MySQL 数据归档的技术困境与 Databend 解决之道
在企业数字化转型的浪潮中,MySQL 作为最受欢迎的开源数据库,承载着越来越多的业务数据。从最初的几百 GB,到现在动辄几个 TB 甚至数十 TB 的数据规模,MySQL 数据库的体量增长速度常常超出企业的预期。然而,一个不容忽视的现实是:这些庞大数据库中真正的热点数据往往只占 20-30%,剩下的大部分都是历史数据、日志记录和归档信息。
这种现象在各个行业都很普遍。电商平台需要保留多年的订单记录用于用户查询和监管合规;金融机构必须长期存储交易流水以满足审计要求;政务系统要保存大量的办事记录和操作日志;游戏公司积累了海量的玩家行为数据用于分析和运营。这些数据有个共同特点:具有明显的生命周期,在线一段时间后失去实时业务价值,但仍需要保留用于合规、审计或分析。与此同时,随着业务规模的扩大,现在有很多企业正在从传统的 MySQL 迁移到分布式数据库,如 TiDB、OceanBase 等原生分布式数据库。这种技术升级往往涉及大量的数据搬迁工作,如果企业平时就做好了数据归档工作,将冷数据提前分离出来,那么在进行数据库迁移时的工作负担就能大大减轻。
如何妥善处理这些"冷数据",既保证业务系统的性能,又控制存储成本,已经成为每个使用 MySQL 的企业都必须面对的问题。更重要的是,随着数据驱动业务决策的趋势越来越明显,这些历史数据的分析价值也在不断提升,企业需要的不仅仅是"存起来",更需要"用得着"。
MySQL 归档的技术困境与现有方案
现在 MySQL 常用于 OLTP 业务环境,一般会使用比较好的硬件资源来提供对外服务。MySQL 数据对外提供的数据动不动好几个 T 也是正常的。在很多业务中,数据有较强的生命周期,在线一段时间后,可能就失去业务意义。
典型的归档需求包括:某个业务下线后的历史数据、业务数据超过服务周期(例如某个业务只需要近 3 个月的数据)、业务操作的日志类型数据进行归档、分库分表的数据库需要合并到同一个地方提供统计查询及分析能力,以及定期的备份归档提供审计工作进行查询使用。
现在常见的归档方式一般分成两大类,核心工具通常是 pt-archive 或解析 binlog 获取归档的数据。
第一类:使用 MySQL 存储归档
这类方案中,一般是通过购买 PC 机,通常是大容量(50T左右)、大内存机型,可以跑实例,来对线上的生产库进行归档,甚至是备份同步。这种场景是最常见的,甚至见到在线下建一个主从,对 PolarDB 进行归档对外提供线下内网查询。
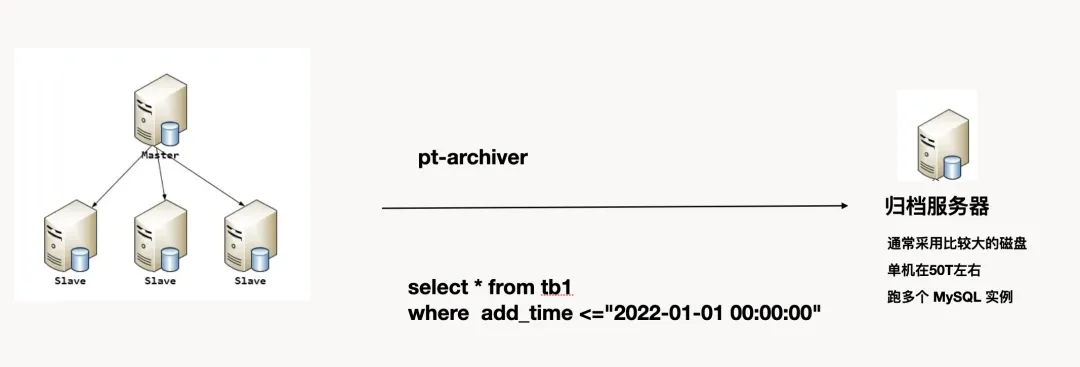
该方式的优点很明确:基于 MySQL 环境,大家都熟悉好管理;和线上环境基本能保持同一个版本及高度的兼容;归档环境可以使用大容量便宜的磁盘构建。
