(二)昇腾AI处理器计算资源层基础
(一)AI Core架构:达芬奇架构的核心理解
AI Core是昇腾AI处理器的计算核心,采用华为自研的达芬奇架构,通常也被叫做Da Vinci Core。AI Core包含计算单元、存储单元、控制单元[1],其架构图如下所示:
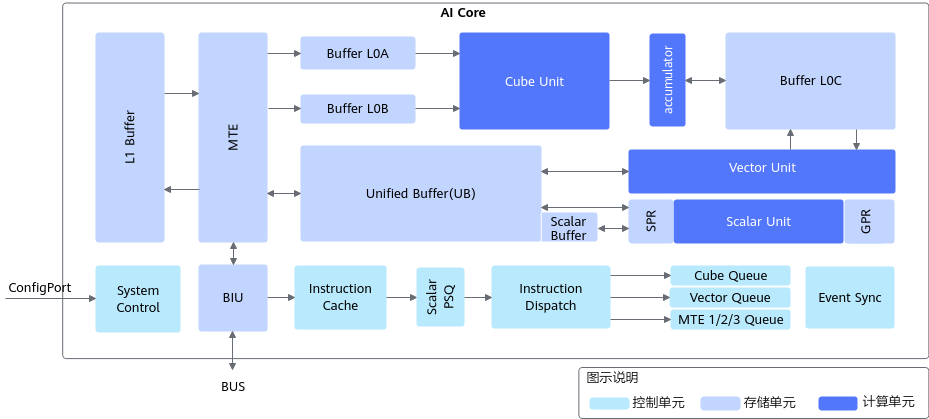
AI Core架构图
1. 计算单元
计算单元负责执行数据的运算操作,AI Core中主要有三种计算单元,每种都有不同的功能。
假设我们在进行图像处理任务,如使用卷积神经网络(CNN)对图像进行分类。在这种情况下,AI Core的计算单元将负责执行卷积操作。
Scalar计算单元:它负责执行简单的标量计算,比如在卷积操作中计算卷积核的偏置项或处理图像的像素位置。它还会决定何时发出“执行卷积”的指令。
Vector计算单元:负责执行向量运算。在卷积操作中,它可以同时处理多个像素的计算,计算多个像素的卷积结果。比如,它可以一次性计算图像中多个像素与卷积核的乘加运算。
Cube计算单元:负责执行矩阵运算。在进行卷积时,Cube单元能够高效地进行大规模的矩阵计算,处理更复杂的图像数据和卷积核。
具体的计算流程如下:
Scalar首先决定哪些卷积操作需要计算。
然后,Vector计算单元处理多个像素的卷积结果。
最后,Cube计算单元进行大规模矩阵运算,完成整个卷积的结果计算。
注:从计算数据的规模来看,Scalar最小(标量计算和控制),Vector适中(向量计算),Cube最大(矩阵计算)。
2. 存储单元
存储单元负责存储计算过程中的数据,AI Core有两类存储。 在机器学习模型的训练过程中,我们通常需要大量的数据进行训练。在AI Core中,Local Memory和Global Memory用于存储这些数据。
Local Memory:假设我们在训练一个深度神经网络,每次训练时,需要将数据加载到Local Memory中进行处理。这些数据可以是当前批次的训练样本、模型的中间结果或梯度信息等。
Global Memory:当训练完成后,处理结果(如模型参数、权重)将被存储到Global Memory,等待下一个训练轮次或者用于推理。
数据流流程如下:
在每次训练的开始,数据从Global Memory加载到Local Memory。
计算过程中,Local Memory存储着当前批次的训练数据和中间计算结果。
当计算结束后,处理结果被写回Global Memory,为下次使用做准备。
注:当前批次是Lcocal Memory,计算完成后放在Global Memory保存。
3. 控制单元
注:AI Core的控制单元设计核心是:
分工:将不同类型的指令(Scalar控制指令、Cube矩阵计算指令、Vector向量计算指令、MTE数据搬运指令)分发给不同的专业单元去执行。
并行:不同的专业单元(如Cube、Vector、MTE)可以同时工作,从而极大提高效率。
这些不同类型的指令与控制单元的关系是 “被管理者与管理者的关系”。控制单元就像一个公司的总部,而Scalar、Cube、Vector、MTE指令就像是公司里不同专业的员工。总部本身不直接去生产产品(执行计算),但它负责管理所有这些员工,确保他们高效、正确、协同地完成工作。
