论文阅读:TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS
abstract
图神经网络( Graph Neural Networks,GNNs )由于能够学习复杂的关系或相互作用的系统,最近变得越来越流行。这些问题产生于从生物学和粒子物理学到社交网络和推荐系统等广泛的问题中。尽管有大量不同的模型用于图上的深度学习,但很少有人提出用于处理本质上是动态的( e.g.随时间演化的特征或连通性)图的方法。我们提出了时态图网络( Temporal Graph Networks,TGNs ),一种通用的、高效的深度学习框架,该框架在动态图上表示为时间事件序列。 得益于记忆模块(memory modules)和基于图的运算器(graph-based operators)的新组合,TGNs显著优于以前的方法,同时具有更高的计算效率。此外,我们还表明,以前的几个学习动态图的模型可以作为我们的框架的具体实例。我们对我们的框架的不同组成部分进行了详细的消融研究,并设计了在几个动态图的转导和归纳预测任务上达到最新性能的最佳配置。
contributions
在本文中,我们首先提出了在以事件序列表示的连续时间动态图上运行的时序图网络( TGNs )的通用归纳框架(inductive framework,可以用于新出现的数据),并表明以前的许多方法都是TGNs的特定实例。
其次,我们提出了一种新颖的训练策略,允许模型从数据的时序性中学习,同时保持高效的并行处理。
第三,我们对框架的不同组成部分进行了详细的消融研究,并分析了速度和精度之间的权衡。
最后,在直推式和归纳式场景下,我们在多个任务和数据集上展示了最新的性能,同时比以前的方法快得多。
Continuos-time dynamic graphs (CTDG)
连续时间动态图( CTDG )更具有一般性,可以表示为事件的时间列表,其中可能包括边的添加或删除、节点的添加或删除以及节点或边的特征变换。详细介绍如下:


1. TEMPORAL GRAPH NETWORKS
遵循( Kazemi et al , 2020)中的术语,动态图的神经模型可以看作是一个编码器-解码器对,其中编码器是一个从动态图映射到节点嵌入的函数,解码器将一个或多个节点嵌入作为输入,并进行特定任务的预测,如节点分类或边缘预测。本文的主要贡献是提出了一种新的时态图网络( Temporal Graph Network,TGN )编码器,该编码器应用于连续时间动态图,表示为时间戳事件序列,并为每个时间t产生图节点的嵌入
![]()
。整体流程图如下:
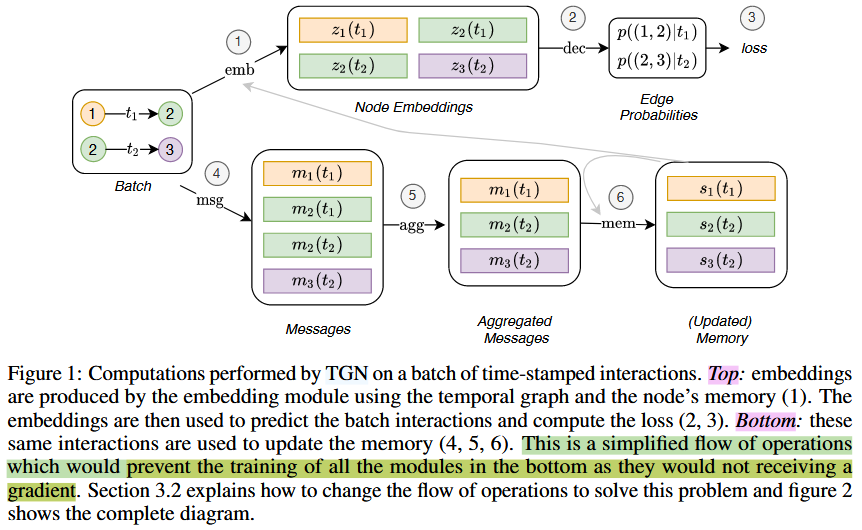
但是这种方式会阻止所有模块的训练,因为它们不能接收梯度。因为这种方法在步骤①中首先根据上次interaction或node变化产生的memory和batch中的嵌入更新节点嵌入,然后计算loss,最后计算本次interaction的updated memory。
1.1. CORE MODULES
1.1.1. Memory——记忆(状态)
该模型在时刻t的记忆(状态)由该模型迄今为止所见到的每个节点i的向量si ( t )组成。节点的内存在事件( e.g.与另一个节点的交互或节点间的变化)之后进行更新,其目的是以压缩的格式表示节点的历史。得益于这个特殊的模块,TGNs有能力记忆图中每个节点的长期依赖关系。当遇到一个新的节点时,它的内存被初始化为零向量,然后对每个涉及该节点的事件进行更新,甚至在模型完成训练之后。虽然也可以在模型中加入全局(图级)记忆来跟踪整个网络的演化,但我们将此作为未来的工作。
1.1.2. Message Function.
对于每个涉及节点i的事件,计算一个消息来更新节点 i 的内存。在源节点i和目标节点j在时刻t之间存在一个
![]()
的情况下,可以计算两个消息:.
