35、模型量化与压缩实践
核心学习目标:掌握模型量化的工程实现,理解精度与性能的权衡,实现模型压缩的完整流程,建立在资源受限环境下部署大模型的能力。
模型量化与压缩是将训练好的大模型高效部署到资源受限环境的关键技术。通过精确的数值表示转换、智能的网络结构优化和有效的知识迁移,我们可以在保持模型性能的前提下显著减少计算开销和存储需求。
35.1 量化技术原理:数值精度的智能转换
> 量化的数学本质与实现策略
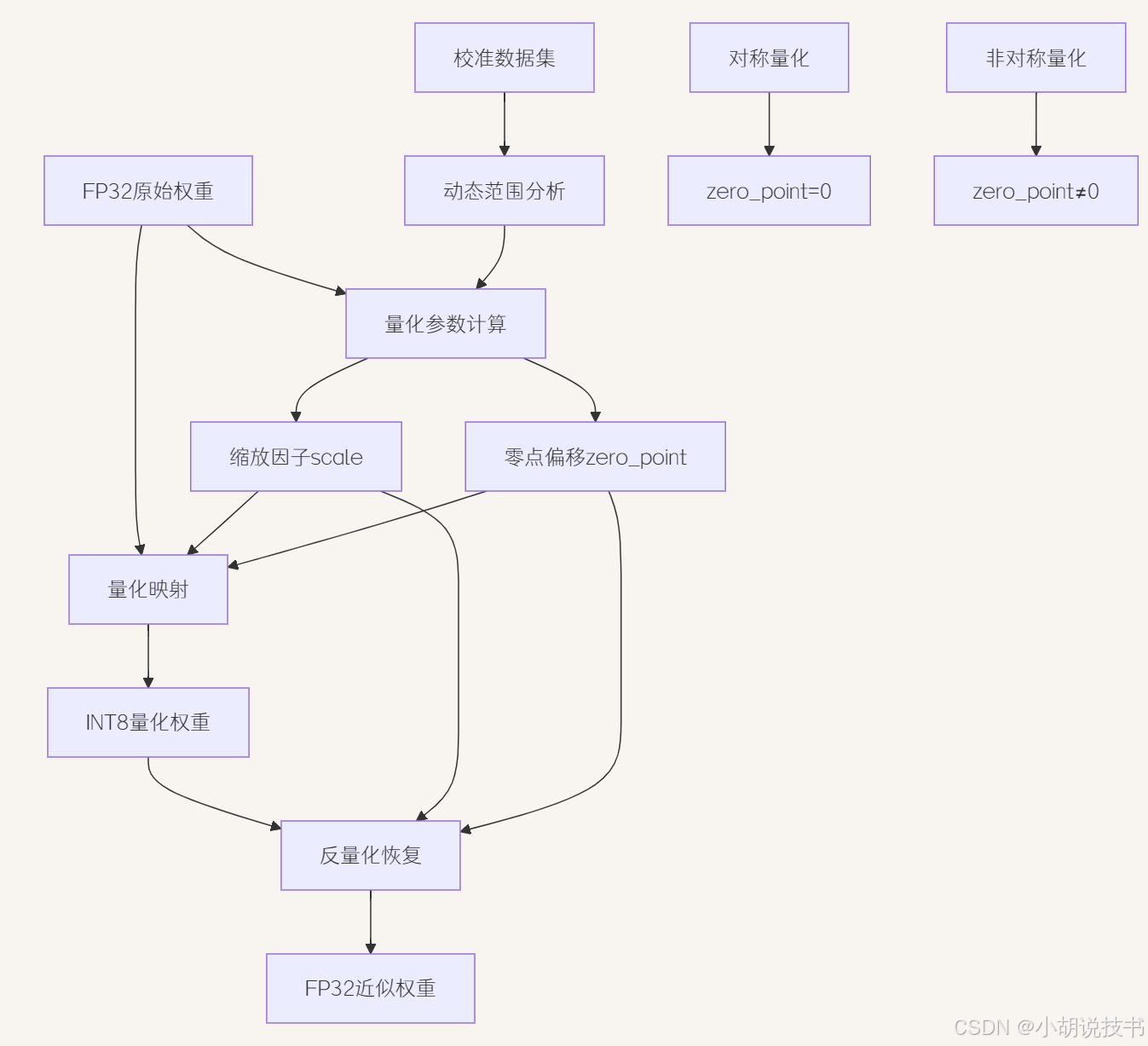
量化过程的核心机制是将浮点数映射到整数空间的精确转换。对于一个FP32权重值,量化过程首先确定其动态范围内的最小值和最大值,然后计算缩放因子和零点偏移。缩放因子(Scale) 决定量化的粒度,即每个整数单位代表的浮点数大小。零点偏移(Zero Point) 确保浮点数零能够精确映射到整数空间,避免量化偏差。
对称量化与非对称量化代表两种不同的量化策略选择。对称量化假设权重分布以零为中心,零点偏移设为零,简化计算但可能不够精确。非对称量化充分利用整数空间,将权重的实际最小值和最大值映射到整数的边界值,提供更好的精度保持,但计算稍复杂。权重分布的对称性决定了最优策略选择。
动态范围的准确估计直接影响量化精度。简单的最小最大值方法容易受到异常值影响,导致量化精度损失。更鲁棒的方法包括百分位数截断,如使用99.9%和0.1%分位数作为边界,或者使用熵最小化方法找到最优的截断点。校准数据集的选择也很关键,应该代表模型的真实推理场景。
量化误差的累积效应在深层网络中尤为显著。每层的量化误差会向后传播并逐层放大,最终可能导致显著的精度下降。混合精度策略通过对关键层保持FP16或FP32精度,对非关键层使用INT8量化,在性能和精度间取得平衡。通常输入输出层、归一化层保持高精度,卷积和全连接层进行量化。
> INT8量化的工程实现细节
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import Tuple, Optional, Dict
import matplotlib.pyplot as pltclass QuantizationConfig:"""量化配置类"""def __init__(self,num_bits: int = 8,symmetric: bool = True,per_channel: bool = True,calibration_size: int = 512):self.num_bits = num_bitsself.symmetric = symmetric # 对称量化或非对称量化self.per_channel = per_channel # 按通道或按张量量化self.calibration_size = calibration_sizeself.qmin = -(2 ** (num_bits - 1)) # 量化最小值self.qmax = 2 ** (num_bits - 1) - 1 # 量化最大值class QuantizationObserver:"""量化观测器,收集激活值统计信息"""def __init__(self, config: QuantizationConfig):self.config = configself.min_vals = []self.max_vals = []self.calibrated = Falseself.scale = Noneself.zero_point = Nonedef observe(self, tensor: torch.Tensor):"""观测张量的数值范围"""if self.config.per_channel and tensor.dim() > 1:# 按通道统计dims = list(range(tensor.dim()))dims.remove(0) # 保留通道维度min_val = tensor.min(dim=tuple(dims), keepdim=True)[0]max_val = tensor.max(dim=tuple(dims), keepdim=True)[0]else:# 全局统计min_val = tensor.min()max_val = tensor.max()self.min_vals.append(min_val)self.max_vals.append(max_val)def calculate_qparams(self) -> Tuple[torch.Tensor, torch.Tensor]:"""计算量化参数:缩放因子和零点偏移"""if not self.min_vals:raise RuntimeError("需要先观测数据才能计算量化参数")# 合并所有观测值min_val = torch.stack(self.min_vals).min(dim=0)[0]max_val = torch.stack(self.max_vals).max(dim=0)[0]if self.config.symmetric:# 对称量化:以绝对值最大值为准max_range = torch.max(torch.abs(min_val), torch.abs(max_val))scale = max_range / (self.config.qmax - self.config.qmin) * 2zero_point = torch.zeros_like(scale, dtype=torch.int32)else:# 非对称量化:充分利用量化范围scale = (max_val - min_val) / (self.config.qmax - self.config.qmin)zero_point = self.config.qmin - torch.round(min_val / scale)zero_point = torch.clamp(zero_point, self.config.qmin, self.config.qmax)zero_point = zero_point.to(torch.int32)# 避免scale为零scale = torch.clamp(scale, min=1e-8)self.scale = scaleself.zero_point = zero_pointself.calibrated = Truereturn scale, zero_pointdef quantize_tensor(tensor: torch.Tensor,scale: torch.Tensor,zero_point: torch.Tensor,num_bits: int = 8
) -> torch.Tensor:"""量化张量到INT8"""qmin = -(2 ** (num_bits - 1))qmax = 2 ** (num_bits - 1) - 1# 量化公式:q = round(x / scale) + zero_pointquantized = torch.round(tensor / scale) + zero_pointquantized = torch.clamp(quantized, qmin, qmax)return quantized.to(torch.int8)def dequantize_tensor(quantized: torch.Tensor,scale: torch.Tensor,zero_point: torch.Tensor
) -> torch.Tensor:"""反量化INT8张量到FP32"""# 反量化公式:x = (q - zero_point) * scalereturn (quantized.to(torch.float32) - zero_point.to(torch.float32)) * scale
35.2 量化感知训练:训练中的量化模拟
> 量化感知训练的技术核心
伪量化操作(Fake Quantization) 是量化感知训练的核心机制。在训练过程中,我们不真正将权重转换为INT8,而是模拟量化过程:先将FP32权重量化到INT8范围,立即反量化回FP32进行计算。这样既让模型学会适应量化带来的数值扰动,又保持了训练的数值稳定性和梯度流动。
梯度直通估计(Straight Through Estimator) 解决量化操作不可微的问题。量化操作本质上是离散化过程,在数学上不可微分。STEs的思想是在前向传播时执行量化,在反向传播时直接传递梯度,忽略量化操作的梯度。这是一种有效的启发式方法,让含有量化操作的网络能够进行端到端训练。
量化噪声的正则化效果帮助模型学习更鲁棒的特征表示。量化过程引入的舍入噪声类似于在训练中加入正则化,迫使模型学习对小扰动不敏感的特征。这种隐式正则化有时能提升模型的泛化能力,使得量化后的模型在某些情况下甚至比原始模型表现更好。
温度调节与量化粒度控制量化感知训练的激进程度。类似于知识蒸馏中的温度参数,我们可以逐渐降低量化的"温度",从粗粒度量化开始,逐步过渡到目标精度。这种渐进式训练策略能够帮助模型更好地适应量化,避免训练初期的不稳定。
class FakeQuantize(nn.Module):"""伪量化层,用于量化感知训练"""def __init__(self, config: QuantizationConfig):super().__init__()self.config = configself.observer = QuantizationObserver(config)self.training = Trueself.register_buffer('scale', torch.tensor(1.0))self.register_buffer('zero_point', torch.tensor(0, dtype=torch.int32))def forward(self, x: torch.Tensor) -> torch.Tensor:if self.training:# 训练时观测数据范围self.observer.observe(x)if len(self.observer.min_vals) % 100 == 0: # 定期更新量化参数scale, zero_point = self.observer.calculate_qparams()self.scale.copy_(scale.mean() if scale.numel() > 1 else scale)self.zero_point.copy_(zero_point.mean() if zero_point.numel() > 1 else zero_point)# 执行伪量化:量化后立即反量化if self.scale.item() > 0:quantized = quantize_tensor(x, self.scale, self.zero_point, self.config.num_bits)return dequantize_tensor(quantized, self.scale, self.zero_point)else:return xclass QuantAwareConv2d(nn.Module):"""量化感知卷积层"""def __init__(self, in_channels, out_channels, kernel_size, **kwargs):super().__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, **kwargs)self.weight_quantizer = FakeQuantize(QuantizationConfig(symmetric=True))self.activation_quantizer = FakeQuantize(QuantizationConfig(symmetric=False))def forward(self, x: torch.Tensor) -> torch.Tensor:# 量化权重quantized_weight = self.weight_quantizer(self.conv.weight)# 使用量化权重进行卷积x = F.conv2d(x, quantized_weight, self.conv.bias, self.conv.stride, self.conv.padding, self.conv.dilation, self.conv.groups)# 量化激活值x = self.activation_quantizer(x)return xdef insert_quantization_layers(model: nn.Module, config: QuantizationConfig) -> nn.Module:"""为模型插入量化感知训练层"""for name, module in model.named_children():if isinstance(module, nn.Conv2d):# 替换卷积层new_conv = QuantAwareConv2d(module.in_channels, module.out_channels, module.kernel_size,stride=module.stride, padding=module.padding, dilation=module.dilation, groups=module.groups, bias=module.bias is not None)new_conv.conv.weight.data.copy_(module.weight.data)if module.bias is not None:new_conv.conv.bias.data.copy_(module.bias.data)setattr(model, name, new_conv)elif isinstance(module, nn.Linear):# 线性层也可以类似处理passelif len(list(module.children())) > 0:# 递归处理子模块insert_quantization_layers(module, config)return model
