基于yolov8/yolo11的视觉识别算法使用和详解
背景:
最近有这样一个场景要求,需要一款可以进行工业场景的视觉识别模型算法,完成对应的检测分类判断功能。说一下我的场景:检测钢筋连接器外露螺纹数量的问题,用来判断是否合格(外露2个螺纹合格,≥3返工)
备注:提前说明,文中的信息皆为demo,不涉及任何业务或商业信息,博主只谈技术,坚决不触碰行业红线,有需要技术研究的,可以参考本文,一定会给你大大的惊喜。
一、方案确立:
经过网上走访调查,确定了几个方案:
1.利用多模态模型能力
2.利用小的视觉模型
方案对比:小模型 vs 大模型
| 方案类型 | 适用性 | 优势 | 劣势 | |
|---|---|---|---|---|
| 小模型(轻量级深度学习) | ✅ 高度契合(任务特定、数据可控) | 成本低(开源免费)、训练部署快、工业场景鲁棒性足够 | 泛化能力略弱于大模型(但数据充足时无差异) | |
| 大模型(多模态视觉大模型) | ❌ 不推荐(算力/成本高、冗余) | 零样本推理、强泛化 | 算力需求高(推理慢)、训练成本大、对简单任务过度kill |
结合客户情况和成本,最终结论是:小模型是首选方案,因为任务明确、数据可控(工业场景可批量采集)、成本敏感(要求“便宜”)
二、小模型实现全流程(基于YOLOv8)
YOLOv8是当前最轻量、易用的开源目标检测模型,支持目标检测+分类,且提供预训练权重,可快速迁移学习;YOLOv8 是一种高效的单阶段目标检测算法,其最新版本通过优化双向特征金字塔网络(BiFPN)和查询驱动模型结构,显著提升了小目标检测的准确性和速度。以下是基于该算法的几个典型应用场景及技术特点:
自动驾驶场景
YOLOv8-QSD 算法针对自动驾驶需求优化了多样化分支块(DBB)模型,通过双向特征融合和查询机制改进长距离检测性能。在SODA-A 数据集测试中,其准确率达 64.5%,计算需求降低至 7.1 GFLOPs,适用于实时车载感知系统。
农业场景
基于 YOLOv8 的农作视觉 AI 可快速识别农民与农用车,支持图片、视频及实时摄像头输入,配套PyQt5 界面实现一键部署。该系统在农田监控、农机识别等场景中表现优异,检测结果以类别和置信度形式直观展示。
工业检测
针对食品包装热收缩膜检测需求,优化后的 YOLOv8 采用 1280×1280 高分辨率输入,新增微缺陷检测层(160×160 分辨率),并融合可见光与近红外成像数据,有效提升小缺陷检出率。
双目测距
结合双目摄像头系统,通过特征匹配和三角测量法实现深度信息提取。该方法可生成深度图,广泛应用于机器人导航、自动驾驶等领域。
1. 数据收集与标注(关键!)
一句话总结这个过程:
把你拍的钢筋连接器照片,用一个工具画个框框住它,并告诉电脑:“这个框里的是‘合格’还是‘不合格’”。
数据质量决定模型精度,需遵循“多样化、覆盖场景、足够数量”原则:
- 数据量:每类(合格/不合格)至少500-1000张图片(工业检测需大量样本覆盖边缘情况)。
- 场景覆盖:模拟实际施工环境,包含不同光照(明暗)、角度(正侧斜)、污渍(油污/锈迹)、背景(图纸/混凝土)等。
- 标注规范:
- 使用标注工具(如LabelImg、VGG Image Annotator)标记连接器区域(Bounding Box),并分类为:
合格:外露螺纹≤2个;不合格:外露螺纹≥3个。
- 示例标注:
- 使用标注工具(如LabelImg、VGG Image Annotator)标记连接器区域(Bounding Box),并分类为:
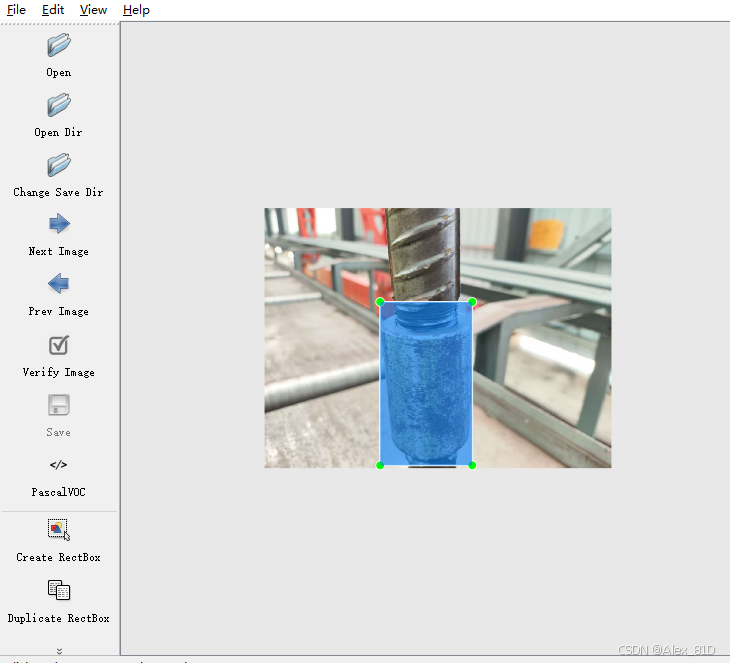
收集图片
拍多少张?
- 至少每类(合格、不合格)拍 300~500 张以上
- 尽量多样化:
- 不同光线(白天/阴天/灯光下)
- 不同角度(正面、斜着、俯视)
- 有灰尘、油污、锈迹等真实工地情况
- 背景复杂一点(比如旁边有模板、钢筋网)
建议:拿手机拍1000张左右,后期筛选出清晰有效的即可。
准备结构
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels_xml/ ← 存放 Labelimg 导出的 .xml 文件
└── labels_txt/ ← 转换后的 .txt 文件将放这里标注工具:labelimg
| 步骤 | 操作 |
