深入浅出CRC校验:从数学原理到单周期硬件实现 (3)CRC线性反馈移位寄存器
硬件加速之道:从串行比特到并行字节的CRC演进
当数学原理遇见硬件逻辑,CRC算法焕发出全新的生命力。本文将带您探索如何用数字电路高效实现CRC计算,并揭示串行处理的性能瓶颈。
前言:从数学到电路的华丽转变
在上一篇文章中,我们深入探讨了CRC的数学基础——多项式模2运算。现在,我们要将这些抽象的数学概念转化为实实在在的数字电路。这种转换不仅优雅,而且极其高效,这正是CRC能够在各种高速接口中广泛应用的原因。
LFSR:多项式除法的硬件化身
线性反馈移位寄存器(LFSR) 是实现CRC计算的完美硬件结构。它将多项式除法巧妙地映射为移位寄存器和异或门的组合。
LFSR的基本结构
让我们以一个简单的CRC-3为例,生成多项式为:g(x) = x³ + x + 1(二进制表示为 1011)
对应的LFSR结构如下:
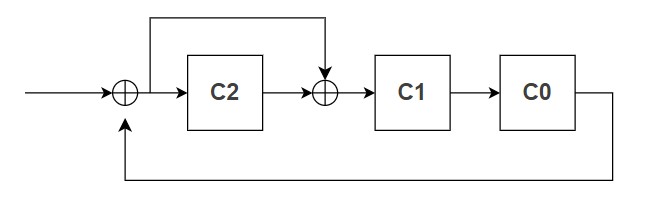
工作流程 :
- 3个寄存器初始化为预定值(通常全0或全1)
- 数据位按位串行输入
- 每个时钟周期,寄存器移位一次
- 根据生成多项式,在特定位置插入异或反馈
生成多项式与电路连接的映射关系
生成多项式中的每一项对应LFS中的一个反馈连接点:
- x³ :代表最高位寄存器(寄存器2)
- x² :无此项,表示寄存器1到寄存器2无直接反馈
- x¹ :代表在寄存器0和寄存器1之间插入异或门
- x⁰ :代表在输入和寄存器0之间插入异或门
换句话说: 生成多项式中为"1"的位(除了最高位)对应需要插入异或反馈的位置 。
串行CRC实现:逐位处理的经典方案
Verilog实现示例
下面是一个通用的串行CRC计算模块:
module serial_crc (input wire clk,input wire rst_n,input wire data_in, // 串行输入数据input wire data_valid, // 数据有效信号output reg [31:0] crc_out // CRC计算结果
);// 以CRC-32生成多项式为例:0x04C11DB7
parameter POLY = 32'h04C11DB7;always @(posedge clk or negedge rst_n) beginif (!rst_n) begincrc_out <= 32'hFFFFFFFF; // 初始值end else if (data_valid) begin// 逐位计算CRCcrc_out <= {crc_out[30:0], 1'b0} ^ ({32{(crc_out[31] ^ data_in)}} & POLY);end
endendmodule
工作原理分析
- 初始化 :寄存器设置为初始值(通常为全1)
- 逐位处理 :每个时钟周期处理1位数据
- 核心操作 :
- 检查最高位(crc_out[31])与输入数据的异或结果
- 如果结果为1,与生成多项式进行异或
- 如果结果为0,只进行移位操作
时序特性
串行CRC的时序行为如下:
时钟周期: 0 1 2 3 4 5 6 7 8
数据输入: D0 D1 D2 D3 D4 D5 D6 D7 ...
CRC计算: 计算D0 计算D1 计算D2 计算D3 计算D4 计算D5 计算D6 计算D7 ...
关键特点 :
- 每个时钟周期处理1位数据
- 计算n位数据需要n个时钟周期
- 硬件资源占用极少(只有寄存器和少量逻辑门)
串行实现的瓶颈:无法满足现代需求
虽然串行实现简单高效,但在现代高速系统中面临严重瓶颈:
速度限制示例
| 数据速率 | 时钟频率要求 | 实际限制 |
|---|---|---|
| 1 Gbps | 1 GHz | FPGA很难达到这么高的频率 |
| 10 Gbps | 10 GHz | 当前技术无法实现 |
| 100 Gbps | 100 GHz | 完全不可能 |
其他局限性
- 高延迟 :处理一个字节需要8个时钟周期
- 吞吐量低 :每个周期只能处理1位数据
- 资源利用率低 :虽然资源占用少,但计算效率也低
并行化的迫切需求:为什么需要单周期CRC?
现代高速接口对CRC计算提出了严苛要求:
现实应用的需求
- PCIe 5.0 :速率达32 GT/s,需要每个时钟周期处理多位数据
- 100G以太网 :需要极低延迟的CRC计算
- SSD控制器 :高速数据处理不能成为性能瓶颈
并行化的基本思路
如果我们能在单个时钟周期内处理整个字节(高速应用场景需要处理4/8字节),性能将大幅提升:
时钟周期: 0 1 2 3
数据输入: D[7:0] D[15:8] D[23:16] D[31:24] ...
CRC计算: 计算字节0 计算字节1 计算字节2 计算字节3 ...
目标 :实现每个时钟周期处理8位(或更多)数据的并行CRC计算
性能对比:串行 vs 并行
| 特性 | 串行实现 | 并行实现(8位) |
|---|---|---|
| 时钟周期数/字节 | 8 | 1 |
| 最高吞吐量 | 较低 | 提高8倍 |
| 逻辑资源 | 极少 | 较多 |
| 时序要求 | 宽松 | 严格 |
| 适用场景 | 低速接口 | 高速接口 |
总结与展望
本文介绍了CRC的硬件实现基础:
- ✅ LFSR原理 :多项式除法的硬件映射
- ✅ 串行实现 :简单但性能有限的传统方案
- ✅ 性能瓶颈 :串行处理无法满足高速需求
下篇预告 :在下一篇文章中,我们将深入探讨 单周期CRC实现的数学推导和硬件设计 。您将看到如何通过巧妙的数学变换,实现每个时钟周期处理一个字节甚至一个字的超高速CRC计算,并附上完整的可综合Verilog代码!