35.3 模型剪枝技术:网络结构的智能精简
> 结构化剪枝与非结构化剪枝的选择策略
非结构化剪枝通过将重要性较低的单个权重置零来减少参数数量。这种方法能够实现更高的剪枝比例,理论上可以保持更好的模型精度,但产生的稀疏矩阵在标准硬件上很难实现真正的加速。权重重要性评估可以基于绝对值大小、梯度幅度、或者Hessian信息。虽然参数数量大幅减少,但计算图结构不变,需要专门的稀疏矩阵加速库才能发挥作用。
结构化剪枝删除整个神经元、通道或层,直接改变网络架构。虽然可能导致更大的精度损失,但在标准硬件上能够实现真正的推理加速和内存节省。通道剪枝是最常用的结构化剪枝方法,通过分析通道的重要性来决定保留哪些通道。重要性评估可以基于通道权重的L1/L2范数、激活值的统计信息、或者通道对最终输出的贡献度。
渐进式剪枝策略避免一次性剪枝带来的剧烈性能下降。从小比例开始逐步增加剪枝率,每次剪枝后进行短期微调以恢复性能。这种策略让模型有机会逐步适应网络结构的变化,通常能够达到更高的剪枝比例同时保持更好的精度。剪枝-微调的循环次数和每次的剪枝比例需要根据具体任务调优。
重要性评估的多维度标准决定剪枝的精准性。简单的权重大小标准往往不够准确,因为权重的大小不完全等同于重要性。更可靠的方法包括:基于梯度的重要性(权重变化对损失的影响)、基于激活的重要性(通道对输出多样性的贡献)、基于信息论的重要性(通道携带的信息量)。综合多种指标通常比单一指标更可靠。
> 剪枝算法的工程实现
class PruningConfig:"""剪枝配置类"""def __init__(self,pruning_ratio: float = 0.5,structured: bool = True,importance_metric: str = "l1_norm",gradual_steps: int = 10,recovery_epochs: int = 5):self.pruning_ratio = pruning_ratio # 剪枝比例self.structured = structured # 结构化或非结构化剪枝self.importance_metric = importance_metric # 重要性评估指标self.gradual_steps = gradual_steps # 渐进剪枝步数self.recovery_epochs = recovery_epochs # 每步后的恢复训练轮数class PruningMask:"""剪枝掩码管理器"""def __init__(self):self.masks = {}def add_mask(self, name: str, mask: torch.Tensor):"""添加层掩码"""self.masks[name] = maskdef apply_masks(self, model: nn.Module):"""将掩码应用到模型"""for name, param in model.named_parameters():if name in self.masks:param.data *= self.masks[name]def get_sparsity(self) -> float:"""计算整体稀疏度"""total_params = 0zero_params = 0for mask in self.masks.values():total_params += mask.numel()zero_params += (mask == 0).sum().item()return zero_params / total_params if total_params > 0 else 0.0class ModelPruner:"""模型剪枝器"""def __init__(self, model: nn.Module, config: PruningConfig):self.model = modelself.config = configself.mask = PruningMask()self.importance_scores = {}def calculate_importance_scores(self, dataloader: torch.utils.data.DataLoader):"""计算各层参数的重要性分数"""self.model.eval()self.importance_scores.clear()if self.config.importance_metric == "l1_norm":# 基于L1范数的重要性for name, param in self.model.named_parameters():if 'weight' in name and param.dim() > 1:if self.config.structured:# 按通道计算重要性if 'conv' in name.lower():importance = param.abs().sum(dim=(1, 2, 3)) # 卷积层else:importance = param.abs().sum(dim=1) # 全连接层else:# 按权重计算重要性importance = param.abs().view(-1)self.importance_scores[name] = importanceelif self.config.importance_metric == "gradient":# 基于梯度的重要性评估total_samples = 0for batch in dataloader:if total_samples >= 1000: # 限制样本数量breakinputs, targets = batchoutputs = self.model(inputs)loss = F.cross_entropy(outputs, targets)loss.backward()for name, param in self.model.named_parameters():if 'weight' in name and param.dim() > 1 and param.grad is not None:grad_importance = param.grad.abs()if name not in self.importance_scores:self.importance_scores[name] = torch.zeros_like(grad_importance)if self.config.structured:if 'conv' in name.lower():self.importance_scores[name] += grad_importance.sum(dim=(1, 2, 3))else:self.importance_scores[name] += grad_importance.sum(dim=1)else:self.importance_scores[name] += grad_importance.view(-1)total_samples += inputs.size(0)self.model.zero_grad()def generate_pruning_masks(self):"""生成剪枝掩码"""for name, scores in self.importance_scores.items():# 计算剪枝阈值sorted_scores, _ = scores.sort()threshold_idx = int(len(sorted_scores) * self.config.pruning_ratio)threshold = sorted_scores[threshold_idx]# 生成掩码mask = (scores > threshold).float()if self.config.structured:# 结构化剪枝:扩展掩码到整个通道/神经元param = dict(self.model.named_parameters())[name]if 'conv' in name.lower() and param.dim() == 4:# 卷积层:扩展到整个卷积核full_mask = mask.unsqueeze(1).unsqueeze(2).unsqueeze(3)full_mask = full_mask.expand_as(param)elif param.dim() == 2:# 全连接层:扩展到整个神经元full_mask = mask.unsqueeze(1).expand_as(param)else:full_mask = maskself.mask.add_mask(name, full_mask)else:# 非结构化剪枝:直接使用权重级别的掩码param_mask = torch.ones_like(dict(self.model.named_parameters())[name])param_mask.view(-1)[scores.argsort()[:threshold_idx]] = 0self.mask.add_mask(name, param_mask)def prune_model(self, dataloader: torch.utils.data.DataLoader):"""执行模型剪枝"""print(f"开始剪枝,目标剪枝率: {self.config.pruning_ratio:.2%}")# 计算重要性分数self.calculate_importance_scores(dataloader)# 生成剪枝掩码self.generate_pruning_masks()# 应用剪枝掩码self.mask.apply_masks(self.model)sparsity = self.mask.get_sparsity()print(f"剪枝完成,实际稀疏度: {sparsity:.2%}")return self.maskdef demonstrate_pruning():"""演示剪枝流程"""# 创建示例模型model = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 128, 3, padding=1),nn.ReLU(),nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Linear(128, 10))# 剪枝配置config = PruningConfig(pruning_ratio=0.3,structured=True,importance_metric="l1_norm")# 创建剪枝器pruner = ModelPruner(model, config)# 模拟数据集dummy_data = torch.randn(100, 3, 32, 32)dummy_targets = torch.randint(0, 10, (100,))dummy_dataset = torch.utils.data.TensorDataset(dummy_data, dummy_targets)dataloader = torch.utils.data.DataLoader(dummy_dataset, batch_size=16)# 执行剪枝pruning_mask = pruner.prune_model(dataloader)print("剪枝演示完成")return model, pruning_mask
35.4 知识蒸馏实现:大模型向小模型的知识转移