|---|---|
| 1️⃣ | 打开一张图,看到连接器位置 |
| 2️⃣ | 按 W 键 → 鼠标拖动 → 把整个连接器外露部分框起来(尽量紧贴边缘) |
| 3️⃣ | 弹出对话框输入类别名: 输入 ok表示“合格” 输入 ng 表示“不合格” |
| 4️⃣ | 点击 Save → 自动生成一个 .xml 文件 |
自动生成 .txt 文件(自动转换)
convert_xml_to_yolo.py
import os
import xml.etree.ElementTree as ET# 类别映射(必须和你标注的名字一致)
class_names = ['ok', 'ng'] # 0: 合格, 1: 不合格def convert_annotation(xml_file, output_dir):tree = ET.parse(xml_file)root = tree.getroot()image_path = root.find('path').textif not image_path:image_path = root.find('filename').text# 获取图片宽高size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)# 输出文件名与图片同名,扩展名为.txttxt_name = os.path.splitext(os.path.basename(xml_file))[0] + '.txt'txt_path = os.path.join(output_dir, txt_name)with open(txt_path, 'w') as f:for obj in root.findall('object'):cls_name = obj.find('name').text.strip()if cls_name not in class_names:print(f"警告:未知类别 {cls_name},跳过")continuecls_id = class_names.index(cls_name)bbox = obj.find('bndbox')xmin = float(bbox.find('xmin').text)ymin = float(bbox.find('ymin').text)xmax = float(bbox.find('xmax').text)ymax = float(bbox.find('ymax').text)# 计算中心点和宽高(归一化)x_center = ((xmin + xmax) / 2) / wy_center = ((ymin + ymax) / 2) / hbox_width = (xmax - xmin) / wbox_height = (ymax - ymin) / h# 写入 .txtf.write(f"{cls_id} {x_center:.6f} {y_center:.6f} {box_width:.6f} {box_height:.6f}\n")# 主程序
xml_dir = 'labels_xml' # 放 .xml 的文件夹
output_dir = 'labels_txt/train' # 输出 .txt 的文件夹
os.makedirs(output_dir, exist_ok=True)for xml_file in os.listdir(xml_dir):if xml_file.endswith('.xml'):convert_annotation(os.path.join(xml_dir, xml_file), output_dir)print("✅ 所有标注已转换为 YOLO 格式!")直接拿去用,直接转换
运行后你会在 labels_txt/ 看到很多 .txt 文件,每个都对应一张图的标注。
内容是这种的:
<class_id> <x_center> <y_center> <width> <height>这五个数字的含义:
假设你的图片大小是 640×480 像素,你画了一个框:
- 左上角坐标:(100, 200)
- 右下角坐标:(200, 300)
那么这个框的信息是:
| 参数 | 计算方式 | 数值 |
|---|---|---|
| 中心点 x | (100 + 200)/2 = 150 | 150 |
