云原生与 AI 驱动下的数据工程新图景——解读 DZone 2025 数据工程趋势报告【附报告下载】
在 AI 技术从“实验性”走向“企业级落地”的关键阶段,数据工程作为底层支撑的重要性愈发凸显。近日,DZone 发布的《2025 数据工程趋势报告》(Scaling Intelligence with the Modern Data Stack)通过对全球 123 位 IT 专业人士的调研,揭示了当前数据工程领域的核心趋势、技术选型偏好与实践痛点。本文将梳理报告的核心发现,并解读其对数据工程师、架构师及技术管理者的实践价值。

一、报告概览:调研背景与核心基调
DZone 本次调研覆盖了全球范围内的开发者、架构师等 IT 从业者,样本呈现三大特征:
- 角色集中:32%为“开发者/工程师”,10%为“开发团队负责人”,核心受访者均深度参与数据系统构建;
- 技术栈成熟:80%企业使用 Python 生态,50%从业者以 Python 为主要工作语言,Java(22%)位居第二;
- 经验丰富:受访者平均 IT 从业经验达 14.65 年,中位数 13 年,反馈具备较强实践参考性。
报告核心基调明确:企业数据能力正从“技术堆砌”转向“整合优化”——不再盲目追逐新工具,而是聚焦成本控制、性能监控与流程编排,以适配 AI 原生架构、实时分析等新需求。
二、核心发现:数据工程的三大“转向”
1. 存储架构:从“混合分散”转向“云原生主导”
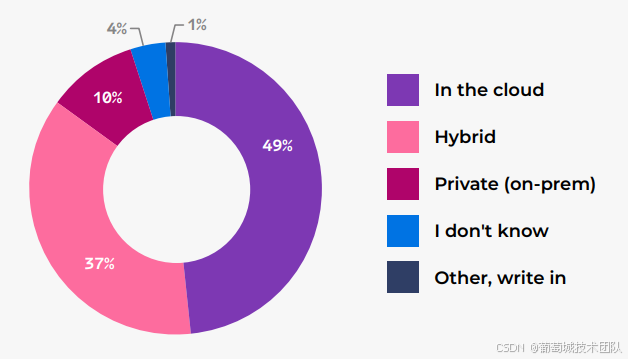
数据存储是本次调研的重点领域,结果显示“云原生”已成为不可逆趋势:
- 云存储占比大幅提升:49%企业主要采用“纯云存储”,较 2024 年的 30%增长 19 个百分点;而混合存储(37%,-11%)、本地私有存储(10%,-10%)占比显著下降;
- 迁移动机务实化:“维持高可用性”(44%)、“降低成本”(39%)、“提升数据可访问性”(34%)是云迁移的三大核心诉求,其中大企业更倾向通过云迁移实现“现代化改造”与“AI 分析支撑”;