> 知识蒸馏的核心机制与温度调节
软目标的信息富集性是知识蒸馏成功的关键因素。教师模型输出的概率分布包含了比硬标签更丰富的信息,不仅告诉我们正确答案,还反映了不同类别间的相似性关系。例如,在图像分类中,教师模型可能给"猫"0.8的概率,给"狗"0.15的概率,给"汽车"0.05的概率,这种软分布蕴含了"猫狗相似度高于猫车相似度"的知识。
温度参数的作用机制控制概率分布的平滑程度。高温度(T>1)使概率分布更加平滑,突出了非最大类别的概率,有利于传递类别间的相似性信息。低温度(T<1)使分布更加尖锐,接近硬标签。在蒸馏过程中,通常使用T=3-5的温度来平衡信息传递和训练稳定性。温度的选择需要根据任务复杂度和模型差异调节。
损失函数的平衡设计结合蒸馏损失和硬标签损失。蒸馏损失使用KL散度衡量学生模型和教师模型软输出的差异,硬标签损失确保学生模型能正确分类。两种损失的权重平衡α是关键超参数,通常α=0.7意味着更重视知识蒸馏,α=0.3意味着更重视准确分类。权重的选择依赖于教师模型的质量和任务特点。
渐进式蒸馏策略处理教师学生模型能力差距过大的问题。当教师模型远比学生模型复杂时,直接蒸馏可能效果不佳。可以设计中间复杂度的模型作为"助教",形成教师→助教→学生的多级蒸馏链。或者采用渐进式蒸馏,逐步增加蒸馏损失的权重,让学生模型逐步适应软目标的指导。
> 知识蒸馏的完整实现
class DistillationConfig:"""知识蒸馏配置"""def __init__(self,temperature: float = 4.0,alpha: float = 0.7,student_target_layers: list = None,teacher_target_layers: list = None):self.temperature = temperature # 蒸馏温度self.alpha = alpha # 蒸馏损失权重self.student_target_layers = student_target_layers or []self.teacher_target_layers = teacher_target_layers or []class KnowledgeDistiller:"""知识蒸馏训练器"""def __init__(self,teacher_model: nn.Module,student_model: nn.Module,config: DistillationConfig,device: torch.device):self.teacher = teacher_model.to(device)self.student = student_model.to(device)self.config = configself.device = device# 冻结教师模型self.teacher.eval()for param in self.teacher.parameters():param.requires_grad = False# 特征提取钩子self.teacher_features = {}self.student_features = {}self._register_hooks()def _register_hooks(self):"""注册特征提取钩子用于中间层蒸馏"""def get_teacher_hook(name):def hook(module, input, output):self.teacher_features[name] = outputreturn hookdef get_student_hook(name):def hook(module, input, output):self.student_features[name] = outputreturn hook# 为指定层注册钩子for layer_name in self.config.teacher_target_layers:layer = dict(self.teacher.named_modules())[layer_name]layer.register_forward_hook(get_teacher_hook(layer_name))for layer_name in self.config.student_target_layers:layer = dict(self.student.named_modules())[layer_name]layer.register_forward_hook(get_student_hook(layer_name))def distillation_loss(self,student_logits: torch.Tensor,teacher_logits: torch.Tensor,temperature: float) -> torch.Tensor:"""计算知识蒸馏损失"""# 应用温度软化student_soft = F.log_softmax(student_logits / temperature, dim=1)teacher_soft = F.softmax(teacher_logits / temperature, dim=1)# KL散度损失,需要乘以温度平方进行缩放distill_loss = F.kl_div(student_soft, teacher_soft, reduction='batchmean')return distill_loss * (temperature ** 2)def feature_distillation_loss(self) -> torch.Tensor:"""中间层特征蒸馏损失"""feature_loss = torch.tensor(0.0, device=self.device)for teacher_layer, student_layer in zip(self.config.teacher_target_layers,self.config.student_target_layers):if teacher_layer in self.teacher_features and student_layer in self.student_features:teacher_feat = self.teacher_features[teacher_layer]student_feat = self.student_features[student_layer]# 特征维度对齐(如果需要)if teacher_feat.shape != student_feat.shape:# 简单的自适应池化对齐if len(teacher_feat.shape) == 4: # 卷积特征teacher_feat = F.adaptive_avg_pool2d(teacher_feat, student_feat.shape[-2:])student_feat = F.adaptive_avg_pool2d(student_feat, teacher_feat.shape[-2:])# MSE损失feature_loss += F.mse_loss(student_feat, teacher_feat)return feature_lossdef train_step(self,inputs: torch.Tensor,targets: torch.Tensor,optimizer: torch.optim.Optimizer) -> Dict[str, float]:"""单步蒸馏训练"""self.student.train()# 清空梯度optimizer.zero_grad()# 教师模型前向传播with torch.no_grad():teacher_logits = self.teacher(inputs)# 学生模型前向传播student_logits = self.student(inputs)# 计算各种损失# 1. 硬标签损失hard_loss = F.cross_entropy(student_logits, targets)# 2. 蒸馏损失distill_loss = self.distillation_loss(student_logits, teacher_logits, self.config.temperature)# 3. 特征蒸馏损失(如果配置了中间层)feature_loss = self.feature_distillation_loss()# 总损失total_loss = ((1 - self.config.alpha) * hard_loss +self.config.alpha * distill_loss +0.1 * feature_loss # 特征损失权重通常较小)# 反向传播total_loss.backward()optimizer.step()# 清空特征缓存self.teacher_features.clear()self.student_features.clear()return {'total_loss': total_loss.item(),'hard_loss': hard_loss.item(),'distill_loss': distill_loss.item(),'feature_loss': feature_loss.item()}def evaluate(self, dataloader: torch.utils.data.DataLoader) -> Dict[str, float]:"""评估学生模型性能"""self.student.eval()total_loss = 0.0correct = 0total = 0with torch.no_grad():for inputs, targets in dataloader:inputs, targets = inputs.to(self.device), targets.to(self.device)student_logits = self.student(inputs)loss = F.cross_entropy(student_logits, targets)total_loss += loss.item()_, predicted = student_logits.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()return {'loss': total_loss / len(dataloader),'accuracy': 100. * correct / total}def create_student_model(teacher_model: nn.Module, compression_ratio: float = 0.5):"""根据教师模型创建更小的学生模型"""# 这里提供一个简化的示例,实际中需要根据具体模型架构设计if hasattr(teacher_model, 'fc') and hasattr(teacher_model, 'features'):# 类似VGG/ResNet结构teacher_features = teacher_model.featuresteacher_classifier = teacher_model.fc# 创建压缩版本(示例:减少通道数)student = nn.Sequential(# 简化的特征提取器nn.Conv2d(3, int(64 * compression_ratio), 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(int(64 * compression_ratio), int(128 * compression_ratio), 3, padding=1),nn.ReLU(),nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Linear(int(128 * compression_ratio), teacher_classifier.out_features))return studentelse:# 默认返回简化模型return nn.Sequential(nn.Linear(784, 128),nn.ReLU(),nn.Linear(128, 10))
35.5 压缩效果评估:多维度性能分析体系
> 性能评估的全面指标体系
模型大小的多层面分析不仅包括参数数量,还要考虑实际存储需求。FP32模型每个参数占用4字节,INT8量化后每个参数1字节,但还需要考虑量化参数(scale和zero_point)的开销。结构化剪枝直接减少参数数量,而非结构化剪枝虽然参数数量减少,但稀疏存储格式可能引入额外开销。压缩比例的计算需要基于实际存储大小而非理论参数数量。