控制单元(特别是其中的指令发射模块 Instruction Dispatch)决定了何时、以及由谁来执行哪条指令,当一条指令进入AI Core后,控制单元会“查看”它的类型(就像HR查看员工的工牌),然后将其分派到对应的专用队列中。看到是 CUBE 指令 -> 发给 Cube Queue -> 等待 Cube计算单元 执行。看到是 VECTOR 指令 -> 发给 Vector Queue -> 等待 Vector计算单元 执行。看到是 MTE 指令 -> 发给 MTE Queue -> 等待 MTE单元 执行。SCALAR 指令本身就在 Scalar PSQ 中由Scalar单元处理,并协助控制单元为其他指令做准备。
控制单元(特别是系统控制模块 System Control)在指令执行前,为其搭建好舞台。控制单元会配置整个AI Core的初始状态。设置程序计数器(PC),告诉系统从哪里开始取指令。设置参数基地址(Para_base),告诉计算单元去哪里找计算所需的权重(Weights)和偏置(Bias)等参数。分配任务块(Block ID),明确当前要处理的任务。
控制单元确保指令之间的“正确顺序”和“协同同步”,这是最复杂也是最重要的一层关系。指令之间往往存在依赖关系。控制单元中的事件同步模块(Event Sync) 就负责解决这个问题。它监控所有队列的进度。当CUBE指令还在执行时,它会阻塞(Hold住)那条依赖它的VECTOR指令,即使Vector Queue有空闲也不会发射它。当CUBE指令执行完毕,发出一个“完成”信号,Event Sync模块才会放行那条VECTOR指令。没有控制单元的同步,指令就会乱序执行,导致使用了错误的数据,计算结果完全错误。并行不等于乱序,而控制单元就是保障并行且有序的关键。
控制单元(通过指令缓存 Instruction Cache)确保指令能够被持续、高速地供应给执行单元,避免其“饿死”。Instruction Cache会预取指令,即提前把后面要执行的指令从慢速的外部内存搬到AI Core内部的高速缓存中。
控制单元为整个计算过程提供了指令控制,负责整个AI Core的运行。AI Core包含的控制单元如下表所示:
控制单元 | 描述 |
|---|---|
系统控制模块(System Control) | 外部的Task Scheduler控制和初始化AI Core的配置接口, 配置PC、Para_base、BlockID等信息,具体功能包括:Block执行控制、Block执行完之后中断和状态申报、执行错误状态申报等。 |
指令缓存模块(Instruction Cache) | AI Core内部的指令Cache, 具有指令预取功能。 |
标量指令处理队列(Scalar PSQ) | Scalar指令处理队列。 |
指令发射模块(Instruction Dispatch) | CUBE/Vector/MTE指令经过Scalar PSQ处理之后,地址、参数等要素都已经配置好,之后Instruction Dispatch单元根据指令的类型,将CUBE/Vector/MTE指令分别分发到对应的指令队列等待相应的执行单元调度执行。 |
