通信高效的数据并行分布式深度学习-综述-图表解读
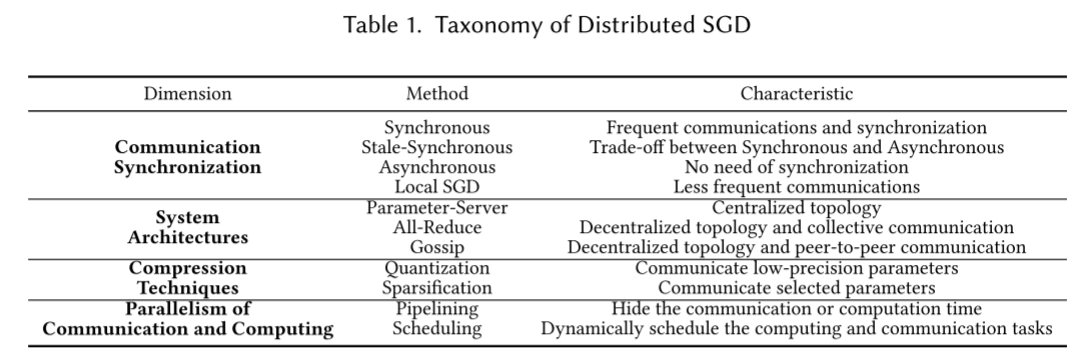
这张表格是分布式随机梯度下降(Distributed SGD)的分类表,从四个维度(Dimension)对分布式 SGD 的不同方法(Method)进行分类,并说明每种方法的特点(Characteristic)。下面逐行解释:
1. Communication Synchronization(通信同步方式)
这一维度描述了分布式训练中多个计算节点(如 GPU、服务器)之间何时、如何同步参数或梯度。
- Synchronous(同步式):
- 特点:节点间需要频繁通信和同步。
- 解释:所有节点在每一轮迭代时,必须等待所有节点都完成本地计算(如梯度计算),然后同步参数/梯度后,再一起进入下一轮迭代。优点是训练更稳定(各节点参数一致),缺点是通信开销大(若有一个节点计算慢,其他节点都要等)。
- Stale-Synchronous( stale - 同步式):
- 特点:在同步式和异步式之间做权衡。
- 解释:允许部分节点的参数“稍旧”(stale),不需要严格等待所有节点同步。比如,当大部分节点完成计算时,就用这些较新的梯度更新参数,少量滞后的节点后续再同步。平衡了同步式的稳定性和异步式的效率。
- Asynchronous(异步式):
- 特点:不需要同步。
- 解释:每个节点独立计算梯度、更新参数,无需等待其他节点。优点是计算资源利用更高效(节点不闲置),缺点是参数更新可能混乱(不同节点的参数版本不一致),训练稳定性稍差。
- Local SGD:
- 特点:通信更不频繁。
- 解释:节点先在本地对参数进行多轮迭代更新(计算多轮梯度、多次更新参数),之后再与其他节点同步一次参数。减少了同步的次数,降低通信开销。
2. System Architectures(系统架构)
这一维度描述分布式训练中节点之间如何连接、组织,以及梯度/参数如何在节点间传递。
- Parameter - Server:
- 特点:有中心化的拓扑结构。
- 解释:存在“参数服务器”(中心节点)和“工作节点”(Worker)。工作节点计算梯度后,发给参数服务器;参数服务器聚合梯度、更新参数,再把新参数发给工作节点。中心节点负责协调,结构清晰,但中心节点可能成为性能瓶颈。
- All - Reduce:
- 特点:去中心化拓扑 + 集体通信。
- 解释:节点之间是平等的(去中心化),通过“All - Reduce”操作(一种集体通信原语),所有节点可以同时交换、聚合梯度。比如,每个节点的梯度会被汇总到所有节点,所有节点都能得到全局梯度。适合多 GPU 等对等设备的分布式训练。
- Gossip:
- 特点:去中心化拓扑 + 点对点通信。
- 解释:节点之间随机、点对点地传递梯度或参数。比如,节点 A 随机选节点 B,把自己的梯度发给 B;节点 B 再随机选节点 C 传递。通过多次这样的“ gossip”( gossip 原指闲聊、传播消息),梯度/参数能扩散到所有节点。无需中心节点,鲁棒性强(单个节点故障不影响整体)。
3. Compression Techniques(压缩技术)
这一维度描述如何减少通信的数据量(因为梯度、参数通常是高维张量,直接传递数据量大,通信耗时)。
- Quantization(量化):
- 特点:传递低精度的参数。
- 解释:把原本高精度的梯度(如 32 位浮点数)转换成低精度(如 8 位整数),减少每个梯度值的存储空间和传输量。牺牲一定精度,换取通信效率提升。
- Sparsification(稀疏化):
- 特点:传递选中的参数。
- 解释:只传递梯度中“重要”的部分(比如,只传递绝对值大的梯度,把小梯度置为 0)。这样传输的数据量减少(很多梯度是 0,无需传递),同时尽量保留对参数更新影响大的信息。
4. Parallelism of Communication and Computing(通信与计算的并行性)
这一维度描述如何让“计算(如梯度计算)”和“通信(如传递梯度)”同时进行,减少整体耗时。
- Pipelining(流水线):
- 特点:隐藏通信或计算时间。
- 解释:把计算和通信分成多个阶段,让它们重叠进行。比如,节点 A 在计算第 ttt 轮梯度时,同时和节点 B 传递第 t−1t - 1t−1 轮的梯度。这样计算和通信的时间可以部分重叠,整体训练时间更短。
- Scheduling(调度):
- 特点:动态调度计算和通信任务。
- 解释:根据节点的计算负载、网络状态等,动态决定何时进行计算、何时进行通信。比如,当网络带宽充足时,多安排通信任务;当计算资源空闲时,多安排计算任务。优化资源利用,提升整体效率。
简单来说,这张表从“通信同步、系统架构、数据压缩、任务并行”四个角度,梳理了分布式 SGD 的不同技术分支,帮助读者理解分布式训练的多样化方法和各自特点。