【完整源码+数据集+部署教程】足球场景分割系统: yolov8-seg-C2f-EMBC
背景意义
研究背景与意义
随着计算机视觉技术的迅猛发展,物体检测与分割在多个领域得到了广泛应用,尤其是在体育分析、智能监控和自动驾驶等领域。其中,足球作为全球最受欢迎的运动之一,其比赛场景的分析与理解对于教练、运动员以及观众都具有重要意义。通过对足球场景的精准分割与分析,可以为战术研究、运动员表现评估以及赛事回放提供重要的数据支持。因此,开发一个高效的足球场景分割系统显得尤为重要。
在众多物体检测与分割算法中,YOLO(You Only Look Once)系列模型因其高效性和实时性而受到广泛关注。YOLOv8作为该系列的最新版本,进一步提升了检测精度和速度,适合于复杂场景下的实时应用。然而,现有的YOLOv8模型在特定场景下的表现仍有提升空间,尤其是在多类别物体分割和细节处理方面。因此,基于改进YOLOv8的足球场景分割系统的研究,具有重要的学术价值和实际意义。
本研究将采用SoccerSee数据集,该数据集包含4800张图像,涵盖了六个类别:‘Team2’、Arbitres(裁判)、Ballon(足球)、Gardien(守门员)、Joueur(球员)和net(球网)。这些类别的多样性为模型的训练和评估提供了丰富的样本,能够有效地反映足球比赛中的各种动态场景。通过对这些类别的精准分割,研究者可以深入分析比赛中的战术布置、球员的运动轨迹以及裁判的判罚行为等,从而为足球战术研究提供数据支持。
