【卷积神经网络详解与实例】7——经典CNN之AlexNet
1 开发背景
AlexNet网络于2012年问世,是深度学习发展史上的里程碑事件。它的诞生并非偶然,而是技术积累、数据爆发、算力突破和学术竞赛共同作用的结果。
一、核心背景:深度学习的低谷与复兴
-
神经网络的历史沉寂
-
20世纪80-90年代,神经网络(如多层感知机)因计算能力不足、数据稀缺、训练困难(如梯度消失)等问题,被支持向量机(SVM)等传统机器学习方法超越,进入“AI寒冬”。
-
2006年,Geoffrey Hinton提出深度信念网络(DBN),通过无监督预训练缓解梯度消失问题,为深度学习复兴奠定理论基础。
-
-
卷积神经网络(CNN)的早期探索
-
1998年,Yann LeCun提出LeNet-5,成功用于手写数字识别(MNIST数据集),但因当时算力限制,未能扩展到更复杂任务。
-
此后十年,CNN在学术界进展缓慢,主流计算机视觉依赖人工设计特征(如SIFT、HOG)+ 分类器(如SVM)的流程,算法的鲁棒性存在较大的问题。(从AlexNet开始,特征变得可以学习,而不是人工设计。)
-
二、关键催化剂:ImageNet竞赛的诞生
-
数据瓶颈的突破
-
2009年,斯坦福大学教授李飞飞团队发布ImageNet大规模视觉数据库,包含1400万张标注图像、2万类别,其中用于竞赛的子集(1000类、120万张图像)成为深度学习的“燃料”。
-
意义:首次提供足够规模的高质量标注数据,使深度模型训练成为可能。
-
-
ImageNet大规模视觉识别挑战赛(ILSVRC)
-
2010年起,ILSVRC成为计算机视觉领域的“奥林匹克”,评测算法在图像分类、定位等任务上的性能。
-
2010-2011年冠军:传统方法(如SIFT+线性SVM)的Top-5错误率约26.2%,技术陷入瓶颈。
-
三、技术突破:AlexNet的核心创新
AlexNet由多伦多大学的Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton设计,在2012年ILSVRC中以Top-5错误率15.3%(远超第二名的26.2%)夺冠,其技术突破包括:
-
深度网络架构
-
8层网络(5个卷积层+3个全连接层),远超LeNet-5的5层,证明深度模型的有效性。
-
首次使用ReLU激活函数:替代传统Sigmoid/Tanh,解决梯度消失问题,加速收敛(训练速度提升数倍)。
-
-
工程化创新
-
GPU并行训练:利用两块NVIDIA GTX 580 GPU(共3GB显存)实现分布式训练,将单次训练时间从数周缩短至5-6天。
-
Dropout正则化:以50%概率随机丢弃神经元,减少过拟合,提升泛化能力。
-
数据增强:通过随机裁剪、水平翻转、颜色扰动等操作,将训练数据量扩充至2048倍,缓解过拟合。
-
-
优化技巧
-
局部响应归一化(LRN):模仿生物神经系统的侧抑制机制,增强泛化性(后被批归一化取代)。
-
重叠池化(Overlapping Pooling):步长小于窗口尺寸,减少过拟合,提升精度。
-
四、硬件与算力的革命性进步
-
GPU的普及:2010年前后,NVIDIA推出CUDA编程框架,使GPU通用计算成为可能。AlexNet首次将GPU大规模用于深度学习,单GPU算力达1.5 TFLOPS,远超CPU(约0.1 TFLOPS)。
-
显存技术:GTX 580的3GB显存支持更大batch size和更深层网络训练。
五、学术与产业的连锁反应
-
深度学习革命的引爆点
-
AlexNet的胜利证明:深度模型+大数据+GPU的组合可颠覆传统方法,直接催生“深度学习”浪潮。
-
2012年后,ILSVRC冠军均被深度学习模型垄断(如2014年VGG、GoogLeNet,2015年ResNet)。
-
-
产业生态重构
-
巨头入局:Google、Facebook、微软等迅速组建AI团队,收购初创公司(如Google收购Hinton的DNNresearch)。
-
硬件竞赛:NVIDIA转向AI芯片研发,推出Tesla系列GPU;后续TPU、专用AI芯片兴起。
-
开源框架涌现:Theano、Caffe(2013)、TensorFlow(2015)、PyTorch(2016)等工具降低开发门槛。
-
六、历史意义:为何AlexNet是转折点?