![]()
类似地,在
![]()
的情况下,可以为事件所涉及的节点计算单个消息:
![]()
其中,
![]()
为节点i在t时刻(也就是说,从前一次互动的时间涉及i )之前的内存,
![]()
为可学习的消息函数,例如。MLPs。在所有的实验中,为了简单起见,我们选择消息函数作为身份( id ),它是输入的简单级联。删除事件也由框架支持,并在附录A.1中呈现。 一个更复杂的消息函数,包括来自节点i和j的邻居的额外聚合也是可能的,并留给未来的研究。
1.1.3. Message Aggregator.
出于效率的考虑,采用批处理的方式可能会导致同一批次中涉及同一节点i的多个事件。由于在我们的公式中每个事件都会产生一个消息,因此对于
![]()
,我们使用一种机制来聚合消息
![]()
。
![]()
其中,
![]()
是一个聚合函数。虽然实现这个模块( e. g . RNNs或注意力w . r . t .节点记忆)可以考虑多种选择,但为了简单起见,我们在实验中考虑了两种有效的不可学习的解决方案:
![]()
(对于给定的节点只保留最近的消息)和
![]()
(对于给定的节点,平均所有的消息)。我们将可学习的聚合作为未来的研究方向。
1.1.4. Memory Updater.
如前所述,节点的Memory根据涉及节点本身的每个事件进行更新:
![]()
对于涉及两个节点 i和j 的
![]()
,事件发生后更新两个节点的记忆。对于
![]()
,只更新相关节点的内存。这里,
![]()
是一个可学习的记忆更新函数,例如循环神经网络,如LSTM 或GRU。
1.1.5. Embedding
嵌入模块用于生成节点 i在任意时刻t的时间嵌入 zi ( t )。嵌入模块的主要目标是避免所谓的memory staleness problem。由于节点 i的内存只有在节点有事件参与时才会更新,所以可能会出现在长时间没有事件(例如,社交网络用户在重新活跃之前停止使用平台一段时间)的情况下,i的内存就会变得陈旧。虽然嵌入模块的多种实现都是可能的,但我们采用如下形式:
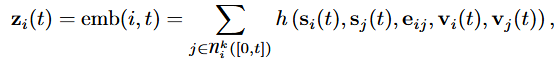
其中,h是一个可学习的函数。这包括许多不同的形式作为特例:.
Identity (id):
![]()
,直接使用内存作为节点嵌入。
Time projection (time):
![]()
,其中 w 为可学习参数,∆t为上一次交互后的时间,o 为逐元素向量积。在Jodie ( Kumar et al , 2019)中使用了这一版本的嵌入方法。
Temporal Graph Attention (attn):一系列 L 图注意力层通过聚合其L - hop时间邻域的信息来计算i的嵌入。
第l层的输入是i的表示
![]()
,当前的时间戳t,i的邻域表示
![]()
,以及时间戳
![]()
和特征
![]()
表示在 i 的时间邻域中形成边的每个所考虑的interactions作用:
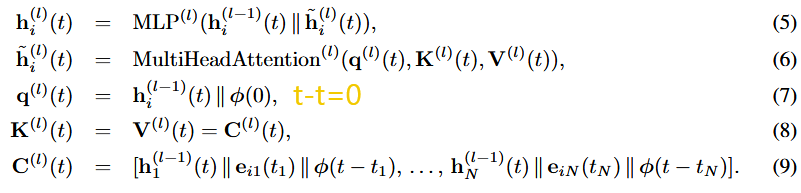
其中,φ ( · )表示( Xu et al , 2020)的
![]()
,‖是concatenation算子且
![]()
.每一层相当于执行多头注意力( Vaswani et al , 2017),其中query(
![]()
)是一个参考节点(即目标节点或它的一个L - 1跳邻居),keys
![]()
和values
![]()
是它的邻居。最后,使用MLP将参考节点表示与聚合信息相结合。不同于该层的原始方案(最早在TGAT中提出( Xu et al ,2020 ) ),这里没有使用节点时间特征,在我们的情况下,每个节点的输入表示
![]()
,因此允许模型利用当前内存
![]()
和时间节点特征
![]()
。
Temporal Graph Sum (sum):图上更简单、更快速的聚集:.
