Java基础面试篇(7)
序列化
怎么把一个对象从一个jvm转移到另一个jvm?
使用序列化和反序列化:将对象序列化为字节流,并将其发送到另一个 JVM,然后在另一个 JVM 中反序列化字节流恢复对象。这可以通过 Java 的 ObjectOutputStream 和 ObjectInputStream 来实现。
使用消息传递机制:利用消息传递机制,比如使用消息队列(如 RabbitMQ、Kafka)或者通过网络套接字进行通信,将对象从一个 JVM 发送到另一个。这需要自定义协议来序列化对象并在另一个 JVM 中反序列化。
使用远程方法调用(RPC):可以使用远程方法调用框架,如 gRPC,来实现对象在不同 JVM 之间的传输。远程方法调用可以让你在分布式系统中调用远程 JVM 上的对象的方法。
使用共享数据库或缓存:将对象存储在共享数据库(如 MySQL、PostgreSQL)或共享缓存(如 Redis)中,让不同的 JVM 可以访问这些共享数据。这种方法适用于需要共享数据但不需要直接传输对象的场景。
序列化和反序列化让你自己实现你会怎么做?
Java 默认的序列化虽然实现方便,但却存在安全漏洞、不跨语言以及性能差等缺陷。
无法跨语言: Java 序列化目前只适用基于 Java 语言实现的框架,其它语言大部分都没有使用 Java 的序列化框架,也没有实现 Java 序列化这套协议。因此,如果是两个基于不同语言编写的应用程序相互通信,则无法实现两个应用服务之间传输对象的序列化与反序列化。
容易被攻击:Java 序列化是不安全的,我们知道对象是通过在 ObjectInputStream 上调用 readObject() 方法进行反序列化的,这个方法其实是一个神奇的构造器,它可以将类路径上几乎所有实现了 Serializable 接口的对象都实例化。这也就意味着,在反序列化字节流的过程中,该方法可以执行任意类型的代码,这是非常危险的。
序列化后的流太大:序列化后的二进制流大小能体现序列化的性能。序列化后的二进制数组越大,占用的存储空间就越多,存储硬件的成本就越高。如果我们是进行网络传输,则占用的带宽就更多,这时就会影响到系统的吞吐量。
我会考虑用主流序列化框架,比如FastJson、Protobuf来替代Java 序列化。
如果追求性能的话,Protobuf 序列化框架会比较合适,Protobuf 的这种数据存储格式,不仅压缩存储数据的效果好, 在编码和解码的性能方面也很高效。Protobuf 的编码和解码过程结合.proto 文件格式,加上 Protocol Buffer 独特的编码格式,只需要简单的数据运算以及位移等操作就可以完成编码与解码。可以说 Protobuf 的整体性能非常优秀。
将对象转为二进制字节流具体怎么实现?
其实,像序列化和反序列化,无论这些可逆操作是什么机制,都会有对应的处理和解析协议,例如加密和解密,TCP的粘包和拆包,序列化机制是通过序列化协议来进行处理的,和 class 文件类似,它其实是定义了序列化后的字节流格式,然后对此格式进行操作,生成符合格式的字节流或者将字节流解析成对象。
在Java中通过序列化对象流来完成序列化和反序列化:
ObjectOutputStream:通过writeObject()方法做序列化操作。
ObjectInputStrean:通过readObject()方法做反序列化操作。
只有实现了Serializable或Externalizable接口的类的对象才能被序列化,否则抛出异常!
