第十六周周报
文章目录
- 摘要
- Abstract
- Multi-Head Self-attention
- 位置编码
- 编码器和解码器的主要区别
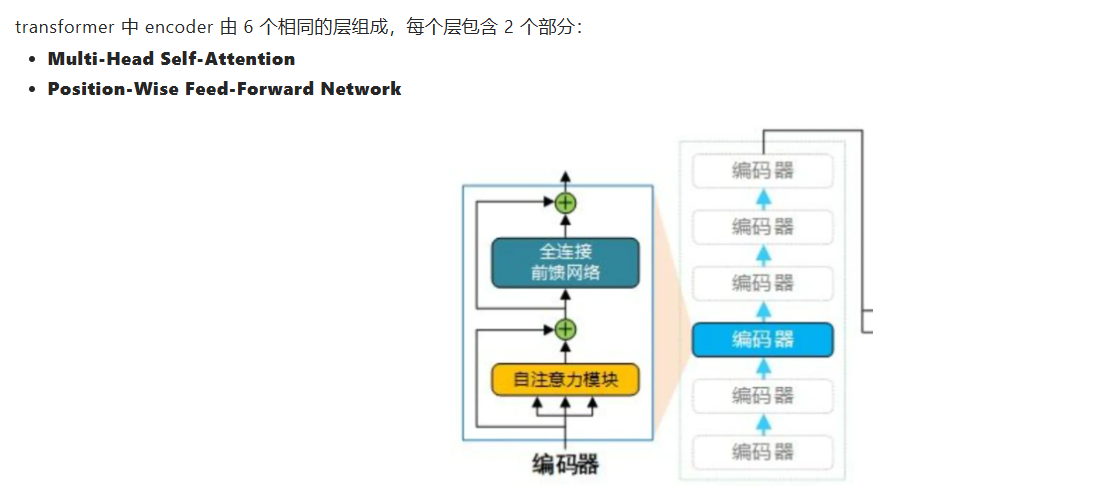
- encoder
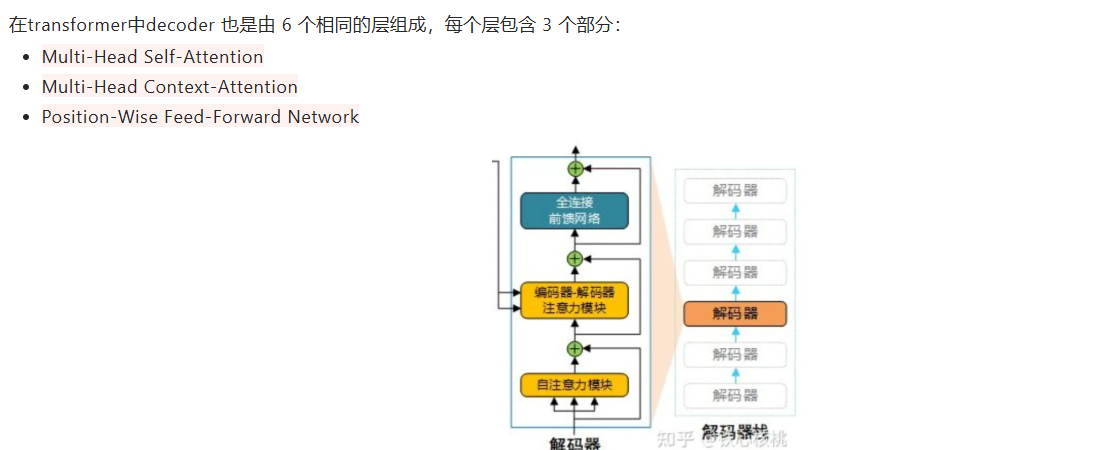
- decoder
- Difference
- 总结
摘要
在上周深入掌握词嵌入、自注意力机制及QKV计算原理的基础上,本周我进一步探究了多头注意力机制如何并行捕捉序列中不同维度的关联信息,并理解了前馈网络在特征非线性变换与增强中的作用。了解了位置编码的相关内容。通过对比分析,我重点辨析了编码器在上下文语义表示与解码器在自回归生成任务中的核心功能差异及结构设计特点,从而对Transformer模型的整体架构和工作机制建立了更为系统全面的认识。
Abstract
Based on the in-depth understanding of word embedding, self attention mechanism and Qkv computing principle last week, this week I further explored how the multi head attention mechanism can capture the correlation information of different dimensions in a sequence in parallel, and understood the role of feedforward network in feature nonlinear transformation and enhancement. Through the comparative analysis, I focus on the differences of the core functions and structural