| 中心点 y | (200 + 300)/2 = 250 | 250 |
| 宽度 w | 200 - 100 = 100 | 100 |
| 高度 h | 300 - 200 = 100 | 100 |
再做“归一化”(除以图片宽高):
| 参数 | 归一化公式 | 结果(保留4位小数) |
|---|---|---|
| x_center | 150 / 640 ≈ 0.2344 | 0.2344 |
| y_center | 250 / 480 ≈ 0.5208 | 0.5208 |
| width | 100 / 640 ≈ 0.1562 | 0.1562 |
| height | 100 / 480 ≈ 0.2083 | 0.2083 |
最后加上类别 ID:
- 假设
ok→ class_id = 0 - ng → class_id = 1
0 0.2344 0.5208 0.1562 0.2083具体labeling标注工具的使用详情和遇到的问题,可以参考博主的这篇文章
labelimg(目标检测标注工具)的安装、使用教程和问题解决
2. 环境搭建
# 安装Python(≥3.8)和依赖
pip install ultralytics opencv-python numpy或者
# 克隆YOLOv8仓库(包含预训练权重)
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics标注文件格式(如xxx.txt):
<class_id> <x_center> <y_center> <width> <height>class_id:0(合格)、1(不合格);- 坐标为归一化值(0-1之间)。
dataset/
├── images/
│ ├── train/ ← 这里放你拍的原始照片(比如 001.jpg, 002.jpg)
│ └── val/ ← 验证集原始照片
├── labels/
│ ├── train/ ← 这里放和图片同名的 .txt 标注文件(001.txt, 002.txt)
│ └── val/ ← 验证集对应的 .txt 文件
└── dataset.yaml ← 配置文件,告诉模型去哪找数据举个例子:
- 你有一张图叫
001.jpg,放在images/train/ - 它的标注结果是外露螺纹太多 → 不合格(class_id=1)
- 你用 LabelImg 标完后生成了
001.xml,再转成001.txt - 把
001.txt放在labels/train/下
这样,模型训练时就会:
- 读
001.jpg图片; - 自动去找同名的
001.txt标注; - 知道这个框对应的是“不合格”。
所以总结一句话:
图片是原图,标注是单独的 .txt 文件,两者靠“文件名相同”关联起来。
修改dataset.yaml
# 数据集路径(相对于训练脚本的位置)
path: ../dataset# 训练集和验证集图片路径(相对于 path)
train: images/train
val: images/val# 标注文件路径(可省略,默认在 labels/train 和 labels/val)
# 如果你把 .txt 放在 labels/train 下,则不用写# 类别数量
nc: 2# 类别名称(顺序必须和 class_names 一致)
names: ['ok', 'ng']3.模型训练
注意dataset.yaml的路径
# 训练脚本(train.py)
from ultralytics import YOLO# 初始化模型(使用小模型"yolov8n")
model = YOLO('yolo11n.pt')# 训练参数
results = model.train(data=r'dataset\dataset.yaml', # 数据集配置文件epochs=100, # 训练轮次(根据数据量调整)imgsz=640, # 输入图片尺寸(640×640足够)batch=16, # 批次大小(根据GPU内存调整)patience=20, # 早停轮次(防止过拟合)augment=True, # 开启数据增强degrees=5, # 旋转角度(±5度)hsv_h=0.05, # 色调扰动hsv_s=0.2, # 饱和度扰动hsv_v=0.2 # 明度扰动
)训练完后,模型保存在哪?
