Android使用GPU指南
首先确认已经用 USB 数据线把手机和电脑连上了,可以直接用 ADB(Android Debug Bridge) 来查看手机芯片和算力支持情况。下面给你分步骤操作:
如果你装了 Android Studio
adb 已经自带在 SDK\platform-tools 目录。
默认路径可能是:
C:\Users\<你的用户名>\AppData\Local\Android\Sdk\platform-tools直接进入这个目录运行:
cd C:\Users\WangRuihua\AppData\Local\Android\Sdk\platform-toolsadb devices
🔹 1. 确认设备连接
在电脑命令行(终端 / CMD / PowerShell)输入:
adb devices

👌 很好,现在说明你的 手机和模拟器 都连上了电脑:
4a38c1b2312bf4cd device ← 真机
emulator-5554 device ← 模拟器
🔹 查看当前手机芯片和算力信息
在命令行输入以下指令(默认针对你的真机 c9ce1ef1cf87998):
1. 查看 CPU 架构
adb -s 4a38c1b2312bf4cd shell getprop ro.product.cpu.abi
可能输出:
arm64-v8a→ 64 位 ARM CPU(现代手机主流,支持 AI 框架)armeabi-v7a→ 32 位 ARM CPU(老旧手机,算力弱)
🔹 查看查看 GPU 信息
adb -s 4a38c1b2312bf4cd shell cmd package list features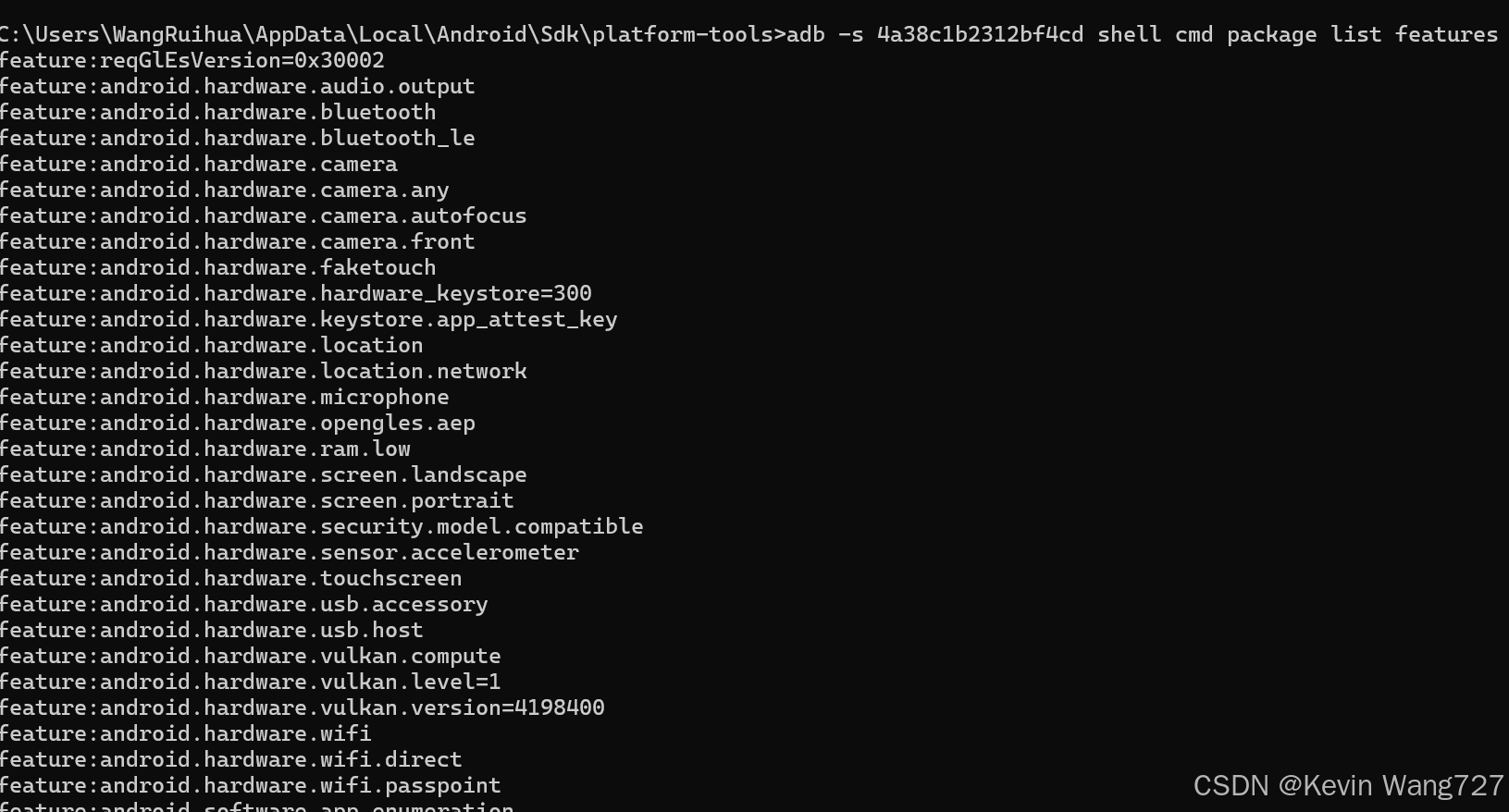
🔹 结论
CPU:
arm64-v8aARMv8 架构,4 个核心(
CPU part 0xd05≈ Cortex-A55 系列,入门/中低端核)。能跑 AI 框架(TFLite / ONNX Runtime Mobile),但主要靠 CPU 推理,算力有限。