design features between the encoder in the context semantic representation and the decoder in the autoregressive generation task, so as to establish a more systematic and comprehensive understanding of the overall architecture and working mechanism of the transformer model
Multi-Head Self-attention
在 Self-Attention 中,所有词向量都会通过同一组参数矩阵映射到同一个语义空间来计算相关性,这意味着它只能从一种角度去衡量词与词之间的关系,而语言中的依赖往往多层次、多维度,比如既有语法关系又有语义关系,单一空间就可能导致模型只捕捉到某一种主导关系而忽略其他重要联系,从而限制了表达能力。例如每次计算都是在同一个语义空间里完成的,可能只能捕捉一种类型的关系(比如语法关系),而忽视了其他信息(比如语义、位置、句法)。
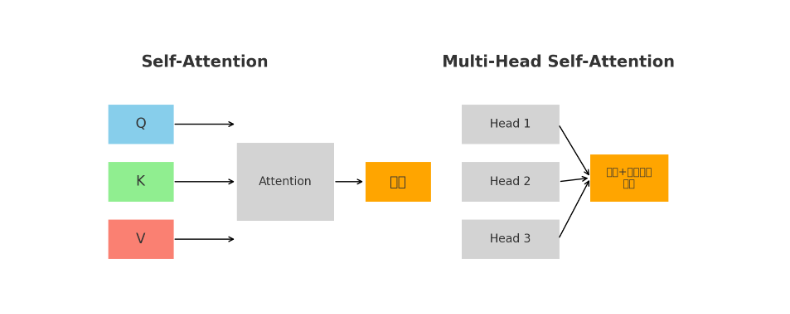
为了解决Self-Attention 中单一空间限制的弊端,于是我们引入了mulit-head Self-attention。
多头自注意力机制(Mulit-head Self-attention)是在自注意力的基础上引入多个并行的注意力头,每个头通过不同的参数矩阵把输入映射到不同的子空间中独立计算注意力,再将这些结果拼接并线性变换,从而使模型能够从多个角度同时捕捉序列中词与词之间的多样化依赖关系,获得更丰富、更全面的表示。
多头自注意力机制的 head 数 并不是一个固定的理论值,而是一个超参数,需要在 模型规模、计算资源和任务需求 之间权衡来确定。一般来说,head 数的选择遵循以下规律:
