多层感知机(MLP)
一、感知机基础
1.1 定义与提出
- 核心逻辑:接收输入信号,通过权重和偏差计算,输出二分类结果(0 或 1)。
1.2 核心公式与参数
- 输出公式:
- 当b+w1x1+w2x2≤0时,输出y=0;
- 当b+w1x1+w2x2>0时,输出y=1。
- 参数含义:
- 权重(w):控制输入信号的重要性,权重越大,对应输入对输出的影响越强。
- 偏置(b):调整神经元被激活的容易程度,偏置值越大,神经元越容易被激活输出 。
1.3 与其他任务输出对比
| 任务类型 | 输出特点 |
|---|---|
| 感知机(二分类) | 仅输出 0 或 1,实现二分类 |
| 回归任务 | 输出连续的实数,用于预测数值 |
| Softmax(多分类) | 输出各类别的概率,概率和为 1,用于多分类 |
1.4 经典应用:逻辑电路实现
通过设定不同的权重(w1, w2)和偏置(b),感知机可实现与门、与非门、或门等简单逻辑电路,具体参数与真值表如下:
与门
真值表:
x1 | x2 | y |
0 | 0 | 0 |
1 | 0 | 0 |
0 | 1 | 0 |
1 | 1 | 1 |
满足条件的参数:(0.5, 0.5, -0.7)、(0.5, 0.5, -0.8)、(1.0, 1.0, -1.0)等。
与非门
真值表:
x1 | x2 | y |
0 | 0 | 1 |
1 | 0 | 1 |
0 | 1 | 1 |
1 | 1 | 0 |
满足条件的参数:(-0.5, -0.5, 0.7)。
或门
真值表:
x1 | x2 | y |
0 | 0 | 0 |
1 | 0 | 1 |
0 | 1 | 1 |
1 | 1 | 1 |
满足条件的参数:(0.5, 0.5, -0.3)。
异或门(感知机无法实现)
真值表:
x1 | x2 | y |
0 | 0 | 0 |
1 | 0 | 1 |
0 | 1 | 1 |
1 | 1 | 0 |
问题:无法通过单一感知机设定权重和偏置实现,暴露了感知机的局限性。
二、感知机的局限性与多层感知机的诞生
2.1 感知机局限性
- 核心问题:仅能表示由一条直线分割的线性空间,无法处理线性不可分问题(如异或门)。
- 示例:异或门的输入输出关系,无法用一条直线将 “输出 1” 和 “输出 0” 的样本完全分开。
2.2 多层感知机(MLP)的定义与作用
- 本质:最简单的深度神经网络,通过引入隐藏层,将线性不可分问题转化为更高维度空间中的线性可分问题,实现用非线性曲线划分空间。
- 结构:输入层 → 隐藏层(可多层) → 输出层。
三、多层感知机核心组件
3.1 网络结构
单隐藏层结构
- 组成:包含输入层、1 个隐藏层、输出层。
- 隐藏层:隐藏层的神经元数量(隐藏层大小)是超参数,需根据任务调整。
- 示例:
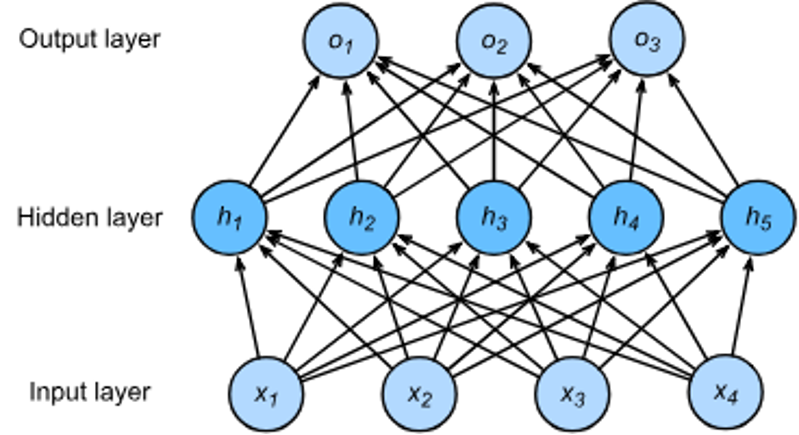
多隐藏层结构(用于多分类)
- 组成:输入层 → 多个隐藏层 → 输出层。
- 适用场景:处理更复杂的多分类任务,通过增加隐藏层深度提升模型表达能力。
3.2 激活函数
定义与作用
- 定义:将神经元输入信号的总和转换为输出信号的函数,决定神经元是否 “激活”。
核心作用:为网络引入非线性,使多层感知机能够拟合复杂的非线性关系(若没有激活函数,多层网络等价于单层感知机)。
必备性质:
- 连续且可导(允许少数点不可导)的非线性函数;
- 函数及其导函数形式简单,便于计算,提升网络效率;
- 导函数的值域在合适区间,避免过大或过小影响训练稳定性和效率。
常见激活函数
| 激活函数 | 函数特点 | 输出范围 |
|---|---|---|
| 阶跃函数 | 以 0 为界,输入>0 输出 1,否则输出 0 | {0, 1} |
| Sigmoid 函数 | 平滑的 “S” 形曲线,将输入映射到 0-1 之间 | (0, 1) |
| tanh(双曲正切) | 类似 Sigmoid,但中心对称,映射输入到 - 1-1 之间 | (-1, 1) |
| ReLU(线性修正函数) | 输入>0 时输出输入值,否则输出 0,缓解梯度消失问题 | [0, +∞) |
3.3 超参数
- 定义:训练前需人工设定的参数,无法通过模型训练自动学习。
- 核心超参数:
