day3 MySOL多表操作
一、表数据查询
1.分组
group by语句
group by 语句是SQL查询中用户汇总和分析数据的重要工具,尤其在处理大量数据的时候,非常有用。
以下表为基础进行示范:
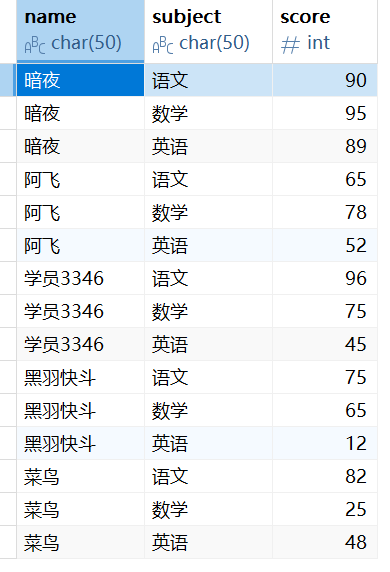
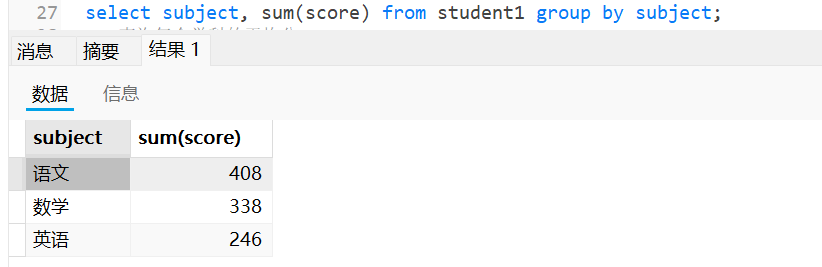
-- 查询每个学科的总分
select subject, sum(score) from student1 group by subject;
-- 查询每个学科的平均分
select subject, avg(score) from student1 group by subject;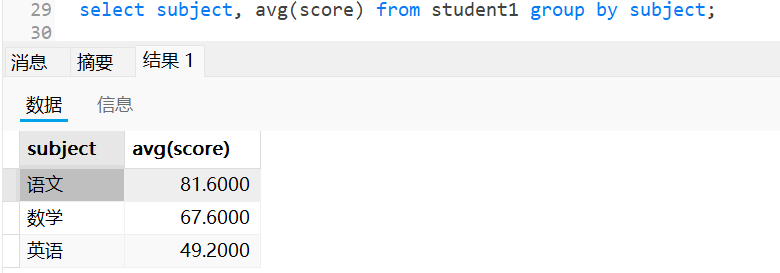
-- 查询每个学生之间的总分
select name, sum(score) from student1 group by name;
-- 请自行尝试^-^2.取别名
在对表数据的操作中,有些表或者字段的名字因为太过于繁杂导致操作时十分困难,这时我们可以采用as关键字对字段或者表取别名,从而方便对表数据的后续操作。
注:as是可以隐藏的。
3.聚合查询
第一点提到的分组示例中分别对学生的每科分数、平均分以及总分,为了更加细致的进行查询,比如只查找总分大于某一值的学生数据,数据库使用了having关键字,having关键字可以在原有查询到数据的基础上进行一定程度的筛选,从而达到最终查询目的,其可以对分组之后的数据进行过滤。
注:having的用法与where用法有一定的相似之处,但不同的是,where只能操作表中的字段,而having可以和聚合函数一起使用。换句话说,having必须和group by一起使用。
-- 查询每个学生的总分,并且总分大于200
select name, sum(score)sum_score from student1 group by name having sum_score > 200;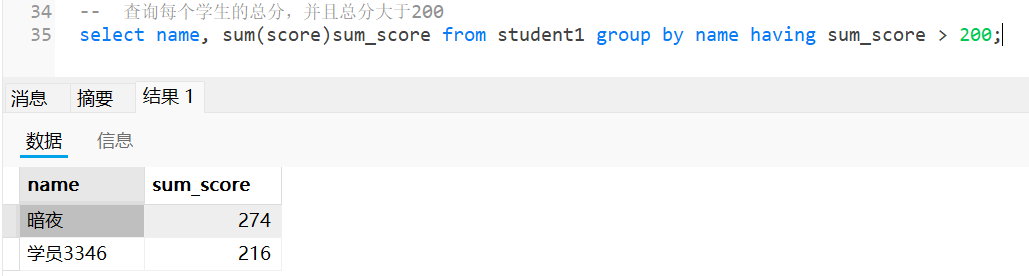
4.子查询
当我们需要查询的数据要满足多个条件时,就可以通过子查询的方式对数据进行索取。一般的子查询有一下两种:
1.在select子句中,嵌套另一个select子句:
select * from (select * from 表名 where 条件) as 别名 where 条件;
2. 在where子句中,嵌套一个select子句:
select * from 表名 where 条件((select 字段 from 表名 where 条件) );
我们以下面的数据来讲解:
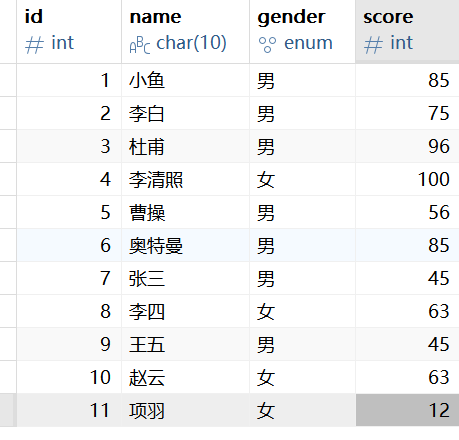
1. 查询所有男生分数大于90分的数据:
上述问题中我们需要查询的内容要满足“男生”,“大于90分”这两个条件,因此我们可以使用select嵌套select来查询,外面的select用来查询分数大于90的人,而内部的select用来筛选男生。
select * from (select * from test where gender ='男') as t where t.score > 90;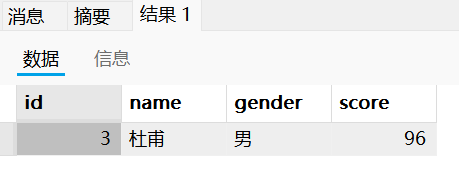
2.查询比李白分数还高的数据:
这道题我们需要先使用select对李白的分数进行查询,然后使用where子句对查询到的李白的分数进行判断,从而找到高于李白分数的数据。
select * from test where score>(select score from test where name='李白');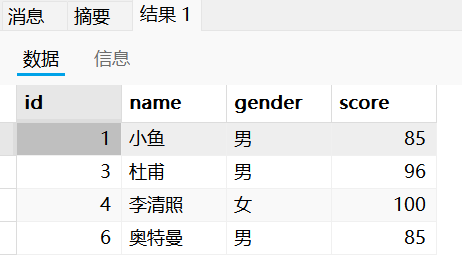
3. 查询成绩最高的信息:
这个问题我们需要先查询“最高成绩”这一数据,之后将“最高成绩”这一数据作为条件进行对应的信息查询。
select * from test where score=(select max(score) from test);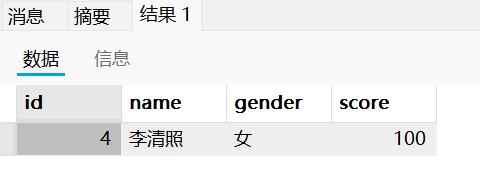
二、表与表之间的关系
1.多表之间的关系
一对一:相当于一个学生对应一张学生证,具有唯一性。
一对多:比如一个部门有多个员工,一个学校有多个年级,一个年级有多个班级。
多对多:这种表之间的关系相当于一个学生对应多个课程,一个课程有多个学生。
2.外键约束
外键:用于建立两个表之间的联系,使用外键表示一个表中的字段被另一个字段引用(一个表中的字段书对应另一个表中数据)。
使用外键约束时将涉及到的两个表分为主表和从表,主表就是没有外键字段的表,从表就是有外键字段的表。
注:
1.在创建表时,需要先创建主表,在创建从表。
2.在添加数据时,需要先添加主表的数据。
3. 从表中外键字段的值只能是主表中已经存在的值。
4. 当我们需要修改和删除主表的时候,如果出现阻碍,要优先删除修改从表的值。
下面我将通过表与表之间的关系进行讲解
用法
foreign key (外键字段名) references 主表名(字段)1.一对一
先展示代码:
-- 一个用户对应一个用户详情
-- 创建用户表
create table users(id int PRIMARY key auto_increment,name char(5)
);-- 创建用户详情表
create table user_info(id int PRIMARY key auto_increment,age int,id_card char(18),-- 创建一个字段当做外键-- 设置唯一约束,让表与表之间成为一个一对一的关系user_info_id int UNIQUE,foreign key (user_info_id) references users(id)
);insert into users(name) values
('张三丰'),
('金克斯'),
('张无忌'),
('刘大姐'),
('老王'),
('法外狂徒');insert into user_info(age, id_card, user_info_id) VALUES
(20, '77777', 1),
(52, '555555', 2),
(45, '1234567844486', 3),
(35, '6587657467', 4),
(12, '44444', 5),
(99, '465465768', 6);在上述代码中创建了两个表users(主表)和user_info(从表),同时设置了user_info_id作为唯一约束,之后代码首先在主表添加人名,之后在从表中添加对应的信息,最终在主表中点击人名就可以直接显示该人名对应的所有信息。
2.一对多
示例代码:
-- 一个部门对应多个员工
-- 部门表
create table dept(id int primary key auto_increment,dept_name char(5),job char(10) COMMENT '部门职责'
);-- 员工表
create table staff(id int primary key auto_increment,staff_name char(5),dept_staff_id int,foreign key (dept_staff_id) references dept(id)
);
insert into dept(dept_name, job) VALUES
('财务部', '管钱'),
('人事部', '考勤'),
('后勤部', '采购');insert into staff(staff_name, dept_staff_id)VALUES
('石头', 1),
('小白', 1),
('菜鸟', 2),
('阿飞', 3);3.多对多
示例代码:
-- 一个作者可以有多本书
-- 一本书可以由多个作者编写
-- 图书表
create table book(id int primary key auto_increment,book_name char(15)
);-- 作者表
create table people(id int primary key auto_increment,people_name char(10),age int
);
insert into book(book_name) VALUES
('红楼梦'),
('西游记'),
('三国演义'),
('水浒传'),
('斗破苍穹'),
('武动乾坤'),
('python');insert into people(people_name, age) VALUES
('曹雪芹', 18),
('罗贯中', 45),
('施耐庵', 23),
('吴承恩', 45),
('天蚕土豆', 32),
('石头', 20);-- 需要建立一个第三方表来表示两张表之间的对应关系
create table book_people(id int primary key auto_increment,-- 设置图书表的外键book_id int,foreign key (book_id) references book(id),-- 设置作者表的外键people_id int,foreign key (people_id) references people(id)
);
insert into book_people(book_id, people_id) VALUES
(1, 1),
(2, 2),
(3, 3),
(4, 4),
(5, 5),
(6, 5),
(7, 6),
(7, 5);以上便是关于表数据的操作与表与表之间的相关操作。