【文献笔记】Point Transformer
参考笔记:
https://blog.csdn.net/qq_43700729/article/details/136796449
https://blog.csdn.net/u013609289/article/details/122906946
https://blog.csdn.net/yangyu0515/article/details/150424070(这篇文章写的很细致,看完收获很大)
ICCV 2021:Point Transformer
论文:https://arxiv.org/abs/2012.09164
源码:https://github.com/POSTECH-CVLab/point-transformer
这篇文章写的非常好,思路清晰,而且源码实现基本与论文中一致,这一点非常难得,不像其他一些论文经常会偷偷在源码中加一些文中未提及的东西(bushi
目录
1. 前言:自注意力机制适合处理点云的原因
2. 文章贡献
3. 自注意力机制介绍
3.1 标量注意力
3.2 矢量注意力
4. Point Transformer Layer
4.1 公式
4.2 图解
5. Position Encoding
6. Point Transformer Block
7. Network Architecture
7.1 Backbone Structure
7.2 Transition Down
7.3 Transition UP
7.4 Output Head
8. Point Transformer Seg的源码
1. 前言:自注意力机制适合处理点云的原因
作者提到,Transformer 特别适合点云处理,因为自注意力机制是 Transformer 的核心,本质上就是一个集合算子:它对输入元素具有顺序不变性和数量不变性
① 排列不变性:3D点云 是无序的,即使改变点云txt文件中的点顺序也不会有任何影响。自注意力机制天然具有排列不变性,因为它通过对所有 "点对" 的关系进行建模来处理输入,而不依赖于任何特定的输入顺序
② 捕捉全局上下文:点云数据通常覆盖了 3D空间 中的对象或场景,理解这些数据需要捕捉点与点之间复杂的空间关系。自注意力机制能够有效的捕捉这些关系,因为它为每个 "点对" 赋予一个注意力权重,这反映了两个点之间的相对重要性或者说相关性
因此由 ①②,将自注意力机制用于点云是自然而然的,点云本质上就是在 3D空间 中的点集合
2. 文章贡献
-
为点云处理设计了一个结合位置编码 Position Encoding 的 Point Transformer Layer,其表达能力非常强
-
在 Point Transformer Layer 的基础上,构建了高性能的 Point Transformer Networks,用于点云分类、点云分割,实验结果非常好,很多都达到了 SOTA
3. 自注意力机制介绍
作者提到自注意力机制可以分为梁类:scalar attention、vector attention,即标量注意力、向量注意力。前者是最原始的 《Attention is all you need》论文中提出的;后者是作者自己以前的论文《Exploring self-attention for image recognition》中提出的;本文使用的是后者 vector attention,即向量注意力
3.1 标量注意力
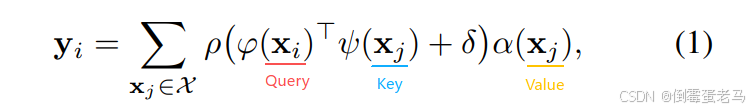
:多组特征向量的集合
:
个特征向量
:表示输出特征
其中, 表示输出特征,
表示对特征的变换,可以是 MLP 或者 Linear
是一个位置编码
是一个标准化函数(通常是SoftMax),用来衡量查询的
与
之间的差异,并指导
的加权输出,建立
与
的关系
流程:使用 转换输入特征
,然后计算他们的标量积(反映两个特征向量之间的关系),并将其与位置编码
相加应用
作为注意力权重,用于对
转换后的特征进行加权处理
问题:在标量注意力中,算出来的注意力权重是一个标量,是一个值,这一方法会将同一注意力权重应用于特征的所有通道上,而不是逐通道进行加权,这意味着整个特征向量会以相同的比例缩放
3.2 矢量注意力
矢量注意力与标量注意力不同,其计算出来的注意力权重是一个向量而非一个值,这个向量可以调节特征的单个通道
公式:
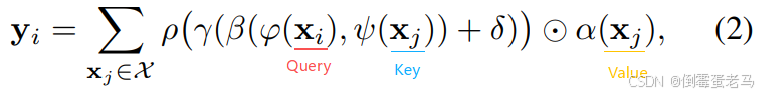
:关系函数,用来衡量特征向量
之间的关系,例如减法等
: 是一个映射函数,如 MLP,产生用于特征加权的注意向量
:哈达玛积,即矩阵对应位置相乘,有一个简单的例子如下:
其他符号均与标量注意力公式中一致
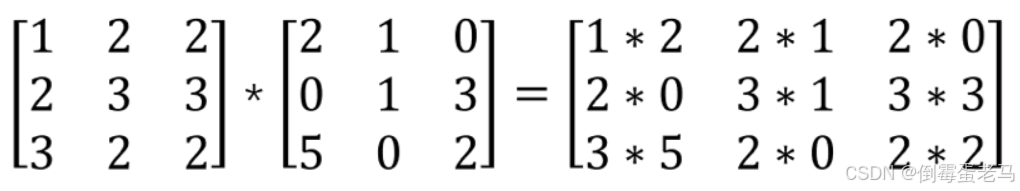
4. Point Transformer Layer
4.1 公式
用于本文的 Point Transformer Layer 即矢量注意力,其公式如下:
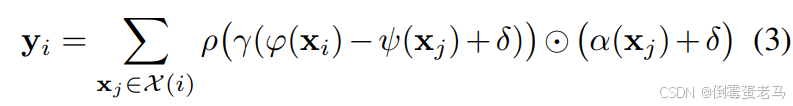
的输出特征
:采样点