| 维度 | AlexNet之前 | AlexNet之后 |
|---|---|---|
| 主流方法 | 人工特征+SVM等浅层模型 | 端到端深度学习 |
| 数据依赖 | 小规模数据集(如MNIST仅6万张) | 大规模数据集(ImageNet超百万张) |
| 算力基础 | CPU单机训练 | GPU集群并行训练 |
| 学术焦点 | 特征工程 | 网络架构设计与优化 |
| 产业应用 | 有限(如OCR) | 广泛(图像识别、自动驾驶、医疗等) |
AlexNet的问世是理论突破(ReLU、Dropout)、数据革命(ImageNet)、算力飞跃(GPU) 三大要素的交汇点。它不仅刷新了计算机视觉的精度纪录,更重新定义了人工智能的研究范式——从“人工设计规则”转向“数据驱动学习”,直接开启了深度学习的黄金时代。正如Hinton所言:“深度学习不是突然出现的,但AlexNet让世界突然相信了它。”
2 网络结构
2.1 整体结构
AlexNet网络结构相对简单,使用了8层卷积神经网络(不包括学习层,即除了三个池化层一共8层),前5层是卷积层,剩下的3层是全连接层,具体如下所示:
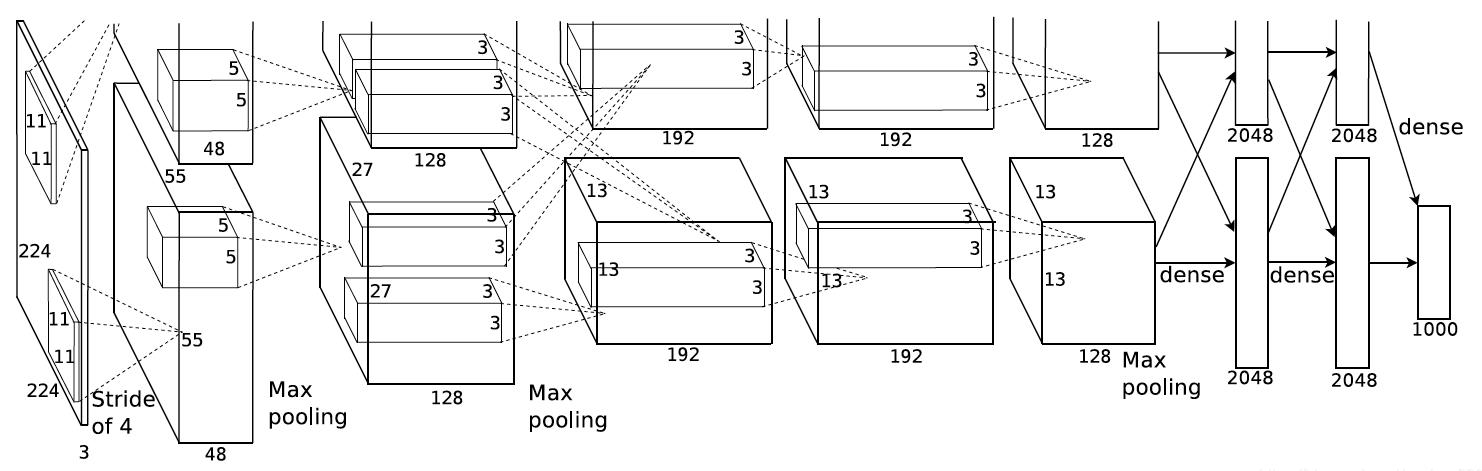
上图包含了GPU通信的部分。这是由当时GPU内存的限制引起的,作者使用两块GPU进行计算,因此分为了上下两部分。
但是,以目前GPU的处理能力,单GPU足够了,因此现代的AlexNet网络结构图可以如下所示:
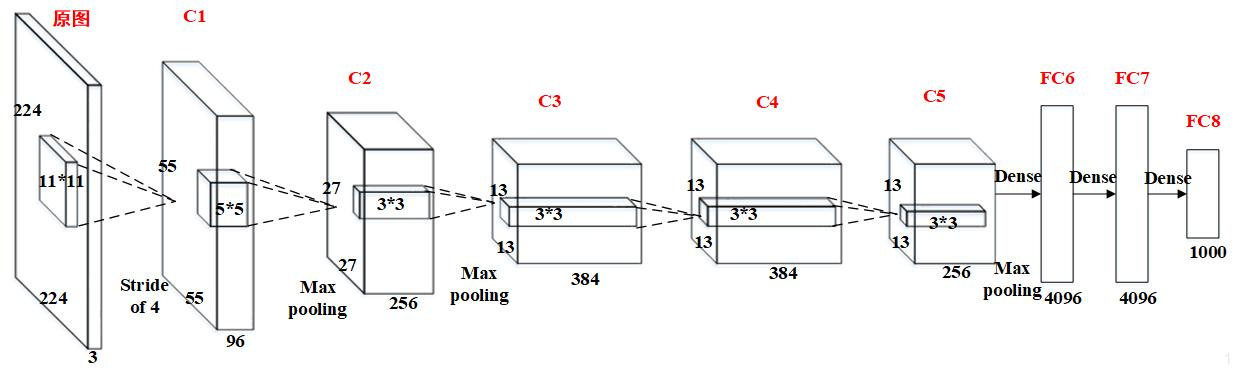
值得注意的一点:原图输入224 × 224,实际上进行了随机裁剪,实际大小为227 × 227。
AlexNet与LeNet结构图的对比如下:

2.2 具体参数
AlexNet原始架构包含8个学习层 - 5个卷积层和3个全连接层。下面是详细的架构描述:
输入层:接受224×224×3的RGB图像(在FashionMNIST中调整为227×227×1的灰度图像)
卷积层1:96个11×11的卷积核,步长4,使用ReLU激活
最大池化层1:3×3池化窗口,步长2
卷积层2:256个5×5的卷积核,padding=2,使用ReLU激活
最大池化层2:3×3池化窗口,步长2
卷积层3:384个3×3的卷积核,padding=1,使用ReLU激活
卷积层4:384个3×3的卷积核,padding=1,使用ReLU激活
卷积层5:256个3×3的卷积核,padding=1,使用ReLU激活
最大池化层3:3×3池化窗口,步长2
全连接层1:4096个神经元,使用ReLU激活,Dropout=0.5
全连接层2:4096个神经元,使用ReLU激活,Dropout=0.5
全连接层3(输出层):1000个神经元(在FashionMNIST中调整为10个)
以FashionMNIST中手写数字识别为例:
-
C1:卷积——ReLU——池化
-
卷积层1:
-
输入:227×227×1
-
96个11×11卷积核
-
stride = 4
-
不扩充边缘padding = 0
-
FeatureMap 大小为:55×55×96 因为(227-11+0×2 + 4)/4= 55
-
参数数量 = (11×11×1 + 1偏置)×96 = 11,712
-
-
最大池化层1:
-
池化核大小3 × 3
-
不扩充边缘padding = 0
-
步长stride = 2
-
FeatureMap 大小为(55-3+0×2+2)/2=27, 即C1输出为27×27×96(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为27×27×48)
-
-
-
C2:卷积——ReLU——池化
-
卷积层2:
-
输入:27×27×96 (经过池化后尺寸)
-
256个5×5×96卷积核(96是卷积核的深度)
-
扩充边缘padding = 2
-
步长stride = 1
-
FeatureMap 大小为(27-5+2×2+1)/1 = 27,即27×27×256
-
参数数量 = (5×5×96 + 1)×256 = 614,656
-
-
最大池化层2:
-
池化核大小3 × 3
-
不扩充边缘padding = 0
-
步长stride = 2
-
