Elasticsearch的自定义score评分
目录
- 一、ES默认评分规则
-
- 1、评分示例介绍
- 2、评分示例解读
- 二、自定义评分检索
-
- 1、自定义评分&相关度
- 三、Function score查询
-
- 1、functions评分函数
-
- 1.1、filter & weight
- 1.2、ES评分模式【脚本或随机】
- 2、score_mode评分组合方式
- 3、boost_mode评分组合方式
- 4、functions相关示例及解读
- 四、Boosting查询
- 五、Script score查询
一、ES默认评分规则
1、评分示例介绍
Post /**/_doc/_search{"query": {"bool": {"must": [{"term": {"tenantsid": 563651117638208}}],"should": [{"match": {"file_context": "测试"}}]}},"from": 0,"size": 10,"_source": {"excludes": []}
}
====返回结果有得分_score
{
“_index”: “****”,
“_type”: “_doc”,
“_id”: “663b238d170cf70041bcd5b3”,
“_score”: 4.693205
}
当增加自定义排序sort后
{"query": {"bool": {"must": [{"term": {"tenantsid": 563651117638208}}],"should": [{"match": {"file_context": "测试"}}]}},"from": 0,"size": 12,"sort": [{"doc_view_number": {"order": "desc"}},{"create_time.keyword":{"order": "desc"}}],"track_scores": true, //先不加"_source": {"excludes": []}
}
===当使用自定义排序(如按字段值排序)时,Elasticsearch 默认不会计算相关性得分(因为排序不依赖它),因此 _score 为 null。
加上"track_scores": true后,会有得分_score数据。
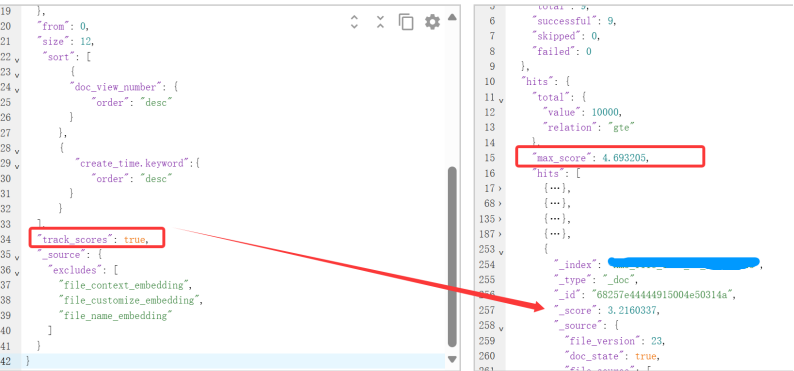
总结说明:在使用Elasticsearch进行全文搜索的时候,默认是使用BM25计算的_score字段进行降序排序的。当自定义排序时,默认是不会计算相关性得分(因为排序不依赖它),即_score 为 null。加了 “track_scores”: true,_score不为null。
=====现在有要求,需要自定义排序特性,同时要求在按照得分进行排序,那么Elasticsearch提供了function_score的DSL来自定义打分,这样就可以根据自定义的_score来进行排序。
2、评分示例解读
Elasticsearch 中查询结果的 _score 表示文档与查询条件的相关性得分,用于衡量文档匹配查询条件的程度。得分越高,说明文档与查询的匹配度越高,相关性越强。_score 是一个相对值(通常为正数),仅在当前查询的上下文中有意义,不同查询之间的得分不具可比性。
计算依据:
基于 Lucene 的 TF/IDF 算法(词频 - 逆文档频率):查询词在文档中出现的次数越多,得分越高。查询词在整个索引中出现的文档越少(越稀有),得分越高。
其他因素:
如字段长度(短字段中的匹配词权重更高)、查询类型(match/bool 等不同查询有不同的评分逻辑)、boost 权重设置等。
{"query": {"bool": {"must": [{"term": {"tenantsid": 563651117638208}}],"should":