深入解析Redis集群模式:构建高可用与可扩展的缓存系统
随着应用规模的不断扩大,单机Redis会遇到容量瓶颈、单点故障、性能压力等诸多问题。Redis集群(Cluster)是Redis官方提供的分布式解决方案,它通过数据分片(Sharding)和主从复制相结合的方式,实现了高性能、高可用、线性扩展的分布式缓存数据库。
一、为什么需要Redis集群?
单机Redis的局限性:
容量瓶颈:单个Redis实例的内存容量有限,无法存储超大规模的热数据。
性能瓶颈:所有请求都由一个实例处理,容易达到CPU、网络和I/O的性能上限。
单点故障:一旦唯一的主机宕机,整个缓存服务将完全不可用。
Redis集群的设计目标就是解决以上问题,提供:
线性扩展:通过增加节点可以线性地提升数据容量和吞吐量。
高可用性:部分节点宕机不会导致整个集群不可用。
写操作安全:系统会尽最大努力保留所有客户端在大多数主节点可达时发起的写操作。
二、Redis集群的核心机制
1. 数据分片(Sharding)
Redis集群并未使用一致性哈希,而是引入了 哈希槽(Hash Slot) 的概念。
哈希槽数量:一个Redis集群有16384(2^14)个哈希槽。
数据分片规则:每个写入的键(Key)都会通过CRC16算法计算出一个值,然后对这个值取模16384,从而确定这个键属于哪个哈希槽。
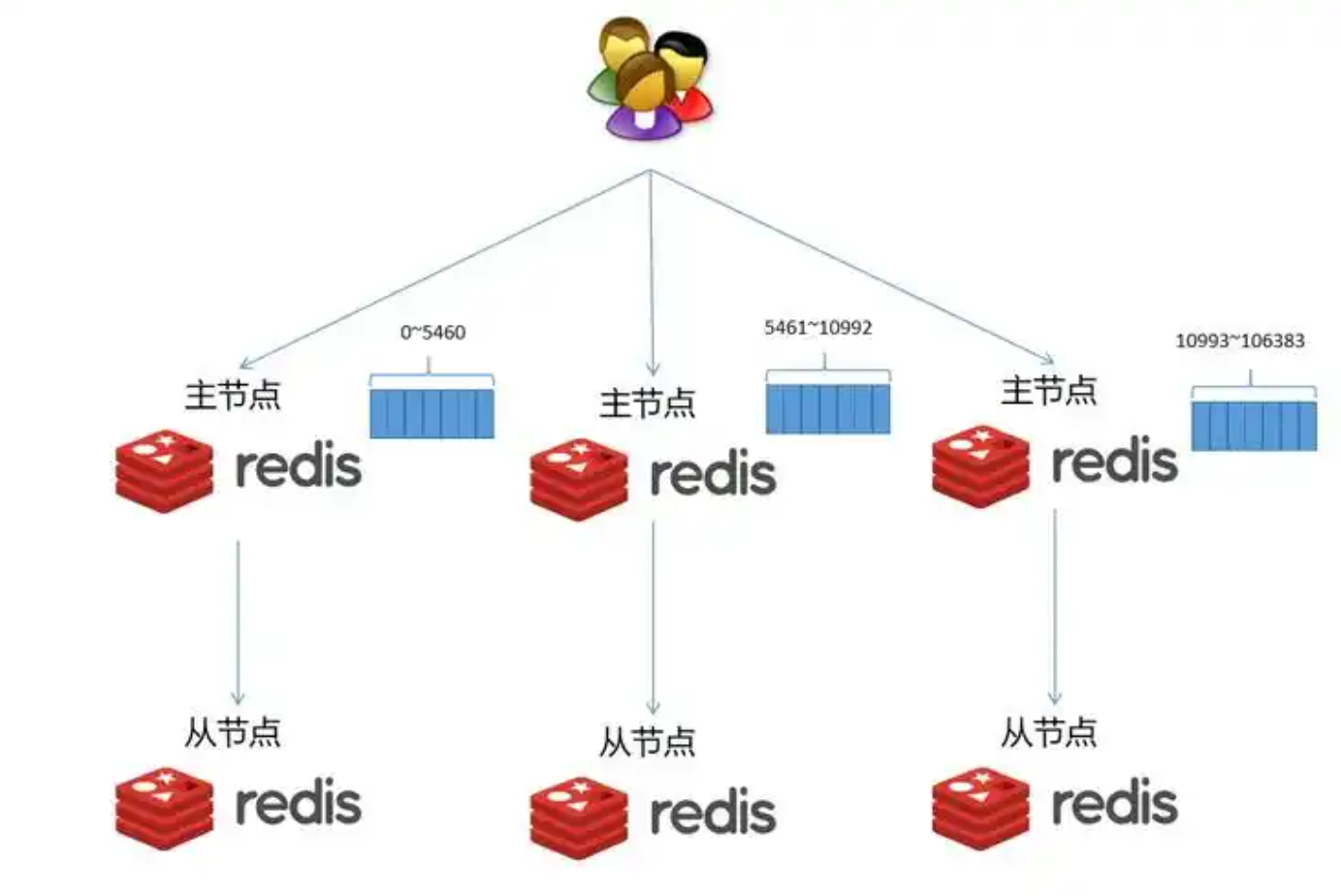
HASH_SLOT = CRC16(key) mod 16384槽分配:集群中的每个主节点(Master)负责处理一部分哈希槽。例如,一个三主节点的集群,分配可能如下:
节点A:处理0 - 5500号槽
节点B:处理5501 - 11000号槽
节点C:处理11001 - 16383号槽
这种方式的优点是易于管理和迁移。要移动数据,只需要将相应的哈希槽从一个节点转移到另一个节点即可。
2. 节点间通信(Gossip协议)
Redis集群是一个去中心化的架构,所有节点通过Gossip协议彼此互联(P2P模式)。
每个节点都维护着整个集群的元数据:包括有哪些节点、哪些节点负责哪些槽、节点的状态等。
节点间定期通过PING/PONG消息交换信息,以此检测节点是否存活、传播集群状态、同步配置信息。
客户端可以连接到集群中的任意节点。如果该节点没有客户端请求的数据(即不负责对应的槽),它会返回一个重定向错误(MOVED) 并告知客户端正确的节点地址。
3. 主从复制与高可用
Redis集群的每个分片都采用主从模式(Master-Slave) 来保证数据高可用。
每个主节点都应该有一个或多个从节点(Slave)。
主节点负责处理槽的读写请求,从节点则异步复制主节点的数据。
当某个主节点宕机时,集群会自动进行故障转移(Failover):由其某个从节点晋升为新的主节点,并接管原来主节点负责的哈希槽。
