LLMs之IR:《MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings》的翻译与解读
LLMs之IR:《MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings》的翻译与解读
导读:这篇论文针对现有高性能多向量检索模型计算成本高昂且流程复杂的痛点,提出了一种名为MUVERA的创新性解决方案。其核心是构建“固定维度编码”(FDEs),通过一种有理论保证的、数据无关的随机映射方法,将复杂的多向量集合相似度计算问题,巧妙地规约为简单的单向量内积搜索问题。这使得研究者可以利用成熟高效的MIPS算法库,将检索流程简化为“快速检索+精确重排”的两步,最终在多个基准测试中实现了比现有SOTA系统(PLAID)更高的召回率、更低的延迟和更小的内存占用,为多向量检索技术的大规模应用铺平了道路。
>> 背景痛点
● 性能与成本的矛盾: 神经嵌入模型已成为现代信息检索(IR)的核心。其中,以ColBERT为代表的多向量(Multi-Vector, MV)模型通过为每个数据点(如文档)生成一组嵌入,在检索任务上取得了远超单向量(Single-Vector, SV)模型的卓越性能。 然而,这种性能提升带来了巨大的计算开销。
● 多向量检索的复杂性: 多向量检索的昂贵主要源于两方面:首先,每个文档产生多个嵌入(通常是每个词元一个),导致索引规模急剧膨胀;其次,其相似度计算函数——Chamfer Similarity(也称MaxSim),是一个非线性的求和-最大化操作,无法直接利用过去几十年里被高度优化的最大内积搜索(MIPS)算法。
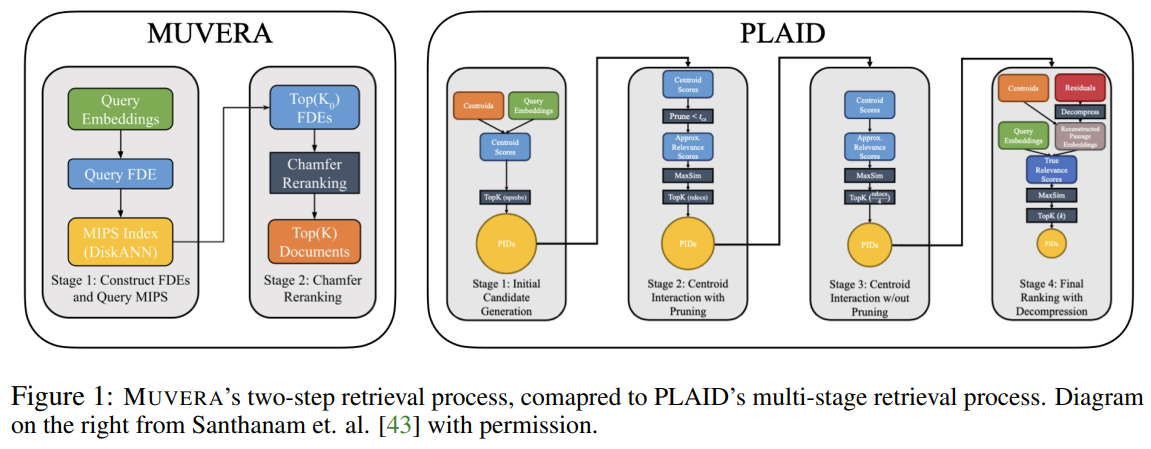
● 现有方案的局限性: 当前主流的多向量检索方案,如ColBERTv2及其检索引擎PLAID,采用的是一种复杂的、多阶段的“单向量启发式(Single-Vector Heuristic)”方法。该方法为查询中的每个向量单独执行MIPS搜索,然后合并、剪枝和重排结果。 这种方法不仅流程复杂、参数敏感、难以调优,而且存在根本性缺陷——它可能会遗漏掉真正的最相似文档,因为它只关注了单个词元的匹配,而忽略了整体的相似度。
>> 具体的解决方案
● 核心方案MUVERA: 论文提出了一种名为MUVERA(Multi-Vector Retrieval Algorithm)的全新检索机制。其核心思想是通过一种巧妙的降维方法,将复杂的多向量相似度搜索问题规约为简单的单向量相似度搜索问题,从而能够直接利用现成的、高效的MIPS求解器。
● 固定维度编码(FDE): 构造 FDE,划分 → 聚合 → 投影 → 拼接。MUVERA的关键技术是固定维度编码(Fixed Dimensional Encodings, FDEs)。它设计了一对非对称的映射函数(一个用于查询,一个用于文档),能将一个向量集合(多向量表示)转换成一个单一的、固定维度的向量(即FDE)。
● 近似相似度计算: 这种转换最神奇的地方在于,两个FDE向量之间的点积(内积),能够高度近似原始多向量集合之间的Chamfer Similarity值。 这样,复杂的 SUM(MAX( dot_product )) 运算就被简化为了单一的 dot_product 运算。
● 简化的两阶段流程: MUVERA将检索流程简化为清晰的两步:
●● 1. 检索(Retrieval): 首先,将数据库中所有文档的多向量表示转换成FDEs并构建MIPS索引。对于一个新查询,计算其FDE,然后在MIPS索引中快速召回最相似的Top-K个候选文档。
●● 2. 重排(Re-ranking): 然后,仅对这K个候选文档,使用原始的、精确的Chamfer Similarity进行重排序,得到最终结果。
这个流程远比PLAID的四阶段流程简洁。
>> 核心思路步骤:空间划分(SimHash/k-means)、簇内聚合(求和/均值)、随机投影降维、多次重复拼接。
● 流程:文档离线构建 FDE → 查询生成 FDE 检索候选 → 用原始 Chamfer 重排序。
● 第一步:空间划分(Partitioning): 使用一种称为“局部敏感哈希”(LSH)的技术(具体为SimHash)生成多个随机超平面,将高维向量空间划分为B个区域(或桶)。LSH的特性保证了距离相近的向量有很大概率落入同一个区域。
● 第二步:非对称聚合(Asymmetric Aggregation): 对于每个区域k,分别对查询和文档向量进行聚合:
* 查询FDE (⃗q(k)): 将所有落入区域k的查询向量求和。
* 文档FDE (⃗p(k)): 将所有落入区域k的文档向量计算质心(即平均值)。 采用质心而非求和,是为了解决一个区域内可能包含多个文档向量的问题。
● 第三步:拼接与降维(Concatenation & Projection): 将所有B个区域的聚合结果拼接起来,形成一个维度为 B × d 的长向量。为了控制最终维度,可以对每个区域的聚合结果应用一次随机投影,将其维度从d降低到d_proj。
● 第四步:重复以增强鲁棒性(Repetition): 将上述过程用不同的随机哈希函数独立重复R_reps次,并将所有结果再次拼接起来。这极大地提高了近似的准确性和稳定性。最终FDE的维度为 B × d_proj × R_reps。
● 第五步:空桶填充(Filling Empty Clusters): 这是一个关键的优化。如果某个查询向量落入的区域k中没有任何文档向量,文档FDE不会简单地置为零,而是会找到离这个区域k“最近”的文档向量来填充。这有效避免了因划分过细而导致的巨大误差。
>> 优势:用 ANN 索引加速检索,PQ 压缩节省存储,简化重排序降低成本。
● 理论保证: 有理论近似保证,FDE 点积可给出 Chamfer 的 ε-近似。MUVERA是第一个为Chamfer Similarity搜索问题提供严格理论保证(ε-近似)的算法,其运行时间快于暴力搜索。这使其从一个“启发式方法”变成了一个“有原则的方法”。
● 高效的检索代理: 实验证明,FDE作为相似度代理远比“单向量启发式”有效。在达到相同召回率的情况下,FDE方法需要检索的候选文档数量比后者少2-5倍,大大减轻了后续重排的计算压力。
