nvshmem源码学习(一)ibgda视角的整体流程
1 背景
DeepSeek v3论文发出来后带火了nvshmem,于是学习了下nvshmem,不过当时工作很忙一直没来得及整理,最近趁着节奏放缓整理一下。
本节主要是介绍一下nvshmem的ibgda初始化流程,代码基于3.2.5。
2 基础概念
就像nccl和mpi的关系一样,nvshmem就是nv版本的openshmem,nvshmem全局有多个进程,一般一个进程对应一个gpu,这个进程称为pe,不过为了方便后续描述,pe后续都称为rank,nvshmem的核心机制如下:
- 如图1所示,构建了一个全局所有gpu的对称堆,即Symmetric Heap,nvshmem创建了一块全局共享的内存空间,然后每个rank通过同时执行nvshmem_malloc可以从对称堆中分配一块内存,但是蓝色的部分不属于对称内存,是通过cudaMalloc等接口分配得到的。
- 提供了host和device的接口,可以向指定rank收发数据,比如put/get,有device接口之后,就可以做通信计算融合的工作,所以从这个角度看,nvshmem和nccl的关系有点像cutlass和cublas。
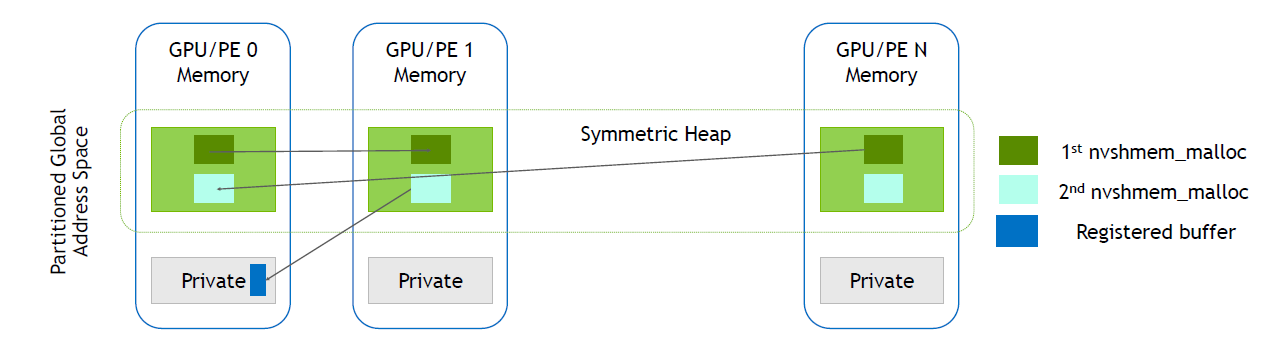
2.1 api
然后介绍一些主要关注的一些api。
2.1.1 rma
rma是指Remote Memory Access,负责从远端读取或者写入远端,分为阻塞和非阻塞两种api。
// 从当前rank的source位置,写nelems个元素到rank[pe]的dest位置,
// block表示是scope为block粒度,同时还有warp粒度的api,TYPENAME为数据类型,阻塞的api
__device__ void nvshmemx_FuncParam{TYPENAME}_put_block(TYPE *dest, const TYPE *source, size_t nelems, int pe)// 从rank[pe]的dest位置,读nelems个元素到当前rank的source,阻塞的api
__device__ void nvshmemx_FuncParam{TYPENAME}_get_block(TYPE *dest, const TYPE *source, size_t nelems, int pe)// 接下来的两个是非阻塞式的api,语义和上述一致
__device__ void nvshmemx_FuncParam{TYPENAME}_put_nbi_block(TYPE *dest, const TYPE *source, size_t nelems, int pe)
__device__ void nvshmemx_FuncParam{TYPENAME}_get_nbi_block(TYPE *dest, const TYPE *source, size_t nelems, int pe)
2.1.2 amo
amo是指Atomic Memory Operations,是rank之间的原子操作,分为fetch和nonfetch两种操作,fetch就是有返回值,比如,nonfetch就是没有返回值。
// non fetch操作,将value原子加到rank[pe]的dest
__device__ void nvshmem_FuncParam{TYPENAME}_atomic_add(TYPE *dest, TYPE value, int pe)
2.2 ibgda
nvshmem支持多个tranport进行数据通信,比如ibrc和ibgda,ibrc工作的方式和nccl有点类似,都是gpu准备好数据,cpu负责网络收发,不过nccl需要在执行kernel之前创建一个proxy args通知cpu proxy线程,ibrc不需要,ibrc的kernel会直接写cmd到一块buf,cpu proxy线程轮询这个buf就可以知道需要执行什么操作。具体执行流程如图2所示。

cpu执行一次post send的性能很好,但是DeepEP这种场景下,一个gpu要向256个专家发送大量7k或者14k的消息,这个时候cpu就会成为瓶颈,尤其在cpu负载比较高的场景;另外cpu和gpu之间的flag同步也会有额外的开销。
因此ibgda将rdma操作通过gpu实现,即将rdma相关资源都放在gpu,然后rdma runtime也通过gpu实现,从而可以利用gpu大量线程并行执行,虽然gpu单线程处理一次post性能比cpu差,但是在大规模场景下会有很大优势,执行流程如下图所示。

3 实现
3.1 初始化
nvshmem和nccl一样,首先需要一个bootstrap的过程,建立一个bootstrap网络用于元信息的交互,这个逻辑和nccl很像,所以这里不再赘述。只关注nvshmemi_common_init做的初始化工作。
nvshmem支持多种对称内存分配方式(后续直接简称为对称内存),比如host内存,device内存,shm,其中device内存又支持static和dynamic,nvshmemi_init_symmetric_heap就是选择一个合适的对称内存,然后通过reserve_heap预留一段内存。
transport_init和_build_transport_map是初始化transport,我们只关注ibgda就好,nvshmemi_setup_connections是执行建链,setup_symmetric_heap是建立全局共享内存。
int nvshmemi_common_init(nvshmemi_state_t *state) {nvshmemi_init_symmetric_heap(state, nvshmemi_use_cuda_vmm,nvshmemi_device_state.symmetric_heap_kind);status = state->heap_obj->reserve_heap();status = nvshmemi_transport_init(state);status = nvshmemi_build_transport_map(state);status = nvshmemi_setup_connections(state);status = state->heap_obj->setup_symmetric_heap();
}
接下来我们看下heap和transport的执行。
3.1.1 heap
对于device内存的分配有nvshmemi_symmetric_heap_vidmem_dynamic_vmm和nvshmemi_symmetric_heap_vidmem_static_pinned两种对称内存,对称内存有个成员变量为mspace,mspace可以理解为一个allocator,通过map维护free_chunk,分配的时候就是遍历free_chunk找到一个满足需求size的chunk,释放就是将chunk加入free_chunk,并尝试合并。
static就是通过cudaMalloc预留一大段内存,比如1GB,然后用户执行nvshmem_malloc的时候通过mspace分配指定size,但是如果空闲的空间小于用户的需求则会报错。
因此nvshmem还提供了dynamic的对称内存,dynamic初始化的时候预留了足够大的虚拟地址空间,比如8 * 128GB,并不会分配物理内存,直到用户执行了nvshmem_malloc之后才会实际分配,并映射到预留的虚拟地址空间。
我们主要关注下nvshmem默认用的dynamic。
构造函数如下:
nvshmemi_symmetric_heap_dynamic::nvshmemi_symmetric_heap_dynamic(nvshmemi_state_t *state) noexcept: nvshmemi_symmetric_heap(state) {set_p2p_transport(nvshmemi_mem_p2p_transport::get_instance(state->mype, state->npes));set_remote_transport(nvshmemi_mem_remote_transport::get_instance());set_mem_handle_type((get_p2pref()->get_mem_handle_type()));state->p2p_transport = get_p2pref();
}
mem_handle_type就是cuMemCreate分配物理内存时指定的requestedHandleTypes,非mnnvl场景为CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR。
int nvshmemi_symmetric_heap_vidmem_dynamic_vmm::reserve_heap() {physical_heap_size_ = 0;status = CUPFN(nvshmemi_cuda_syms,cuMemAddressReserve((CUdeviceptr *)&global_heap_base_, p2p_npes * heap_size_,alignbytes, (CUdeviceptr)NULL, 0));heap_base_ = (void *)((uintptr_t)global_heap_base_);status = setup_mspace();
}
在reserve_heap中通过cuMemAddressReserve预留了足够大的虚拟地址空间到heap_base_,但此时没有实际内存的分配,physical_heap_size_ 为0,mspace中没有可用空间。
然后在setup_symmetric_heap中通过allgather获取所有rank的heap_base_,这样每个rank就知道了其他所有rank的共享内存的起始位置。
3.1.2 transport
每个transport都实现了nvshmemt_init函数,用于初始化transport,nvshmem会遍历每个可用的transport执行对应的nvshmemt_init,对于ibgda,核心逻辑如下。
int nvshmemt_init(nvshmem_transport_t *t, struct nvshmemi_cuda_fn_table *table, int api_version) {ibgda_state = (nvshmemt_ibgda_state_t *)calloc(1, sizeof(nvshmemt_ibgda_state_t));transport->state = (void *)ibgda_state;nvshmemt_ibv_ftable_init(&ibv_handle, &ftable, ibgda_state->log_level);nic_mapping_memtype_request =ibgda_parse_nic_mapping_memtype_request(options->IBGDA_FORCE_NIC_BUF_MEMTYPE);dev_list = ftable.get_device_list(&num_devices);for (int i = 0; i < num_devices; i++) {device = (struct ibgda_device *)ibgda_state->devices + i;device->dev = dev_list[i];device->context = ftable.open_device(device->dev);status = ibgda_check_gpu_mapping_nic_uar(device);device->nic_handler = status ? IBGDA_NIC_HANDLER_CPU : IBGDA_NIC_HANDLER_GPU;status = ibgda_check_nic_mapping_memtypes(ibgda_state, device, nic_mapping_memtype_request);}for (int i = 0; i < transport->n_devices; i++) {status = get_pci_path(i, &transport->device_pci_paths[i], transport);}