- 隐藏层数量:隐藏层越多,模型复杂度越高,需平衡拟合能力与过拟合风险;
- 每层隐藏单元数目(隐藏层大小):单元数越多,每层表达能力越强,但计算成本也越高。
四、多层感知机的学习过程
4.1 学习本质
通过外界输入样本的刺激,动态调整网络的连接权值(甚至拓扑结构),使网络输出不断接近期望输出。
4.2 核心流程:前向传播与反向传播
前向传播(正向传播)
- 路径:输入样本 → 输入层 → 各隐藏层(逐层计算激活值) → 输出层(得到预测结果)。
- 作用:根据当前网络参数,计算模型对输入样本的预测输出。
反向传播(误差反传)
- 路径:输出层(计算预测值与真实值的误差) → 各隐藏层(逐层反向计算误差对参数的梯度) → 输入层。
- 作用:通过梯度下降法,根据误差调整各层的权值和偏置,最小化模型误差。
4.3 参数更新
- 依据:反向传播计算得到的参数梯度。
- 目标:通过梯度下降等优化算法,更新权重和偏置,使模型在训练数据上的误差逐步减小。
五、模型评估与优化
5.1 误差类型
| 误差类型 | 定义 | 示例 |
|---|---|---|
| 训练误差 | 模型在训练数据集上的误差 | 用历年考试真题训练,模型在真题上的错误率 |
| 泛化误差 | 模型在新的未知数据集上的误差 | 用历年真题训练的模型,在未来新考试中的错误率 |
5.2 数据集划分
为准确评估训练误差和泛化误差,需将数据划分为三类:
- 训练数据集:用于模型训练,更新参数;
- 验证数据集:用于评估模型在训练过程中的好坏,调整超参数(如隐藏层大小),通常占训练数据的 50% 左右,需与训练集严格区分;
- 测试数据集:仅用于评估最终训练完成的模型性能,理论上只能使用一次(如高考作为最终 “测试”)。
5.3 K - 折交叉验证
- 适用场景:当数据量不足时,用于更充分地利用数据评估模型。
- 算法步骤:
- 将训练数据均匀划分为 K 个部分;
- 依次选择第 i(i=1 到 K)部分作为验证集,其余 K-1 部分作为训练集训练模型;
- 计算 K 次验证的误差平均值,作为模型的最终验证误差。
- 常见 K 值:5 或 10。
5.4 过拟合与欠拟合
定义与表现
| 问题类型 | 定义 | 表现 |
|---|---|---|
| 过拟合 | 模型 “过度学习” 训练样本的特点,将样本的个别特性当作所有数据的普遍规律 | 训练误差极低,但泛化误差很高(如学生死记硬背真题,考试时遇到新题就出错) |
| 欠拟合 | 模型未充分学习训练样本的普遍规律,表达能力不足 | 训练误差和泛化误差都很高(如学生未理解知识点,真题和新题都做不好) |
影响因素
- 模型复杂度:
- 复杂度过低(如隐藏层少、单元数少)→ 欠拟合;
- 复杂度过高(如隐藏层多、单元数多)→ 过拟合;
- 关键:找到 “最佳复杂度”,平衡训练误差和泛化误差。
- 数据复杂度:
- 样本数量:数量过少易导致过拟合,数量充足有助于模型学习普遍规律;
- 特征数量:特征不足可能欠拟合,特征冗余可能增加过拟合风险;
- 数据多样性:数据分布单一易导致模型泛化能力差;
- 时间 / 空间结构:若数据存在时序或空间关联,需特殊处理(如时序数据需考虑序列信息)。
解决方法
- 过拟合缓解:
- 权重衰减:通过在损失函数中加入权重的 L1/L2 正则项,限制权重过大;
- 暂退法(丢弃法):训练时随机 “丢弃” 部分神经元,防止模型过度依赖特定神经元;
- 增加训练数据量,提升数据多样性。
- 欠拟合缓解:
- 增加模型复杂度(如增加隐藏层数量、隐藏单元数);
- 补充更多特征,提升数据的信息丰富度。
六、总结
- 多层感知机核心:通过引入隐藏层和激活函数,解决感知机无法处理的线性不可分问题,是最简单的深度神经网络;
- 关键组件:
- 网络结构:输入层、隐藏层(超参数:层数和单元数)、输出层;
- 激活函数:提供非线性,常用 Sigmoid、tanh、ReLU;
- 多分类处理:使用 Softmax 函数输出类别概率。
- 学习过程:通过前向传播计算预测值,反向传播计算梯度并更新参数,本质是调整权值优化模型;
- 模型评估与优化:通过划分训练 / 验证 / 测试集、K - 折交叉验证评估误差;通过控制模型复杂度、数据增强、正则化(权重衰减、暂退法)解决过拟合 / 欠拟合问题。