Class60 Transformer
Class60 Transformer

Transformer
仅靠注意力机制就能处理序列,不再需要RNN或CNN。
Transformer优势
1.完全并行化(不像 RNN 要一步步算)。
2.容易建模长距离依赖(注意力机制可以直接连接远处的元素)。
3.扩展性好(大模型 → GPT、BERT 等)。
Transformer的整体架构
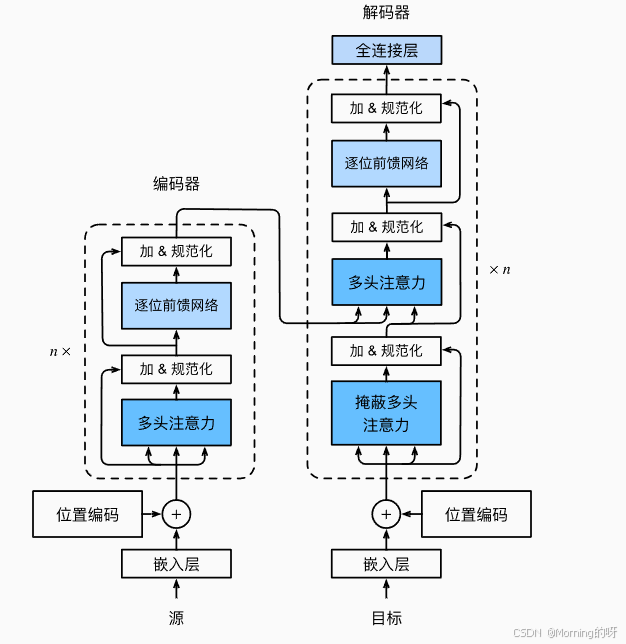
一、整体框架
左边:编码器(Encoder)
输入源序列(比如英文句子) → 经过多层编码 → 得到上下文表示
右边:解码器(Decoder)
输入目标序列(比如法语句子,带位置信息) → 在编码器输出的帮助下生成最终翻译
二、编码器
1.嵌入层(Embedding)
把词(离散 token)映射为向量表示
2.位置编码(Positional Encoding)
因为 Transformer 没有循环结构,需要加入位置信息
词向量 + 位置编码 = 位置敏感的输入向量
3.编码器层(重复 n 次)
每一层包含:
多头自注意力(Multi-Head Self-Attention)
每个词和序列中所有词交互,捕捉依赖
加 & 规范化(Add & Norm)
残差连接 + LayerNorm,保证稳定训练
前馈网络(Feed Forward Network, FFN)
对每个位置单独做非线性变换。
加 & 规范化(再一次)
残差连接 + LayerNorm,保证稳定训练
三、解码器
1.嵌入层 + 位置编码
目标序列(比如法语翻译前半句)嵌入 + 位置编码
2.解码器层(重复 n 次)
每一层包含:
掩蔽多头注意力(Masked Multi-Head Self-Attention)
和编码器的自注意力类似,但加了 mask,保证预测第 i 个词时只能看到前 i-1 个词,防止“偷看未来”
编码器-解码器注意力(Encoder-Decoder Attention)
Query 来自解码器,Key 和 Value 来自编码器 → 让解码器在生成时关注输入序列
前馈网络(FFN)
和编码器一样,对每个位置单独做非线性变换
加 & 规范化
残差连接 + LayerNorm,保证稳定训练
多头注意力
把注意力拆成多个“子空间”,在不同子空间里并行计算注意力,再拼接起来。
这样模型可以从多个视角捕捉信息(例如语法关系、语义关系、短距离依赖、长距离依赖)。
多头注意力的核心思想
1.线性映射
首先输入的𝑄,𝐾,𝑉各自通过不同的权重矩阵映射到低维子空间:
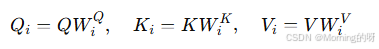
2.并行计算注意力
每个头独立做一次缩放点积注意力:
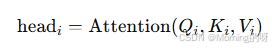
- 拼接与线性变换
把所有头的结果拼接起来,再过一个线性层:
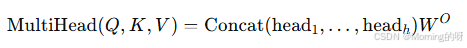
层归一化
稳定训练、加速收敛
LayerNorm的公式
1.计算均值
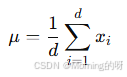
2.计算方差
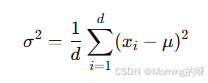
3.归一化
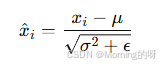
4.缩放和平移
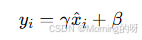
批量归一化和层归一化
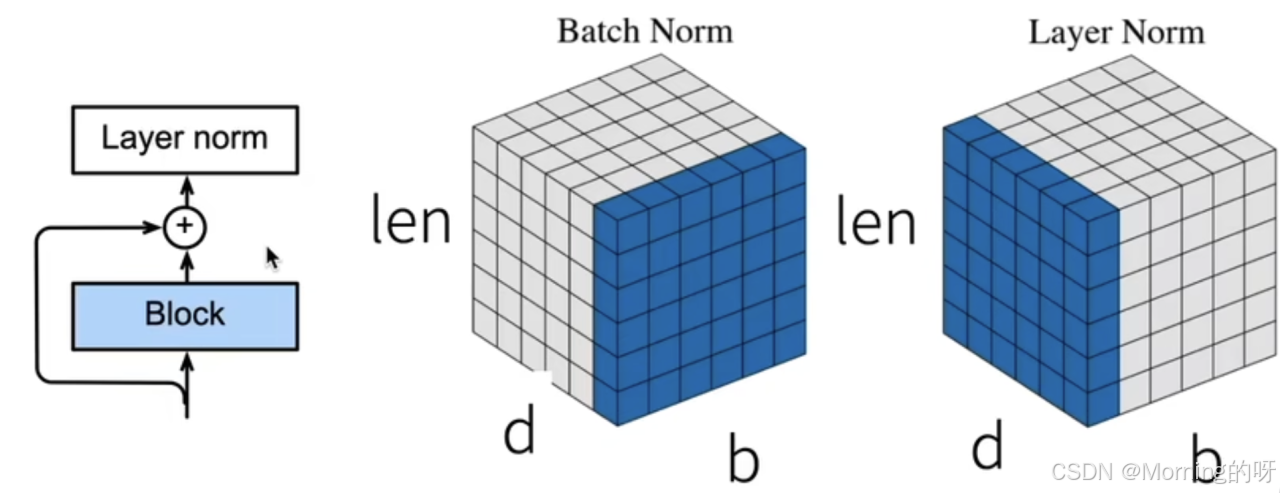
左边的小图:残差 + LayerNorm

LayerNorm:
1、归一化范围:单个样本内部的所有隐藏维度
2、不依赖 batch
3、适合 RNN / Transformer
中间的立方体:Batch Norm

BatchNorm:
1、归一化范围:同一隐藏维度,跨 batch + 跨时间(序列)
2、统计依赖 batch
3、适合 CNN
在 NLP 或 Transformer 里,一个批次的数据通常是一个三维张量:
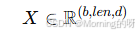

所以一个样本 = (len, d) 的矩阵
BatchNorm 的核心思想是:对每一个特征维度(d 方向上的某一列),跨 batch 和时间位置(len)统计均值和方差。
所以是:在同一维度d上,跨 batch(b)和序列位置(len)一起统计均值和方差。