Hadoop3.3.5搭建指南(简约版)
本实践从3台服务器,1个NN与2个DN,扩展4台服务器双NN和双DN,到最后形成双NN和3个DN的生产环境演变
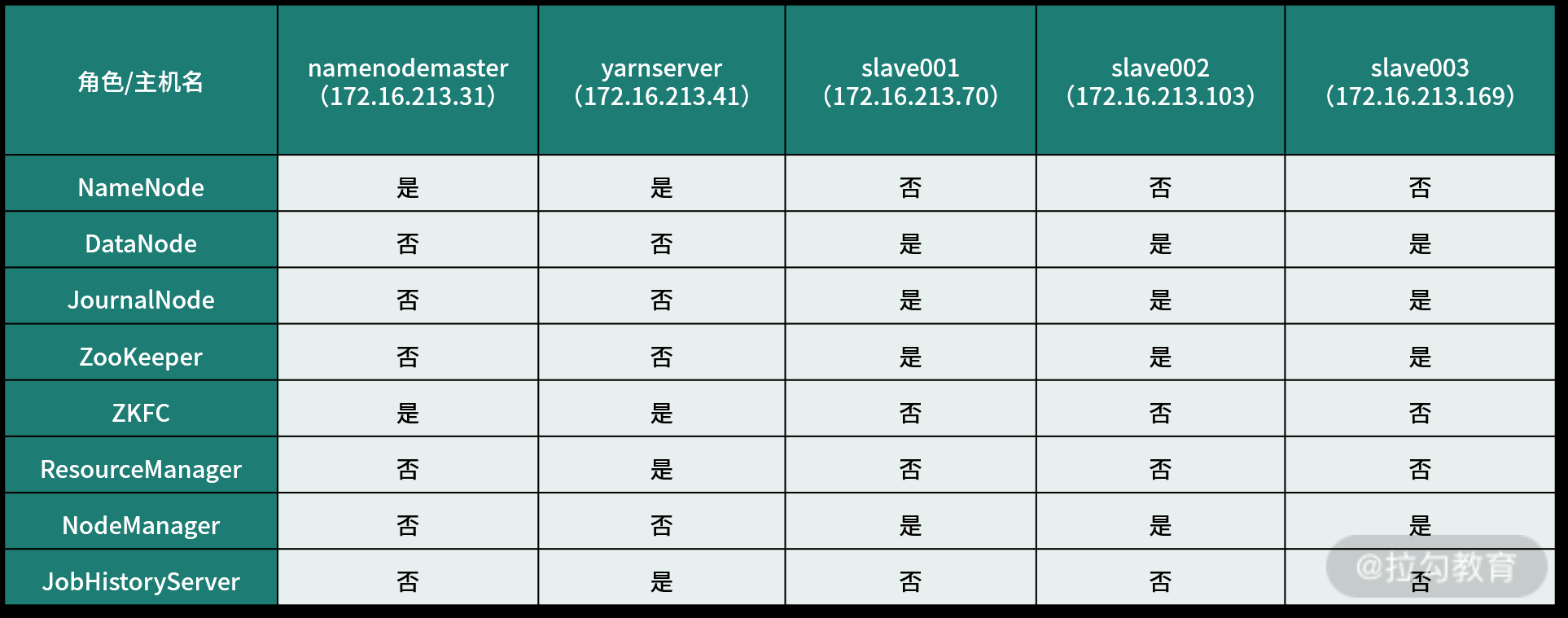
最后的架构图会演变成以下形式,此处引用其他博主对该架构的介绍:
双 NameNode 的 Hadoop 集群环境涉及到的角色有 Namenode、datanode、resourcemanager、nodemanager、historyserver、ZooKeeper、JournalNode 和 zkfc,这些角色可以单独运行在一台服务器上,也可以将某些角色合并在一起运行在一台机器上。
一般情况下,NameNode 服务要独立部署,这样两个 NameNode 就需要两台服务器,而 datanode 和 nodemanager 服务建议部署在一台服务器上,resourcemanager 服务跟 NameNode 类似,也建议独立部署在一台服务器上,而 historyserver 一般和 resourcemanager 服务放在一起。ZooKeeper 和 JournalNode 服务是基于集群架构的,因此至少需要 3 个集群节点,即需要 3 台服务器,不过 ZooKeeper 和 JournalNode 集群可以放在一起,共享 3 台服务器资源。最后,zkfc 是对 NameNode 进行资源仲裁的,所以它必须和 NameNode 服务运行在一起,这样 zkfc 就不需要占用独立的服务器了
 服务器配置如下:
服务器配置如下:
54 服务器 NN RM
61.62服务器 DN NM
1、首先配置hosts
54 master
61 slave1
62 slave2
2、免密配置
生成公钥私钥
执行:sh-keygen,将公钥分发给各个服务器
ssh-copy-id root@master
ssh-copy-id root@slave1
ssh-copy-id root@slave2
测试 ssh slave1,查看是否可以登录到其他服务器
3、zookeeper 集群安装
下载地址如下https://downloads.apache.org/zookeeper/
选择 zookeeper-3.8.4 版本
tar -xvf apache-zookeeper-3.8.4-bin.tar.gz
mv apache-zookeeper-3.8.4-bin zookeeper
cd zookeeper/
mkdir data
配置zoo.cfg文件
cd conf/
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改 dataDir=/datas/hadoop/zookeeper/data
server.1=xx.xx.xx.54:2888:3888
server.2=xx.xx.xx.61:2888:3888
server.3=xx.xx.xx.62:2888:3888
配置myid文件
cd data/
vi myid 输入1,其于2台服务器分别是2和3
声明环境变量
export ZOOKEEPER_HOME=/u01/datas/hadoop/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
其余服务器也照此安装
4、Hadoop安装
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 下载hadoop-3.3.5/
tar -zxvf hadoop-3.3.5.tar.gz
配置一下配置文件/etc/profile
export HADOOP_HOME=/datas/hadoop/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