FeatureMap 大小为(27-3+0+2)/2=13, 即C2输出为13×13×256(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为13×13×128)
-
-
-
C3:卷积——ReLU
-
卷积层3:
-
输入:13×13×256
-
384个3×3×256卷积核
-
扩充边缘padding = 1
-
步长stride = 1
-
FeatureMap大小为(13-3+1×2+1)/1 = 13,即13×13×384
-
参数数量 = (3×3×256 + 1)×384 = 885,120
-
-
-
C4:卷积——ReLU
-
卷积层4:
-
输入:13×13×384
-
384个3×3×384卷积核
-
扩充边缘padding = 1
-
步长stride = 1
-
其FeatureMap大小为(13-3+1×2+1)/1 = 13,即13×13×384
-
参数数量 = (3×3×384 + 1)×384 = 1,327,488
-
-
-
C5:卷积——ReLU——池化
-
卷积层5:
-
输入:13×13×384
-
256个3×3×384卷积核
-
扩充边缘padding = 1
-
步长stride = 1
-
FeatureMap大小为(13-3+1×2+1)/1 = 13,即13×13×256
-
参数数量 = (3×3×384 + 1)×256 = 884,992
-
-
最大池化层3:
-
池化核大小3 × 3
-
不扩充边缘padding = 0
-
步长stride = 2
-
FeatureMap 大小为(13-3+0×2+2)/2=6, 即C5输出为6×6×256(此处未将输出分到两个GPU中,若按照论文将分成两组,每组为6×6×128)
-
-
-
FC6:全连接——ReLU——Dropout
-
全连接层1:
-
输入:6×6×256 = 9216
-
4096个6×6×256的卷积核
-
不扩充边缘padding = 0
-
步长stride = 1
-
FeatureMap大小为(6-6+0×2+1)/1 = 1,即1×1×4096
-
Dropout:全连接层中去掉了一些神经节点,达到防止过拟合,FC6输出为1×1×4096;
-
参数数量 = (9216 + 1)×4096 = 37,752,832
-
-
-
FC7:全连接——ReLU——Dropout
-
全连接层2:
-
输入1×1×4096
-
Dropout:全连接层中去掉了一些神经节点,达到防止过拟合,FC7输出为1×1×4096
-
参数数量 = (4096 + 1)×4096 = 16,781,312
-
-
-
FC8:全连接——softmax
-
全连接层3:
-
输入1×1×4096
-
MNIST手写数字识别:softmax为10,FC8输出为1×1×10,参数数量 = (4096 + 1)×10 = 40,970
-
-
总参数数量验证
| 层 | 参数数量 | 累计参数量 |
|---|---|---|
| C1 | 11,712 | 11,712 |
| C2 | 614,656 | 626,368 |
| C3 | 885,120 | 1,511,488 |
| C4 | 1,327,488 | 2,838,976 |
| C5 | 884,992 | 3,723,968 |
| FC6 | 37,752,832 | 41,476,800 |
| FC7 | 16,781,312 | 58,258,112 |
| FC8 | 40,970 | 58,299,082 |
如果是ImageNet 1000类图像分类任务,则要:
-
将C1层的输入改为224×224×3,并用96个11×11×3卷积核
-
将FC8中改为:softmax为1000,FC8输出为1×1×1000,参数数量 = (4096 + 1)×1000 = 40,97000
| 任务 | C1参数量 | FC8参数量 | 其他层参数量 | 总参数量 |
|---|---|---|---|---|
| MNIST(10类) | 11,712 | 40,970 | 58,246,400 | 58,299,082 |
| ImageNet(1000类) | 34,944 | 4,097,000 | 58,246,400 | 62,378,344 |
Q:经典的神经网络结构有具体的设计思路吗?为什么是这么多层,为什么参数要这样设置,真的只是试出来的吗?