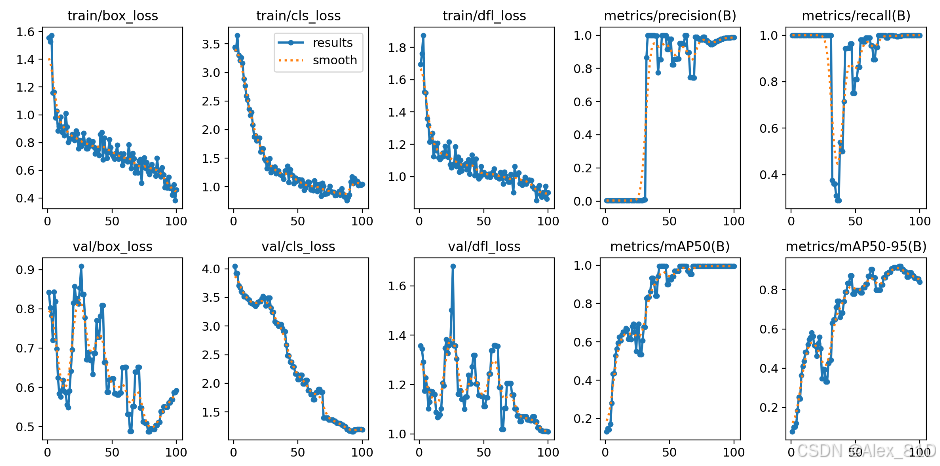
训练完后,Ultralytics 会自动创建一个保存目录,并把以下内容存进去:
- 训练日志(loss 曲线、mAP 等)
- 每轮的权重
.pt文件 - 最好的模型(best.pt)
- 最后一轮的模型(last.pt)
- 结果可视化图(如 confusion matrix)
📍 默认保存路径是:
runs/detect/train/ ← 所有训练结果都存在这里那你要找的“最好模型”是哪个?
在对应文件夹里找这个文件:
best.pt比如第一次训练完成后,你的模型就在:
runs/detect/train/weights/best.pt文件夹内容长这样:
runs/detect/train/
├── weights/
│ ├── best.pt ← ✅ 你最终要用的模型(性能最好的)
│ └── last.pt ← 最后一轮的模型(不一定最好)
├── results.png ← 训练曲线图(loss, mAP 等)
├── confusions_matrix.png
├── dataset.yaml -> 复制了一份你的配置
└── args.yaml ← 保存了你传入的所有参数
4.模型预测
# 推理脚本(infer.py)
from ultralytics import YOLO
import cv2# 加载模型
model = YOLO(r'\dataset\runs\detect\train15\weights\best.pt')# 读取图片
img = cv2.imread(r'\tu1\ng11.png')# 检测
# results = model(img, conf=0.5) # conf为置信度阈值(0.5表示≥50%置信度才输出)
# 检测,设置更高的 IOU 阈值以减少重叠的边界框
results = model(img, conf=0.5, iou=0.7)for r in results:im_array = r.plot() # 自动画框,绿色=合格,红色=不合格result_img = im_array[..., ::-1] # BGR → RGBcv2.imshow('Result', result_img)cv2.waitKey(0)# 解析结果# 初始化变量存储最高置信度的边界框信息
max_conf = 0
best_box = None
best_cls_id = Nonefor result in results:boxes = result.boxesfor box in boxes:cls_id = int(box.cls[0]) # 类别ID(0合格,1不合格)conf = float(box.conf[0]) # 置信度x1, y1, x2, y2 = box.xyxy[0] # 边界框坐标print(f'Class: {cls_id}, Conf: {conf:.2f}, x1: {x1}, y1: {y1}, x2: {x2}, y2: {y2}')if conf > max_conf:max_conf = confbest_box = boxbest_cls_id = cls_idif best_box is not None:x1, y1, x2, y2 = best_box.xyxy[0] # 边界框坐标print('-----------------------------------最终----------------------------------------------------------------------')print(f'Class: {best_cls_id}, Conf: {max_conf:.2f}, x1: {x1}, y1: {y1}, x2: {x2}, y2: {y2}')print('---------------------------------------------------------------------------------------------------------')print(f"类别结果为: {best_cls_id}")
else:print("No detections above the confidence threshold.")https://github.com/ultralytics/assets/releases
5.封装接口
文件结构:
your_project/
├── app.py # Flask 主程序
├── templates/
│ └── index.html # 前端页面
├── uploads/ # 自动创建,存放上传的图片
└── runs/detect/train/weights/best.pt # 你的训练模型(需替换路径)
from flask import Flask, request, jsonify, render_template, send_from_directory
from ultralytics import YOLO
import cv2
import os
import jsonapp = Flask(__name__)# 加载模型,注意选择自己的路径
model = YOLO(r'dataset\runs\detect\train15\weights\best.pt')# 设置上传目录