当原主节点恢复后,它会成为新主节点的从节点。
三、搭建一个最简单的Redis集群
Redis集群要求至少三个主节点才能正常工作(因为需要多数派达成共识)。为每个主节点配置一个从节点,则最少需要6个Redis实例。
步骤简述:
启动节点:配置并启动6个
redis-server实例,在配置文件中启用集群模式:cluster-enabled yescluster-config-file nodes-6379.conf(每个实例的集群配置文件需不同)cluster-node-timeout 15000组建集群:使用
redis-cli --cluster create命令,自动完成槽分配和主从关系建立:redis-cli --cluster create \127.0.0.1:7000 127.0.0.1:7001 \127.0.0.1:7002 127.0.0.1:7003 \127.0.0.1:7004 127.0.0.1:7005 \--cluster-replicas 1 # 为每个主节点配置1个从节点客户端连接:使用
-c参数以集群模式连接,客户端会自动处理重定向。redis-cli -c -p 7000
四、集群模式下的客户端行为
客户端需要具备集群意识(Cluster-aware)。
客户端启动时,可以连接集群中的任一节点来获取完整的槽位配置信息(Slots map)。
客户端会本地缓存这份槽位配置。
当请求一个Key时,客户端先本地计算其槽位,然后直接发送给对应的主节点。
如果节点返回
MOVED错误(如MOVED 3999 127.0.0.1:7001),表示槽位已迁移,客户端需要更新本地缓存,并将请求重发到新节点。如果集群正在reshard(槽位迁移),节点可能返回
ASK错误,这是一个临时重定向,客户端需要向新节点先发送一个ASKING命令,再发送原请求。
大多数成熟的Redis客户端(如Jedis、Lettuce)都已经内置了集群支持,会自动处理重定向和缓存更新。
五、优缺点与适用场景
优点:
无缝扩容:可以轻松地增加节点来扩容集群。
高可用性:自动故障转移,服务可用性高。
原生分布式:官方解决方案,兼容性好,无需第三方代理。
缺点与限制:
适用场景:
不支持多数据库:集群模式下只能使用
db0,不再支持SELECT命令。Key操作限制:涉及多Key的操作(如MSET),要求所有Key必须在同一个哈希槽中。可以使用哈希标签(Hash Tag) 来强制将一组Key分配到同一个槽,例如将
user:{1000}:profile和user:{1000}:account中的{1000}作为计算槽位的部分。部署复杂:管理和运维一个集群比单机实例更复杂。
网络依赖:严重依赖内部节点间的网络质量。
需要缓存的数据量超过了单机内存容量。
需要更高的吞吐量以应对高并发读写。
要求缓存服务具备高可用性,不能有单点故障。