实现对象序列化:
让类实现Serializable接口:
import java.io.Serializable;public class MyClass implements Serializable {// class code
}创建输出流并写入对象:
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;MyClass obj = new MyClass();
try {FileOutputStream fileOut = new FileOutputStream("object.ser");ObjectOutputStream out = new ObjectOutputStream(fileOut);out.writeObject(obj);out.close();fileOut.close();
} catch (IOException e) {e.printStackTrace();
}实现对象反序列化:
创建输入流并读取对象:
import java.io.FileInputStream;
import java.io.ObjectInputStream;MyClass newObj = null;
try {FileInputStream fileIn = new FileInputStream("object.ser");ObjectInputStream in = new ObjectInputStream(fileIn);newObj = (MyClass) in.readObject();in.close();fileIn.close();
} catch (IOException | ClassNotFoundException e) {e.printStackTrace();
}通过以上步骤,对象obj会被序列化并写入到文件"object.ser"中,然后通过反序列化操作,从文件中读取字节流并恢复为对象newObj。这种方式可以方便地将对象转换为字节流用于持久化存储、网络传输等操作。需要注意的是,要确保类实现了Serializable接口,并且所有成员变量都是Serializable的才能被正确序列化。
设计模式
volatile和sychronized如何实现单例模式
public class SingleTon {// volatile 关键字修饰变量 防止指令重排序private static volatile SingleTon instance = null;private SingleTon(){}public static SingleTon getInstance(){if(instance == null){//同步代码块 只有在第一次获取对象的时候会执行到 ,第二次及以后访问时 instance变量均非null故不会往下执行了 直接返回啦synchronized(SingleTon.class){if(instance == null){instance = new SingleTon();}}}return instance;}