A:经典的神经网络结构是“基于理论直觉和领域知识进行设计,并通过大量实验验证和迭代优化”的产物。
3 创新点
AlexNet的成功主要归功于以下几个创新点:
-
使用ReLU(Rectified Linear Unit)作为激活函数,解决了传统Sigmoid/Tanh激活函数在深层网络中的梯度消失问题。
【前馈神经网络详解与实例】2——激活函数-CSDN博客 https://blog.csdn.net/colus_SEU/article/details/150534855?spm=1001.2014.3001.5501激活函数详解参考以上链接▲
https://blog.csdn.net/colus_SEU/article/details/150534855?spm=1001.2014.3001.5501激活函数详解参考以上链接▲采用修正线性单元(ReLU)的深度卷积神经网络训练时间比等价的tanh单元要快几倍。而时间开销是进行模型训练过程中很重要的考量因素之一。同时,ReLU有效防止了过拟合现象的出现。由于ReLU激活函数的高效性与实用性,使得它在深度学习框架中占有重要地位。
-
为了防止过拟合,AlexNet 引入了数据增强和 Dropout 技术。
数据增强可以通过对图像进行旋转、翻转、裁剪等变换,增加训练数据的多样性,提高模型的泛化能力。
-
采用Dropout技术减少全连接层的过拟合。
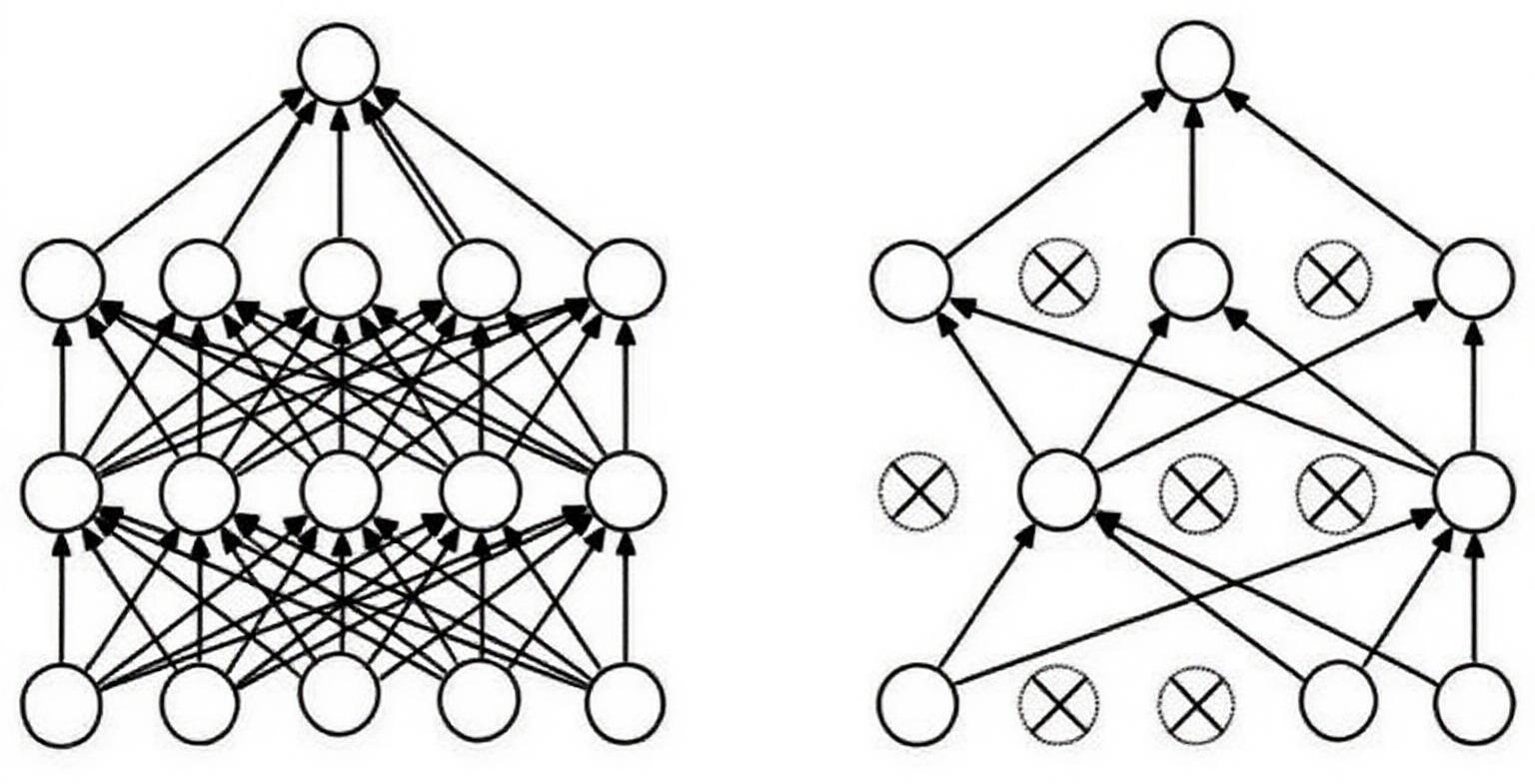
Dropout操作会将概率小于0.5的每个隐层神经元的输出设为0,即去掉了一些神经节点,达到防止过拟合。那些“失活的”神经元不再进行前向传播并且不参与反向传播。这个技术减少了复杂的神经元之间的相互影响。在论文中,也验证了此方法的有效性。
-
使用重叠的最大池化(max pooling)代替传统平均池化,提升了特征不变性。
【卷积神经网络详解与实例】3——池化与反池化操作-CSDN博客https://blog.csdn.net/colus_SEU/article/details/151370006?spm=1001.2014.3001.5501池化操作的详细方法参考以上链接▲以往池化的大小PoolingSize与步长stride一般是相等的,例如:图像大小为256*256,PoolingSize=2×2,stride=2,这样可以使图像或是FeatureMap大小缩小一倍变为128,此时池化过程没有发生层叠。但是AlexNet采用了层叠池化操作,即PoolingSize > stride。这种操作非常像卷积操作,可以使相邻像素间产生信息交互和保留必要的联系。论文中也证明,此操作可以有效防止过拟合的发生。
-
首次在CNN中成功应用GPU加速训练,使得训练大规模深层网络成为可能
AlexNet的出现开启了深度学习在计算机视觉领域的新纪元,为后续各种CNN架构(如VGG、ResNet等)的发展奠定了基础。
4 基于Pytorch实现
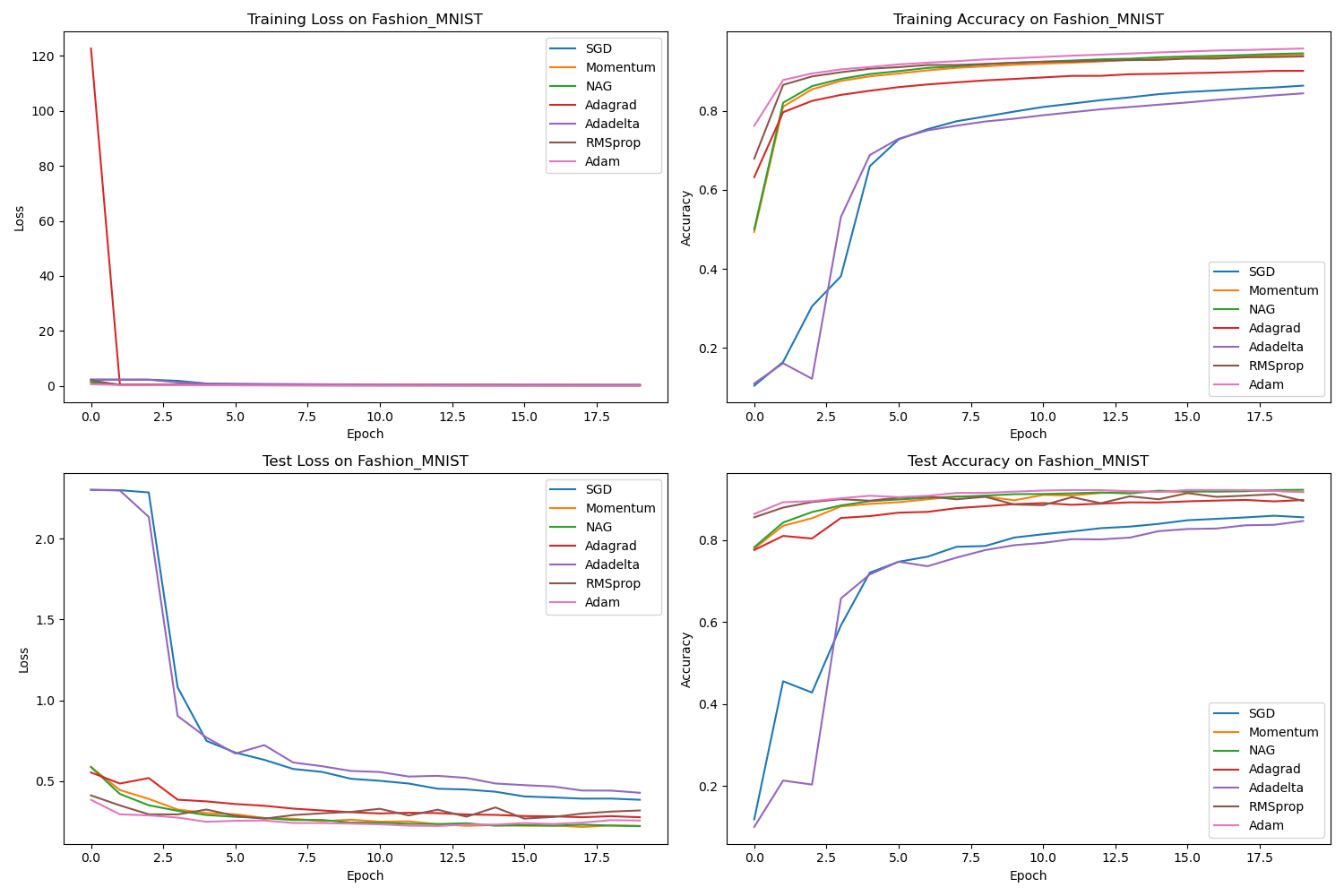
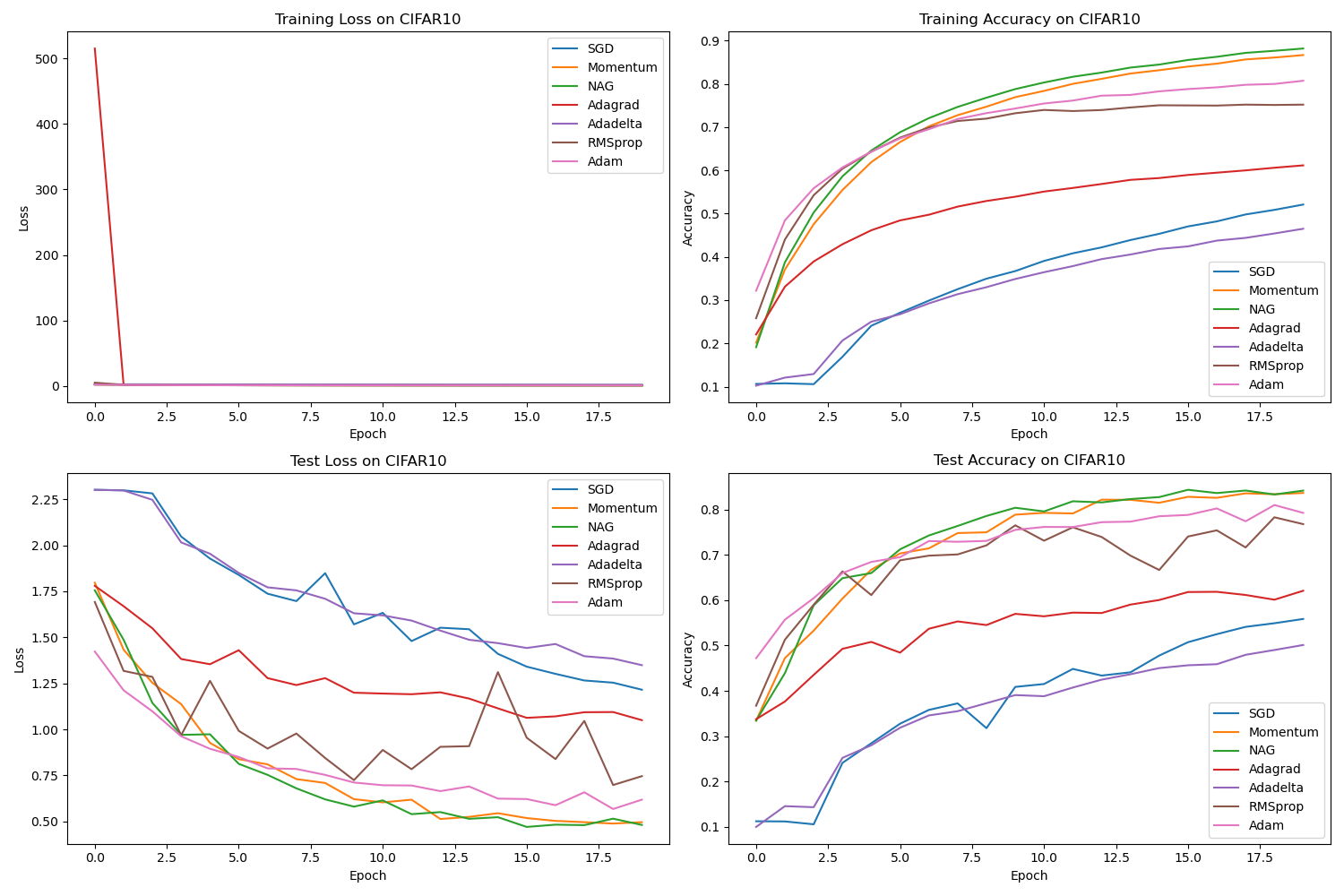
以下项目实现了 AlexNet 网络,并在 CIFAR10 和 Fashion-MNIST 上验证了改网络的有效性,最后还比较了不同优化器对网络的影响!
项目目录如下:
alexnet_project/├── main.py # 主程序入口├── config.py # 配置参数├── models/│ └── alexnet.py # AlexNet模型定义├── data/│ └── data_loader.py # 数据加载和预处理└── utils/├── optimizer_utils.py # 优化器工具└── visualization.py # 可视化工具具体代码如下:
配置文件
# config.pyimport osimport torch# 数据集配置DATA_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data')FASHION_MNIST_DIR = os.path.join(DATA_DIR, 'fashion_mnist')CIFAR10_DIR = os.path.join(DATA_DIR, 'cifar10')# 模型配置MODEL_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'models')SAVE_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'saved_models')# 训练配置BATCH_SIZE = 128LEARNING_RATE = 0.01MOMENTUM = 0.9WEIGHT_DECAY = 5e-4EPOCHS = 20# Adam优化器配置ADAM_LR = 0.001 # Adam通常使用较小的学习率ADAM_BETA1 = 0.9ADAM_BETA2 = 0.999ADAM_WEIGHT_DECAY = 1e-4 # Adam的权重衰减通常设置较小# 设备配置DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'# 确保目录存在os.makedirs(DATA_DIR, exist_ok=True)os.makedirs(FASHION_MNIST_DIR, exist_ok=True)os.makedirs(CIFAR10_DIR, exist_ok=True)os.makedirs(MODEL_DIR, exist_ok=True)os.makedirs(SAVE_DIR, exist_ok=True)数据加载(代码会自动下载数据集到data文件夹中)
# data/data_loader.pyimport osimport torchimport torchvisionimport torchvision.transforms as transformsfrom torch.utils.data import DataLoaderfrom config import FASHION_MNIST_DIR, CIFAR10_DIR, BATCH_SIZEdef get_fashion_mnist_loaders():# 定义数据转换transform = transforms.Compose([transforms.Resize((32, 32)), # AlexNet期望至少32x32的输入transforms.Grayscale(num_output_channels=3), # 将灰度图转换为3通道transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])# 下载并加载训练集train_set = torchvision.datasets.FashionMNIST(root=FASHION_MNIST_DIR,train=True,download=True,transform=transform)# 下载并加载测试集test_set = torchvision.datasets.FashionMNIST(root=FASHION_MNIST_DIR,train=False,download=True,transform=transform)# 创建数据加载器train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=False,num_workers=2)# 保存为.pt文件torch.save(train_set, os.path.join(FASHION_MNIST_DIR, 'fashion_mnist_train.pt'))torch.save(test_set, os.path.join(FASHION_MNIST_DIR, 'fashion_mnist_test.pt'))return train_loader, test_loaderdef get_cifar10_loaders():# 定义数据转换transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])# 下载并加载训练集train_set = torchvision.datasets.CIFAR10(root=CIFAR10_DIR,train=True,download=True,transform=transform_train)# 下载并加载测试集test_set = torchvision.datasets.CIFAR10(root=CIFAR10_DIR,train=False,download=True,transform=transform_test)# 创建数据加载器train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True,num_workers=2)test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=False,num_workers=2)# 保存为.pt文件torch.save(train_set, os.path.join(CIFAR10_DIR, 'cifar10_train.pt'))torch.save(test_set, os.path.join(CIFAR10_DIR, 'cifar10_test.pt'))return train_loader, test_loader模型定义
# models/alexnet.pyimport torchimport torch.nn as nnclass AlexNet(nn.Module):def __init__(self, num_classes=10, in_channels=3):super(AlexNet, self).__init__()self.features = nn.Sequential(# 第一个卷积层nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第二个卷积层nn.Conv2d(64, 192, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第三到五个卷积层nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)# 全局平均池化层:将任意尺寸的特征图调整为6x6的固定尺寸self.avgpool = nn.AdaptiveAvgPool2d((6, 6))# 分类模块:全连接层+Dropout,实现分类self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)# 定义数据如何通过网络的每一层,从输入到输出。def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x辅助模块
# utils/optimizer_utils.pyimport torch.optim as optimfrom config import LEARNING_RATE, MOMENTUM, WEIGHT_DECAY, ADAM_LR, ADAM_BETA1, ADAM_BETA2, ADAM_WEIGHT_DECAYdef get_optimizer(model, optimizer_name):if optimizer_name.lower() == 'sgd':return optim.SGD(model.parameters(), lr=LEARNING_RATE, weight_decay=WEIGHT_DECAY)elif optimizer_name.lower() == 'momentum':return optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM, weight_decay=WEIGHT_DECAY)elif optimizer_name.lower() == 'nag':return optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM, nesterov=True, weight_decay=WEIGHT_DECAY)elif optimizer_name.lower() == 'adagrad':return optim.Adagrad(model.parameters(), lr=LEARNING_RATE, weight_decay=WEIGHT_DECAY)elif optimizer_name.lower() == 