深入浅出Disruptor:高性能并发框架的设计与实践

目录
- 一、Disruptor是什么?为何而生?
- 1.1 基本定义
- 1.2 诞生背景
- 二、Disruptor的核心优势
- 三、Disruptor的核心组件与结构
- 3.1 核心组件
- (1)Ring Buffer(环形缓冲区)
- (2)Sequence(序列号)
- (3)Sequencer(序列器)
- (4)EventHandler(事件处理器)
- (5)EventFactory(事件工厂)
- (6)Producer(生产者)
- (7)WaitStrategy(等待策略)
- 3.2 整体结构关系
- 四、Disruptor的核心技术:为何如此之快?
- 4.1 无锁设计:CAS替代锁
- 4.2 消除伪共享(False Sharing)
- 4.3 固定大小与预分配:减少GC与内存开销
- 4.4 批量处理:提高吞吐量
- 五、Disruptor的工作流程
- 5.1 初始化阶段
- 5.2 事件发布阶段(生产者)
- 5.3 事件消费阶段(消费者)
- 六、多消费者模式:灵活的依赖关系
- 6.1 并行消费(多消费者独立处理)
- 6.2 串行消费(多消费者按顺序处理)
- 6.3 混合消费(并行+串行)
- 七、Disruptor使用示例
- 7.1 定义事件类
- 7.2 实现事件工厂
- 7.3 实现事件处理器(消费者)
- 7.4 配置并启动Disruptor
- 7.5 运行结果
- 八、Disruptor的应用场景与局限性
- 8.1 典型应用场景
- 8.2 局限性
- 九、总结
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
在高并发场景中,传统的队列(如ArrayBlockingQueue)往往因为锁竞争、线程阻塞等问题成为性能瓶颈。而Disruptor作为一款由LMAX(英国外汇交易公司)开发的高性能异步处理框架,凭借其独特的无锁设计和优化策略,在金融交易、日志处理等对吞吐量和延迟要求极高的场景中大放异彩。本文将从核心原理、结构设计到实际应用,全面解析Disruptor。
一、Disruptor是什么?为何而生?
1.1 基本定义
Disruptor是一个高性能的线程间消息传递库,它通过环形缓冲区(Ring Buffer)和无锁设计,实现了生产者与消费者之间的高效数据传递,旨在解决高并发场景下的队列性能瓶颈。
1.2 诞生背景
LMAX在开发高频交易系统时,发现传统的并发队列(如ConcurrentLinkedQueue)存在严重的性能问题:
- 锁竞争导致线程频繁阻塞/唤醒,上下文切换开销大;
- 队列扩容带来的内存分配和数据迁移开销;
- 缓存伪共享(False Sharing)导致的CPU缓存利用率低。
为解决这些问题,LMAX团队设计了Disruptor,其核心目标是:在高并发下实现低延迟、高吞吐量的数据传递。在官方测试中,Disruptor的吞吐量可达传统队列的数倍甚至数十倍。
二、Disruptor的核心优势
与传统并发队列相比,Disruptor的核心优势体现在以下几点:
| 特性 | 传统队列(如ArrayBlockingQueue) | Disruptor |
|---|---|---|
| 数据结构 | 动态数组/链表(可扩容) | 固定大小的环形缓冲区(不可扩容) |
| 并发控制 | 基于锁(ReentrantLock) | 无锁(CAS操作 + 序列号) |
| 伪共享处理 | 未优化(缓存行冲突严重) | 主动消除(缓存行填充) |
| 批量处理支持 | 弱(需手动控制) | 强(通过序列号范围批量处理) |
| 延迟与吞吐量 | 中低(锁竞争、上下文切换) | 高低(无锁设计,减少开销) |
简单来说,Disruptor通过“空间换时间”(固定大小缓冲区)和“无锁化设计”,最大限度减少了并发场景下的性能损耗。
三、Disruptor的核心组件与结构