更换hadoop-env.sh和yarn-env.sh的jdk地址
cd etc/hadoop/
vi hadoop-env.sh
配置jdk
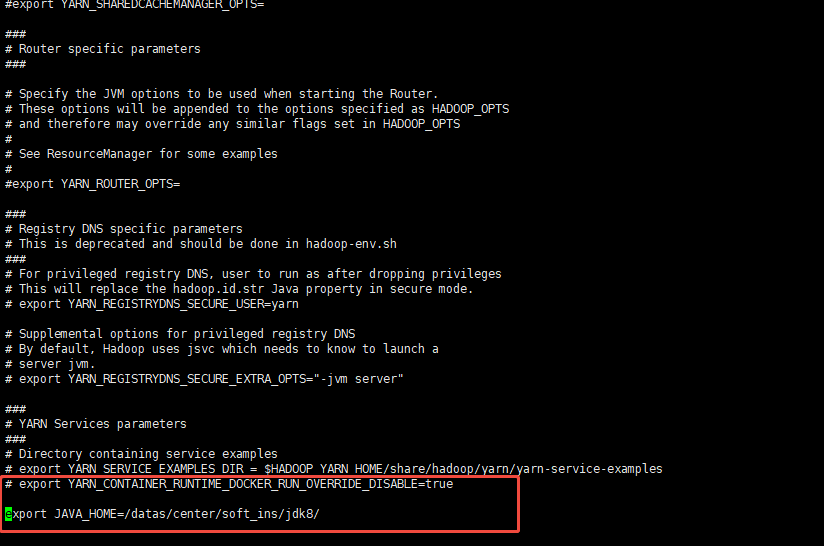
vi yarn-env.sh
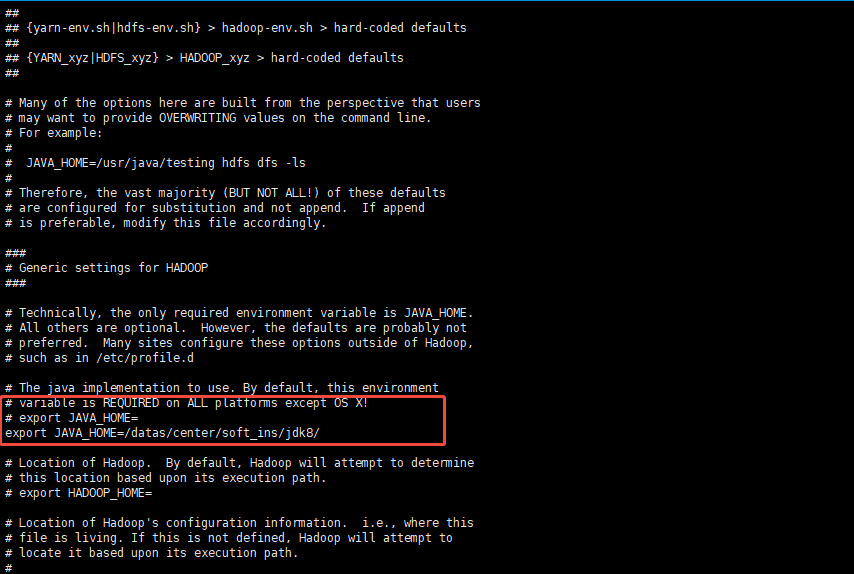
配置jdk
vi core-site.xml
配置vi core-site.xml文件,此处的9000由于端口被占用,所以选择8020端口
<property>
<!-- 配置Hadoop 的临时目录 -->
<name>hadoop.tmp.dir</name>
<value>file:/datas/hadoop/hadoop-3.3.5/tmp</value>
</property>
<property>
<!-- 配置Hadoop的文件系统,由URI指定 -->
<name>fs.defaultFS</name>
<!-- 这里我之前配置过主机名和IP映射所以写成主机名即可,
没配置过的话,写完整的IP地址即可 192.168.197.133
-->
<value>hdfs://xx.xx.xx.54:8020</value>
</property>配置vi hdfs-site.xml
<configuration>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/datas/hadoop/hadoop-3.3.5/tmp/master</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/datas/hadoop/hadoop-3.3.5/tmp/slave</value>
</property>
</configuration>配置vi mapred-site.xml
<property>
<!-- 指定MapReduce运行时框架,指定yarn,默认是local -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>配置vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN集群的管理者Resoucemanage的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>添加 workers
vi /datas/hadoop/hadoop-3.3.5/etc/hadoop/workers
slave1slave2在三台服务器上的/etc/profile文件新增加以下:
[root@namenode bin]# vim /etc/profile
#配置文件中添加以下内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
5、复制文件到其余两台服务器
scp -r /datas/hadoop/hadoop-3.3.5 root@slave1:/datas/hadoop/
scp -r /datas/hadoop/hadoop-3.3.5 root@slave2:/datas/hadoop/
在54服务器的bin目录执行格式化操作
hdfs namenode -format
启动:
start-dfs.sh
start-yarn.sh
访问地址如下:
http://xx.xx.xx.54:50070/dfshealth.html#tab-datanode
http://xx.xx.xx.54:8088/cluster/nodes
安装单NN双DN的架构没有遇到问题,安装步骤简单