'adadelta':return optim.Adadelta(model.parameters(), lr=LEARNING_RATE, weight_decay=WEIGHT_DECAY)elif optimizer_name.lower() == 'adam':return optim.Adam(model.parameters(), lr=ADAM_LR, betas=(ADAM_BETA1, ADAM_BETA2), weight_decay=ADAM_WEIGHT_DECAY)#elif optimizer_name.lower() == 'rmsprop':# return optim.RMSprop(model.parameters(), lr=LEARNING_RATE, weight_decay=WEIGHT_DECAY) #结果有问题elif optimizer_name.lower() == 'rmsprop':# 尝试不同的参数组合return optim.RMSprop(model.parameters(), lr=0.001, weight_decay=1e-5, alpha=0.9)else:raise ValueError(f"Unknown optimizer: {optimizer_name}") # utils/visualization.pyimport matplotlib.pyplot as pltfrom matplotlib.animation import FuncAnimationimport osdef plot_results(results, dataset_name, save_dir):"""绘制不同优化器的训练和测试结果Args:results: 包含不同优化器结果的字典dataset_name: 数据集名称save_dir: 保存路径"""plt.figure(figsize=(15, 10))# 绘制训练损失plt.subplot(2, 2, 1)for optimizer_name, result in results.items():plt.plot(result['train_loss'], label=optimizer_name)plt.title(f'Training Loss on {dataset_name}')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()# 绘制训练准确率plt.subplot(2, 2, 2)for optimizer_name, result in results.items():plt.plot(result['train_acc'], label=optimizer_name)plt.title(f'Training Accuracy on {dataset_name}')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()# 绘制测试损失plt.subplot(2, 2, 3)for optimizer_name, result in results.items():plt.plot(result['test_loss'], label=optimizer_name)plt.title(f'Test Loss on {dataset_name}')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()# 绘制测试准确率plt.subplot(2, 2, 4)for optimizer_name, result in results.items():plt.plot(result['test_acc'], label=optimizer_name)plt.title(f'Test Accuracy on {dataset_name}')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.savefig(os.path.join(save_dir, f'{dataset_name}_comparison.png'))plt.close()def create_animation(results, dataset_name, save_dir):"""创建动态可视化图,显示不同优化器的收敛过程Args:results: 包含不同优化器结果的字典dataset_name: 数据集名称save_dir: 保存路径"""# 确定最大epoch数max_epochs = max(len(result['train_loss']) for result in results.values())# 创建图形fig, axs = plt.subplots(2, 2, figsize=(15, 10))fig.suptitle(f'Optimizer Comparison on {dataset_name}')# 初始化线条lines = {}for optimizer_name in results.keys():lines[optimizer_name] = {'train_loss': axs[0, 0].plot([], [], label=optimizer_name)[0],'train_acc': axs[0, 1].plot([], [], label=optimizer_name)[0],'test_loss': axs[1, 0].plot([], [], label=optimizer_name)[0],'test_acc': axs[1, 1].plot([], [], label=optimizer_name)[0]}# 设置坐标轴标签axs[0, 0].set_title('Training Loss')axs[0, 0].set_xlabel('Epoch')axs[0, 0].set_ylabel('Loss')axs[0, 0].legend()axs[0, 1].set_title('Training Accuracy')axs[0, 1].set_xlabel('Epoch')axs[0, 1].set_ylabel('Accuracy')axs[0, 1].legend()axs[1, 0].set_title('Test Loss')axs[1, 0].set_xlabel('Epoch')axs[1, 