矩阵运算队列(Cube Queue) | Cube指令队列。同一个队列里的指令顺序执行,不同队列之间可以并行执行。 |
向量运算队列(Vector Queue) | Vector指令队列。同一个队列里的指令顺序执行,不同队列之间可以并行执行。 |
存储转换队列(MTE Queue) | MTE指令队列。同一个队列里的指令顺序执行,不同队列之间可以并行执行。 |
事件同步模块(Event Sync) | 用于控制不同队列指令(也叫做不同指令流水)之间的依赖和同步的模块。 |
系统控制模块负责指挥和协调AI Core的整体运行模式,配置参数和实现功耗控制等。当指令通过指令发射模块顺次发射出去后,根据指令的不同类型,将会分别被发送到矩阵运算队列、向量运算队列和存储转换队列。
指令执行过程中,可以提前预取后续指令,并一次读入多条指令进入缓存,提升指令执行效率。多条指令从系统内存通过总线接口(BIU)进入到AI Core的指令缓存模块(Instruction Cache)中等待后续硬件快速自动解码或运算。指令被解码后便会被导入标量队列中,实现地址解码与运算控制。
注:系统内存 (System Memory)通常就是片外的DDR内存。它的容量很大,但速度相对较慢。所有待执行的指令最初都存储在这里。总线接口 (BIU - Bus Interface Unit)是AI Core与外部世界(主要是系统内存)通信的“门户”或“港口”。它负责发起读/写请求,在AI Core和内存之间搬运数据和指令。指令缓存 (Instruction Cache)是AI Core内部的一块高速静态存储器 (SRAM)。它的容量较小,但速度极快,非常接近计算单元。
(二)AI CPU在计算资源层中的角色与功能
注:如果任务是AI Core擅长的(如卷积、矩阵乘),AI Core 接到指令后,全力执行这个计算任务,在此期间AI CPU可以去处理别的事情。AI CPU 会通过驱动配置好AI Core的寄存器,告诉它:“去地址X取数据,用地址Y的权重,执行一个16x16的矩阵乘法,结果存到地址Z”。如果任务是控制逻辑或通用计算(如循环控制、条件判断),AI CPU 会自己执行这些任务,不会交给AI Core。AI Core 计算完成后,可能会发出一个中断信号通知AI CPU:“任务完成!”AI CPU 检查结果,然后决定下一步做什么,是继续分发下一个计算任务给AI Core,还是需要根据结果执行一些分支逻辑?
AI CPU 在昇腾AI处理器中扮演着至关重要的角色,它与多个模块(如 GE、AI CPU Engine、AI CPU Schedule、AI CPU Processor 和 Data Processor)紧密配合,确保了从模型准备到最终执行的每个环节都高效进行[1]。AI CPU负责执行昇腾AI处理器的CPU类算子(包括控制算子、标量和向量等通用计算),其在解决方案系统架构中的位置如下所示:
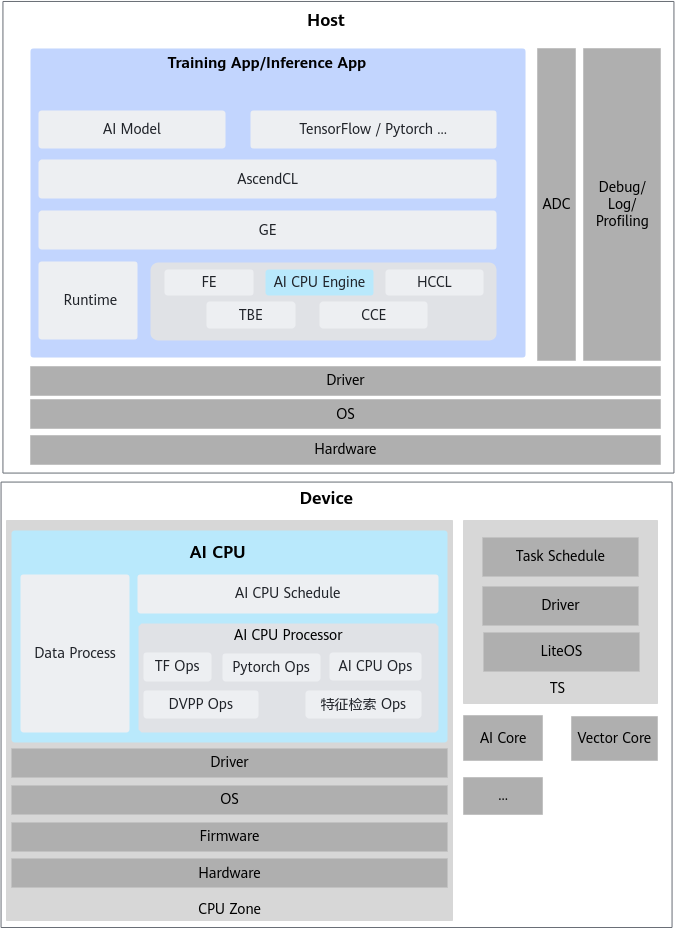
