性能分析工具的使用
1、perf
使用perf监测存储类型性能测试,
perf report 可视化查看record采集的性能测试文件的结果
使用perf list命令查看可用事件
2、numastat
3、iostat
4、blktrace
5、sar
1、perf
dnf install -y perf //安装perf
使用perf监测存储类型性能测试,
perf record -e cpu-clock,context-switches -g bash ./vdbench -f examples/filesys/create_files -jn //执行vdbench,使用perf来检测cpu占用情况以及线程调度
| 参数 | 类型 | 作用说明 |
|---|---|---|
-e cpu-clock,context-switches | 事件选择 | 指定要追踪的 2 个核心性能事件: 1. cpu-clock:CPU 时钟周期事件(反映 CPU 占用情况);2. context-switches:进程上下文切换事件(反映进程 / 线程调度频繁度)。 |
-g | 调用栈记录 | 开启 “调用栈追踪”,记录每个性能事件对应的函数调用链(如 “哪个函数触发了上下文切换”),是后续分析 “性能瓶颈在哪行代码” 的关键。 |
bash ./vdbench ... | 目标进程 | 指定 perf 追踪的目标:通过 bash 启动 vdbench 压测命令(-f 指定压测配置文件,-jn 启用 JSON 输出 + 不清理临时文件)。→ 注:用 bash 启动而非直接执行 ./vdbench,是为了让 perf 追踪到 Vdbench 及其子进程(如 slave 进程)的完整调用链。 |
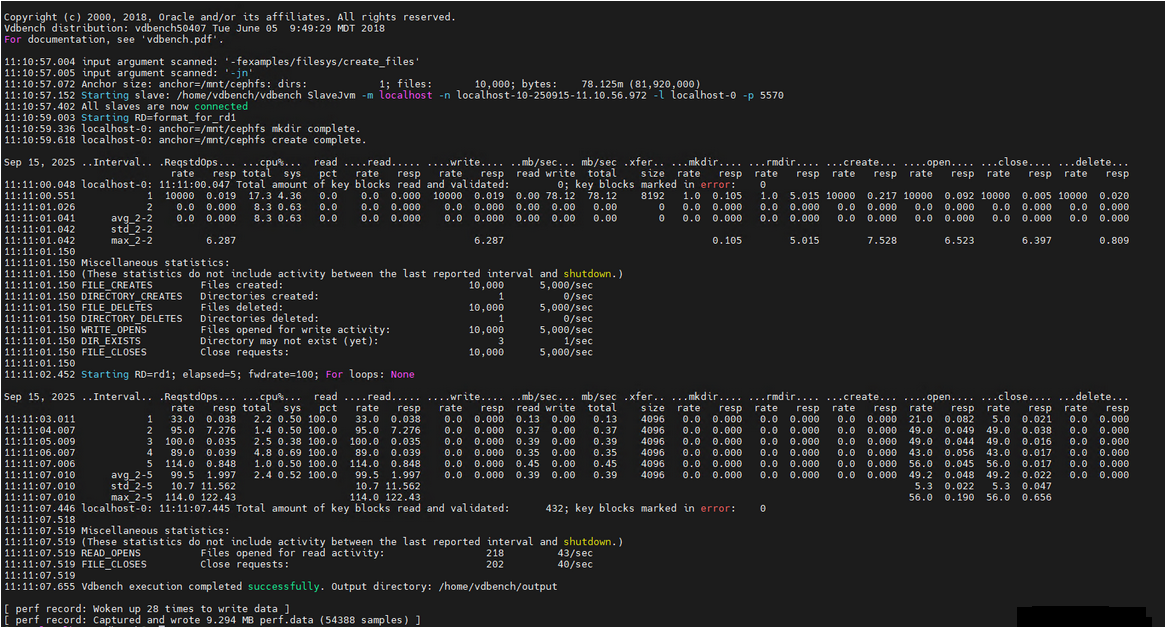
结果解析:
结合 Vdbench 负载和 perf 记录结果,可初步判断当前系统(Ceph 文件系统)的性能特征:
1、CPU 压力中等:cpu-clock 事件样本数较多,但 Vdbench 日志中 cpu% total 最高仅 17.3%(无满负载),说明 CPU 未成为瓶颈;