0].set_ylabel('Loss')axs[1, 0].legend()axs[1, 1].set_title('Test Accuracy')axs[1, 1].set_xlabel('Epoch')axs[1, 1].set_ylabel('Accuracy')axs[1, 1].legend()# 设置坐标轴范围all_train_loss = [loss for result in results.values() for loss in result['train_loss']]all_train_acc = [acc for result in results.values() for acc in result['train_acc']]all_test_loss = [loss for result in results.values() for loss in result['test_loss']]all_test_acc = [acc for result in results.values() for acc in result['test_acc']]axs[0, 0].set_xlim(0, max_epochs)axs[0, 0].set_ylim(0, max(all_train_loss) * 1.1)axs[0, 1].set_xlim(0, max_epochs)axs[0, 1].set_ylim(0, 1)axs[1, 0].set_xlim(0, max_epochs)axs[1, 0].set_ylim(0, max(all_test_loss) * 1.1)axs[1, 1].set_xlim(0, max_epochs)axs[1, 1].set_ylim(0, 1)def init():for optimizer_lines in lines.values():for line in optimizer_lines.values():line.set_data([], [])return [line for optimizer_lines in lines.values() for line in optimizer_lines.values()]def update(frame):for optimizer_name, optimizer_lines in lines.items():result = results[optimizer_name]if frame < len(result['train_loss']):optimizer_lines['train_loss'].set_data(range(frame + 1), result['train_loss'][:frame + 1])optimizer_lines['train_acc'].set_data(range(frame + 1), result['train_acc'][:frame + 1])optimizer_lines['test_loss'].set_data(range(frame + 1), result['test_loss'][:frame + 1])optimizer_lines['test_acc'].set_data(range(frame + 1), result['test_acc'][:frame + 1])return [line for optimizer_lines in lines.values() for line in optimizer_lines.values()]ani = FuncAnimation(fig, update, frames=max_epochs, init_func=init, blit=True, interval=200)# 保存动画ani.save(os.path.join(save_dir, f'{dataset_name}_animation.gif'), writer='pillow', fps=5)plt.close()主函数:模型训练和测试
# main.pyimport osimport timeimport torchimport torch.nn as nnfrom torch.utils.data import DataLoaderimport numpy as npfrom models.alexnet import AlexNetfrom data.data_loader import get_fashion_mnist_loaders, get_cifar10_loadersfrom utils.optimizer_utils import get_optimizerfrom utils.visualization import plot_results, create_animationfrom config import DEVICE, EPOCHS, SAVE_DIRdef train(model, train_loader, optimizer, criterion):model.train()running_loss = 0.0correct = 0total = 0for inputs, labels in train_loader:inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()train_loss = running_loss / len(train_loader)train_acc = correct / totalreturn train_loss, train_accdef test(model, test_loader, criterion):model.eval()running_loss = 0.0correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)outputs = model(inputs)loss = criterion(outputs, labels)running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()test_loss = running_loss / len(test_loader)test_acc = correct / totalreturn test_loss, test_accdef run_experiment(dataset_name, optimizers):print(f"\nRunning experiment on {dataset_name} dataset...")