【Haddop】Hive的离线分析与Sqoop的数据集成
本专栏文章持续更新,新增内容使用蓝色表示。
一、Hive
Hive 是一个基于 Hadoop 的数据仓库工具,专门用于解决海量结构化日志数据的统计与分析问题。它提供了一套类 SQL 查询语言 HQL(Hive Query Language),使得传统数据库开发人员能够轻松处理大数据任务。
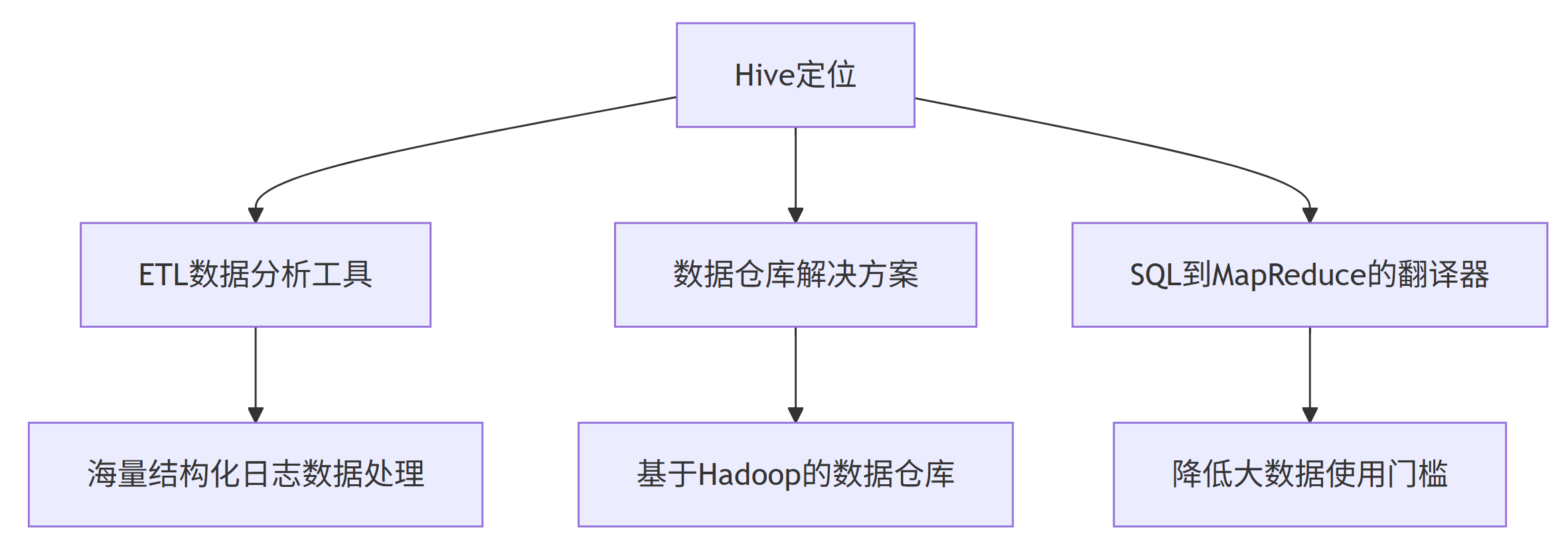
核心定位:ETL(Extraction-Transformation-Loading)数据分析工具。
1.1 产生原因
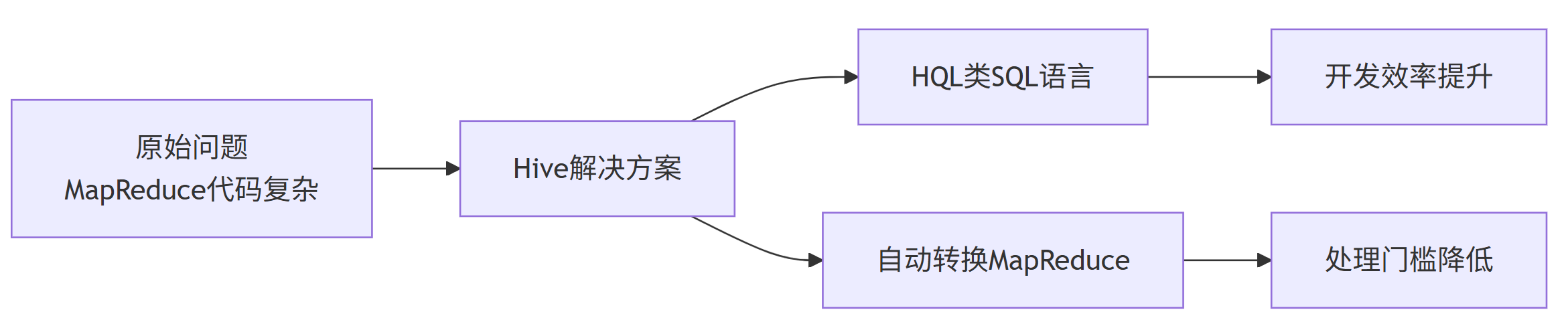
Hadoop 开源后,虽然解决了大数据存储和计算的基本问题,但 MapReduce 代码编写复杂、开发效率低下。Hive 应运而生,通过将 HQL 语句转换为 MapReduce 任务,大大降低了大数据处理的门槛。
1.2 架构演进
传统Hive:计算使用 MapReduce,存储使用 HDFS。
现代Hive:支持多种计算引擎(包括Spark、Tez等),提升计算效率。
1.3 系统架构