Disruptor的核心结构围绕“环形缓冲区”和“序列号”展开,理解这些组件是掌握Disruptor的关键。
3.1 核心组件
(1)Ring Buffer(环形缓冲区)
RingBuffer是Disruptor的核心数据结构,本质是一个固定大小的数组(而非链表),因操作时通过“取模”实现环形访问而得名。
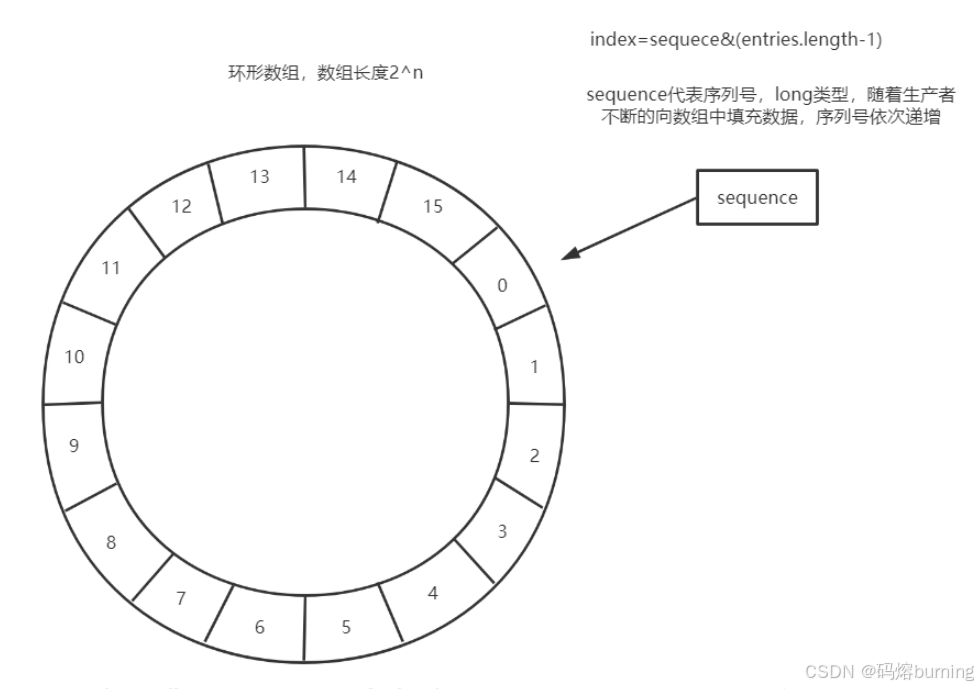
关键特点:
- 固定大小:创建时指定容量(必须是2的幂,如1024、2048),运行中不可扩容(避免内存分配开销)。
- 元素预分配:初始化时已创建所有元素对象(通过
EventFactory),后续仅修改元素内容,不新建对象(减少GC)。 - 序列号定位:通过“序列号 % 容量”计算元素在数组中的索引(如容量为8,序列号9的索引为1)。
(2)Sequence(序列号)
Sequence是Disruptor实现无锁并发的核心,本质是一个volatile修饰的long变量,用于跟踪生产者/消费者的进度。
- 生产者序列号:记录生产者已写入的最新事件位置(
nextPublish)。 - 消费者序列号:每个消费者都有一个
Sequence,记录其已处理的最新事件位置。
通过比较序列号,Disruptor可无锁判断“是否有新事件可处理”或“是否有空间写入新事件”。
(3)Sequencer(序列器)
Sequencer是Disruptor的“大脑”,负责协调生产者与消费者的序列号,控制事件的发布与消费节奏。主要实现有两种:
SingleProducerSequencer:单生产者场景(性能更优,无生产者间竞争)。MultiProducerSequencer:多生产者场景(通过CAS解决生产者间的序列号竞争)。
(4)EventHandler(事件处理器)
EventHandler是消费者的核心接口,定义了事件处理逻辑,其核心方法为:
void onEvent(T event, long sequence, boolean endOfBatch) throws Exception;
event:待处理的事件对象。sequence:事件对应的序列号。endOfBatch:是否为批量处理的最后一个事件(用于优化批量操作)。
(5)EventFactory(事件工厂)
EventFactory用于初始化RingBuffer中的事件对象(预分配),确保缓冲区创建时所有元素已存在:
public interface EventFactory<T> {T newInstance();
}
(6)Producer(生产者)
生产者负责向RingBuffer写入事件,核心流程是:
- 获取下一个可写入的序列号(通过
Sequencer)。 - 从
RingBuffer中获取该序列号对应的事件对象。 - 修改事件内容。
- 发布事件(更新生产者序列号,通知消费者)。
(7)WaitStrategy(等待策略)
当消费者无新事件可处理时,WaitStrategy定义了其等待方式(影响延迟和CPU占用)。常见实现:
BlockingWaitStrategy:阻塞等待(类似ArrayBlockingQueue,CPU占用低,延迟高)。SleepingWaitStrategy:自旋+短暂睡眠(平衡CPU和延迟,适合低延迟场景)。YieldingWaitStrategy:自旋+yield(CPU占用高,延迟低,适合对延迟敏感的场景)。BusySpinWaitStrategy:纯自旋(CPU占用极高,延迟极低,适合绑定CPU核心的场景)。
3.2 整体结构关系
各组件的协作关系可概括为:
RingBuffer存储事件,通过EventFactory预分配。Sequencer协调生产者和消费者的Sequence,控制事件发布/消费节奏。- 生产者通过
Sequencer获取序列号,写入事件后发布。 - 消费者通过
EventHandler处理事件,其Sequence跟踪处理进度。 WaitStrategy决定消费者无事件时的等待方式。
四、Disruptor的核心技术:为何如此之快?