}
分配ibgda_state,记录到transport;dlopen verbs.so,将相关handle load到ftable,dlopen gdrapi.so,将相关handle load到gdrcopy_ftable;检查是否支持dma_buf,后续假设为不支持;IBGDA_FORCE_NIC_BUF_MEMTYPE是个环境变量,表示在ibgda场景下,nic相关的内存分配在gpu还是cpu,默认为gpumem。
然后通过get_device_list获取机器所有可用的网卡,对于每个可用的网卡,首先通过ibgda_check_gpu_mapping_nic_uar测试下是否可以分配uar并且uar可以被映射到device,如果可以的话,nic_handler设置为IBGDA_NIC_HANDLER_GPU,表示由gpu写网卡db;然后通过ibgda_check_nic_mapping_memtypes检查该网卡是否可以注册gpu显存。遍历出来的网卡会根据用户指定的环境变量进行选择,比如如果用户指定了HCA_LIST,那么会根据这个list进行过滤选择网卡。
最后对于选择出来的网卡,获取pci地址,用于之后gpu进行亲和性选择网卡。
int nvshmemi_build_transport_map(nvshmemi_state_t *state) {int status = 0; int *local_map = NULL;state->transport_map = (int *)calloc(state->npes * state->npes, sizeof(int));local_map = (int *)calloc(state->npes, sizeof(int));state->transport_bitmap = 0;for (int i = 0; i < state->npes; i++) {int reach_any = 0;for (int j = 0; j < state->num_initialized_transports; j++) {int reach = 0;status = state->transports[j]->host_ops.can_reach_peer(&reach, &state->pe_info[i],state->transports[j]);state->transports[j]->cap[i] = reach;reach_any |= reach;if (reach) {int m = 1 << j;local_map[i] |= m;if ((state->transport_bitmap & m) == 0) {state->transport_bitmap |= m;}}}}status = nvshmemi_boot_handle.allgather((void *)local_map, (void *)state->transport_map,sizeof(int) * state->npes, &nvshmemi_boot_handle);
}
nvshmemi_build_transport_map用于计算出当前节点到所有节点的可达性。
通过transport的can_reach_peer计算得到当前rank到rank[i]的reach,表示当前节点通过transports[j]到rank[i]的cap,对于ibgda,cap为支持write,read和atomic,将reach记录到state->transports[j]->cap[i];local_map[i]的第j为设置为1,表示可以通过第j个transport到达rank[i],然后将local_map执行allgather到transport_map;transport_bitmap记录了当前state用了哪些transport。
static int nvshmemi_setup_nvshmem_handles(nvshmemi_state_t *state) {int status = 0; int dev_attr = 0; /* TODO: We should really check all of these allocations. */;state->selected_transport_for_rma = (int *)calloc(state->npes, sizeof(int));state->selected_transport_for_amo = (int *)calloc(state->npes, sizeof(int));CUDA_RUNTIME_CHECK(cudaDeviceGetAttribute(&dev_attr, cudaDevAttrCanUseHostPointerForRegisteredMem, state->device_id));state->host_memory_registration_supported =dev_attr & cudaDevAttrCanUseHostPointerForRegisteredMem;for (int pe = 0; pe < state->npes; pe++) {state->selected_transport_for_rma[pe] = -1;state->selected_transport_for_amo[pe] = -1;} int tbitmap;for (int i = 0; i < state->npes; i++) {bool amo_initialized = false, rma_initialized = false;tbitmap = state->transport_bitmap;for (int j = 0; j < state->num_initialized_transports; j++) {if (!(state->transports[j])) {tbitmap >>= 1;continue;} if (tbitmap & 1) { if (!rma_initialized &&nvshmemi_transport_cap_support_rma(nvshmemi_state->transports[j]->cap[i])) {rma_initialized = true;state->selected_transport_for_rma[i] = j; } if (!amo_initialized &&nvshmemi_transport_cap_support_amo(nvshmemi_state->transports[j]->cap[i])) {amo_initialized = true;state->selected_transport_for_amo[i] = j; } } tbitmap >>= 1;} } return status;
}记录结构体selected_transport_for_rma[i] = j,表示当前节点可以通过transport[j]向rank[i]发起rma操作,selected_transport_for_amo[i] = j,表示当前节点可以通过transport[j]向rank[i]发起amo操作。
3.2 建链
然后通过nvshmemi_setup_connections执行建链的逻辑,对于ibgda就是nvshmemt_ibgda_connect_endpoints,由于DeepEP中只使用了RC,所以之后我们先忽略DCI,DCT相关的逻辑。
selected_dev_ids为当前rank使用的网卡,数量为num_selected_devs,不过IBGDA_ENABLE_MULTI_PORT环境变量默认为false,就是只使用第一个网卡。
int nvshmemt_ibgda_connect_endpoints(nvshmem_transport_t t, int *selected_dev_ids,int num_selected_devs) {int mype = t->my_pe;int n_pes = t->n_pes;int num_rc_eps_per_pe = options->IBGDA_NUM_RC_PER_PE;int num_rc_eps = num_rc_eps_per_pe * n_pes;local_rc_handles = (struct ibgda_rc_handle *)calloc(num_rc_eps, sizeof(*local_rc_handles));
}
num_rc_eps_per_pe是当前rank在一个网卡上到每个peer需要用几个rc,num_rc_eps = num_rc_eps_per_pe * n_pes,表示当前rank的一个网卡上共有多少个rc,然后分配local_rc_handles,即num_rc_eps个ibgda_rc_handle。ibgda_rc_handle保存的就是qpn,lid或者gid等建链需要的信息。
然后遍历每个网卡,对每个网卡进行建链。
int nvshmemt_ibgda_connect_endpoints(nvshmem_transport_t t, int *selected_dev_ids,int num_selected_devs) {for (int i = 0; i < num_selected_devs; i++) {device = ((struct ibgda_device *)ibgda_state->devices + curr_dev_id);portid = ibgda_state->port_ids[selected_dev_ids[i]];skip_cst &= (!ibgda_cst_is_required(device, gpu_device_id));device->rc.map_by = rc_map_type;device->rc.num_eps_per_pe = num_rc_eps_per_pe;device->rc.peer_ep_handles =(struct ibgda_rc_handle *)calloc(num_rc_eps, sizeof(*device->rc.peer_ep_handles));device->rc.eps = (struct ibgda_ep **)calloc(num_rc_eps, sizeof(*device->dci.eps));}
}
然后分配peer_ep_handles,用于之后all2all拿到所有rank对应的ibgda_rc_handle;分配rc.eps,即当前rank上所有的qp。
