基于红尾鹰优化的LSTM深度学习网络模型(RTH-LSTM)的一维时间序列预测算法matlab仿真
目录
1.程序功能描述
2.测试软件版本以及运行结果展示
3.部分程序
4.算法理论概述
5.完整程序
1.程序功能描述
红尾鹰优化的LSTM(RTH-LSTM)算法,是将红尾鹰优化算法(Red-Tailed Hawk Optimization, RTHO)与长短期记忆网络(Long Short-Term Memory, LSTM)结合,针对一维时间序列预测任务提出的混合模型。其核心逻辑在于:利用RTHO算法的全局寻优能力,解决LSTM网络训练中易陷入局部最优、初始权重与偏置参数随机化导致预测精度低的问题,再通过LSTM捕捉时间序列的长短期依赖关系,最终实现高精度预测。
2.测试软件版本以及运行结果展示
MATLAB2022A/MATLAB2024B版本运行
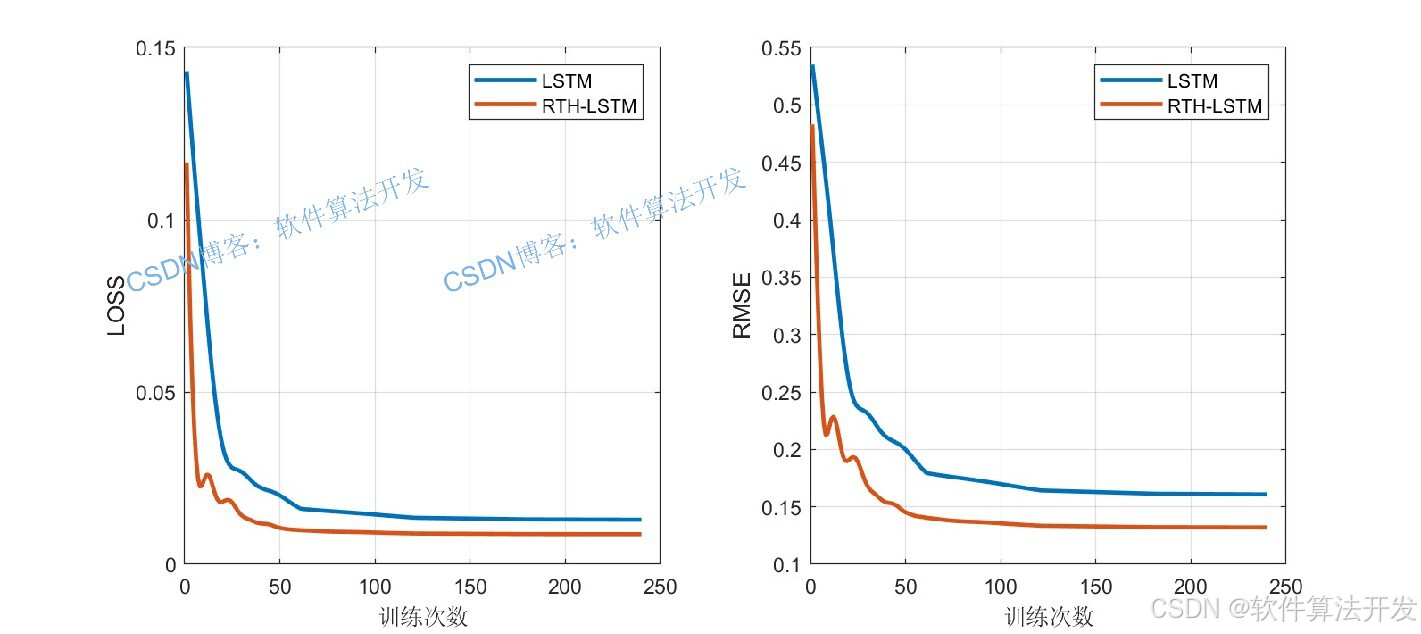
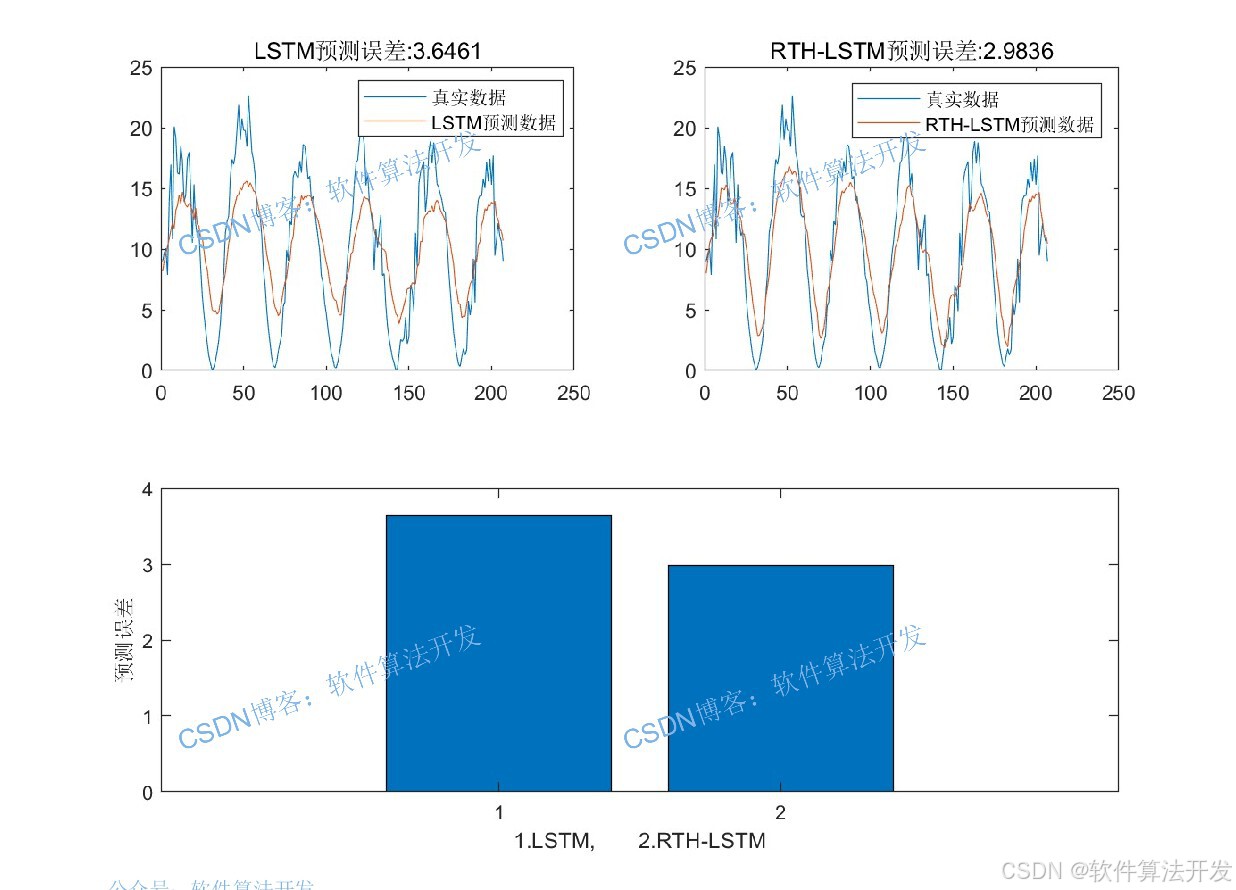
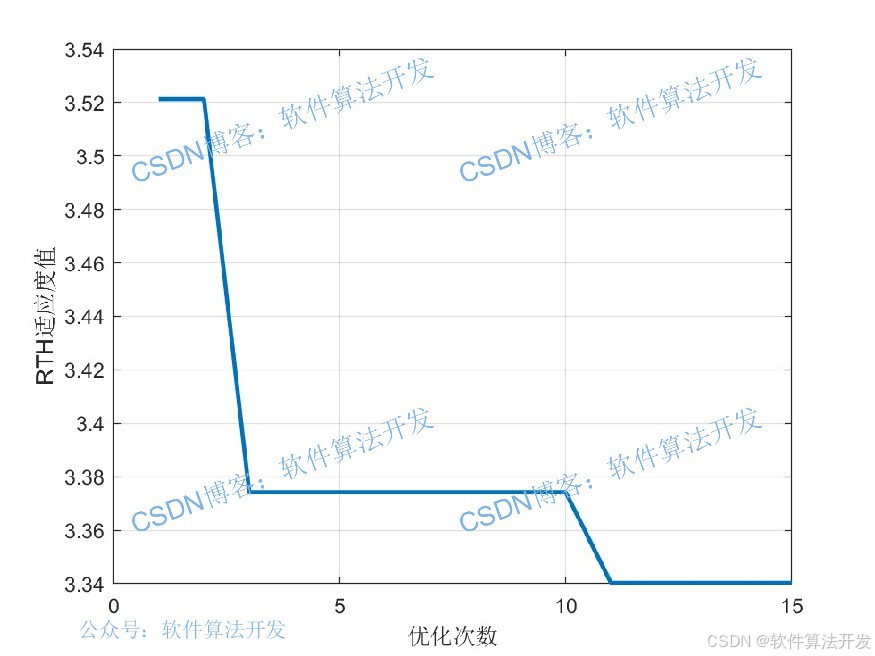
3.部分程序
% 定义全局变量,用于存储训练和测试数据及相关参数
global T_train; % 训练目标数据
global T_test; % 测试目标数据
global Pxtrain; % 训练输入数据
global Txtrain; % 训练目标数据(归一化后)
global Pxtest; % 测试输入数据
global Txtest; % 测试目标数据(归一化后)
global Norm_I; % 输入数据归一化参数
global Norm_O; % 输出数据归一化参数
global indim; % 输入数据维度
global outdim; % 输出数据维度% 加载数据文件data.mat