推理速度的精确测量需要考虑多种因素的影响。端到端延迟包括数据预处理、模型前向传播、后处理的全部时间。吞吐量测试在不同batch size下进行,因为批处理大小显著影响GPU利用率。预热运行排除初始化开销,多次测量取平均值减少测量误差。硬件相关的优化(如TensorRT、ONNX Runtime)对压缩模型的加速效果也需要单独评估。
精度保持的细粒度评估超越简单的整体准确率对比。不同类别的性能变化反映压缩技术对模型知识的影响模式,某些类别可能受影响更大。困难样本的性能变化测试模型在边界情况下的鲁棒性。对抗样本测试评估压缩是否影响模型的安全性。长尾分布数据的性能变化反映压缩对稀有样本的影响。
内存占用的动态监控追踪训练和推理过程中的内存使用模式。峰值内存使用决定了模型是否能在目标硬件上运行,平均内存占用影响多任务并发性能。GPU内存碎片化问题在压缩模型中可能更严重,需要专门分析。内存访问模式的变化(连续访问vs随机访问)影响缓存命中率和实际性能。
class CompressionEvaluator:"""模型压缩效果评估器"""def __init__(self, original_model: nn.Module, compressed_model: nn.Module, device: torch.device):self.original_model = original_model.to(device)self.compressed_model = compressed_model.to(device)self.device = deviceself.evaluation_results = {}def evaluate_model_size(self) -> Dict[str, float]:"""评估模型大小变化"""def count_parameters(model):return sum(p.numel() for p in model.parameters())def calculate_model_size_mb(model):param_size = sum(p.numel() * p.element_size() for p in model.parameters())buffer_size = sum(b.numel() * b.element_size() for b in model.buffers())return (param_size + buffer_size) / (1024 ** 2)original_params = count_parameters(self.original_model)compressed_params = count_parameters(self.compressed_model)original_size_mb = calculate_model_size_mb(self.original_model)compressed_size_mb = calculate_model_size_mb(self.compressed_model)results = {'original_params': original_params,'compressed_params': compressed_params,'param_reduction_ratio': (original_params - compressed_params) / original_params,'original_size_mb': original_size_mb,'compressed_size_mb': compressed_size_mb,'size_reduction_ratio': (original_size_mb - compressed_size_mb) / original_size_mb,'compression_ratio': original_size_mb / compressed_size_mb}self.evaluation_results.update(results)return resultsdef evaluate_inference_speed(self,test_loader: torch.utils.data.DataLoader,num_trials: int = 100) -> Dict[str, float]:"""评估推理速度"""def measure_inference_time(model, data_loader, trials):model.eval()times = []# 预热with torch.no_grad():for i, (inputs, _) in enumerate(data_loader):if i >= 10: # 预热10个batchbreakinputs = inputs.to(self.device)_ = model(inputs)# 正式测量torch.cuda.synchronize() if torch.cuda.is_available() else Nonewith torch.no_grad():for i, (inputs, _) in enumerate(data_loader):if i >= trials:breakinputs = inputs.to(self.device)start_time = time.time()_ = model(inputs)if torch.cuda.is_available():torch.cuda.synchronize()end_time = time.time()times.append((end_time - start_time) * 1000) # 转换为毫秒return timesimport time# 测量两个模型的推理时间original_times = measure_inference_time(self.original_model, test_loader, num_trials)compressed_times = measure_inference_time(self.compressed_model, test_loader, num_trials)# 计算吞吐量(samples per second)batch_size = next(iter(test_loader))[0].size(0)original_throughput = batch_size / (np.mean(original_times) / 1000)compressed_throughput = batch_size / (np.mean(compressed_times) / 1000)results = {'original_avg_time_ms': np.mean(original_times),'original_std_time_ms': np.std(original_times),'compressed_avg_time_ms': np.mean(compressed_times),'compressed_std_time_ms': np.std(compressed_times),'speedup_ratio': np.mean(original_times) / np.mean(compressed_times),'original_throughput_sps': original_throughput,'compressed_throughput_sps': compressed_throughput,'throughput_improvement': compressed_throughput / original_throughput}self.evaluation_results.update(results)return resultsdef evaluate_accuracy_preservation(self,test_loader: torch.utils.data.DataLoader,num_classes: int) -> Dict[str, float]:"""评估精度保持情况"""def evaluate_model(model):model.eval()correct = 0total = 0class_correct = [0] * num_classesclass_total = [0] * num_classesall_predictions = []all_targets = []with torch.no_grad():for inputs, targets in test_loader:inputs, targets = inputs.to(self.device), targets.to(self.device)outputs = model(inputs)_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()# 按类别统计for i in range(targets.size(0)):label = targets[i].item()class_total[label] += 1if predicted[i] == label:class_correct[label] += 1all_predictions.extend(predicted.cpu().numpy())all_targets.extend(targets.cpu().numpy())accuracy = 100. * correct / totalclass_accuracies = [100. * class_correct[i] / class_total[i] if class_total[i] > 0 else 0 for i in range(num_classes)]return {'accuracy': accuracy,'class_accuracies': class_accuracies,'predictions': all_predictions,'targets': all_targets}# 评估两个模型original_results = evaluate_model(self.original_model)compressed_results = evaluate_model(self.compressed_model)# 计算性能变化accuracy_drop = original_results['accuracy'] - compressed_results['accuracy']relative_accuracy_drop = accuracy_drop / original_results['accuracy']# 计算各类别精度变化class_accuracy_changes = []for i in range(num_classes):original_acc = original_results['class_accuracies'][i]compressed_acc = compressed_results['class_accuracies'][i]change = compressed_acc - original_accclass_accuracy_changes.append(change)results = {'original_accuracy': original_results['accuracy'],'compressed_accuracy': compressed_results['accuracy'],'accuracy_drop': accuracy_drop,'relative_accuracy_drop': relative_accuracy_drop,'class_accuracy_changes': class_accuracy_changes,'worst_class_drop': min(class_accuracy_changes),'best_class_improvement': max(class_accuracy_changes)}self.evaluation_results.update(results)return resultsdef evaluate_memory_usage(self, test_loader: torch.utils.data.DataLoader) -> Dict[str, float]:"""评估内存使用情况"""def measure_memory_usage(model):if not torch.cuda.is_available():return {'peak_memory_mb': 0, 'allocated_memory_mb': 0}torch.cuda.empty_cache()torch.cuda.reset_peak_memory_stats()model.eval()with