ibgda_cst_is_required用于判断gpu对PCIe的写保序能力,就像之前NCCL系列中提到的flush操作,由于Ampere gpu对于gdr写入的data和flag可能发生乱序导致kernel读到脏数据,因此需要flush操作,但是Hooper对PCIe写是保序的,不需要flush,因此通过ibgda_cst_is_required可以判断是否需要跳过flush操作。
static bool ibgda_cst_is_required(struct ibgda_device *device, CUdevice dev_id) {bool rval = true;int order = 0; if (CUPFN(ibgda_cuda_syms,cuDeviceGetAttribute(&order, (CUdevice_attribute)CU_DEVICE_ATTRIBUTE_GPU_DIRECT_RDMA_WRITES_ORDERING,dev_id))) {NVSHMEMI_WARN_PRINT("Cannot query dev attr. Assuming no GDR write ordering\n");} else {// GPU guarantees incoming PCIe write ordering. No need to do CST.if (order >= CU_FLUSH_GPU_DIRECT_RDMA_WRITES_TO_OWNER) rval = false;} return rval;
}
通过cuDeviceGetAttribute查询gpu的CU_DEVICE_ATTRIBUTE_GPU_DIRECT_RDMA_WRITES_ORDERING,得到的order是一个scope,如果用户实际执行PCIe写操作的scope不超过查询gpu得到的scope,那么不需要执行flush。
这里判断逻辑是,如果得到的order至少为CU_FLUSH_GPU_DIRECT_RDMA_WRITES_TO_OWNER,即当前卡对于PCIe写是保序的,这种场景就不需要执行flush。
3.2.1 cq相关资源分配
static int ibgda_create_cq_shared_objects(nvshmemt_ibgda_state_t *ibgda_state,struct ibgda_device *device, int n_pes) {unsigned int num_cqs = device->dci.num_eps + device->rc.num_eps_per_pe * n_pes;size_t num_cqe = IBGDA_ROUND_UP_POW2_OR_0(ibgda_qp_depth);size_t cq_buf_size_per_cq = num_cqe * NVSHMEMI_IBGDA_CQE_SIZE;size_t cq_buf_size = num_cqs * cq_buf_size_per_cq;size_t dbr_buf_size = IBGDA_DBRSIZE * num_cqs;...
}
每个qp对应一个cq,因此num_cqs就是qp数,num_cqe表示一个cq的buff大小,因此所有cq总的buff大小为num_cqs * cq_buf_size_per_cq,同理每个cq对应一个dbr,因此总的dbr大小为IBGDA_DBRSIZE * num_cqs;
然后开始分配内存
static int ibgda_create_cq_shared_objects(...) {...status = ibgda_nic_control_alloc(&cq_mobject, cq_buf_size, IBGDA_GPAGE_SIZE);status = cudaMemset(cq_mobject->base.gpu_ptr, 0xff, cq_mobject->base.size);status = ibgda_mobject_nic_map(cq_mobject, context, IBV_ACCESS_LOCAL_WRITE,ibgda_state->dmabuf_support_for_control_buffers);
}
ibgda_nic_control_alloc就是通过cudaMalloc分配大小为cq_buf_size的显存,并记录到ibgda_mem_object类型的cq_mobject;然后将cq buff初始化为0xff,即INVALID;ibgda_mobject_nic_map就是通过mlx5dv_devx_umem_reg将mobject中的gpu_ptr执行注册得到umem。
static int ibgda_mobject_nic_map(struct ibgda_mem_object *mobject, struct ibv_context *context,uint32_t access, bool use_dmabuf = false) {void *addr;struct mlx5dv_devx_umem *umem = NULL;addr = (void *)mobject->aligned.gpu_ptr;umem = mlx5dv_devx_umem_reg(context, addr, mobject->aligned.size, access);mobject->umem = umem;mobject->has_nic_mapping = true;return status;
}
同理对于dbr,也是相同的流程完成分配和注册。
3.2.2 qp相关资源分配
static int ibgda_create_qp_shared_objects(nvshmemt_ibgda_state_t *ibgda_state,struct ibgda_device *device, int n_pes) {pdn = dvpd.pdn;srq_init_attr.attr.max_wr = ibgda_srq_depth;srq_init_attr.attr.max_sge = 1; srq = ftable.create_srq(pd, &srq_init_attr);...srqn = dvsrq.srqn;recv_cq = ftable.create_cq(context, ibgda_srq_depth, NULL, NULL, 0);rcqn = dvrcq.cqn;status = ibgda_create_internal_buffer(&device->qp_shared_object.internal_buf, ibgda_state,device, n_pes);...
}
由于recv操作使用不频繁,因此这里直接在host内存上创建了srq和recv_cq。
static int ibgda_create_internal_buffer(struct ibgda_internal_buffer *internal_buf,nvshmemt_ibgda_state_t *ibgda_state,struct ibgda_device *device, int n_pes) {struct ibgda_mem_object *internal_buf_mobject = NULL;struct nvshmemt_ib_common_mem_handle *internal_buf_mhandle = NULL;size_t size_per_dci = ...;size_t size_per_rc =NVSHMEMI_IBGDA_IBUF_SLOT_SIZE * (ibgda_num_fetch_slots_per_rc + IBGDA_IBUF_RESERVED_SLOTS);size_t buf_size =(size_per_dci * device->dci.num_eps) + (size_per_rc * device->rc.num_eps_per_pe * n_pes);status = ibgda_gpu_mem_alloc(&internal_buf_mobject, buf_size, IBGDA_GPAGE_SIZE, false);internal_buf_mhandle =(struct nvshmemt_ib_common_mem_handle *)calloc(1, sizeof(*internal_buf_mhandle));status = nvshmemt_ib_common_reg_mem_handle(...);internal_buf->mem_object = internal_buf_mobject;internal_buf->mem_handle = internal_buf_mhandle;return status;
}
然后开始分配internal_buf,internal_buf有多个slot,一个slot大小为NVSHMEMI_IBGDA_IBUF_SLOT_SIZE,大小为256,所以一个warp的每个线程在一个slot都有一个uint64空间。internal_buf分为两部分,第一部分只有一个slot,用于执行cst或者non_fetch的amo,剩余的部分组成一个环形队列,用于fetch的amo,后续具体介绍。然后通过ibgda_gpu_mem_alloc,即cudaMalloc,分配长度为buf_size的内存,记录到internal_buf_mobject,然后通过nvshmemt_ib_common_reg_mem_handle,即reg_mr,注册这段内存。
static int ibgda_create_qp_shared_objects(...) {... wq_buf_size_per_qp = num_wqebb * MLX5_SEND_WQE_BB; // num_wqebb is always a power of 2wq_buf_size = wq_buf_size_per_qp * num_eps;status = ibgda_nic_control_alloc(&wq_mobject, wq_buf_size, IBGDA_GPAGE_SIZE);status = ibgda_mobject_nic_map(wq_mobject, context, IBV_ACCESS_LOCAL_WRITE,ibgda_state->dmabuf_support_for_control_buffers);dbr_buf_size = IBGDA_DBRSIZE * num_eps;status = ibgda_nic_control_alloc(&dbr_mobject, dbr_buf_size, IBGDA_GPAGE_SIZE);status = ibgda_mobject_nic_map(dbr_mobject, context, IBV_ACCESS_LOCAL_WRITE,ibgda_state->dmabuf_support_for_control_buffers);NVSHMEMI_NZ_ERROR_JMP(status, NVSHMEMX_ERROR_INTERNAL, out, "cannot register dbr buf.\n");// Outputdevice->qp_shared_object.srq = srq; device->qp_shared_object.recv_cq = recv_cq;device->qp_shared_object.pdn = pdn;...
