scrapy项目-爬取某招聘网站信息
scrapy项目-爬取某招聘网站信息
目标
网站:职位 | 网易社会招聘
需求
-
爬取python职位所有数据
-
爬取职位名称,职位类型,基本要求,基本学历,经验要求,地区
-
保存csv文件
步骤
-
分析网站,抓取数据包
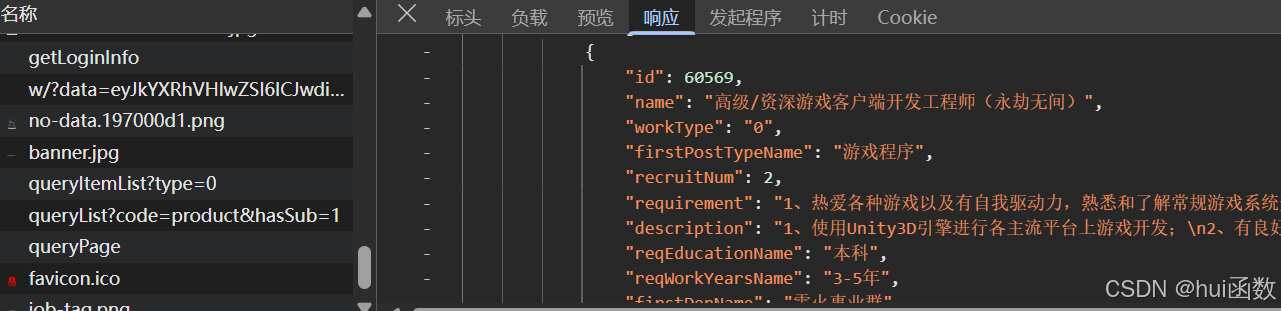
这里找到了就是queryPage数据包里面
-
看看请求需要带什么参数
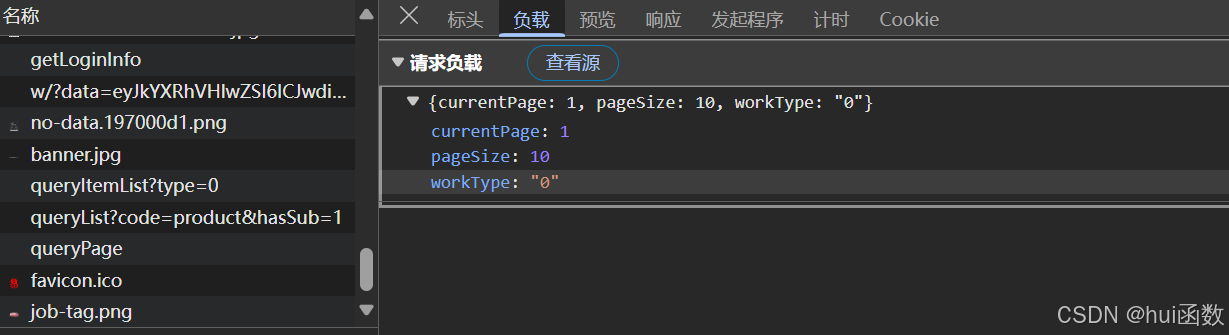
发现要带3个参数,先进行一页的抓取,然后再进行多页的抓取
-
创建scrapy项目,创建爬虫,开始写抓取第一页的代码,然后写分页数据
代码
spider/items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class JobItem(scrapy.Item):title = scrapy.Field() # 职位名称 (Title)job_type = scrapy.Field() # 职业类型 (Job Type)requirements = scrapy.Field() # 基本要求 (Requirements)education = scrapy.Field() # 学历要求 (Education)experience_years = scrapy.Field() # 经验年份 (Experience Years)address = scrapy.Field() # 工作地址 (Address)spider/wangyi.py
import scrapy
import json
from ..items import JobItem # 确保这个路径是正确的
class WangyiSpider(scrapy.Spider):name = "wangyi"allowed_domains = ["163.com"]start_urls = ["https://hr.163.com/api/hr163/position/queryPage"]headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0","Content-Type": "application/json","Referer": "https://hr.163.com/job-list.html"}
def start_requests(self):currentPage = 1pageSize = 10data = {"currentPage": currentPage, "pageSize": pageSize, "keyword": "python"}yield scrapy.Request(url=self.start_urls[0],callback=self.parse,method='POST',body=json.dumps(data),headers=self.headers,meta={'currentPage':1,'pageSize':10})
def parse(self, response):dic = response.json()# 获取一共有多少页pages = dic['data']['pages']# 获取数据列表get_data_item_list = dic['data']['list']for data_item in get_data_item_list:job_item = JobItem() # 创建 JobItem 实例# 获取职称job_item['title'] = data_item['name']# 获取职业类型job_item['job_type'] = data_item['firstPostTypeName']# 获取基本要求job_item['requirements'] = data_item['requirement'] + data_item['description']# 获取学历要求job_item['education'] = data_item['reqEducationName']# 获取经验年份job_item['experience_years'] = data_item['reqWorkYearsName']# 获取地址job_item['address'] = ', '.join(data_item['workPlaceNameList']) # 合并地址列表为一个字符串
yield job_item # 返回 JobItem 实例# 分页处理current_page = response.meta["currentPage"]page_size = response.meta["pageSize"]
if pages > current_page:next_page = current_page + 1data = {"currentPage": next_page, "pageSize": page_size, "keyword": "python"}yield scrapy.Request(url=self.start_urls[0],callback=self.parse,method='POST',body=json.dumps(data),headers=self.headers,meta={'currentPage': next_page, 'pageSize': page_size})settings.py
BOT_NAME = "scrapy_day03"
SPIDER_MODULES = ["scrapy_day03.spiders"]
NEWSPIDER_MODULE = "scrapy_day03.spiders"
ADDONS = {}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Concurrency and throttling settings
#CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 1
DOWNLOAD_DELAY = 3
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "en",
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "scrapy_day03.middlewares.ScrapyDay03SpiderMiddleware": 543,
#}
ITEM_PIPELINES = {'scrapy_day03.pipelines.ScrapyDay03Pipeline': 300,
}
FEED_EXPORT_ENCODING = "utf-8"pipeline.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
# pipelines.py
import csv
from itemadapter import ItemAdapter
class ScrapyDay03Pipeline:def open_spider(self, spider):self.file = open('网易招聘.csv', 'w', newline='', encoding='utf-8')self.writer = csv.writer(self.file)# 写入 CSV 文件的头部self.writer.writerow(['职称', '职业类型', '基本要求', '学历要求', '经验年份', '地址'])
def process_item(self, item, spider):adapter = ItemAdapter(item)self.writer.writerow([adapter.get('title'), adapter.get('job_type'), adapter.get('requirements'),adapter.get('education'), adapter.get('experience_years'), adapter.get('address')])return item
def close_spider(self, spider):self.file.close()