torch.no_grad():# 取一个batch进行测试inputs, _ = next(iter(test_loader))inputs = inputs.to(self.device)_ = model(inputs)peak_memory = torch.cuda.max_memory_allocated() / (1024 ** 2)current_memory = torch.cuda.memory_allocated() / (1024 ** 2)return {'peak_memory_mb': peak_memory,'allocated_memory_mb': current_memory}original_memory = measure_memory_usage(self.original_model)compressed_memory = measure_memory_usage(self.compressed_model)results = {'original_peak_memory_mb': original_memory['peak_memory_mb'],'compressed_peak_memory_mb': compressed_memory['peak_memory_mb'],'memory_reduction_mb': original_memory['peak_memory_mb'] - compressed_memory['peak_memory_mb'],'memory_reduction_ratio': (original_memory['peak_memory_mb'] - compressed_memory['peak_memory_mb']) / original_memory['peak_memory_mb']if original_memory['peak_memory_mb'] > 0 else 0}self.evaluation_results.update(results)return resultsdef generate_comprehensive_report(self) -> str:"""生成综合评估报告"""report = "=== 模型压缩效果综合评估报告 ===\n\n"if 'compression_ratio' in self.evaluation_results:report += f"📊 模型大小分析:\n"report += f" • 参数数量: {self.evaluation_results['original_params']:,} → {self.evaluation_results['compressed_params']:,}\n"report += f" • 参数减少: {self.evaluation_results['param_reduction_ratio']:.2%}\n"report += f" • 存储大小: {self.evaluation_results['original_size_mb']:.2f}MB → {self.evaluation_results['compressed_size_mb']:.2f}MB\n"report += f" • 压缩比例: {self.evaluation_results['compression_ratio']:.2f}x\n\n"if 'speedup_ratio' in self.evaluation_results:report += f"⚡ 推理速度分析:\n"report += f" • 平均延迟: {self.evaluation_results['original_avg_time_ms']:.2f}ms → {self.evaluation_results['compressed_avg_time_ms']:.2f}ms\n"report += f" • 加速比例: {self.evaluation_results['speedup_ratio']:.2f}x\n"report += f" • 吞吐量提升: {self.evaluation_results['throughput_improvement']:.2f}x\n\n"if 'accuracy_drop' in self.evaluation_results:report += f"🎯 精度保持分析:\n"report += f" • 原始精度: {self.evaluation_results['original_accuracy']:.2f}%\n"report += f" • 压缩后精度: {self.evaluation_results['compressed_accuracy']:.2f}%\n"report += f" • 精度下降: {self.evaluation_results['accuracy_drop']:.2f}% ({self.evaluation_results['relative_accuracy_drop']:.2%})\n"report += f" • 最大类别精度损失: {-self.evaluation_results['worst_class_drop']:.2f}%\n\n"if 'memory_reduction_ratio' in self.evaluation_results:report += f"💾 内存使用分析:\n"report += f" • 峰值内存: {self.evaluation_results['original_peak_memory_mb']:.2f}MB → {self.evaluation_results['compressed_peak_memory_mb']:.2f}MB\n"report += f" • 内存节省: {self.evaluation_results['memory_reduction_ratio']:.2%}\n\n"# 综合评价report += f"📈 综合评价:\n"if 'speedup_ratio' in self.evaluation_results and 'accuracy_drop' in self.evaluation_results:efficiency_score = self.evaluation_results['speedup_ratio'] / (1 + abs(self.evaluation_results['relative_accuracy_drop']))report += f" • 效率得分: {efficiency_score:.2f} (加速比/精度损失权衡)\n"if self.evaluation_results['speedup_ratio'] >= 2.0 and abs(self.evaluation_results['accuracy_drop']) <= 3.0:report += f" • ✅ 达到目标要求 (2x加速, ≤3%精度损失)\n"else:report += f" • ❌ 未达到目标要求 (需要2x加速, ≤3%精度损失)\n"return reportdef plot_evaluation_results(self):"""可视化评估结果"""fig, axes = plt.subplots(2, 2, figsize=(15, 12))# 模型大小对比if 'original_size_mb' in self.evaluation_results:sizes = [self.evaluation_results['original_size_mb'], self.evaluation_results['compressed_size_mb']]labels = ['Original', 'Compressed']axes[0, 0].bar(labels, sizes, color=['skyblue', 'lightcoral'])axes[0, 0].set_title('Model Size Comparison')axes[0, 0].set_ylabel('Size (MB)')for i, v in enumerate(sizes):axes[0, 0].text(i, v + 0.1, f'{v:.1f}MB', ha='center')# 推理速度对比if 'original_avg_time_ms' in self.evaluation_results:times = [self.evaluation_results['original_avg_time_ms'], self.evaluation_results['compressed_avg_time_ms']]labels = ['Original', 'Compressed']axes[0, 1].bar(labels, times, color=['skyblue', 'lightcoral'])axes[0, 1].set_title('Inference Time Comparison')axes[0, 1].set_ylabel('Time (ms)')for i, v in enumerate(times):axes[0, 1].text(i, v + 0.1, f'{v:.1f}ms', ha='center')# 精度对比if 'original_accuracy' in self.evaluation_results:accuracies = [self.evaluation_results['original_accuracy'], self.evaluation_results['compressed_accuracy']]labels = ['Original', 'Compressed']axes[1, 0].bar(labels, accuracies, color=['skyblue', 'lightcoral'])axes[1, 0].set_title('Accuracy Comparison')axes[1, 0].set_ylabel('Accuracy (%)')axes[1, 0].set_ylim([min(accuracies) - 2, 100])for i, v in enumerate(accuracies):axes[1, 0].text(i, v + 0.5, f'{v:.1f}%', ha='center')# 综合指标雷达图if all(k in self.evaluation_results for k in ['compression_ratio', 'speedup_ratio', 'relative_accuracy_drop']):# 标准化指标到0-100范围compression_score = min(self.evaluation_results['compression_ratio'] * 20, 100)speed_score = min(self.evaluation_results['speedup_ratio'] * 50, 100)accuracy_score = max(0, 100 - abs(self.evaluation_results['relative_accuracy_drop']) * 1000)categories = ['Compression', 'Speed', 'Accuracy']scores = [compression_score, speed_score, accuracy_score]axes[1, 1].bar(categories, scores, color=['gold', 'lightgreen', 'lightblue'])axes[1, 1].set_title('Overall Performance Scores')axes[1, 1].set_ylabel('Score (0-100)')axes[1, 1].set_ylim([0, 100])for i, v in enumerate(scores):axes[1, 1].text(i, v + 2, f'{v:.0f}', ha='center')plt.tight_layout()plt.show()
35.6 综合优化策略:多技术协同的压缩方案
当单一压缩技术无法满足性能要求时,需要设计多技术协同的综合压缩方案。技术组合的协同效应往往能实现1+1>2的效果,但也可能产生负面交互。量化和剪枝的结合是最常见的方案:先剪枝去除不重要的参数,再量化降低数值精度。知识蒸馏可以在压缩过程中恢复部分性能损失,特别适合大幅度压缩场景。
渐进式压缩流程避免激进压缩带来的性能崩塌。典型流程是:知识蒸馏→结构化剪枝→量化感知训练→最终微调。每个阶段都需要适度的性能恢复训练,确保压缩效果的积累而非损失的累积。阶段间的衔接策略很重要,比如在剪枝后立即进行短期微调,然后再开始量化感知训练。