2、上下文切换频繁:perf 唤醒 28 次,样本数 5.4 万,结合 Vdbench 多线程(slave 进程)特性,推测 “进程 / 线程调度” 是潜在关注点(需用 perf report 确认是否有异常切换);
3、数据有效性高:Vdbench 压测成功、perf 样本数充足(5.4 万),后续可通过 perf report 精准定位 “文件创建 / 读写过程中的性能热点”(如 Ceph 客户端的 I/O 延迟是否由某函数导致)。
perf report 可视化查看record采集的性能测试文件的结果
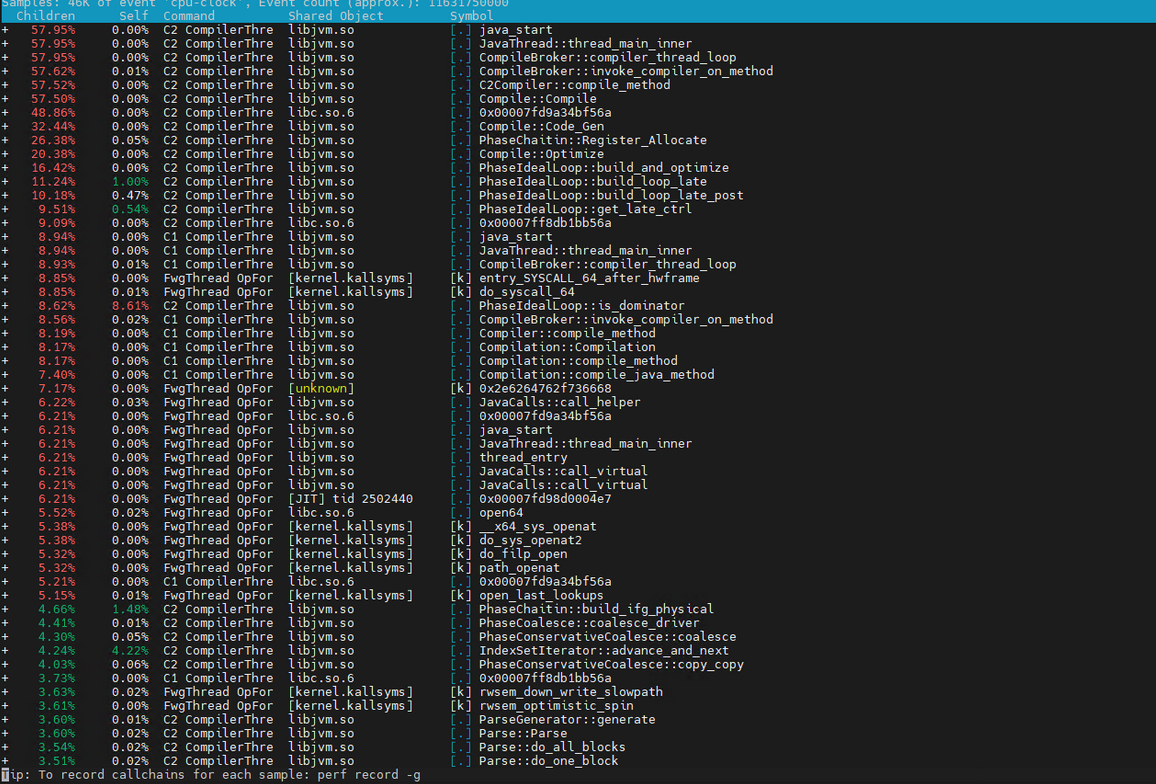
| 列名 | 描述 |
|---|---|
self | 该函数 / 模块消耗的事件占比(核心指标,占比越高,性能影响越大) |
Command | 对应的进程名(如 my_program、kernel) |
Shared Object | 函数所在的二进制文件(如 /usr/bin/my_program、/lib/modules/xxx/kernel/kernel) |
Symbol | 函数名(如 main、malloc、sys_open,内核函数会带 kallsyms 标记) |
使用perf list命令查看可用事件
perf list 可以列出对应的性能分析场景;
常见的性能事件:
①硬件事件
1.cache-references:缓存引用的次数。
2.cache-misses:缓存未命中的次数。
3.cycles: CPU 周期总数。
4.instructions:执行的指令总数。
5.branches:分支指令的总数。
6.branch-misses:分支预测失败的次数。
②软件事件
1.page-faults:页面错误的次数。
2.context-switches:上下文切换的次数。
3.cpu-migrations:进程迁移到不同 CPU 核心的次数。
4.faults:所有类型的错误。
③其他事件
1.syscalls:系统调用的次数。