● 卓越的端到端性能: 召回率比 PLAID 提升约 10%,延迟降低约 90%。与当前最先进的PLAID系统相比,MUVERA在多个BEIR基准测试集上,平均获得了10%的召回率提升和90%的延迟降低。
● 简化的系统与易调优性: MUVERA将复杂的检索流程简化为“MIPS搜索+重排”两步,更容易部署和维护。其性能与FDE维度紧密相关,通过增加维度可以稳定地提升召回率,调优过程更可预测。
● 高压缩率与内存友好: 候选数减少 2–5 倍,存储可压缩 32×论文证明,可以使用“乘积量化”(Product Quantization, PQ)技术将FDEs压缩高达32倍,而召回率损失可以忽略不计。这不仅极大地节省了内存,还因为数据量减少而提升了查询速度。
● 鲁棒性与数据无关性: 调参需求低,跨数据集鲁棒性强。由于其核心的SimHash分区方法不依赖于数据本身的分布,FDE的生成过程是数据无关的(data-oblivious),使其对数据分布变化更鲁棒,也易于在流式环境中使用。
>> 结论和观点 (侧重经验与建议)
● 空簇填充:可降低召回误差。
● 简化重排序:可在保持召回的同时降低延迟。
● FDE是更优的检索代理: FDE 维度最关键:维度越高召回越好。论文的核心观点是,FDE是一种远优于单向量启发式(即对每个查询词元单独搜索)的检索代理。它更好地捕捉了查询和文档之间“集合对集合”的相似性。
● 乘积量化(PQ)是关键实践: PQ 压缩:大幅节省内存,质量损失小。在实践中,对FDEs应用PQ压缩(特别是PQ-256-8配置)是至关重要的。它不仅能将内存占用降低32倍,还能将QPS(每秒查询数)提升高达20倍,而端到端召回率损失极小。
● 查询向量聚类可加速重排: 在重排阶段前,可以使用一种名为“球雕刻”(Ball Carving)的方法对查询的32个向量进行聚类(例如,相似度大于0.7的聚为一类)。这可以将查询向量数量减少约5.4倍,从而将重排速度提升20-25%,且几乎不影响最终召回率。这暗示原始模型生成的32个查询向量可能存在冗余。
● SimHash优于k-means: SimHash 通常比 k-means 更稳定。尽管k-means也可以用于空间划分,但实验表明SimHash在性能上不相上下甚至更优,且具有数据无关的额外优势,是更佳的选择。
● 系统一致性是亮点: MUVERA的一个显著特点是,它在各种不同类型的数据集上都能保持一致的高召回和低延迟,且无需针对特定数据集进行复杂的参数调优。
目录
《MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings》的翻译与解读
Abstract
1、Introduction
Figure 1:Muvera’s two-step retrieval process, comapred to PLAID’s multi-stage retrieval process. Diagram on the right from Santhanam et. al. [43] with permission.图 1:Muvera 的两步检索过程与 PLAID 的多阶段检索过程的对比。右侧图表由 Santhanam 等人[43]提供,已获许可。
Conclusion
《MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings》的翻译与解读
| 地址 | https://arxiv.org/abs/2405.19504 |
| 时间 | 2025年5月29日 |
| 作者 | Google Research |
Abstract
| Neural embedding models have become a fundamental component of modern information retrieval (IR) pipelines. These models produce a single embedding per data-point, allowing for fast retrieval via highly optimized maximum inner product search (MIPS) algorithms. Recently, beginning with the landmark ColBERT paper, multi-vector models, which produce a set of embedding per data point, have achieved markedly superior performance for IR tasks. Unfortunately, using these models for IR is computationally expensive due to the increased complexity of multi-vector retrieval and scoring. In this paper, we introduce MUVERA (MUlti-VEctor Retrieval Algorithm), a retrieval mechanism which reduces multi-vector similarity search to single-vector similarity search. This enables the usage of off-the-shelf MIPS solvers for multi-vector retrieval. MUVERA asymmetrically generates Fixed Dimensional Encodings (FDEs) of queries and documents, which are vectors whose inner product approximates multi-vector similarity. We prove that FDEs give high-quality -approximations, thus providing the first single-vector proxy for multi-vector similarity with