UPLOAD_FOLDER = 'uploads'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER# 设置静态文件路由:允许访问 /uploads/ 下的文件
@app.route('/uploads/<filename>')
def uploaded_file(filename):return send_from_directory(app.config['UPLOAD_FOLDER'], filename)@app.route('/')
def index():return render_template('index.html')@app.route('/upload', methods=['POST'])
def upload_file():if 'file' not in request.files:return jsonify({"error": "No file part"}), 400file = request.files['file']if file.filename == '':return jsonify({"error": "No selected file"}), 400if file:filename = file.filenamefilepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)file.save(filepath)# 返回可访问的 URLreturn jsonify({"image_url": f"/uploads/{filename}"}), 200@app.route('/predict', methods=['POST'])
def predict():data = request.get_json()image_path = data.get('image_path')if not image_path or not os.path.exists(image_path):return jsonify({"error": "Image not found"}), 400img = cv2.imread(image_path)# 检测,设置更高的 IOU 阈值以减少重叠的边界框results = model(img, conf=0.5, iou=0.7)# 处理结果...response = []# 初始化变量存储最高置信度的边界框信息max_conf = 0best_box = Nonebest_cls_id = Nonefor result in results:boxes = result.boxesfor box in boxes:cls_id = int(box.cls[0]) # 类别ID(0合格,1不合格)conf = float(box.conf[0]) # 置信度x1, y1, x2, y2 = box.xyxy[0] # 边界框坐标print(f'Class: {cls_id}, Conf: {conf:.2f}, x1: {x1}, y1: {y1}, x2: {x2}, y2: {y2}')if conf > max_conf:max_conf = confbest_box = boxbest_cls_id = cls_idif best_box is not None:x1, y1, x2, y2 = best_box.xyxy[0] # 边界框坐标max_conf = round(max_conf, 2)print('-----------------------------------最终----------------------------------------------------------------------')print(f'Class: {best_cls_id}, Conf: {max_conf:.2f}, x1: {x1}, y1: {y1}, x2: {x2}, y2: {y2}')print('---------------------------------------------------------------------------------------------------------')print(f"类别结果为: {best_cls_id}")response.append({"class": cls_id,"confidence": max_conf,"box": [x1, y1, x2, y2]})# 如果cls_id为0,则输出为合格,否则为不合格result = ""if cls_id == 0:print("合格")result = "合格"else:print("不合格")result = "不合格"return jsonify({"识别结果": result,"置信度": max_conf}), 200else:print("No detections above the confidence threshold.")return jsonify({"No detections above the confidence threshold."}), 400if __name__ == '__main__':app.run(port=8888, host='0.0.0.0')index.html
<!-- templates/index.html -->
<!DOCTYPE html>
<html lang="zh">
<head><meta charset="UTF-8"><title>钢筋质检 - 图片上传与预测</title><meta name="viewport" content="width=device-width, initial-scale=1.0"><style>body {font-family: Arial, sans-serif;margin: 40px;background: #f5f5f5;}.container {max-width: 800px;margin: 0 auto;background: white;padding: 30px;border-radius: 10px;box-shadow: 0 2px 10px rgba(0,0,0,0.1);}h1, h3 {color: #333;}.upload-section, .preview-section, .result-section {margin: 25px 0;}#preview-img {max-width: 100%;height: auto;border: 1px solid #ddd;border-radius: 8px;margin-top: 10px;display: none;}textarea {width: 100%;height: 200px;font-family: monospace;padding: 12px;border: 1px solid #ccc;border-radius: 6px;box-sizing: border-box;resize: vertical;}button {padding: 10px 18px;font-size: 16px;background: #007bff;color: white;border: none;border-radius: 6px;cursor: pointer;margin-right: 10px;}button:hover {background: #0056b3;}button:disabled {background: #ccc;cursor: not-allowed;}</style>
</head>
<body><div class="container"><h1>📷 钢筋连接器质检系统</h1><!-- 上传区域 --><div class="upload-section"><h3>1. 上传图片</h3><input type="file" id="image-upload" accept="image/*"><button onclick="uploadImage()">📤 上传图片</button></div><!-- 预览区域 --><div class="preview-section"><h3>2. 当前图片</h3><img id="preview-img" alt="上传的图片将显示在这里"></div><!-- 预测按钮 --><div class="predict-section"><button onclick="predict()" disabled id="predict-btn">🔍 开始预测</button></div><!-- 结果区域 --><div class="result-section"><h3>3. 预测结果(JSON格式)</h3><textarea id="result-textarea" placeholder="预测结果将显示在这里..."></textarea></div></div><script>
let currentImagePath = null;// 上传图片
function uploadImage() {const input = document.getElementById('image-upload');const file = input.files[0];if (!file) {alert("请先选择一张图片!");return;}const formData = new FormData();formData.append('file', file);fetch('/upload', {method: 'POST',body: formData}).then(response => response.json()).then(data => {if (data.image_url) {document.getElementById('preview-img').src = data.image_url;document.getElementById('preview-img').style.display = 'block';document.getElementById('predict-btn').disabled = false;currentImagePath = data.image_url; // 保存路径用于预测} else {alert("上传失败:" + data.error);}}).catch(err => {console.error("上传失败:", err);alert("上传失败,请检查网络或后端服务");});
}// 发起预测
function predict() {if (!currentImagePath) return;fetch('/predict', {method: 'POST',headers: { 'Content-Type': 'application/json' },body: JSON.stringify({ image_path: '.' + currentImagePath })}).then(response => response.json()).then(result => {if (result.error) {document.getElementById('result-textarea').value = "预测错误:" + result.error;} else {document.getElementById('result-textarea').value = JSON.stringify(result, null, 2);}}).catch(err => {document.getElementById('result-textarea').value = "预测出错:" + err.message;});
}
</script></body>
</html>来,看成品:
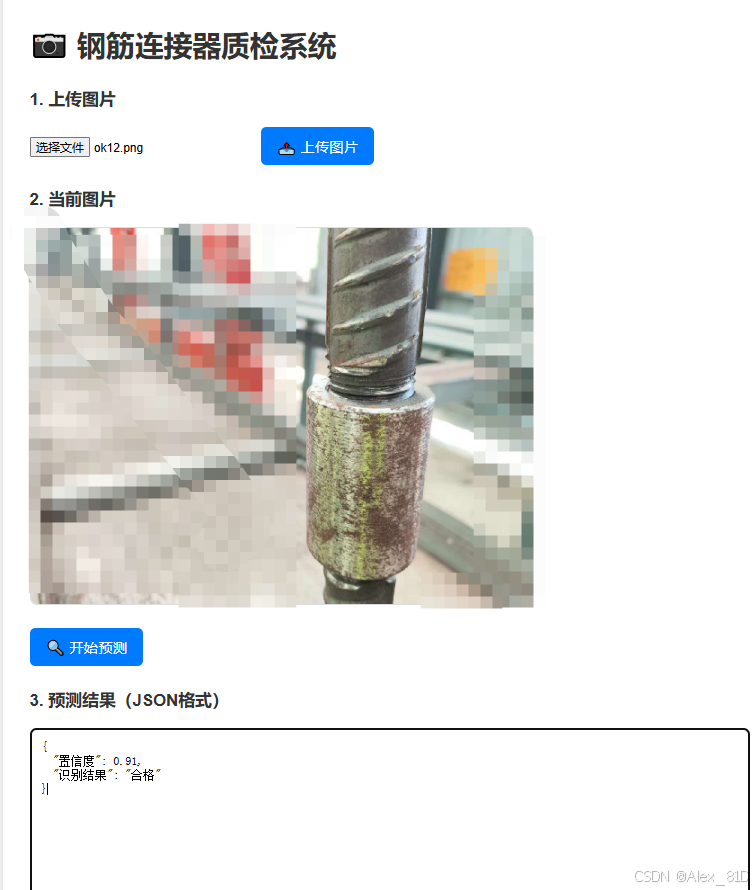
三、技术延展
1.model = YOLO('yolov8n.pt') 这个里面到底填什么
1.1 这句代码是 加载一个 YOLO 模型
括号里的 'xxx.pt' 就是:
模型文件的路径或名称
它决定了你是:
- 用别人训练好的预训练模型(比如检测通用物体)
- 还是你自己训练出来的钢筋连接器质检模型
1.2 常见的几种写法和含义
| 写法 | 含义 | 是否推荐 |
|---|---|---|
YOLO('yolov8n.pt') | 使用 Ultralytics 官方提供的 预训练小模型(nano版) | ✅ 推荐(用于训练起点) |
YOLO('yolov8s.pt') | 更大一点的预训练模型(small) | 可选 |
YOLO('yolov8n.yaml') | 不加载权重,只用“随机初始化”的网络结构 | ❌ 初学者不推荐 |
YOLO('runs/detect/train/weights/best.pt') | 加载你自己训练好的模型(用于推理) | ✅ 推荐(训练完后用这个) |
1.3你应该怎么选?分两个阶段说
阶段1:我要开始训练模型
你想让电脑学会识别“钢筋连接器是否合格”,但模型一开始啥也不懂。所以你要:
拿一个已经会“看图识别东西”的现成模型,再教它学会你的任务
这就叫 迁移学习(Transfer Learning)
正确写法:
model = YOLO('yolov8n.pt')解释:
yolov8n.pt是 Ultralytics 官方在 COCO 数据集上训练好的 小模型权重文件- 它已经学会了识别很多物体(人、车、猫狗等),具备基本的“视觉理解能力”
- 我们拿它做“起点”,然后用我们的钢筋图片微调(fine-tune),让它学会区分“合格/不合格”
📌 好处:训练快、效果好、不需要大量数据
注意:你不需要手动下载 yolov8n.pt!
当你第一次运行这行代码时,
Python 会自动联网下载这个文件,并保存到你的本地缓存目录,你什么都不用做,只要确保网络通畅就行。
阶段2:我已经训练完了,现在要检测新图
训练完成后,你会得到自己的模型文件,比如:
这时候你要用:
runs/detect/train/weights/best.pt
model = YOLO('runs/detect/train/weights/best.pt')这才是你的“钢筋质检专用模型”!
| 想用更大的模型 | 想要更高精度 | 改成 'yolov8s.pt' 或 'yolov8m.pt' |
总结:
- 训练时:
YOLO('yolov8n.pt')→ 用官方预训练模型当老师 - 检测时:
YOLO('best.pt')→ 用你自己训练出的模型去干活
1.4 那么用.yaml 还是 .pt?
| 使用场景 | 推荐写法 | 原因 |
|---|---|---|
| 我要开始训练自己的模型 | YOLO('yolov8n.pt') | 利用预训练知识,快速收敛,效果更好 |
| 我想从零开始训练(不推荐) | YOLO('yolov8n.yaml') | 随机初始化,训练慢,需要海量数据 |
| 我想加载自己训练好的模型做检测 | YOLO('best.pt') | 用你最终得到的模型去干活 |
举个生活化的比喻
| 文件类型 | 类比 |
|---|---|
yolov8n.yaml | 医学院的课程大纲(解剖学、内科、外科…)—— 理论框架 |
yolov8n.pt | 一位毕业+实习3年的医生 —— 不仅学过理论,还有临床经验 |
best.pt(你训练的) | 一位专门看钢筋病的专家医生 —— 经验更专精 |
方法1:从零开始(不推荐)
model = YOLO('yolov8n.yaml') # 随机权重,啥也不会
model.train(data='dataset.yaml', epochs=100)- 训练极慢
- 效果差
- 需要几千张图才能勉强学会
方法2:迁移学习(强烈推荐)
model = YOLO('yolov8n.pt') # 已经会“看图”的模型
model.train(data='dataset.yaml', epochs=50) # 微调即可- 训练快
- 效果好
- 几百张图就能达到高精度
yolov8n.yaml→ 只有“模型结构”,适合研究或从头训练(难且慢)yolov8n.pt→ 有“结构 + 预训练权重”,适合绝大多数项目(快且准)你几乎永远都应该用
yolov8n.pt来启动训练!
除非你在做科研,想验证某种新结构,否则不要碰 .yaml 初始化方式。
就这么多吧,后面想起来了再接着补吧!