load data.mat
% 调用数据处理函数,对原始数据进行预处理
[T_train,T_test,Pxtrain,Txtrain,Pxtest,Txtest,Norm_I,Norm_O,indim,outdim]=func_process(dat);% 定义优化参数范围
low = 5; % 搜索空间下界
high = 100; % 搜索空间上界
dim = 1; % 优化维度
Tmax = 15; % 最大迭代次数
Npop = 10; % 种群大小% 初始化最优解
Xbestcost = inf; % 初始化最优代价为无穷大
Xbestpos = rand(Npop,dim); % 初始化最优位置% 将优化得到的最佳参数转换为整数,作为LSTM隐藏层神经元数量
NN=floor(Xnewpos)+1;
% 定义LSTM神经网络结构
layers = [ ...]; % 回归层,用于回归任务% 训练LSTM网络
[net,INFO] = trainNetwork(Pxtrain, Txtrain, layers, options);% 使用训练好的网络进行预测
Dat_yc1 = predict(net, Pxtrain); % 对训练数据进行预测
Dat_yc2 = predict(net, Pxtest); % 对测试数据进行预测% 将预测结果反归一化,恢复原始数据范围
Datn_yc1 = mapminmax('reverse', Dat_yc1, Norm_O);
Datn_yc2 = mapminmax('reverse', Dat_yc2, Norm_O); % 将细胞数组转换为矩阵
Datn_yc1 = cell2mat(Datn_yc1);
Datn_yc2 = cell2mat(Datn_yc2);% 保存训练信息、预测结果和收敛曲线
