(论文速读)CLR-GAN: 通过一致的潜在表征和重建提高gan的稳定性和质量
论文题目:CLR-GAN: Improving GANs Stability and Quality via Consistent Latent Representation and Reconstruction(通过一致的潜在表征和重建提高gan的稳定性和质量)
会议:ECCV2024
摘要:摘要。生成对抗网络(GANs)因其出色的图像生成能力而受到广泛关注。然而,训练GAN是困难的,因为生成器(G)和鉴别器(D)之间的博弈是不公平的。为了使竞争更加公平,我们提出了一种新的训练gan的视角,称为一致潜在表示和重建(CLR-GAN)。在此范例中,我们将G和D视为一个逆过程,鉴别器有一个额外的任务来恢复预定义的潜在代码,而生成器也需要重建真实输入,从而获得G的潜在空间与D的out-features之间的关系。我们可以用一个新的标准在训练中把D和G放在一个相等的位置。在各种数据集和架构上的实验结果证明,我们的范式可以使gan更稳定,生成更好的图像质量(CIFAR10上的FID增益31.22%,AFHQ-Cat上的FID增益39.5%)。我们希望提出的观点可以激励研究人员探索观察gan训练的不同方式,而不是局限于双人游戏。
源码链接:https://github.com/Petecheco/CLR-GAN
训练自己的数据集指南可见如下链接:
https://blog.csdn.net/LJ1147517021/article/details/151794203?fromshare=blogdetail&sharetype=blogdetail&sharerId=151794203&sharerefer=PC&sharesource=LJ1147517021&sharefrom=from_link![]() https://blog.csdn.net/LJ1147517021/article/details/151794203?fromshare=blogdetail&sharetype=blogdetail&sharerId=151794203&sharerefer=PC&sharesource=LJ1147517021&sharefrom=from_link
https://blog.csdn.net/LJ1147517021/article/details/151794203?fromshare=blogdetail&sharetype=blogdetail&sharerId=151794203&sharerefer=PC&sharesource=LJ1147517021&sharefrom=from_link
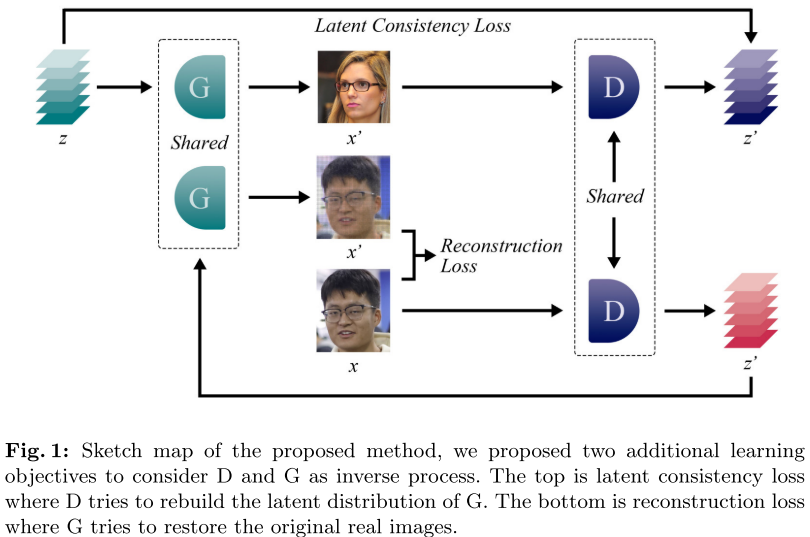
CLR-GAN:通过一致性潜在表示让GAN训练更公平