GPU:
通过 Vulkan 相关 feature (
android.hardware.vulkan.compute) 可以确认支持 GPU 计算。说明可以跑 Vulkan 后端的 AI 框架(如 TFLite + NNAPI + Vulkan Delegate)。
🔹 进入 PowerShell
方法有几种:
在任务栏搜索框输入 PowerShell → 右键 → 选择 以管理员身份运行。
或者在你当前目录(
D:\platform-tools)里按住 Shift + 右键 → 选择 在此处打开 PowerShell 窗口。
打开后,你会看到提示符类似:
PS D:\platform-tools>这就是 PowerShell 环境。
🔹 在 PowerShell 里运行 ADB 命令
1. 查看 GPU 信息(过滤 GLES)
.\adb -s 4a38c1b2312bf4cd shell dumpsys SurfaceFlinger | Select-String "GLES"
.\adb -s 4a38c1b2312bf4cd shell cat /proc/meminfo | Select-String "MemTotal"2.查看内存信息
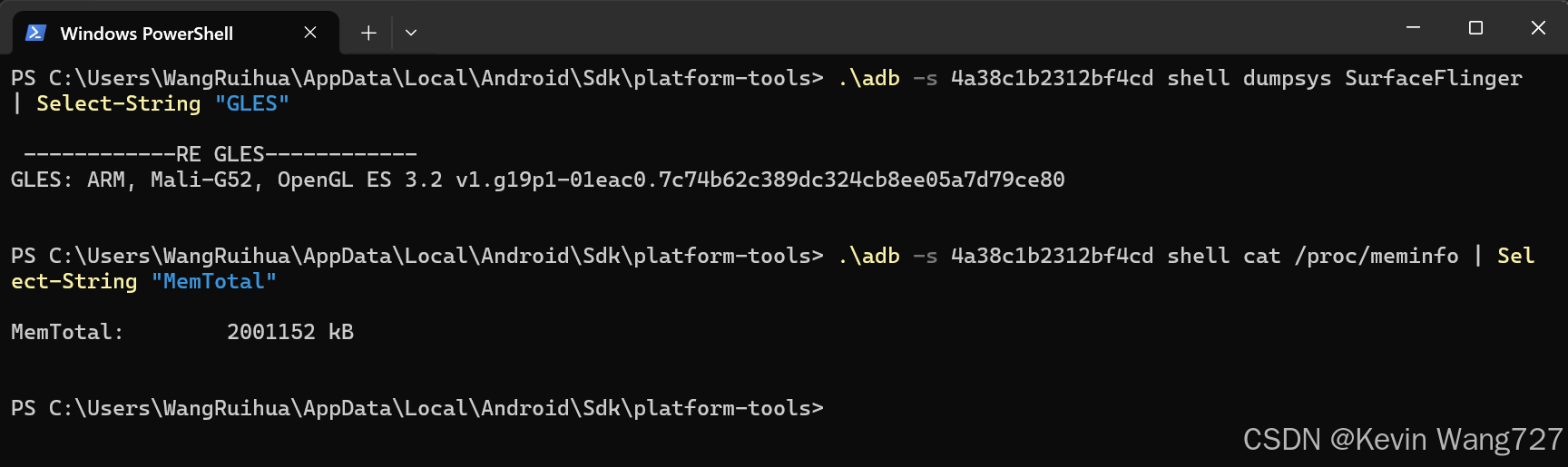
棒了 ✅
现在你已经成功查到 GPU 信息:
GLES: ARM, Mali-G52, OpenGL ES 3.2 v1.g19p1-01eac0.7c74b62c389dc324cb8ee05a7d79ce80🔹 分析结果
GPU 型号:Mali-G52
厂商:ARM
API 支持:OpenGL ES 3.2
👉 Mali-G52 是一款中端 GPU(常见于联发科/紫光展锐等芯片),支持 OpenGL ES 3.2 和 Vulkan,算力中规中矩,适合跑一些轻量级 AI(语音识别、图像分类、小型 NLP 模型)。
🔹 当前设备算力总结
CPU:ARM Cortex-A55(低功耗核,arm64-v8a 架构)