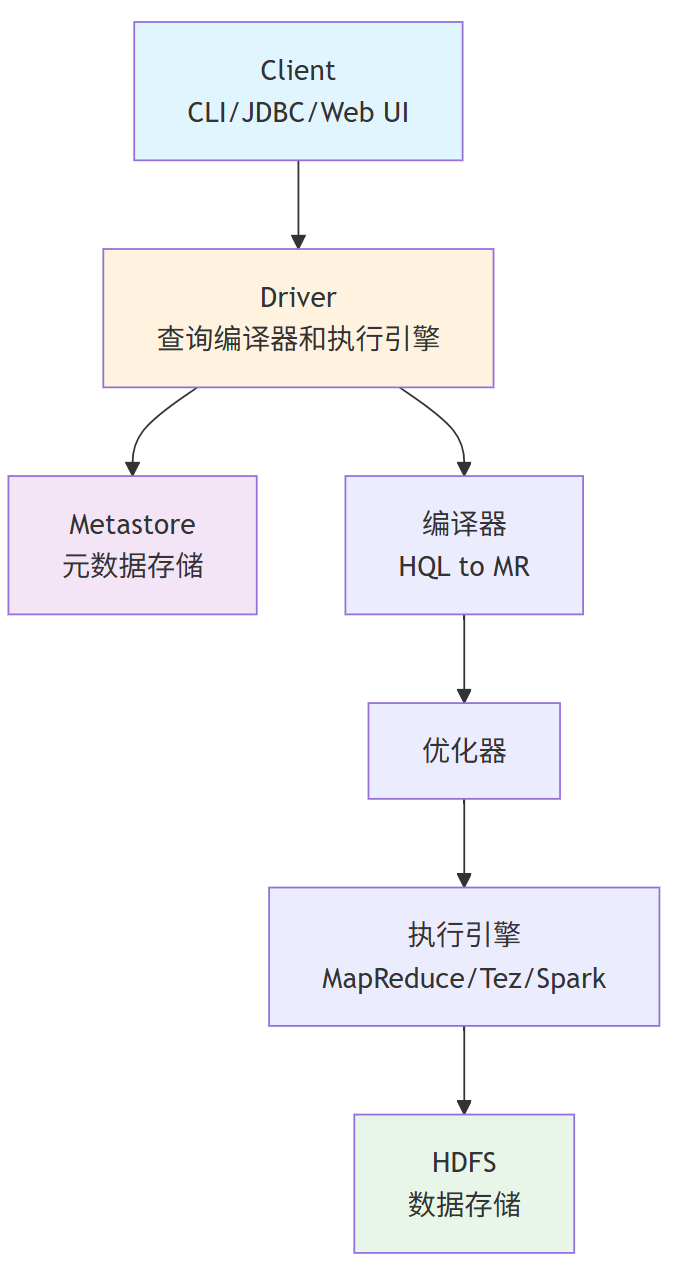
1.4 工作流程
1)用户提交HQL:通过 CLI、JDBC 等接口向 Driver 提交查询。
2)获取元数据:Driver 与 Metastore 交互,获取表结构、分区等元信息。
3)编译与优化:编译器将 HQL 字符串转换为逻辑计划 -> 优化器进行优化 -> 执行引擎将逻辑计划转换为物理计划(MR/Tez/Spark作业)。
4)执行与返回:执行引擎与计算框架和存储层交互,执行任务并返回最终结果。
二、Hive的核心概念
2.1 数据模型
表(Table):与关系数据库中的表类似,包含行和列。
分区(Partition):根据特定列的值对数据进行划分,提高查询效率。
分桶(Bucket):对每个分区或表中的数据进一步细分,用于优化 join 操作和采样。
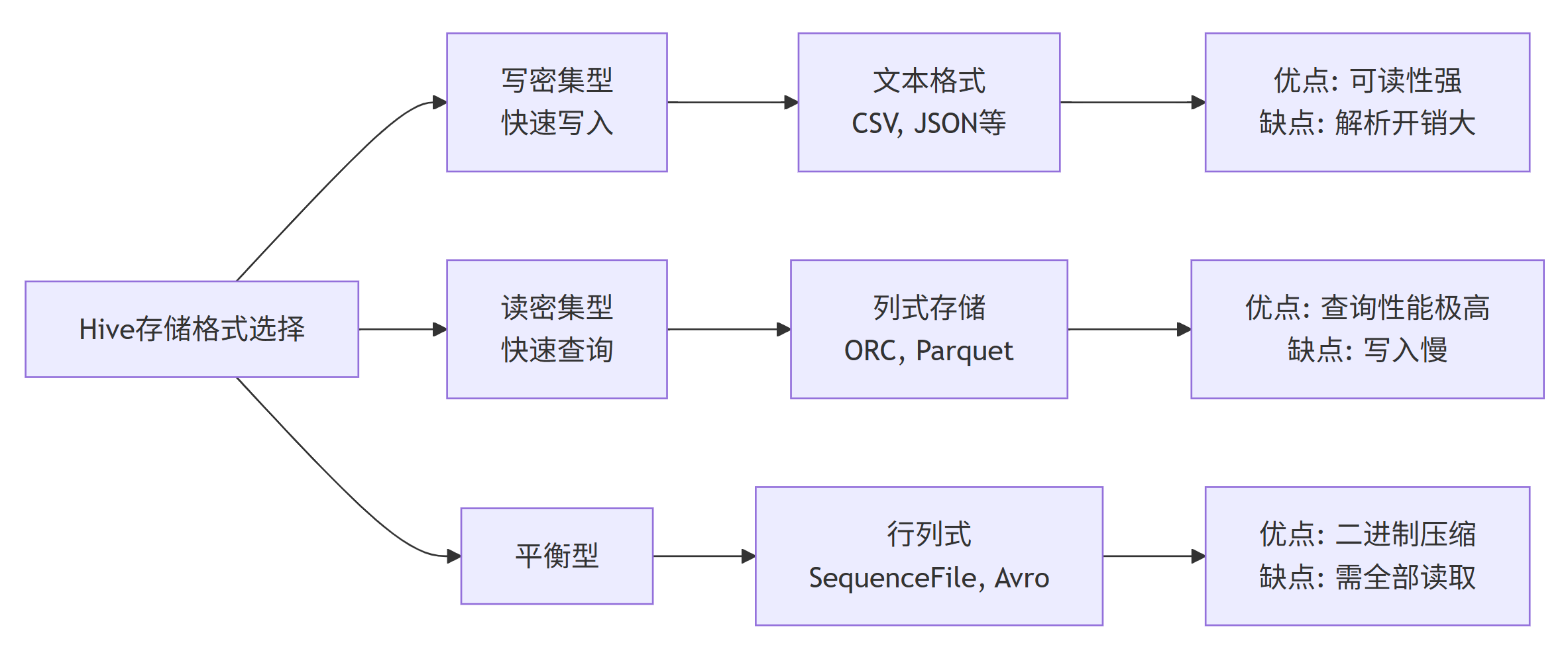
2.2 存储格式
Hive支持多种存储格式,每种格式都有其适用场景:
2.3 主要优势
易用性强:类 SQL 语法,学习成本低。
扩展性好:基于 Hadoop 生态系统,可处理 PB 级数据。