在 Transformer 里,隐藏维度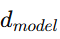 会被均分给每个head上,即每个head的维度通常是
会被均分给每个head上,即每个head的维度通常是
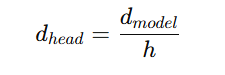
因此head的数量h需要能整除,否则没办法均分。例如GPT-3的每一个向量是12288维,需要有96个head,每一个向量被分为96个128维的向量。
下面以2个head的情况加以介绍,
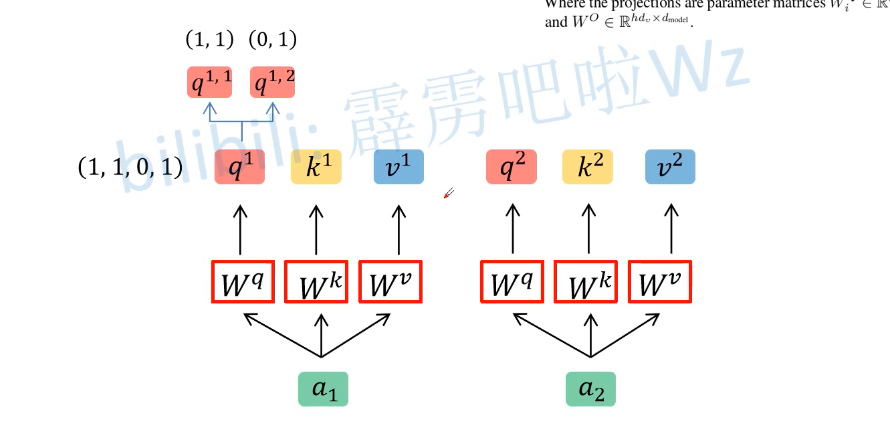
我们将输入向量ai分别与参数矩阵Wq、Wk、Wv相乘得到Qi、Ki、Vi,然后再将得到的Qi、Ki、
Vi进行数据拆分,如上图所示,得到Q1为(1,1,0,1),head数h=2,于是就将Q1进行线性映射(线性映射实质上就是对Q1进行均分),得到q11(1,1)和q12(0,1)。
将新得到的下标为1的分为一组作为head1,将下标为2的分为另外一组作为head2
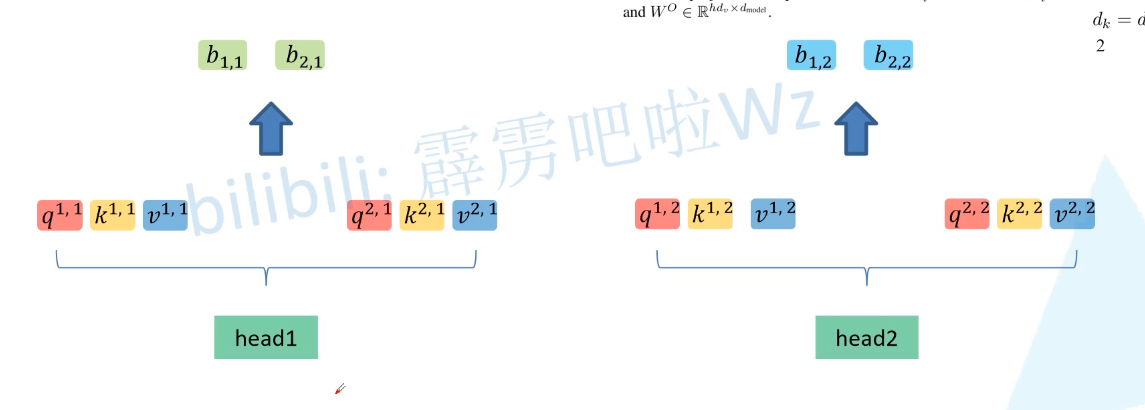
接下来需要对结果进行拼接(将b11与b12拼接(第一个向量输出的head),b21和b22进行拼接(第二个向量输出的)),然后再对每个拼接结果分别乘上同一个 𝑊O得到最终输出。
位置编码
Transformer 的核心运算是 Self-Attention。它的好处是能捕捉任意两个 token(输入向量)之间的依赖关系,而不受距离限制。Self-Attention 本身是 无序的 —— 它把输入序列看成一个集合(set),没有顺序信息。比如输入 “I love NLP”和“NLP love I”,在 Self-Attention 里,如果没有额外机制,它们会被当成一样的输入,因为 attention 只会根据向量之间的相似度来算关系。所以必须引入 位置编码(Positional Encoding),来告诉模型 token 在序列里的位置。