2.task-clock:任务的总运行时间。
3.softirq:软中断的次数。
如perf list | grep cycle

2、numastat
安装numastat,dnf install -y numastat;
查看当前NUMA节点的内存使用情况 numastat -m
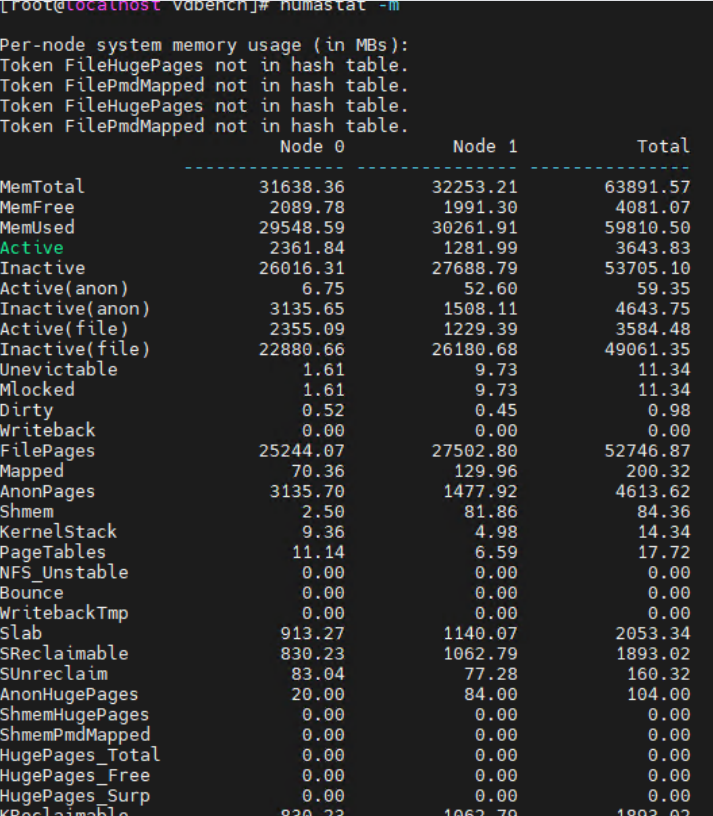
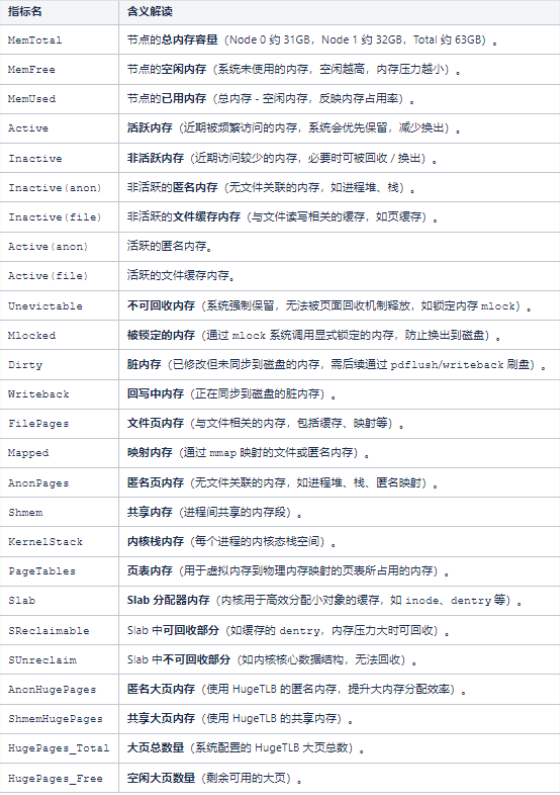
通过以下脚本进行numastat性能检测,监测vdbench时性能,分别保存vdbench和numastat的结果。
#!/bin/bash# 配置参数
VDBENCH_SCRIPT="examples/filesys/create_files" # Vdbench测试脚本路径
OUTPUT_DIR="vdbench_numa_results" # 结果输出目录
INTERVAL=5 # 监控间隔(秒)
VDBENCH_ARGS="-jn" # Vdbench额外参数# 创建输出目录
mkdir -p "$OUTPUT_DIR"
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
NUMA_LOG="$OUTPUT_DIR/numa_stats_$TIMESTAMP.log"
VDBENCH_LOG="$OUTPUT_DIR/vdbench_output_$TIMESTAMP.log"# 打印开始信息
echo "===== Vdbench 测试与 NUMA 监控开始 ====="
echo "测试脚本: $VDBENCH_SCRIPT"
echo "监控间隔: $INTERVAL 秒"
echo "结果保存至: $OUTPUT_DIR"
echo "开始时间: $(date)"
echo "======================================"
echo ""# 启动 Vdbench 测试(后台运行)
echo "启动 Vdbench 测试..."
