力扣刷题笔记(1)--面试150数组部分
这些题目是力扣150中的内容,题目的代码是我想出或者根据题解思路复现的。里面的一些方法和技巧,是我根据自己做题中的一些不懂或者不熟练的内容,让AI生成的总结技巧。这个教程适合对于go语言有一定使用或者纯新手的快速了解go语言算法题的技巧和特性,如果你可以看完,我相信你对数组和切片这部分的大多数算法一定有了不错的了解(没有针对解法做一个总结,因为我觉得如果刷或者浏览一部分题目之后,看到某些特征就有一定的基础思路,看到复杂度就会有一定的优化想法)。如果有不足或者需要改进的地方,欢迎大家在评论区批评指正。
后续的150内容我立一个flag在这周之内出完,希望大家可以多多支持。
合并两个有序数组(9.15.1)
方法1 追加之后排序
这个方法针对无序数组也可以使用
func merge(nums1 []int, m int, nums2 []int, n int) {//使用数组处理方法直接处理copy(nums1[m:],nums2)//追加切片sort.Ints(nums1)//对整形数组的排序方法
}
方法2 双指针法
func merge(nums1 []int, m int, nums2 []int, n int) {//创建结果数组并且进行赋值result := make([]int,0,m+n)//创建左右指针p1 := 0p2 := 0//赋值for {//防止nums中有空切片 并且顺带可以简化for循环if p1==m{result=append(result,nums2[p2:]...)break}if p2==n{result=append(result,nums1[p1:]...)break} if nums1[p1]>=nums2[p2]{result = append(result,nums2[p2])p2++continue}else{result = append(result,nums1[p1])p1++continue}}copy(nums1,result)
}
注意
result := make([]int,m+n)//这样写再加上append方法,会造成前面m+n个元素全为0
知识点
make方法
make 是 Go 语言中用于初始化内建引用类型(slice、map、channel) 的函数,它分配内存并初始化相应的数据结构,返回的是类型本身(而不是指针)。
用于切片 (Slice) - 力扣最常用
切片是动态数组,是解决数组类题目的核心数据结构。
语法:
// 语法1: 指定长度和容量
slice := make([]T, length, capacity)// 语法2: 省略容量,则长度 == 容量
slice := make([]T, length)
T: 切片元素的类型 (如int,string,byte)length: 切片的当前长度(已有元素个数)capacity: 切片的总容量(底层数组能容纳的元素个数)
力扣实战技巧:
-
预分配内存以避免频繁扩容:这是最重要的性能优化点。如果你能预估结果切片的大致大小,使用
make预先分配足够的capacity可以避免append操作时底层数组的多次重新分配和拷贝,极大提升性能。- 例子 (力扣 509. 斐波那契数):你知道要计算前 N 个斐波那契数。
func fib(n int) int {if n <= 1 {return n}// 预分配一个长度为 n+1 的切片,避免后续 append 的扩容开销dp := make([]int, n+1)dp[0], dp[1] = 0, 1for i := 2; i <= n; i++ {dp[i] = dp[i-1] + dp[i-2]}return dp[n] }
- 例子 (力扣 509. 斐波那契数):你知道要计算前 N 个斐波那契数。
-
创建空切片但有容量:当你需要一个初始为空的切片,但又知道即将添加大量元素时。
- 例子:收集二叉树遍历的结果。
// 假设你知道树节点大约有1000个 result := make([]int, 0, 1000) // 然后使用 result = append(result, value) 添加元素,效率极高
- 例子:收集二叉树遍历的结果。
-
创建具有初始长度的切片:当你需要直接通过索引
dp[i]赋值,而不是使用append时,必须指定足够的length。- 动态规划 (DP) 问题:几乎所有的 DP 题都需要先创建一个
dp数组(切片)。// 力扣 70. 爬楼梯 func climbStairs(n int) int {if n <= 2 {return n}dp := make([]int, n+1) // 创建长度为 n+1 的切片dp[1] = 1dp[2] = 2for i := 3; i <= n; i++ {dp[i] = dp[i-1] + dp[i-2] // 直接按索引赋值}return dp[n] }
- 动态规划 (DP) 问题:几乎所有的 DP 题都需要先创建一个
用于映射 (Map) - 也很常用
Map 用于存储键值对,解决需要快速查找、计数的题目。
语法:
m := make(map[KeyType]ValueType)
m := make(map[KeyType]ValueType, initialCapacity) // 推荐指定初始容量
initialCapacity: 提示 Go 运行时预先分配大约能存储initialCapacity个元素的空间。虽然不是严格的限制,但指定一个合理的值可以避免初期的内存重整,提升性能。
力扣实战技巧:
-
用于计数:统计元素出现的频率。
- 例子 (力扣 1. 两数之和):虽然最优解是一遍哈希,但也能体现 map 的创建。
func twoSum(nums []int, target int) []int {// 创建一个map,key是数字,value是索引numMap := make(map[int]int, len(nums)) // 建议指定容量为nums的长度for i, num := range nums {complement := target - numif idx, ok := numMap[complement]; ok {return []int{idx, i}}numMap[num] = i}return nil }
- 例子 (力扣 1. 两数之和):虽然最优解是一遍哈希,但也能体现 map 的创建。
-
用于记录状态:记录访问过的节点或状态,避免重复处理(如图的遍历、回溯算法)。
- 例子:克隆图(力扣 133)、避免回溯中的重复选择。
用于通道 (Channel) - 并发题目中使用
Channel 用于 goroutine 之间的通信,在并发类的题目中可能会用到。
语法:
ch := make(chan T) // 无缓冲通道
ch := make(chan T, n) // 带缓冲通道,缓冲区大小为 n
- 在力扣的算法题中,单纯使用 channel 的情况较少,除非题目明确要求并发。
总结与对比 (make vs new)
| 特性 | make | new |
|---|---|---|
| 适用类型 | 仅用于内建引用类型:slice, map, channel | 用于任何类型(包括值类型和自定义结构体) |
| 返回值 | 类型 T 本身 (e.g., []int, map[int]int) | 指向该类型的指针 (*T) |
| 初始化 | 会初始化内存(置零值),并设置好内部数据结构(如 slice 的 len/cap) | 只分配内存,并将内存置为零值(nil for references, 0 for numbers, "" for strings),返回指向这块零值内存的指针 |
错误示例:
var s *[]int = new([]int) // s 现在是一个指向 nil 切片的指针
*s = make([]int, 10) // 必须这样使用:先 new 出一个指针,再让指针指向 make 出来的切片
// 通常我们直接写更简单: s := make([]int, 10)
力扣题刷技巧
- 看到数组、字符串、动态规划题:第一反应想到
make([]T, len, cap)来创建你的切片(DP 表、结果集)。 - 看到需要查找、去重、计数的题:第一反应想到
make(map[K]V)来创建你的映射。 - 养成预分配容量的习惯:在知道或能估算数据规模时,始终为
make函数指定capacity参数。这是一个简单且有效的性能优化手段,能让你的解法跑得更快。
append方法
追加单个元素
numbers := []int{1, 2, 3}
numbers = append(numbers, 4) // [1, 2, 3, 4]
追加多个元素
numbers := []int{1, 2, 3}
numbers = append(numbers, 4, 5, 6) // [1, 2, 3, 4, 5, 6]
追加另一个切片
slice1 := []int{1, 2, 3}
slice2 := []int{4, 5, 6}
slice1 = append(slice1, slice2...) // [1, 2, 3, 4, 5, 6]
下面内容了解一下即可
重要特性
-
自动扩容:当切片容量不足时,
append会自动分配一个新的底层数组,通常是原容量的2倍(当长度小于1024时)。 -
返回值:
append总是返回一个新的切片,必须将返回值赋给原切片变量。 -
零值切片:可以向
nil切片追加元素:var s []int s = append(s, 1) // [1]
性能考虑
-
频繁的
append操作可能导致多次内存分配和复制 -
如果知道最终大小,可以预先分配容量:
s := make([]int, 0, 100) // 长度为0,容量为100
常见错误
s := []int{1, 2, 3}
_ = append(s, 4) // 错误:没有使用返回值
// s 仍然是 [1, 2, 3]
append 是 Go 中处理动态数组增长的主要方式,理解它的工作原理对于编写高效的 Go 代码非常重要。
copy方法
copy 是 Go 语言中用于复制切片内容的内置函数,常用于将一个切片的内容复制到另一个切片中。
copy(dst, src []T) int
- 返回实际复制的元素个数(取 dst 和 src 长度的较小值)
用法
nums1 := make([]int, 10) // 假设 nums1 有足够容量
nums2 := []int{4, 5, 6}
m := 5 // 从 nums1 的第 m 个位置开始复制n := copy(nums1[m:], nums2) // 将 nums2 复制到 nums1[m:] 的位置
// n 是实际复制的元素数
以下内容了解一下即可
- 不会自动扩容,目标切片必须有足够空间
- 可以部分复制(取决于目标切片的剩余空间)
- 常用于合并切片或覆盖切片部分内容
示例:合并两个有序切片
nums1 := make([]int, len(nums1Original)+len(nums2)
copy(nums1, nums1Original)
copy(nums1[len(nums1Original):], nums2)
sort包
sort 包是 Go 标准库中用于排序和搜索的包,提供了对切片和用户定义集合进行排序的功能。
基本类型排序方法
- 整型排序
func Ints(x []int) // 对 int 切片进行升序排序
func IntsAreSorted(x []int) bool // 检查 int 切片是否已排序sort.Ints(nums)//升序
sort.Sort(sort.Reverse(sort.IntSlice(nums)))//降序
- 浮点数排序
func Float64s(x []float64) // 对 float64 切片进行升序排序
func Float64sAreSorted(x []float64) bool // 检查 float64 切片是否已排序
- 字符串排序
func Strings(x []string) // 对 string 切片进行升序排序(按字典序)
func StringsAreSorted(x []string) bool // 检查 string 切片是否已排序
通用排序接口
- Slice 排序 (Go 1.8+)
func Slice(x interface{}, less func(i, j int) bool) // 根据 less 函数对切片排序
func SliceStable(x interface{}, less func(i, j int) bool) // 稳定排序
func SliceIsSorted(x interface{}, less func(i, j int) bool) bool // 检查是否已排序
- 自定义排序接口
type Interface interface {Len() intLess(i, j int) boolSwap(i, j int)
}
func Sort(data Interface) // 排序
func Stable(data Interface) // 稳定排序
func IsSorted(data Interface) bool // 检查是否已排序
搜索方法
func SearchInts(a []int, x int) int // 在已排序的 int 切片中搜索 x
func SearchFloat64s(a []float64, x float64) int // 在已排序的 float64 切片中搜索
func SearchStrings(a []string, x string) int // 在已排序的 string 切片中搜索
func Search(n int, f func(int) bool) int // 通用二分搜索
逆序排序
Go 1.21+ 引入了新的逆序排序方式:
// 对整型切片降序排序
sort.Sort(sort.Reverse(sort.IntSlice(nums)))// Go 1.21+ 更简洁的方式
slices.SortFunc(nums, func(a, b int) int {return b - a // 降序排序
})
实用示例
- 自定义结构体排序
type Person struct {Name stringAge int
}people := []Person{{"Alice", 25},{"Bob", 20},
}// 按年龄排序
sort.Slice(people, func(i, j int) bool {return people[i].Age < people[j].Age
})
- 搜索示例
nums := []int{1, 3, 5, 7, 9}
x := 5
pos := sort.SearchInts(nums, x) // 返回 2
- 检查切片是否已排序
if sort.IntsAreSorted(nums) {fmt.Println("切片已排序")
}
性能提示
- 对于基本类型,优先使用
sort.Ints等特定函数,它们比通用sort.Slice更快 - 需要保持相等元素原始顺序时,使用
Stable系列方法 - 对大型数据集,考虑使用
sort.Slice而非实现sort.Interface接口,代码更简洁 sort包提供了强大而灵活的排序功能,是 Go 语言中处理有序数据的核心工具之一。
移除元素(9.15.2)
方法1:前后指针法
func removeElement(nums []int, val int) int {//创建前后指针以及最终元素个数的记录follow := 0result := 0for front,_ := range nums{if nums[front] != val{nums[follow]=nums[front]result++front++follow++}else{front++}}return result
}
知识点
快慢指针写法
func removeElement(nums []int, val int) int {slow := 0 // 慢指针,指向下一个要放置非val元素的位置for fast := 0; fast < len(nums); fast++ {if nums[fast] != val {nums[slow] = nums[fast]slow++}}return slow
}
range方法
好的!为您总结Go语言range方法在力扣题目中的使用要点,特别针对算法题目的特点:
for index, value := range collection {// 循环体
}
数组/切片(最常用)
nums := []int{1, 2, 3, 4, 5}// 方式1:获取索引和值(推荐)
for i, num := range nums {fmt.Printf("nums[%d] = %d\n", i, num)
}// 方式2:只获取值
for _, num := range nums {fmt.Printf("值: %d\n", num)
}// 方式3:只获取索引
for i := range nums {fmt.Printf("索引: %d, 值: %d\n", i, nums[i])
}
字符串(字符遍历)
s := "hello"// 遍历字符串(按rune遍历,支持中文)
for i, char := range s {fmt.Printf("位置%d: %c (Unicode: %U)\n", i, char, char)
}
Map(无序遍历)
m := map[string]int{"a": 1, "b": 2, "c": 3}// 遍历map(顺序随机)
for key, value := range m {fmt.Printf("%s: %d\n", key, value)
}
力扣题目中的实用技巧
-
原地修改数组
// 错误:修改的是副本,不影响原数组 for _, num := range nums {num = num * 2 // 无效! }// 正确:通过索引修改原数组 for i := range nums {nums[i] = nums[i] * 2 // 有效! } -
双指针技巧中的range
func twoSum(nums []int, target int) []int {// 使用range遍历,配合map快速查找seen := make(map[int]int)for i, num := range nums {complement := target - numif idx, exists := seen[complement]; exists {return []int{idx, i}}seen[num] = i}return nil } -
字符串处理
func countCharacters(s string) int {count := 0for _, char := range s {if char != ' ' {count++}}return count } -
矩阵遍历(二维数组)
matrix := [][]int{{1,2,3}, {4,5,6}, {7,8,9}}// 遍历二维数组 for i, row := range matrix {for j, value := range row {fmt.Printf("matrix[%d][%d] = %d\n", i, j, value)} }
常见陷阱与注意事项
-
值拷贝问题
nums := []int{1, 2, 3} for _, num := range nums {num++ // 这只是修改副本,原数组不变! } // nums仍然是[1, 2, 3] -
性能考虑
// 对于大数组,直接使用索引可能更快 bigArray := make([]int, 1000000)// 较慢:每次迭代都有值拷贝 for _, value := range bigArray {_ = value }// 较快:直接通过索引访问 for i := range bigArray {_ = bigArray[i] } -
边界情况处理
// 空数组/切片不会panic var empty []int for i, num := range empty {fmt.Println(i, num) // 不会执行 }// nil切片也不会panic var nilSlice []int = nil for i, num := range nilSlice {fmt.Println(i, num) // 不会执行 }
力扣实战示例
-
移除元素
func removeElement(nums []int, val int) int {slow := 0// 使用range遍历,但通过索引修改原数组for _, num := range nums {if num != val {nums[slow] = numslow++}}return slow } -
反转字符串
func reverseString(s []byte) {// 使用range获取索引,进行双指针交换for i := range s[:len(s)/2] {j := len(s) - 1 - is[i], s[j] = s[j], s[i]} } -
寻找重复元素
func findDuplicate(nums []int) int {seen := make(map[int]bool)for _, num := range nums {if seen[num] {return num}seen[num] = true}return -1 }
总结
- 优先使用索引:在需要修改原数组时,使用
for i := range形式 - 值遍历只读:
for _, value := range中的value是副本,不能修改原数据 - map遍历无序:不要依赖map的遍历顺序
- 性能敏感时:大数组考虑直接使用索引访问
- 安全遍历:range对nil和空集合是安全的
(须回看)删除有序数组中的重复项(9.15.3)
快慢指针法
func removeDuplicates(nums []int) int {//异常情况length:=len(nums)if length == 0{return 0}//慢指针slow := 0//快指针起始遍历for fast:=1;fast<length;fast++{if nums[fast]!=nums[slow]{slow++nums[slow]=nums[fast]}}return slow+1
}
注意1
下面这段代码存在问题:
对于输入 [1,1,2],当 fast = 1(指向第二个1)时:
nums[fast] == nums[fast+1]→1 == 2→ false- 进入
else分支:fast++→fast = 2 - 现在
fast = 2,但数组长度是3(索引0,1,2) - 下一次循环:
if fast == length-1→2 == 2,应该跳出循环
但是,如果数组是 [1,1,1]:
- 内层循环会一直
fast++,直到fast = 2 - 然后检查
nums[2] != nums[3]→ 访问nums[3]导致越界
func removeDuplicates(nums []int) int {//慢指针fast,slow := 0,0length := len(nums)for {//弹出条件if fast == length-1{break}if nums[fast]==nums[fast+1]{for{if nums[fast]!=nums[fast+1]{break}fast++}fast++slow++nums[slow]=nums[fast]}else{fast++slow++nums[slow]=nums[fast]}}return slow+1
}
注意2
return slow++ // 错误!
- 语法错误:Go 的
return语句不能包含表达式,只能返回值 - 逻辑错误:即使语法正确,
slow++是后置自增,会先返回slow的值,然后再自增
因此要写成:
return slow+1
哈希表(如果不是非严格递增就要用到)
基本操作
// 创建哈希表
m := make(map[keyType]valueType)// 字面量初始化
m := map[string]int{"a": 1, "b": 2}// 基本操作
m["key"] = value // 插入/更新
value := m["key"] // 读取
delete(m, "key") // 删除
len(m) // 获取大小
力扣常用哈希表模式
频率统计(最常用)
// 统计元素频率
func countFrequency(nums []int) map[int]int {freq := make(map[int]int)for _, num := range nums {freq[num]++}return freq
}// 字符串字符统计
func charCount(s string) map[rune]int {count := make(map[rune]int)for _, char := range s {count[char]++}return count
}
快速查找存在性
// 检查重复元素
func hasDuplicate(nums []int) bool {seen := make(map[int]bool)for _, num := range nums {if seen[num] {return true}seen[num] = true}return false
}// 两数之和(经典题目)
func twoSum(nums []int, target int) []int {indexMap := make(map[int]int)for i, num := range nums {complement := target - numif idx, exists := indexMap[complement]; exists {return []int{idx, i}}indexMap[num] = i}return nil
}
分组归类
// 按某种规则分组
func groupAnagrams(strs []string) [][]string {groups := make(map[string][]string)for _, str := range strs {key := sortString(str) // 对字符串排序作为keygroups[key] = append(groups[key], str)}result := make([][]string, 0, len(groups))for _, group := range groups {result = append(result, group)}return result
}
高级使用技巧
存在性检查的两种方式
m := map[string]int{"a": 1}// 方式1:使用双返回值(推荐)
if value, exists := m["key"]; exists {// key存在
} else {// key不存在
}// 方式2:使用零值特性(小心陷阱)
value := m["key"] // 不存在的key返回零值
if value != 0 { // 如果0是有效值,这会出错!// ...
}
默认值处理
// 安全的计数器模式
func safeIncrement(m map[string]int, key string) {if _, exists := m[key]; !exists {m[key] = 0 // 初始化}m[key]++
}// 或者使用一行代码
m[key] = m[key] + 1 // 如果key不存在,m[key]返回0
遍历技巧
m := map[int]string{1: "a", 2: "b", 3: "c"}// 遍历键值对(顺序随机!)
for key, value := range m {fmt.Printf("%d: %s\n", key, value)
}// 只遍历键
for key := range m {fmt.Println(key)
}// 只遍历值
for _, value := range m {fmt.Println(value)
}
常见陷阱与注意事项
并发安全问题
// 错误:并发读写map
go func() { m["a"] = 1 }()
go func() { _ = m["a"] }() // 可能panic!// 解决方案:使用sync.Map或互斥锁
var mu sync.Mutex
mu.Lock()
m["a"] = 1
mu.Unlock()
引用类型陷阱
// map的值是引用类型时要注意
m := make(map[string][]int)
m["key"] = append(m["key"], 1) // 需要先初始化// 正确做法
if m["key"] == nil {m["key"] = make([]int, 0)
}
m["key"] = append(m["key"], 1)
性能优化
// 预分配空间提高性能
// 如果你知道大概的大小:
m := make(map[int]int, 1000) // 预分配1000个元素的容量// 避免频繁的map访问
value := m[key] // 一次访问
if value > 0 { // 使用局部变量// ...
}
// 而不是重复 m[key] > 0
力扣实战示例
有效的字母异位词
func isAnagram(s string, t string) bool {if len(s) != len(t) {return false}count := make(map[rune]int)for _, char := range s {count[char]++}for _, char := range t {count[char]--if count[char] < 0 {return false}}return true
}
示例2:最长连续序列
func longestConsecutive(nums []int) int {numSet := make(map[int]bool)for _, num := range nums {numSet[num] = true}longest := 0for num := range numSet {// 只从序列的起点开始计算if !numSet[num-1] {currentNum := numcurrentStreak := 1for numSet[currentNum+1] {currentNum++currentStreak++}if currentStreak > longest {longest = currentStreak}}}return longest
}
字母异位词分组
func groupAnagrams(strs []string) [][]string {groups := make(map[string][]string)for _, str := range strs {// 将字符串转换为字符数组并排序chars := []rune(str)sort.Slice(chars, func(i, j int) bool {return chars[i] < chars[j]})key := string(chars)groups[key] = append(groups[key], str)}result := make([][]string, 0, len(groups))for _, group := range groups {result = append(result, group)}return result
}
总结要点
- 首选数据结构:需要快速查找、去重、计数时优先考虑哈希表
- 存在性检查:使用
value, exists := m[key]模式 - 频率统计:
m[key]++是最常用的模式 - 预分配空间:使用
make(map[K]V, capacity)提高性能 - 注意并发:map不是并发安全的,需要加锁
- 遍历无序:不要依赖map的遍历顺序
- 零值特性:利用好零值,但要小心陷阱
(需回看)删除有序数组中的重复项 II(9.15.4)
快慢指针法
这道题可以类比上一道题,区别在于长度,因此对于异常判断、初始位置、前后指针的相差距离这些要做一些改动。直接看的题解默写的,真不知道这思路是怎么想出来的,我感觉启发就是确定好slow和fast的锚定与探索作用,而不是上来就根据实例进行推断
func removeDuplicates(nums []int) int {length:=len(nums)//如果长度小于等于2,不需要进行任何处理就是正确结果if length<=2{return length}//设置快慢指针 但是起始位置slow, fast := 2, 2for fast < length{if nums[slow-2]!=nums[fast]{nums[slow] = nums[fast]slow++}fast++}return slow
}
for循环的使用技巧
好的!为您全面总结Go语言中for循环在力扣题目中的使用要点和技巧:
for循环的四种基本形式
1. 传统三段式(最常用)
for 初始化; 条件; 后置操作 {// 循环体
}
示例:
for i := 0; i < 5; i++ {fmt.Println(i) // 输出: 0,1,2,3,4
}
2. while风格(条件循环)
for 条件 {// 循环体
}
示例:
count := 5
for count > 0 {fmt.Println(count) // 输出: 5,4,3,2,1count--
}
3. 无限循环
for {// 循环体,需要break退出if 退出条件 {break}
}
示例:
for {fmt.Println("循环中...")time.Sleep(1 * time.Second)break // 实际使用时需要合理的退出条件
}
4. range循环(遍历集合)
for 索引, 值 := range 集合 {// 循环体
}
示例:
nums := []int{1, 2, 3}
for i, num := range nums {fmt.Printf("索引:%d, 值:%d\n", i, num)
}
力扣常用for循环模式
1. 数组/切片遍历
// 方式1:使用range(只读场景)
for i, num := range nums {// i: 索引, num: 值(副本)
}// 方式2:使用索引(需要修改原数组)
for i := 0; i < len(nums); i++ {nums[i] = nums[i] * 2 // 修改原数组
}// 方式3:从特定位置开始
for i := 1; i < len(nums); i++ { // 从第2个元素开始// ...
}
2. 双指针技巧
// 左右指针
left, right := 0, len(nums)-1
for left < right {// 处理逻辑left++right--
}// 快慢指针
slow, fast := 0, 0
for fast < len(nums) {if 条件 {nums[slow] = nums[fast]slow++}fast++
}
3. 矩阵遍历
// 二维数组遍历
matrix := [][]int{{1,2,3}, {4,5,6}}
for i := 0; i < len(matrix); i++ {for j := 0; j < len(matrix[i]); j++ {fmt.Print(matrix[i][j], " ")}fmt.Println()
}// 螺旋矩阵遍历
top, bottom, left, right := 0, len(matrix)-1, 0, len(matrix[0])-1
for top <= bottom && left <= right {// 遍历四个方向
}
4. 链表操作
// 链表遍历
for curr != nil {// 处理当前节点curr = curr.Next
}// 寻找链表中点
slow, fast := head, head
for fast != nil && fast.Next != nil {slow = slow.Nextfast = fast.Next.Next
}
循环控制语句
1. break - 跳出循环
for i := 0; i < 10; i++ {if i == 5 {break // 当i=5时跳出循环}fmt.Println(i) // 输出: 0,1,2,3,4
}
2. continue - 跳过本次循环
for i := 0; i < 5; i++ {if i%2 == 0 {continue // 跳过偶数次循环}fmt.Println(i) // 输出: 1,3
}
3. 标签break - 跳出多重循环
outerLoop:
for i := 0; i < 3; i++ {for j := 0; j < 3; j++ {if i*j == 4 {break outerLoop // 直接跳出外层循环}fmt.Printf("i=%d, j=%d\n", i, j)}
}
常见陷阱与最佳实践
1. 索引越界问题
// 错误:可能越界
for i := 0; i <= len(nums); i++ { // 应该用 < 而不是 <=fmt.Println(nums[i]) // 当i==len(nums)时越界
}// 正确:
for i := 0; i < len(nums); i++ {fmt.Println(nums[i])
}
2. 无限循环预防
// 危险:可能死循环
i := 0
for i < 5 {// 忘记 i++,导致无限循环fmt.Println(i)// 应该加上: i++
}// 安全:使用三段式
for i := 0; i < 5; i++ {fmt.Println(i)
}
3. 性能优化
// 较差:每次循环都计算len(nums)
for i := 0; i < len(nums); i++ {// len(nums)每次都会调用
}// 较好:预先计算长度
n := len(nums)
for i := 0; i < n; i++ {// 使用预先计算的长度
}// 最好:使用range(编译器优化)
for i := range nums {// 最高效的遍历方式
}
4. 修改遍历中的集合
// 危险:在range循环中修改切片长度
nums := []int{1, 2, 3, 4, 5}
for i, num := range nums {if num%2 == 0 {nums = append(nums[:i], nums[i+1:]...) // 修改原切片,可能导致意外行为}
}// 安全:创建新切片或使用反向遍历
result := []int{}
for _, num := range nums {if num%2 != 0 {result = append(result, num)}
}
力扣实战示例
示例1:两数之和
func twoSum(nums []int, target int) []int {seen := make(map[int]int)for i, num := range nums {complement := target - numif idx, exists := seen[complement]; exists {return []int{idx, i}}seen[num] = i}return nil
}
示例2:反转字符串
func reverseString(s []byte) {for left, right := 0, len(s)-1; left < right; left, right = left+1, right-1 {s[left], s[right] = s[right], s[left]}
}
示例3:移动零
func moveZeroes(nums []int) {slow := 0for fast := 0; fast < len(nums); fast++ {if nums[fast] != 0 {nums[slow], nums[fast] = nums[fast], nums[slow]slow++}}
}
示例4:二分查找
func search(nums []int, target int) int {left, right := 0, len(nums)-1for left <= right {mid := left + (right-left)/2if nums[mid] == target {return mid} else if nums[mid] < target {left = mid + 1} else {right = mid - 1}}return -1
}
总结要点
-
选择合适的形式:
- 知道次数 → 三段式
for i:=0; i<n; i++ - 条件循环 → while风格
for condition {} - 遍历集合 → range循环
for i, v := range
- 知道次数 → 三段式
-
性能优先:
- 预先计算循环边界
- 优先使用range遍历
- 避免在循环内进行昂贵操作
-
安全第一:
- 检查索引越界
- 确保循环有退出条件
- 小心修改正在遍历的集合
-
掌握控制语句:
break跳出循环continue跳过本次- 标签跳出多重循环
多数元素(9.16.1)
使用哈希表求解
func majorityElement(nums []int) int {//求出目标出现次数target := len(nums)/2//使用哈希表来计次counter := make(map[int]int)for _,val := range nums{//处理键不存在的情况if _,ok := counter[val];!ok{counter[val]=1//注意这个是直等}else{counter[val]++}}//检查计次结果并且输出最终值for key,value := range counter{if value > target{return key}}return 0
}
注意
这段逻辑中if的判断条很容易搞反
if _,ok := counter[val];!ok{counter[val]=1//注意这个是直等}else{counter[val]++}
if语句用法总结
1. 基础if-else结构
if condition {// 条件为true时执行
} else {// 条件为false时执行
}
力扣应用场景:二分查找、条件判断
// 示例:判断数字正负
if num > 0 {return "positive"
} else {return "non-positive"
}
2. if带初始化语句
if statement; condition {// 作用域仅限于if块内
}
力扣常见用法:
// 示例1:map键存在性检查(您的题目中的情况)
if _, ok := counter[val]; ok {counter[val]++ // 键存在
} else {counter[val] = 1 // 键不存在
}// 示例2:错误处理
if err := doSomething(); err != nil {return err
}// 示例3:循环中的条件判断
for i := 0; i < n; i++ {if val := nums[i]; val > max {max = val}
}
3. 多条件判断
if condition1 {// ...
} else if condition2 {// ...
} else {// ...
}
力扣应用场景:复杂条件分支
// 示例:判断数字特性
if num == 0 {return "zero"
} else if num % 2 == 0 {return "even"
} else {return "odd"
}
4. 嵌套if语句
if condition1 {if condition2 {// 两个条件都满足}
}
5. 特殊用法技巧
5.1 简化map操作
// 不需要检查键是否存在,直接++
counter := make(map[int]int)
for _, val := range nums {counter[val]++ // 自动处理键不存在的情况
}
5.2 提前返回(Guard Clause)
func process(nums []int) error {if len(nums) == 0 {return errors.New("empty slice")}if nums[0] < 0 {return errors.New("invalid value")}// 主要逻辑...return nil
}
5.3 链式条件判断
// 判断数组是否有序
if len(nums) <= 1 {return true
}
if nums[0] <= nums[1] && nums[1] <= nums[2] {// 升序检查
}
6. 力扣刷题实用模式
模式1:边界检查优先
func example(nums []int, index int) int {if index < 0 || index >= len(nums) {return -1 // 越界处理}return nums[index]
}
模式2:双指针条件判断
func twoSum(nums []int, target int) []int {left, right := 0, len(nums)-1for left < right {sum := nums[left] + nums[right]if sum == target {return []int{left, right}} else if sum < target {left++} else {right--}}return nil
}
模式3:递归终止条件
func dfs(node *TreeNode, target int) bool {if node == nil {return false}if node.Val == target {return true}return dfs(node.Left, target) || dfs(node.Right, target)
}
7. 常见错误及避免方法
错误1:混淆赋值(=)和比较(==)
// 错误
if x = 5 { ... } // 编译错误
// 正确
if x == 5 { ... }
错误2:作用域混淆
// 错误:val在if外不可用
if val := getValue(); val > 0 {// ...
}
fmt.Println(val) // 错误:val未定义// 正确:提前声明
var val int
if val = getValue(); val > 0 {// ...
}
fmt.Println(val) // 正确
8. 性能优化建议
- 将最常见条件放在前面,减少不必要的判断
- 避免深层嵌套,使用提前返回模式
- 合并相关条件,减少判断次数
- 利用短路求值特性:
if condition1 && condition2
// 优化前
if i < len(nums) {if nums[i] == target {return i}
}// 优化后
if i < len(nums) && nums[i] == target {return i
}
轮转数组(9.16.2)
除余赋值法
func rotate(nums []int, k int) {//创建工具数组之后再赋值回去length := len(nums)tools := make([]int,length)//可以回去对比一下合并两个有序数组//遍历赋值for i,val := range nums{//计算新位置tools[(k+i)%length]=val}copy(nums,tools)
}
注意
我们在这个题目中创建数组的方法是有别于切片的
tools := make([]int,length)//定长数组的创建 用于直接对元素赋值result := make([]int,0,m+n)//定容0长切片的创建 用于append
如果想深入了解的话看一下下面的知识点总结
数组与切片创建方法对比
1. 数组 vs 切片的核心区别
| 特性 | 数组 | 切片 |
|---|---|---|
| 声明方式 | var arr [n]T | var slice []T |
| 长度 | 固定,编译时确定 | 动态,运行时可变 |
| 内存分配 | 栈或静态存储 | 堆分配(底层引用数组) |
| 传递方式 | 值传递(拷贝) | 引用传递(共享底层数组) |
| 长度表达式 | 必须是常量 | 可以是变量或表达式 |
2. 创建方式对比
2.1 数组创建方式
// 方式1:声明并初始化
var arr1 [5]int = [5]int{1, 2, 3, 4, 5}// 方式2:简短声明
arr2 := [3]string{"a", "b", "c"}// 方式3:自动长度推断
arr3 := [...]int{1, 2, 3, 4, 5} // 编译器推断长度为5// 方式4:指定索引初始化
arr4 := [5]int{0: 10, 3: 40} // [10, 0, 0, 40, 0]
2.2 切片创建方式
// 方式1:make函数创建(您的rotate函数中使用的方式)
slice1 := make([]int, length) // 长度=容量
slice2 := make([]int, length, cap)// 指定长度和容量// 方式2:字面量创建
slice3 := []int{1, 2, 3, 4, 5}// 方式3:从数组或切片创建
arr := [5]int{1, 2, 3, 4, 5}
slice4 := arr[1:4] // [2, 3, 4]// 方式4:从现有切片创建(您的merge函数中使用的方式)
slice5 := make([]int, 0) // 空切片
slice6 := make([]int, 0, m+n) // 预分配容量(推荐)
3. 代码分析
3.1 rotate函数中的切片创建
tools := make([]int, length) // 正确用法
- 优点:预分配了确切长度的切片,避免后续append的内存重新分配
- 适用场景:已知确切长度,需要直接通过索引赋值
3.2 merge函数中的切片创建
result := make([]int, 0, m+n) // 更优的写法
- 优化建议:使用预分配容量,避免append时的多次内存分配
- 当前问题:
make([]int, 0, m+n)比make([]int, 0)更高效
4. 力扣刷题中的选择策略
4.1 选择数组的情况
// 当数据大小固定且已知时
func fixedSizeProblem() {const size = 100var cache [size]int // 使用数组// ...
}
4.2 选择切片的情况(更常见)
// 动态大小问题
func dynamicSizeProblem(input []int) {// 方式1:已知确切长度result := make([]int, len(input))// 方式2:需要逐步添加元素result := make([]int, 0, len(input)*2) // 预分配足够容量// 方式3:不确定最终大小var result []int // 初始为nil切片
}
5. 性能优化技巧
5.1 预分配容量(最重要)
// 不好:可能多次重新分配内存
result := []int{}
for i := 0; i < 1000; i++ {result = append(result, i)
}// 好:一次性分配足够容量
result := make([]int, 0, 1000)
for i := 0; i < 1000; i++ {result = append(result, i)
}
5.2 避免不必要的拷贝
// 直接操作原切片(如果允许修改)
func inPlaceModification(nums []int) {for i := range nums {nums[i] *= 2}
}// 需要新切片时才创建
func needNewSlice(nums []int) []int {result := make([]int, len(nums))copy(result, nums)// 修改result...return result
}
6. 常见错误及避免
错误1:切片共享底层数组
// 错误:修改slice2会影响slice1
slice1 := []int{1, 2, 3, 4, 5}
slice2 := slice1[1:4]
slice2[0] = 999 // slice1也变为[1, 999, 3, 4, 5]// 正确:需要独立拷贝时
slice2 := make([]int, len(slice1[1:4]))
copy(slice2, slice1[1:4])
错误2:未预分配导致性能问题
// 在循环中append没有预分配容量
// 可能导致O(n²)的时间复杂度(由于多次内存重新分配)
错误3:混淆长度和容量
// 创建长度为5,容量为10的切片
s := make([]int, 5, 10)
// s[0]到s[4]为0,s[5]到s[9]不可直接访问(需要append)
7. 实用代码模板
模板1:原地修改
func inPlaceSolution(nums []int) {// 直接修改原切片for i := range nums {// 处理逻辑}
}
模板2:返回新切片
func newSliceSolution(nums []int) []int {// 预分配结果切片result := make([]int, len(nums))// 或者逐步构建// result := make([]int, 0, len(nums))// for ... {// result = append(result, value)// }return result
}
模板3:合并多个切片(如merge函数)
func mergeSlices(slices ...[]int) []int {// 计算总长度totalLen := 0for _, s := range slices {totalLen += len(s)}// 预分配结果result := make([]int, 0, totalLen)// 合并for _, s := range slices {result = append(result, s...)}return result
}
总结
在力扣刷题中:
- 优先使用切片(90%的情况)
- 总是预分配容量(使用
make([]T, length, capacity)) - 考虑是否允许原地修改来节省内存
- 注意切片共享底层数组的问题
- 数组仅用于固定大小的场景
买卖股票的最佳时机(9.16.3)
动态规划解法简述
1. 动态规划核心思想
动态规划就是:将大问题分解为小问题,保存中间结果避免重复计算
对于这道题:
- 状态定义:定义
dp[i]表示第i天能获得的最大利润 - 状态转移:今天的最大利润 = max(昨天的最大利润, 今天价格 - 历史最低价)
2. 具体解法
func maxProfit(prices []int) int {if len(prices) == 0 {return 0}//记录最大利润结果和当前最低价minPrice := prices[0]maxProfit := 0//遍历数组 最低价买后找最大利润for _,price := range prices{//更新现有最低价if price < minPrice{minPrice = price}//更新最大利润if price-minPrice > maxProfit{maxProfit = price-minPrice}} return maxProfit
}
3. 动态规划四要素
(1) 状态定义
minPrice:到当前为止的历史最低买入价格maxProfit:到当前为止的最大利润
(2) 状态转移方程
minPrice = min(minPrice, 当前价格)
maxProfit = max(maxProfit, 当前价格 - minPrice)
(3) 初始状态
minPrice = prices[0] // 第一天只能买入
maxProfit = 0 // 第一天不能卖出,利润为0
(4) 遍历顺序
从第二天开始遍历到最后一天
4. 动态规划思维模式
| 步骤 | 内容 | 本题示例 |
|---|---|---|
| 1. 定义状态 | 用什么变量表示问题状态 | minPrice, maxProfit |
| 2. 状态转移 | 当前状态如何从前一个状态得来 | 比较当前价格与历史最低价 |
| 3. 初始条件 | 最开始的状态是什么 | 第一天的情况 |
| 4. 计算顺序 | 按什么顺序计算状态 | 从左到右遍历 |
5. 为什么这是动态规划?
虽然代码看起来简单,但它包含了动态规划的所有要素:
- 最优子结构:今天的最大利润依赖于之前的最优解(历史最低价)
- 重叠子问题:每个状态都重复使用之前计算的结果
- 状态保存:用变量保存中间计算结果
6. 更直观的理解
想象你每天都在做决策:
- 第i天:我可以选择在今天卖出
- 最大利润 = 今天价格 - 历史最低价
- 只需要记住:到目前为止的历史最低价和最大利润
7. 时间复杂度:O(n)
8. 空间复杂度:O(1)
这就是动态规划的威力:用最少的空间和時間解决复杂问题!
总结:动态规划就是通过保存中间结果,避免重复计算,从而高效解决问题。这道题是学习动态规划的完美入门题目!
买卖股票的最佳时机 II(9.16.4)
动态规划
func maxProfit(prices []int) int {//初始化记录表 上面是序号 下面是需要投入的成本length := len(prices)dp := make([][2]int, length)dp[0][1] = -prices[0]//0表示手里没有股票的最大利润、1表示交易完后手里持有一支股票的最大利润for i := 1; i < length; i++ {//前者是一直不交易的 后者是今天给股票卖了 的收益dp[i][0] = max(dp[i-1][0], dp[i-1][1]+prices[i])//前者是今天不抛售 后者是之前不持股但是今天买进dp[i][1] = max(dp[i-1][1], dp[i-1][0]-prices[i])}return dp[length-1][0]
}func max(a, b int) int {if a > b {return a}return b
}
贪心算法
func maxProfit(prices []int) (ans int) {for i := 1; i < len(prices); i++ {ans += max(0, prices[i]-prices[i-1])}return
}func max(a, b int) int {if a > b {return a}return b
}
这个算法模拟的是下面这个过程:
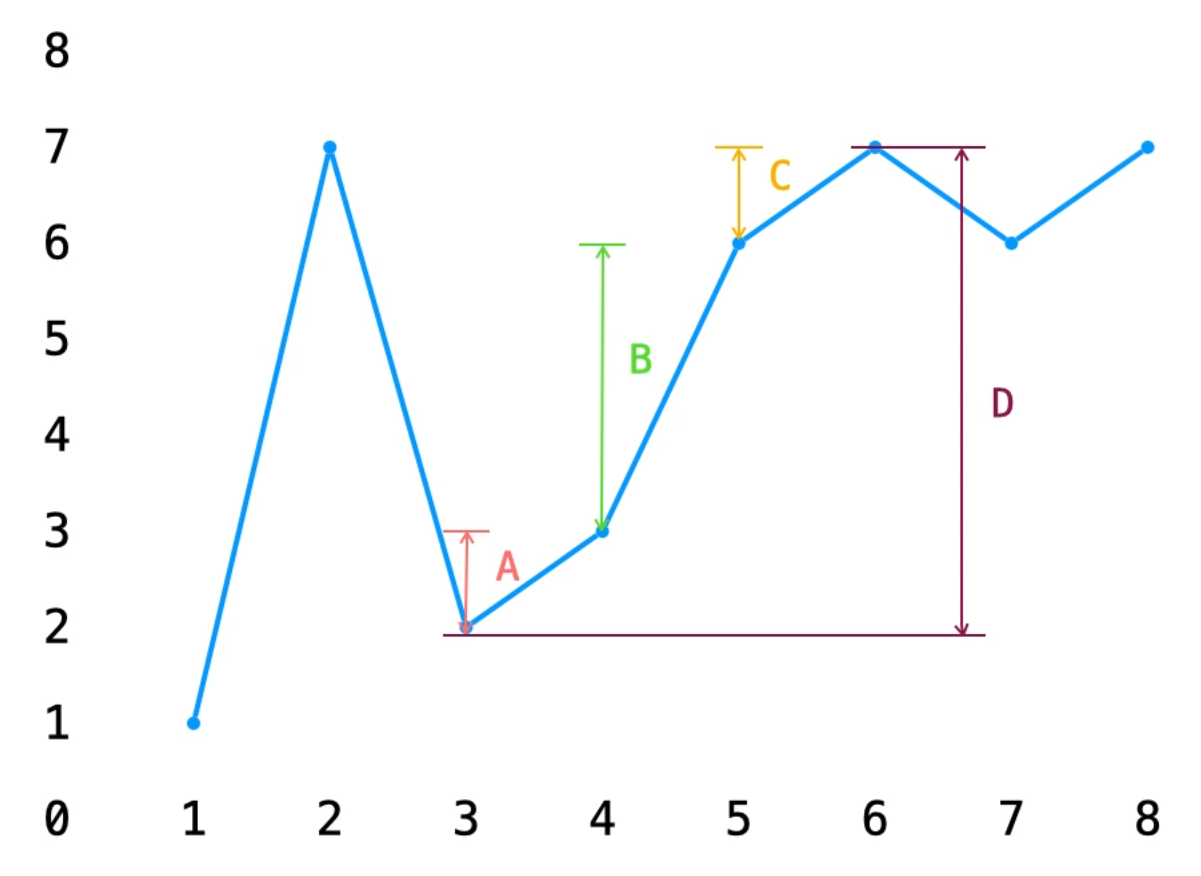
并非去进行了交易,而是通过减法找到了高低差。然后我们充分利用每一段高低差(这个适合没有手续费的情况)
跳跃游戏(9.17.1)
贪心算法
func canJump(nums []int) bool {//设置记录最长可跃迁位置坐标maxLocation := 0//遍历并且更新最长距离for i , movePath := range nums{//发现无法到达当前节点if i > maxLocation{return false}//更新最长距离if maxLocation < i+movePath{maxLocation = i+movePath}// // 如果已经可以到达最后一个位置,提前返回true// if maxLocation >= len(nums) {// return true// }}return true
}
注释掉的部分属于可以提前结束循环的内容,优化程序但是不影响能不能跑通
跳跃游戏 II(9.17.2)
贪心算法
这个算法引入了一个end边界变量,便于确定是否跳
func jump(nums []int) int {//初始化单次查询边界 跳步数 最大预期位置end,steps,maxLocation := 0,0,0 //不要访问最后一个元素,否则会多加1for i:=0 ; i<len(nums)-1 ;i++{// if maxLocation >= len(nums)-1{// return steps+1//说明可以直接跳到,但是还没有记步// }//遍历到某个节点时 优先更新最大预期位置maxLocation = max(maxLocation,i+nums[i])//判断是否到达当前边界 到达的话就需要更新距离if i == end{steps++end = maxLocation}}return steps
}func max(a,b int) int{if a>b{return a}return b
}
注释部分用于优化算法,不影响跑步跑的通,但是要注意循环里面len()方法要改成外部计算声明变量,避免每次循环都要重复计算
注意
-
在for循环的头上,
len()方法只计算一次for i:=0 ; i<len(nums)-1 ;i++ -
在for循环的内部,
len()方法每次都要进行计算
H 指数(9.17.3)
方法一:顺序排序
func hIndex(citations []int) int {//创建h值maxH := 0//降序进行排列// sort.Sort(sort.Reverse(sort.IntSlice(citations)))这个不太好记住 我们使用正序sort.Ints(citations)for i := len(citations)-1 ; i>=0 ;i--{if citations[i] > maxH{//这个地方不能取等 取等的话会多加1maxH++}else{break}}return maxH
}
注意
if citations[i] > maxH{//这个地方不能取等 取等的话会多加1
这部分代码不能取等,因为如果遇到下面这种情况[1,3,1],当遍历到第二个1的时候,取等判断符合条件,就回再加1,造成多加
方法二:计数排序
func hIndex(citations []int) (h int) {n := len(citations)counter := make([]int, n+1)for _, citation := range citations {if citation >= n {counter[n]++} else {counter[citation]++}}for i, tot := n, 0; i >= 0; i-- {tot += counter[i]if tot >= i {return i}}return 0
}
方法三:二分搜索
func hIndex(citations []int) int {// 答案最多只能到数组长度left,right:=0,len(citations)var mid intfor left<right{// +1 防止死循环mid=(left+right+1)>>1cnt:=0for _,v:=range citations{if v>=mid{cnt++}}if cnt>=mid{// 要找的答案在 [mid,right] 区间内left=mid}else{// 要找的答案在 [0,mid) 区间内right=mid-1}}return left
}
O(1) 时间插入、删除和获取随机元素(9.17.4)
这道题目涉及到数据结构的设计,本身和算法无关。我们通过阅读题干可以发现,这道题目需要时间复杂度为O(1)的插入和删除以及检索。
//类型定义与初始化
type RandomizedSet struct {nums []intindices map[int]int
}func Constructor() RandomizedSet {return RandomizedSet{[]int{}, map[int]int{}}
}//插入操作
func (rs *RandomizedSet) Insert(val int) bool {if _, ok := rs.indices[val]; ok {return false}//哈希表以元素值为键,以下标为值 实现O(1)的索引rs.indices[val] = len(rs.nums)//在变长数组的末位加上元素 实现O(1)的插入rs.nums = append(rs.nums, val)return true
}//实现删除
func (rs *RandomizedSet) Remove(val int) bool {//获取对应的数组idid, ok := rs.indices[val]if !ok {return false}//将数组尾部元素移动到id位置last := len(rs.nums) - 1rs.nums[id] = rs.nums[last]//删除末位元素位置 并且在哈希表中记录一条新数据rs.indices[rs.nums[id]] = idrs.nums = rs.nums[:last]//删除哈希表中元素delete(rs.indices, val)return true
}func (rs *RandomizedSet) GetRandom() int {return rs.nums[rand.Intn(len(rs.nums))]
}
rand 包力扣刷题速查指南
🎯 核心函数速查
1. 基础随机数生成
import "math/rand"// 初始化种子(力扣中通常不需要,但要知道)
// rand.Seed(time.Now().UnixNano())rand.Int() // 随机int (0到2^31-1)
rand.Intn(100) // [0, 100) 的随机整数 ← 最常用!
rand.Float64() // [0.0, 1.0) 的随机浮点数
2. 数组/切片随机操作
// 随机选择一个元素(最常用!)
arr := []int{1, 2, 3, 4, 5}
randomElem := arr[rand.Intn(len(arr))]// 随机索引
randomIndex := rand.Intn(len(arr))// 随机布尔值
randomBool := rand.Intn(2) == 1 // 50%概率true
🚀 力扣常用技巧
1. 数组随机化(洗牌算法)
// Fisher-Yates 洗牌算法
func shuffle(nums []int) {rand.Seed(time.Now().UnixNano())for i := len(nums) - 1; i > 0; i-- {j := rand.Intn(i + 1)nums[i], nums[j] = nums[j], nums[i]}
}// 或者使用 rand.Shuffle (Go 1.10+)
rand.Shuffle(len(nums), func(i, j int) {nums[i], nums[j] = nums[j], nums[i]
})
2. 加权随机选择
// 根据权重随机选择(力扣528题)
type Solution struct {prefix []inttotal int
}func Constructor(w []int) Solution {prefix := make([]int, len(w))prefix[0] = w[0]for i := 1; i < len(w); i++ {prefix[i] = prefix[i-1] + w[i]}return Solution{prefix, prefix[len(prefix)-1]}
}func (s *Solution) PickIndex() int {target := rand.Intn(s.total) + 1// 二分查找找到第一个 ≥ target 的位置left, right := 0, len(s.prefix)-1for left < right {mid := left + (right-left)/2if s.prefix[mid] < target {left = mid + 1} else {right = mid}}return left
}
3. 随机集合操作(力扣380题)
type RandomizedSet struct {nums []intindices map[int]int
}func Constructor() RandomizedSet {return RandomizedSet{nums: make([]int, 0),indices: make(map[int]int),}
}func (rs *RandomizedSet) Insert(val int) bool {if _, exists := rs.indices[val]; exists {return false}rs.indices[val] = len(rs.nums)rs.nums = append(rs.nums, val)return true
}func (rs *RandomizedSet) Remove(val int) bool {if idx, exists := rs.indices[val]; exists {last := len(rs.nums) - 1rs.nums[idx] = rs.nums[last]rs.indices[rs.nums[idx]] = idxrs.nums = rs.nums[:last]delete(rs.indices, val)return true}return false
}func (rs *RandomizedSet) GetRandom() int {return rs.nums[rand.Intn(len(rs.nums))]
}
⚡ 性能优化提示
- 避免重复初始化种子:力扣环境中通常已经初始化好了
- 缓存长度:
n := len(arr)比多次调用len(arr)更快 - 使用 Intn:比
Int() % n更准确且性能更好
🎲 常见应用场景
| 力扣题型 | rand 应用 | 示例 |
|---|---|---|
| 384. 打乱数组 | 洗牌算法 | rand.Intn(i+1) |
| 380. O(1) 时间插入、删除和获取随机元素 | 随机访问 | nums[rand.Intn(len(nums))] |
| 528. 按权重随机选择 | 前缀和+二分 | rand.Intn(total) |
| 470. 用 Rand7() 实现 Rand10() | 随机数转换 | 拒绝采样 |
| 398. 随机数索引 | 蓄水池采样 | rand.Intn(count) |
💡 刷题小贴士
- 记住这个模式:
arr[rand.Intn(len(arr))] - 洗牌算法从后往前遍历
- 加权随机用前缀和+二分查找
- O(1) 随机访问需要维护数组和映射
掌握这些就足够应对力扣中90%的随机数相关题目了!
除自身以外数组的乘积(9.18.1)
题目上禁止了除法的使用
愚蠢的O(n*n)暴力求解(太慢了过不了)
func productExceptSelf(nums []int) []int {results := make([]int,len(nums)) for i,_ := range nums{results[i] = conclulateOneNumber(i,nums)} return results
}//内层循环计算函数
func conclulateOneNumber(id int,nums []int) int {result := 1for i,val := range nums{if i == id{continue}if val == 0{return 0}result = val*result}return result
}
注意
result := 1
乘法的初始化一定是1,不要初始成0了
左前缀右后缀结果式的计算
func productExceptSelf(nums []int) []int {// L 和 R 分别表示左右两侧的乘积列表length := len(nums)L, R, answer := make([]int, length), make([]int, length), make([]int, length)//计算左前缀结果 L[0] = 1//注意初始化for i := 1; i < length; i++ {L[i] = nums[i-1] * L[i-1]//使用的是迭代的方式 使得for循环无嵌套}//我们来写一下倒序的右后缀遍历计算R[length-1] = 1for i:=length-2; i >= 0;i--{R[i] = nums[i+1]*R[i+1]} //使用这两个结果式进行计算for i := 0; i<length ;i++{answer[i] = R[i]*L[i]}return answer
}
🔍 从 O(n²) 到 O(n):力扣降维打击技巧总结
在做完上面的两种解法,可以感觉到一些n*n的循环嵌套可以使用空间换时间的方式来进行复杂度优化,下面是针对优化的分析和总结
📊 两个算法对比
算法一:O(n²) 暴力解法
func productExceptSelf(nums []int) []int {results := make([]int,len(nums)) for i := range nums { // 外层循环 O(n)results[i] = calculateOneNumber(i, nums) // 内层循环 O(n)} return results // 总复杂度 O(n²)
}
算法二:O(n) 优化解法
func productExceptSelf(nums []int) []int {length := len(nums)L, R, answer := make([]int, length), make([]int, length), make([]int, length)// 左前缀计算 O(n)L[0] = 1for i := 1; i < length; i++ {L[i] = nums[i-1] * L[i-1]}// 右后缀计算 O(n)R[length-1] = 1for i := length-2; i >= 0; i-- {R[i] = nums[i+1] * R[i+1]}// 合并结果 O(n)for i := 0; i < length; i++ {answer[i] = R[i] * L[i]}return answer // 总复杂度 O(n)
}
🚀 力扣降维打击核心技巧
1. 空间换时间法
// 暴力:每次重新计算 → O(n²)
// 优化:预先计算并存储 → O(n)
left[i] = left[i-1] * nums[i-1] // 利用之前的结果
2. 前缀和/后缀和思想
// 适用于:区间和、区间乘积、累积统计等问题
前缀和:prefix[i] = prefix[i-1] + nums[i-1]
后缀和:suffix[i] = suffix[i+1] + nums[i+1]
3. 双指针/多指针技巧
// 将嵌套循环变为单循环
left, right := 0, len(nums)-1
for left < right {// 同时从两端处理left++right--
}
4. 哈希表优化查找
// 暴力:遍历查找 → O(n²)
// 优化:哈希表存储 → O(n)
hash := make(map[int]int)
for i, num := range nums {if j, exists := hash[target-num]; exists {return []int{j, i}}hash[num] = i
}
5. 滑动窗口技巧
// 优化嵌套循环为单循环
left := 0
for right := 0; right < len(nums); right++ {// 移动右指针for 窗口不满足条件 {// 移动左指针left++}// 更新结果
}
6. 动态规划记忆化
// 避免重复计算
dp := make([]int, n)
dp[0] = 1
for i := 1; i < n; i++ {dp[i] = dp[i-1] * nums[i-1] // 复用之前结果
}
7. 二分查找优化
// 将O(n)查找优化为O(log n)
sort.Ints(nums) // 先排序
for i := 0; i < n; i++ {j := sort.SearchInts(nums, target-nums[i])// 二分查找替代线性查找
}
🎯 实战思维转换
从暴力到优化的思考过程:
- 识别重复计算:发现内层循环在做重复工作
- 寻找递推关系:
result[i]能否用result[i-1]推导? - 考虑预处理:能否预先计算一些信息?
- 选择数据结构:哈希表、数组、堆等哪种合适?
- 空间换时间:多用一些内存来节省时间
经典优化模式:
| 原问题 | 优化技巧 | 复杂度变化 |
|---|---|---|
| 两数之和 | 哈希表 | O(n²) → O(n) |
| 最大子数组和 | 动态规划 | O(n²) → O(n) |
| 区间求和 | 前缀和 | O(n²) → O(n) |
| 滑动窗口最大值 | 单调队列 | O(n²) → O(n) |
💡 刷题建议
- 先写暴力解:理解问题本质,确保正确性
- 分析重复计算:找出可以优化的部分
- 选择合适技巧:前缀和、哈希、双指针等
- 测试边界情况:空数组、极端值等
- 复杂度分析:确保满足题目要求
记住:90%的力扣中等题都可以通过这几种技巧将复杂度从 O(n²) 降到 O(n) 或 O(n log n)!
Go 语言中 for range 的实现逻辑与性能比较
刚刚讲了一些算法的优化,下面我查了一下一直很困扰的一个问题,就是for range对性能的影响
for range 的实现逻辑
for range 循环在 Go 语言中是一种语法糖,编译器会根据不同的数据类型生成不同的底层代码:
1. 数组和切片
// 源码
for i, v := range arr {// 处理逻辑
}// 编译器生成的近似代码
len_temp := len(arr)
for i := 0; i < len_temp; i++ {v := arr[i]// 处理逻辑
}
2. 映射(map)
// 源码
for k, v := range m {// 处理逻辑
}// 编译器生成的近似代码(简化版)
// 实际会使用哈希迭代器,顺序是随机的
3. 字符串
// 源码
for i, r := range s {// 处理逻辑
}// 编译器生成的代码会处理 UTF-8 编码,正确迭代 rune
4. 通道(channel)
// 源码
for v := range ch {// 处理逻辑
}// 编译器生成的代码会不断从通道接收值,直到通道关闭
性能比较:for range vs for len()
测试代码示例
package mainimport ("testing"
)const size = 1000000var arr = make([]int, size)func init() {for i := 0; i < size; i++ {arr[i] = i}
}// BenchmarkForRange 测试 for range 性能
func BenchmarkForRange(b *testing.B) {for n := 0; n < b.N; n++ {sum := 0for _, v := range arr {sum += v}_ = sum}
}// BenchmarkForLen 测试 for len() 性能
func BenchmarkForLen(b *testing.B) {for n := 0; n < b.N; n++ {sum := 0for i := 0; i < len(arr); i++ {sum += arr[i]}_ = sum}
}// BenchmarkForLenCached 测试缓存 len 的 for 循环性能
func BenchmarkForLenCached(b *testing.B) {for n := 0; n < b.N; n++ {sum := 0length := len(arr)for i := 0; i < length; i++ {sum += arr[i]}_ = sum}
}
性能测试结果
通常情况下,性能排序为:
- for len() 缓存长度 - 最快
- for len() - 中等
- for range - 稍慢
具体分析
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
for range | 代码简洁,安全性高,不会越界 | 每次迭代创建值副本,稍慢 | 需要值的场景,代码可读性优先 |
for len() | 直接索引访问,性能较好 | 需要手动处理索引,可能越界 | 性能敏感场景,只需要索引 |
for len() 缓存 | 性能最优,避免重复计算长度 | 代码稍冗长 | 极致性能要求的场景 |
推荐建议
推荐使用 for range 的情况:
- 需要元素值而不是索引时
- 代码可读性更重要时
- 对 map、string、channel 进行迭代时
- 一般的业务逻辑代码
推荐使用 for len() 的情况:
- 性能敏感的代码段
- 只需要索引不需要值时
- 需要修改原数组元素时(range 创建的是副本)
- 在热点循环中需要极致优化时
示例对比
// 推荐使用 for range(需要值,代码简洁)
func sumWithRange(arr []int) int {sum := 0for _, v := range arr {sum += v}return sum
}// 推荐使用 for len()(性能敏感,只需要索引)
func processLargeArray(arr []int) {n := len(arr)for i := 0; i < n; i++ {// 高性能处理逻辑arr[i] = process(arr[i])}
}// 需要修改原数组时使用 for len()
func doubleValues(arr []int) {for i := 0; i < len(arr); i++ {arr[i] *= 2 // 直接修改原数组}
}
结论
- 大多数情况下:使用
for range,因为代码更简洁安全 - 性能关键路径:使用
for len()并缓存长度 - 需要修改元素:使用
for len()直接通过索引修改 - 特殊数据类型:map、string、channel 必须使用
for range
在实际开发中,建议先使用 for range 编写清晰易懂的代码,只有在性能测试表明需要优化时才考虑改用 for len()。
加油站(9.18.2)
暴力求解
从头到尾遍历每个加油站,并检查以该加油站为起点,最终能否行驶一周
func canCompleteCircuit(gas []int, cost []int) int {n := len(gas)// 尝试每一个加油站作为起点for start := 0; start < n; start++ {if checkOneStart(start, gas, cost) {return start}}// 所有起点都尝试过了,都无法完成环路return -1
}// 检查从指定起点出发能否完成环路
func checkOneStart(start int, gas []int, cost []int) bool {n := len(gas)currentGas := 0// 检查从start出发能否完成环路for i := 0; i < n; i++ {currentStation := (start + i) % ncurrentGas += gas[currentStation] // 在当前加油站加油currentGas -= cost[currentStation] // 消耗汽油前往下一站// 如果油量不够,说明这个起点不行if currentGas < 0 {return false}}// 能够完成整个环路return true
}
贪心算法优化
发现:如果从加油站A出发,开到加油站C时没油了,那么A到C之间的任何一个加油站作为起点,都开不到C之后
所以:不是傻傻地一个个试,而是"跳跃式"检查,从起点A开始模拟行驶,如果在加油站C没油了,下次直接从C+1开始检查,跳过中间所有站
func canCompleteCircuit(gas []int, cost []int) int {for i, n := 0, len(gas); i < n; {//初始化花费油、获取油和圈数sumOfGas, sumOfCost, cnt := 0, 0, 0// 尝试从i出发能开多远for cnt < n {j := (i + cnt) % n // 当前检查的加油站sumOfGas += gas[j] // 累计加油量sumOfCost += cost[j] // 累计耗油量// 如果累计耗油 > 累计加油,说明开不下去了if sumOfCost > sumOfGas {break}cnt++ // 成功开到下一站}// 如果开完了全程,返回起点if cnt == n {return i} else {// 关键:跳跃到失败点的下一个站i += cnt + 1}}return -1
}
分发糖果(9.18.3)
下周一就要面试,难题就先只写思路理解了
两次遍历
也就是将规则拆解成两个规则,使用从左到右和从右到左的方式进行遍历
- 左规则:当 ratings[i−1]<ratings[i] 时,i 号学生的糖果数量将比 i−1 号孩子的糖果数量多。
- 右规则:当 ratings[i]>ratings[i+1] 时,i 号学生的糖果数量将比 i+1 号孩子的糖果数量多。
//力扣官方题解
func candy(ratings []int) (ans int) {n := len(ratings)left := make([]int, n)for i, r := range ratings {//如过现在这个积分大于左边那一个的积分if i > 0 && r > ratings[i-1] {//排除第一个left[i] = left[i-1] + 1} else {left[i] = 1}}right := 0for i := n - 1; i >= 0; i-- {if i < n-1 && ratings[i] > ratings[i+1] {right++} else {right = 1}//统计最终结果 顺手的事ans += max(left[i], right)//取的是都符合左右要求的结果 就是最大结果}return
}func max(a, b int) int {if a > b {return a}return b
}
常数空间遍历
感觉不如上面那个好理解
func candy(ratings []int) int {n := len(ratings)ans, inc, dec, pre := 1, 1, 0, 1for i := 1; i < n; i++ {if ratings[i] >= ratings[i-1] {dec = 0if ratings[i] == ratings[i-1] {pre = 1} else {pre++}ans += preinc = pre} else {dec++if dec == inc {dec++}ans += decpre = 1}}return ans
}
接雨水(9.18.4)
下周一就要面试,难题就先只写思路理解了
动态规划
func trap(height []int) (ans int) {n := len(height)if n == 0 {return}//记录一下每个点左、右侧最高的高度leftMax := make([]int, n)leftMax[0] = height[0]for i := 1; i < n; i++ {leftMax[i] = max(leftMax[i-1], height[i])}rightMax := make([]int, n)rightMax[n-1] = height[n-1]for i := n - 2; i >= 0; i-- {rightMax[i] = max(rightMax[i+1], height[i])}//木桶效应 决定了某一个点的最高存水量 这个不一定是直接相邻的边界高度for i, h := range height {ans += min(leftMax[i], rightMax[i]) - h}return//声明返回
}func min(a, b int) int {if a < b {return a}return b
}func max(a, b int) int {if a > b {return a}return b
}
下面的两个随后再看吧
单调栈
func trap(height []int) (ans int) {stack := []int{}for i, h := range height {for len(stack) > 0 && h > height[stack[len(stack)-1]] {top := stack[len(stack)-1]stack = stack[:len(stack)-1]if len(stack) == 0 {break}left := stack[len(stack)-1]curWidth := i - left - 1curHeight := min(height[left], h) - height[top]ans += curWidth * curHeight}stack = append(stack, i)}return
}func min(a, b int) int {if a < b {return a}return b
}
双指针
func trap(height []int) (ans int) {left, right := 0, len(height)-1leftMax, rightMax := 0, 0for left < right {leftMax = max(leftMax, height[left])rightMax = max(rightMax, height[right])if height[left] < height[right] {ans += leftMax - height[left]left++} else {ans += rightMax - height[right]right--}}return
}func max(a, b int) int {if a > b {return a}return b
}
罗马数字转整数(9.19.1)
var symbolValues = map[byte]int{'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500, 'M': 1000}func romanToInt(s string) (ans int) {n := len(s)for i := range s {value := symbolValues[s[i]]//如果右边有更大的数字,说明是要捆绑在一起的 前缀需要减掉if i < n-1 && value < symbolValues[s[i+1]] {ans -= value} else {ans += value}}return
}
基于这两个罗马数字题目,我为你总结了力扣字符串类型问题的刷题指南:
字符串刷题技巧
len(string)不计算字符串默认终止符
🧩 字符串问题核心分类
1. 编码转换类(如这两题)
- 特点:不同编码系统间的相互转换
- 解题技巧:
- 建立映射表(map或数组)
- 注意特殊规则(如罗马数字的减法规则)
- 贪心算法:从大到小处理
2. 字符串匹配与搜索
- 经典题目:实现strStr()、正则表达式匹配
- 技巧:
- KMP算法(字符串匹配)
- 双指针技巧
- 滑动窗口
3. 字符串操作与变换
- 常见问题:反转字符串、字符串转换、Z字形变换
- 技巧:
- 双指针反转
- 模拟过程,注意边界条件
- 数学规律寻找
4. 回文串相关问题
- 题目:验证回文串、最长回文子串、回文分割
- 技巧:
- 中心扩展法
- 动态规划
- 双指针比较
5. 字符串计数与统计
- 题目:字符出现次数、唯一字符、字母异位词
- 技巧:
- 使用数组或map统计频率
- 滑动窗口统计
🎯 高效刷题策略
1. 掌握核心数据结构
// 字符映射表(常用)
charMap := make(map[byte]int)
// 或者使用数组(更高效)
count := make([]int, 128) // ASCII码范围
2. 熟悉字符串操作API
// 重要字符串操作
len(s) // 长度
s[i] // 访问字符
s[i:j] // 切片
strings.Contains(s, substr) // 包含判断
strings.Split(s, sep) // 分割
3. 常用算法模式
// 模式1:建立映射 + 遍历处理(如罗马数字转整数)
func solve(s string) int {mapping := createMapping()result := 0for i := 0; i < len(s); i++ {// 根据映射规则处理if shouldSubtract(s, i, mapping) {result -= mapping[s[i]]} else {result += mapping[s[i]]}}return result
}// 模式2:贪心选择(如整数转罗马数字)
func solve(num int) string {values := []struct{val int; sym string}{}result := ""for _, item := range values {for num >= item.val {num -= item.valresult += item.sym}}return result
}
📋 推荐刷题顺序
初级(掌握基础)
- 反转字符串(344)- 双指针基础
- 字符串中的第一个唯一字符(387)- 频率统计
- 验证回文串(125)- 双指针应用
中级(提升技巧)
- 字符串转换整数(8)- 边界处理
- 最长公共前缀(14)- 字符串比较
- 罗马数字转整数(13)- 映射+规则
高级(综合应用)
- 整数转罗马数字(12)- 贪心算法
- Z字形变换(6)- 模拟+规律
- 字符串相乘(43)- 数学模拟
💡 重要解题技巧
1. 边界处理技巧
// 检查下一个字符时的安全写法
if i < len(s)-1 && s[i] == 'I' && s[i+1] == 'V' {// 安全访问s[i+1]
}
2. 效率优化
// 使用字节切片而非字符串拼接(性能更好)
var result []byte
for condition {result = append(result, byteValue)
}
return string(result)
3. 特殊字符处理
// 处理Unicode字符
for _, r := range s { // 使用rune循环// 处理每个字符
}
🚀 刷题建议
- 先理解规则:如罗马数字的减法规则
- 画图分析:复杂问题先画图理解
- 测试边界:空字符串、极端值测试
- 总结模式:同类题目总结通用解法
📊 常见错误避免
- 数组越界(总是检查 i < len(s)-1)
- 字符与数字转换错误
- 忘记处理大小写(如回文串问题)
- 字符串拼接的性能问题
这样的分类和策略能帮助你系统性地刷字符串相关题目,提高刷题效率!
整数转罗马数字(9.19.2)
var valueSymbols = []struct {value int//有哪些特殊情况需要列出来比较关键symbol string
}{//这些特殊的数字就是因为罗马数字不允许四个同样的列举在一起{1000, "M"},{900, "CM"},{500, "D"},{400, "CD"},{100, "C"},{90, "XC"},{50, "L"},{40, "XL"},{10, "X"},{9, "IX"},{5, "V"},{4, "IV"},{1, "I"},
}func intToRoman(num int) string {roman := []byte{}for _, vs := range valueSymbols {for num >= vs.value {//从大到小遍历num -= vs.valueroman = append(roman, vs.symbol...)}if num == 0 {break}}return string(roman)
}
最后一个单词的长度(9.19.3)
这道题依旧是和字符串相关
倒序遍历法
func lengthOfLastWord(s string) int {index := len(s) - 1//如果最后几个是空格,就会跳过for s[index] == ' '{index--} ans := 0//结果统计for index >= 0 && s[index] != ' ' {ans++index--}return ans
}
最长公共前缀(9.19.4)
二重遍历
就是从前往后遍历所有字符串的每一列,比较相同列上的字符是否相同,如果相同则继续对下一列进行比较,如果不相同则当前列不再属于公共前缀
func longestCommonPrefix(strs []string) string {if len(strs) == 0 {return ""}for i := 0; i < len(strs[0]); i++ {//对单词内部的迭代遍历for j := 1; j < len(strs); j++ {//对数组中单词的遍历//长度和某个单词一样 发现这个位置的字母在某两个单词中不一样if i == len(strs[j]) || strs[j][i] != strs[0][i] {return strs[0][:i]}}}return strs[0]
}
分治法
分治法好比总公司(所有字符串)要找到全员共识,但直接让所有人一起讨论太混乱,于是采用分层讨论的方式
总公司:[flower, flow, flight]/ \部门A:[flower, flow] 部门B:[flight]/ \ │
员工1:flower 员工2:flow 员工3:flight
func longestCommonPrefix(strs []string) string {if len(strs) == 0 {return ""}// 定义递归函数var lcp func(int, int) stringlcp = func(start, end int) string {// 递归终止条件:只有一个字符串时,前缀就是它自己if start == end {return strs[start]}// 分治:将问题分成左右两部分mid := (start + end) / 2lcpLeft := lcp(start, mid) // 递归处理左半部分lcpRight := lcp(mid+1, end) // 递归处理右半部分// 合并:找到左右两部分结果的公共前缀minLength := min(len(lcpLeft), len(lcpRight))for i := 0; i < minLength; i++ {if lcpLeft[i] != lcpRight[i] {return lcpLeft[:i] // 发现不同字符,返回前面的公共部分}}return lcpLeft[:minLength] // 完全匹配,返回较短的那个}// 从整个数组范围开始递归return lcp(0, len(strs)-1)
}// 辅助函数:返回两个整数中的较小值
func min(x, y int) int {if x < y {return x}return y
}
二分查找
假设有3个字符串:["flower", "flow", "flight"],最短字符串是"flow"(长度4),我们要找到最长的公共开头。
二分查找的方法可以理解为:我知道公共前缀长度在0到4之间(因为最短字符串长度4),我要用最少的次数猜出正确的长度
-
步骤1:确定搜索范围
最小可能长度:0 最大可能长度:4(最短字符串"flow"的长度) 搜索范围:[0, 4] -
步骤2:第一次猜测(中间值)
猜长度:mid = (0 + 4 + 1) / 2 = 2(取整后) 检查前2个字符是否都是公共前缀: "flower"前2位:"fl" "flow"前2位:"fl" "flight"前2位:"fl" ✓ 全部匹配! -
步骤3:调整搜索范围
既然长度2是公共前缀,说明实际长度至少为2 新的搜索范围:[2, 4] -
步骤4:第二次猜测
猜长度:mid = (2 + 4 + 1) / 2 = 3 检查前3个字符是否都是公共前缀: "flower"前3位:"flo" "flow"前3位:"flo" "flight"前3位:"fli" ❌ 不匹配! -
步骤5:再次调整范围
长度3不是公共前缀,说明实际长度小于3 新的搜索范围:[2, 2] -
步骤6:找到答案
搜索范围收敛到2 最终答案:前2个字符"fl"