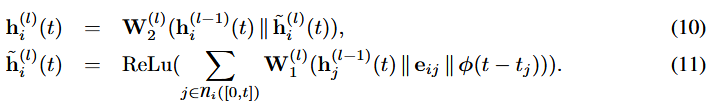
这里φ ( · )是一个时间编码,
![]()
.在实验中,对于Temporal Graph Attention模块和Temporal Graph Sum模块,我们都使用了Time2Vec ( Kazemi et al , 2019)中提出的时间编码和TGAT ( Xu et al , 2020)中使用的时间编码。
图嵌入模块通过聚合来自节点邻居内存的信息来缓解memory staleness problem。当一个节点已经处于非活动状态一段时间时,它的一些邻居很可能最近一直处于活动状态,通过聚合它们的内存,TGN可以计算出该节点的最新嵌入。时间图注意力还能够基于特征和定时信息来选择哪些邻居更重要。
1.2. TRAINING
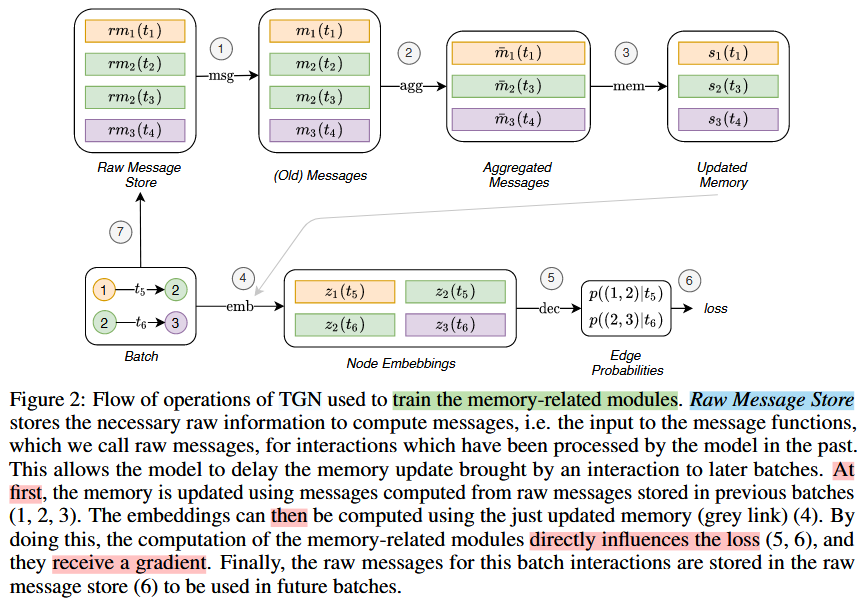
TGN可以用于多种任务的训练,例如边缘预测(自监督)或节点分类(半监督)。我们使用链接预测作为例子:提供一个时间有序的interactions,目标是从过去观察到的interactions中预测未来的interactions。图1展示了TGN在一批训练数据上进行的计算。
我们的训练策略中的复杂度与记忆相关的模块(消息函数、消息聚合器和内存更新器)有关,因为它们不直接影响损失,因此不会得到梯度。为了解决这个问题,在预测批次交互之前必须更新内存。然而,在使用模型预测相同的交互之前,用一个交互eij ( t )更新记忆,会导致信息泄露。为了避免这个问题,在处理一个批处理时,我们用前一个批处理(它们存储在Raw Message Store中)的消息来更新内存,然后对交互进行预测。图2展示了内存相关模块的训练流程。训练过程的伪代码见附录A。2 .

更正式地,在任意时刻t,Raw Message Store包含(至多)每个节点i的一条原始消息
![]()
(Raw Message Store中不包含对i的消息,仅当i在过去从未参与过某个事件。),产生于t时刻之前涉及i的最后一次交互。当模型处理涉及i的下一个交互时,使用rmi (图2中箭头1 , 2 , 3)更新其内存,然后使用更新后的内存计算节点的嵌入和批损失(箭头4、5、6)。最后,新交互的原始消息存储在原始消息存储中(箭头7 )。
还值得注意的是,给定批次中的所有预测都可以访问相同状态的memory。而从批处理中的第一个交互的角度来看,内存是最新的(因为它包含了图中所有以前的相互作用的信息),从批处理中的最后一个交互的角度来看,同一内存是过时的,因为它缺乏关于同一批处理中以前的交互的信息。这抑制了大批量(在批大小与数据集一样大的极端情况下,所有的预测都将使用初始的零内存进行)的使用。我们发现批大小为200在速度和更新粒度之间是一个很好的折衷。