./vdbench -f "$VDBENCH_SCRIPT" $VDBENCH_ARGS > "$VDBENCH_LOG" 2>&1 &
VDBENCH_PID=$!# 等待 Vdbench 初始化
sleep 2# 检查 Vdbench 是否正常启动
if ! ps -p $VDBENCH_PID &> /dev/null; then
echo "错误:Vdbench 启动失败,请查看日志 $VDBENCH_LOG"
exit 1
fi# 记录 NUMA 监控头部信息
echo "===== NUMA 性能监控日志 - 开始于 $(date) =====" > "$NUMA_LOG"
echo "监控间隔: $INTERVAL 秒" >> "$NUMA_LOG"
echo "Vdbench 进程 PID: $VDBENCH_PID" >> "$NUMA_LOG"
echo "==========================================" >> "$NUMA_LOG"
echo "" >> "$NUMA_LOG"# 循环监控 NUMA 状态,直到 Vdbench 结束
echo "开始 NUMA 监控(每 $INTERVAL 秒一次)..."
echo "按 Ctrl+C 可强制终止测试和监控"while ps -p $VDBENCH_PID &> /dev/null; do
# 记录当前时间
echo "----- 监控时间: $(date) -----" >> "$NUMA_LOG"
# 记录 numastat 基本内存统计
echo "=== numastat 内存使用统计 ===" >> "$NUMA_LOG"
numastat -m >> "$NUMA_LOG" 2>&1
# 记录 numastat 进程内存分布(可选,针对Vdbench进程)
echo "=== Vdbench 进程内存分布 ===" >> "$NUMA_LOG"
numastat -p $VDBENCH_PID >> "$NUMA_LOG" 2>&1
echo "" >> "$NUMA_LOG"