元数据统一管理:通过 HCatalog 实现元数据共享。
生态系统完善:与 Hadoop 生态工具无缝集成。
2.4 主要局限性
表达能力有限:迭代算法和复杂运算难以表达。
性能瓶颈:自动生成的 MapReduce 作业效率不高。
实时性差:适合离线批处理,不支持实时查询。
调优困难:优化粒度较粗,可控性较差。
三、Hive与 Pig 的对比
3.1 Hive vs Pig
相同点:
– Hive 和 Pig 都运行在 Hadoop 之上。
– 设计目的都是为用户提供一种更简单的在 Hadoop 上进行数据分析的方式,解决相同问题。
不同点:
| 特性 | Hive | Pig |
|---|---|---|
| 数据要求 | 需要 Schema | 无 Schema 要求 |
| 安装部署 | 需要安装 Server | 无需安装 Server |
| 编程语言 | HQL(声明式) | Pig Latin(过程式) |
| 设计哲学 | 告诉系统要什么结果 | 告诉系统如何处理数据 |
3.2 Hive的演进版本
Stinger:下一代 Hive,使用 Tez 替代 MapReduce。
优势:DAG 计算框架,减少磁盘 IO,充分利用内存。
特点:提供多种算子,作业合并优化。
Shark(Hive on Spark):
完全兼容 Hive,底层使用 Spark 计算引擎。
内存计算,效率比 MapReduce 提升百倍。
3.3 适用场景
– 海量结构化数据的离线批处理;
– 数据仓库建设和 ETL 处理;
– 传统 SQL 开发人员的大数据分析;
– 需要与 Hadoop 生态系统集成的场景。
3.4 不适用场景
– 实时数据分析和流处理;
– 迭代式计算和复杂机器学习算法;
– 低延迟的交互式查询。
3.5 性能优化技巧
1)分区和分桶:合理使用分区和分桶大幅提升查询性能。
2)选择合适的文件格式:ORC 和 Parquet 格式在大多数场景下性能更优。
3)压缩数据:使用 Snappy 或 LZO 压缩减少存储空间和 IO 开销。
4)向量化查询:启用向量化查询执行提升 CPU 利用率。
四、Sqoop
Sqoop(SQL-to-Hadoop)是一个用于在 Hadoop 生态系统与传统关系型数据库之间高效传输批量数据的工具。它充当了两者之间的桥梁,解决了数据迁移和集成的关键问题。
核心定位:关系型数据库与 Hadoop 系统之间的数据交换工具。
