解析预训练:BERT到Qwen的技术演进与应用实践
引言:预训练范式的崛起
在人工智能的发展历程中,预训练模型无疑是最具革命性的技术突破之一。从早期的Word2Vec、GloVe等静态词向量模型,到ELMo带来的上下文感知词表示,再到2018年BERT的横空出世,自然语言处理领域经历了一场深刻的范式转移。
预训练模型的核心思想是通过在大规模无标注文本上进行自监督学习,获取通用的语言表示能力,然后通过微调适应下游任务。这种方法不仅显著提升了各类NLP任务的性能,更重要的是建立了一种"预训练+微调"的新范式,彻底改变了自然语言处理的研究和应用方式。
本文将深入解析预训练模型的技术原理,重点分析BERT及其后续发展,并深入探讨阿里巴巴通义千问(Qwen)系列模型的技术特点与应用实践,为读者提供全面而深入的技术视角。
一、预训练模型的技术基础
1.1 自监督学习
预训练模型的核心学习范式是自监督学习,即从数据本身自动生成监督信号,而不需要人工标注的标签。在自然语言处理中,最常见的自监督任务包括:
语言建模(Language Modeling):预测下一个词或掩盖的词
自编码(Autoencoding):从损坏的输入重建原始文本
对比学习(Contrastive Learning):区分相似和不相似的文本对
这些任务使得模型能够从海量无标注文本中学习语言的内在规律和知识表示。
1.2 Transformer架构
Transformer架构是当代预训练模型的技术基石,由Vaswani等人在2017年提出。其核心创新在于完全基于自注意力机制,摒弃了传统的循环和卷积结构。
自注意力机制的计算过程如下:
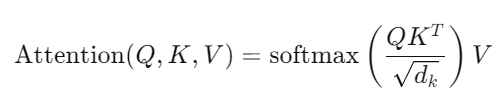
其中$Q$(Query)、$K$(Key)、$V$(Value)分别表示查询、键和值矩阵,$d_k$是键向量的维度。
多头注意力进一步扩展了这一机制:
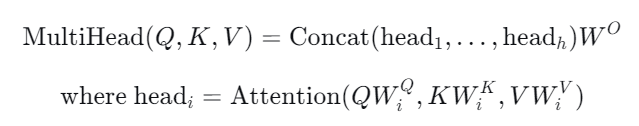
这种设计使模型能够同时关注来自不同位置的不同表示子空间的信息。
1.3 位置编码
由于Transformer不包含循环或卷积操作,需要显式地注入位置信息。常用的位置编码包括:
正弦位置编码:使用不同频率的正弦和余弦函数
学习式位置编码:将位置视为可学习的参数
相对位置编码:关注 token 之间的相对距离而非绝对位置
二、BERT:双向编码器的里程碑
2.1 核心创新
BERT(Bidirectional Encoder Representations from Transformers)在2018年由Google提出,其最大创新是实现了真正的双向上下文理解。与之前基于单向语言模型的预训练方法不同,BERT通过掩码语言模型(MLM)和下一句预测(NSP)任务进行预训练。
掩码语言模型随机掩盖输入序列中的部分token(通常为15%),然后训练模型预测这些被掩盖的token。数学上,给定输入序列$X = (x_1, ..., x_N)$,掩盖后的序列为$X^{\text{masked}}$,模型需要最大化似然函数:
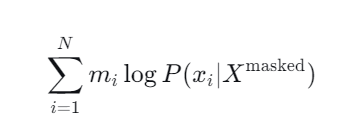
其中$m_i$是指示函数,当$x_i$被掩盖时为1,否则为0。
下一句预测任务判断两个句子是否在原文中相邻,帮助模型理解句子间关系。
2.2 模型架构
BERT的基础架构基于Transformer编码器堆叠,主要有两个版本:
BERT-Base:12层,768隐藏单元,12个注意力头,1.1亿参数
BERT-Large:24层,1024隐藏单元,16个注意力头,3.4亿参数
# 简化版的BERT模型实现核心代码
import torch
import torch.nn as nn
from transformers import BertConfig, BertModelclass SimplifiedBERT(nn.Module):def __init__(self, config):super(SimplifiedBERT, self).__init__()self.config = configself.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config)self.pooler = BertPooler(config)def forward(self, input_ids, attention_mask=None, token_type_ids=None):embedding_output = self.embeddings(input_ids, token_type_ids)encoder_outputs = self.encoder(embedding_output, attention_mask)sequence_output = encoder_outputs[0]pooled_output = self.pooler(sequence_output)return sequence_output, pooled_output2.3 应用实践:文本分类任务
以下是一个使用BERT进行文本分类的完整示例:
import torch
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
import pandas as pd# 数据准备
class TextClassificationDataset(Dataset):def __init__(self, texts, labels, tokenizer, max_length):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_length = max_lengthdef __len__(self):return len(self.texts)def __getitem__(self, idx):text = str(self.texts[idx])label = self.labels[idx]encoding = self.tokenizer.encode_plus(text,add_special_tokens=True,max_length=self.max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt',)return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 加载预训练模型和分词器
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)# 假设我们有训练数据
train_texts = ["This is a positive example", "This is negative"] * 100