# 等待指定间隔
sleep $INTERVAL
done# 测试结束处理
echo ""
echo "===== 测试与监控结束 ====="
echo "Vdbench 测试已完成"
echo "NUMA 监控日志: $NUMA_LOG"
echo "Vdbench 输出日志: $VDBENCH_LOG"
echo "结束时间: $(date)"
结果查看:
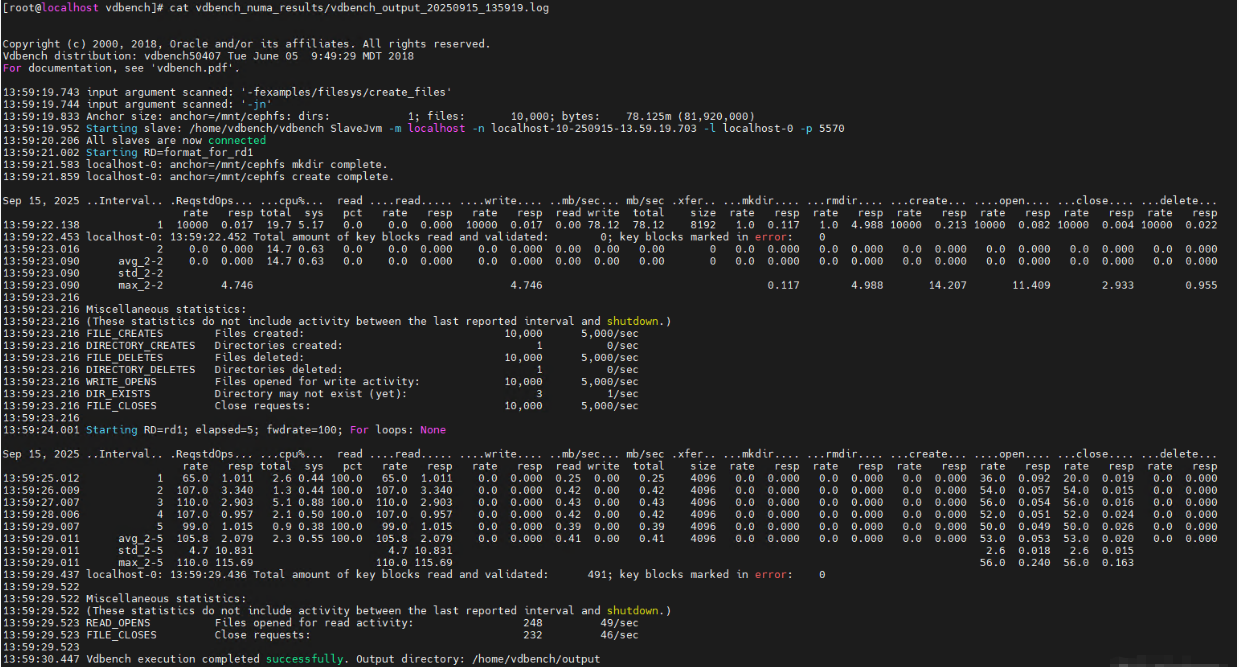
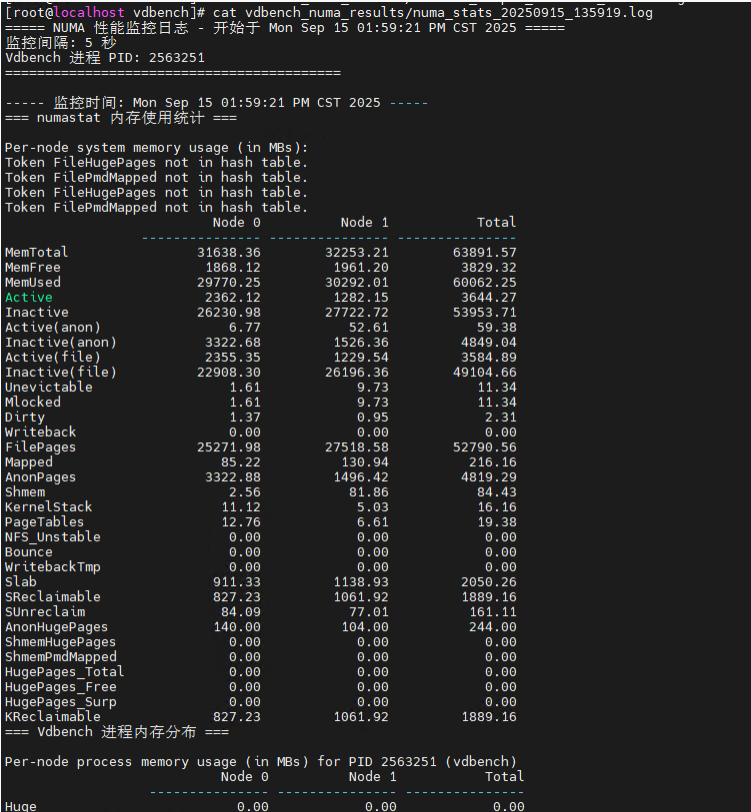
3、iostat
iostat监测cpu使用率以及磁盘io信息。
iostat-x 1
(对象存储)
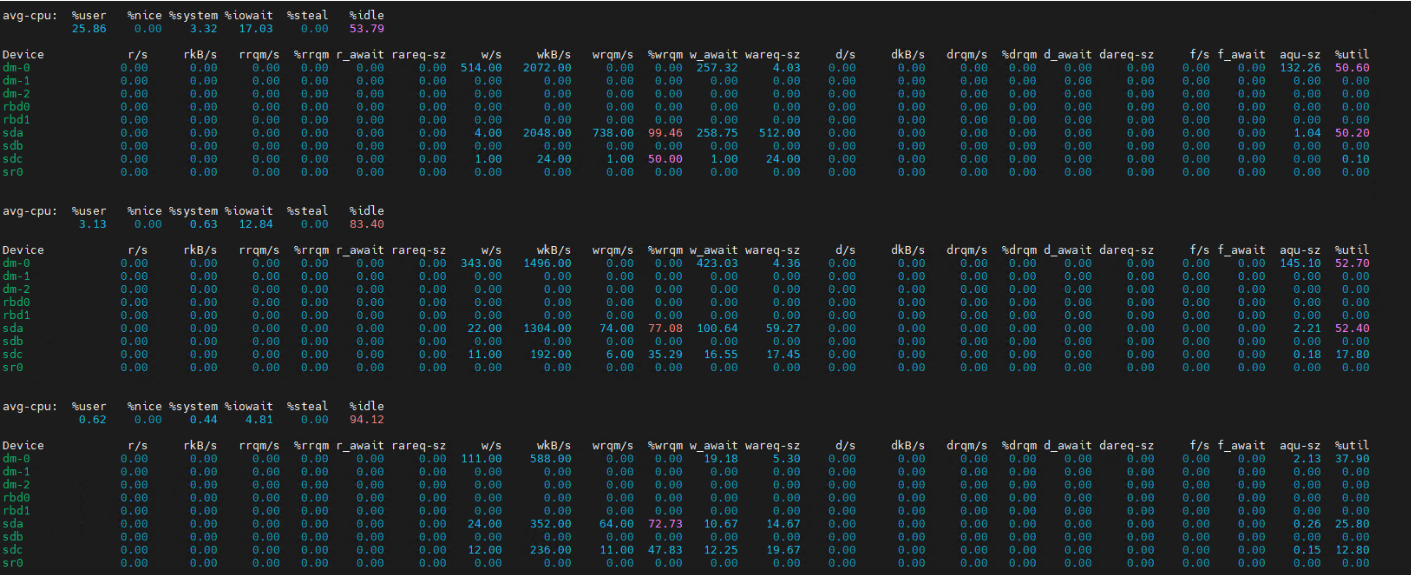
(块存储)io等待99%,表明cpu长时间处于等待状态,同时rbd2的util为100%,表明块设备一直繁忙。

指标介绍:
CPU 部分(avg-cpu 行)
%user:用户态 CPU 使用率,反映用户程序消耗的 CPU 占比。
%nice:低优先级用户态进程的 CPU 使用率。
%system:系统态(内核态)CPU 使用率,体现内核处理任务(如系统调用、IO 调度)的 CPU 消耗。
%iowait:CPU 等待 IO 完成的时间占比,若此值高,说明 IO 是性能瓶颈。
%steal:虚拟机环境下,被其他虚拟机窃取的 CPU 时间占比。
%idle:CPU 空闲时间占比。
磁盘 / 块设备部分(各设备行,如 dm-0、sda 等)
r/s:每秒读操作次数(Read operations per second)。
rkB/s:每秒读数据量(Kilobytes read per second)。
rrqm/s:每秒合并的读请求数(Read requests merged per second,合并请求可提升 IO 效率)。
%rrqm:读请求合并的比例。
r_await:读操作的平均响应时间(毫秒),包含等待和实际处理时间。
rareq-sz:平均读请求大小(千字节)。