- 存储架构分层明显:55%企业使用数据仓库,47%使用数据湖,27%使用湖仓一体(Lakehouse);大企业(1000+员工)是“湖仓一体”的主要实践者(38%),小企业(<100 人)因规模限制,数据仓库使用率仅 37%(低于整体 55%)。
2. 数据安全:从“工具堆砌”转向“体系化落地”
尽管数据安全的重要性达成共识,但实践呈现“认知与落地脱节”的特点:
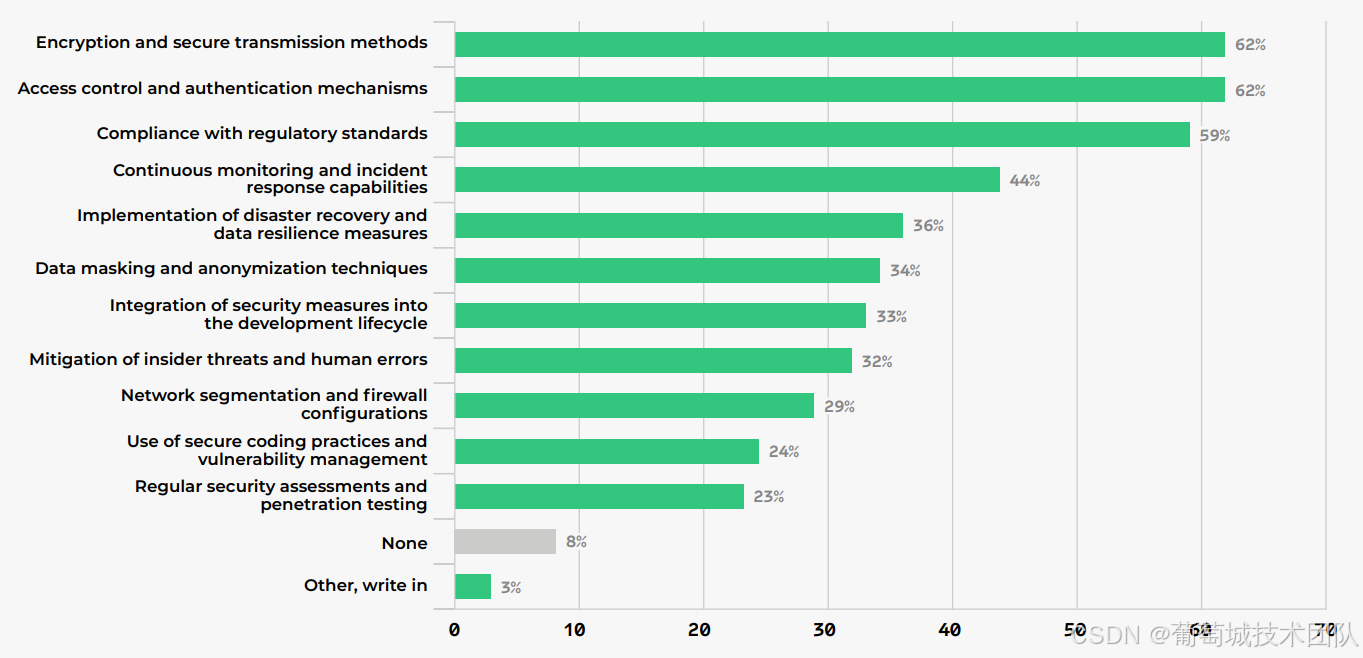
- 核心策略集中:62%企业依赖“加密与安全传输”“访问控制与认证”,59%关注“合规性标准”,三者构成安全实践的“铁三角”;
- 实践 Adoption 下降:与 2024 年相比,“灾难恢复”(-22%)、“数据脱敏”(-21%)、“安全编码”(-22%)等实践的使用率显著下滑,推测与“依赖云厂商默认安全能力”“成本压缩”有关;
- 威胁感知聚焦:60%企业最担忧“数据泄露”,50%关注“认证与访问控制失效”,43%警惕“不安全数据处理”,中小企业对“弱加密”的担忧更突出(40%,高于大企业 17%)。
3. 数据管道:从“批量离线”转向“实时 AI 适配”
数据管道是支撑 AI 落地的核心环节,调研显示其正在向“实时化、AI 原生”转型:
- ETL 工作量高企:从业者平均 30%工作时间用于 ETL/ELT,大企业(35%)与小企业(33%)耗时更高,中型企业(20%)因流程成熟度居中;
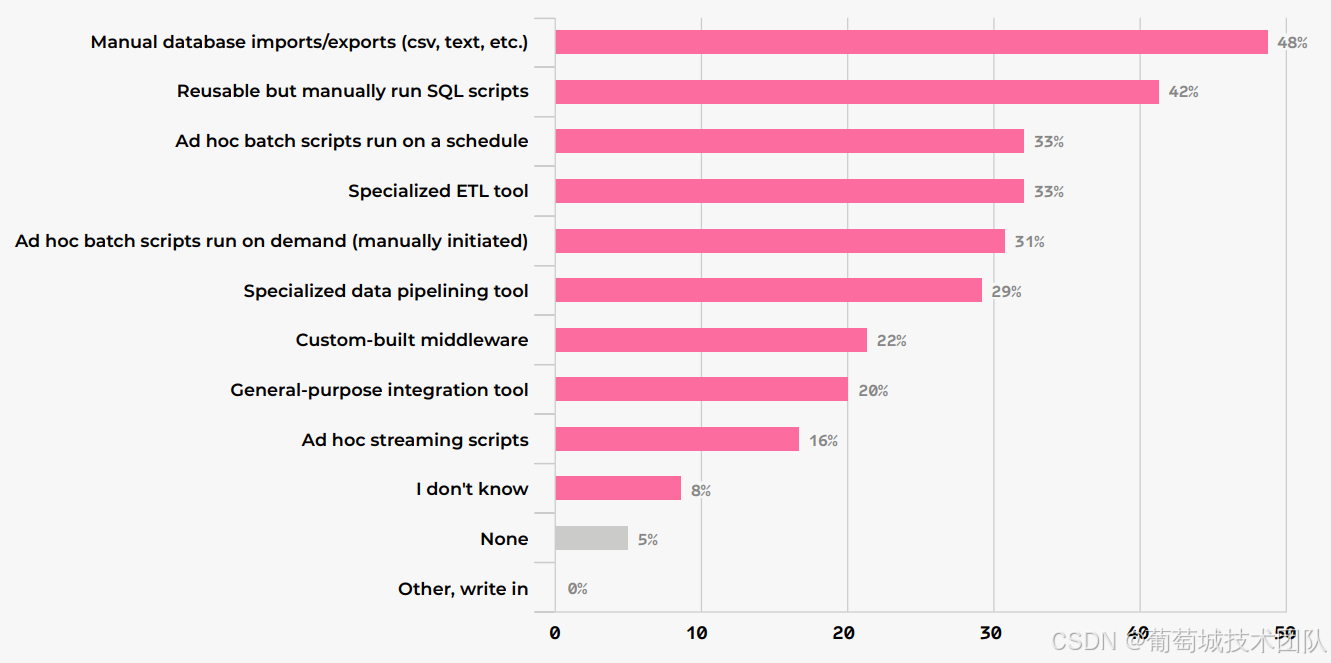
- 工具选型分化:48%企业仍依赖“手动数据库导入/导出”,33%使用“专业 ETL 工具”(较 2024 年下降 11%);大企业更偏好专业工具(40%),小企业则依赖“临时批处理脚本”(43%);
- AI 数据准备待加强:仅 18%从业者“非常自信”于 AI/ML 数据准备最佳实践,39%通过“API 实时供数”支撑生成式 AI,36%使用向量数据库实现 RAG(检索增强生成),但小企业的数据质量实践覆盖率显著低于大企业。
三、专家洞见:来自行业一线的实践指南