train_labels = [1, 0] * 100# 分割数据集
train_texts, val_texts, train_labels, val_labels = train_test_split(train_texts, train_labels, test_size=0.2, random_state=42
)# 创建数据加载器
train_dataset = TextClassificationDataset(train_texts, train_labels, tokenizer, max_length=128)
val_dataset = TextClassificationDataset(val_texts, val_labels, tokenizer, max_length=128)train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False)# 训练循环
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)for epoch in range(3):model.train()total_loss = 0for batch in train_loader:input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['labels'].to(device)outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossloss.backward()optimizer.step()optimizer.zero_grad()total_loss += loss.item()print(f'Epoch {epoch+1}, Average Loss: {total_loss/len(train_loader)}')2.4 BERT的局限性
尽管BERT取得了巨大成功,但仍存在一些局限性:
计算资源需求大,推理速度慢
掩码语言模型预训练与微调任务之间存在差异
对长文本处理能力有限(最大512个token)
静态掩码策略可能导致预训练效率不高
三、BERT的演进与改进
3.1 RoBERTa:优化预训练过程
RoBERTa(Robustly Optimized BERT Pretraining Approach)通过一系列改进提升了BERT的性能:
移除了下一句预测任务
使用更大的批次大小和更长的训练时间
动态掩码策略,每个epoch重新生成掩码模式
更大规模且更高质量的训练数据
3.2 ALBERT:参数共享与分解
ALBERT(A Lite BERT)通过两种主要技术减少参数数量:
参数共享:所有Transformer层共享参数
因子化参数分解:将词汇表嵌入矩阵分解为两个小矩阵
这些技术使ALBERT在大幅减少参数量的同时保持了模型性能。
3.3 DistilBERT:模型蒸馏
DistilBERT通过知识蒸馏技术将BERT模型压缩为更小的版本:
使用教师-学生框架,让学生模型模仿教师模型的行为
结合语言建模损失、蒸馏损失和余弦嵌入损失
在保持97%性能的同时,参数减少40%,推理速度提升60%
四、Qwen:大语言模型的新篇章
4.1 Qwen系列概述
Qwen(通义千问)是阿里巴巴开发的大语言模型系列,涵盖了从7B到72B参数规模的多个版本,以及专门的代码模型Qwen-Coder和多模态模型Qwen-VL。
4.2 技术特点
4.2.1 扩展的上下文长度
Qwen支持长达32K token的上下文窗口,远超传统BERT模型的512限制。这一特性使其能够处理长文档、保持长对话和进行复杂的推理任务。
长上下文处理的技术挑战包括:
计算复杂度随序列长度平方增长
注意力稀释问题(关注度随距离增加而下降)
长序列训练稳定性
Qwen通过以下技术应对这些挑战:
# 简化版的长注意力机制实现
class LongAttention(nn.Module):def __init__(self, config):super(LongAttention, self).__init__()self.config = configself.attention_head_size = config.hidden_size // config.num_attention_heads# 使用线性复杂度的注意力机制self.use_linear_attention = config.use_linear_attentionif self.use_linear_attention:self.linear_attention = LinearAttention(config)else:self.full_attention = FullAttention(config)def forward(self, hidden_states, attention_mask=None):if self.use_linear_attention and hidden_states.size(1) > 2048:return self.linear_attention(hidden_states, attention_mask)else:return self.full_attention(hidden_states, attention_mask)4.2.2 多模态能力
Qwen-VL整合了视觉和语言理解能力,支持图像描述、视觉问答等多模态任务。其架构采用视觉编码器提取图像特征,然后与文本特征融合处理。
# 简化的多模态融合实现
class MultimodalFusion(nn.Module):def __init__(self, config):super(MultimodalFusion, self).__init__()self.config = config# 视觉编码器(如ViT)self.visual_encoder = VisualTransformer(config.visual_config)# 文本编码器self.text_encoder = TextTransformer(config.text_config)# 跨模态注意力融合self.cross_attention = CrossAttention(config.fusion_config)# 多模态预测头self.prediction_head = MultimodalHead(config.head_config)def forward(self, images, input_ids, attention_mask):# 提取视觉特征visual_features = self.visual_encoder(images)# 提取文本特征text_features = self.text_encoder(input_ids, attention_mask)# 跨模态融合fused_features = self.cross_attention(visual_features, text_features)# 预测输出output = self.prediction_head(fused_features)return output4.2.3 强化人类偏好对齐