w/s:每秒写操作次数(Write operations per second)。
wkB/s:每秒写数据量(Kilobytes written per second)。
wrqm/s:每秒合并的写请求数(Write requests merged per second)。
%wrqm:写请求合并的比例。
w_await:写操作的平均响应时间(毫秒)。
wareq-sz:平均写请求大小(千字节)。
d/s:每秒删除操作次数(Delete operations per second,部分场景适用)。
dkB/s:每秒删除数据量(Kilobytes deleted per second)。
drqm/s:每秒合并的删除请求数(Delete requests merged per second)。
%drqm:删除请求合并的比例。
d_await:删除操作的平均响应时间(毫秒)。
dareq-sz:平均删除请求大小(千字节)。
f/s:每秒 fsync 操作次数(fsync 用于强制将内存数据同步到磁盘)。
f_await:fsync 操作的平均响应时间(毫秒)。
aqu-sz:平均请求队列长度,队列越长,IO 延迟可能越高。
%util:设备的 IO 利用率,若接近 100%,说明设备处于饱和状态,IO 性能受限。
结果分析:
avg-cpu:
CPU 空闲率 53.79%,但 %iowait 达 17.03% → IO 等待占比偏高,说明可能存在存储瓶颈。
CPU 空闲率提升至 83.40%,%iowait 降至 12.84% → IO 压力有所缓解。
CPU 空闲率 94.12%,%iowait 仅 4.81% → IO 等待占比低,系统整体较空闲。
块设备:
设备 dm-0
| 指标 | 数值 | 解读 |
|---|---|---|
w/s | 514.00 | 每秒写操作 514 次 → 写 IOPS 极高,是主要 IO 负载来源。 |
wkB/s | 2072.00 | 每秒写数据 2072 KB(约 2.02 MB/s)→ 写吞吐量中等,但请求 “小而碎”。 |