生成对抗网络(GANs)自2014年问世以来,在图像生成领域取得了令人瞩目的成就。然而,GAN的训练一直存在着不稳定和困难的问题。最近,一篇名为"CLR-GAN: Improving GANs Stability and Quality via Consistent Latent Representation and Reconstruction"的论文提出了一种新颖的解决方案,通过重新思考生成器和判别器之间的关系,显著提升了GAN的训练稳定性和生成质量。
传统GAN训练的核心问题
不公平的"两人游戏"
在传统的GAN框架中,生成器G和判别器D被视为两个对抗的玩家:
- 生成器:努力生成逼真的假图像来"欺骗"判别器
- 判别器:努力区分真实图像和生成的假图像
这个设定看似公平,但实际上存在严重的不平衡:
-
梯度来源单一:在标准的GAN目标函数中,所有的优化梯度都来自判别器,这使得判别器天然处于主导地位
-
信息不对称:判别器可以直接访问真实数据分布,而生成器只能通过判别器的反馈间接学习
-
早期主导效应:判别器通常在训练早期就能轻松识别出假图像,并在整个训练过程中保持这种优势
现有解决方案的局限性
虽然研究者们提出了许多改进方法,如新的损失函数、网络架构调整、数据增强等,但这些方法都没有从根本上改变生成器和判别器之间的核心关系,也没有充分利用潜在空间的结构信息。
CLR-GAN:一个全新的视角
核心思想:互逆过程
CLR-GAN的创新之处在于重新定义了生成器和判别器的角色,将它们视为互逆的过程:
- 生成器:将潜在表示映射到真实数据分布
- 判别器:不仅输出真实度评分,还将高维数据转换回潜在表示空间
这种新视角为两个网络建立了对称的约束关系,使得竞争更加公平。
两大技术创新
1. 一致性潜在表示(Consistent Latent Representation)
工作原理:
- 判别器在输出真实度评分的同时,还需要重构出一个潜在代码
- 通过计算原始潜在代码z和重构潜在代码φ(x)之间的距离,构建一致性损失
- 数学表达:
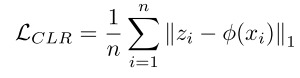
作用机制:
- 强制判别器的潜在空间与生成器的潜在空间保持一致
- 为判别器提供了额外的约束,防止其过度主导训练过程
2. 真实图像重构(Real Image Reconstruction)
工作原理:
- 利用判别器重构的潜在代码,让生成器尝试重建原始真实图像
- 重构过程:$I_{rec} = G(\phi(x))$
- 重构损失:$\mathcal{L}{rec} = \frac{1}{n} \sum{i=1}^{n} |I(x) - I_{rec}|_1$
关键优势:
- 使生成器能够直接从真实数据分布获得梯度信息
- 提供了额外的训练目标,增强了生成器的学习能力
从正则化角度的理论分析
论文还从正则化的角度分析了方法的有效性:
训练判别器时:当判别器过强时,一致性损失的负梯度可以减小判别器的梯度幅度,起到稳定训练的作用。
训练生成器时:当判别器主导游戏时,重构损失为生成器提供了额外的优化目标,防止生成器崩溃。
实验验证与结果分析
数据集和评估指标
研究者在多个数据集上进行了全面的实验验证:
- 低分辨率:CIFAR-10、CelebA (64×64)