Disruptor的高性能源于其对并发细节的极致优化,核心技术包括:
4.1 无锁设计:CAS替代锁
传统队列使用锁(如ReentrantLock)保证线程安全,导致线程阻塞/唤醒的上下文切换开销。Disruptor则通过CAS(Compare-And-Swap)操作实现无锁并发:
- 生产者获取序列号时,通过CAS原子性更新“下一个可用序列号”(多生产者场景)。
- 消费者处理事件时,通过比较序列号判断是否有新事件,无需加锁。
CAS是CPU级别的原子操作,开销远小于锁的上下文切换。
4.2 消除伪共享(False Sharing)
伪共享是CPU缓存机制导致的性能问题:CPU缓存以“缓存行”(通常64字节)为单位存储数据,若多个线程频繁修改同一缓存行中的不同变量,会导致缓存行频繁失效(“缓存颠簸”),大幅降低性能。
Disruptor通过缓存行填充(Padding)解决伪共享:在Sequence等关键变量前后添加无意义的占位字段,确保每个Sequence独占一个缓存行。
示例(简化版Sequence):
class Sequence {// 缓存行填充(前)long p1, p2, p3, p4, p5, p6, p7;// 核心变量(volatile保证可见性)private volatile long value;// 缓存行填充(后)long p8, p9, p10, p11, p12, p13, p14, p15;
}
填充后,value所在的缓存行不会包含其他线程修改的变量,避免缓存颠簸。
4.3 固定大小与预分配:减少GC与内存开销
- 固定大小:
RingBuffer容量固定(2的幂),避免动态扩容的内存分配和数据迁移开销。 - 事件预分配:
RingBuffer初始化时通过EventFactory创建所有事件对象,后续仅修改内容,不新建对象,大幅减少GC压力。
4.4 批量处理:提高吞吐量
Disruptor支持批量获取/处理事件:
- 生产者可一次性申请多个序列号(如批量写入10个事件),减少CAS操作次数。
- 消费者可一次性处理连续的多个事件(通过序列号范围),减少循环和判断开销。
批量处理能有效利用CPU缓存(连续内存访问),提升吞吐量。
五、Disruptor的工作流程
以“单生产者-单消费者”为例,Disruptor的核心工作流程如下:
5.1 初始化阶段
- 定义事件类(如
TradeEvent),包含需要传递的数据(如交易金额、时间)。 - 实现
EventFactory,用于预分配TradeEvent对象。 - 实现
EventHandler,定义事件处理逻辑(如计算手续费)。 - 配置
Disruptor:指定容量、线程工厂、等待策略等。 - 启动
Disruptor,初始化RingBuffer。
5.2 事件发布阶段(生产者)
- 生产者通过
RingBuffer.next()获取下一个可写入的序列号(sequence)。 - 通过
RingBuffer.get(sequence)获取该序列号对应的事件对象。 - 修改事件对象的内容(如设置交易金额)。
- 调用
RingBuffer.publish(sequence)发布事件(更新生产者序列号,通知消费者)。
5.3 事件消费阶段(消费者)
- 消费者通过
WaitStrategy等待新事件(根据生产者序列号判断是否有新事件)。 - 当有新事件时,消费者获取待处理的序列号范围(如从
lastSequence+1到currentSequence)。 - 遍历序列号,通过
RingBuffer.get(sequence)获取事件,调用EventHandler.onEvent()处理。 - 处理完成后,更新消费者自身的
Sequence(标记已处理到的位置)。
六、多消费者模式:灵活的依赖关系
Disruptor支持复杂的消费者依赖关系,通过EventHandlerGroup可配置串行、并行或混合的消费模式,满足不同场景需求。
6.1 并行消费(多消费者独立处理)
多个消费者并行处理同一批事件(彼此无依赖),适用于“同一事件需要多维度处理”的场景(如日志同时写入磁盘和数据库)。
生产者 → RingBuffer↓ ↓消费者A 消费者B (并行处理)
6.2 串行消费(多消费者按顺序处理)
消费者按固定顺序处理事件(如消费者A处理完后,消费者B才能处理),适用于“事件处理有依赖”的场景(如先验证数据,再入库)。
生产者 → RingBuffer → 消费者A → 消费者B (串行处理)
6.3 混合消费(并行+串行)
更复杂的依赖关系,例如:
生产者 → RingBuffer↓ ↓消费者A 消费者B (并行)↘ ↙消费者C (依赖A和B处理完成)
七、Disruptor使用示例
下面通过一个简单示例演示Disruptor的使用流程:实现“生产者发布订单事件,消费者计算订单金额”。
首先引入Disruptor的依赖:
<!-- disruptor -->
<dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>3.3.4</version>
</dependency>
7.1 定义事件类
// 订单事件(存储订单ID和金额)
public class OrderEvent {private String orderId;private double amount;// getter和setterpublic String getOrderId() { return orderId; }public void setOrderId(String orderId) { this.orderId = orderId; }public double getAmount() { return amount; }public void setAmount(double amount) { this.amount = amount; }