w_await | 257.32 | 写响应时间 257.32 毫秒 → 延迟极高,说明写请求大量排队或磁盘处理慢。 |
aqu-sz | 132.26 | 平均请求队列长度 132.26 → 队列严重积压,新请求需等待大量已有请求完成。 |
%util | 50.60 | 设备利用率 50.60% → 看似未饱和,但延迟和队列已爆炸,说明磁盘处理能力不足(如机械盘,单盘处理能力有限)。 |
设备 sda
| 指标 | 数值 | 解读 |
|---|---|---|
w/s | 4.00 | 每秒写操作 4 次 → 写 IOPS 低。 |
wkB/s | 2048.00 | 每秒写数据 2048 KB(2 MB/s)→ 写吞吐量与 dm-0 相当,但 IOPS 低 → 说明 sda 的写请求更大、更集中。 |
wrqm/s | 738.00 | 每秒合并 738 个写请求 → 合并比例极高(%wrqm=99.46),说明原写请求 “小而碎”,依赖内核合并优化。 |
w_await | 258.75 | 写响应时间 258.75 毫秒 → 延迟极高,与 dm-0 问题一致。 |
%util | 50.20 | 设备利用率 50.20% → 同样 “利用率不高但延迟高”,反映磁盘处理能力是瓶颈。 |
随着监控推进,dm-0 和 sda 的 w/s、wkB/s 逐渐下降,w_await 也随之降低(如第二组 dm-0 的 w_await=423.03 是异常峰值,第三组降至 19.18)。%util 同步下降,队列长度(aqu-sz)也从 “百级” 降至 “个级”,说明IO 负载在减轻,系统逐渐从 “IO 饱和” 向 “空闲” 过渡。
4、blktrace
使用blktrace对比vdbench前后各cpu的IO时间统计。
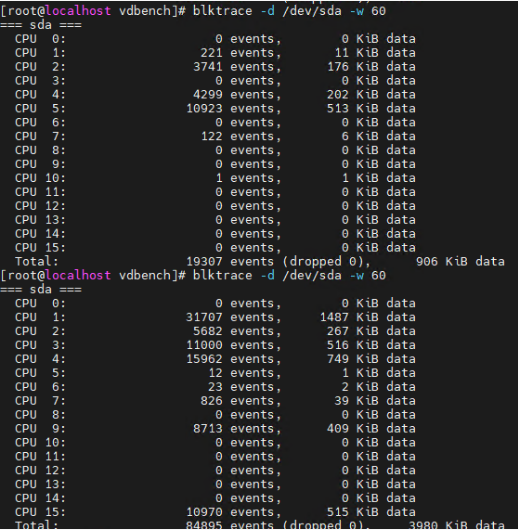
结果分析:
第一次 blktrace(vdbench 运行前)