}正确的双重检查锁定模式需要需要使用 volatile。volatile主要包含两个功能。
保证可见性。使用 volatile 定义的变量,将会保证对所有线程的可见性。
禁止指令重排序优化。
由于 volatile 禁止对象创建时指令之间重排序,所以其他线程不会访问到一个未初始化的对象,从而保证安全性。
代理模式和适配器模式有什么区别?
目的不同:代理模式主要关注控制对对象的访问,而适配器模式则用于接口转换,使不兼容的类能够一起工作。
结构不同:代理模式一般包含抽象主题、真实主题和代理三个角色,适配器模式包含目标接口、适配器和被适配者三个角色。
应用场景不同:代理模式常用于添加额外功能或控制对对象的访问,适配器模式常用于让不兼容的接口协同工作。
I/O
Java怎么实现网络IO高并发编程?
可以用 Java NIO ,是一种同步非阻塞的I/O模型,也是I/O多路复用的基础。
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据, 如果使用BIO要想要并发处理多个客户端的i/o,那么会使用多线程模式,一个线程专门处理一个客户端 io,这种模式随着客户端越来越多,所需要创建的线程也越来越多,会急剧消耗系统的性能。
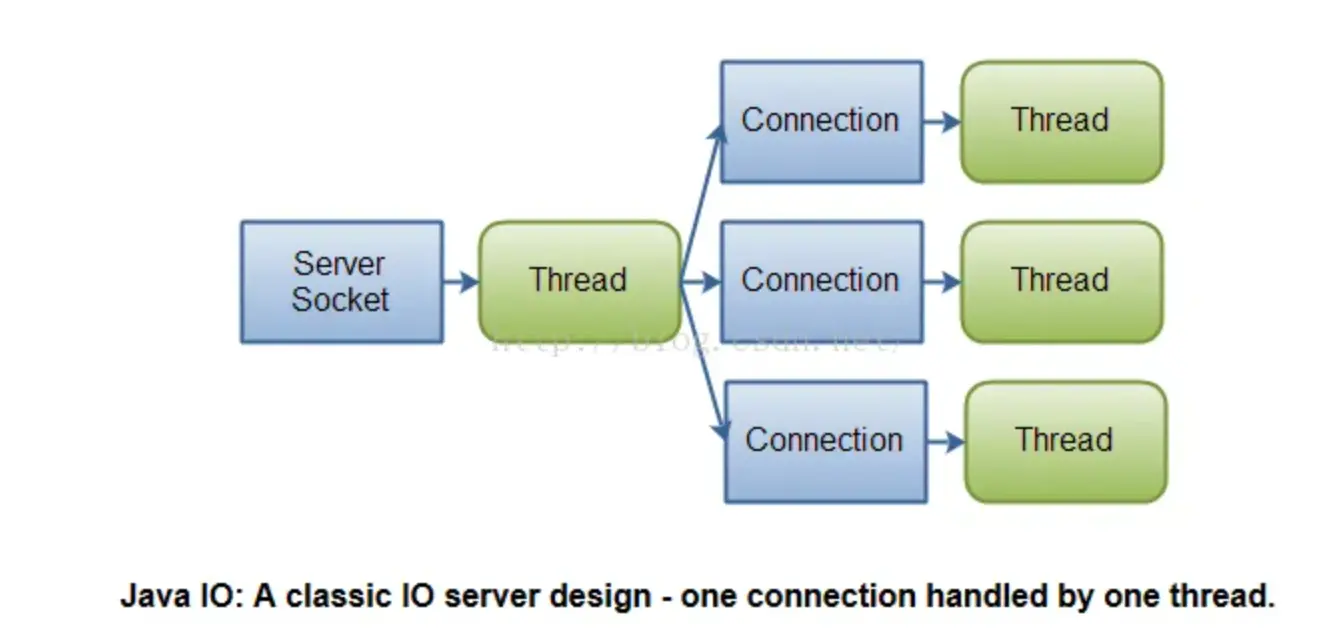
NIO 是基于I/O多路复用实现的,它可以只用一个线程处理多个客户端I/O,如果你需要同时管理成千上万的连接,但是每个连接只发送少量数据,例如一个聊天服务器,用NIO实现会更好一些。
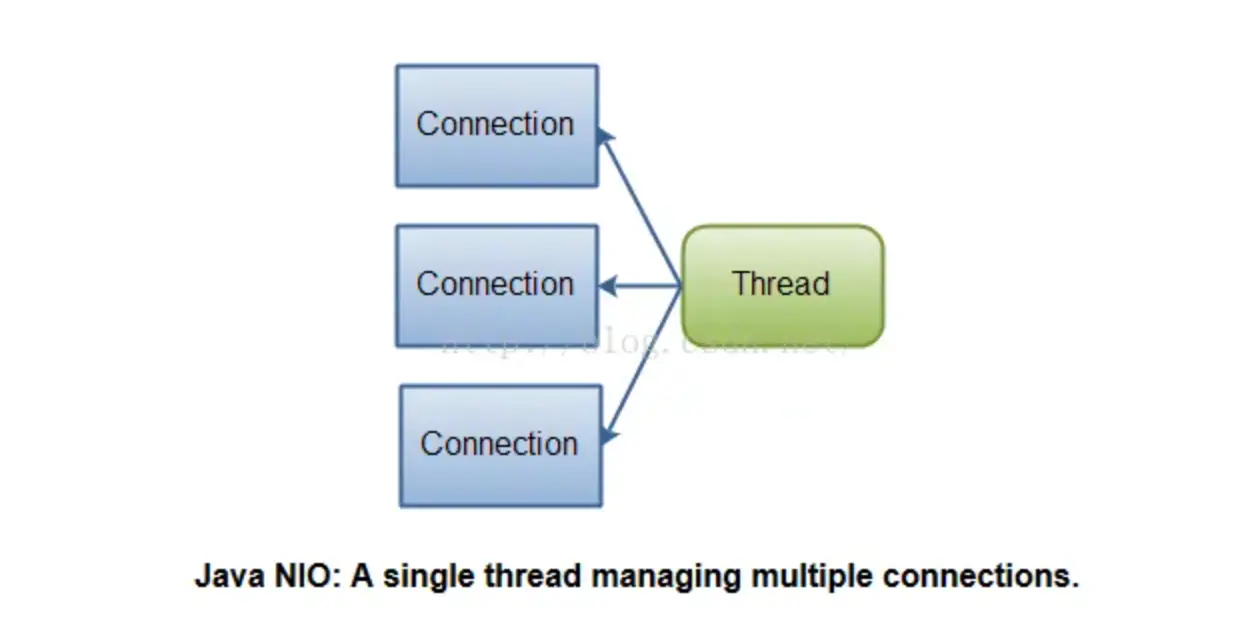
BIO、NIO、AIO区别是什么?
BIO(blocking IO):就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。优点是代码比较简单、直观;缺点是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
NIO(non-blocking IO) :Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
AIO(Asynchronous IO) :是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,所以人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
NIO是怎么实现的?
