OCR 后结构化处理最佳实践
随着大语言模型(LLM)在办公、科研、企业业务等领域的深度落地,“高质量数据输入决定模型性能上限” 已成为行业共识。当前,LLM 在 RAG(检索增强生成)、Agent 智能体、企业知识库构建等场景中,需频繁处理 PDF、Word、扫描件等各类文档,但传统 OCR 工具仅能提取文本,无法解决文档中公式、复杂表格、手写批注等元素的结构化问题,导致 “数据输入质量低” 成为制约 LLM 落地效果的关键瓶颈。
与此同时,真实业务场景对文档解析的需求愈发复杂 —— 从学术论文的公式与嵌套表格,到企业财报的多维度数据排版,再到政府公文的规范格式与手写批注,均要求解析工具具备 “全要素识别 + 结构化输出 + 适配下游模型” 的综合能力,这也推动了 OCR 后结构化处理技术的快速发展。
OCR 后结构化处理,是指在传统 OCR(光学字符识别)提取文本的基础上,进一步对文档中的非结构化元素(如表格、公式、列表、手写体、图表注释等)进行逻辑梳理、格式标准化与信息分类,最终将整份文档转换为机器可理解、可直接用于 LLM 输入的结构化格式(如 Markdown、JSON)的技术过程。
其核心目标并非简单 “识别文字”,而是实现 “文档语义理解”—— 即还原文档的阅读顺序、解析复杂元素的内在逻辑(如跨行合并表格的单元格关联、公式的符号与运算关系)、保留关键信息的位置溯源,从而为下游 LLM 任务(如文档问答、数据统计、知识提炼)提供高质量的 “数据原料”,解决传统 OCR“提取乱序、信息缺失、无法适配 AI” 的痛点。
案例数据
为验证 OCR 后结构化处理工具的实际效果,我们针对当前主流开源模型与商用工具开展了多维度测评,核心数据与结论如下:
1. 开源模型测评范围与局限
本次调研实测了 7 类主流开源文档解析模型,覆盖不同细分场景,但均存在明显能力边界:
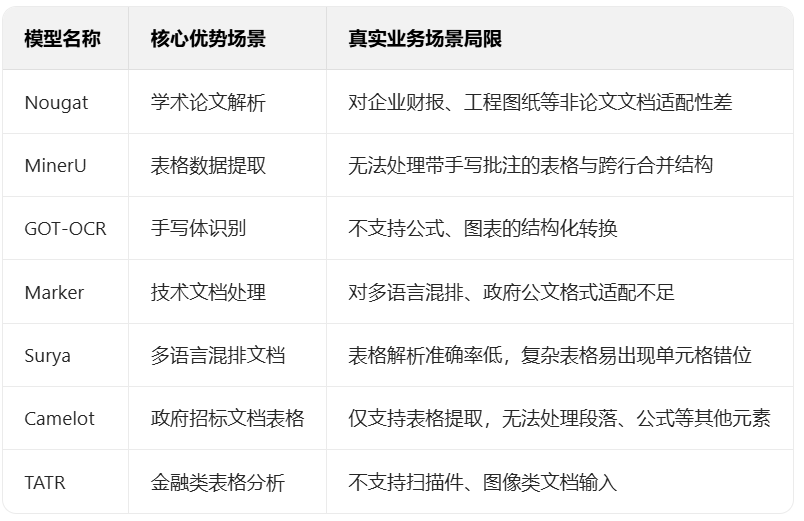
2. 商用工具(TextIn ParseX)实测数据
基于 “标题、段落、文本、阅读顺序、公式、表格”6 个核心维度,针对 20 余种真实文档样本(涵盖 PDF 扫描件、图像文件、电子文档,内容包含印刷体 + 手写体、中英文混排,场景覆盖学术论文、商业报告、教育试卷、政府公文、工程图纸)开展定量测评,TextIn ParseX 表现如下:
处理效率:100 页文档结构化处理仅需 1.5 秒,远超开源模型平均 30-60 秒 / 100 页的速度;
核心能力准确率:表格(含跨行合并、嵌套表格)识别准确率 98%+,段落与阅读顺序还原准确率 99%+,手写体识别准确率 95%+;
格式适配性:一次性支持 PDF/Word/DOCX/HTML/JPG/PNG 等 6 类格式输入,无需提前转换;
下游适配性:输出的 Markdown/JSON 格式可直接对接 LLM,无需二次处理,下游模型调用效率提升 40%。
核心优势
1. 全要素识别能力:覆盖文档所有信息类型
需支持有线 / 无线表格、章节标题、列表、公式、手写体、扫描件等全类型元素的识别与结构化,无需用户分多次处理不同元素。例如,教育试卷中的 “印刷体题目 + 手写答题内容 + 内嵌公式” 可一次性解析,避免信息割裂。
2. 复杂表格解析能力:突破结构化核心难点
针对真实场景中高频出现的跨行合并表格、嵌套表格、带注释表格,需具备专属解析算法,无需手动调整参数即可精准还原表格结构。同时需保证处理效率,如 100 页含复杂表格的文档可在 1.5 秒内完成解析,满足批量处理需求。
3. 灵活输入输出能力:适配多场景使用需求
输入端:需支持在线上传(小批量处理)、API 调用(实时响应)、本地部署(企业数据安全需求)三种模式,且单次可处理万页以上大规模数据,覆盖从个人办公到企业级业务的全场景;
输出端:默认生成 Markdown/JSON 等大模型友好格式,无需额外格式转换,直接衔接 RAG、知识库构建等下游任务,简化工作流。
4. 内容溯源与交互能力:保障信息准确性与易用性
溯源功能:提取的每段内容需关联原文位置,用户校验时可直接跳转至原文对应处,尤其适用于长文档(如数百页合同)的准确性核查;
交互功能:支持在工具内直接与文档进行问答交互(如 “提取表格中 2023 年 Q4 的营收数据”),无需手动翻阅即可快速获取特定信息,降低使用门槛。
5. 多格式兼容能力:降低操作成本
无需用户提前转换文档格式,直接支持 PDF、Word、DOCX、HTML、JPG、PNG 等常见格式输入,工具自动适配解析,避免因格式不兼容导致的重复操作。
独特价值
OCR 后结构化处理的核心价值,并非 “替代传统 OCR”,而是通过 “语义级结构化” 打通 “文档信息” 与 “LLM 应用” 之间的断层,其独特价值体现在三个层面:
1. 提升 LLM 落地效果:从 “能用” 到 “好用”
传统 OCR 提取的乱序文本,会导致 LLM 理解偏差(如表格数据错位、公式含义误解);而结构化处理后的数据,能让 LLM 精准把握文档逻辑与关键信息,使 RAG 问答准确率提升 30%-50%,企业知识库的知识检索效率提升 60% 以上。
2. 降低企业人力成本:从 “手动处理” 到 “自动化”
以企业处理 500 万页财报文档为例,传统方式需人工校正 OCR 结果与表格结构,耗时约 30 天、投入 10 人团队;使用 TextIn ParseX 等结构化工具,3 天即可完成全量处理,人力成本降低 90%,且避免了人工操作的误差。
3. 保障业务可持续性:从 “一次性工具” 到 “长期支撑”
优质的结构化工具具备持续迭代能力,可随业务场景拓展(如新增工程图纸、医疗报告解析需求)更新算法,同时支持本地部署保障数据安全,成为企业构建 AI 业务体系的 “长期数据预处理引擎”,而非仅能处理单一场景的 “一次性工具”。
立即体验 Textin文档解析![]() https://cc.co/16YSWm
https://cc.co/16YSWm