总事件数:19307 个,总数据量 906 KiB。CPU 分布:主要集中在 CPU 2、4、5(如 CPU 5 有 10923 个事件,占比超 56%),其他 CPU 几乎无 I/O 事件。说明系统在无 vdbench 压测时,I/O 负载由少量 CPU 核心承担(可能是系统后台进程或基础服务导致)。
第二次 blktrace(vdbench 运行后)
总事件数:84895 个,总数据量 3980 KiB。
CPU 分布:负载分散到更多 CPU 核心(CPU 0、2、3、9 等均有大量事件)。关键变化:CPU 0:从 0 事件 → 31707 事件(成为最活跃核心,占比~37%)。CPU 2:从 3741 事件 → 5682 事件(增长明显)。CPU 3:从 4299 事件 → 11000 事件(翻倍增长)。CPU 9:从 0 事件 → 8713 事件(新增大量负载)。总事件数和数据量均大幅提升(事件数增约 4.4 倍,数据量增约 4.4 倍)。
总结
I/O 负载显著增加:vdbench 作为磁盘 I/O 压测工具,主动发起了大量磁盘读写请求,导致总 I/O 事件数和数据量暴增。
负载更分散:vdbench 可能通过多线程 / 多进程发起 I/O,使 I/O 负载从原本集中的少数 CPU 核心,分散到更多核心(如 CPU 0、9 等),更充分利用系统 CPU 资源进行 I/O 处理。
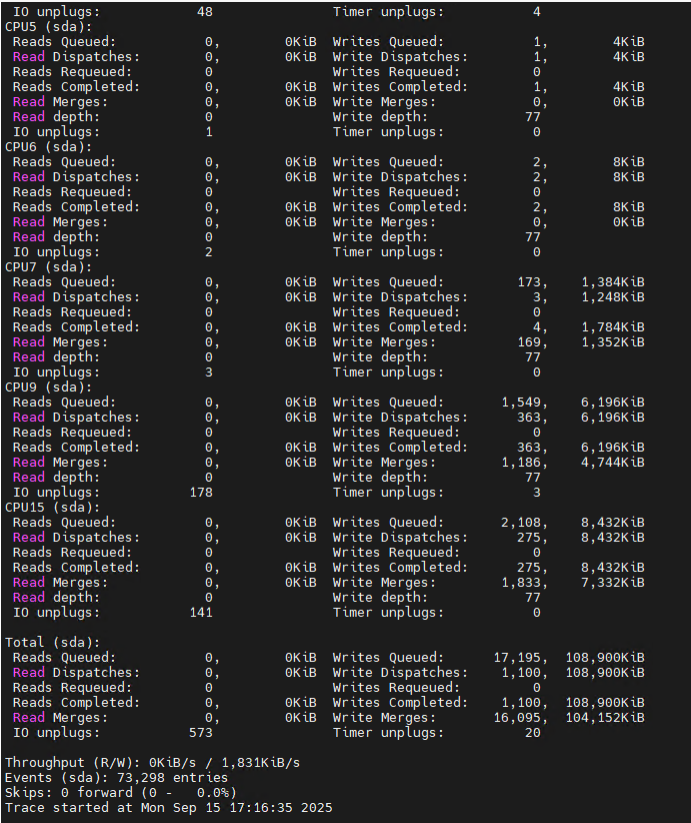
使用blkparse解析原始跟踪文件。

blkparse -i sda.blktrace.0 //解析blktrace的结果

5、sar
sar -u 5 3

%user:用户空间占用 CPU 的百分比。
%nice:表示用户态中以低优先级(nice 值调整)运行的进程所占用 CPU 的百分比。
%system:系统空间占用 CPU 的百分比。
%iowait:表示 CPU 等待 I/O 操作完成所花费的时间百分比,值高说明系统存在 I/O 瓶颈。
%steal:在虚拟化环境中,被其他虚拟机占用的 CPU 时间百分比。
%idle:表示 CPU 空闲时间的百分比。
希望本文对您有所帮助!你的点赞、收藏和关注这是对我最大的鼓励。如果有任何问题或建议,欢迎在评论区留言讨论。