GE是连接“软件世界(机器学习框架)”和“硬件世界(昇腾AI处理器)”的桥梁,同时它也是统筹管理硬件世界内部所有计算资源(包括AI CPU、AI Core、Data Processor等)的“大脑”或“总指挥官”。它的工作流程是:接收来自TensorFlow、PyTorch等框架定义的整个神经网络模型(计算图),对这个大图进行拆分、优化(如算子融合、内存优化等),决定计算图中的哪些算子(操作)由AI Core执行(如卷积、矩阵乘),哪些由AI CPU执行(如控制流算子),哪些需要Data Processor预处理,将优化和拆分后的子任务分别下发到对应的硬件单元(AI Core, AI CPU等)的驱动上去执行。GE并不直接连接硬件,它通过下层的软件栈(如Runtime)来指挥硬件。它决定了AI CPU和AI Core各自要做什么工作,并确保它们协同工作完成整个计算图。
1. GE(Graph Engine)
Graph Engine (GE) 是昇腾AI软件栈的一部分,它提供了一个统一的接口,帮助不同的机器学习框架(比如TensorFlow、PyTorch等)与昇腾AI处理器对接。简单来说,GE就像是一个“中介”,帮助框架和硬件之间顺利沟通。它的主要功能包括图准备、图拆分、图优化、图编译、图加载、图执行和图管理。
这里的“图”指的是网络模型的结构图,包含了模型中的各个层和它们之间的连接。GE的工作就是把复杂的任务分解成多个小任务,优化这些任务,并确保它们能够高效地在昇腾AI的计算单元(AI Core)和处理单元(AI CPU)上执行。这使得不同框架的模型可以在昇腾硬件上高效地进行训练和推理。
2. AI CPU Engine
AI CPU Engine 是专门为AI CPU设计的编译引擎,它与Graph Engine(GE)配合工作,主要负责提供与AI CPU相关的算子信息。你可以把它理解为一个“助手”,它帮助AI CPU理解并执行计算任务。它的主要任务包括:
算子注册:注册并管理不同的计算操作(比如加法、乘法等基本操作)。
算子内存需求计算:计算每个算子需要多少内存资源。
子图优化:优化计算图中的一部分子图,以提高执行效率。
任务生成:把计算任务拆解成具体的执行步骤,便于AI CPU执行。
这些功能确保AI CPU可以在GE的调度下高效地完成各种计算任务,像是控制算子、标量计算和向量计算等。简单来说,AI CPU Engine 就是帮助AI CPU更聪明、更高效地执行计算任务的工具。
3. AI CPU Schedule
AI CPU Schedule是AI CPU的模型调度器,它与Task Schedule配合完成NN模型的调度和执行。在模型训练和推理过程中,AI CPU Schedule负责根据任务的优先级和资源可用情况,合理调度各个子任务,确保整个系统的高效运行。
4. AI CPU Processor
AI CPU Processor 就是 AI CPU 的“执行者”,它的任务是完成具体的算子运算。你可以把它看作是负责执行任务的“工人”。
它包含一个 算子实现库,这个库里面存放了各种计算操作的具体执行方式,比如加法、乘法等基本运算。每当 AI CPU Engine 生成一个任务(例如,执行某个算子),AI CPU Processor 就会从算子实现库中找到合适的执行方式,并将任务执行在硬件资源上。
简而言之,AI CPU Processor 就是直接在硬件上执行任务的部件,确保每个算子都能够快速、准确地完成计算。