save R2.mat INFO Datn_yc1 Datn_yc2 T_train T_test Convergence_curve
X14.算法理论概述
LSTM通过 “门控机制” 解决传统循环神经网络(RNN)的梯度消失 / 爆炸问题,其核心结构包括输入门(Input Gate)、遗忘门(Forget Gate)、细胞状态(Cell State)和输出门(Output Gate)。
设LSTM网络层N的取值,N∈[N_min, N_max],如 N_min=10、N_max=50)。 以LSTM在训练集上的预测误差作为适应度函数(目标:最小化误差),采用均方根误差(RMSE),公式为:
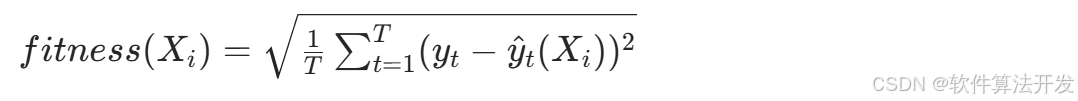
其中,T为训练集样本数, y t 为t时刻真实值, y^ t (Xi ) 为基于个体 Xi 的LSTM预测值。
RTH通过两轮更新实现寻优,模拟红尾鹰的搜索行为:
第一轮:盘旋搜索(全局探索) 红尾鹰围绕猎物区域盘旋,个体位置更新公式为:

第二轮:俯冲捕食(局部开发) 当红尾鹰锁定猎物后俯冲,个体位置向最优个体靠近,同时引入局部扰动:

当迭代次数达到预设最大值T ,或最优个体的适应度值小于预设误差阈值ϵ时,停止寻优,将此时的最优个体Xbest 作为LSTM的初始参数。
算法核心优势
自适应层数量选择:避免人工调参(如凭经验设N=20 或30)的主观性,RTH可根据序列复杂度自动匹配最优N,平衡欠拟合与过拟合。
参数 - 结构协同优化:同步优化层数量与对应层参数,相比 “先定N再调参” 的传统方式,大幅提升模型收敛速度与预测精度。
鲁棒性强:RTH的全局寻优能力降低了初始参数随机化对模型的影响,对含噪声的时间序列(如工业传感器数据)适应性更强。
5.完整程序
VVV