theoretical guarantees. Empirically, we find that FDEs achieve the same recall as prior state-of-the-art heuristics while retrieving 2-5 fewer candidates. Compared to prior state of the art implementations, MUVERA achieves consistently good end-to-end recall and latency across a diverse set of the BEIR retrieval datasets, achieving an average of 10 improved recall with lower latency. | 神经嵌入模型已成为现代信息检索(IR)流程中的基本组成部分。这些模型为每个数据点生成一个嵌入,从而能够通过高度优化的最大内积搜索(MIPS)算法实现快速检索。最近,从具有里程碑意义的 ColBERT 论文开始,多向量模型(为每个数据点生成一组嵌入)在信息检索任务中取得了显著的性能提升。然而,由于多向量检索和评分的复杂性增加,使用这些模型进行信息检索在计算上成本高昂。 在本文中,我们引入了 MUVERA(多向量检索算法),这是一种将多向量相似性搜索简化为单向量相似性搜索的检索机制。这使得可以使用现成的 MIPS 求解器来进行多向量检索。MUVERA 非对称地生成查询和文档的固定维度编码(FDE),这些向量的内积近似多向量相似性。我们证明了 FDE 能够提供高质量的近似值,从而为多向量相似性提供了首个具有理论保证的单向量代理。从经验来看,我们发现 FDEs 在召回率与先前最先进的启发式算法相同的情况下,检索出的候选对象少 2 到 5 个。与先前最先进的实现方式相比,MUVERA 在 BEIR 检索数据集的多样化集合中始终表现出良好的端到端召回率和延迟,平均召回率提高了 10%,且延迟更低。 |
1、Introduction
| Over the past decade, the use of neural embeddings for representing data has become a central tool for information retrieval (IR) [56], among many other tasks such as clustering and classification [39]. Recently, multi-vector (MV) representations, introduced by the late-interaction framework in ColBERT [29], have been shown to deliver significantly improved performance on popular IR benchmarks. ColBERT and its variants [17, 21, 32, 35, 42, 44, 49, 54] produce multiple embeddings per query or document by generating one embedding per token. The query-document similarity is then scored via the Chamfer Similarity (§1.1), also known as the MaxSim operation, between the two sets of vectors. These multi-vector representations have many advantages over single-vector (SV) representations, such as better interpretability [15, 50] and generalization [36, 16, 55, 51]. Despite these advantages, multi-vector retrieval is inherently more expensive than single-vector retrieval. Firstly, producing one embedding per token increases the number of embeddings in a dataset by orders of magnitude. Moreover, due to the non-linear Chamfer similarity scoring, there is a lack of optimized systems for multi-vector retrieval. Specifically, single-vector retrieval is generally accomplished via Maximum Inner Product Search (MIPS) algorithms, which have been highly-optimized over the past few decades [18]. However, SV MIPS alone cannot be used for MV retrieval. This is because the MV similarity is the sum of the SV similarities of each embedding in a query to the nearest embedding in a document. Thus, a document containing a token with high similarity to a single query token may not be very similar to the query overall. Thus, in an effort to close the gap between SV and MV retrieval, there has been considerable work in recent years to design custom MV retrieval algorithms with improved efficiency [43, 12, 21, 42]. | 在过去十年中,神经嵌入在信息检索(IR)[56] 中已成为一种核心工具,同时在聚类和分类等众多任务中也得到了广泛应用[39]。最近,由 ColBERT 晚期交互框架引入的多向量(MV)表示法已被证明在流行的 IR 基准测试中能显著提高性能。ColBERT 及其变体[17, 21, 32, 35, 42, 44, 49, 54] 通过为每个词生成一个嵌入来为每个查询或文档生成多个嵌入。然后通过两组向量之间的 Chamfer 相似度(§1.1),也称为 MaxSim 操作,来计算查询与文档的相似度得分。这些多向量表示法相较于单向量(SV)表示法具有诸多优势,例如更好的可解释性[15, 50]和泛化能力[36, 16, 55, 51]。 尽管有这些优势,但多向量检索本质上比单向量检索更昂贵。首先,每个词生成一个嵌入会使数据集中的嵌入数量增加几个数量级。此外,由于非线性倒角相似度评分的存在,目前缺乏针对多向量检索的优化系统。具体而言,单向量检索通常通过最大内积搜索(MIPS)算法来实现,这种算法在过去几十年中得到了高度优化[18]。然而,单向量 MIPS 本身无法用于多向量检索。这是因为多向量相似度是查询中每个嵌入与文档中最接近嵌入的单向量相似度之和。因此,包含与单个查询词高度相似的词项的文档可能整体上与查询的相似度并不高。因此,为了缩小单向量检索和多向量检索之间的差距,近年来人们做了大量工作来设计具有更高效率的定制多向量检索算法[43, 12, 21, 42]。 |
| The most prominent approach to MV retrieval is to employ a multi-stage pipeline beginning with single-vector MIPS. The basic version of this approach is as follows: in the initial stage, the most similar document tokens are found for each of the query tokens using SV MIPS. Then the corresponding documents containing these tokens are gathered together and rescored with the original Chamfer similarity. We refer to this method as the single-vector heuristic. ColBERTv2 [44] and its optimized retrieval engine PLAID [43] are based on this approach, with the addition of several intermediate stages of pruning. In particular, PLAID employs a complex four-stage retrieval and pruning process to gradually reduce the number of final candidates to be scored (Figure 1). Unfortunately, as described above, employing SV MIPS on individual query embeddings can fail to find the true MV nearest neighbors. Additionally, this process is expensive, since it requires querying a significantly larger MIPS index for every query embedding (larger because there are multiple embeddings per document). Finally, these multi-stage pipelines are complex and highly sensitive to parameter setting, as recently demonstrated in a reproducibility study [37], making them difficult to tune. To address these challenges and bridge the gap between single and multi-vector retrieval, in this paper we seek to design faster and simplified MV retrieval algorithms. Contributions. | 多向量检索最突出的方法是采用多阶段流水线,从单向量 MIPS 开始。这种方法的基本版本如下:在初始阶段,使用单向量 MIPS 为查询中的每个词项找到最相似的文档词项。然后,包含这些标记的相应文档会被收集起来,并使用原始的 Chamfer 相似度重新评分。我们将这种方法称为单向量启发式。ColBERTv2 [44] 及其优化的检索引擎 PLAID [43] 基于此方法,增加了几个中间的剪枝阶段。特别是,PLAID 采用了一个复杂的四阶段检索和剪枝过程,逐步减少最终要评分的候选数量(图 1)。不幸的是,如上所述,在单个查询嵌入上使用 SV MIPS 可能无法找到真正的 MV 最近邻。此外,此过程成本高昂,因为对于每个查询嵌入,都需要查询一个明显更大的 MIPS 索引(更大是因为每个文档都有多个嵌入)。最后,这些多阶段的流水线复杂且对参数设置高度敏感,正如最近的一项可重复性研究 [37] 所证明的那样,这使得它们难以调整。为了解决这些挑战,并弥合单向量检索和多向量检索之间的差距,在本文中,我们试图设计更快且更简化的 MV 检索算法。 |
| We propose Muvera: a multi-vector retrieval mechanism based on a light-weight and provably correct reduction to single-vector MIPS. Muvera employs a fast, data-oblivious transformation from a set of vectors to a single vector, allowing for retrieval via highly-optimized MIPS solvers before a single stage of re-ranking. Specifically, Muvera transforms query and document MV sets Q,P⊂ℝd into single fixed-dimensional vectors q→,p→, called Fixed Dimensional Encodings (FDEs), such that the the dot product q→⋅p→ approximates the multi-vector similarity between Q,P (§2). Empirically, we show that retrieving with respect to the FDE dot product significantly outperforms the single vector heuristic at recovering the Chamfer nearest neighbors (§3.1). For instance, on MS MARCO, our FDEs Recall@N surpasses the Recall@2-5N achieved by the SV heuristic while scanning a similar total number of floats in the search. We prove in (§2.1) that our FDEs have strong approximation guarantees; specifically, the FDE dot product gives an ε-approximation to the true MV similarity. This gives the first algorithm with provable guarantees for Chamfer similarity search with strictly faster than brute-force runtime (Theorem 2.2). Thus, Muvera provides the first principled method for MV retrieval via a SV proxy. We compare the end-to-end retrieval performance of Muvera to PLAID on several of the BEIR IR datasets, including the well-studied MS MARCO dataset. We find Muvera to be a robust and efficient retrieval mechanism; across the datasets we evaluated, Muvera obtains an average of 10% higher recall, while requiring 90% lower latency on average compared with PLAID. Additionally, Muvera crucially incorporates a vector compression technique called product quantization that enables us to compress the FDEs by 32× (i.e., storing 10240 dimensional FDEs using 1280 bytes) while incurring negligible quality loss, resulting in a significantly smaller memory footprint. | 贡献。我们提出 Muvera:一种基于轻量级且可证明正确的单向量 MIPS 归约的多向量检索机制。Muvera 采用一种快速且与数据无关的转换方法,将一组向量转换为单个向量,从而能够通过高度优化的 MIPS 求解器进行检索,然后再进行一轮重排序。具体而言,Muvera 将查询和文档的多向量集 Q、P ⊂ ℝd 转换为单个固定维度向量 q→、p→,称为固定维度编码(FDE),使得 q→·p→ 的点积近似于 Q、P 之间的多向量相似度(§2)。通过实验,我们证明了基于 FDE 点积的检索在恢复 Chamfer 最近邻方面显著优于单向量启发式方法(§3.1)。例如,在 MS MARCO 数据集上,我们的 FDEs 的 Recall@N 超过了单向量启发式方法在扫描相似数量的浮点数时所达到的 Recall@2-5N。我们在(§2.1)中证明,我们的 FDE 具有很强的近似保证;具体来说,FDE 点积对真实多向量相似度给出了 ε 近似。这给出了首个具有严格优于暴力搜索运行时间的可证明保证的 Chamfer 相似性搜索算法(定理 2.2)。因此,Muvera 为通过 SV 代理进行 MV 检索提供了首个有原则的方法。 我们对 Muvera 和 PLAID 在多个 BEIR 检索数据集上的端到端检索性能进行了比较,其中包括广受研究的 MS MARCO 数据集。我们发现 Muvera 是一种稳健且高效的检索机制;在我们评估的数据集中,Muvera 的平均召回率比 PLAID 高出 10%,同时平均延迟降低了 90%。此外,Muvera 关键性地采用了名为乘积量化的产品压缩技术,这使我们能够将 FDE 压缩 32 倍(即使用 1280 字节存储 10240 维的 FDE),同时几乎不会造成质量损失,从而显著减少了内存占用。 |
Figure 1:Muvera’s two-step retrieval process, comapred to PLAID’s multi-stage retrieval process. Diagram on the right from Santhanam et. al. [43] with permission.图 1:Muvera 的两步检索过程与 PLAID 的多阶段检索过程的对比。右侧图表由 Santhanam 等人[43]提供,已获许可。
Conclusion
| In this paper, we presented Muvera: a principled and practical MV retrieval algorithm which reduces MV similarity to SV similarity by constructing Fixed Dimensional Encoding (FDEs) of a MV representation. We prove that FDE dot products give high-quality approximations to Chamfer similarity (§2.1). Experimentally, we show that FDEs are a much more effective proxy for MV similarity, since they require retrieving 2-4× fewer candidates to achieve the same recall as the SV Heuristic (§3.1). We complement these results with an end-to-end evaluation of Muvera, showing that it achieves an average of 10% improved recall with 90% lower latency compared with PLAID. Moreover, despite the extensive optimizations made by PLAID to the SV Heuristic, we still achieve significantly better latency on 5 out of 6 BEIR datasets we consider (§3). Given their retrieval efficiency compared to the SV heuristic, we believe that there are still significant gains to be obtained by optimizing the FDE method, and leave further exploration of this to future work. | 在本文中,我们提出了 Muvera:一种基于原则且实用的多视图检索算法,通过构建多视图表示的固定维度编码(FDE)将多视图相似度转化为单视图相似度。我们证明了 FDE 点积能很好地近似到切比雪夫相似度(§2.1)。实验表明,FDE 是多视图相似度更有效的代理,因为要达到与单视图启发式方法相同的召回率,它需要检索的候选对象数量减少了 2 到 4 倍(§3.1)。我们还通过端到端评估了 Muvera,结果表明,与 PLAID 相比,其平均召回率提高了 10%,延迟降低了 90%。此外,尽管 PLAID 对单视图启发式方法进行了大量优化,但在我们考虑的 6 个 BEIR 数据集中的 5 个上,我们的延迟仍显著更低(§3)。鉴于 FDE 方法与单视图启发式方法相比在检索效率上的优势,我们认为通过优化 FDE 方法仍能获得显著收益,并将对此进一步探索留作未来工作。 |
| Broader Impacts and Limitations: While retrieval is an important component of LLMs, which themselves have broader societal impacts, these impacts are unlikely to result from our retrieval algorithm. Our contribution simply improves the efficiency of retrieval, without enabling any fundamentally new capabilities. As for limitations, while we outperformed PLAID, sometimes significantly, on 5 out of the 6 datasets we studied, we did not outperform PLAID on MS MARCO, possibly due to their system having been carefully tuned for MS MARCO given its prevalence. Additionally, we did not study the effect that the average number of embeddings mavg per document has on retrieval quality of FDEs; this is an interesting direction for future work. | 更广泛的影响与局限性:尽管检索是大型语言模型的重要组成部分,而大型语言模型本身具有更广泛的社会影响,但这些影响不太可能源于我们的检索算法。我们的贡献只是提高了检索效率,并未赋予任何根本性的新能力。至于局限性,尽管在我们研究的 6 个数据集中,我们在其中 5 个数据集上显著优于 PLAID,但在 MS MARCO 数据集上我们并未超越 PLAID,这可能是由于 PLAID 系统针对该数据集进行了精心调优,鉴于其广泛使用。此外,我们没有研究每份文档的平均嵌入数量 mavg 对 FDE 检索质量的影响;这是未来研究的一个有趣方向。 |