能跑 AI,但性能有限。
GPU:ARM Mali-G52
支持 Vulkan / OpenGL ES 3.2,可用来加速 TensorFlow Lite / ONNX Runtime。
NPU:⚠️ 没检测到
android.hardware.neuralnetworks,说明系统没暴露独立 NPU。AI 运算主要依赖 CPU/GPU。
内存:约 2 GB(MemTotal → 设备的物理内存总量,2001152 kB ≈ 2001152 / 1024 ≈ 1953 MB ≈ 1.95 GB。表示:这台设备的总 RAM 大约是 2GB。)
🔹手机上 Vulkan Driver 的开启
Mali-G52 GPU 是支持 Vulkan 的,你查到的
feature:android.hardware.vulkan.compute就证明了。一般来说,手机出厂就带 Vulkan driver,只要 Android 版本 ≥ 7.0,Vulkan API 就能用。
你可以验证 Vulkan 是否可用:
.\adb -s 4a38c1b2312bf4cd shell pm list features | Select-String "vulkan"
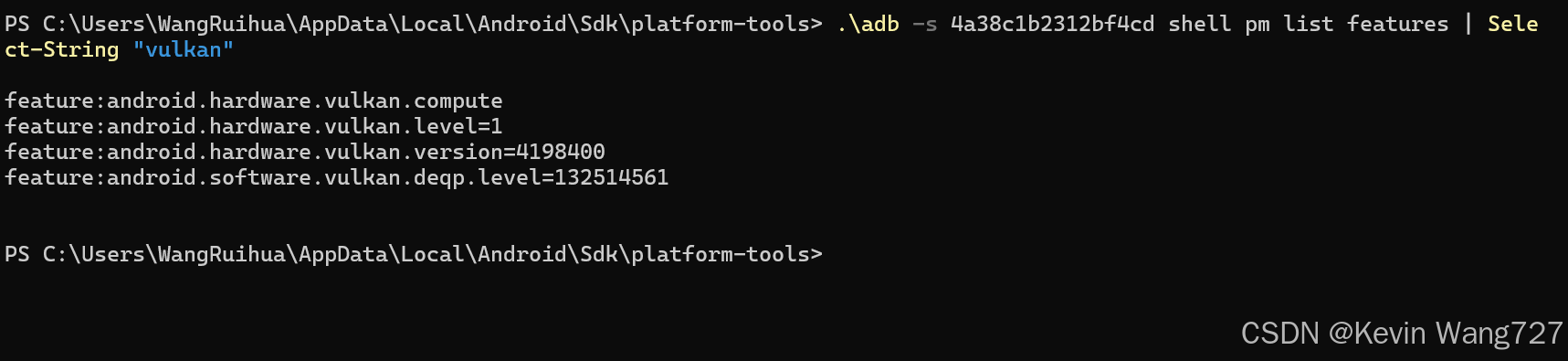
✅ 说明 Vulkan 驱动已经启用,不需要你手动再开。手机已经完全支持 Vulkan,包括:
android.hardware.vulkan.compute→ 说明支持 GPU 计算,不仅是图形渲染。android.hardware.vulkan.level=1→ Vulkan 功能级别,Level 1 表示支持 Compute。android.hardware.vulkan.version=4198400→ Vulkan 版本号(4198400 = 1.1.128)。android.software.vulkan.deqp.level=132514561→ Vulkan 的兼容性测试等级(deqp)。