Qwen采用了基于人类反馈的强化学习(RLHF)技术,使模型输出更符合人类期望。这一过程包括三个步骤:
监督微调(SFT):使用高质量指令数据微调预训练模型
奖励模型训练:训练一个模型来评估响应质量
强化学习优化:使用PPO算法优化策略模型以最大化奖励
4.3 Qwen-Coder:代码专用模型
Qwen-Coder专门针对代码理解和生成任务进行了优化,在多个代码基准测试中表现出色。其技术特点包括:
代码特定的分词器和词汇表
代码结构感知的注意力机制
跨文件上下文理解能力
# 代码结构感知的注意力机制示例
class CodeStructureAwareAttention(nn.Module):def __init__(self, config):super(CodeStructureAwareAttention, self).__init__()self.config = config# 语法距离偏置self.syntax_distance_bias = nn.Parameter(torch.zeros(config.max_syntax_distance, config.num_attention_heads))# 数据类型嵌入self.data_type_embedding = nn.Embedding(config.num_data_types, config.hidden_size)def forward(self, hidden_states, syntax_distances, data_types):# 添加语法结构偏置attention_scores = compute_attention_scores(hidden_states)# 根据语法距离调整注意力分数syntax_bias = self.syntax_distance_bias[syntax_distances]attention_scores = attention_scores + syntax_bias# 添加数据类型信息type_embeds = self.data_type_embedding(data_types)hidden_states = hidden_states + type_embeds# 计算注意力权重和输出attention_weights = F.softmax(attention_scores, dim=-1)context = torch.matmul(attention_weights, hidden_states)return context五、预训练模型的实际应用分析
5.1 文本分类与情感分析
预训练模型在文本分类任务中表现出色,以下是一个使用Qwen进行细粒度情感分析的示例:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as npclass FineGrainedSentimentAnalyzer:def __init__(self, model_name="Qwen/Qwen-7B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=5 # 5个情感等级)self.sentiment_labels = ["非常负面", "负面", "中性", "正面", "非常正面"]def analyze(self, text):inputs = self.tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)with torch.no_grad():outputs = self.model(**inputs)predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)predicted_class = torch.argmax(predictions, dim=1).item()confidence = predictions[0][predicted_class].item()return {"sentiment": self.sentiment_labels[predicted_class],"confidence": confidence,"distribution": predictions.numpy()[0]}# 使用示例
analyzer = FineGrainedSentimentAnalyzer()
result = analyzer.analyze("这部电影的视觉效果令人惊叹,但剧情有些拖沓")
print(f"情感: {result['sentiment']}, 置信度: {result['confidence']:.3f}")5.2 智能问答系统
基于预训练模型的问答系统能够理解复杂问题并提供准确答案:
class IntelligentQASystem:def __init__(self, model_name="Qwen/Qwen-7B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForQuestionAnswering.from_pretrained(model_name)self.knowledge_base = self.load_knowledge_base()def load_knowledge_base(self):# 加载知识库(这里简化为字典,实际应用中可能是向量数据库)return {"company_founder": "阿里巴巴由马云和18位创始人在1999年创立","company_headquarters": "阿里巴巴总部位于中国杭州","main_business": "阿里巴巴主要业务包括电子商务、云计算、数字媒体和娱乐等"}def answer_question(self, question, context=None):if context is None:# 如果没有提供上下文,从知识库中检索相关信息context = self.retrieve_relevant_context(question)inputs = self.tokenizer(question, context, return_tensors="pt", truncation=True, max_length=512)with