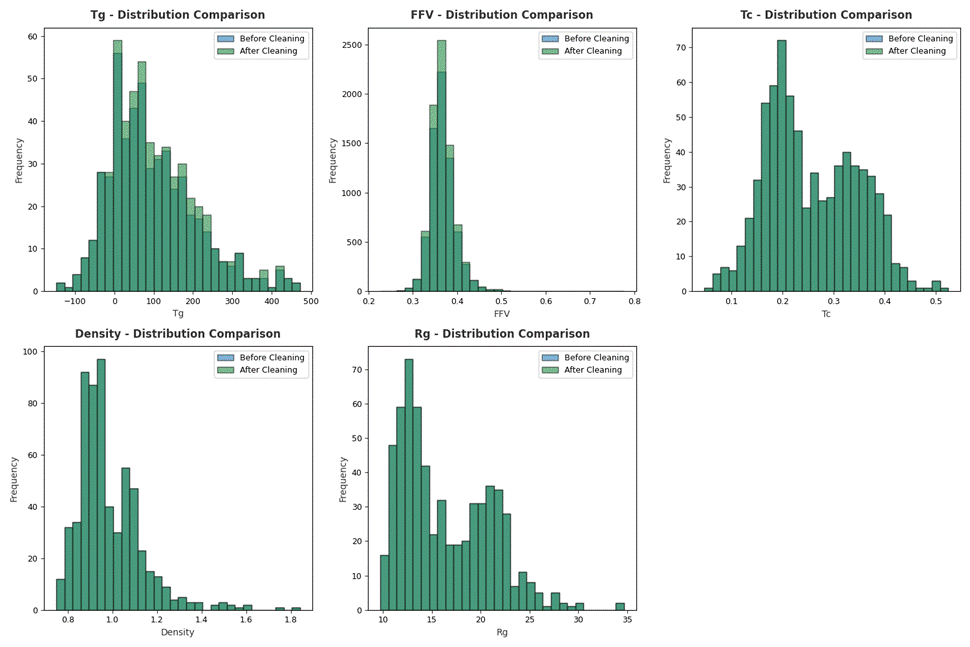
图3. 11 各个标签数据清洗前后分布对比
清洗和整理数据函数代码如下:
def clean_and_integrate_data(train_df, test_df, dataset1, dataset2, dataset3, dataset4):train_clean = train_df.copy()test_clean = test_df.copy()tc_null_mask = train_clean['Tc'].isnull()shared_smiles = set(train_clean['SMILES']).intersection(set(dataset1['SMILES'])tc_map = dict(zip(dataset1['SMILES'], dataset1['TC_mean']))train_clean.loc[tc_null_mask, 'Tc'] = train_clean.loc[tc_null_mask, 'SMILES'].map(tc_map)print(f"补充了 {tc_null_mask.sum()} 个Tc缺失值")dataset3_columns = dataset3.columns.tolist()dataset4_columns = dataset4.columns.tolist()label_maps_dataset3 = {}for label in ['Tg', 'FFV', 'Tc', 'Density', 'Rg']:if label in dataset3_columns:label_map = dict(zip(dataset3['SMILES'], dataset3[label]))label_maps_dataset3[label] = label_mapprint(f"dataset3包含标签: {label}")label_maps_dataset4 = {}for label in ['Tg', 'FFV', 'Tc', 'Density', 'Rg']:if label in dataset4_columns:label_map = dict(zip(dataset4['SMILES'], dataset4[label]))label_maps_dataset4[label] = label_mapprint(f"dataset4包含标签: {label}")for label, label_map in label_maps_dataset3.items():null_mask = train_clean[label].isnull()before = null_mask.sum()train_clean.loc[null_mask, label] = train_clean.loc[null_mask, 'SMILES'].map(label_map)after = train_clean[label].isnull().sum()print(f"使用dataset3补充{label}: {before} -> {after}个缺失值")for label, label_map in label_maps_dataset4.items():null_mask = train_clean[label].isnull()before = null_mask.sum()train_clean.loc[null_mask, label] = train_clean.loc[null_mask, 'SMILES'].map(label_map)after = train_clean[label].isnull().sum()print(f"使用dataset4补充{label}: {before} -> {after}个缺失值")print("添加dataset3和dataset4中的新样本...")new_smiles_dataset3 = set(dataset3['SMILES']) - set(train_clean['SMILES'])if new_smiles_dataset3:print(f"从dataset3添加 {len(new_smiles_dataset3)} 个新样本")new_data_dataset3 = dataset3[dataset3['SMILES'].isin(new_smiles_dataset3)].copy()for col in ['Tg', 'FFV', 'Tc', 'Density', 'Rg']:if col not in new_data_dataset3.columns:new_data_dataset3[col] = np.nanif 'id' not in new_data_dataset3.columns:new_data_dataset3['id'] = [f"dataset3_{i}" for i in range(len(new_data_dataset3))]train_clean = pd.concat([train_clean, new_data_dataset3[['id', 'SMILES', 'Tg', 'FFV', 'Tc', 'Density', 'Rg']]], ignore_index=True)new_smiles_dataset4 = set(dataset4['SMILES']) - set(train_clean['SMILES'])if new_smiles_dataset4:print(f"从dataset4添加 {len(new_smiles_dataset4)} 个新样本")new_data_dataset4 = dataset4[dataset4['SMILES'].isin(new_smiles_dataset4)].copy()for col in ['Tg', 'FFV', 'Tc', 'Density', 'Rg']:if col not in new_data_dataset4.columns:new_data_dataset4[col] = np.nanif 'id' not in new_data_dataset4.columns:new_data_dataset4['id'] = [f"dataset4_{i}" for i in range(len(new_data_dataset4))]train_clean = pd.concat([train_clean, new_data_dataset4[['id', 'SMILES', 'Tg', 'FFV', 'Tc', 'Density', 'Rg']]], ignore_index=True)print(f"添加dataset2中的 {len(dataset2)} 个无标签样本")dataset2 = dataset2.copy()for col in ['Tg', 'FFV', 'Tc', 'Density', 'Rg']:if col not in dataset2.columns:dataset2[col] = np.nanif 'id' not in dataset2.columns:dataset2['id'] = [f"dataset2_{i}" for i in range(len(dataset2))]train_clean = pd.concat([train_clean, dataset2[['id', 'SMILES', 'Tg', 'FFV', 'Tc', 'Density', 'Rg']]], ignore_index=True)before = len(train_clean)target_cols = ['Tg', 'FFV', 'Tc', 'Density', 'Rg']train_clean = train_clean[train_clean[target_cols].notnull().any(axis=1)]after = len(train_clean)print(f"过滤掉 {before - after} 个所有标签都缺失的样本")print("\n有效样本统计:")for col in target_cols:count = train_clean[col].notnull().sum()print(f"{col}有效样本数: {count}")print(f"整合后训练集总样本数: {len(train_clean)}")return train_clean, test_clean结果如图3.12:
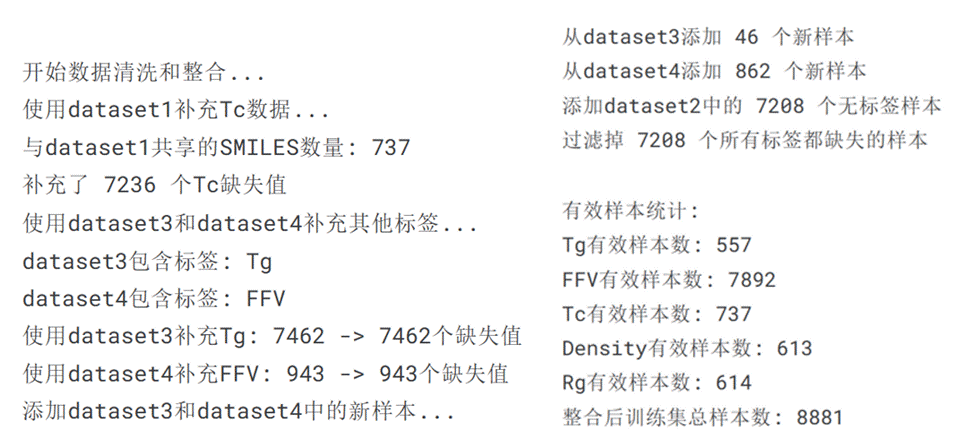
图3. 12 数据集清洗-代码运行结果
清洗前后数据对比可视化代码如下:
def visualize_cleaning_effect(original_df, cleaned_df, target_cols):before_color = '#2c7fb8' after_color = '#238b45' border_color = '#1a1a1a' text_color = '#333333' original_missing=[original_df[col].isnull().sum() / len(original_df) * 100 for col in target_cols]cleaned_missing= [cleaned_df[col].isnull().sum() / len(cleaned_df) * 100 for col in target_cols]x = np.arange(len(target_cols))width = 0.35plt.figure(figsize=(12, 6))plt.bar(x - width/2, original_missing, width, label='Before Cleaning',alpha=0.8, color=before_color, edgecolor=border_color)plt.bar(x + width/2, cleaned_missing, width, label='After Cleaning',alpha=0.8, color=after_color, edgecolor=border_color)plt.xlabel('Target Variables', fontsize=12, color=text_color)plt.ylabel('Missing Rate (%)', fontsize=12, color=text_color)plt.title('Missing Rate Comparison Before and After Cleaning',fontsize=14, fontweight='bold', pad=15, color=text_color)plt.xticks(x, target_cols, fontsize=10, fontweight='bold', color=text_color)plt.legend(fontsize=10)for i, v in enumerate(original_missing):plt.text(i - width/2, v + 1, f'{v:.1f}%', ha='center', fontsize=10)for i, v in enumerate(cleaned_missing):plt.text(i + width/2, v + 1, f'{v:.1f}%', ha='center', fontsize=10)plt.tight_layout()plt.savefig('missing_rate_comparison.png')plt.show()fig, axes = plt.subplots(2, 3, figsize=(15, 10))axes = axes.flatten()for i, col in enumerate(target_cols):if col in original_df.columns and col in cleaned_df.columns:original_non_null = original_df[col].dropna()cleaned_non_null = cleaned_df[col].dropna()if len(original_non_null) > 0 and len(cleaned_non_null) > 0:bp=axes[i].boxplot([original_non_null, cleaned_non_null], labels=['Before', 'After'], patch_artist=True)for patch, color in zip(bp['boxes'], [before_color, after_color]):patch.set_facecolor(color)patch.set_alpha(0.7)patch.set_edgecolor(border_color)axes[i].set_title(f'{col} - Outlier Handling Effect',fontsize=12, pad=10, color=text_color)axes[i].set_ylabel(col, fontsize=10, color=text_color)set_xticklabelsaxes[i].tick_params(axis='x',labelsize=9, color=text_color)axes[i].tick_params(axis='y',labelsize=9, color=text_color)labels = axes[i].get_xticklabels()axes[i].set_xticklabels(labels, fontweight='bold')for j in range(i+1, len(axes)):fig.delaxes(axes[j])plt.tight_layout()plt.savefig('outlier_treatment_comparison.png')plt.show()fig, axes = plt.subplots(2, 3, figsize=(15, 10))axes = axes.flatten()for i, col in enumerate(target_cols):if col in original_df.columns and col in cleaned_df.columns:original_non_null = original_df[col].dropna()cleaned_non_null = cleaned_df[col].dropna()if len(original_non_null) > 0 and len(cleaned_non_null) > 0:axes[i].hist(original_non_null, bins=30, alpha=0.6,label='Before Cleaning', color=before_color, edgecolor=border_color)axes[i].hist(cleaned_non_null, bins=30, alpha=0.6,label='After Cleaning', color=after_color, edgecolor=border_color)axes[i].set_title(f'{col} - Distribution Comparison',fontsize=12, fontweight='bold', pad=10, color=text_color)axes[i].set_xlabel(col, fontsize=10, color=text_color)axes[i].set_ylabel('Frequency', fontsize=10,color=text_color)axes[i].legend(fontsize=9)axes[i].tick_params(axis='both',labelsize=9, color=text_color)xtick_labels = axes[i].get_xticklabels()ytick_labels = axes[i].get_yticklabels()axes[i].set_xticklabels(xtick_labels)axes[i].set_yticklabels(ytick_labels)for j in range(i+1, len(axes)):fig.delaxes(axes[j])plt.tight_layout()plt.savefig('distribution_comparison.png')plt.show()datasets_added = len(cleaned_df) - len(original_df)plt.figure(figsize=(8, 6))bars = plt.bar(['Before Cleaning','After Cleaning'], [len(original_df), len(cleaned_df)],color=[before_color,after_color],alpha=0.8, edgecolor=border_color)plt.ylabel('Sample Count', fontsize=12, color=text_color)plt.title('Sample Count Change Before and After Cleaning',fontsize=14, fontweight='bold', pad=15, color=text_color)plt.xticks(fontsize=10, color=text_color)xtick_labels = plt.gca().get_xticklabels()plt.gca().set_xticklabels(xtick_labels)for bar in bars:height = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2., height + 5,f'{int(height)}',ha='center', va='bottom', fontsize=10)plt.tight_layout()plt.savefig('sample_count_comparison.png')plt.show()print(f"\nSample Count Change Before-After Cleaning: {len(original_df)} → {len(cleaned_df)} (+{datasets_added})")original_counts=[original_df[col].notnull().sum() for col in target_cols]cleaned_counts=[cleaned_df[col].notnull().sum() for col in target_cols]x = np.arange(len(target_cols))width = 0.35plt.figure(figsize=(12, 6))plt.bar(x - width/2, original_counts, width, label='Before Cleaning',alpha=0.8, color=before_color, edgecolor=border_color)plt.bar(x + width/2, cleaned_counts, width, label='After Cleaning',alpha=0.8, color=after_color, edgecolor=border_color)plt.xlabel('Target Variables', fontsize=12, color=text_color)plt.ylabel('Valid Sample Count', fontsize=12, color=text_color)plt.title('Valid Sample Count Comparison Before and After Cleaning',fontsize=14, fontweight='bold', pad=15, color=text_color)plt.xticks(x, target_cols, fontsize=10, color=text_color)xtick_labels = plt.gca().get_xticklabels()plt.gca().set_xticklabels(xtick_labels)plt.legend(fontsize=10)for i, v in enumerate(original_counts):plt.text(i - width/2, v + 5, f'{v}', ha='center', fontsize=10)for i, v in enumerate(cleaned_counts):plt.text(i + width/2, v + 5, f'{v}', ha='center', fontsize=10)plt.tight_layout()plt.savefig('valid_sample_count_comparison.png')plt.show()-
-
-
特征工程
-
-
由于训练集样本只有聚合物的结构和5个标签组成,因此要从聚合物的结构中进行特征提取。使用了三个方法进行特征提取,分别是对有标签聚合物提取RDKit化学分子信息、使用预训练模型ChemBERTa提取聚合物语义特征、通过自编码器学习无标签数据特征并用于有标签数据特征的再次提取。
RDKit分子特征
由于参与竞赛时无法直接使用线上工具包,因此必须提前下载该工具包,并上传至kaggle。
在RDKit官网RDKit 文档 — RDKit 2025.03.6 文档下载适配kaggle环境的工具包。
RDKit_pypi-2022.9.5-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
上传至kaggle之后,在笔记本中导入代码如下:
!pip install /kaggle/input/flq-RDKit/chem_resources/{whl_filename} --no-indexfrom RDKit import Chemfrom RDKit.Chem import Descriptors, rdMolDescriptorsprint("RDKit版本:", Chem.rdBase.RDKitVersion)利用RDKit工具从SMILE中提取25类基础分子描述符,涵盖分子量、脂水分配系数、受体原子数、环结构数量等物理化学属性。特征具体信息已在表2.1说明。
RDKit分子特征提取代码如下:
def extract_rdkit_features(smiles_list):rdkit_features = []for smiles in tqdm(smiles_list, desc="提取RDKit特征"):mol = Chem.MolFromSmiles(smiles)if mol is not None:descs = [Descriptors.MolWt(mol),Descriptors.MolLogP(mol),Descriptors.NumHAcceptors(mol),Descriptors.NumHDonors(mol),Descriptors.NumRotatableBonds(mol),Descriptors.TPSA(mol),rdMolDescriptors.CalcNumRings(mol),Descriptors.HeavyAtomCount(mol),Descriptors.NumValenceElectrons(mol),Descriptors.NumAromaticRings(mol),Descriptors.FractionCSP3(mol),rdMolDescriptors.CalcNumAliphaticCarbocycles(mol),rdMolDescriptors.CalcNumAliphaticHeterocycles(mol),rdMolDescriptors.CalcNumAromaticCarbocycles(mol),rdMolDescriptors.CalcNumAromaticHeterocycles(mol),]rdkit_features.append(descs)else:rdkit_features.append([0] * 15)return np.array(rdkit_features)ChemBERTa语义特征
采用预训练的ChemBERTa模型,对SMILES进行语义级编码。通过批量处理 SMILES,生成每个分子的[CLS] token隐藏状态,捕捉分子结构的高层语义模式,为模型提供分子整体的抽象结构表征,提取的语义特征维度为768维。
拉取ChemBERTa模型并获得分词器的代码如下:
def load_pretrained_model():try:model_path='/kaggle/input/m/fuliuqin/flq-model5/pytorch/default/1/ChemBERTa_zinc250k_v2_40k'tokenizer = AutoTokenizer.from_pretrained(model_path)chemberta_model = AutoModel.from_pretrained(model_path).to(device)print("使用更先进的ChemBERTa模型")return tokenizer, chemberta_modelexcept:model_path='/kaggle/input/flq-model5/pytorch/default/1/PubChem10M_SMILES_BPE_60k'tokenizer = AutoTokenizer.from_pretrained(model_path)chemberta_model = AutoModel.from_pretrained(model_path).to(device)print("使用原始ChemBERTa模型")return tokenizer, chemberta_modeltokenizer, chemberta_model = load_pretrained_model()-
-
-
-
自编码特征融合
-
-
-
为了充分利用数据集中大量无标签样本的潜在信息,并融合ChemBERTa 语义特征与RDKit分子特征的互补性,本研究引入改进型自编码器ImprovedAutoencoder开展特征融合,实现多源特征的深度整合与增强。
自编码器的输入为ChemBERTa 语义特征与RDKit分子特征的拼接结果。
从模型结构看,ImprovedAutoencoder包含编码器(Encoder)与解码器(Decoder)。Encoder通过三层线性变换,依次将输入映射到1024维、768维,最终压缩至512维编码维度,搭配BatchNorm1d批归一化,加速训练收敛、提升稳定性、ReLU激活函数引入非线性表达能力与Dropout丢弃率设为 0.2,缓解过拟合风险,将高维的ChemBERTa、RDKit拼接特征压缩为更紧凑的编码表示。Decoder则通过对称的三层线性变换,尝试从编码表示中重构原始输入特征,训练过程以均方误差为损失函数,确保编码后的特征能精准保留原始多源特征的关键信息。训练阶段,收集所有可用的SMILES样本,提取其ChemBERTa语义特征与RDKit分子特征并拼接,构建自编码器的训练数据集。批次大小为16、训练100个轮次。对于有标签的聚合物样本,在自编码器训练完成后,会先提取其 ChemBERTa语义特征与RDKit分子特征并拼接,再通过自编码器的encode方法,将拼接特征映射到512 维的融合增强特征。该特征既保留了ChemBERTa对分子整体结构的语义理解、RDKit对理化属性的精准刻画,又融入了无标签数据中学习到的通用特征模式,为后续多任务模型提供更具代表性的输入,进而提升对目标属性的预测性能。
如图3.13为自编码器训练损失曲线,可知再60轮左右,损失就趋于平稳。
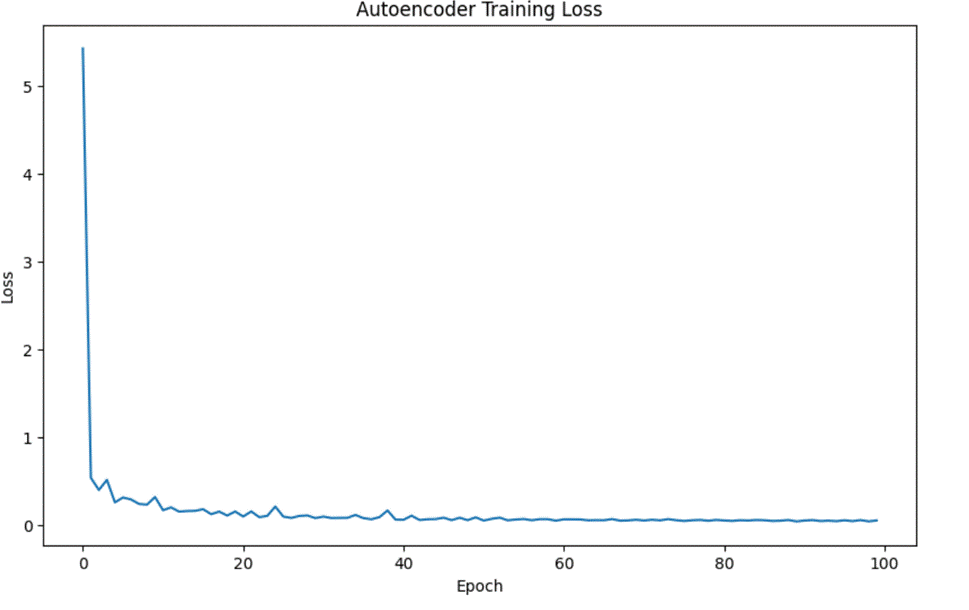
图3. 13 自编码器训练损失
定义自编码器代码如下:
class ImprovedAutoencoder(nn.Module):def __init__(self, input_dim, encoding_dim=512):super(ImprovedAutoencoder, self).__init__()self.encoder = nn.Sequential(nn.Linear(input_dim, 1024),nn.BatchNorm1d(1024),nn.ReLU(),nn.Dropout(0.2),nn.Linear(1024, 768),nn.BatchNorm1d(768),nn.ReLU(),nn.Dropout(0.2),nn.Linear(768, encoding_dim),nn.BatchNorm1d(encoding_dim),nn.ReLU())self.decoder = nn.Sequential(nn.Linear(encoding_dim, 768),nn.BatchNorm1d(768),nn.ReLU(),nn.Dropout(0.2),nn.Linear(768, 1024),nn.BatchNorm1d(1024),nn.ReLU(),nn.Dropout(0.2),nn.Linear(1024, input_dim))def forward(self, x):encoded = self.encoder(x)decoded = self.decoder(encoded)return decodeddef encode(self, x):return self.encoder(x)自编码器训练代码如下:def train_autoencoder(features, encoding_dim=1024, batch_size=16, epochs=100):class FeatureDataset(Dataset):def __init__(self, features):self.features = featuresdef __len__(self):return len(self.features)def __getitem__(self, idx):return torch.FloatTensor(self.features[idx])dataset = FeatureDataset(features)dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)input_dim = features.shape[1]model = Autoencoder(input_dim, encoding_dim).to(device)criterion = nn.MSELoss()optimizer = Adam(model.parameters(), lr=0.001)losses = []model.train()for epoch in range(epochs):total_loss = 0for batch in tqdm(dataloader, desc=f"Epoch {epoch+1}/{epochs}"):batch = batch.to(device)outputs = model(batch)loss = criterion(outputs, batch)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()avg_loss = total_loss / len(dataloader)losses.append(avg_loss)print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss:.6f}")plt.figure(figsize=(10, 6))plt.plot(losses)plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('Autoencoder Training Loss')plt.savefig('autoencoder_training_loss.png')plt.show()print("自编码器训练完成")return model-
-
-
-
特征选择
-
-
-
比较上述三种特征提取方法,RDKit提取的特征更容易让人理解,因此对该25个特征进行分析。
首先是特征与特征之间的相关性分析如图3.14。
发现大量特征对的相关系数>0.8。这种高度共线性会引发多重共线性问题。
若直接将所有特征用于建模,模型会因特征冗余难以区分每个特征对目标属性的独立贡献,导致参数估计不稳定、解释性下降,甚至训练时出现数值震荡。
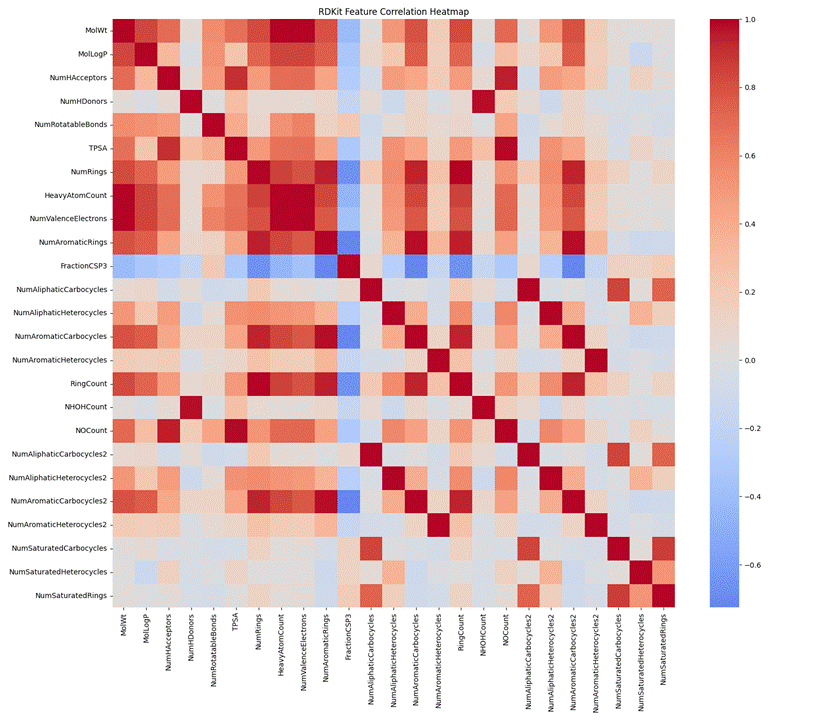
图3. 14 特征相关性分析-25个RDKit特征
因此筛选出相关性小于0.8的特征共有8个,如图3.15。
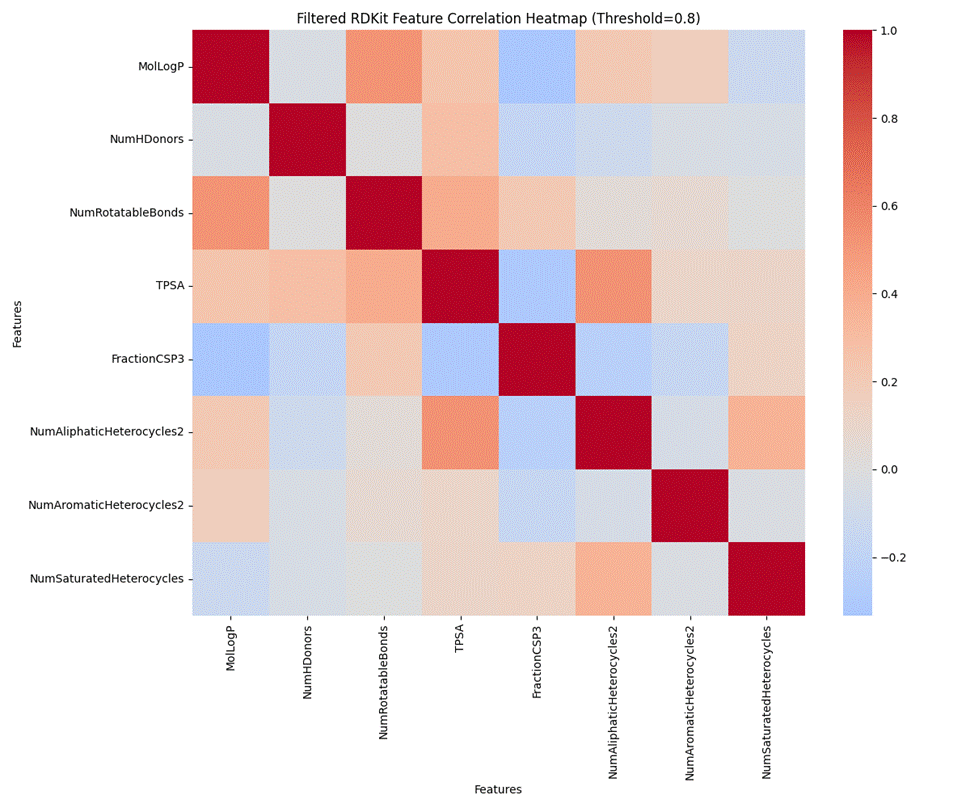
图3. 15 特征相关性分析-8个RDKit特征
特征相关性分析代码如下:
from sklearn.feature_selection import SelectKBest, f_regressiondef remove_high_correlation_features(rdkit_df, importance_results, target_cols, corr_threshold=0.8):corr_matrix = rdkit_df.corr().abs() print(f"原始特征数量: {rdkit_df.shape[1]}")upper=corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))to_keep = {col: True for col in rdkit_df.columns}for col in upper.columns:high_corr_features = [row for row in upper.indexif upper.loc[row, col] > corr_threshold and row != col]if high_corr_features:feature_group = [col] + high_corr_featuresprint(f"\n高相关特征组: {feature_group}")feature_scores = {}for feat in feature_group:total_score = 0count = 0for target in target_cols:if target in importance_results and feat in importance_results[target]['Feature'].values:score = importance_results[target].loc[importance_results[target]['Feature'] == feat, 'Score'].values[0]total_score += scorecount += 1feature_scores[feat] = total_score / count if count > 0 else 0sorted_features=sorted(feature_scores.items(), key=lambda x: x[1], reverse=True)print(f"特征重要性排序: {sorted_features}")best_feature = sorted_features[0][0]print(f"保留特征: {best_feature}")for feat in feature_group:if feat != best_feature:to_keep[feat] = Falseselected_features=[col for col in rdkit_df.columns if to_keep[col]]filtered_rdkit_df = rdkit_df[selected_features]print(f"\n筛选后特征数量: {filtered_rdkit_df.shape[1]}")print(f"保留的特征: {selected_features}")plt.figure(figsize=(12, 10))filtered_corr = filtered_rdkit_df.corr()sns.heatmap(filtered_corr, annot=False, cmap='coolwarm', center=0)plt.title(f'Filtered RDKit Feature Correlation Heatmap (Threshold={corr_threshold})')plt.xlabel('Features')plt.ylabel('Features')plt.tight_layout()plt.savefig('filtered_rdkit_correlation.png')plt.show()return selected_features, filtered_rdkit_df基于筛选后8个RDKit特征与聚合物5类属性的相关性分析,如图3.16可知,MolLogP与Tc呈显著正相关,说明亲脂性强的分子更易通过疏水相互作用形成有序结晶结构,大幅促进结晶过程;MolLogP与FFV正相关、与Density负相关、与Tg微弱正相关、与Rg正相关的关联体现了亲脂性对分子尺寸、链段运动的弱调控。NumHDonors与Tc正相关、与Rg显著正相关、与FFV负相关、与Tg微弱正相关、Density微弱负相关的关联则反映,氢键对链段运动、分子堆砌的弱调控。
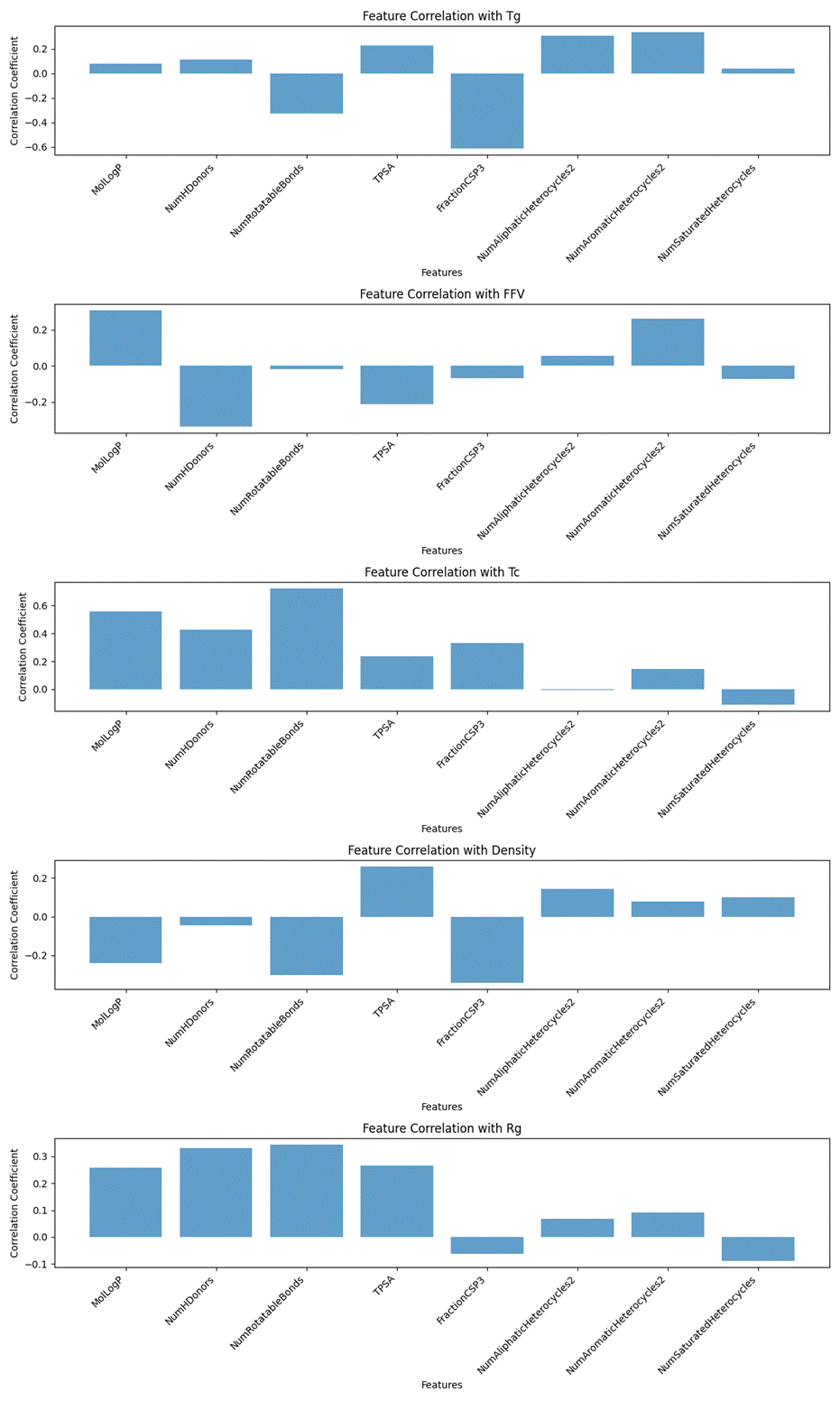
图3. 16 特征与标签相关性分析
特征之间相关性、特征与标签效关系可视化代码如下:
def visualize_rdkit_features(rdkit_features, feature_names, target_cols, train_clean):rdkit_df = pd.DataFrame(rdkit_features, columns=feature_names)n_features = len(feature_names)n_cols = 5n_rows = (n_features + n_cols - 1) // n_colsfig, axes = plt.subplots(n_rows, n_cols, figsize=(20, 4*n_rows))axes = axes.flatten()for i, feature in enumerate(feature_names):axes[i].hist(rdkit_df[feature].values, bins=30, alpha=0.7, color='skyblue', edgecolor='black')axes[i].set_title(f'{feature} Distribution')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')for j in range(i+1, len(axes)):fig.delaxes(axes[j])plt.tight_layout()plt.savefig('rdkit_feature_distributions.png')plt.show()plt.figure(figsize=(16, 14))corr_matrix = rdkit_df.corr()sns.heatmap(corr_matrix, annot=False, cmap='coolwarm', center=0)plt.title('RDKit Feature Correlation Heatmap')plt.tight_layout()plt.savefig('rdkit_feature_correlation.png')plt.show()valid_targets = []for col in target_cols:if col in train_clean.columns and train_clean[col].notnull().sum() > 10:valid_targets.append(col)if valid_targets:target_correlations = {}for target in valid_targets:valid_indices = train_clean[target].notnull()target_values=train_clean.loc[valid_indices, target].valuesfeature_values = rdkit_features[valid_indices]correlations = []for i in range(rdkit_features.shape[1]):if np.std(feature_values[:, i]) > 0:corr=np.corrcoef(feature_values[:, i], target_values)[0, 1]correlations.append(corr)else:correlations.append(0)target_correlations[target] = correlationsn_targets = len(valid_targets)fig, axes=plt.subplots(n_targets, 1, figsize=(12, 4*n_targets))if n_targets == 1:axes = [axes]for i, target in enumerate(valid_targets):axes[i].bar(range(len(feature_names)), target_correlations[target], alpha=0.7)axes[i].set_title(f'Feature Correlation with {target}')axes[i].set_xlabel('Features')axes[i].set_ylabel('Correlation Coefficient')axes[i].set_xticks(range(len(feature_names)))axes[i].set_xticklabels(feature_names, rotation=45, ha='right')plt.tight_layout()plt.savefig('feature_target_correlations.png')plt.show()return rdkit_df通过上述的分析,说明特征去冗余后的有效性与属性特异性,即不同的特征与不同的标签的相关性不同,也可通过对8个特征的重要性分析来体现,如图3.17。表明不同特征对不同标签的贡献度不同。
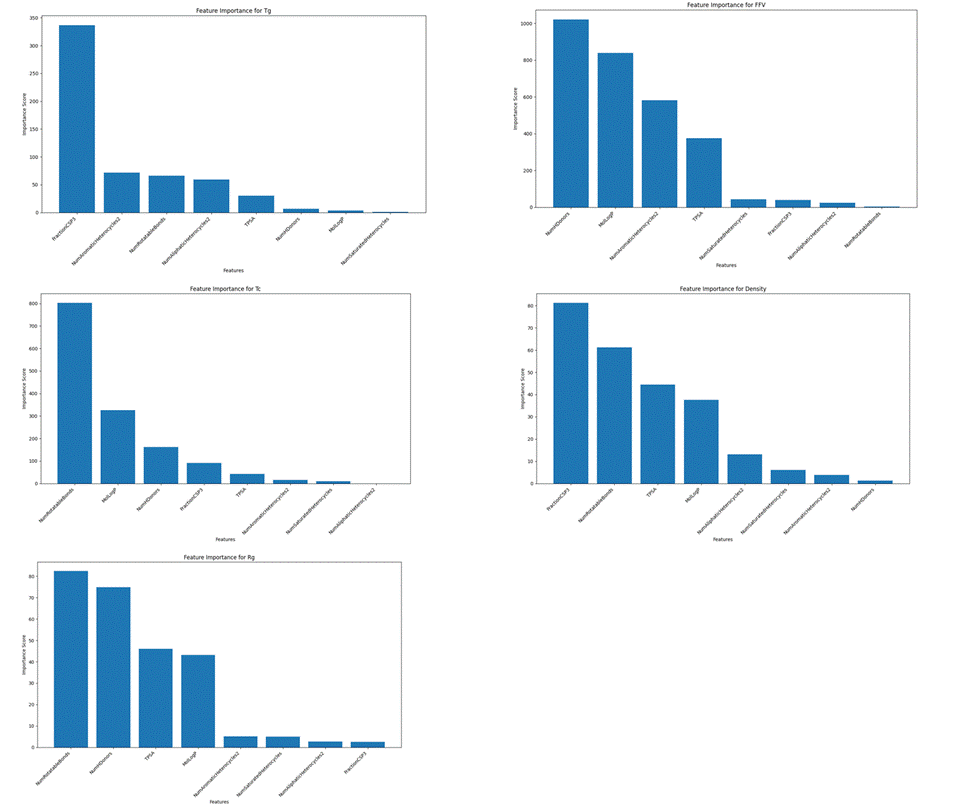
图3. 17 特征重要性分析
数据集划分
若同一聚合物分子的SMILES同时出现在训练集与验证集,会导致验证集评估失去独立性,本研究采用基于SMILES唯一性的分组划分策略。首先从原始数据中提取所有不重复的 SMILES 字符串,得到唯一分子的标识集合。将唯一 SMILES 集合随机打乱后,按8:2的比例划分为,训练集和验证集。通过判断原始数据中每个样本的 SMILES 是否属于训练或验证 SMILES 子集,生成训练集索引与验证集索引。基于索引从特征、标签、掩码数据中筛选样本,实例化自定义的PolymerDataset类,最终得到训练集7104个样本与验证集1777个样本。
实现代码如下:
class PolymerDataset(Dataset):def __init__(self, features, labels, masks):self.features = featuresself.labels = labelsself.masks = masksdef __len__(self):return len(self.features)def __getitem__(self, idx):return {'features': torch.FloatTensor(self.features[idx]),'labels': torch.FloatTensor(self.labels[idx]),'mask': torch.FloatTensor(self.masks[idx])}labels = train_clean[target_cols].valuesmasks = ~np.isnan(labels)task_sample_counts = [masks[:, 0].sum(),masks[:, 1].sum(),masks[:, 2].sum(),masks[:, 3].sum(),masks[:, 4].sum()]task_weights = []min_non_zero = min([count for count in task_sample_counts if count > 0]) if any(task_sample_counts) else 1for count in task_sample_counts:if count == 0:task_weights.append(0.0)else:weight = min_non_zero / counttask_weights.append(weight)task_weights = [weight / sum(task_weights) for weight in task_weights]print("任务样本数量: ", task_sample_counts)print("计算的任务权重: ", task_weights)print("权重总和: ", sum(task_weights))scalers = []for i in range(5):scaler = RobustScaler()non_null_mask = masks[:, i]if non_null_mask.sum() > 0:non_null_labels = labels[non_null_mask, i]scaled_labels = scaler.fit_transform(non_null_labels.reshape(-1, 1)).flatten()labels[non_null_mask, i] = scaled_labelsscalers.append(scaler)unique_smiles = train_clean['SMILES'].unique()np.random.shuffle(unique_smiles)train_ratio = 0.8train_size = int(len(unique_smiles) * train_ratio)train_smiles = set(unique_smiles[:train_size])val_smiles = set(unique_smiles[train_size:])train_indices = train_clean['SMILES'].isin(train_smiles)val_indices = train_clean['SMILES'].isin(val_smiles)train_dataset = PolymerDataset(train_features[train_indices],labels[train_indices],masks[train_indices])val_dataset = PolymerDataset(train_features[val_indices],labels[val_indices],masks[val_indices])-
-
模型构建与训练
-
实现细节
-
本研究基于PyTorch 2.6.0+cu124和Transformers 4.37.0构建了完整的深度学习训练框架,充分利用GPU加速计算,通过CUDA 12.4实现硬件级优化。自定义EnhancedMultiTaskModel作为核心预测模型,采用共享特征提取层和任务特定输出层的双阶段架构设计。共享特征提取层包含两层线性变换Linear 层,每层后依次衔接LayerNorm层归一化、GELU激活函数为模型引入非线性表达能力与Dropout丢弃率设为 0.3,有效缓解过拟合风险,从而从输入特征中提炼多任务通用的核心表征。
针对5个目标任务,分别设计独立的输出子网络,使模型既能挖掘任务间的潜在关联以提升整体性能,又能针对性捕获每个任务的特有模式。通过Kaiming 初始化方法对网络权重进行初始化,进一步保障了训练过程的稳定性;同时自定义train_model函数封装完整训练流程,实现了数据批次迭代、加权损失计算、优化器更新等关键环节的高效管理。
训练策略
本研究采用加权多任务损失函数,根据每个任务有效样本量的倒数为其分配权重,以此缓解了数据严重不平衡的问题,确保样本稀少的任务也能得到充分学习。
计算任务权重代码如下:
target_cols = ['Tg', 'FFV', 'Tc', 'Density', 'Rg']labels = train_clean[target_cols].valuesmasks = ~np.isnan(labels)task_sample_counts = [masks[:, 0].sum(),masks[:, 1].sum(),masks[:, 2].sum(),masks[:, 3].sum(),masks[:, 4].sum()]task_weights = []min_non_zero = min([count for count in task_sample_counts if count > 0]) if any(task_sample_counts) else 1for count in task_sample_counts:if count == 0:task_weights.append(0.0)else:weight = min_non_zero / counttask_weights.append(weight)if sum(task_weights) == 0:task_weights = [1.0/5] * 5else:task_weights = [weight / sum(task_weights) for weight in task_weights]task_weights=torch.tensor(task_weights, dtype=torch.float32).to(device)print("最终任务权重张量: ", task_weights)代码结果如图4.1。

图4. 1 权重计算代码输出结果
EnhancedMultiTaskModel函数定义如下:class EnhancedMultiTaskModel(nn.Module):def __init__(self, input_dim, hidden_dim=512, output_dim=5, dropout_rate=0.3):super(EnhancedMultiTaskModel, self).__init__()self.shared_layer = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.LayerNorm(hidden_dim),nn.GELU(),nn.Dropout(dropout_rate),nn.Linear(hidden_dim, hidden_dim // 2),nn.LayerNorm(hidden_dim // 2),nn.GELU(),nn.Dropout(dropout_rate),)self.task_layers = nn.ModuleList([nn.Sequential(nn.Linear(hidden_dim // 2, hidden_dim // 4),nn.GELU(),nn.Dropout(dropout_rate),nn.Linear(hidden_dim // 4, 1)) for _ in range(output_dim)])self._init_weights()def _init_weights(self):for module in self.modules():if isinstance(module, nn.Linear):nn.init.kaiming_normal_(module.weight, nonlinearity='relu')if module.bias is not None:nn.init.zeros_(module.bias)def forward(self, x):shared_features = self.shared_layer(x)outputs = [layer(shared_features) for layer in self.task_layers]return torch.cat(outputs, dim=1)优化过程使用AdamW优化器,其内置的权重衰减机制有助于防止过拟合。训练中引入了动态学习率调度ReduceLROnPlateau与早停Early Stopping策略,学习率调度器在验证损失停滞时自动降低学习率以精细调优,而早停机制则在验证损失连续15个epoch未改善时果断终止训练,不仅节省了计算资源,也有效避免了过拟合。
如图4.2,从训练过程的损失曲线图中可以清晰观察到,训练损失与验证损失均呈现稳步下降并在最终收敛的趋势。
各个标签的训练和验证损失也是呈现下降趋势。其中FFV和Density的验证损失始终低于训练损失,表明有良好的泛化能力;Tg在10轮左右,验证损失便超过了训练损失,有过拟合倾向;Tc和Rg的损失下降都比较少。
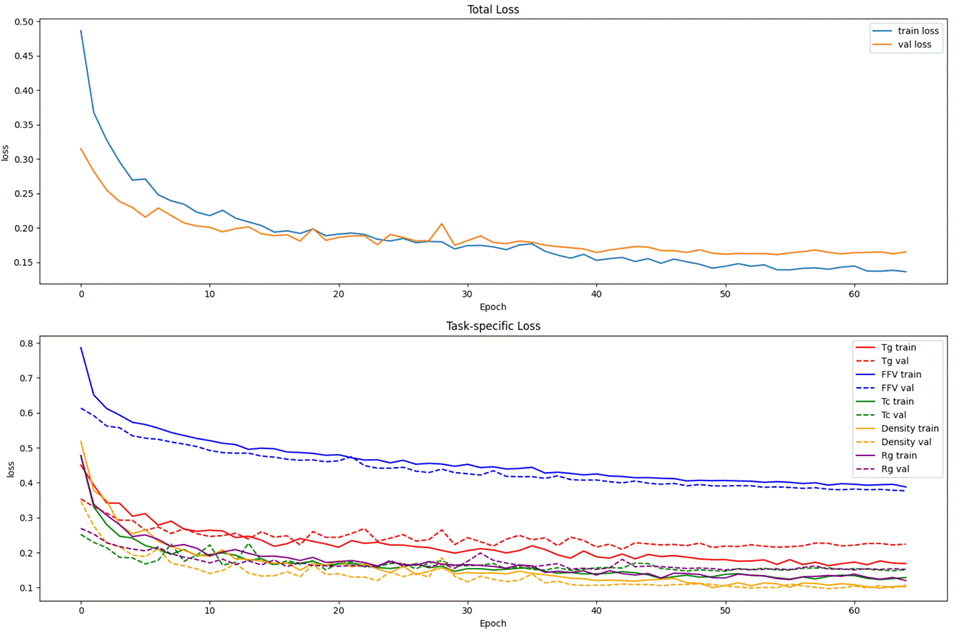
图4. 2 训练损失曲线
最终训练函数代码如下:
def optimize_hyperparameters(train_features, labels, masks, device):param_grid = {'hidden_dim': [512, 1024, 1536],'learning_rate': [1e-4, 5e-5, 1e-5],'batch_size': [16, 32, 64],'dropout_rate': [0.2, 0.3, 0.4]}best_score = float('inf')best_params = {}for hidden_dim in param_grid['hidden_dim']:for lr in param_grid['learning_rate']:for batch_size in param_grid['batch_size']:for dropout_rate in param_grid['dropout_rate']:print(f"\n测试参数: hidden_dim={hidden_dim}, lr={lr}, batch_size={batch_size}, dropout={dropout_rate}")train_dataset=PolymerDataset(train_features, labels, masks)train_loader=DataLoader(train_dataset, batch_size=batch_size, shuffle=True)model = EnhancedMultiTaskModel(train_features.shape[1],hidden_dim=hidden_dim,dropout_rate=dropout_rate).to(device)optimizer=AdamW(model.parameters(),lr=lr, weight_decay=1e-5)model.train()total_loss = 0for batch in train_loader:features = batch['features'].to(device)labels_batch = batch['labels'].to(device)masks_batch = batch['mask'].to(device)optimizer.zero_grad()outputs = model(features)loss = torch.tensor(0.0).to(device)for i in range(5):task_output = outputs[:, i]task_label = labels_batch[:, i]task_mask = masks_batch[:, i]if task_mask.sum() > 0:task_loss = nn.L1Loss()(task_output[task_mask.bool()], task_label[task_mask.bool()])loss = loss + task_lossif loss.item() > 0:loss.backward()optimizer.step()total_loss += loss.item()avg_loss = total_loss / len(train_loader)print(f"平均损失: {avg_loss:.4f}")if avg_loss < best_score:best_score = avg_lossbest_params = {'hidden_dim': hidden_dim,'learning_rate': lr,'batch_size': batch_size,'dropout_rate': dropout_rate}print(f"\n最佳参数: {best_params}, 最佳分数: {best_score:.4f}")return best_params-
-
-
超参数优化
-
-
采用网格搜索策略,对隐藏层维度(512、1024、1536)、学习率(1e-4、5e-5、1e-5)、批大小(16、32、64)和丢弃率(0.2、0.3、0.4)等进行交叉验证。结果表明,隐藏层维度为1536、学习率为0.0001、批大小为16、丢弃率为0.2时,模型在验证集上达到最优性能,平均损失为2.4669,显著优于其他参数组合。
超参数网格搜索代码如下:
模型评估与分析
评估指标
对于回归任务,主要采用MAE、RMSE和R²作为评价标准。
MAE计算公式如式(5-1)。
MAE=1ni=1nyi-yi#式5-1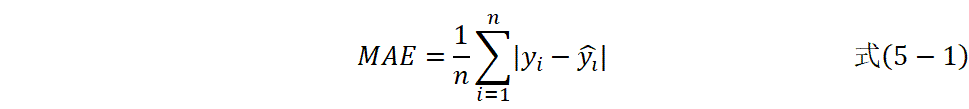
N为样本量;
yi![]() 为第i个样本的真实值;
为第i个样本的真实值;
yi![]() 为第i个样本的预测值。
为第i个样本的预测值。
MAE用于衡量预测值与真实值之间的平均绝对偏差,反映误差的平均大小。
RMSE计算公式如式(5-2)。
RMSE=1ni=1nyi-yi2#式5-2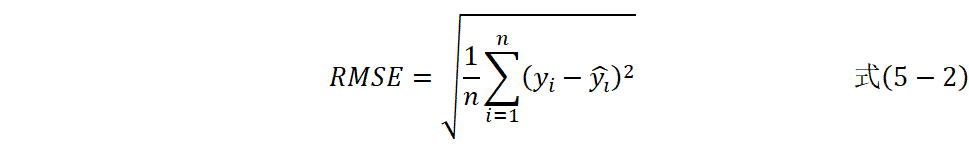
通过平方放大偏差的影响,再开方还原单位,侧重惩罚大误差,对异常值敏感,能反映预测结果的稳定性。
决定系数R2![]() 计算公式如式(5-3)。
计算公式如式(5-3)。
R2=1-i=1nyi-yi2i=1nyi-y2#式5-3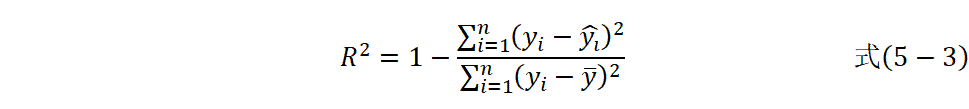
y=1ni=1nyi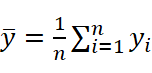 为真实值的平均值;
为真实值的平均值;
分子为残差平方和SSE,衡量模型预测的误差;
分母为总离差平方和SST,衡量真实值本身的波动范围。
R2![]() 表示模型能够解释的目标变量变异的比例,即拟合优度。
表示模型能够解释的目标变量变异的比例,即拟合优度。
评估结果
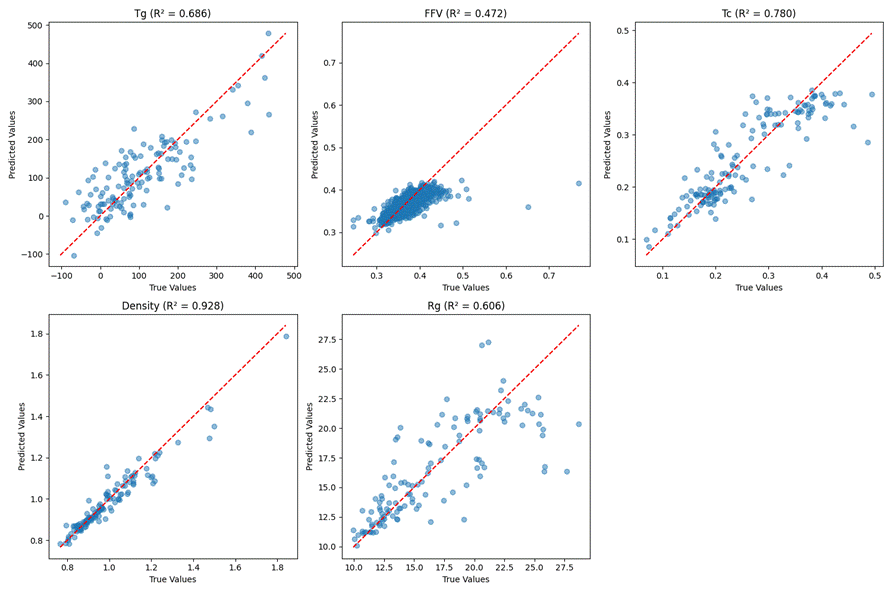
模型在验证集上的各项评估指标如表5-1所示。
从数据来看,不同目标属性的预测性能存在差异。
Density的预测效果最优,MAE为0.02,RMSE为0.04,R²达到0.92,表明模型能较好捕捉密度与分子结构间的关联。Tc的R²为0.78,MAE和RMSE分别为0.03和0.04,预测精度仅次于Density。
Tg的R²为0.68,MAE为47.98,RMSE为62.06,误差相对较大,但仍能解释近70%的Tg变化。Rg的R²为0.60,MAE为2.00,RMSE为2.96,预测稳定性一般。
FFV的预测性能最差,R²仅为0.47,MAE和RMSE分别为0.01和0.02,虽绝对误差小,但对FFV变异的解释能力较弱。。
表5. 1 验证集评估指标
| 标签\指标 | MAE | RMSE | R^2 |
| Tg | 47.98 | 62.06 | 0.68 |
| FFV | 0.01 | 0.02 | 0.47 |
| Tc | 0.03 | 0.04 | 0.78 |
| Density | 0.02 | 0.04 | 0.92 |
| Rg | 2.00 | 2.96 | 0.60 |
如图5.1,从预测值与真实值的对比可以发现,Density的散点更贴近对角线,数据点分布集中,说明模型能很好的拟合。Tc和Tg的散点虽有一定离散,但整体仍呈明显线性趋势。FFV和Rg的散点离散程度较高,部分预测值与真实值偏差较大,与上述指标结果相符。
结果分析
模型整体具备聚合物性质预测能力,但存在明显的任务性能差异。
Density和Tc预测效果好,可能因为这两种属性与RDKit分子结构特征的关联更直接。RDKit提取的分子描述符能有效刻画这些关联,ChemBERTa的语义特征也进一步强化了结构与性质的映射,使得模型易学习规律。
FFV预测性能差,推测是FFV与RDKit分子结构的关系更复杂,受分子堆积方式、链段柔性等多因素非线性影响。现有特征未能充分捕捉这些复杂关联,且FFV样本中可能存在特殊结构聚合物,导致模型泛化能力不足。
Tg和Rg的预测误差中等,一方面是这两种属性受多种分子特征协同影响,模型难以完全学习复杂作用机制;另一方面,Tg样本量较少,可能导致模型对部分结构聚合物的Tg预测不够精准。
结合训练过程的损失曲线分析,Tg在训练10轮后验证损失超过训练损失,存在轻微过拟合。这与Tg样本量少、特征表达不充分有关,模型在训练集上过度学习局部规律,在验证集上泛化能力下降。FFV和Density的验证损失始终低于训练损失,泛化能力良好;Tc和Rg的损失下降幅度小,可能是模型对这两种属性的特征学习速度较慢,需更多训练轮次或更优特征组合。
如图5.2,从竞赛排行榜来看,本研究提交的模型损失得分为0.068,排名是625/2189,第一名的损失得分是0.055。
图5. 2 竞赛排行榜
总结与展望
研究总结
本研究围绕聚合物性质预测任务,构建了一个基于多任务学习的深度学习模型,能够依据SMILES字符串同步预测Tg、FFV、Tc、Density和Rg五项关键物理化学性质。面对原始数据中存在的大规模非随机缺失、标注不完整和高维度小样本的挑战,研究系统整合了来自竞赛与多个外部数据集的数据,提出了“先补充、再扩充”的数据清洗与整合策略,显著提升了有效样本规模与质量。在特征工程方面,融合了RDKit分子描述符、ChemBERTa语义特征与自编码器所提取的抽象特征,有效增强了输入信息的表征能力与可解释性。模型采用硬参数共享架构,结合动态加权损失函数、早停机制与学习率调度策略,在验证集上取得了稳定表现,其中Density与Tc预测效果优异,Tg与Rg预测能力中等,FFV仍有改进空间。本方法为聚合物性能的高通量预测提供了可靠计算框架,具备良好的实际应用潜力与方法参考价值。
未来工作
本研究仍存在许多可拓展与深化之处。在数据层面,可引入更多真实实验数据或更高精度模拟数据,尤其增加FFV、Tg等样本稀缺属性的覆盖规模,以缓解数据不均衡问题。特征方面,可进一步探索GNN等结构感知模型,直接从分子图结构中提取拓扑与几何特征,弥补字符串表示对空间结构信息的缺失。模型架构上,可引入软参数共享策略、或基于元学习的多任务平衡方法,以缓解负迁移现象并提升跨任务泛化能力。训练策略方面,可探索引入不确定性估计模块,使模型具备预测置信度判断能力,提升其在真实场景中的可靠性。最终,可将训练好的模型嵌入到材料开发平台中,实现预测到验证再到反馈的闭环,推动聚合物智能研发流程的实际应用与迭代优化。