切换到 GPU (推荐)
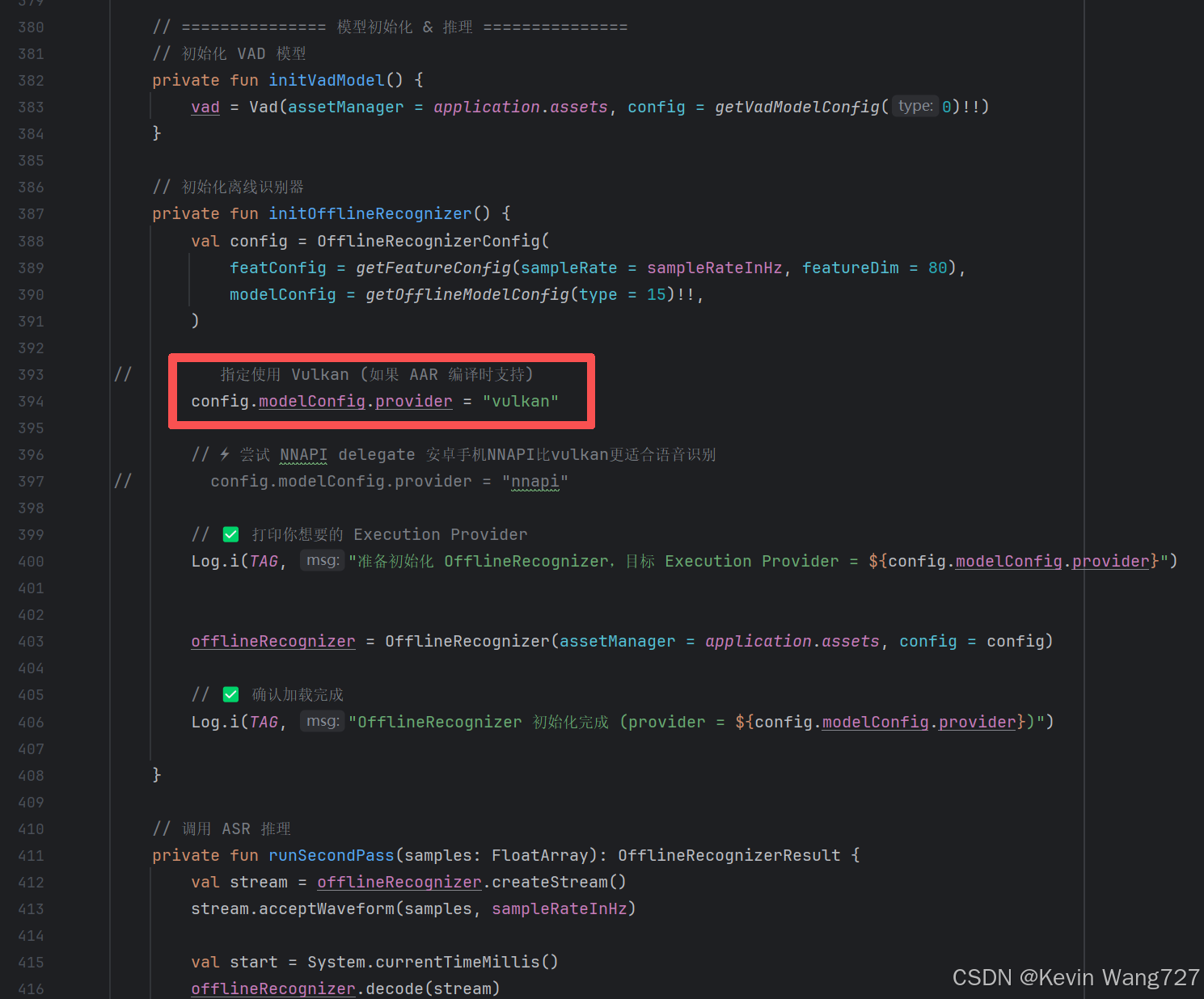
需要一个编译时启用 Vulkan 的
libonnxruntime.so/sherpa-onnx.aar。在初始化时写:
config.modelConfig.provider = "vulkan"然后在 Logcat 里确认执行设备(CPU / GPU)。
你想在 App 代码里主动确认:OfflineRecognizer 到底是跑在 CPU 还是 GPU (Vulkan Delegate)。
Sherpa-ONNX 的 Android 层没有直接暴露 ONNX Runtime 的 provider 信息,不过我们可以通过 两步日志方案 来实现:
🔹 方案 1:打印你设置的 provider
在初始化时,你可以直接把配置打印出来:
private fun initOfflineRecognizer() { val config = OfflineRecognizerConfig( featConfig = getFeatureConfig(sampleRate = sampleRateInHz, featureDim = 80), modelConfig = getOfflineModelConfig(type = 15)!!, ) config.modelConfig.provider = "vulkan" // 你想启用的后端 Log.i(TAG, "准备加载模型,目标 Execution Provider=${config.modelConfig.provider}") offlineRecognizer = OfflineRecognizer(assetManager = application.assets, config = config) Log.i(TAG, "OfflineRecognizer 初始化完成 (provider=${config.modelConfig.provider})") }这样可以确认你代码里确实指定了 vulkan。