但这种归档服务也有明显的缺点:为了成本考虑,归档节点通常没开启 Binlog,真正的备份还会放到对象存储中一份,也没有从库,如果发生数据损坏或硬盘损坏,数据恢复周期长;计算能力不够,基本没有能力对计算节点扩展,如果需要计算,通常需要把数据抽出来放到大数据环境中计算;这种架构存在大量的 CPU 和 RAM 资源的闲置。
第二类:使用 MariaDB 归档
MariaDB 有一个特性:S3 engine,该引擎有较高的压缩能力,基本也保持了 MySQL 的使用习惯。归档流程是先写 InnoDB,然后 alter table tb_name engine=s3。
该方案的优点包括:基本保持了 MySQL 兼容能力、存储上支持 s3 类对象存储、支持高压缩存储。
该方案的缺点也很明显:s3 引擎只能读,不能写;不支持增加写入,如需改变还需要转成 InnoDB 表;每次 InnoDB 到 s3 引擎的转换需要非常长的时间,增加了复杂度。
除了这两种主流方案,还有企业选择 Hadoop 生态或云端商业数据仓库,但前者的复杂度和成本往往超出预期,后者则面临厂商锁定和高昂费用的问题。
Databend 的技术优势:云原生架构的新选择
在这些传统方案的局限性日益明显的背景下,Databend 提供了一个更完美的解决方案。
Databend 是一个使用 Rust 研发、开源、完全面向云架构的新式数仓,提供极速的弹性扩展能力,致力于打造按需、按量的 Data Cloud 产品体验。它具备以下特点:
- 开源 Cloud Data Warehouse 明星项目
- Vectorized Execution 和 Pull&Push-Based Processor Model
- 真正的存储、计算分离架构,高性能、低成本,按需按量使用
- 完整的数据库支持,兼容 MySQL、Clickhouse 协议,SQL Over HTTP 等
- 完善的事务性,支持 Time Travel、Database Clone、Data Share 等功能
- 支持基于同一份数据的多租户读写、共享操作
Databend 设计上遵循几个重要原则:
1.No Partition
2.No index(Auto Index)
3.Support Transaction
4.Data Time travel/Data Zero copy clone/Data Share
5.Enough Performance/Low Cost
部署和使用方式
Databend 支持 MySQL、Clickhouse、SQL Over Http 三种方式的处理,这种多协议支持为不同的业务场景提供了灵活性。
数据写入的多样化选择
Databend 提供了三种主要的数据写入方式:
-
Insert into 写入:支持 JDBC、Python、Golang 进行 insert 写入。如果要使用 insert 写入,建议使用 Bulk insert 增加批量写入。这个使用上和 MySQL 没有什么区别。
-
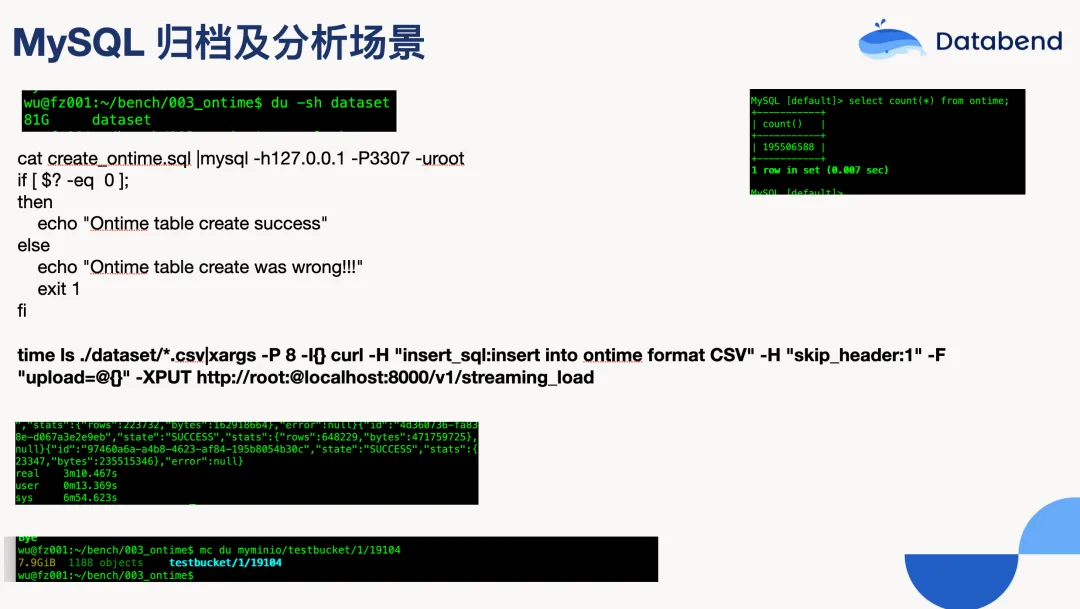
