C++线程池学习 Day06
任务:延续昨天的内容,理解内存序
内存序 std::memory_order
你和你的朋友(代表不同的CPU线程)在合作完成一个巨大的拼图。你们之间隔着一堵墙,只能通过一个小窗口传递拼图块(这代表线程间通信开销很大)
1.默认情况(std::memory_order_seq_cst):每当你拼上一块拼图,你就必须立刻走到窗口前,对你的朋友大声说:“我刚刚拼上了A块!”。然后你才能回去拼下一块。这样做的结果很明确,这使得你们对任务的进度有完全一致的认知,但效率低下,因为大部分时间都花在通知上
2.宽松模式(std::memory_order_relaxed):你只管埋头拼命拼图。只有当你手头所有拼图块用完了,或者完成了一大片区域,你才会走到窗口前说:“我拼了很多,具体哪些我也记不清了,你自己看吧!“。这样效率极高,但是你的朋友根本不知道你拼图的顺序,它对进度的认知可能是混乱的
3.释放-获取模式(std::memory_order_release/acquire):你拼好了一块非常关键的中心块(释放操作),拿着这块中心块走到窗口前说:“注意,在我交出这块中心块之前,我完成的所有拼图(例如一片蓝色的天空)都是有效的!”。然后你的朋友接过中心块(获取操作),他听到你的话后就明白了:”既然我拿到了这块中心块,那我就确信他刚才说的那片蓝色天空一定拼好了。“这种方式在关键点上同步,在其它地方则保持高效,是一种聪明的合作方式
在这个比喻中:
”拼图块“就是普通的内存读写操作
”走到窗口前说话“就是一个原子操作
”说话的内容和方式“就是内存序。它定义了这次沟通要传递多少信息、保证什么样的顺序
再举一个例子:假设我们有两个变量:一个普通变量data(装着重要答案)和一个原子变量flag(作为发布信号的哨兵)
// 线程 1: 生产者/发布者
data = 42; // (1) 准备答案,这是一个普通写操作
flag.store(true, std::memory_order_release); // (2) RELEASE操作:发布信号!昨天说过,编译器会对我们写的代码进行优化。如果没有std::memory_order_release,编译器或CPU可能会觉得:我先执行(2),再执行(1)也没关系啊,反正逻辑不变,说不定还会更快呢?于是进行了代码重排。如果在多线程环境下,这是危险的。如果另一个线程在flag变成true时来读data,它可能会读到陈旧的、错误的data
有了std::memory_order_release,相当于对编译器和CPU下了一个严格的命令:不管怎么优化,必须保证操作(1)的效果在操作(2)之前完成!
我们再看它的另一半:Acquire
// 线程 2: 消费者/获取者
if (flag.load(std::memory_order_acquire)) { // (3) ACQUIRE操作:检查信号print(data); // (4) 使用答案
}std::memory_order_acquire保证acquire操作之后的所有内存操作,不会被重排到它之前
也就是说,(4)一定不会被重排到操作(3)之前执行
现在,我们把两个线程的代码结合起来看
线程1:data写入->release存储flag
线程2:acquire加载flag->data读取
当线程2通过acquire加载flag并看到它的值为true,即线程1的release存储已经完成时,这两个内存序之间就建立了一个同步关系。就好比上面的拼图比喻,当对方接收到你给的中心块时,你们对整个任务的进度的认知是同步的
即,线程1在release操作之前所做的所有事情,其结果对线程2在acquire操作之后的所有操作都是可见的。更具体地说,线程2不需要亲眼去看着线程1完成任务,因为它相信,只要flag为true,那么线程1的任务就必然完成了。所谓的可见性就是,线程2发现flag为true,它就知道线程1的工作做完了,本质是认知同步。这种信任是由内存序的规则背书的。
所以内存序是什么?它是一个规则,让你可以精确控制原子操作周围的其它内存操作(读、写)的顺序和可见性,让你能够与编译器和CPU进行对话,告诉它们这个位置是否需要严格的顺序(seq_cst),或者这个位置的顺序无所谓,可以随便优化(relaxed)
内存序通过规定 操作的执行顺序,要求在关键点必须进行同步。为了在硬件层面实现这些同步,CPU必须执行缓存一致性操作(如使缓存失效、刷写内存),从而解决了缓存不一致的问题,进而保证了一个线程的修改都能够被另一个线程知道。所谓的可见性,本质上就是通过内存序触发CPU执行缓存一致性操作后的结果,是通过确保缓存一致实现的。