👉 但这还不能保证 Vulkan 真的被加载成功。
🔹 方案 2:检测推理耗时,推断是否跑 GPU
在 runSecondPass() 里加上耗时打印:
private fun runSecondPass(samples: FloatArray): OfflineRecognizerResult { val stream = offlineRecognizer.createStream() stream.acceptWaveform(samples, sampleRateInHz) val start = System.currentTimeMillis() offlineRecognizer.decode(stream) val end = System.currentTimeMillis() val result = offlineRecognizer.getResult(stream) stream.release() Log.i(TAG, "执行 decode 耗时=${end - start} ms (provider=${offlineRecognizer.hashCode()})") return result }⚡ 如果 GPU 生效,decode 耗时会显著低于 CPU(几百 ms → 数十 ms)。
🔹 方案 3(可选):JNI 层暴露 provider 名称
如果你能改 JNI,可以在 C++ 里调用:
auto providers = Ort::GetAvailableProviders(); for (auto &p : providers) { LOGI("ONNX Runtime 支持的 Provider: %s", p.c_str()); }再通过 Logcat 打印出来。
👉 但这需要你能重新编译 Sherpa-ONNX AAR。
✅ 结论
在 App 代码里,你能做的就是:
打印你配置的
provider。在推理时打印 耗时,结合 Logcat 判断是否真的跑 GPU。