}
然后类似cq,创建所有qp的wq buff和dbr,最后,将srq,recv_cq等相关信息保存到qp_shared_object。
3.2.3 创建qp和cq
static int ibgda_create_qp_shared_objects(...) {...for (int i = 0; i < num_rc_eps; ++i) {status = ibgda_create_qp(&device->rc.eps[i], device, portid, i,NVSHMEMI_IBGDA_DEVICE_QP_TYPE_RC);status = ibgda_get_rc_handle(&local_rc_handles[i], device->rc.eps[i], device);}if (num_rc_eps) {status = t->boot_handle->alltoall((void *)local_rc_handles, (void *)device->rc.peer_ep_handles,sizeof(*local_rc_handles) * device->rc.num_eps_per_pe, t->boot_handle);}...
}
准备好qp所需要的资源之后,开始通过ibgda_create_qp创建每一个qp,创建完成后通过ibgda_get_rc_handle将qp[i]的handle存到上述的local_rc_handles,handle就是lid,qpn等信息。然后通过bootstrap网络对local_rc_handles执行一个all2all,拿到所有rank对应qp的handle,这样就可以建链了。
然后看下ibgda_create_qp,在上述准备qp资源的过程中,nvshmem分配了一段连续的wq_buff空间和连续的dbr_buff空间用于所有qp,每个qp会使用这个buff的一部分,因此已经有了wq buff和dbr,还有srq和rcq,但是还没有scq和uar,因此create_qp的过程中需要先创建scq。
scq的cq buff和dbr也是预留了所有cq的空间,每个cq通过偏移找到自己对应的地址,即cq_offset和dbr_offset。
static int ibgda_create_cq(struct ibgda_cq **pgcq, struct ibgda_device *device) {struct mlx5dv_devx_umem *cq_umem = device->cq_shared_object.cq_mobject->umem;off_t cq_offset = device->cq_shared_object.cur_cq_off;struct mlx5dv_devx_umem *dbr_umem = device->cq_shared_object.dbr_mobject->umem;off_t dbr_offset = device->cq_shared_object.cur_dbr_off;
}
由于cq并没有使用到uar,因此这里虽然申请了uar,但是没有映射到device空间,然后将dbr,cq buff等信息填充到cmd,执行mlx5dv_devx_obj_create完成cq的创建,最后将cq信息记录到pgcq。
static int ibgda_create_cq(...) {DEVX_SET(create_cq_in, cmd_in, opcode, MLX5_CMD_OP_CREATE_CQ);DEVX_SET(create_cq_in, cmd_in, cq_umem_id, cq_umem->umem_id);DEVX_SET(cqc, cq_context, cc, 0x1);DEVX_SET(cqc, cq_context, dbr_umem_id, dbr_umem->umem_id);DEVX_SET64(cqc, cq_context, dbr_addr, dbr_offset);DEVX_SET(create_cq_in, cmd_in, cq_umem_id, cq_umem->umem_id); // CQ bufferDEVX_SET64(create_cq_in, cmd_in, cq_umem_offset, cq_offset);gcq->devx_cq =mlx5dv_devx_obj_create(context, cmd_in, sizeof(cmd_in), cmd_out, sizeof(cmd_out));
}
创建cq时设置了cc,所以cqe只会生成在cq buff的第一个entry,poll cq时需要通过wqe_counter判断,后续会看到。
cq创建完成后开始分配qp的uar,通过mlx5dv_devx_alloc_uar分配uar,然后映射到device空间,记录到uar_mobject中。
static int ibgda_alloc_and_map_qp_uar(struct ibv_context *context, ibgda_nic_handler_t handler,struct ibgda_mem_object **out_mobject) {uar = mlx5dv_devx_alloc_uar(context, MLX5DV_UAR_ALLOC_TYPE_BF);status = ibgda_nic_mem_gpu_map(&uar_mobject, uar, uar_reg_size);*out_mobject = uar_mobject;
}
此时send_cq和uar都有了,加上之前的srq,wq_buff,所有信息都有了,然后开始创建qp,将dbr,wq_buff填充到cmd,通过mlx5dv_devx_obj_create创建qp,将qp相关信息记录到ep中。
static int ibgda_create_qp(...) {DEVX_SET(create_qp_in, cmd_in, opcode, MLX5_CMD_OP_CREATE_QP);DEVX_SET(create_qp_in, cmd_in, wq_umem_id, wq_umem->umem_id); // WQ bufferDEVX_SET64(create_qp_in, cmd_in, wq_umem_offset, wq_offset);}
创建完成之后通过modify qp将qp设置为rts,就完成了整个建链的过程。
现在host端的qp已经完成创建和建链了,接下来需要将host的qp写入到device,从而可以让kernel直接访问。
3.2.4 device端初始化
device端qp的数据结构为nvshmemi_ibgda_device_qp,成员含义如下所示,mvar以及cq的部分稍后在发送数据章节介绍,这里先跳过。
typedef struct nvshmemi_ibgda_device_qp {int version;nvshmemi_ibgda_device_qp_type_t qp_type; // dci还是rcuint32_t qpn;uint32_t dev_idx; // 表示哪个网卡struct {uint32_t nslots; // 如上所述,环形队列长度void *buf; // internal buffer地址__be32 lkey;__be32 rkey;} ibuf; // Internal bufferstruct {uint16_t nwqes; // wq大小void *wqe; // wq buffer地址__be32 *dbrec; // db record地址void *bf; // uar地址nvshmemi_ibgda_device_cq_t *cq; // send_cquint64_t *prod_idx;} tx_wq;nvshmemi_ibgda_device_qp_management_v1 mvars; // management variables
} nvshmemi_ibgda_device_qp_v1;
nvshmemi_ibgda_device_state_t是device端整体入口,保存了所有的qp,cq和mr,相关含义如下所示。
typedef struct {...uint32_t num_qp_groups; // 同num_rc_per_peuint32_t num_rc_per_pe; // 当前pe在一个网卡上到每个peer需要用几个rcnvshmemi_ibgda_device_qp_map_type_t rc_map_type; // map typeuint32_t num_requests_in_batch; /* always a power of 2 */ // 多少个wqe写一次dbsize_t log2_cumem_granularity; // 内存的chunk大小int num_devices_initialized; // 使用的网卡数bool nic_buf_on_gpumem; // nic buf是否在gpubool may_skip_cst; // 上述的是否需要flushbool use_async_postsend; // gpu场景为falsestruct {// lkeys[idx] gives the lkey of chunk idx.nvshmemi_ibgda_device_key_t lkeys[NVSHMEMI_IBGDA_MAX_CONST_LKEYS];// rkeys[idx * npes + pe] gives rkey of chunck idx targeting peer pe.nvshmemi_ibgda_device_key_t rkeys[NVSHMEMI_IBGDA_MAX_CONST_RKEYS];} constmem;struct {uint8_t *qp_group_switches;nvshmemi_ibgda_device_cq_t *cqs; // For both dcis and rcs. CQs for DCIs come first.nvshmemi_ibgda_device_qp_t *rcs;nvshmemi_ibgda_device_local_only_mhandle *local_only_mhandle_head;// For lkeys that cannot be contained in constmem.lkeys.// lkeys[idx - NVSHMEMI_IBGDA_MAX_CONST_LKEYS] gives the lkey of chunk idx.nvshmemi_ibgda_device_key_t *lkeys;// For rkeys that cannot be contained in constmem.rkeys.// rkeys[(idx * npes + pe) - NVSHMEMI_IBGDA_MAX_CONST_RKEYS] gives rkey of chunck idx// targeting peer pe.nvshmemi_ibgda_device_key_t *rkeys;} globalmem;
} nvshmemi_ibgda_device_state_v1;
typedef nvshmemi_ibgda_device_state_v1 nvshmemi_ibgda_device_state_t;
constmem和globalmem中保存了qp,cq和mr,这里引入constmem的原因是为了优化性能,constmem是一个固定大小的数组,如果数据量小于这个长度,那么就可以不用再访问一次gm。
然后看初始化device state的过程,首先分配host上的rc_h和cq_h,num_rc_handles是所有网卡到所有rank的qp数综合,同理对于num_cq_handles。还是先跳过关于mvar相关的操作,接下来数据发送流程会介绍。