# 获取数据加载器if dataset_name.lower() == 'fashion_mnist':train_loader, test_loader = get_fashion_mnist_loaders()in_channels = 3 # 因为我们将灰度图转换为3通道elif dataset_name.lower() == 'cifar10':train_loader, test_loader = get_cifar10_loaders()in_channels = 3else:raise ValueError(f"Unknown dataset: {dataset_name}")# 定义损失函数criterion = nn.CrossEntropyLoss()# 存储结果results = {}# 对每个优化器进行训练和测试for optimizer_name in optimizers:print(f"\nTraining with {optimizer_name} optimizer...")# 创建模型model = AlexNet(in_channels=in_channels).to(DEVICE)# 获取优化器optimizer = get_optimizer(model, optimizer_name)# 记录训练和测试的损失和准确率train_losses = []train_accs = []test_losses = []test_accs = []# 训练和测试for epoch in range(EPOCHS):start_time = time.time()# 训练train_loss, train_acc = train(model, train_loader, optimizer, criterion)train_losses.append(train_loss)train_accs.append(train_acc)# 测试test_loss, test_acc = test(model, test_loader, criterion)test_losses.append(test_loss)test_accs.append(test_acc)# 打印进度epoch_time = time.time() - start_timeprint(f"Epoch {epoch + 1}/{EPOCHS} - Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, "f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}, Time: {epoch_time:.2f}s")# 保存结果results[optimizer_name] = {'train_loss': train_losses,'train_acc': train_accs,'test_loss': test_losses,'test_acc': test_accs}# 保存模型torch.save(model.state_dict(), os.path.join(SAVE_DIR, f'{dataset_name}_{optimizer_name}_model.pth'))# 绘制结果plot_results(results, dataset_name, SAVE_DIR)# 创建动态可视化create_animation(results, dataset_name, SAVE_DIR)return resultsdef main():# 定义要测试的优化器optimizers = ['SGD', 'Momentum', 'NAG', 'Adagrad', 'Adadelta', 'RMSprop', 'Adam'] # 添加Adam# 在Fashion-MNIST上运行实验fashion_mnist_results = run_experiment('Fashion_MNIST', optimizers)# 在CIFAR-10上运行实验cifar10_results = run_experiment('CIFAR10', optimizers)# 打印最终结果print("\nFinal Results on Fashion-MNIST:")for optimizer_name, result in fashion_mnist_results.items():print(f"{optimizer_name}: Test Accuracy = {result['test_acc'][-1]:.4f}")print("\nFinal Results on CIFAR-10:")for optimizer_name, result in cifar10_results.items():print(f"{optimizer_name}: Test Accuracy = {result['test_acc'][-1]:.4f}")if __name__ == '__main__':main()运行结果:
Final Results on Fashion-MNIST:SGD: Test Accuracy = 0.8560Momentum: Test Accuracy = 0.9178NAG: Test Accuracy = 0.9231Adagrad: Test Accuracy = 0.8982Adadelta: Test Accuracy = 0.8468RMSprop: Test Accuracy = 0.8961Adam: Test Accuracy = 0.9174Final Results on CIFAR-10:SGD: Test Accuracy = 0.5585Momentum: Test Accuracy = 0.8363NAG: Test Accuracy = 0.8415Adagrad: Test Accuracy = 0.6207Adadelta: Test Accuracy = 0.5011RMSprop: Test Accuracy = 0.7676Adam: Test Accuracy = 0.7924