Streaming load:专为大批量数据设计,性能表现相当出色。实际测试显示,81G 的文件、近 2 亿数据导入 Databend 只需要 3 分钟多一点。另外 Databend 也支持直接读取压缩文件,虽然性能还有提升空间。
- 基于 stage 写入:Stage 可以理解为 Databend 的一个网盘管理功能。可以创建 Stage、上传文件、查看文件,通过 copy into 的命令直接将 Stage 的文件加载到 Databend 的表中。

真实案例:从理论到实践的验证
MySQL 归档到 Databend 的最佳实践方案
基于我们接触过的大量真实案例经验,对于需要考虑 MySQL 归档的场景,建议可以考虑使用 Databend 加对象存储来替代传统方案。
利用 Databend 归档 MySQL 可以获得显著的优势:
- 基于 对象存储 基本可以实现容量无限。不再需要担心磁盘空间不够的问题,也不需要提前规划容量。
- Databend 数据压缩 比较高,正常情况下可以做到 10:1,大大降低存储空间需求。这个压缩比比传统的 MySQL 存储要优秀很多。
- 可以基于 MySQL 协议管理数据,对使用上基本可以做到没有任何变化。现有的 MySQL 客户端、工具、应用程序都可以直接使用,学习成本几乎为零。
- 存算分离架构,对于计算层不足的情况下,可以非常方便的扩容,也无须担心存储的高可用。当需要进行复杂分析时,可以动态增加计算资源,而不需要担心存储层的扩展问题。
- 原来 MySQL 生态的工具基本可以重用。无论是监控工具、备份工具还是数据分析工具,都可以继续使用。
Databend 现在对象存储支持相当广泛:AWS S3、Azure、阿里云、腾讯云、青云、金山云以及 minio、ceph 等设备。同时 Databend 的计算能力很强,如果需要分析,可以直接在 Databend 中进行计算,而不需要把数据再导出到其他分析系统中。
利用 Databend 可以帮助用户更方便地使用云上的资源,让用户可以获得足够的性能及较低的成本。这种架构既解决了传统 MySQL 归档方案的性能瓶颈,又避免了 MariaDB S3 引擎方案的使用限制,为企业提供了一个真正实用的归档解决方案。
除了帮助 MySQL 数据库归档,Databend 也可以对前文提到的 TiDB 和 Oceanbase 等数据库进行归档,降低数据存储成本。以下是两个真实案例:
案例一:多点的 TiDB 归档实战
多点作为新零售领域的代表企业,面临着典型的数据爆炸式增长挑战。他们的核心业务系统运行在 TiDB 集群上,随着业务规模扩大,数据量呈指数级增长,给存储和管理带来了巨大压力。传统的做法是将所有数据都保留在 TiDB 中,但这种方式的问题逐渐显现:不仅占用了大量存储资源,还影响了在线业务的查询性能。