}
7.2 实现事件工厂
import com.lmax.disruptor.EventFactory;// 用于预分配OrderEvent对象
public class OrderEventFactory implements EventFactory<OrderEvent> {@Overridepublic OrderEvent newInstance() {return new OrderEvent(); // 预创建事件对象}
}
7.3 实现事件处理器(消费者)
import com.lmax.disruptor.EventHandler;// 消费者:计算订单金额(这里简化为打印)
public class OrderEventHandler implements EventHandler<OrderEvent> {@Overridepublic void onEvent(OrderEvent event, long sequence, boolean endOfBatch) {System.out.println("处理订单:" + event.getOrderId() + ",金额:" + event.getAmount() + ",序列号:" + sequence);}
}
7.4 配置并启动Disruptor
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.YieldingWaitStrategy;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class DisruptorDemo {public static void main(String[] args) {// 1. 创建事件工厂OrderEventFactory factory = new OrderEventFactory();// 2. 配置RingBuffer容量(必须是2的幂)int bufferSize = 1024;// 3. 创建DisruptorExecutorService executor = Executors.newSingleThreadExecutor();Disruptor<OrderEvent> disruptor = new Disruptor<>(factory,bufferSize,executor,ProducerType.SINGLE, // 单生产者new YieldingWaitStrategy() // 等待策略:自旋+yield);// 4. 设置事件处理器(消费者)disruptor.handleEventsWith(new OrderEventHandler());// 5. 启动Disruptordisruptor.start();// 6. 获取RingBuffer,发布事件(生产者)RingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();for (int i = 0; i < 10; i++) {// 获取下一个序列号long sequence = ringBuffer.next();try {// 获取事件对象并设置数据OrderEvent event = ringBuffer.get(sequence);event.setOrderId("ORDER_" + i);event.setAmount(100.0 + i);} finally {// 发布事件ringBuffer.publish(sequence);}}// 7. 关闭资源disruptor.shutdown();executor.shutdown();}
}
7.5 运行结果

八、Disruptor的应用场景与局限性
8.1 典型应用场景
- 高频交易系统:处理大量订单,要求低延迟(微秒级响应)。
- 日志收集与分析:高吞吐量处理日志流,如ELK栈中的缓冲层。
- 数据采集与处理:物联网设备数据实时处理,传感器数据聚合等。
- 消息队列:作为高性能消息中间件的底层核心(如部分MQ的内部实现)。
8.2 局限性
- 内存占用:固定大小的
RingBuffer预分配大量对象,内存占用较高。 - 复杂度:相比传统队列,Disruptor的配置和使用更复杂,学习成本高。
- 不适合动态场景:容量固定,无法应对突发的超大规模数据(需提前预估容量)。
- 无持久化:默认仅在内存中传递数据,需额外实现持久化(如结合磁盘存储)。
九、总结
Disruptor是一款为高并发、低延迟场景设计的高性能框架,其核心优势源于:
- 无锁设计(CAS操作)避免了锁竞争的开销;
- 环形缓冲区和预分配机制减少了GC和内存开销;
- 缓存行填充消除了伪共享,提升CPU缓存利用率;
- 灵活的消费模式支持复杂的依赖关系。
尽管Disruptor存在内存占用高、复杂度高等局限性,但在对吞吐量和延迟要求极高的场景中,它仍是无可替代的选择。理解Disruptor的设计思想(如无锁并发、缓存优化),不仅能帮助我们更好地使用它,还能提升对Java并发编程底层细节的认知。
如果你正在开发高频交易、实时数据处理等系统,Disruptor绝对值得一试。