硬件感知的优化策略针对目标部署环境进行定制化优化。不同硬件平台的计算特点差异很大,RTX 2050的Tensor Core对INT8计算友好,但对稀疏矩阵支持有限。因此在这个平台上,量化优先级高于非结构化剪枝。批处理大小的选择也需要考虑GPU内存限制和计算单元利用率。
> RTX 2050优化实战项目

import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import time
import json
from typing import Dict, List, Optional, Tuple
import matplotlib.pyplot as pltclass QuantizationConfig:"""量化配置类"""def __init__(self, num_bits: int = 8, symmetric: bool = True):self.num_bits = num_bitsself.symmetric = symmetricself.qmin = -(2 ** (num_bits - 1))self.qmax = 2 ** (num_bits - 1) - 1class FakeQuantize(nn.Module):"""伪量化层,用于量化感知训练"""def __init__(self, config: QuantizationConfig):super().__init__()self.config = configself.scale = nn.Parameter(torch.tensor(1.0))self.zero_point = nn.Parameter(torch.tensor(0.0))self.observed_min = torch.tensor(float('inf'))self.observed_max = torch.tensor(float('-inf'))self.calibrated = Falsedef forward(self, x: torch.Tensor) -> torch.Tensor:if self.training and not self.calibrated:# 观测数据范围self.observed_min = torch.min(self.observed_min, x.min())self.observed_max = torch.max(self.observed_max, x.max())# 更新量化参数if self.config.symmetric:max_range = torch.max(torch.abs(self.observed_min), torch.abs(self.observed_max))self.scale.data = max_range / (self.config.qmax - self.config.qmin) * 2else:self.scale.data = (self.observed_max - self.observed_min) / (self.config.qmax - self.config.qmin)self.zero_point.data = self.config.qmin - self.observed_min / self.scale.data# 伪量化:量化后立即反量化if self.scale > 0:quantized = torch.round(x / self.scale) + self.zero_pointquantized = torch.clamp(quantized, self.config.qmin, self.config.qmax)return (quantized - self.zero_point) * self.scalereturn xclass SimplePruner:"""简化的剪枝器"""def __init__(self, model: nn.Module, pruning_ratio: float = 0.3):self.model = modelself.pruning_ratio = pruning_ratioself.masks = {}def calculate_importance_scores(self):"""基于L1范数计算重要性"""for name, param in self.model.named_parameters():if 'weight' in name and param.dim() > 1:if 'conv' in name.lower():# 卷积层按通道计算importance = param.abs().sum(dim=(1, 2, 3))else:# 线性层按输出神经元计算importance = param.abs().sum(dim=1)# 生成掩码sorted_scores, indices = importance.sort()threshold_idx = int(len(sorted_scores) * self.pruning_ratio)threshold = sorted_scores[threshold_idx]mask = (importance > threshold).float()if 'conv' in name.lower():mask = mask.unsqueeze(1).unsqueeze(2).unsqueeze(3).expand_as(param)else:mask = mask.unsqueeze(1).expand_as(param)self.masks[name] = maskdef apply_pruning(self):"""应用剪枝掩码"""self.calculate_importance_scores()for name, param in self.model.named_parameters():if name in self.masks:param.data *= self.masks[name]# 计算稀疏度total_params = sum(p.numel() for p in self.model.parameters() if p.requires_grad)zero_params = sum((self.masks[name] == 0).sum().item() for name in self.masks)sparsity = zero_params / total_params if total_params > 0 else 0return sparsityclass SimpleDistiller:"""简化的知识蒸馏器"""def __init__(self, teacher: nn.Module, student: nn.Module, temperature: float = 4.0, alpha: float = 0.7):self.teacher = teacher.eval()self.student = studentself.temperature = temperatureself.alpha = alpha# 冻结教师模型for param in self.teacher.parameters():param.requires_grad = Falsedef distillation_loss(self, student_logits, teacher_logits, targets):"""计算蒸馏损失"""# 硬标签损失hard_loss = F.cross_entropy(student_logits, targets)# 蒸馏损失student_soft = F.log_softmax(student_logits / self.temperature, dim=1)teacher_soft = F.softmax(teacher_logits / self.temperature, dim=1)distill_loss = F.kl_div(student_soft, teacher_soft, reduction='batchmean') * (self.temperature ** 2)# 总损失total_loss = (1 - self.alpha) * hard_loss + self.alpha * distill_lossreturn total_loss, hard_loss.item(), distill_loss.item()class PerformanceEvaluator:"""性能评估器"""def __init__(self, device):self.device = devicedef evaluate_accuracy(self, model, dataloader):"""评估准确率"""model.eval()correct = 0total = 0with torch.no_grad():for inputs, targets in dataloader:inputs, targets = inputs.to(self.device), targets.to(self.device)outputs = model(inputs)_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()return 100. * correct / totaldef measure_inference_time(self, model, dataloader, num_trials=20):"""测量推理时间"""model.eval()times = []# 预热with torch.no_grad():for i, (inputs, _) in enumerate(dataloader):if i >= 5:breakinputs = inputs.to(self.device)_ = model(inputs)# 正式测量with torch.no_grad():for i, (inputs, _) in enumerate(dataloader):if i >= num_trials:breakinputs = inputs.to(self.device)if torch.cuda.is_available():torch.cuda.synchronize()start_time = time.time()_ = model(inputs)if torch.cuda.is_available():torch.cuda.synchronize()end_time = time.time()times.append((end_time - start_time) * 1000) # 转为毫秒return np.mean(times), np.std(times)def calculate_model_size(self, model):"""计算模型大小"""param_count = sum(p.numel() for p in model.parameters())param_size = sum(p.numel() * p.element_size() for p in model.parameters())buffer_size = sum(b.numel() * b.element_size() for b in model.buffers())total_size_mb = (param_size + buffer_size) / (1024 ** 2)return param_count, total_size_mbclass RTX2050OptimizationPipeline:"""面向RTX 2050的模型优化流水线"""def __init__(self, model: nn.Module, target_speedup: float = 2.0, max_accuracy_drop: float = 3.0):self.original_model = modelself.target_speedup = target_speedupself.max_accuracy_drop = max_accuracy_dropself.