编码器和解码器的主要区别
encoder
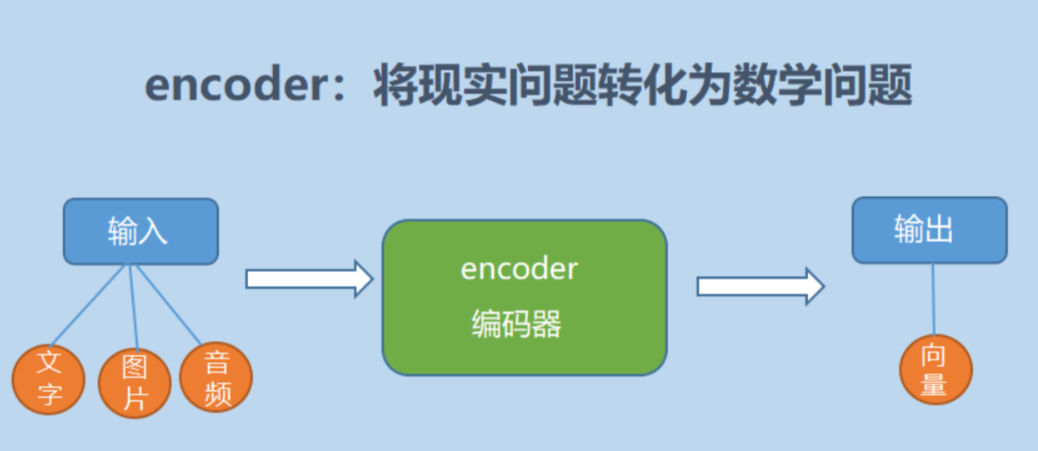
encoder,也就是编码器,负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,然后进行编码,或进行特征提取(可以看做更复杂的编码)。
简单来说就是机器读取数据的过程,将现实问题转化成数学问题
decoder
也就是解码器,负责根据encoder部分输出的语义向量c来做解码工作。以翻译为例,就是生成相应的译文。
Difference
(1)第一级中: 将self attention 模块加入了Masked模块,变成了 Masked self-attention, 这样以来就只考虑解码器的当前输入和当前输入的左侧部分, 不考虑右侧部分; ( 注意,第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。)
(2)第二级中:引入了 Cross attention 交叉注意力模块, 在 masked self-attention 和全连接层 之间加入;
(3)Cross attention 交叉注意力模块的输入 Q,K,V 不是来自同一个模块,K,V 来自编码器的输出, Q来自解码器的输出;
【注意】 解码器的输出一个一个产生的
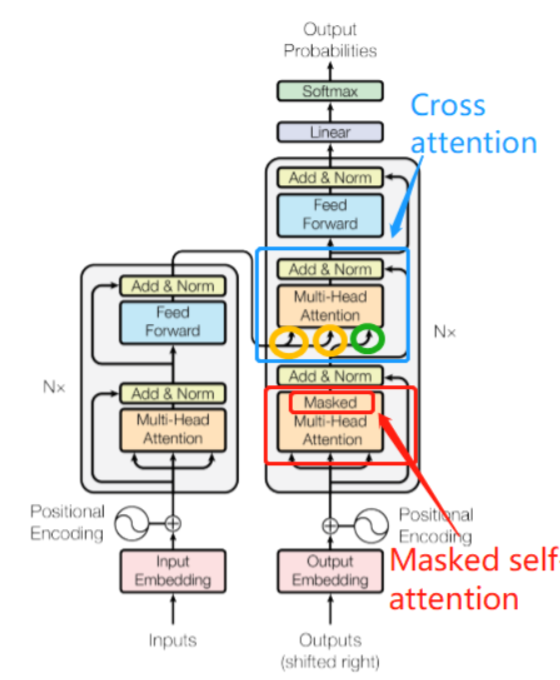
其中新出现的Masked self attention模块
例如,1300个token,其中第一个token只能和自己进行信息聚合、第二个只能和本身及前一个进行信息聚合,以此类推……

总结
本周主要对上周未完成的transformer的相关知识进行补充学习,明白了mulit-head Self-attention的工作原理、对比了其与Self-attention的不同之处;明白了位置编码对于transformer的重要性;学习了transformer的结构,重点掌握了编码器和解码器之间的区别。