func longestCommonPrefix(strs []string) string {if len(strs) == 0 {return ""}// 1. 找到最短字符串长度minLength := len(strs[0])for _, str := range strs {if len(str) < minLength {minLength = len(str)}}// 2. 二分查找low, high := 0, minLengthfor low < high {mid := (high-low+1)/2 + low // 取中间值,向上取整if isCommonPrefix(strs, mid) {low = mid // 如果mid是公共前缀,说明可以更长} else {high = mid - 1 // 如果不是,说明太长了}}return strs[0][:low] // 返回找到的长度对应的前缀
}// 检查指定长度是否是所有字符串的公共前缀
func isCommonPrefix(strs []string, length int) bool {prefix := strs[0][:length]for i := 1; i < len(strs); i++ {// 逐个字符比较,避免字符串切片创建开销for j := 0; j < length; j++ {if strs[i][j] != prefix[j] {return false}}}return true
}
反转字符串中的单词(9.20.1)
- 倒序的遍历整个数组
- 对于一个单词中的倒序恢复,使用栈
func reverseWords(s string) string {//初始化length := len(s) stack := []byte{}// 使用字节切片作为栈来存储单词 result := []byte{}// 结果字节切片// 倒序遍历字符串for i := length - 1; i >= 0; i-- {// 如果当前字符不是空格,压入栈中(收集单词)if s[i] != ' ' {stack = append(stack, s[i])} else {// 遇到空格,且栈不为空,说明一个单词收集完成if len(stack) > 0 {// 将栈中的单词反转(因为是倒序压入的)并添加到结果中for j := len(stack) - 1; j >= 0; j-- {result = append(result, stack[j])}// 添加单词间的空格result = append(result, ' ')// 清空栈,准备收集下一个单词stack = []byte{}}}}// 处理最后一个单词(如果存在)if len(stack) > 0 {for j := len(stack) - 1; j >= 0; j-- {result = append(result, stack[j])}} else {// 如果结果末尾有空格,去除它if len(result) > 0 && result[len(result)-1] == ' ' {result = result[:len(result)-1]}} return string(result)
}
(需回看)Z 字形变换(9.20.2)
方法一:二维矩阵模拟(最直观的方法)
func convert(s string, numRows int) string {n, r := len(s), numRows// 特殊情况处理:只有一行或行数大于等于字符串长度时,直接返回原字符串if r == 1 || r >= n {return s}// 计算Z字形的周期:向下r-1次,向上r-1次,总共2r-2t := r*2 - 2// 计算需要的列数:周期数 × 每个周期占用的列数(r-1)c := (n + t - 1) / t * (r - 1)// 创建r行c列的二维矩阵mat := make([][]byte, r)for i := range mat {mat[i] = make([]byte, c)}// 初始化当前位置为矩阵左上角(0,0)x, y := 0, 0for i, ch := range s {// 将当前字符放入矩阵mat[x][y] = byte(ch)// 判断移动方向:向下或向右上if i%t < r-1 {x++ // 向下移动(Z字形的竖线部分)} else {x-- // 向上移动y++ // 同时向右移动(Z字形的斜线部分)}}// 按行扫描矩阵,收集非空字符ans := make([]byte, 0, n)for _, row := range mat {for _, ch := range row {if ch > 0 {ans = append(ans, ch)}}}return string(ans)
}
就像在网格纸上按Z字形写字,写完后再按行读出来。
方法二:压缩矩阵空间(优化空间)
func convert(s string, numRows int) string {n, r := len(s), numRowsif r == 1 || r >= n {return s}// 创建r个空切片,每个切片代表一行mat := make([][]byte, r)for i := range mat {mat[i] = make([]byte, 0)}t := r*2 - 2x := 0 // 当前行号for i, ch := range s {// 将字符添加到对应行的末尾mat[x] = append(mat[x], byte(ch))// 确定下一个字符的行位置if i%t < r-1 {x++ // 向下移动} else {x-- // 向上移动}}// 将所有行的字符连接起来ans := make([]byte, 0, n)for _, row := range mat {ans = append(ans, row...)}return string(ans)
}
不再使用完整的二维网格,而是为每一行准备一个"篮子",按Z字形顺序把字符放到对应的篮子里,最后把所有篮子里的字符按顺序倒出来。
方法三:直接构造(最优雅的方法)
func convert(s string, numRows int) string {n, r := len(s), numRowsif r == 1 || r >= n {return s}t := r*2 - 2 // 周期长度ans := make([]byte, 0, n)// 遍历每一行for i := 0; i < r; i++ {// 遍历该行中的所有字符for j := 0; j+i < n; j += t {// 添加竖线上的字符(每个周期的第一个字符)ans = append(ans, s[j+i])// 添加斜线上的字符(每个周期的第二个字符,首尾行没有)if i > 0 && i < r-1 && j+t-i < n {ans = append(ans, s[j+t-i])}}}return string(ans)
}
找到数学规律,直接计算每个字符在结果中的位置,不需要模拟Z字形路径。
找出字符串中第一个匹配项的下标(9.20.3)
这个题目就是使用KMP算法来实现的,看懂这个算法中next数组是怎么使用的就好
暴力破解
func strStr(haystack, needle string) int {n, m := len(haystack), len(needle)
outer:for i := 0; i+m <= n; i++ {for j := range needle {//发现不匹配,快速跳出循环if haystack[i+j] != needle[j] {continue outer}}return i}return -1
}
continue outer是跳过外层循环的当前迭代,直接开始外层循环的下一次迭代!break outer是跳出两层循环!
值得注意的是,每次跳出循环只是+1的匹配下一个字母,这样可能会造成很多重复的匹配,影响性能。如何增加已知匹配的使用呢?使用KMP算法
Knuth-Morris-Pratt 算法
算法核心:避免重复比较,当匹配失败时,利用已知信息跳过不必要的比较。
想象你在找一本书中的某句话:
- 暴力法:从第一页开始,每页逐字对比
- KMP法:记住已经匹配的部分,失败时直接跳到可能匹配的位置
func strStr(haystack, needle string) int {n, m := len(haystack), len(needle)if m == 0 {return 0 // 空字符串总是在开头出现}// 🎯 第一步:构建前缀表(pi数组)// pi[i] 表示:needle[0:i] 的最长公共前后缀长度pi := make([]int, m)// i: 当前正在处理的位置(后缀末尾)// j: 当前匹配的前缀长度(也是前缀的末尾位置)for i, j := 1, 0; i < m; i++ {// 🔁 关键:当字符不匹配时,回退j到前一个匹配位置for j > 0 && needle[i] != needle[j] {j = pi[j-1] // 回退到前一个匹配位置}// 如果当前字符匹配,前缀长度+1if needle[i] == needle[j] {j++}pi[i] = j // 记录当前位置的最长公共前后缀长度}// 🎯 第二步:在haystack中搜索needle// i: 在haystack中的当前位置// j: 在needle中已匹配的长度for i, j := 0, 0; i < n; i++ {// 🔁 关键:当字符不匹配时,利用前缀表回退jfor j > 0 && haystack[i] != needle[j] {j = pi[j-1] // 回退到前一个匹配位置,避免从头开始}// 如果字符匹配,继续前进if haystack[i] == needle[j] {j++}// 如果完全匹配,返回起始位置if j == m {return i - m + 1}}return -1 // 没找到
}
🧩 前缀表(pi数组)详解
以 needle = "ababc" 为例:
| i | 子串 | 最长公共前后缀 | pi[i] | 解释 |
|---|---|---|---|---|
| 0 | “a” | 无 | 0 | 单个字符无真前后缀 |
| 1 | “ab” | 无 | 0 | “a"≠"b” |
| 2 | “aba” | “a” | 1 | 前缀"a"=后缀"a" |
| 3 | “abab” | “ab” | 2 | 前缀"ab"=后缀"ab" |
| 4 | “ababc” | 无 | 0 | 不匹配 |
所以 pi = [0, 0, 1, 2, 0]
🔍 搜索过程示例
haystack = "abababc", needle = "ababc"
步骤0: i=0, j=0 → "a" vs "a" → j=1
步骤1: i=1, j=1 → "b" vs "b" → j=2
步骤2: i=2, j=2 → "a" vs "a" → j=3
步骤3: i=3, j=3 → "b" vs "b" → j=4
步骤4: i=4, j=4 → "a" vs "c" ❌ 不匹配!关键回退:j = pi[3] = 2
现在比较:haystack[4]="a" vs needle[2]="a" ✅
然后继续:j=3, i=5...最终在位置2找到:"ababc"
💡 刷题要点
- 前缀表是核心:先构建needle的前缀表
- 回退机制:匹配失败时不是回到开头,而是回退到前缀表指示的位置
- 时间复杂度:O(m+n),比暴力法O(m*n)快很多
go标签
🎯 标签的核心作用
快速跳出多层嵌套循环 - 这是刷题中最常用的场景
💡 刷题常用场景
1. 找到答案立即退出所有循环
// 在矩阵中寻找目标值
found:
for i := 0; i < n; i++ {for j := 0; j < n; j++ {if matrix[i][j] == target {fmt.Println("Found!")break found // 立即退出所有循环}}
}
2. 满足条件跳过外层当前迭代
// 检查每组数据,有一项不合格就跳过整组
group:
for _, group := range groups {for _, item := range group {if !isValid(item) {continue group // 这组不合格,检查下一组}}// 只有全合格才会执行到这里
}
3. 错误处理时快速退出
// 多步骤操作,任何一步失败都直接退出
process:
for step1() {for step2() {for step3() {if err := step4(); err != nil {break process // 任何步骤出错都退出}}}
}
🚀 刷题优势
- 代码更简洁:避免设置多个 flag 变量
- 效率更高:找到答案立即退出,不继续无用计算
- 逻辑清晰:明确表达"跳出所有循环"的意图
⚠️ 使用建议
- 只在确实需要跳出多层循环时使用
- 给标签起有意义的名字(如:
outer、search、found) - 避免过度使用,保持代码可读性
标签主要解决深层嵌套循环的快速退出问题,在算法题中很实用!
(未看)文本左右对齐(9.20.4)
// blank 返回长度为 n 的由空格组成的字符串
func blank(n int) string {return strings.Repeat(" ", n)
}func fullJustify(words []string, maxWidth int) (ans []string) {right, n := 0, len(words)for {left := right // 当前行的第一个单词在 words 的位置sumLen := 0 // 统计这一行单词长度之和// 循环确定当前行可以放多少单词,注意单词之间应至少有一个空格for right < n && sumLen+len(words[right])+right-left <= maxWidth {sumLen += len(words[right])right++}// 当前行是最后一行:单词左对齐,且单词之间应只有一个空格,在行末填充剩余空格if right == n {s := strings.Join(words[left:], " ")ans = append(ans, s+blank(maxWidth-len(s)))return}numWords := right - leftnumSpaces := maxWidth - sumLen// 当前行只有一个单词:该单词左对齐,在行末填充剩余空格if numWords == 1 {ans = append(ans, words[left]+blank(numSpaces))continue}// 当前行不只一个单词avgSpaces := numSpaces / (numWords - 1)extraSpaces := numSpaces % (numWords - 1)s1 := strings.Join(words[left:left+extraSpaces+1], blank(avgSpaces+1)) // 拼接额外加一个空格的单词s2 := strings.Join(words[left+extraSpaces+1:right], blank(avgSpaces)) // 拼接其余单词ans = append(ans, s1+blank(avgSpaces)+s2)}
}