技术团队意识到需要一个更高效的归档方案。他们选择了 Databend 作为归档目标,并使用了 db-archiver 这个专门的归档工具。这个工具的设计相当巧妙,支持多种数据源(MySQL、TiDB、PostgreSQL、Oracle 等),并且内置了智能的数据切片算法。
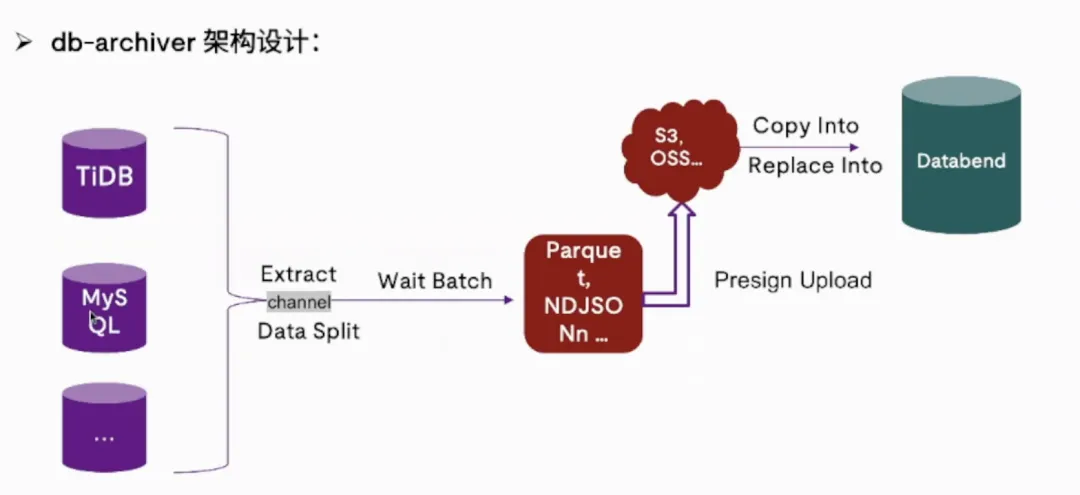
具体的归档流程是这样的:db-archiver 会根据用户配置的同步范围、线程数量和批次大小,自动将源端数据切分成多个小片段,然后通过多线程并行处理。每个线程会将抽取的数据攒批,生成 Parquet 或 JSON 格式的文件上传到对象存储,最后利用 Databend 的 COPY INTO 或 REPLACE INTO 命令完成数据导入。
在具体实施过程中,多点的工程师们发现了一个有趣的细节。最初同步速度并不理想,通过 db-archiver 内置的丰富监控指标,他们发现瓶颈出现在 upload stage(文件上传到对象存储的环节)。进一步排查发现,运行 db-archiver 的机器与目标对象存储不在同一个地域,产生了跨网段传输的性能损失。将部署节点调整到与源端、目标端相同的区域后,同步效率立即得到了显著提升。
最终的效果令人印象深刻。在压缩测试中,将 150GB 的 MySQL 数据分别导入 TiDB 和 Databend,TiDB 通过 RocksDB 实现了 6 倍的压缩比,而 Databend 达到了 8 倍的压缩比。但真正让人震惊的是成本数据:整体数据存储成本降低了 98%。
这个惊人的数字背后有三个关键因素:
首先是副本数量的差异。TiKV 需要维护 3 个副本来保证高可用,而 Databend 基于对象存储只需要一份数据(对象存储服务商会在后台处理冗余备份)。
其次是存储预留的问题。传统数据库通常需要预留 20-30% 的磁盘空间以防止写满,但对象存储可以按需扩展,无需预留。
最重要的是存储单价的巨大差异。对象存储相比普通 HDD 硬盘成本约为 1/10,相比 SSD 更是只有 1/30。综合计算:(1/3 副本) × (60% 磁盘利用率) × (1/10 磁盘价格) = 2% 的存储成本。
全文阅读:
https://mp.weixin.qq.com/s/kkfz0wlHA4_7QXJqymQxvw
案例二:OceanBase 到 Databend Cloud 的云原生归档
另一个案例展示了云原生架构在归档场景中的优势。某企业使用 OceanBase 作为核心数据库,随着业务发展面临同样的归档需求。他们选择了 Databend Cloud 作为归档目标,这个方案的亮点在于完全基于云基础设施,实现了真正的按需付费。
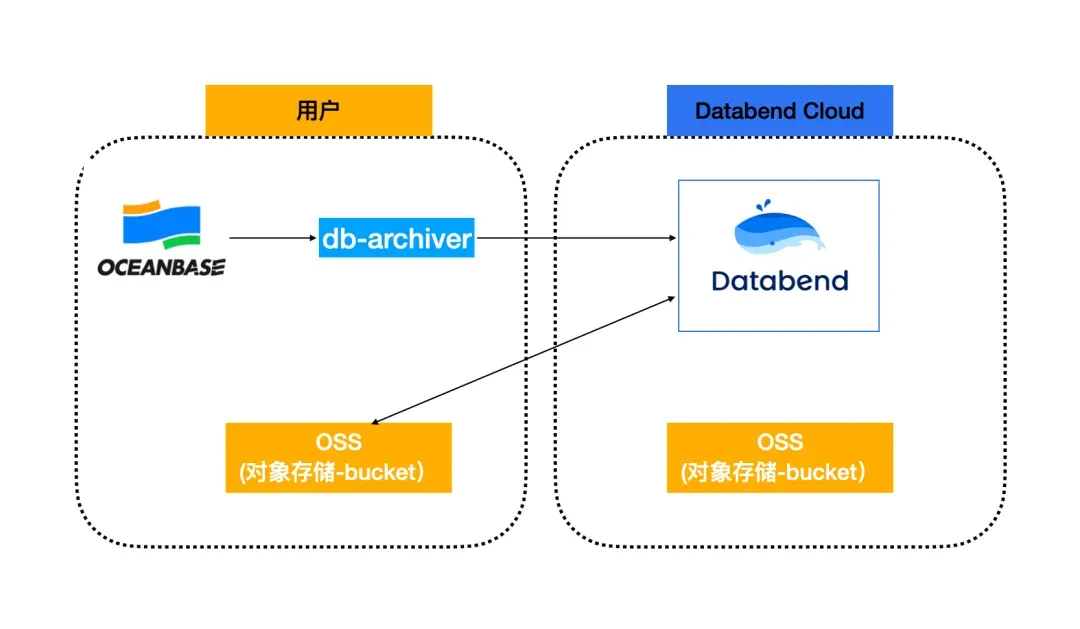
技术架构相当简洁:使用 db-archiver 连接 OceanBase 读取数据,写入 Databend Cloud,而 Databend Cloud 通过外部表将数据存储在用户自己的对象存储桶中。当不进行计算时,Databend Cloud 不会产生任何费用,只有对象存储的存储成本。