- 高分辨率:AFHQ-Cat、LSUN Church、FFHQ
- 评估指标:FID (Fréchet Inception Distance)、Precision & Recall
显著的性能提升
实验结果令人印象深刻:
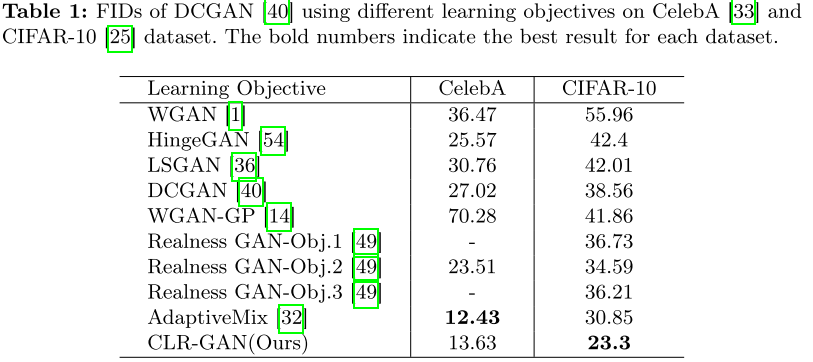
低分辨率图像生成:
- CIFAR-10:FID从38.56降至23.3(31.22%提升)
- CelebA:达到13.63的竞争性结果
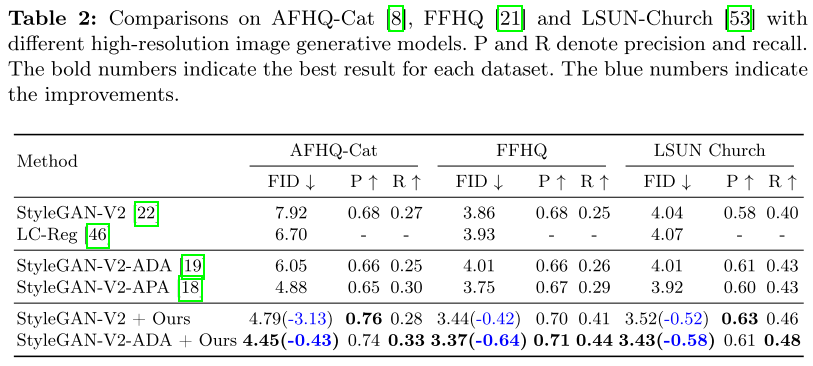
高分辨率图像生成:
- AFHQ-Cat:FID从7.92降至4.79(39.5%提升)
- FFHQ:FID从3.86降至3.44
- LSUN Church:FID从4.04降至3.52
架构兼容性
CLR-GAN的另一个优势是其即插即用的特性:
- 可以与DCGAN、StyleGAN-V2等多种架构结合
- 与StyleGAN-V2-ADA等现有改进方法兼容,实现进一步提升
消融实验的洞察
通过详细的消融实验,研究者发现:
- 两个损失项(一致性损失和重构损失)缺一不可
- 最优的权重配置为λ₁ = 5, λ₂ = 0.5
- 比值η = λ₁/λ₂的选择对训练动态有重要影响
训练公平性的量化验证
论文通过可视化真实图像和生成图像的"真实度评分",直观地展示了CLR-GAN如何实现更公平的训练:
- 传统方法中,真实图像和生成图像的评分差距很大
- CLR-GAN显著缩小了这个差距,表明竞争更加公平
意义与启示
理论贡献
- 新的训练范式:提出了将G和D视为互逆过程的新视角
- 公平性量化:提供了衡量GAN训练公平性的方法
- 正则化解释:从理论角度解释了方法的有效性
实用价值
- 即插即用:可以轻松集成到现有的GAN架构中
- 显著提升:在多个数据集和架构上都取得了明显改进
- 附加价值:训练出的判别器可以作为优秀的无监督特征提取器
对未来研究的启发
这项工作的最大价值在于提供了一个全新的思考GAN训练的角度。它启发研究者们:
- 重新审视生成器和判别器之间的关系
- 探索更多利用潜在空间结构信息的方法
- 寻找实现公平训练的新途径
潜在局限与未来方向
虽然CLR-GAN取得了显著成果,但仍有一些值得进一步探索的方向:
- 计算开销:额外的重构任务增加了计算成本
- 超参数敏感性:需要仔细调节λ₁和λ₂的值
- 理论分析:可以进一步深化对方法有效性的理论理解
结论
CLR-GAN通过重新定义生成器和判别器的关系,提出了一种简单而有效的改进GAN训练的方法。其核心创新在于将两者视为互逆过程,并通过一致性潜在表示和真实图像重构两个约束项实现更公平的训练。
这项工作不仅在实验上取得了显著的性能提升,更重要的是为GAN研究提供了新的思路和方向。它提醒我们,有时候解决复杂问题的关键不在于增加更多的技术细节,而在于从一个全新的角度重新审视问题的本质。
对于GAN研究领域而言,CLR-GAN开启了一扇新的大门,相信会激发更多关于如何实现公平、稳定训练的创新研究。