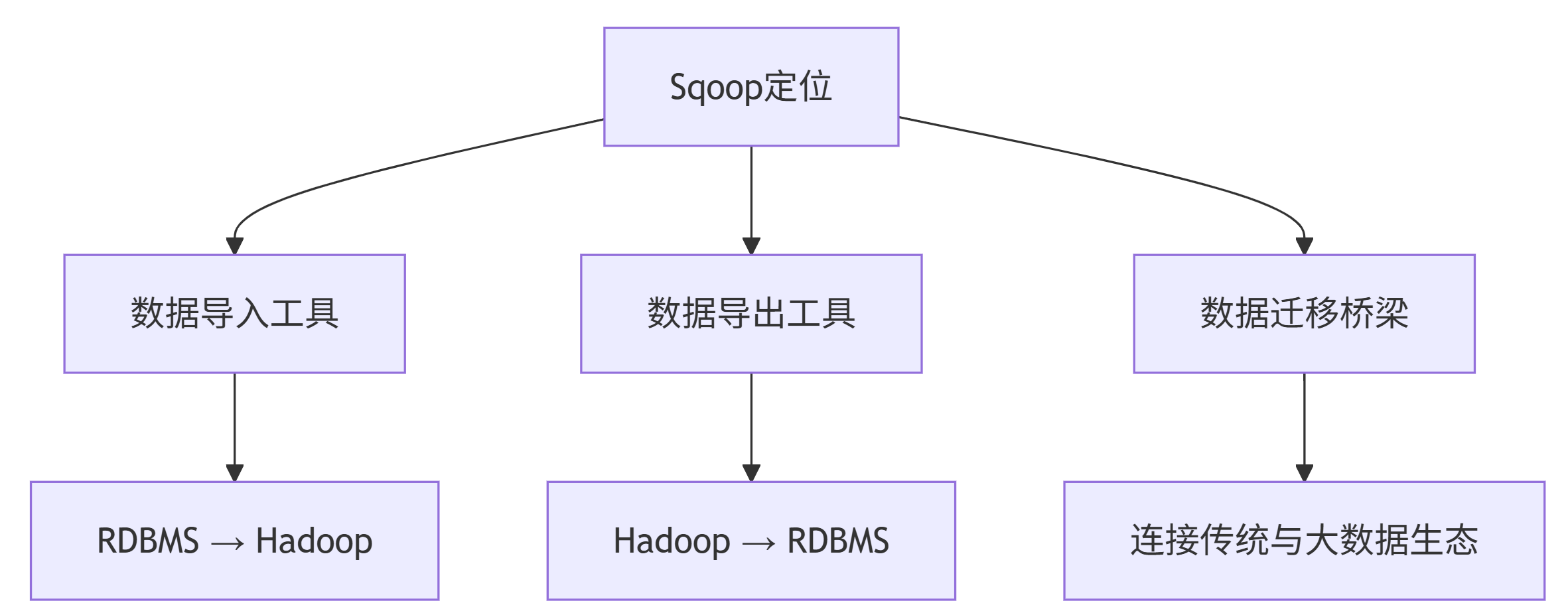
4.1 主要功能
数据导入:将关系型数据库的数据导入到 Hadoop 系统(如HDFS、HBase和Hive)。
数据导出:将数据从 Hadoop 系统抽取并导出到关系型数据库。
批量处理:采用批处理方式进行数据传输(静态的,非流式)。
并行传输:利用 MapReduce 框架加速数据传输过程。
4.2 核心优势
– 支持任务并行度调节、超时时间配置等资源控制;
– 自动完成数据类型映射与转换(支持用户自定义);
– 支持Oracle、MySQL、PostgreSQL等主流数据库;
– 提供命令行接口,使用简便。
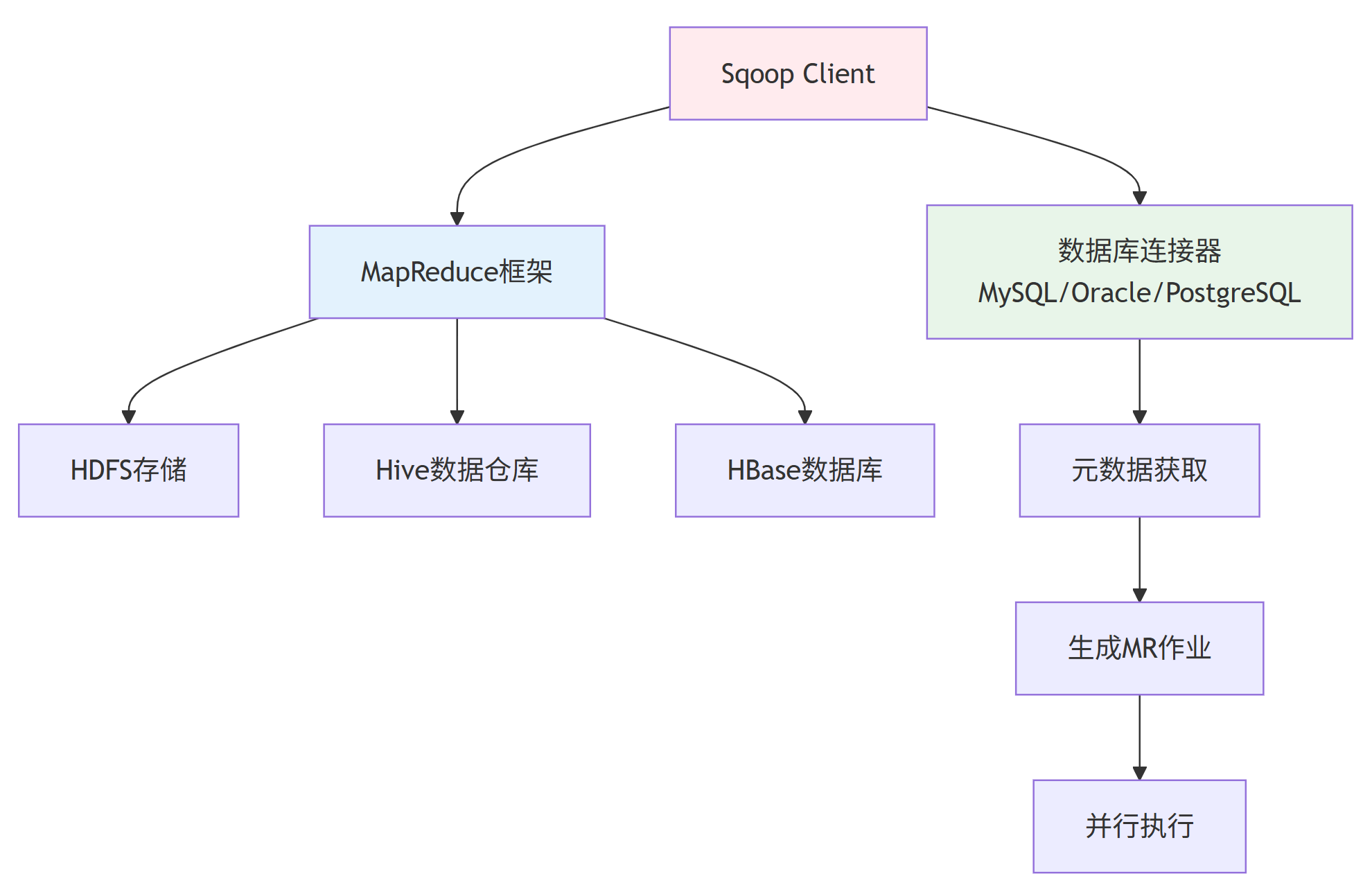
4.3 系统架构
4.4 数据导入(Import)流程
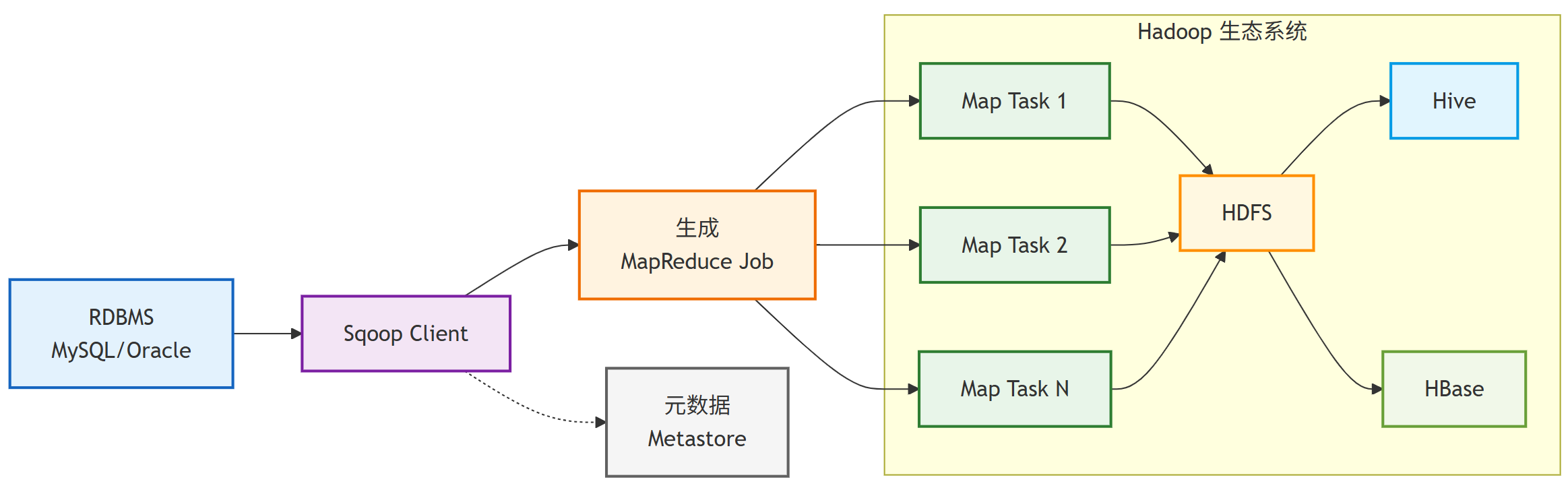
(导出流程是反向的,原理类似,即从HDFS读取数据,通过MR作业并行写入RDBMS。)
1)元数据获取:Sqoop 首先与数据库服务器通信,获取数据库表的元数据信息。
2)作业生成:根据元数据信息生成 Map-Only 的 MapReduce 作业。
3)并行处理:每个 Map Task 负责传输一部分数据,实现并行化处理。
4)数据写入:将数据并行写入 Hadoop 目标系统。
4.5 数据导出(Export)流程
1)元数据获取:Sqoop 与数据库服务器通信,获取目标表的元数据信息。
2)数据划分:将 Hadoop 上的文件划分成若干个 split。
3)并行导出:每个 Map Task 负责一个 split 的数据导入到数据库。
4)事务处理:确保数据的一致性和完整性。
4.6 性能优化策略
– 根据数据库和 Hadoop 集群性能调整 Map Task 数量;
– 优化每次传输的数据量大小;
– 使用直接连接器(如mysql-direct)提高传输效率;
– 启用数据压缩减少网络传输时间;
– 设置适当的错误容忍度以提高作业成功率。
4.7 典型应用场景
– 数据仓库定期 ETL 流程;
– 历史数据迁移到 Hadoop 平台;
– 数据分析结果导出到业务数据库;
– 传统系统与大数据平台的数据同步。
总结
Hive 负责数据分析,Sqoop 负责数据同步。
如有问题或建议,欢迎在评论区中留言~