static int ibgda_setup_gpu_state(nvshmem_transport_t t) {rc_h = (nvshmemi_ibgda_device_qp_t *)calloc(num_rc_handles, sizeof(*rc_h));cq_h = (nvshmemi_ibgda_device_cq_t *)calloc(num_cq_handles, sizeof(*cq_h));for (int i = 0; i < num_rc_handles / n_devs_selected; ++i) {int arr_offset = i * n_devs_selected;for (int j = 0; j < n_devs_selected; j++) {int arr_idx = arr_offset + j; int dev_idx = ibgda_state->selected_dev_ids[j];struct ibgda_device *device = (struct ibgda_device *)ibgda_state->devices + dev_idx;ibgda_get_device_qp(&rc_h[arr_idx], device, device->rc.eps[i], j);rc_h[arr_idx].tx_wq.cq = &cq_d[cq_idx];ibgda_get_device_cq(&cq_h[cq_idx], device->rc.eps[i]->send_cq);cq_h[cq_idx].qpn = rc_h[arr_idx].qpn;cq_h[cq_idx].qp_type = rc_h[arr_idx].qp_type;++cq_idx;}}
}
n_devs_selected为网卡数,这里会遍历所有的qp,通过ibgda_get_device_qp将qp信息记录下来。同理对于ibgda_get_device_cq。
ibgda_get_device_qp将ep对应的qp信息写入dev_qp。因为tx_wq等相关信息都是直接透传,所以这里不用关注,然后就是将internal_buf记录下来,如上所述,internal_buf也是一个连续的buffer,每个qp根据偏移记录自己的地址。
static void ibgda_get_device_qp(nvshmemi_ibgda_device_qp_t *dev_qp, struct ibgda_device *device,const struct ibgda_ep *ep, int selected_dev_idx) {size_t size_per_rc =NVSHMEMI_IBGDA_IBUF_SLOT_SIZE * (ibgda_num_fetch_slots_per_rc + IBGDA_IBUF_RESERVED_SLOTS);ibuf_rc_start = ibuf_dci_start + (size_per_dci * device->dci.num_eps);if (ep->qp_type == NVSHMEMI_IBGDA_DEVICE_QP_TYPE_RC) {ibuf_ptr = (void *)(ibuf_rc_start + (size_per_rc * ep->user_index));dev_qp->ibuf.nslots = ibgda_num_fetch_slots_per_rc;}dev_qp->ibuf.lkey = htobe32(device->qp_shared_object.internal_buf.mem_handle->lkey);dev_qp->ibuf.rkey = htobe32(device->qp_shared_object.internal_buf.mem_handle->rkey);dev_qp->ibuf.buf = ibuf_ptr;
}static int ibgda_setup_gpu_state(nvshmem_transport_t t) {status = cudaMalloc(&dci_d, num_dci_handles * sizeof(*dci_d));status = cudaMalloc(&rc_d, num_rc_handles * sizeof(*rc_d));status = cudaMalloc(&cq_d, num_cq_handles * sizeof(*cq_d));status = cudaMalloc(&qp_group_switches_d, num_qp_groups * sizeof(*qp_group_switches_d));cudaMemsetAsync(qp_group_switches_d, 0, num_qp_groups * sizeof(*qp_group_switches_d),ibgda_state->my_stream);status = cudaMemcpyAsync(rc_d, (const void *)rc_h, sizeof(*rc_h) * num_rc_handles,cudaMemcpyHostToDevice, ibgda_state->my_stream);status = cudaMemcpyAsync(cq_d, (const void *)cq_h, sizeof(*cq_h) * num_cq_handles,cudaMemcpyHostToDevice, ibgda_state->my_stream); ibgda_device_state_h->globalmem.rcs = rc_d;ibgda_device_state_h->globalmem.cqs = cq_d;...
}
最后就是分配显存,将host端初始化好的qp,cq等拷贝到device state,到这里就可以执行数据的发送了。
3.3 内存分配
之前有提到,对称内存中现在还没有实际分配空间,直到用户执行了nvshmem_malloc才会真正分配。
void *nvshmemi_symmetric_heap_vidmem_dynamic_vmm::allocate_symmetric_memory(size_t size,size_t count,size_t alignment,int type) {int status = 0; void *ptr = NULL;ptr = allocate_virtual_memory_from_mspace(size, count, alignment, type);if ((size > 0) && (ptr == NULL)) {status = allocate_physical_memory_to_heap(size + alignment);ptr = allocate_virtual_memory_from_mspace(size, count, alignment, type);status = nvshmemi_update_device_state();} out:return (ptr);
}
allocate_virtual_memory_from_mspace就是前文说的在free_chunk中找空闲内存,因为现在没有分配,所以返回NULL,然后执行allocate_physical_memory_to_heap进行实际分配。
int nvshmemi_symmetric_heap_vidmem_dynamic_vmm::allocate_physical_memory_to_heap(size_t size) {size = ((size + mem_granularity_ - 1) / mem_granularity_) * mem_granularity_;remaining_size = size;buf_start = (char *)heap_base_ + physical_heap_size_;do {buf_end = (char *)heap_base_ + physical_heap_size_;register_size =remaining_size > adjusted_max_handle_len ? adjusted_max_handle_len : remaining_size;status = CUPFN(nvshmemi_cuda_syms, cuMemCreate(&cumem_handle, register_size,(const CUmemAllocationProp *)&prop, 0));/* Global offset in the heap */heap_offset = (off_t)(physical_heap_size_);cumem_handles_.push_back(std::make_tuple(cumem_handle, heap_offset /*mc_offset*/, mmap_offset, register_size));status = CUPFN(nvshmemi_cuda_syms,cuMemMap((CUdeviceptr)buf_end, register_size, mmap_offset, cumem_handle, 0));status =register_heap_memory((nvshmem_mem_handle_t *)&cumem_handle, buf_end, register_size);remaining_size -= register_size;} while (remaining_size > 0);}
首先会将用户申请的size对mem_granularity_进行对齐,mem_granularity_默认为500M,然后开始循环按照2GB的粒度进行分配,通过cuMemCreate分配物理内存得到cumem_handle,将cumem_handle记录到cumem_handles_,然后通过cuMemMap将cumem_handle映射到虚拟地址buf_end,这样就在之前的虚拟地址空间的最后又分配了一个chunk。整体如图4所示

heap为用户使用的连续的虚拟地址,绿色为新分配的chunk,所以首先需要分配绿色的物理内存映射到heap。
int nvshmemi_symmetric_heap_dynamic::register_heap_chunk(nvshmem_mem_handle_t *mem_handle_in,void *buf, size_t size) {nvshmem_mem_handle_t local_handles[state->num_initialized_transports];NVSHMEMU_FOR_EACH_IF(idx, state->num_initialized_transports, NVSHMEMU_IS_BIT_SET(state->transport_bitmap, idx), {current = transports[idx];if (NVSHMEMI_TRANSPORT_IS_CAP(current, state->mype, NVSHMEM_TRANSPORT_CAP_MAP)) {...} else {status = remotetran.register_mem_handle(&local_handles[0], idx, mem_handle_in, buf,size, current);}})
}
然后开始使用每个tranport执行这个新内存块的注册得到lkey,对于ibgda,就是nvshmemt_ibgda_get_mem_handle。
int nvshmemt_ibgda_get_mem_handle(...) {for (int i = 0; i < n_devs_selected; ++i) {struct ibgda_device *device =((struct ibgda_device *)ibgda_state->devices + ibgda_state->selected_dev_ids[i]);nvshmem_mem_handle_t *dev_handle = (nvshmem_mem_handle_t *)&handle->dev_mem_handles[i];status = nvshmemt_ib_common_reg_mem_handle(...);}num_elements = length >> transport->log2_cumem_granularity;while (num_elements > 0) {for (int i = 0; i < n_devs_selected; i++) {device_lkey = htobe32(handle->dev_mem_handles[i].lkey);nvshmemi_ibgda_device_key_t dev_key;dev_key.key = device_lkey;dev_key.next_addr = (uint64_t)buf + length;ibgda_device_lkeys.emplace_back(dev_key);}--num_elements;}}
首先遍历每个可用的网卡,reg_mr存到handle。然后按照500M的粒度记录lkey,如图4所示。最后将新的lkey写到ibgda_device_state,不超过constmem的直接写,超过constmem的写到globalmem。
3.4 数据收发流程简介
ibgda的数据发送使用的是device函数,那将会有如下一些问题:
- wq的同步问题,用户希望发送一些wqe,这些消息如何通知网卡,相反的,网卡完成wqe发送之后,如何同步给上层。
- 数据收发的api可能会多线程执行,这些线程可能来自同一个warp,也可能是不同的warp,甚至是不同的block,如何保证执行时的线程安全。
- 由于写db是PCIe的write,并且需要fence,是个比较耗时的操作,因此ibgda的设计中,是写多个wqe后再写一次db,那么如何知道谁来写,写的时候怎么保证其他线程已经执行完成。
- 对于不支持PCIe保序的gpu,需要执行flush,但是对于异步的api,ibgda怎么知道什么时候执行flush。
- 对于执行fetch的amo,数据应该存在哪里。
建链过程中我们跳过了mvar的介绍,qp中有一个成员为mvars,每个qp都对应了一个send_cq,cq中通过指针指向mvars,所以mvars在一对qp和cq间共享。这里先列一下每个变量的含义,然后具体介绍如何解决上述问题的。
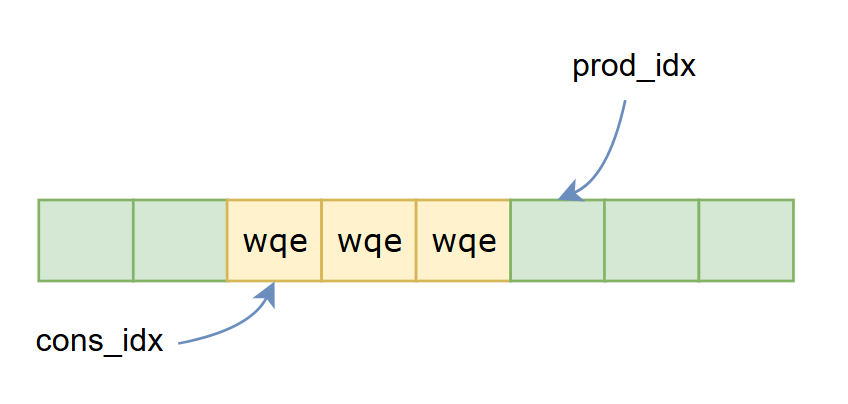
typedef struct {int post_send_lock;struct {// All indexes are in wqebb unituint64_t resv_head; // last reserved wqe idx + 1uint64_t ready_head; // last ready wqe idx + 1uint64_t prod_idx; // posted wqe idx + 1 (producer index + 1)uint64_t cons_idx; // polled wqe idx + 1 (consumer index + 1)uint64_t get_head; // last wqe idx + 1 with a "fetch" operation (g, get, amo_fetch)uint64_t get_tail; // last wqe idx + 1 polled with cst; get_tail > get_head is possible} tx_wq;struct {uint64_t head;uint64_t tail;} ibuf;
} __attribute__((__aligned__(8))) nvshmemi_ibgda_device_qp_management_v1;
接下来以不准确但是不影响理解的方式定性描述一下这几个问题的解决,准确的表述稍后介绍。
3.4.1 生产者消费者
对于问题1,可以将wq buf理解为一个生产者消费者队列,通过头尾指针来协调生产消费,用户是生产者,每执行一次数据发送,用户都会在wq buff中写一些wqe,接下来会更新prod_idx,表示有了新的wqe,然后将prod_idx写入db通知网卡。
网卡是消费者,收到通知后接下来网卡会执行这些新wqe的发送任务,当wqe发送结束后会写cqe,用户通过执行poll_cq会得到这些cqe,从cqe中解析出网卡完成了wqe的发送,然后更新cons_idx通知用户。
3.4.2 线程安全
对于qp和cq的线程安全都是用原子指令实现的,以对wqe的写入为例,是通过resv_head实现的,比如当前线程需要写入2个wqe,那么就对resv_head原子加2,那么当前线程就可以放心的写[old_resv_head, old_resv_head + 1]这两个位置了。
3.4.3 合并DB
对于db的写入时机,简单来讲当wq中积累的wqe数超过num_requests_in_batch时,就会触发一次写db。对于如何保证写db的时候,之前的线程对应的wqe已经完成写入,是通过ready_idx实现的,这里先有个大概印象,后续pollcq详细描述。
3.4.4 flush
只有get操作需要执行flush,对于同步的get操作,因为知道是get,所以直接在post_send之后执行pollcq + 执行flush即可。对于异步操作,执行quiet的时候不知道之前是否执行过get,因此ibgda引入了get_head和get_tail变量,get_head记录最新的get操作对应的位置,get_tail记录最新的flush操作对应的位置,那么执行quiet的时候,如果发现get_head > get_tail,那么说明有未执行flush的get,此时需要执行flush。
3.4.5 fetch amo
上述internal_buff除了第一个slot,后续的slot组成了一个环形队列,当用户执行一个fetch amo的时候,通过atomicadd更新ibuf.head预留一些slot作为fetch amo的输出,当执行quiet后,更新ibuf.tail。
3.5 数据收发流程实现
在不准确但是不影响理解的方式定性描述这几个问题的解决方法后,我们看下实际实现方式。
3.5.1 put / get
先以Hopper gpu scope为block的put_nbi为例介绍下整体流程,这些操作最后调用都会执行到ibgda_rma,dst_pe是对端的rank,proxy_pe可以忽略,等于dst_pe,bytes为数据长度,req_lptr为本地地址,req_rptr为对端地址。
template <threadgrp_t SCOPE, nvshmemi_op_t channel_op, bool nbi, bool support_half_av_seg>
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE void ibgda_rma(uint64_t req_rptr,uint64_t req_lptr,size_t bytes, int dst_pe,int proxy_pe) {const bool need_cst = (channel_op == NVSHMEMI_OP_GET) && !state->may_skip_cst;const bool need_immediate_cst = !nbi && need_cst;need_additional_wqe =need_immediate_cst ||((qp->qp_type == NVSHMEMI_IBGDA_DEVICE_QP_TYPE_DCI) && !support_half_av_seg);int my_tid = nvshmemi_thread_id_in_threadgroup<SCOPE>();int tg_size = nvshmemi_threadgroup_size<NVSHMEMI_THREADGROUP_WARP>();if (my_tid >= tg_size) {goto out; } my_tid = nvshmemi_thread_id_in_threadgroup<NVSHMEMI_THREADGROUP_WARP>();if (my_tid == 0) {qp = ibgda_get_qp(proxy_pe, (bool *)&is_qp_shared_among_ctas);}qp = (nvshmemi_ibgda_device_qp_t *)__shfl_sync(IBGDA_FULL_WARP, (uintptr_t)qp, 0);is_qp_shared_among_ctas = __shfl_sync(IBGDA_FULL_WARP, is_qp_shared_among_ctas, 0);
}
由于为Hopper,所以不需要flush,因此need_cst,need_immediate_cst,need_additional_wqe为0。
scope为block的场景只使用一个warp执行通信,my_tid为在blcok中的id,tg_size为一个warp的线程数,非warp0的线程直接退出。
重新计算my_tid,表示当前线程在warp的id。
tid[0]通过ibgda_get_rc选择出本次的qp,由于两个rank之间有多个qp,这里会根据用户指定的map_type进行轮询选择一个指定的qp,比如如果map_type为warp,就是根据warp_id进行hash选择,然后将qp地址通过__shfl_sync广播到整个warp。rc场景下is_qp_shared_among_ctas为true。
__device__ void ibgda_rma(...) {...while (remaining_size > 0) { ibgda_get_lkey(lptr, &lkey, &lchunk_size, &is_data_buf_in_sysmem, qp->dev_idx);ibgda_get_raddr_rkey(rptr, dst_pe, proxy_pe, &raddr, &rkey, &rchunk_size, qp->dev_idx);transfer_size = ibgda_cal_transfer_size(remaining_size, lchunk_size, rchunk_size);if (my_tid == chunk_idx) {my_lkey = lkey;my_laddr = lptr;my_rkey = rkey;my_raddr = raddr;my_transfer_size = transfer_size;} remaining_size -= transfer_size;rptr += transfer_size;lptr += transfer_size;++chunk_idx;} num_wqes = num_wqes_per_cmd * chunk_idx + (need_additional_wqe ? 1 : 0);if (my_tid == 0) {base_wqe_idx = ibgda_reserve_wqe_slots(qp, num_wqes, is_qp_shared_among_ctas);}...
}
由于heap中的地址按照chunk进行分配的,因此当laddr或者raddr跨越了chunk的时候,对应了不同的mr,这时候就需要一个新的wqe,如下图所示,虽然raddr在一个chunk中,但是由于laddr跨越了chunk,因此要拆分成两个wqe,tid[i]负责第i个wqe,此时num_wqes为2。

然后tid0通过ibgda_reserve_wqe_slots预留wq buff中长度为num_wqes的空间。就是通过对resv_head进行atomicAdd预留的空间。 ```cpp __device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE uint64_t ibgda_reserve_wqe_slots(nvshmemi_ibgda_device_qp_t *qp, unsigned long long int num_wqes, bool is_qp_shared_among_ctas) {nvshmemi_ibgda_device_qp_management_t *mvars = &qp->mvars;uint64_t wqe_idx;if (is_qp_shared_among_ctas)wqe_idx = atomicAdd((unsigned long long int *)&mvars->tx_wq.resv_head, num_wqes);ibgda_wait_for_slot_availability(qp, wqe_idx + num_wqes);return wqe_idx; } ``` 由于是wq buf是环形队列,预留的长度可能会覆盖到已有的位置,所以ibgda_wait_for_slot_availability会对覆盖的位置进行poll_cq,poll_cq的逻辑稍等再介绍,这里先跳过。
__device__ void ibgda_rma(...) {base_wqe_idx = __shfl_sync(IBGDA_FULL_WARP, base_wqe_idx, 0);my_wqe_idx = base_wqe_idx + (my_tid * num_wqes_per_cmd);// Generate CQE only if we create the last WQE in the group.fm_ce_se = (!need_additional_wqe && (my_tid == chunk_idx - 1)) ? MLX5_WQE_CTRL_CQ_UPDATE : 0;if (my_tid < chunk_idx) {wqe_ptrs[0] = ibgda_get_wqe_ptr(qp, my_wqe_idx);wqe_ptrs[1] = ibgda_get_wqe_ptr(qp, my_wqe_idx + 1);switch (channel_op) {case NVSHMEMI_OP_PUT:ibgda_write_rdma_write_wqe<support_half_av_seg>(qp, dct, my_laddr, my_lkey,my_raddr, my_rkey, my_transfer_size,my_wqe_idx, fm_ce_se, wqe_ptrs);break;case NVSHMEMI_OP_GET:ibgda_write_rdma_read_wqe<support_half_av_seg>(qp, dct, my_laddr, my_lkey, my_raddr,my_rkey, my_transfer_size,my_wqe_idx, fm_ce_se, wqe_ptrs);break;default:assert(0);}}
}
tid0将base_wqe_idx广播给warp的所有线程,然后每个线程通过ibgda_write_rdma_write_wqe填写write wqe。
__device__ void ibgda_rma(...) {nvshmemi_warp_sync();if (my_tid == chunk_idx - 1) {...if (is_qp_shared_among_ctas)ibgda_submit_requests<true>(qp, base_wqe_idx, num_wqes);if (!nbi) {ibgda_quiet(qp);}}
}
先执行一个warp的同步,然后通过ibgda_submit_requests尝试写db,这里可以看到nbi和非nbi的不同就是加不加ibgda_quiet执行poll cq,先看下如何写db。
template <bool need_strong_flush>
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE void ibgda_submit_requests(nvshmemi_ibgda_device_qp_t *qp, uint64_t base_wqe_idx, uint16_t num_wqes) {uint64_t mask = ~((uint64_t)(state->num_requests_in_batch - 1));uint64_t new_wqe_idx = base_wqe_idx + num_wqes;unsigned long long int *ready_idx =(unsigned long long int *)(state->use_async_postsend ? qp->tx_wq.prod_idx: &mvars->tx_wq.ready_head);// WQE writes must be finished first.if (need_strong_flush)// membar from a different CTA does not push prior writes of this CTA.// We must push them out first because a different CTA might post-send for us.IBGDA_MEMBAR_NO_OPTIMIZATION();else// It is ok for those wqes to not be visible to the GPU scope yet.// ibgda_post_send will take care of that (if we choose to call it).IBGDA_MFENCE();while (atomicCAS(ready_idx, (unsigned long long int)base_wqe_idx,(unsigned long long int)new_wqe_idx) != base_wqe_idx); // wait hereIBGDA_MFENCE();if (!state->use_async_postsend) {bool do_post_send =(new_wqe_idx ==ibgda_atomic_read(&mvars->tx_wq.resv_head)) // No concurrent submissions|| ((base_wqe_idx & mask) !=(new_wqe_idx & mask)) // Num of not-yet-posted wqes is beyond the threshold.|| (num_wqes >= state->num_requests_in_batch); // The number of wqes in this submission// reaches the threshold.if (do_post_send) ibgda_post_send<need_strong_flush>(qp, new_wqe_idx);}
}
因为写db的线程写db的时机是在看到ready_idx之后,因此写wqe和写ready_idx需要保序,因此需要通过fence
从这里可以看出ready_idx的作用了,如下图所示,一共有3个warp,warp[0]有4个线程写wqe,为黄色区域,同理warp[1]为蓝色,warp[2]为绿色,方框中写了"wqe"的表示写完成,空着的表示还没写完成。此时ready_idx为0,以蓝色线程视角为例,虽然蓝色线程已经完成了wqe的写入,但是会在atomicCAS处循环等待,所以无法尝试写db,要等到ready_idx为自己的base_wqe_idx,即4,才能继续执行。

在等到warp[0]的tid[1]完成了wqe的写入之后,warp[0]的tid[0]通过atomicCAS将ready_idx修改为4,如下图所示。此时warp[1]的tid[0]可以继续执行尝试写db的逻辑了。

因此ready_idx就是一个flag,表示之前的wqe都已经写完成,既然有flag,那就又引入了保序问题。 写db之前需要保证wqe都落盘,因此需要写db的线程需要在写db之前加fence,保证网卡读到db后wqe都可见。但是写db的线程和写wqe的线程可能来自甚至不同的block,因此每个写flag(即ready_idx)的warp,需要在写flag之前执行fence。 可以看到代码中如果是need_strong_fence,会执行IBGDA_MEMBAR_NO_OPTIMIZATION,和下边的IBGDA_MFENCE区别只是scope,IBGDA_MFENCE的scope为cta,IBGDA_MEMBAR_NO_OPTIMIZATION的scope为gpu。
// Prevent code reordering from both compiler and GPU
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE void IBGDA_MFENCE() {
#ifdef NVSHMEMI_IBGDA_PTX_OPTIMIZATION_MFENCEasm volatile("fence.acq_rel.cta;" ::: "memory");
#else__threadfence_block();
#endif /* NVSHMEMI_IBGDA_PTX_OPTIMIZATION_MFENCE */
}__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE void IBGDA_MEMBAR_NO_OPTIMIZATION() {
#ifdef NVSHMEM_IBGDA_SUPPORT_GPUMEM_ONLY__threadfence();
#elseif (likely(ibgda_get_state()->nic_buf_on_gpumem))__threadfence();else __threadfence_system();
#endif /* NVSHMEM_IBGDA_SUPPORT_GPUMEM_ONLY */
}
从这可以看出,网卡侧的保序不需要scope为system,gpu就可以,也是挺奇怪的。。
然后看尝试写db的逻辑,可以看出有三个条件:
- 如果resv_head等于new_wqe_idx,说明没有新的线程在执行写wqe的操作,所以这个时候自己必须写db,否则可能会hang
- 积攒的db超过了num_requests_in_batch
- 自己提交的wqe超过了num_requests_in_batch
然后看下写db的过程
template <bool need_strong_flush>
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE void ibgda_post_send(nvshmemi_ibgda_device_qp_t *qp, uint64_t new_prod_idx) {nvshmemi_ibgda_device_qp_management_t *mvars = &qp->mvars;uint64_t old_prod_idx;// Update prod_idx before ringing the db so that we know which index is needed in quiet/fence.ibgda_lock_acquire<NVSHMEMI_THREADGROUP_THREAD>(&mvars->post_send_lock);if (need_strong_flush) old_prod_idx = atomicMax((unsigned long long int *)&mvars->tx_wq.prod_idx,(unsigned long long int)new_prod_idx);elseold_prod_idx = atomicMax_block((unsigned long long int *)&mvars->tx_wq.prod_idx,(unsigned long long int)new_prod_idx);if (likely(new_prod_idx > old_prod_idx)) {IBGDA_MEMBAR();ibgda_update_dbr(qp, new_prod_idx);IBGDA_MEMBAR();ibgda_ring_db(qp, new_prod_idx);}ibgda_lock_release<NVSHMEMI_THREADGROUP_THREAD>(&mvars->post_send_lock);
}
从这里可以看到prod_idx和cons_idx的关系,如下图所示,绿色为空闲空间,或者是已完成wqe,黄色为未完成的wqe,pollcq后会更新cons_idx
通过atomicMax更新prod_idx,如果new_prod_idx比prod_idx大,就更新prod_idx,然后写dbr和db,第一个fence就是上述的保证网卡读到db后wqe都可见。
3.5.2 quiet
quiet在ibgda场景下就是poll cq,首先拿到最新的ready_head,即最新写的db值。
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE uint64_t
ibgda_quiet(nvshmemi_ibgda_device_qp_t *qp) {nvshmemi_ibgda_device_state_t *state = ibgda_get_state();uint64_t prod_idx = state->use_async_postsend ? ibgda_atomic_read(qp->tx_wq.prod_idx): ibgda_atomic_read(&qp->mvars.tx_wq.ready_head);nvshmemi_ibgda_device_cq_t cq = *qp->tx_wq.cq;int err = 0;int status = ibgda_poll_cq(&cq, prod_idx, &err);return prod_idx;
}
然后看下poll_cq的流程
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE int ibgda_poll_cq(nvshmemi_ibgda_device_cq_t *cq, uint64_t idx, int *error) {int status = 0;struct mlx5_cqe64 *cqe64 = (struct mlx5_cqe64 *)cq->cqe;const uint32_t ncqes = cq->ncqes; uint64_t cons_idx = ibgda_atomic_read(cq->cons_idx);uint64_t new_cons_idx; if (unlikely(cons_idx >= idx)) goto out;// If idx is a lot greater than cons_idx, we might get incorrect result due// to wqe_counter wraparound. We need to check prod_idx to be sure that idx// has already been submitted.while (unlikely(ibgda_atomic_read(cq->prod_idx) < idx))...
}
首先读取cons_idx,即已经完成的位置,如果cons_idx已经大于等于idx了,直接返回就好。
如果prod_idx小于idx,说明wqe还没下发,则需要等待wqe实际被下发。
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE int ibgda_poll_cq() {do {new_wqe_counter = ibgda_atomic_read(&cqe64->wqe_counter);new_wqe_counter = BSWAP16(new_wqe_counter);wqe_counter = new_wqe_counter;// Another thread may have updated cons_idx.cons_idx = ibgda_atomic_read(cq->cons_idx);if (likely(cons_idx >= idx)) goto out;}while (unlikely(((uint16_t)((uint16_t)idx - wqe_counter - (uint16_t)2) < ncqes)));// new_cons_idx is uint64_t but wqe_counter is uint16_t. Thus, we get the// MSB from idx. We also need to take care of wraparound.++wqe_counter;new_cons_idx =(idx & ~(0xffffULL) | wqe_counter) + (((uint16_t)idx > wqe_counter) ? 0x10000ULL : 0x0);atomicMax((unsigned long long int *)cq->cons_idx, (unsigned long long int)new_cons_idx);
}
然后开始循环判断,完成的条件有两个,一个是cqe的wqe_counter + 1 >= idx,说明已经上报了对应的cqe,第二个是其他线程执行pollcq更新了cons_idx,并且cons_idx >= idx,最后将wqe_counter + 1,并尝试更新到cons_idx,就完成了pollcq。
3.5.3 atomic
首先看下fetch的atomic,整体流程和rma非常类似。
template <typename T, bool support_half_av_seg>
__device__ NVSHMEMI_DEVICE_ALWAYS_INLINE T nvshmemi_ibgda_amo_fetch_impl(void *rptr, const T value,const T compare, int pe,nvshmemi_amo_t op) {if (my_tid == 0) {base_ibuf_idx = ibgda_reserve_ibuf_slots(qp, tg_size);base_wqe_idx = ibgda_reserve_wqe_slots(qp, num_wqes, is_qp_shared_among_ctas);}uint64_t my_wqe_idx = base_wqe_idx + (my_tid * num_wqes_per_cmd);uint64_t my_ibuf_idx = base_ibuf_idx + my_tid;uint64_t laddr = ibgda_get_ibuf_addr(qp, my_ibuf_idx);ibgda_write_atomic_wqe<support_half_av_seg>(qp, dct, &value, &compare, laddr, lkey, raddr, rkey,sizeof(T), my_wqe_idx, op, fm_ce_se, wqe_ptrs);if (my_tid == tg_size - 1) {ibgda_quiet(qp);}ret = READ_ONCE(*(T *)laddr);if (can_coalesce_warp) nvshmemi_warp_sync();if (my_tid == tg_size - 1) ibgda_release_ibuf(qp, base_ibuf_idx, tg_size);if (can_coalesce_warp) nvshmemi_warp_sync();return ret;
}
如上所述,fetch需要有返回值,利用的是internal_buf,所以tid[0]除了预留wqe空间,还需要预留internal_buf空间,和预留wqe一样,通过atomicAdd预留的,对于正在使用的slot,需要通过while循环等待释放。can_coalesce_warp表示是否一个warp的线程都在同时执行这个函数,并且peer一样,这里比较奇怪的是如果can_coalesce_warp为1,那么internal_buf只需要预留一个就行,而不是32个,不过影响不大。
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE uint64_t
ibgda_reserve_ibuf_slots(nvshmemi_ibgda_device_qp_t *qp, unsigned long long int num_slots) {nvshmemi_ibgda_device_qp_management_t *mvars = &qp->mvars;uint32_t nslots = qp->ibuf.nslots;uint64_t base_idx = atomicAdd((unsigned long long int *)&mvars->ibuf.head, num_slots);uint64_t idx = base_idx + num_slots;// Wait until the slots become available.while (idx - ibgda_atomic_read(&mvars->ibuf.tail) > nslots);// Prevent the reordering of the above wait loop.IBGDA_MFENCE();return base_idx;
}
然后通过ibgda_write_atomic_wqe写wqe,然后pollcq,从laddr读到返回值,释放inernal_buf。
non_fetch的逻辑类似,唯一的区别就是固定使用internal_buf的第0个slot。
3.5.4 cst
nvshmem对flush的实现很有趣,以get的rma为例,在执行完write wqe之后会写一个dump wqe,但由于这个wqe并没有通过umr配置signature,所以只会读一下位于gpu的ibuf,达到flush的效果。
__device__ NVSHMEMI_STATIC NVSHMEMI_DEVICE_ALWAYS_INLINE void ibgda_rma() {if (my_tid == tg_size - 1) {if (need_immediate_cst) {// Enqueue CST op in the QP. This command has NIC Fence, which// waits for all prior READ/ATOMIC to finish before issuing this// DUMP.my_wqe_idx += num_wqes_per_cmd;wqe_ptrs[0] = ibgda_get_wqe_ptr(qp, my_wqe_idx);ibgda_write_dump_wqe(qp, (uint64_t)qp->ibuf.buf, qp->ibuf.lkey, sizeof(char),my_wqe_idx, IBGDA_MLX5_FM_FENCE, wqe_ptrs);} ...}
}
参考
https://developer.nvidia.com/blog/improving-network-performance-of-hpc-systems-using-nvidia-magnum-io-nvshmem-and-gpudirect-async/
https://docs.nvidia.com/nvshmem/api/index.html