再用一个比喻理解:
科学家A规定:“在我发布胜利宣言(flag.store(true,release))之前,我必须把我的发现正式提交到中央档案库(刷新缓存),并通知其它科学家,他们笔记本上关于这个定理的记录已经作废(缓存失效)。”
科学家B也规定:“在我看到胜利宣言之后,我必须从中央档案库获取最新资料,确保我的认知是最新的(认知同步)。”
接下来看一下六个内存序
1️⃣std::memory_order_relaxed(宽松)
昨天说过,它只保证自己的操作本身是原子的,不保证该操作之前或之后的任何其它内存操作的顺序
也就是说,如果对于原子变量flag,我们执行:
flag.store(true,std::memory_order_relaxed);它唯一的作用就是保证了flag=true这条语句被原子地执行。由Day02的总结,我们知道flag=true并不是一个原子操作。加上std::memory_order_relaxed后,它能保证这条语句被原子地执行
至于它的上下文是否会重排到它的前面或者后面,它并不关心。
用一个具体的例子加深理解:
int data = 0;
std::atomic<int> counter(0);
void thread1() {data = 42; // (1) 普通写操作counter.store(1, std::memory_order_relaxed); // (2) relaxed存储int b = data; // (3) 普通读操作
}对于线程thread1自己来说,它永远会看到b=42
但是对于其它观察者(其它线程)来说,他们看到的顺序可能是混乱的
可能的情况1:编译器/CPU先执行2,再执行1
counter.store(1, std::memory_order_relaxed); // (2) 先发生
data = 42; // (1) 后发生
int b = data; // (3)可能的情况2:
int b = data; // (3) 先发生(读到旧值0)
counter.store(1, std::memory_order_relaxed); // (2)
data = 42; // (1)std::memory_order_relaxed允许所有这些可能的重排。它只关心自己的counter.store操作原子地完成了
2️⃣std::memory_order_seq_cst(顺序一致性)
它保证了全局顺序一致性:所有线程看到的所有seq_cst操作的顺序都是一致的。即,对于两个seq_cst操作A和B,所有线程对于A和B谁先执行有统一的认知
它隐式地包含了acquire和release的语义:
seq_cst_load≈acquire_load+参与全局排序
seq_cst_store≈release_store+参与全局排序
怎么理解它隐式包含了acquire和release的语义?
seq_cst和acquire一样,在自己所在的线程中,确保在自己之后的必然在自己之后执行
seq_cst和release一样,在自己所在的线程中,确保在自己之前的必然在自己之前执行
比如说在线程1中,seq_cst语句A写在了seq_cst语句B前面,那么它保证了先A后B。在线程2中用同样的方法保证了先C后D。但是从全局来看,A与C和D的先后是不确定的,B与C和D的先后也是不确定的。
可能的顺序有几种?这就变成了一个排列问题了:ABCD四人排队,其中A在B前面,C在D前面,有几种排法?答案是
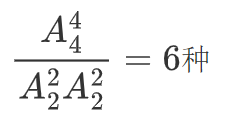
但是最终只会选择一种排法,并且所有线程都达成了ABCD四个线程就应该这么排的共识
3️⃣std::memory_order_release
4️⃣std::memory_order_acquire
这两个不再赘述,要配对使用才能发挥效果。release用于store,保证在我之前的必然在我之前执行,acquire用于load,保证在我之后的必然在我之后执行。这是构建线程同步的黄金组合
5️⃣std::memory_order_acq_rel
顾名思义,是acquire和release的结合体,用于Read-Modify-Write(RMW)操作(如昨天的fetch_add)
对于RMW操作之后的内存操作,保证它必然在后面执行
对于RMW操作之前的内存操作,保证它必然在前面执行
6️⃣std::memory_order_consume
c++20已经弃用,一般使用acquire替代它