torch.no_grad():outputs = self.model(**inputs)start_logits = outputs.start_logitsend_logits = outputs.end_logits# 找到答案的起始和结束位置start_idx = torch.argmax(start_logits)end_idx = torch.argmax(end_logits) + 1 # 包含结束位置answer_tokens = inputs.input_ids[0][start_idx:end_idx]answer = self.tokenizer.decode(answer_tokens, skip_special_tokens=True)return answerdef retrieve_relevant_context(self, question):# 简单的关键词匹配检索(实际应用中可使用更复杂的语义检索)relevant_context = ""for key, value in self.knowledge_base.items():if any(word in question for word in key.split('_')):relevant_context += value + " "return relevant_context if relevant_context else "没有找到相关信息"# 使用示例
qa_system = IntelligentQASystem()
question = "阿里巴巴是谁创立的?"
answer = qa_system.answer_question(question)
print(f"问题: {question}")
print(f"答案: {answer}")5.3 代码生成与补全
Qwen-Coder在代码生成任务中表现优异,以下是一个代码自动补全的实现示例:
class CodeAutocompletion:def __init__(self, model_name="Qwen/Qwen-Coder-7B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.model.eval()def complete_code(self, partial_code, max_length=100, temperature=0.8):inputs = self.tokenizer(partial_code, return_tensors="pt", truncation=True, max_length=1024)with torch.no_grad():outputs = self.model.generate(inputs.input_ids,attention_mask=inputs.attention_mask,max_length=len(inputs.input_ids[0]) + max_length,temperature=temperature,do_sample=True,pad_token_id=self.tokenizer.eos_token_id,eos_token_id=self.tokenizer.eos_token_id)completed_code = self.tokenizer.decode(outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True)return completed_code# 使用示例
code_completer = CodeAutocompletion()
partial_code = """
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)# 测试快速排序
test_arr = [3, 6, 8, 10, 1, 2, 1]
sorted_arr = quick_sort(test_arr)
print("排序结果:", sorted_arr)# 下面实现一个二分查找算法
def binary_search(arr, target):
"""completed_code = code_completer.complete_code(partial_code)
print("生成的代码补全:")
print(completed_code)六、预训练模型的优化与部署
6.1 模型压缩技术
在实际部署中,预训练模型通常需要压缩以减少资源消耗:
6.1.1 量化
量化将模型参数从32位浮点数转换为低精度表示(如16位浮点数、8位整数):
from transformers import AutoModel, quantization# 动态量化
def dynamic_quantization(model_path, output_path):model = AutoModel.from_pretrained(model_path)quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)quantized_model.save_pretrained(output_path)# 训练后静态量化
def static_quantization(model, calibration_data):model.eval()model.qconfig = torch.quantization.get_default_qconfig('fbgemm')# 准备模型model_prepared = torch.quantization.prepare(model)# 校准with torch.no_grad():for data in calibration_data:model_prepared(data)# 转换model_quantized = torch.quantization.convert(model_prepared)return model_quantized6.1.2 知识蒸馏
知识蒸馏通过教师-学生框架将大模型的知识转移给小模型:
class DistillationTrainer:def __init__(self, teacher_model, student_model, temperature=3.0):self.teacher_model = teacher_modelself.student_model = student_modelself.temperature = temperatureself.ce_loss = nn.CrossEntropyLoss()self.kl_loss = nn.KLDivLoss(reduction="batchmean")def compute_loss(self, student_outputs, teacher_outputs, labels, alpha=0.5):# 学生模型的交叉熵损失ce_loss = self.ce_loss(student_outputs.logits, labels)# 知识蒸馏损失soft_labels = F.softmax(teacher_outputs.logits / self.temperature, dim=-1)soft_predictions = F.log_softmax(student_outputs.logits / self.temperature, dim=-1)kd_loss = self.kl_loss(soft_predictions, soft_labels) * (self.temperature ** 2)# 组合损失total_loss = alpha * ce_loss + (1 - alpha) * kd_lossreturn total_loss6.2 推理优化
6.2.1 使用ONNX Runtime加速
import onnxruntime as ort
from transformers import AutoTokenizer, AutoModel
import torchdef convert_to_onnx(model_path, onnx_path):model = AutoModel.from_pretrained(model_path)tokenizer = AutoTokenizer.from_pretrained(model_path)# 创建示例输入dummy_input = tokenizer("这是一个示例", return_tensors="pt")# 导出ONNX模型torch.onnx.export(model,tuple(dummy_input.values()),onnx_path,input_names=['input_ids', 'attention_mask'],output_names=['last_hidden_state'],dynamic_axes={'input_ids': {0: 'batch_size', 1: 'sequence_length'},'attention_mask': {0: 'batch_size', 1: 'sequence_length'},'last_hidden_state': {0: 'batch_size', 1: 'sequence_length'}},opset_version=13)def create_onnx_session(onnx_path):options = ort.SessionOptions()options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALLsession = ort.InferenceSession(onnx_path, options)return sessiondef onnx_inference(session, text, tokenizer):inputs = tokenizer(text, return_tensors="np")outputs = session.run(None,{'input_ids': inputs['input_ids'],'attention_mask': inputs['attention_mask']})return outputs6.2.2 使用TensorRT进一步优化
# TensorRT优化示例
def build_tensorrt_engine(onnx_path, trt_path):import tensorrt as trtlogger = trt.Logger(trt.Logger.WARNING)builder = trt.Builder(logger)network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))parser = trt.OnnxParser(network, logger)# 解析ONNX模型with open(onnx_path, 'rb') as model:if not parser.parse(model.read()):for error in range(parser.num_errors):print(parser.get_error(error))return None# 构建配置config = builder.create_builder_config()config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30) # 1GB# 构建引擎engine = builder.build_engine(network, config)# 保存引擎with open(trt_path, "wb") as f:f.write(engine.serialize())return engine七、未来发展趋势与挑战
7.1 技术发展趋势
模型架构创新:更高效的注意力机制(如线性注意力、稀疏注意力)
多模态融合:深度融合视觉、语音、文本等多种模态信息
推理能力提升:增强模型的逻辑推理和数学计算能力
个性化与适配:开发更高效的领域适配和个性化技术
绿色AI:降低模型训练和推理的能耗,提高计算效率
7.2 面临的挑战
计算资源需求:大模型训练需要巨大的计算资源和能源消耗
偏见与公平性:模型可能放大训练数据中的偏见和不公平
可解释性:大模型的决策过程仍然缺乏透明度
安全与对齐:确保模型行为与人类价值观保持一致
知识更新:如何有效更新模型知识而不需要完全重新训练
7.3 应对策略
高效训练技术:开发参数高效微调(PEFT)等技术
联邦学习:在保护隐私的前提下利用分布式数据
模型编辑:开发直接修改模型知识的技术
多模型协作:结合大模型和小模型的优势
持续学习:使模型能够持续学习新知识而不遗忘旧知识
结论
预训练模型已经从BERT的基础双向编码器发展到如Qwen这样功能丰富的大语言模型,在自然语言处理、多模态理解和代码生成等领域展现出强大的能力。这些模型通过大规模预训练获得了丰富的世界知识和强大的泛化能力,为各种下游任务提供了强大的基础。
然而,预训练模型的发展仍面临计算资源、偏见、可解释性等多方面的挑战。未来的研究需要在提升模型性能的同时,关注效率、公平性和安全性,推动人工智能技术向着更加高效、可靠和有益于人类的方向发展。
随着技术的不断进步,预训练模型将继续深刻改变我们与计算机交互的方式,为各行各业带来创新和变革。对于开发者和研究人员而言,深入理解这些模型的工作原理和应用方法,将有助于更好地利用这一强大技术解决实际问题。
喜欢本文的小伙伴请记得收藏,点赞,加关注哦!!