报告收录了微软、Netflix、Factorial 等企业专家的深度解读,核心聚焦三大方向:
1. 数据架构的“融合与开放”:湖仓一体+开放表格式
Factorial 工程 VP Miguel Garcia Lorenzo 指出,传统数据湖、仓库的边界正在消失,基于开放表格式(如 Apache Iceberg)的湖仓一体成为主流:
- Iceberg 凭借“引擎中立性”“隐藏分区”“元数据管理”优势,成为多引擎(Trino、Flink、DuckDB)共享数据的统一层;
- 现代架构采用“多引擎策略”:DuckDB 用于嵌入式边缘分析,Trino 用于跨源联邦查询,ClickHouse 用于实时 OLAP,实现“存储与计算解耦”。
2. AI 原生架构的“底层重构”
微软产品经理 Abhishek Gupta 强调,AI 原生架构与传统架构存在本质差异(如下表),需从“数据类型、处理模式、存储选型”全链路重构:
| 维度 | 传统架构 | AI 原生架构 |
|---|---|---|
| 数据类型 | 结构化数据 | 文本、图像等多模态数据 |
| 处理模式 | 批量 ETL | 实时流+批量混合 |
| 延迟要求 | 小时级-天级 | 毫秒级-秒级 |
| 存储核心 | 数据仓库(星型模型) | 数据湖+向量库+特征库 |
| 查询模式 | SQL 分析 | 向量相似性搜索+传统查询 |
3. 实时系统的“DataOps 落地”
Netflix 高级工程师 Tulika Bhatt 分享了实时数据系统的 DataOps 实践:
- schema 版本化:通过 Avro/Protobuf 定义 schema,结合 Apicurio Schema Registry 实现兼容性校验;
- CI/CD 全自动化:将 Flink 作业、配置文件纳入 Git 管理,通过 GitHub Actions 实现“构建-测试-灰度部署”;
- 可观测性体系:聚焦 Kafka 消费延迟、Flink checkpoint 时长等核心指标,通过 Prometheus+Grafana 建立业务告警。
四、报告价值:为不同角色提供行动指南
1. 数据工程师:明确工具与技能优先级
- 工具选型:优先掌握 Python 生态、Apache Iceberg、Kafka/Pulsar 流处理,以及 Prometheus/Grafana 可观测性工具;
- 技能升级:补充向量数据库(Pinecone、Weaviate)、RAG 数据准备、DataOps 自动化等 AI 相关能力。
2. 架构师:把握技术选型的“平衡术”
- 存储层:中小企业可从“云存储+数据仓库”起步,大企业推进“湖仓一体+开放表格式”;
- 安全层:避免“工具堆砌”,聚焦“加密+访问控制+合规”核心,借力云厂商安全能力降低成本;
- 管道层:根据规模选择“专业 ETL 工具(大企业)”或“脚本+轻量工具(中小企业)”,逐步推进自动化。
3. 技术管理者:平衡“创新与成本”
- 资源倾斜:向“实时数据管道”“AI 数据质量”等核心环节倾斜预算,优先解决“数据可用性”问题;
- 团队协同:建立“数据工程师+数据科学家+ML 工程师”跨职能团队,通过 Feature Store、数据目录实现协作效率提升。
五、总结:数据工程的未来三大关键词
- 云原生深化:纯云存储将持续替代混合/本地存储,云厂商的“Serverless+托管服务”成为中小企业首选;
- AI 驱动重构:向量数据库、实时流处理、开放表格式成为 AI 原生架构的“基础设施”,数据工程与 AI 工程的边界进一步模糊;
- DataOps 常态化:实时系统的“自动化部署、可观测性、版本控制”将成为标配,推动数据工程从“手工运维”转向“工程化交付”。
如需深入探索,可参考报告附录的“解决方案目录”——涵盖 DataStax Astra DB(AI 原生 NoSQL)、Langflow(LLM 可视化构建)、Apache Kafka(流处理)等 100+工具的选型指南,为实践落地提供直接参考。
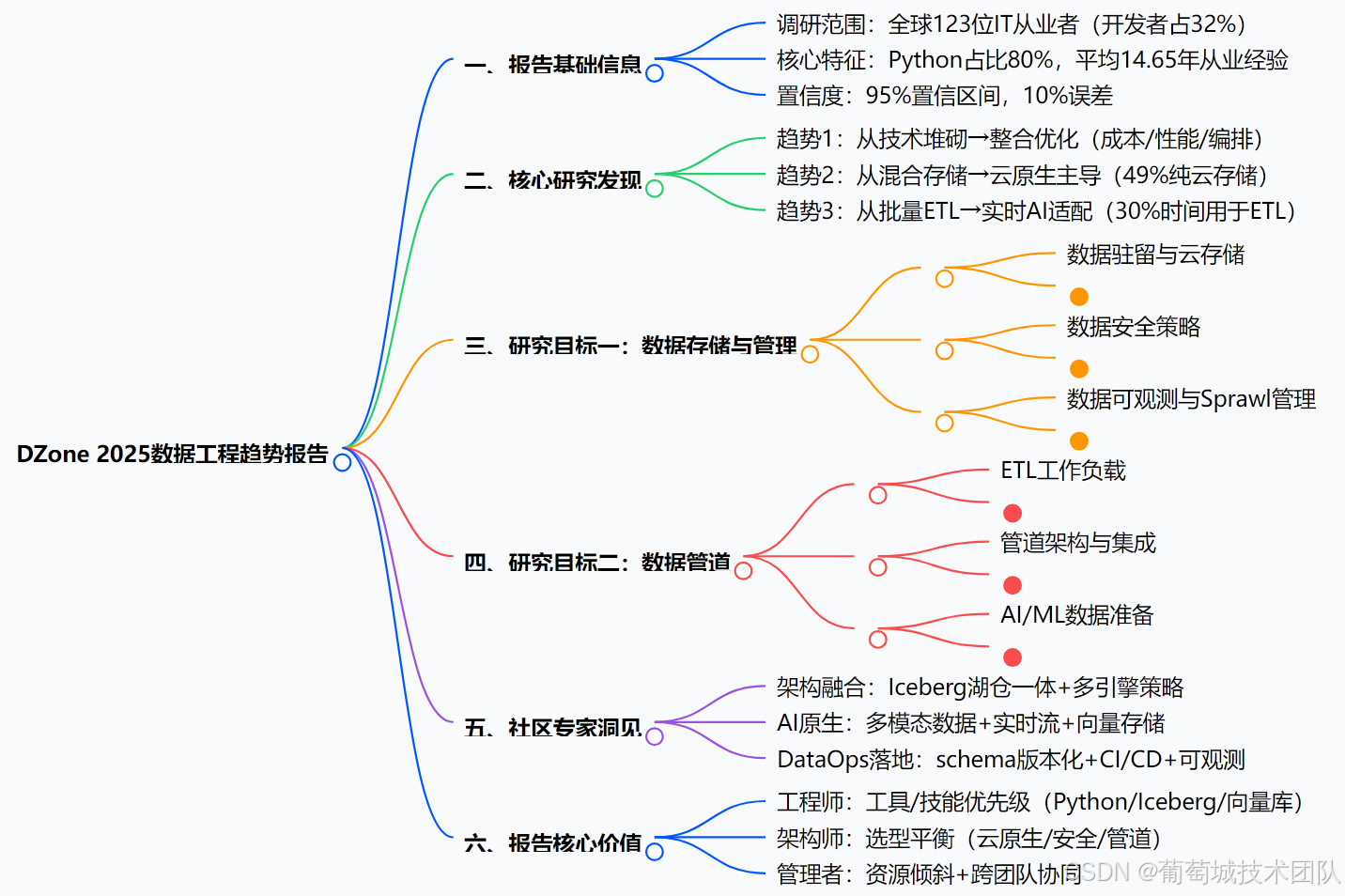
附:报告核心内容脑图大纲
下载地址