在具体实施中,他们遇到了一些有意思的技术细节。比如在创建外部表时,需要先建立与对象存储的连接:
CREATE OR REPLACE CONNECTION wubx_ossSTORAGE_TYPE = 'oss' ENDPOINT_URL='oss-cn-beijing-internal.aliyuncs.com' ACCESS_KEY_ID = '用户AK' ACCESS_KEY_SECRET = '用户SK';然后创建外部表,指定数据在对象存储中的具体位置:
CREATE TABLE sbtest1 (id int(11) NOT NULL,k int(11) NOT NULL DEFAULT '0',c char(120) NOT NULL DEFAULT '',pad char(60) NOT NULL DEFAULT ''
)
'oss://wubx-bj01/wubx/'
CONNECTION=(CONNECTION_NAME='wubx_oss'
);db-archiver 的配置文件也展现了工具的灵活性。可以通过 sourceSplitKey 指定按主键 ID 切分,也可以通过 sourceSplitTimeKey 和 timeSplitUnit 实现按时间维度的归档。这种设计让工具能够适应不同的业务场景。
这个案例的优势在于完全利用了云上基础设施的弹性。存储按需付费,计算资源可以秒级伸缩,而且基于无运维架构,大大降低了维护复杂度。
全文阅读:
https://mp.weixin.qq.com/s/ynUcnfUFZGdiXIChpUKuRg
告别数据坟墓:重新思考历史数据的价值
随着企业数字化程度的不断加深,数据归档已经从单纯的"存储管理"问题演进为"数据资产管理"问题。传统的归档方案往往把历史数据当作负担,想方设法降低存储成本,但很少考虑这些数据的潜在价值。
现代的归档方案需要在三个维度上找到平衡:成本控制、数据可用性和分析能力。Databend 这样的云原生数据仓库恰好在这三个方面都有出色表现。它不仅大幅降低了存储成本,更重要的是让归档数据保持了"活性"——可以随时查询、分析,甚至进行机器学习训练。
从多点的 98% 成本降低,到 OceanBase 归档方案的云原生实践,这些真实案例证明了现代归档技术的价值。对于仍在使用传统归档方案的企业来说,现在是重新审视数据架构的好时机。继续把所有数据堆在单一的 MySQL 实例中,在成本、性能和数据价值挖掘上都不是最优选择。
同时,随着 AI 和机器学习技术的普及,企业对历史数据的需求会进一步增长。那些建立了现代化归档体系的企业,势必将在数据驱动的竞争中获得先发优势。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab…