ACP(五):优化提示词(Prompt),精细地控制大模型的输出
前文回顾
上一节中通过RAG方法,大模型已经获取到了公司的私有知识。为了方便调用,将其封闭成了几个函数,并保存在了chatbot/rag.py中。现在你可以通过如下代码来快速调用。
rag.py
# 导入依赖
from llama_index.core import SimpleDirectoryReader,VectorStoreIndex,StorageContext,load_index_from_storage
from llama_index.embeddings.dashscope import DashScopeEmbedding,DashScopeTextEmbeddingModels
from llama_index.llms.dashscope import DashScope
# 这两行代码是用于消除 WARNING 警告信息,避免干扰阅读学习,生产环境中建议根据需要来设置日志级别
import logging
logging.basicConfig(level=logging.ERROR)
from llama_index.llms.openai_like import OpenAILike
import osdef indexing(document_path="./docs", persist_path="knowledge_base/test"):"""建立索引并持久化存储参数path(str): 文档路径"""index = create_index(document_path)# 持久化索引,将索引保存为本地文件index.storage_context.persist(persist_path)def create_index(document_path="./docs"):"""建立索引参数path(str): 文档路径"""# 解析 ./docs 目录下的所有文档documents = SimpleDirectoryReader(document_path).load_data()# 建立索引index = VectorStoreIndex.from_documents(documents,# 指定embedding 模型embed_model=DashScopeEmbedding(# 你也可以使用阿里云提供的其它embedding模型:https://help.aliyun.com/zh/model-studio/getting-started/models#3383780daf8hwmodel_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2))return indexdef load_index(persist_path="knowledge_base/test"):"""加载索引参数persist_path(str): 索引文件路径返回VectorStoreIndex: 索引对象"""storage_context = StorageContext.from_defaults(persist_dir=persist_path)return load_index_from_storage(storage_context,embed_model=DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2))def create_query_engine(index):"""创建查询引擎参数index(VectorStoreIndex): 索引对象返回QueryEngine: 查询引擎对象"""query_engine = index.as_query_engine(# 设置为流式输出streaming=True,# 此处使用qwen-plus-0919模型,你也可以使用阿里云提供的其它qwen的文本生成模型:https://help.aliyun.com/zh/model-studio/getting-started/models#9f8890ce29g5ullm=OpenAILike(model="qwen-plus-0919",api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key=os.getenv("DASHSCOPE_API_KEY"),is_chat_model=True))return query_enginedef ask(question, query_engine):"""向答疑机器人提问参数question(str): 问题query_engine(QueryEngine): 查询引擎对象返回str: 回答"""streaming_response = query_engine.query(question)streaming_response.print_response_stream()from llama_index.core import PromptTemplate
def update_prompt_template(query_engine,qa_prompt_tmpl_str = ("你叫公司小蜜,是公司的答疑机器人。你需要仔细阅读参考信息,然后回答大家提出的问题。""注意事项:\n""1. 根据上下文信息而非先验知识来回答问题。\n""2. 如果是工具咨询类问题,请务必给出下载地址链接。\n""3. 如果员工部门查询问题,请务必注意有同名员工的情况,可能有2个、3个甚至更多同名的人\n""以下是参考信息。""---------------------\n""{context_str}\n""---------------------\n""问题:{query_str}\n。""回答:")):"""修改prompt模板输入是prompt修改前的query_engine,以及提示词模板;输出是prompt修改后的query_engine"""qa_prompt_tmpl_str = qa_prompt_tmpl_strqa_prompt_tmpl = PromptTemplate(qa_prompt_tmpl_str)query_engine.update_prompts({"response_synthesizer:text_qa_template": qa_prompt_tmpl})# print("提示词模板修改成功")return query_engine调用
from chatbot import rag, llm
# 加载索引
# 上小节已经建立了索引,因此这里可以直接加载索引。如果需要重建索引,可以增加一行代码:rag.indexing()
index = rag.load_index()
query_engine = rag.create_query_engine(index=index)
# 定义问答函数
def ask_llm(question, query_engine):streaming_response = query_engine.query(question)streaming_response.print_response_stream()
优化提示词以改善大模型回答质量
上一节,你已经成功地让答疑机器人通过RAG掌握了公司的内部知识。现在,你可以测试一下它的实际效果。一位新同事想了解项目管理工具,于是他向机器人发起了提问:
# 仅使用RAG时,机器人的表现
question = "我们公司项目管理应该用什么工具?"
ask_llm(question, query_engine)
#输出
公司项目管理可以使用Jira或Trello这样的项目管理软件。这些工具能够帮助团队有效地跟踪项目进度,管理任务分配,并确保所有成员都对项目的当前状态有清晰的了解。
这个回答是正确的,但不够“好用”。同事反馈说:“如果能直接附上工具的链接就完美了,省得我再去到处找。”
这个需求非常合理。一个最直观、最“暴力”的解决方法,或许是在用户的问题后面,手动加上一句指令:
# 尝试一个简单的“补丁”
question = "我们公司项目管理应该用什么工具?"
instruction = " 回答时请务必附带上工具的官方网站或下载链接。"# 将问题和指令简单地拼接在一起
new_question = question + instruction
ask_llm(new_question, query_engine)
#输出
对于项目管理,推荐使用 Jira 或 Trello。这两个工具都非常适合管理和跟踪项目进度,确保团队成员之间的高效协作。- **Jira**: [官方网站](https://www.atlassian.com/software/jira)
- **Trello**: [官方网站](https://trello.com/)
问题似乎解决了。但…真的解决了吗?
你需要考虑另一个场景,当用户问一个跟工具无关的问题时:
# 看看这个“补丁”在其他问题上的表现
question_2 = "我们公司的年假有多少天?"
instruction = " 回答时请务必附带上工具的官方网站或下载链接。"new_question_2 = question_2 + instruction
ask_llm(new_question_2, query_engine)
#输出
关于您询问的年假天数,您的问题没有直接提及具体的公司政策或相关细节,因此我无法给出确切的答案。通常,年假天数会根据公司的具体规定以及员工的工作年限等因素有所不同。建议您可以咨询人力资源部门获取更准确的信息。至于您提到的需要附带工具的官方网站或下载链接,由于您的问题中并未明确指出需要哪种工具,我暂时无法提供相应的链接。如果您能进一步说明所需工具的类型或名称,我将很乐意为您提供帮助。同时,对于公司内部使用的工具,您可以联系IT部门的张伟,他可以为您提供相关的支持和指导。
现在,问题暴露了。这种“一刀切”地拼接指令的方式非常脆弱。它不仅可能让模型的回答变得啰嗦和奇怪,而且每次提问都要手动判断该拼接哪句指令,这在真实的应用中是完全不可行的。
这正是深入学习提示词工程(Prompt EngIneering)的原因。它属于上下文工程(Context Engineering) 一部分,教你如何不再使用这种临时的“补丁”,而是系统性地、智能地构建与模型的对话上下文,精确的“指导”模型如何根据不同的情况来回答问题。
提示词框架
基本要素
当和大模型在交流时,可以将它想象是一个经过**“社会化训练的”人**,交流方式应当和人与人之间传递信息的方式一样。你的需求需要清晰明确,不能有歧义。你的提问方式(Prompt)越清晰明确,大模型越能抓住问题的关键点,回复就越符合你的预期。为了系统性地构建高效的上下文,我们可以遵循一个包含多个基本要素的提示词框架:任务目标、上下文、角色、受众、样例、输出格式。这些要素共同构成了一个完整的上下文“蓝图”,能帮助你构建一个完整、有效的提示词。
| 要素 | 含义 |
|---|---|
| 任务目标(Object) | 明确要求大模型完成什么任务,让大模型专注具体目标 |
| 上下文(Context) | 任务的背景信息,比如操作流程、任务场景等,明确大模型理解讨论的范围 |
| 角色(Role) | 大模型扮演的角色,或者强调大模型应该使用的语气、写作风格等,明确大模型回应的预期情感 |
| 受众(Audience) | 明确大模型针对的特定受众,约束大模型的应答风格 |
| 样例(Sample) | 让大模型参考的具体案例,大模型会从中抽象出实现方案、需要注意的具体格式等信息 |
| 输出格式(Output Format) | 明确指定输出的格式、输出类型、枚举值的范围。通常也会明确指出不需要输出的内容和不期望的信息,可以结合样例来进一步明确输出的格式和输出方法 |
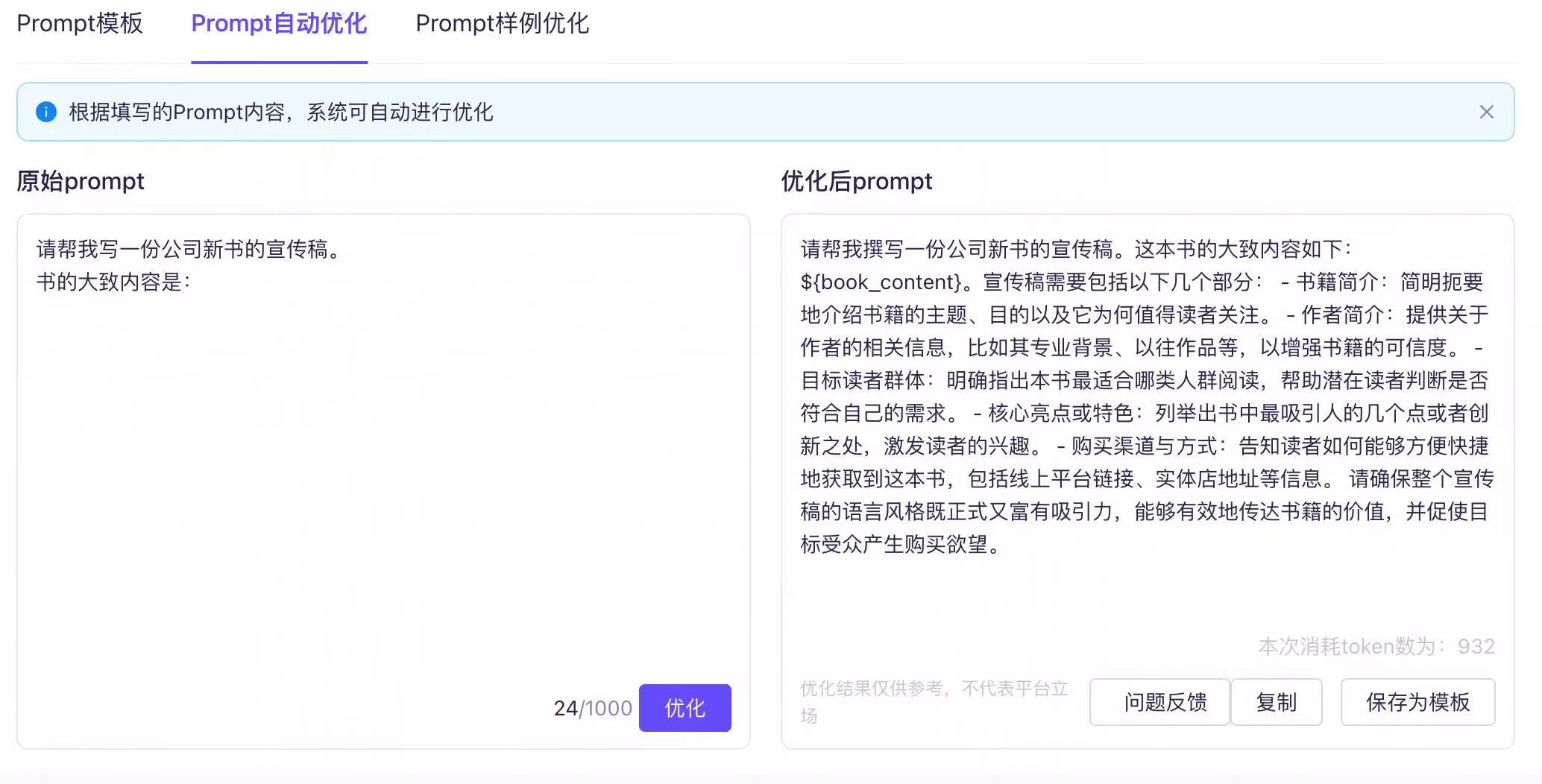
提示词模板
在开发大模型应用时,直接让用户根据框架书写提示词并非最佳选择。你可参考各种提示词要素,构建一个提示词模板。提示词模板可能预设部分信息,如大模型的角色、注意事项等,以此来约束大模型的行为。开发者只需在模板中配置输入参数,便能创建标准化的大模型的应用。
使用LlamaIndex中创建的RAG应用中,有个默认的提示词模板,如下所示:
默认的模板可以使用代码查看,你可以参考LlamaIndex官网的代码
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
其中,context_str和query_str都表示变量。在进行向量检索和提问过程中,context_str将替换为从向量库存检索到的上下文信息,query_str则替换为用户的问题。
由于原模板是通用模板,不适合用来约束答疑机器人的行为。你可以通过下列示例代码重新调整提示词模板,其中prompt_template_string表示新的提示词模板,你可以根据自己的场景自行修改。
# 构建提示词模板
prompt_template_string = ("你是公司的客服小蜜,你需要简明扼要的回答用户的问题""【注意事项】:\n""1. 依据上下文信息来回答用户问题。\n""2. 你只需要回答用户的问题,不要输出其他信息\n""以下是参考信息。""---------------------\n""{context_str}\n""---------------------\n""问题:{query_str}\n。""回答:"
)# 更新提示词模板
rag.update_prompt_template(query_engine,prompt_template_string)
构建有效提示词的技巧
清晰表达需求,并使用分隔符
明确的表达需求可以确保大模型生成的内容与任务高度相关。需求包括任务目标、背景及上下文信息,还可以使用分隔符将各种提示词要素隔开。
分隔符可以使大模型抓住具体的目标,避免模糊的理解,也减少对不必要信息的处理。分隔符一般可以选择**“【】”、“<< >>”、"###"来标识关键要素,用“===”、“—”来分隔段落,或者使用xml标签**如<tag></tag>来对特定段落进行标识。当然,分隔符不止上述提到的几种,只需要起到明确阻隔的作用即可。需要注意的是,如果提示词中已大量使用某种符号(如【】),则应避免用该符号作为分隔符,以防混淆。
限定角色和受众
角色指大模型在特定场景下应扮演的身份,如专家、顾问或助手。受从是使用模型输出的目标用户群体,如普通消费者或学生。这有助于开发者定制内容的风格和深度。以下示例将展示不同的系统角色对输出文本风格和内容影响,用户的问题为:qwen-vl是什么?
以下仅演示提示模板和输出的内容,你可以将提示词模板传入到prompt_template_string中,将用户问题传入到question中,再调用ask_llm函数。
| 角色 | 大模型算法工程师 | 小学老师 |
|---|---|---|
| 提示模板 | "你是资深的大模型算法工程师,请根据用户的问题进行解答\n" "---------------------\n" "{context_str}\n" "---------------------\n" "问题:{query_str}\n。" "回答:" | "你是一名小学老师,请根据用户的问题进行解答\n" "---------------------\n" "{context_str}\n" "---------------------\n" "问题:{query_str}\n。" "回答:" |
| 用户问题 | Qwen-VL | Qwen-VL |
| 输出回答 | Qwen-VL是阿里巴巴云推出的一种多模态预训练模型,它结合了文本和图像处理能力,能够理解和生成与图像相关的文本描述。简单来说,Qwen-VL可以看作是一个能够“看图说话”的人工智能助手,它不仅能够理解图片的内容,还能根据图片内容生成相应的文字描述或回答相关问题。这种技术在多个领域都有广泛的应用前景,比如自动图像标注、视觉问答系统、基于内容的图像搜索等。对于新媒体运营而言,Qwen-VL这样的工具可以帮助提高内容创作效率,增强用户体验,为用户提供更加丰富多元的信息展示方式。 | 小朋友们,我们今天来认识一个新朋友,它的名字叫做Qwen-VL! Qwen-VL就像是一个非常聪明的机器人,它拥有“眼睛”👀和“大脑”🧠。它能“看”图片、视频,还能理解它们的意思,就像我们一样! 比如,你给它看一张小猫玩毛线球的图片,它不仅能认出这是一只小猫🐱,还能告诉你它在玩毛线球🧶。 更厉害的是,你还可以问它:“小猫是什么颜色的?”,它就能告诉你小猫的颜色。 它还能理解视频里的内容,比如你给它看一段小朋友们踢足球⚽️的视频,它能告诉你谁在踢球,球踢到了哪里,甚至还能猜到接下来可能会发生什么! Qwen-VL就像一个正在学习的小朋友,它还在不断地学习和进步,将来它会变得更聪明,能做更多的事情,帮助我们更好地了解这个世界! |
规定输出格式
有时候,开发者在设计大模型应用时,需要采用结构化的数据作为下游系统的输入,才能完成整个应用的开发,但是一般大模型是输出连续的文本。不用担心,大模型有结构化输出的能力。你只需在提示词中指定输出的格式和要求,大模型有很大可能会输出结构化的内容。
question_task= """
【任务要求】
你将看到一句话或一段话。你需要审查这段话中有没有错别字。如果出现了错别字,你要指出错误,并给出解释。“的” 和 “地” 混淆不算错别字,没有错误
---
【输出要求】
请你只输出json格式,不要输出代码段
其中,label只能取0或1,0代表有错误,1代表没有错误
reason是错误的原因
correct是修正后的文档内容
---
【用户输入】
以下是用户输入,请审阅:
"""
question_doc = "分隔符是特殊的符号,它们帮助大语言膜形 (LLM) 识别提示中哪些部分应当被视为一个完整的意思单元。"question = question_task + question_doc
ask_llm(question, query_engine
{"label": 0,"reason": "‘膜形’应为‘模型’","correct": "分隔符是特殊的符号,它们帮助大语言模型 (LLM) 识别提示中哪些部分应当被视为一个完整的意思单元。"
}
提供少样本示例
在上个例子中,提示词规定了输出的格式,大模型成功生成了格式化的内容。然而,如果希望大模型输出的内容不仅格式正确,而且风格和结构也保持一致,可以提供几个样例作为参考。这相当于给大模型提供了一本“参考书”。下面的代码示例中,先观察下没有样例时的大模型的输出。
question_task = """
【任务要求】
请你根据用户的主题,创作内容。
---
【输出要求】
最终输出需要以Markdown格式呈现,请注意,在你的回答中包含所有必要的Markdown元素,如标题、列表、链接、图片引用、加粗等,以便于阅读、后续编辑和保存。
---
【用户输入】
以下是用户的要求创作的主题:
"""
question_doc = "手工钥匙扣制作教程"question = question_task + question_doc
ask_llm(question, query_engine)
# 手工钥匙扣制作教程欢迎来到手工钥匙扣制作教程!本教程将引导您一步步完成一个独特且个性化的钥匙扣制作过程。无论您是手工爱好者还是初学者,都能从中学到实用的技巧和创意灵感。让我们开始吧!## 准备材料在开始之前,请确保您已经准备好了以下材料和工具:- **彩色布料**:选择您喜欢的颜色和图案。
- **剪刀**:用于裁剪布料。
- **针线**:用于缝合布料。
- **填充物**:如棉花,用于填充钥匙扣内部。
- **钥匙扣环**:用于连接钥匙。
- **装饰品**:如纽扣、亮片等,用于装饰您的钥匙扣。## 制作步骤### 步骤 1: 设计图案1. **选择设计**:决定您想要的钥匙扣形状,可以是动物、植物或其他任何您喜欢的图案。
2. **绘制模板**:在纸上画出设计图案,然后剪下作为模板。### 步骤 2: 裁剪布料1. **放置模板**:将模板放在布料上,确保布料平整。
2. **裁剪布料**:沿着模板边缘仔细裁剪布料,确保边缘整齐。### 步骤 3: 缝合布料1. **对齐布料**:将两块裁剪好的布料正面相对,对齐边缘。
2. **缝合边缘**:用针线沿着边缘缝合,留一个小口用于填充。
3. **翻面**:将缝合好的布料翻面,使正面朝外。### 步骤 4: 填充与封口1. **填充**:通过预留的小口,将填充物填入布料内,直到感觉饱满。
2. **封口**:用针线将预留的小口缝合,确保填充物不会掉出。### 步骤 5: 添加装饰1. **装饰**:使用纽扣、亮片等装饰品,为您的钥匙扣增添个性。
2. **固定装饰品**:用针线将装饰品固定在钥匙扣上。### 步骤 6: 安装钥匙扣环1. **固定环**:在钥匙扣的一端缝上钥匙扣环,确保牢固。
2. **检查**:检查所有部分是否牢固,确保钥匙扣可以安全使用。## 完成与展示恭喜您完成了自己的手工钥匙扣!现在您可以将它挂在钥匙圈上,或者作为礼物送给朋友。希望这个教程对您有所帮助,如果您有任何问题或建议,欢迎随时联系我们。## 小贴士- **选择布料时**,可以选择质地较厚的布料,这样更容易缝制且更耐用。
- **填充物的选择**也很重要,过多或过少都会影响钥匙扣的手感。
- **装饰品**可以根据个人喜好自由发挥,让每个钥匙扣都独一无二。希望您享受制作过程,期待看到您的作品!---如果您有任何疑问或需要进一步的帮助,请随时联系我们的客服团队。祝您制作愉快!
有样例情况:
question_task= """
【任务要求】
请根据用户的主题,结合下面【样例】给的例子,理解和使用一致的风格和结构继续创作内容,不要输出多余的内容。
---
【输出要求】
最终输出需要以Markdown格式呈现,请注意,在你的回答中包含所有必要的Markdown元素,如标题、列表、链接、图片引用、加粗等,以便于阅读、后续编辑和保存。
---
【样例】
### 示例1: 制作简易书签
# 简易书签制作教程## 材料清单
- 彩色卡纸
- 剪刀
- 装饰贴纸
- 铅笔## 步骤
1. 选择一张彩色卡纸。
2. 用铅笔在卡纸上画出一个长方形,尺寸约为2英寸 x 6英寸。
3. 沿着铅笔线剪下长方形。
4. 使用装饰贴纸对书签进行个性化装饰。
5. 完成!现在你有了一个独一无二的书签。## 结束语
希望这个教程能帮助你制作出满意的书签!---
【用户输入】
以下是用户的要求创作的主题:
"""
question_doc = "制作手工贺卡"question = question_task + question_doc
ask_llm(question, query_engine)
# 手工贺卡制作教程## 材料清单
- 彩色卡纸
- 剪刀
- 胶水或双面胶
- 马克笔或彩色铅笔
- 装饰物(如亮片、贴纸、丝带)
- 尺子## 步骤
1. **准备材料**:首先,准备好所有需要的材料,包括彩色卡纸、剪刀、胶水或双面胶、马克笔或彩色铅笔、装饰物和尺子。
2. **裁剪卡纸**:使用尺子和铅笔在彩色卡纸上量出一个合适的大小,通常贺卡的尺寸可以是5英寸 x 7英寸。然后,用剪刀沿着铅笔线小心地剪下。
3. **折叠卡纸**:将剪好的卡纸对折,确保边缘整齐,这样贺卡的封面和内页就形成了。
4. **设计封面**:使用马克笔或彩色铅笔在贺卡封面上绘制图案或写上祝福语。也可以粘贴装饰物,如亮片、贴纸或丝带来增加视觉效果。
5. **添加内部内容**:打开贺卡,在内页写下你想对收卡人说的话。可以是温馨的话语、诗句或是简单的祝福。
6. **检查和完善**:检查贺卡的所有部分是否牢固,确保没有遗漏的装饰或文字错误。如果需要,可以进行最后的修饰。
7. **完成**:现在,你的手工贺卡已经完成了!你可以将其送给亲朋好友,表达你的心意。## 结束语
希望这个教程能帮助你制作出充满心意的手工贺卡,让你的情感传递更加特别和有意义!
给模型“思考”的时间
对于一些复杂的任务来说,使用上面提到的提示词也许还不能帮助大模型完成任务。但是你可以通过让大模型一步步“思考”,引导大模型输出任务的中间步骤,允许大模型在进行推理之前,得到更多的依据,从而提升在复杂任务的表现能力。思维链(COT) 方法是让模型进行思考的一种方法。它通过让模型处理中间步骤,逐步将复杂问题分解为子问题,最终推导出正确答案。
假设有这样的场景,让大模型计算下面这道数学题,在此先提示一下,这道题的正确答案为10500元。先使用简单的提示词:
question = """
【背景信息】
某教育培训机构(以下简称“公司”)在2023年度发生了以下主要支出:
为了给不同城市的学校学生上课,公司的老师全年共出差了5次,每次出差时间为一周,具体费用如下:- 交通费及住宿费:平均1600元/次- 教学用具采购费用:公司在年初一次性购买了一批教学用具,总价为10000元,预计可以使用4年。【问题描述】
请根据上述背景信息,完成以下任务:
计算全年因教师出差而产生的差旅总费用,包括摊销的教学用具。【输出要求】
直接给出总差旅费用,不要其他信息"""ask_llm(question, query_engine)#最终输出 9000元
由上面的实验结果来看,大模型计算结果不正确。下面将使用COT方法,让大模型逐步进行思考。
question = """某教育培训机构(以下简称“公司”)在2023年度发生了以下主要支出:
为了给不同城市的学校学生上课,公司的老师全年共出差了5次,每次出差时间为一周,具体费用如下:- 交通费及住宿费:平均1600元/次- 教学用具采购费用:公司在年初一次性购买了一批教学用具,总价为10000元,预计可以使用4年。### 问题描述
请根据上述背景信息,完成以下任务:
计算全年因教师出差而产生的差旅总费用,包括摊销的教学用具。### 输出要求
请你一步步推导,计算总差旅费用"""ask_llm(question, query_engine)
#思考过程
首先,我们需要计算全年因教师出差而产生的交通费及住宿费。根据题目信息,公司老师全年共出差了5次,每次出差的交通费及住宿费平均为1600元。因此,这部分费用计算如下:\[ 1600 \, \text{元/次} \times 5 \, \text{次} = 8000 \, \text{元} \]接下来,计算教学用具的摊销费用。教学用具总价为10000元,预计可以使用4年,因此每年的摊销费用为:\[ \frac{10000 \, \text{元}}{4 \, \text{年}} = 2500 \, \text{元/年} \]最后,将这两部分费用相加,得到全年的总差旅费用:\[ 8000 \, \text{元} + 2500 \, \text{元} = 10500 \, \text{元} \]因此,全年因教师出差而产生的总差旅费用为10500元。
经过优化后的提示词,大模型能够准确计算出结果。因此在开发大模型应用时,可以在提示词中添加思维链的方法,可以确保一些推理任务能正确执行。
使大模型进行“思考”的方法还有很多种,比如:思维树(TOT)、思维图(GOT)等。但是就目前大模型的发展来说,仅靠引导大模型“思考”还是无法完成更复杂的工作。大模型也逐渐从COT的提示方法向多智能体(Agent)方向进行发展。
让大模型成为你的提示词教练
一次性就写好一个完美的提示词,往往非常困难。更常见的工作流是:
- 写出第一版本提示词
- 运行它,并分析输出结果中有哪些不符合预期的地方
- 总结问题,思考如何改进,然后修改提示词
- 不断重复这个迭代过程,直到满意为止
你可以回想一下,这是否也是你优化提示词的常规路径?这个过程虽然有效,但非常依赖经验,也颇为耗时。
这时你可能会想:既然大模型这么强大,这个分析、总结、改进的迭代过程,是否能让大模型自己来做呢?让它扮演提示词评审专家的角色,帮助我们分析和优化提示词,无疑会更高效。
答案是肯定的。这种让你和模型一起“讨论”如何优化提示词本身的方法,就叫做Meta Prompting。
- 步骤一:一个不甚理想的初始提示词
假设你的任务是优化答疑机器人的回答,让它在回答新员工关于“公司福利”的问题时,输出更友好、结构更清晰的内容。你可能会从一个简单的提示词开始:
# 在真实的 RAG 应用中,这段文本会由你的向量数据库检索而来。
# 这里用一个字符串来模拟它,方便你进行实验。
retrieved_text = """
关于公司的福利政策,我们提供全面的健康保险,覆盖员工及其直系家属。
年度体检是标配。此外,每年有15天的带薪年假,以及5天的带薪病假。
我们还提供每月500元的交通补贴和300元的餐饮补贴。
为了鼓励员工成长,公司设有每年高达8000元的教育培训基金,员工可以申请用于课程学习或购买专业书籍。
健身方面,公司与多家健身房有合作,员工可享受折扣价。
"""# 这是一个非常基础的提示词,只是简单地将任务和信息拼接起来。
initial_prompt = f"""
根据以下信息,回答新员工关于公司福利的问题。【参考信息】
{retrieved_text}
"""# 看看这个“朴素”的提示词会产生什么样的效果。
response = llm.invoke(initial_prompt)
print("--- 初始回答 ---")
print(response)
输出:
--- 初始回答 ---
新员工您好!很高兴您加入我们的团队。关于公司福利,我可以为您详细介绍:1. **健康保险**:我们为所有员工及其直系家属提供全面的健康保险,确保您和您的家人在健康方面得到充分的保障。2. **年度体检**:每位员工每年都可以享受一次免费的全面体检,帮助您及时了解自己的健康状况。3. **带薪假期**:您每年享有15天的带薪年假,以及5天的带薪病假,让您在需要休息或处理个人事务时无后顾之忧。4. **交通和餐饮补贴**:为了减轻您的日常开销,我们提供每月500元的交通补贴和300元的餐饮补贴。5. **教育培训基金**:公司非常重视员工的成长和发展,特设每年高达8000元的教育培训基金,您可以申请这笔资金用于参加各类课程学习或购买专业书籍,提升自己的职业技能。6. **健身优惠**:我们与多家健身房建立了合作关系,员工可以享受特别折扣价,帮助您保持良好的身体状态
这个回答虽然饮食了所有信息,但你可能会觉得对于一个刚入职的新员工来说,它显得有些平淡和杂乱。它只是简单地复述文本,没有重点,也缺乏热情的欢迎语气。
显然,这个效果没有达到你的预期。现在,你无需自己苦思冥想如何修改,而是可以尝试一种更高效的方法:让大模型来帮你优化。
- 步骤二:构建Meta Prompt,让大模型提供优化建议
现在,你对这个平淡的回答不满意,你可构建一个“Meta Prompt”,清晰地向模型描述你的目标(友好、结构化、重点突出),并将你那不甚理想的初始提示词和它产出的回答一并“喂”给大模型,请求它以“提示词工程专家”的身份,帮你改进。
# 你需要将你的不满和期望清晰地表达出来,这是让AI教练理解你意图的关键。
meta_prompt = f"""
我正在为公司的新员工答疑机器人优化一个提示词,目标是回答关于“公司福利”的问题。这是我的第一个尝试:
---
{initial_prompt}
---这是它生成的输出:
---
{response}
---这个输出不够好。我希望机器人的回答更具吸引力,并且结构清晰,能让新员工快速抓住重点。具体要求如下:
1. **语气**:友好、热情,有欢迎新同事的感觉。
2. **结构**:使用清晰的要点(比如用表情符号开头的列表)来组织内容。
3. **内容**:将福利分为几个类别,如“健康与假期”、“补贴与激励”等。请你扮演一位提示词工程专家,帮我重写这个提示词,以实现上述目标。
"""# 现在,让AI教练开始工作,为你生成一个优化版的提示词。
optimization_suggestion = llm.invoke(meta_prompt)
print("--- 来自AI教练的优化建议 --")
print(optimization_suggestion)
输出:
--- 来自AI教练的优化建议 --
当然可以!以下是根据你的要求优化后的提示词:---根据以下信息,回答新员工关于公司福利的问题,确保回答友好、热情,有欢迎新同事的感觉。同时,使用清晰的要点(比如用表情符号开头的列表)来组织内容,并将福利分为几个类别,如“健康与假期”、“补贴与激励”等。【参考信息】关于公司的福利政策,我们提供全面的健康保险,覆盖员工及其直系家属。
年度体检是标配。此外,每年有15天的带薪年假,以及5天的带薪病假。
我们还提供每月500元的交通补贴和300元的餐饮补贴。
为了鼓励员工成长,公司设有每年高达8000元的教育培训基金,员工可以申请用于课程学习或购买专业书籍。
健身方面,公司与多家健身房有合作,员工可享受折扣价。---这是优化后的输出示例:---🎉 欢迎加入我们的大家庭!🌟 我们为每一位新员工准备了丰富的福利,希望这些福利能帮助您更好地融入公司,享受工作和生活。以下是您可能关心的几大类福利:### 🏥 健康与假期
- **全面健康保险**:我们为所有员工及其直系家属提供全面的健康保险,确保您和您的家人在健康方面得到充分的保障。
- **年度体检**:每位员工每年都可以享受一次免费的全面体检,帮助您及时了解自己的健康状况。
- **带薪假期**:您每年享有15天的带薪年假,以及5天的带薪病假,让您在需要休息或处理个人事务时无后顾之忧。### 💸 补贴与激励
- **交通补贴**:每月提供500元的交通补贴,帮助您减轻通勤费用。
- **餐饮补贴**:每月提供300元的餐饮补贴,让您在工作日也能享受美味的餐食。
- **教育培训基金**:公司非常重视员工的成长和发展,特设每年高达8000元的教育培训基金,您可以申请这笔资金用于参加各类课程学习或购买专业书籍,提升自己的职业技能。### 🏋️♂️ 生活与休闲
- **健身优惠**:我们与多家健身房建立了合作关系,员工可以享受特别折扣价,帮助您保持良好的身体状态。希望这些福利能够帮助您更好地融入公司,享受工作的同时也照顾好自己和家人的生活。如果您有任何疑问,欢迎随时向人力资源部门咨询。祝您在公司有一个愉快的工作体验!---希望这个版本更符合你的需求!如果还有其他调整或补充,请随时告诉我。
观察AI教练给出的建议,你会发现,它给出的优化后提示词,很可能应用了你在前面章节学到的多种技巧,例如:
明确角色(例如,“你是一位热情、友好的入职伙伴”)
清晰的任务描述(例如,“根据提供的参考信息,生成一段关于公司福利的介绍”)
规定输出格式和风格(例如,“使用热情的欢迎语”、“用表情符号开头的列表”)
- 步骤三:使用优化后的提示词
现在你可以直接将这位“AI”教练为你量身定做的提示词用于你的任务,看看效果如何。
# 这是一个假设的、由AI教练建议的优化版提示词
# 在实际应用中,你可以直接使用 `optimization_suggestion` 的输出
# 这里为了演示,我们手动构建一个符合建议的提示词optimized_prompt = f"""
【角色】
你是一位热情、友好的入职伙伴(Onboarding Buddy),你的任务是欢迎新同事,并清晰地介绍公司的福利政策。【任务】
根据提供的【参考信息】,生成一段关于公司福利的介绍。【输出要求】
1. 开头使用热情洋溢的欢迎语。
2. 将福利信息分类整理,例如分为“健康与假期”、“补贴与激励”等。
3. 每个福利项目前使用一个相关的表情符号,使其更生动。
4. 结尾表达对新同事的美好祝愿。【参考信息】
{retrieved_text}
"""# 使用优化后的提示词再次调用模型
final_response = llm.invoke(optimized_prompt)
print("--- 使用优化版提示词的回答 ---")
print(final_response)
--- 使用优化版提示词的回答 ---
🎉 欢迎加入我们的大家庭!作为新成员,你将享受到一系列丰富且贴心的福利政策,让我们一起看看吧!🌟 **健康与假期**
🏥 全面的健康保险:我们为每位员工及其直系家属提供全面的健康保险,确保你和家人的健康得到保障。
🩺 年度体检:每年一次的免费体检,帮助你及时了解自己的健康状况。
🏖️ 带薪年假:每年享有15天的带薪年假,让你有足够的时间放松和充电。
🛌 带薪病假:除了年假,还有5天的带薪病假,确保你在需要时能够安心休息。💰 **补贴与激励**
🚗 交通补贴:每月提供500元的交通补贴,减轻你的通勤负担。
🍽️ 餐饮补贴:每月还有300元的餐饮补贴,让你在忙碌的工作中也能享受美味的餐食。📚 **成长与发展**
🎓 教育培训基金:公司每年提供高达8000元的教育培训基金,支持你参加课程学习或购买专业书籍,不断提升自我。💪 **生活品质提升**
🏋️♂️ 健身优惠:公司与多家健身房合作,员工可以享受折扣价,帮助你保持良好的体态和精神状态。希望这些福利能让你感受到公司的关怀和支持。在这里,你不仅能够实现职业发展,还能享受愉快的工作生活。再次欢迎你加入我们,期待与你共创美好未来!🌈
多轮迭代:引入参考答案进行差距分析
在前面的盒子中,你扮演了主导角色,接收“AI教练”的建议并手动应用它。但是这个过程还可以进一步自动和精确化。与其让评估者给出一个模糊的“好”或“不好”的判断,一个更高级的方法是引入一个“参考答案”(Reference Answer).
这个“参考答案是你心目中最完美的理想答案,可以由人类专家撰写,也可以用一个非常详尽的提示词让最强大的模型完成。迭代优化的止标就变成了:不断修改提示词,使其生成的回答与这个"参考答案”之间的差距越来越小。
这个过程就像一个拥有精确制导系统的自修正流程:
- 设定参考答案(Set Reference Answer):首先,定义一个高质量、理想的“参考答案”。
- 生成(Generate):使用当前待优化的提示词,生成一个回答。
- 分析差距(Analyze Gap):让一个“评估者”大模型(Critic)来比较“生成的回答”和“参考答案”,并输出一份详细的“差距分析报告”,并输出一份详细的“差距分析报告”,指出两在语气、结构、内容、格式等方面的具体差异。
- 优化(Optimixe):将“差距分析报告”连同原始提示词、生成的回答一起、交给一个“优化者”大模型(Optimizer)。它的任务是根据这份报告,重写提示词,以专门解决其中指出的问题,从而缩小差距。
- 重复(Repeat):用优化后的新提示词替换旧的,然后回至,直到“评估者”认为两差距足够小,或达到最大迭代次数。
# 1. 设定参考答案
reference_answer = """
👋 欢迎加入我们的大家庭!很高兴能为你介绍我们超棒的福利政策:**🏥 健康与假期,我们为你保驾护航:**
- **全面健康保险**:覆盖你和你的家人,安心工作无烦忧。
- **年度体检**:你的健康,我们时刻关心。
- **带薪年假**:每年足足15天,去探索诗和远方吧!
- **带薪病假**:5天时间,让你安心休养,快速恢复活力。**💰 补贴与激励,为你加油打气:**
- **交通补贴**:每月500元,通勤路上更轻松。
- **餐饮补贴**:每月300元,午餐加个鸡腿!
- **教育培训基金**:每年高达8000元,投资自己,未来可期。
- **健身折扣**:与多家健身房合作,工作再忙也别忘了锻炼哦!希望这些福利能让你感受到公司的关怀!期待与你一起创造更多价值!🎉
"""# 2. 定义差距分析和优化函数
def analyze_gap(generated_response, reference):gap_analysis_prompt = f"""【角色】你是一位文本比较专家。【任务】请详细比较【生成回答】与【参考答案】之间的差距。【参考答案】{reference}---【生成回答】{generated_response}---【要求】请从语气、结构、内容细节、格式(如表情符号使用)等方面,输出一份详细的差距分析报告。如果两者几乎没有差距,请直接回答“差距很小”。"""return llm.invoke(gap_analysis_prompt)def optimize_prompt_with_gap_analysis(current_prompt, generated_response, gap_report):optimization_prompt = f"""【角色】你是一位顶级的提示词工程师。【任务】根据提供的“差距分析报告”,优化“当前提示词”,使其能够生成更接近“参考答案”的输出。---【当前提示词】{current_prompt}---【它生成的回答】{generated_response}---【差距分析报告】{gap_report}---【要求】请只返回优化后的新提示词,不要包含任何其他解释。"""return llm.invoke(optimization_prompt)# 3. 迭代优化循环
current_prompt = initial_prompt # 复用上述的initial_prompt
for i in range(3): # 最多迭代3次print(f"--- 第 {i+1} 轮迭代 ---")generated_response = llm.invoke(current_prompt.format(retrieved_text=retrieved_text))print(f"生成的回答 (部分):\\n{generated_response[:100]}...")gap_report = analyze_gap(generated_response, reference_answer)print(f"差距分析报告:\\n{gap_report}")if "差距很小" in gap_report:print("\\n评估通过,优化完成!")breakprint("\\n评估未通过,根据差距分析报告优化提示词...")current_prompt = optimize_prompt_with_gap_analysis(current_prompt, generated_response, gap_report)
else:print("\\n达到最大迭代次数,停止优化。")final_prompt_based_on_reference = current_prompt
--- 第 1 轮迭代 ---
生成的回答 (部分):\n你好,欢迎加入我们的团队!关于你提到的公司福利问题,我可以为你详细解答:1. **健康保险**:我们为所有员工及其直系家属提供全面的健康保险,确保大家在医疗方面的基本需求得到保障。2. **年...
差距分析报告:\n### 差距分析报告#### 1. 语气
- **参考答案**:语气更加热情和友好,使用了“👋 欢迎加入我们的大家庭!”和“🎉”等表情符号,营造出一种温馨和欢迎的氛围。
- **生成回答**:语气较为正式和专业,虽然也表达了欢迎,但没有使用表情符号,整体感觉稍微冷淡一些。#### 2. 结构
- **参考答案**:结构清晰,分为两个主要部分:“健康与假期”和“补贴与激励”,每个部分下有具体的福利项目,条理分明。
- **生成回答**:结构也较为清晰,但没有明确的分段标题,而是直接列出各项福利。虽然信息齐全,但不如参考答案直观。#### 3. 内容细节
- **参考答案**:- **健康与假期**:详细列出了健康保险、年度体检、带薪年假和带薪病假,并且每项福利都有简短的描述,如“安心工作无烦忧”、“去探索诗和远方吧”等。- **补贴与激励**:同样详细列出了交通补贴、餐饮补贴、教育培训基金和健身折扣,并且每项福利也有简短的描述,如“通勤路上更轻松”、“工作再忙也别忘了锻炼哦”等。
- **生成回答**:- **健康与假期**:内容与参考答案基本一致,但缺少了一些描述性的语言,如“安心工作无烦忧”、“去探索诗和远方吧”等。- **补贴与激励**:内容也与参考答案基本一致,但同样缺少了一些描述性的语言,如“通勤路上更轻松”、“工作再忙也别忘了锻炼哦”等。#### 4. 格式
- **参考答案**:使用了表情符号(👋、🎉)和Markdown格式(如**加粗**),使内容更加生动和易于阅读。
- **生成回答**:没有使用表情符号,虽然使用了Markdown格式(如**加粗**),但整体视觉效果不如参考答案丰富。### 总结
虽然两者的差距不大,但参考答案在语气、结构和格式上更为出色,能够更好地传达公司的关怀和热情。生成回答虽然内容详尽,但在表达上略显正式和缺乏情感色彩。建议在生成回答中适当增加一些描述性和情感化的语言,以及使用表情符号,以提升整体的亲和力和吸引力。
\n评估未通过,根据差距分析报告优化提示词...
--- 第 2 轮迭代 ---
生成的回答 (部分):\n欢迎加入我们的大家庭!😊 我们非常重视每位员工的健康和幸福,所以为你们准备了一系列超棒的福利计划,希望能让你在这里的工作生活更加美好和充实!首先,关于健康方面,我们提供全面的健康保险,不仅覆盖你本...
差距分析报告:\n### 差距分析报告#### 1. 语气
- **参考答案**:整体语气较为正式且热情,使用了一些积极的词汇和短语,如“超棒的福利政策”、“期待与你一起创造更多价值”等,给人一种专业而亲切的感觉。
- **生成回答**:语气更加亲切和友好,使用了更多的表情符号(如😊、😉、💖、💰、📚、💪、🌟),使文本显得更加生动和活泼。同时,语言更加口语化,如“希望能在一定程度上减轻你的生活负担”。#### 2. 结构
- **参考答案**:结构清晰,分为两个主要部分:“健康与假期”和“补贴与激励”,每个部分下有具体的福利项目,条理分明。
- **生成回答**:虽然也分为健康、休息、日常生活需求和个人成长四个部分,但没有明确的标题和项目列表,而是采用了段落形式进行描述,显得更加自然流畅。#### 3. 内容细节
- **参考答案**:- **健康与假期**:详细列出了健康保险、年度体检、带薪年假和带薪病假的具体内容。- **补贴与激励**:具体说明了交通补贴、餐饮补贴、教育培训基金和健身折扣的金额和用途。
- **生成回答**:- **健康与假期**:内容与参考答案基本一致,但增加了“直系家属”的说明,使信息更加具体。- **补贴与激励**:内容与参考答案一致,但在描述上更加详细,例如“希望能在一定程度上减轻你的生活负担”。#### 4. 格式
- **参考答案**:使用了Markdown格式,包括标题(**)、列表(-)和段落,使文本结构更加清晰。
- **生成回答**:使用了较多的表情符号,使文本更加生动,但没有使用Markdown格式,而是采用了普通的段落形式。### 总结
- **语气**:生成回答更加亲切和友好,适合用于内部沟通或非正式场合;参考答案则更加正式,适合用于官方文件或对外宣传。
- **结构**:参考答案结构更加清晰,便于快速阅读和理解;生成回答则更加自然流畅,适合阅读体验。
- **内容细节**:两者内容基本一致,但生成回答在某些细节上更加具体和详细。
- **格式**:参考答案使用了Markdown格式,结构清晰;生成回答则使用了表情符号,使文本更加生动。总体来说,两者的差距主要体现在语气、结构和格式上,内容细节基本一致。如果需要选择一个版本,可以根据具体应用场景和目标受众来决定。
\n评估未通过,根据差距分析报告优化提示词...
--- 第 3 轮迭代 ---
生成的回答 (部分):\n# 欢迎加入我们的大家庭!🎉亲爱的同事们,你们好!🌟 今天,我想为大家详细介绍我们公司的福利政策,希望能帮助大家更好地了解和利用这些福利,让工作和生活更加美好!😊## 健康保障 🏥- **...
差距分析报告:\n### 差距分析报告#### 1. 语气
- **参考答案**:整体语气较为正式且亲切,使用了一些简单的表情符号(如:👋、🎉)来增加友好感。
- **生成回答**:语气同样正式且亲切,但使用了更多的表情符号(如:🎉、🌟、😊、🏥、🌴、🍽️、🚀、💪、🌈),使整个文本看起来更加生动和活泼。#### 2. 结构
- **参考答案**:- 开头:欢迎语- 主体:分两个大块(健康与假期、补贴与激励)- 结尾:总结和祝福
- **生成回答**:- 开头:欢迎语- 主体:分五个小节(健康保障、休假政策、生活补贴、成长与发展、健身优惠)- 结尾:总结和祝福**差异**:生成回答的结构更为细化,将“补贴与激励”拆分为“生活补贴”和“成长与发展”,使内容更加清晰和条理化。#### 3. 内容细节
- **参考答案**:- **健康与假期**:提到全面健康保险、年度体检、带薪年假、带薪病假。- **补贴与激励**:提到交通补贴、餐饮补贴、教育培训基金、健身折扣。
- **生成回答**:- **健康保障**:提到全面健康保险、年度体检。- **休假政策**:提到带薪年假、带薪病假。- **生活补贴**:提到交通补贴、餐饮补贴。- **成长与发展**:提到教育培训基金。- **健身优惠**:提到健身房合作。**差异**:生成回答在内容上与参考答案基本一致,但在描述上更加详细,例如“全面健康保险”中提到“每位员工及直系家属”,“年度体检”中提到“预防疾病的发生”。#### 4. 格式
- **参考答案**:- 使用了简单的Markdown格式,如粗体(**)和项目符号(-)。- 表达简洁,没有过多的装饰性元素。
- **生成回答**:- 使用了更丰富的Markdown格式,如标题(#、##)、粗体(**)、项目符号(-)。- 使用了更多的表情符号,增加了视觉效果和情感表达。**差异**:生成回答在格式上更加丰富和多样化,使用了更多的标题和表情符号,使文本更具吸引力和亲和力。### 总结
总体来看,生成回答在语气、结构、内容细节和格式上都与参考答案有相似之处,但也有一些显著的差异。生成回答通过更丰富的表情符号和更详细的描述,使内容更加生动和亲切。结构上,生成回答更为细化,使信息呈现更加条理化。因此,虽然两者在核心内容上基本一致,但在表达方式和细节处理上,生成回答显得更加细致和贴心。
\n评估未通过,根据差距分析报告优化提示词...
\n达到最大迭代次数,停止优化。
这个自动化的迭代过程展示了Meta Prompting的址效果。它将从你繁琐的手动调中解放出来,让模型自己去探索和发现最佳的表达方式,也为更复杂的**AI自我改进(Self-Improvident)系统的设计提供了基础思路。
效果评测:量化你的优化成果
当你有多个版本的提示词(例如,初始版本 vs 单次优化版 vs 多轮迭代最终版),你如何客观地证明哪个更好呢?除了直观感受,更科学的方法是进行量化评估。
你可以再次利用大模型,让它扮演一个**“评分员”(Grader)**的角色,根据一系列标准对不同提示词生成的回答进行打分。
例如,你可以定义一个评分标准:
- 友好度(Friendliness):1-5分
- 结构清晰度(Clarity):1-5分
- 信息准确性(Accuracy):1-5分
- 然后,构建一个“Grader Prompt”,将评分标准和待评估的回答一起交给大模型,让它输出一个结构化的评分结果(如JSON)。
import json
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pandas as pd# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 三个质量差异明显的典型回答样本
# 差:只是简单罗列信息,没有结构和感情
poor_response = "公司福利:健康保险,家属可用。15天年假,5天病假。交通补贴500,餐饮补贴300。培训基金8000。健身房有折扣。"# 中:有基本结构和分类,但语气平淡
medium_response = """
公司福利:
1. 💦健康和假期:- 健康保险(含家属)- 年度体检- 15天年假和5天病假
2. 💰补贴和激励:- 每月500交通补贴和300餐饮补贴- 8000元/年的教育培训基金- 合作健身房折扣
"""# 优:结构清晰、语气友好、视觉吸引力强(直接使用我们的参考答案)
good_response = reference_answer # 设计更细化的评估维度
def grade_response_detailed(response_to_grade):grader_prompt = f"""【角色】你是一位经验丰富的内部沟通和员工体验评测官。【任务】请根据以下四个维度,对提供的“公司福利介绍”文本进行1-5分的量化评分。【评分维度】1. **欢迎语气 (welcoming_tone)**: 1分表示语气冰冷生硬,5分表示非常热情、有感染力。2. **内容结构化 (structuring)**: 1分表示信息混乱无序,5分表示分类清晰、逻辑性强。3. **视觉吸引力 (visual_appeal)**: 1分表示枯燥乏味,5分表示善用表情符号、粗体等元素,非常吸引眼球。4. **信息完整性 (completeness)**: 1分表示信息缺失严重,5分表示关键福利信息完整无缺。【待评估文本】{response_to_grade}---【输出要求】请严格以JSON格式返回你的评分,不要包含任何解释。例如:{{"welcoming_tone": 5, "structuring": 4, "visual_appeal": 5, "completeness": 5}}"""try:raw_output = llm.invoke(grader_prompt)# 提取JSON部分json_str = raw_output[raw_output.find('{'):raw_output.rfind('}')+1]return json.loads(json_str)except (json.JSONDecodeError, IndexError):# 容错处理,在无法解析时返回一个默认的低分return {{"welcoming_tone": 1, "structuring": 1, "visual_appeal": 1, "completeness": 1}}# 对三个典型样本进行评分
# 注意:这里的 key 将作为图表中的标签,我们使用新视觉方案中提供的名称
scores = {"Original Answer": grade_response_detailed(poor_response),"Single Iteration Optimize": grade_response_detailed(medium_response),"Multi-turn Iteration Optimize": grade_response_detailed(good_response)
}# 将 scores 转换为 DataFrame
df = pd.DataFrame(scores)
df = df.reset_index().rename(columns={'index': 'Dim'})
df_long = df.melt(id_vars='Dim', var_name='Version', value_name='Score')# --- 单幅分组柱状图 ---
plt.figure(figsize=(10, 6))
ax = sns.barplot(data=df_long,x="Dim", # 每个维度一组y="Score",hue="Version", # 3 个版本并排palette="viridis"
)# 为每根柱子添加数值标签
for p in ax.patches:height = p.get_height()if height == 0: # 跳过高度为 0 的占位 patchcontinueax.annotate(f"{height}",(p.get_x() + p.get_width() / 2., height),ha='center', va='center',xytext=(0, 5),textcoords='offset points',fontsize=11)# 轴和标题美化
ax.set_ylim(0, 6)
ax.set_ylabel('Score (1-5)', fontsize=12)
ax.set_xlabel('') # 隐藏 X 轴标题
ax.set_title('Evaluation', fontsize=20)
ax.tick_params(axis='x', labelsize=12)plt.legend() # 显示图例
plt.tight_layout()
plt.show()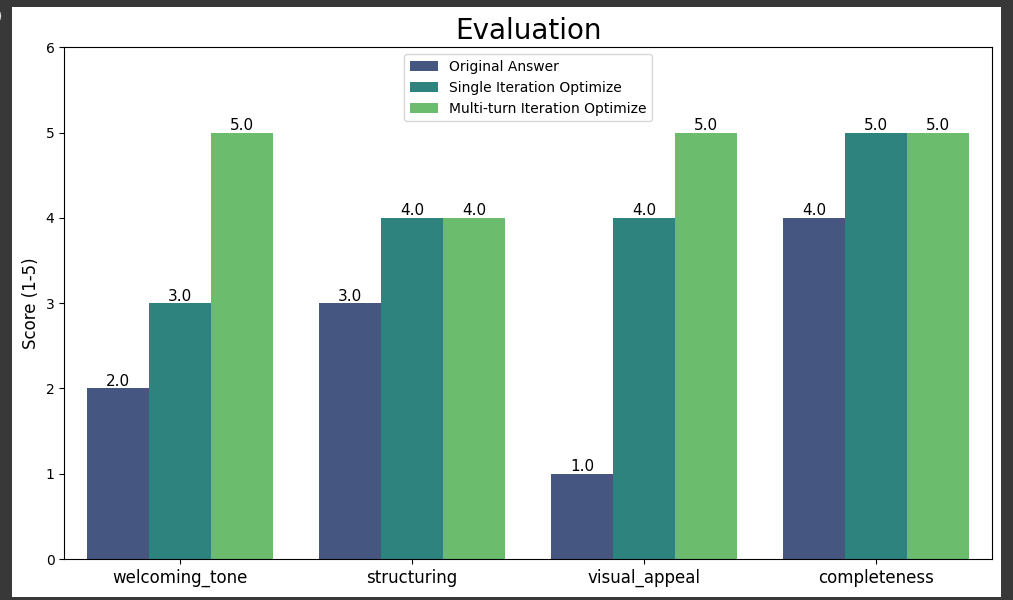
你可以看到,每次迭代的大模型的回复效果都有不同程度的提升。通过这种量化评估,你不仅能直观地看到每次优化带来的提升,还能将“好”或“不好”这种模糊的感觉,转化为清晰、可衡量的数据。这为你提供了一种科学的方法来验证和迭代的提示词策略,确保每一步改进都有据可依,最终交付出真正高质量的用户体验。
推理大模型
前面所讲的提示词技巧和提示词框架可以广泛适用于能用大模型(如Qwen2.5-max、GPT-4、DeepSeek- V3),这类模型面向通用对话、知识问答、文本生成等广泛的场景。除了通用大模型,目前还有一类专门为“推理”设计的大模型———推理大模型。
什么是推理大模型?
from openai import OpenAI
import osdef reasoning_model_response(user_prompt, system_prompt="你是一个编程助手。", model="qwen3-235b-a22b-thinking-2507"):"""prompt: 用户输入的提示词model: 此处以 qwen3-235b-a22b-thinking-2507 为例,可按需更换推理模型名称,如:deepseek-r1"""# 初始化客户端client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),base_url=os.getenv("BASE_URL"))# 初始化状态变量is_answering = False# 发起流式请求completion = client.chat.completions.create(model=model,# messages=[{"role": "user", "content": prompt}],messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}],stream=True,)# 打印思考过程标题print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")# 处理流式响应for chunk in completion:if chunk.choices:delta = chunk.choices[0].deltaif hasattr(delta, 'reasoning_content') and delta.reasoning_content is not None:# 处理思考过程内容print(delta.reasoning_content, end='', flush=True)else:# 切换到答案输出模式if delta.content != "" and not is_answering:print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")is_answering = True# 处理答案内容if delta.content:print(delta.content, end='', flush=True)
reasoning_model_response(user_prompt="你是谁?")
====================思考过程====================好的,用户问“你是谁?”,我需要先确定他们想了解什么。作为编程助手,我应该明确介绍自己的身份和功能。首先,用户可能想知道我的角色,是AI还是人类。需要说明我是通义千问,阿里巴巴集团旗下的AI模型,专门帮助编程相关的问题。接下来,用户可能有潜在需求,比如需要帮助解决代码问题,或者想测试我的能力。要强调我能提供代码示例、调试帮助、解释概念等,这样用户知道可以提出具体问题。还要考虑用户可能不熟悉技术术语,所以用简单易懂的语言,避免太专业的词汇。比如“生成代码”、“解释错误”这些比较直观。另外,可能需要引导用户给出具体问题,这样能更好地帮助他们。所以结尾可以邀请他们提出具体需求,促进进一步互动。检查有没有遗漏的重要信息,比如支持的编程语言,但可能不需要一开始就全列出来,等用户问再详细说明。保持回答简洁,重点突出。最后,确保语气友好,专业但不生硬。用“随时为你提供帮助”这样的表达,显得亲切。
====================完整回复====================你好!我是Qwen,是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。作为你的编程助手,我擅长:- **代码生成**:根据需求生成Python、Java、C++等主流语言的代码
- **错误调试**:帮你分析报错信息并提供解决方案
- **技术解释**:用通俗易懂的方式讲解算法、框架等技术概念
- **最佳实践**:提供符合行业规范的代码优化建议无论是写脚本、解算法题、排查bug,还是学习新技术,都可以随时告诉我具体需求。比如:
"用Python写个快速排序"
"解释React Hooks的工作原理"
"这个Java空指针异常怎么解决?"需要什么帮助呢? 😊
通过例子可以看到,推理模型相较于通用大模型多出了**“思考过程”**,就像解数学题时有人会先在草稿纸上一步步推导,而不是直接报答案,减少模型出现“拍脑袋”的错误,同时在分步思考过程中,如果某一步骤发现矛盾,还可以回头检查并重新调整思路,展示推理步骤还可以方便人们理解,顺着模型思考路线验证逻辑。
相较于通用大模型,推理大模型通常在解决复杂问题时更可靠,比如在数学解题、代码编写、法律案件分析等需要严谨推理的场景。并不是说推理模型一定更好,两种模型都有各自的应用场景,下表从一些典型维度对这两类模型进行了对比:
| 维度 | 推理模型 | 通用模型 |
|---|---|---|
| 设计目标 | 专注于逻辑推理、多步问题求解、数学计算等需要深度分析的任务 | 面向通用对话、知识问答、文本生成等广泛场景 |
| 训练数据侧重 | 大量数学题解、代码逻辑、科学推理数据集增强推理能力 | 覆盖百科、文学、对话等多领域海量数据 |
| 典型输出特征 | 输出包含完整推导步骤,注重逻辑链条的完整性 | 输出简洁直接,侧重结果的自然语言表达 |
| 响应速度 | 复杂推理任务响应较慢(需多步计算) | 常规任务响应更快(单步生成为主) |
推理模型还是通用模型?如何选择?以下是一些推荐
- 明确的通用任务:对于明确定义的问题,通用模型一般能够很好地处理
- 复杂任务:对于非常复杂的任务,且需要给出相对更精确和可靠的答案,推荐使用推理模型。这些任务可能有:
- 模糊的任务:任务相关信息很少,你无法提供模型相对明确的指引
- 大海捞针:传递大量非结构化数据,提取最相关的信息或寻找关联/差别
- 调试和改进代码:需要审查并进一步调试、改进大量代码
- 速度和成本:一般来说推理模型的推理时间较长,如果你对于时间和成本敏感,且任务复杂度不高,通用模型可能是更好的选择。
当然你可以在你的应用结合使用两种模型:使用推理模型完成Agent的规划和决策,使用通用模型完成任务执行。
适用于推理大模型的提示词技巧
- 技巧一:保持任务提示简洁温格,提供足够的背景信息
虽然推理模型能力很强,但却不能“看穿人的想法”,你需要保持简洁清晰,从而让推理大模型专注于核心任务
bad_prompt="""
def example(a):b = []for i in range(len(a)):b.append(a[i]*2)return sum(b)
"""reasoning_model_response(user_prompt=bad_prompt)

通过如上示例,可以看到就算你只给推理大模型一段代码,它还是能够通过一系列的推理给出很丰富的答案,但返回推理中可能包含了很多你不关注的信息,你可以尝试明确任务目标,从而获得更有针对性的建议:
prompt_A="""
如下 python 代码有什么问题?怎么优化?
def example(a):b = []for i in range(len(a)):b.append(a[i]*2)return sum(b)
"""reasoning_model_response(user_prompt=prompt_A)
同样地,你还可以在结合西班牙队4.2限定角色和受众、4.3规定输出格式等技巧进一步限定范围,确保结果符合你的预期。
同时,如果提示词比较复杂,你可以通过分隔符帮助模型理解你的意图。
prompt_B="""
<audience>初级Python开发者</audience><task>函数性能优化,优化code中的代码。</task><format>
如有多种优化方案请按照如下格式进行输出:
【优化方案X】
问题描述:[描述]
优化方案:[描述]
示例代码:[代码块]
</format><code>
def example(a):b = []for i in range(len(a)):b.append(a[i]*2)return sum(b)
</code>
"""reasoning_model_response(user_prompt=prompt_B)
-
技巧二:避免思维链提示
本节中你了解到通过思维链(COT)技术让大模型深入思考提升回复效果。一般来说,你无需提示推理模型“逐步思考”或“解释你的推理”,因为它们本身会进行深入的思考,你的提示可能反而限制推理模型的发挥。除非你需要大模型严格按照固定的思路去推理,这种情况少发生。 -
技巧三:根据模型响应调整提示词
推理模型因其回复形式(包含思考过程),天然适合你分析它的思考推理结论的过程,便于你调整提示词。因此,你不需要纠结提示词是否足够完善,只需要不断与推理模型对话,过程中补充信息,完善提示词即可。比如当你的描述太抽象或无法准确描述时,你可以用上述提到“增加示例”的技巧来明确这些明确这些信息,这些示例有时可以从与模型的对话历史中挑选出来。这个过程可以是重复多次,不断尝试调整提示,让模型不断推理迭代,直到符合你的要求。 -
技巧四:让推理模型成为你的“提示词教练”
学习了Meta Prompting,即让大模型帮助你优化提示词。那么,哪种模型最适合扮演这位“教练”的角色呢?
答案是推理模型。
由于推理模型擅长分步思考和逻辑推导,它们在分析一个提示词的优缺点,并系统性地提出改进建议方面表现得尤为出色。它们不仅能给你一个更好的提示词,还能清晰展示出“为什么”这样改会更好,让你在优化过程中也能学到提示词工程的精髓。
# 我们将复用 4.6 节中的公司福利场景
retrieved_text = """
关于公司的福利政策,我们提供全面的健康保险,覆盖员工及其直系家属。
年度体检是标配。此外,每年有15天的带薪年假,以及5天的带薪病假。
我们还提供每月500元的交通补贴和300元的餐饮补贴。
为了鼓励员工成长,公司设有每年高达8000元的教育培训基金,员工可以申请用于课程学习或购买专业书籍。
健身方面,公司与多家健身房有合作,员工可享受折扣价。
"""# 初始的、比较简单的提示词
initial_prompt = f"""
根据以下信息,回答新员工关于公司福利的问题。【参考信息】
{retrieved_text}
"""# 假设这是通用模型的、不甚理想的输出
initial_response = """
我们公司提供全面的健康保险,覆盖员工及其家属。每年有15天带薪年假和5天病假。还有每月500元交通补贴和300元餐饮补贴。公司提供8000元的年度教育基金,并与健身房有合作折扣。
"""# 构建我们的 Meta Prompt,请求推理模型帮助优化
meta_prompt_for_reasoning = f"""
我正在为公司的新员工答疑机器人优化一个提示词,目标是回答关于“公司福利”的问题。这是我的第一个尝试:
---\n{initial_prompt}\n---这是它生成的输出:
---\n{initial_response}\n---这个输出不够好。我希望机器人的回答更具吸引力,并且结构清晰,能让新员工快速抓住重点。具体要求如下:
1. **语气**:友好、热情,有欢迎新同事的感觉。
2. **结构**:使用清晰的要点(比如用表情符号开头的列表)来组织内容。
3. **内容**:将福利分为几个类别,如“健康与假期”、“补贴与激励”等。请你扮演一位提示词工程专家,帮我重写这个提示词,以实现上述目标。
请在最终答案中,只给出优化后的提示词本身,不要包含其他解释性文字。
"""# 使用推理模型来获取优化建议
reasoning_model_response(user_prompt=meta_prompt_for_reasoning, system_prompt="你是一位顶级的提示词工程专家。")
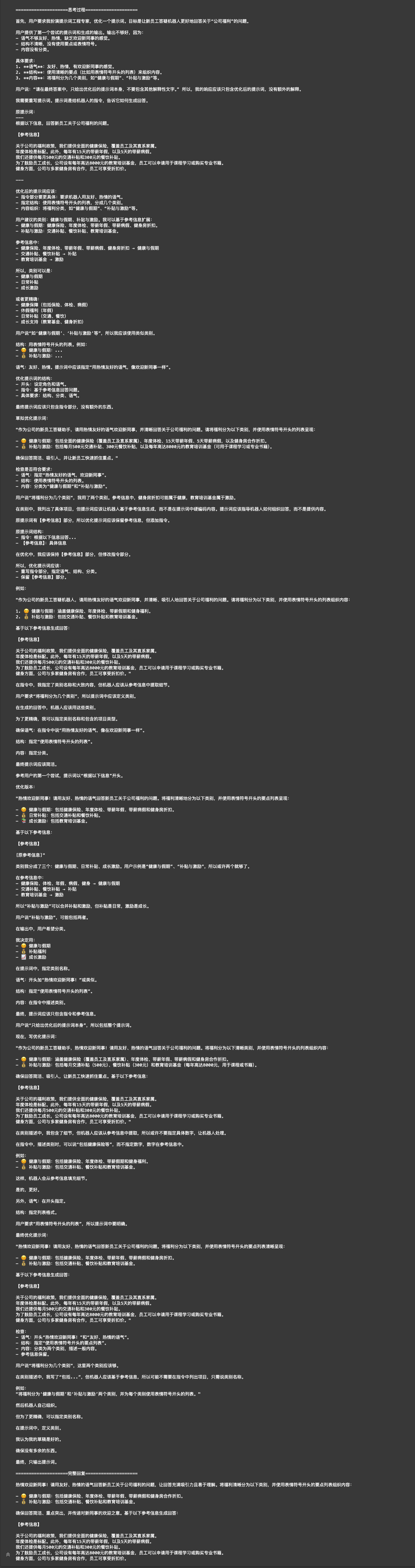
通过上面的示例,你可以清晰地看到推理模型是如何一步步分析原始提示词的不足,并结合我们提出的要求(友好的语气、清晰的结构、生动的内容等),最终构建出一个结构更加严谨、意图更加明确的优化版提示词。
这充分展示了将合适的工具用在合适的任务上重要性,这背后是任务复杂性与**执行成本(时间与费用)**之间的权衡:
- 通用模型(非推理模型):
- 优势:执行速度快,成本较低。
- 适用场景:适合执行相对直接、明确的任务,例如根据一个已经优化好的提示词进行信息提取、格式转换或简单问答。
- 推理模型:
- 优势:擅长处理复杂
- 模糊或需要深度逻辑推导的任务
- 适用场景:更适合执行“元任务”(meta-task),例如分析和优化另一个任务(即提示词本身)的定义、进行复杂的规划或调试代码
- 成本:由于需要进行多步思考,其响应时间通常更长,成本也相对更高。