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.evaluator = PerformanceEvaluator(self.device)self.optimization_log = []# 检测硬件if torch.cuda.is_available():self.gpu_name = torch.cuda.get_device_name()self.supports_tensor_core = "RTX" in self.gpu_name or "A100" in self.gpu_nameelse:self.gpu_name = "CPU"self.supports_tensor_core = Falseprint(f"目标硬件: {self.gpu_name}")print(f"Tensor Core支持: {self.supports_tensor_core}")def create_student_model(self):"""创建高效的学生模型"""# 创建更小的模型架构return nn.Sequential(nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.AdaptiveAvgPool2d((4, 4)),nn.Flatten(),nn.Linear(64 * 16, 128),nn.ReLU(),nn.Dropout(0.3),nn.Linear(128, 10)).to(self.device)def stage1_knowledge_distillation(self, train_loader, val_loader):"""阶段1: 知识蒸馏"""print("\n=== 阶段1: 知识蒸馏 ===")student_model = self.create_student_model()distiller = SimpleDistiller(self.original_model, student_model)optimizer = torch.optim.AdamW(student_model.parameters(), lr=1e-3, weight_decay=1e-4)# 简化的训练循环for epoch in range(3): # 演示用较少轮数student_model.train()total_loss = 0batch_count = 0for batch_idx, (inputs, targets) in enumerate(train_loader):if batch_idx >= 10: # 演示用较少批次breakinputs, targets = inputs.to(self.device), targets.to(self.device)with torch.no_grad():teacher_outputs = self.original_model(inputs)student_outputs = student_model(inputs)loss, hard_loss, distill_loss = distiller.distillation_loss(student_outputs, teacher_outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()batch_count += 1if batch_idx % 5 == 0:print(f' Epoch {epoch}, Batch {batch_idx}: Loss={loss.item():.4f}')avg_loss = total_loss / batch_count if batch_count > 0 else 0accuracy = self.evaluator.evaluate_accuracy(student_model, val_loader)print(f' Epoch {epoch}: Avg Loss={avg_loss:.4f}, Accuracy={accuracy:.2f}%')# 记录结果final_accuracy = self.evaluator.evaluate_accuracy(student_model, val_loader)param_count, model_size = self.evaluator.calculate_model_size(student_model)self.optimization_log.append({'stage': 'Knowledge Distillation','accuracy': final_accuracy,'model_params': param_count,'model_size_mb': model_size})print(f" 蒸馏完成: 精度={final_accuracy:.2f}%, 参数量={param_count:,}, 大小={model_size:.2f}MB")return student_modeldef stage2_structured_pruning(self, model, train_loader, val_loader):"""阶段2: 结构化剪枝"""print("\n=== 阶段2: 结构化剪枝 ===")pruner = SimplePruner(model, pruning_ratio=0.3)sparsity = pruner.apply_pruning()print(f" 剪枝完成,稀疏度: {sparsity:.2%}")# 剪枝后微调optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-5)print(" 开始剪枝后微调...")for epoch in range(2): # 简化的微调model.train()for batch_idx, (inputs, targets) in enumerate(train_loader):if batch_idx >= 10:breakinputs, targets = inputs.to(self.device), targets.to(self.device)optimizer.zero_grad()outputs = model(inputs)loss = F.cross_entropy(outputs, targets)loss.backward()# 重新应用掩码for name, param in model.named_parameters():if name in pruner.masks:param.grad *= pruner.masks[name]optimizer.step()# 确保权重仍然为0for name, param in model.named_parameters():if name in pruner.masks:param.data *= pruner.masks[name]accuracy = self.evaluator.evaluate_accuracy(model, val_loader)param_count, model_size = self.evaluator.calculate_model_size(model)self.optimization_log.append({'stage': 'Structured Pruning','accuracy': accuracy,'sparsity': sparsity,'model_params': param_count,'model_size_mb': model_size})print(f" 剪枝微调完成: 精度={accuracy:.2f}%, 稀疏度={sparsity:.2%}")return modeldef stage3_quantization_aware_training(self, model, train_loader, val_loader):"""阶段3: 量化感知训练"""print("\n=== 阶段3: 量化感知训练 ===")# 插入量化层quant_config = QuantizationConfig(num_bits=8, symmetric=True)# 为卷积和线性层添加量化for name, module in model.named_modules():if isinstance(module, (nn.Conv2d, nn.Linear)):# 添加权重量化setattr(module, 'weight_quantizer', FakeQuantize(quant_config))# 添加激活量化setattr(module, 'activation_quantizer', FakeQuantize(quant_config))# 修改前向传播以包含量化original_forward_methods = {}def create_quantized_forward(original_forward, module):def quantized_forward(x):if hasattr(module, 'weight'):# 量化权重quantized_weight = module.weight_quantizer(module.weight)# 临时替换权重original_weight = module.weight.datamodule.weight.data = quantized_weight# 执行原始前向传播output = original_forward(x)# 恢复原始权重module.weight.data = original_weight# 量化激活if hasattr(module, 'activation_quantizer'):output = module.activation_quantizer(output)return outputelse:return original_forward(x)return quantized_forward# 替换前向传播方法for name, module in model.named_modules():if isinstance(module, (nn.Conv2d, nn.Linear)):original_forward_methods[name] = module.forwardmodule.forward = create_quantized_forward(module.forward, module)# 量化感知训练optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-5)print(" 开始量化感知训练...")for epoch in range(2): # 简化的训练model.train()for batch_idx, (inputs, targets) in enumerate(train_loader):if batch_idx >= 10:breakinputs, targets = inputs.to(self.device), targets.to(self.device)optimizer.zero_grad()outputs = model(inputs)loss = F.cross_entropy(outputs, targets)loss.backward()optimizer.step()if batch_idx % 5 == 0:print(f' Epoch {epoch}, Batch {batch_idx}: QAT Loss={loss.item():.4f}')# 标记量化已校准for name, module in model.named_modules():if hasattr(module, 'weight_quantizer'):module.weight_quantizer.calibrated = Trueif hasattr(module, 'activation_quantizer'):module.activation_quantizer.calibrated = Trueaccuracy = self.evaluator.evaluate_accuracy(model, val_loader)param_count, model_size = self.evaluator.calculate_model_size(model)self.optimization_log.append({'stage': 'Quantization Aware Training','accuracy': accuracy,'model_params': param_count,'model_size_mb': model_size})print(f" 量化训练完成: 精度={accuracy:.2f}%")return modeldef run_optimization_pipeline(self, train_loader, val_loader):"""运行完整优化流水线"""print(f"\n开始RTX 2050优化流水线")print(f"目标: {self.target_speedup}x加速,≤{self.max_accuracy_drop}%精度损失")# 评估原始模型original_accuracy = self.evaluator.evaluate_accuracy(self.original_model, val_loader)original_param_count, original_size = self.evaluator.calculate_model_size(self.original_model)original_time_mean, original_time_std = self.evaluator.measure_inference_time(self.original_model, val_loader, num_trials=10)print(f"\n原始模型基准:")print(f" 精度: {original_accuracy:.2f}%")print(f" 参数量: {original_param_count:,}")print(f" 模型大小: {original_size:.2f}MB")print(f" 推理时间: {original_time_mean:.2f}±{original_time_std:.2f}ms")# 阶段1: 知识蒸馏student_model = self.stage1_knowledge_distillation(train_loader, val_loader)# 阶段2: 结构化剪枝pruned_model = self.stage2_structured_pruning(student_model, train_loader, val_loader)# 阶段3: 量化感知训练final_model = self.stage3_quantization_aware_training(pruned_model, train_loader, val_loader)# 最终评估print("\n=== 最终评估 ===")final_accuracy = self.evaluator.evaluate_accuracy(final_model, val_loader)final_param_count, final_size = self.evaluator.calculate_model_size(final_model)final_time_mean, final_time_std = self.evaluator.measure_inference_time(final_model, val_loader, num_trials=10)# 计算改进指标accuracy_drop = original_accuracy - final_accuracycompression_ratio = original_size / final_sizespeedup_ratio = original_time_mean / final_time_meanparam_reduction = (original_param_count - final_param_count) / original_param_countprint(f"\n📊 优化结果总结:")print(f" 精度变化: {original_accuracy:.2f}% → {final_accuracy:.2f}% (下降{accuracy_drop:.2f}%)")print(f" 模型大小: {original_size:.2f}MB → {final_size:.2f}MB (压缩{compression_ratio:.2f}x)")print(f" 推理速度: {original_time_mean:.2f}ms → {final_time_mean:.2f}ms (加速{speedup_ratio:.2f}x)")print(f" 参数减少: {param_reduction:.2%}")# 检查目标达成情况speedup_achieved = speedup_ratio >= self.target_speedupaccuracy_maintained = accuracy_drop <= self.max_accuracy_dropprint(f"\n🎯 目标达成情况:")print(f" 加速目标 ({self.target_speedup}x): {'✅ 达成' if speedup_achieved else '❌ 未达成'}")print(f" 精度目标 (≤{self.max_accuracy_drop}%): {'✅ 达成' if accuracy_maintained else '❌ 未达成'}")if speedup_achieved and accuracy_maintained:print(f"\n🎉 优化目标完全达成!")else:print(f"\n⚠️ 部分目标未达成,建议进一步调优")# 保存优化日志final_results = {'original_model': {'accuracy': original_accuracy,'params': original_param_count,'size_mb': original_size,'inference_time_ms': original_time_mean},'optimized_model': {'accuracy': final_accuracy,'params': final_param_count,'size_mb': final_size,'inference_time_ms': final_time_mean},'improvements': {'accuracy_drop': accuracy_drop,'compression_ratio': compression_ratio,'speedup_ratio': speedup_ratio,'param_reduction_ratio': param_reduction},'stages': self.optimization_log}# 保存结果with open('rtx2050_optimization_results.json', 'w') as f:json.dump(final_results, f, indent=2)print(f"\n详细结果已保存到 rtx2050_optimization_results.json")return final_model, final_resultsdef run_rtx2050_optimization_demo():"""RTX 2050优化演示"""print("=== RTX 2050 模型优化演示 ===")# 设备检测device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print(f"使用设备: {device}")# 创建示例模型(模拟一个中等复杂度的分类模型)original_model = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(64, 128, 3, padding=1),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(128, 256, 3, padding=1),nn.ReLU(),nn.AdaptiveAvgPool2d((4, 4)),nn.Flatten(),nn.Linear(256 * 16, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 10)).to(device)# 创建演示数据集(模拟CIFAR-10)print("\n创建演示数据集...")train_size = 500 # 演示用较小数据集val_size = 200# 生成随机数据train_data = torch.randn(train_size, 3, 32, 32)train_targets = torch.randint(0, 10, (train_size,))val_data = torch.randn(val_size, 3, 32, 32)val_targets = torch.randint(0, 10, (val_size,))# 创建数据加载器train_dataset = torch.utils.data.TensorDataset(train_data, train_targets)val_dataset = torch.utils.data.TensorDataset(val_data, val_targets)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=False)# 创建优化流水线optimizer = RTX2050OptimizationPipeline(model=original_model,target_speedup=2.0,max_accuracy_drop=3.0)# 运行优化流水线optimized_model, results = optimizer.run_optimization_pipeline(train_loader, val_loader)print(f"\n=== 演示完成 ===")print(f"注意: 这是演示版本,使用了随机数据和简化的训练过程")print(f"实际项目中需要:")print(f" 1. 真实的训练数据集")print(f" 2. 更多的训练轮数")print(f" 3. 更精细的超参数调优")print(f" 4. 更全面的模型验证")return optimized_model, resultsif __name__ == "__main__":# 运行演示optimized_model, results = run_rtx2050_optimization_demo()
35.7 实战项目总结与生产级部署
通过本课程的深入学习,你已经掌握了模型压缩的完整技术体系。从基础的量化技术到复杂的多策略协同优化,这些技术构成了在资源受限环境下部署大模型的核心能力。
技术整合的关键洞察:单一压缩技术往往无法满足实际部署需求,需要根据具体硬件特点和性能要求设计综合优化方案。量化技术在现代GPU上效果显著,结构化剪枝能实现真正的推理加速,知识蒸馏提供了性能恢复的有效途径。三者的协同使用通常能达到最佳的性能平衡点。
硬件感知优化的重要性:不同硬件平台的计算特点决定了最优的压缩策略。RTX 2050等消费级GPU对INT8量化支持良好,但稀疏计算能力有限,因此量化优先级高于非结构化剪枝。批处理大小、内存访问模式、计算并行度都需要针对目标硬件进行专门优化。
渐进式优化的策略价值:避免一次性激进压缩导致的性能崩塌,通过多阶段渐进式优化,让模型逐步适应结构和精度的变化。知识蒸馏→结构化剪枝→量化感知训练的流水线是经过实践验证的有效方案,每个阶段都包含适度的恢复训练。
评估体系的全面性:模型压缩效果的评估不能仅看单一指标,需要建立包含模型大小、推理速度、精度保持、内存占用的多维度评估体系。真实部署环境的测试结果比理论分析更具指导价值,端到端的性能测量更能反映用户体验。
> 专业术语表
量化(Quantization):将浮点数权重和激活值转换为低精度整数表示的过程,显著减少模型大小和计算开销
缩放因子(Scale Factor):量化过程中用于确定浮点数和整数映射关系的参数,决定量化精度
零点偏移(Zero Point):确保浮点数零能精确映射到整数空间的偏移量,避免量化偏差
伪量化(Fake Quantization):训练过程中模拟量化操作但保持浮点计算的技术,用于量化感知训练
梯度直通估计(Straight Through Estimator):解决不可微操作反向传播的技术,前向执行量化,反向直接传递梯度
结构化剪枝(Structured Pruning):删除整个神经元、通道或层的剪枝方法,能在标准硬件上实现真正加速
非结构化剪枝(Unstructured Pruning):删除单个权重参数的剪枝方法,可达到更高稀疏度但需要专门硬件支持
知识蒸馏(Knowledge Distillation):通过软目标传递教师模型知识到学生模型的技术,实现模型压缩
温度参数(Temperature Parameter):控制知识蒸馏中概率分布平滑程度的参数,影响知识传递效果
量化感知训练(Quantization Aware Training):训练过程中模拟量化操作,让模型适应量化带来的数值扰动
混合精度(Mixed Precision):在同一模型中使用不同精度数值表示的策略,平衡性能和精度
参数高效微调(PEFT):以很少的可训练参数实现模型适配的技术,如LoRA等
Tensor Core:NVIDIA GPU中专门用于混合精度矩阵运算的硬件单元,对特定数据类型有加速作用