NIO是一种同步非阻塞的IO模型,所以也可以叫NON-BLOCKINGIO。同步是指线程不断轮询IO事件是否就绪,非阻塞是指线程在等待IO的时候,可以同时做其他任务。
同步的核心就Selector(I/O多路复用),Selector代替了线程本身轮询IO事件,避免了阻塞同时减少了不必要的线程消耗;非阻塞的核心就是通道和缓冲区,当IO事件就绪时,可以通过写到缓冲区,保证IO的成功,而无需线程阻塞式地等待。
NIO由一个专门的线程处理所有IO事件,并负责分发。事件驱动机制,事件到来的时候触发操作,不需要阻塞的监视事件。线程之间通过wait,notify通信,减少线程切换。
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
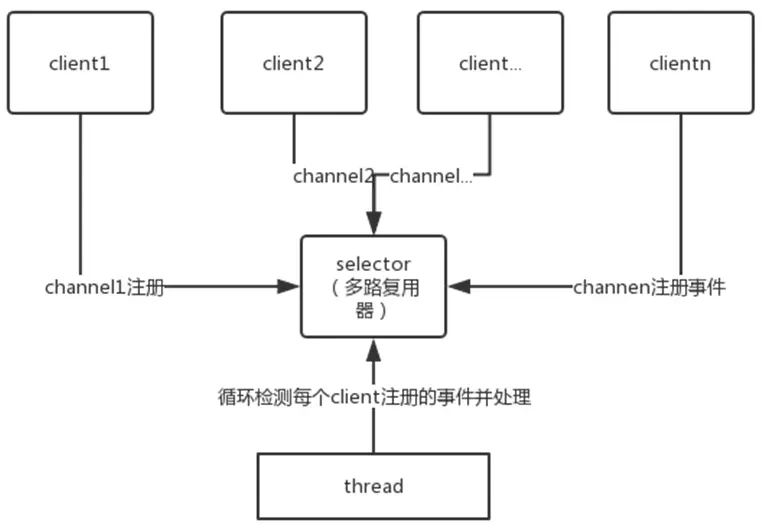
你知道有哪个框架用到NIO了吗?
Netty。
Netty 的 I/O 模型是基于非阻塞 I/O 实现的,底层依赖的是 NIO 框架的多路复用器 Selector。采用 epoll 模式后,只需要一个线程负责 Selector 的轮询。当有数据处于就绪状态后,需要一个事件分发器(Event Dispather),它负责将读写事件分发给对应的读写事件处理器(Event Handler)。事件分发器有两种设计模式:Reactor 和 Proactor,Reactor 采用同步 I/O, Proactor 采用异步 I/O。
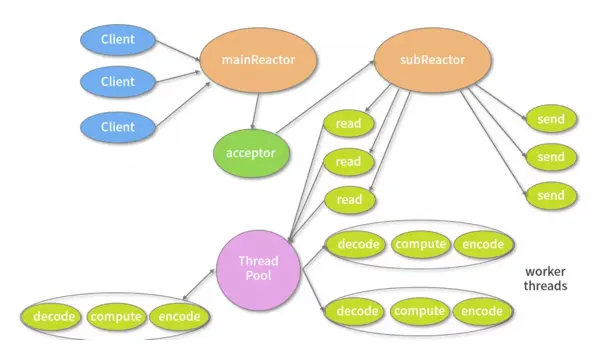
Reactor 实现相对简单,适合处理耗时短的场景,对于耗时长的 I/O 操作容易造成阻塞。Proactor 性能更高,但是实现逻辑非常复杂,适合图片或视频流分析服务器,目前主流的事件驱动模型还是依赖 select 或 epoll 来实现。
其他
有一个学生类,想按照分数排序,再按学号排序,应该怎么做?
可以使用Comparable接口来实现按照分数排序,再按照学号排序。首先在学生类中实现Comparable接口,并重写compareTo方法,然后在compareTo方法中实现按照分数排序和按照学号排序的逻辑。
public class Student implements Comparable<Student> {private int id;private int score;// 构造方法和其他属性、方法省略@Overridepublic int compareTo(Student other) {if (this.score != other.score) {return Integer.compare(other.score, this.score); // 按照分数降序排序} else {return Integer.compare(this.id, other.id); // 如果分数相同,则按照学号升序排序}}
}
然后在需要对学生列表进行排序的地方,使用Collections.sort()方法对学生列表进行排序即可:
List<Student> students = new ArrayList<>();
// 添加学生对象到列表中
Collections.sort(students);Native方法解释一下
在Java中,native方法是一种特殊类型的方法,它允许Java代码调用外部的本地代码,即用C、C++或其他语言编写的代码。native关键字是Java语言中的一种声明,用于标记一个方法的实现将在外部定义。
在Java类中,native方法看起来与其他方法相似,只是其方法体由native关键字代替,没有实际的实现代码。例如:
public class NativeExample {public native void nativeMethod();
}
要实现native方法,你需要完成以下步骤:
生成JNI头文件:使用javah工具从你的Java类生成C/C++的头文件,这个头文件包含了所有native方法的原型。
编写本地代码:使用C/C++编写本地方法的实现,并确保方法签名与生成的头文件中的原型匹配。
编译本地代码:将C/C++代码编译成动态链接库(DLL,在Windows上),共享库(SO,在Linux上)
加载本地库:在Java程序中,使用System.loadLibrary()方法来加载你编译好的本地库,这样JVM就能找到并调用native方法的实现了。