此外,改进YOLOv8模型的研究不仅限于提高分割精度,还包括优化模型的推理速度和资源消耗,使其能够在实时应用中表现出色。这对于直播赛事分析、即时战术调整以及球迷互动体验等方面都有着重要的推动作用。通过将深度学习与足球场景分析相结合,本研究有望为智能体育分析系统的发展提供新的思路和方法。
在实际应用层面,基于改进YOLOv8的足球场景分割系统能够为教练团队提供实时的战术分析工具,帮助他们更好地理解比赛动态,制定相应的战术调整。同时,球迷也能够通过这一系统获得更为丰富的比赛信息,提升观赛体验。此外,该系统还可以为足球训练提供数据支持,帮助运动员在训练中更好地理解战术和技术要点。
综上所述,基于改进YOLOv8的足球场景分割系统的研究,不仅具有重要的理论意义,也为实际应用提供了广阔的前景。通过对足球场景的深入分析,研究者可以为体育科学、人工智能和数据分析等多个领域的交叉研究提供新的视角和方法,推动相关领域的进一步发展。
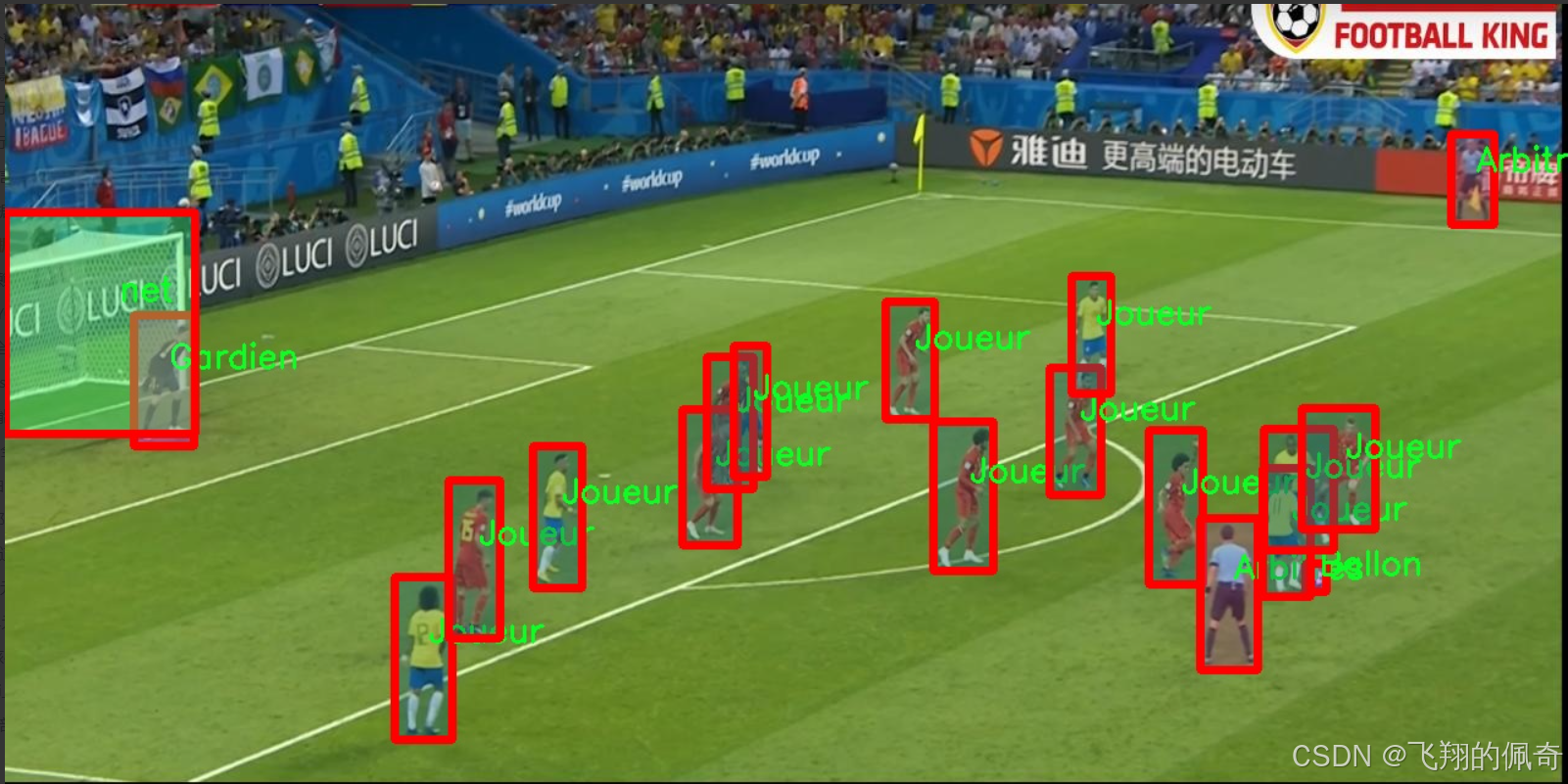
图片效果
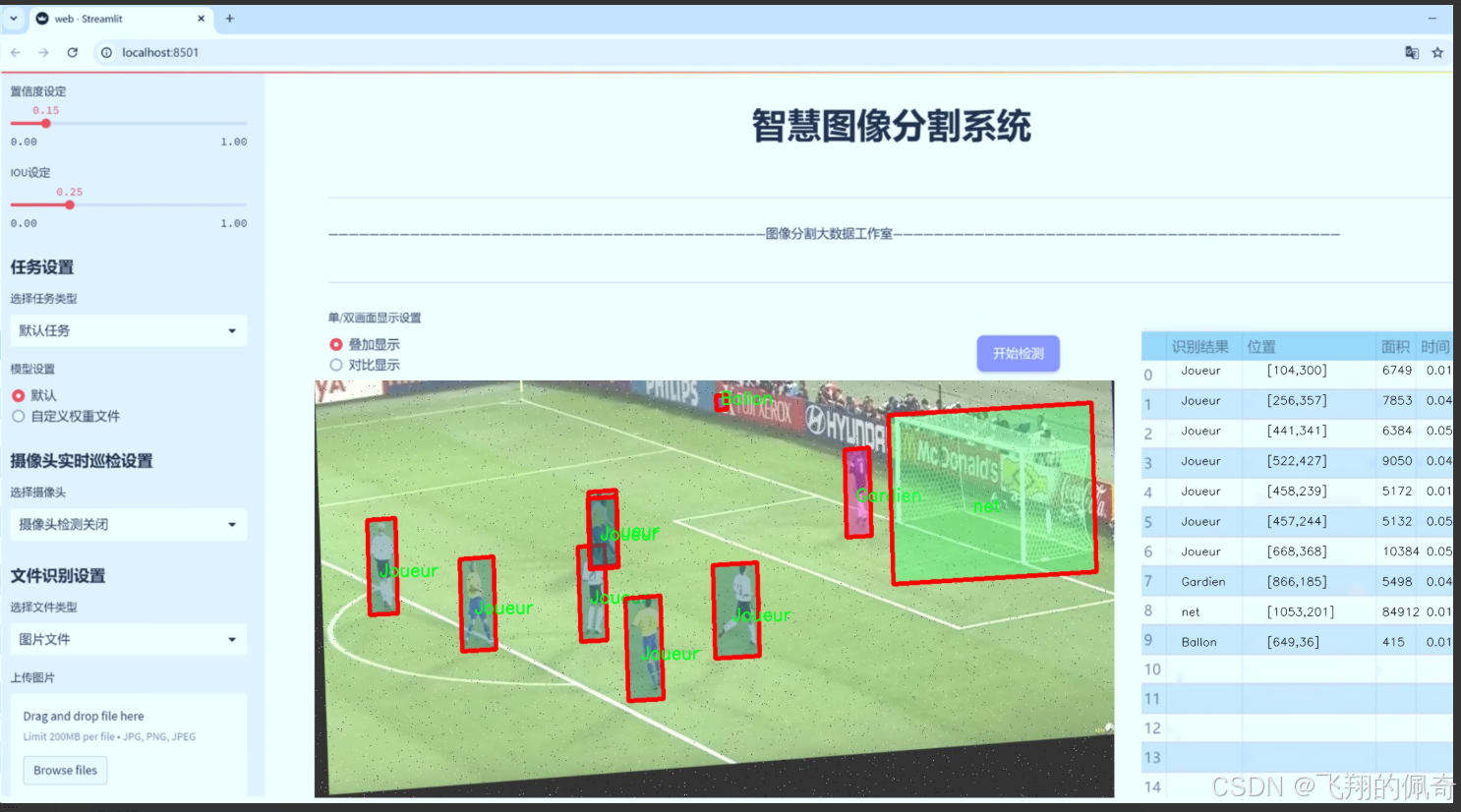
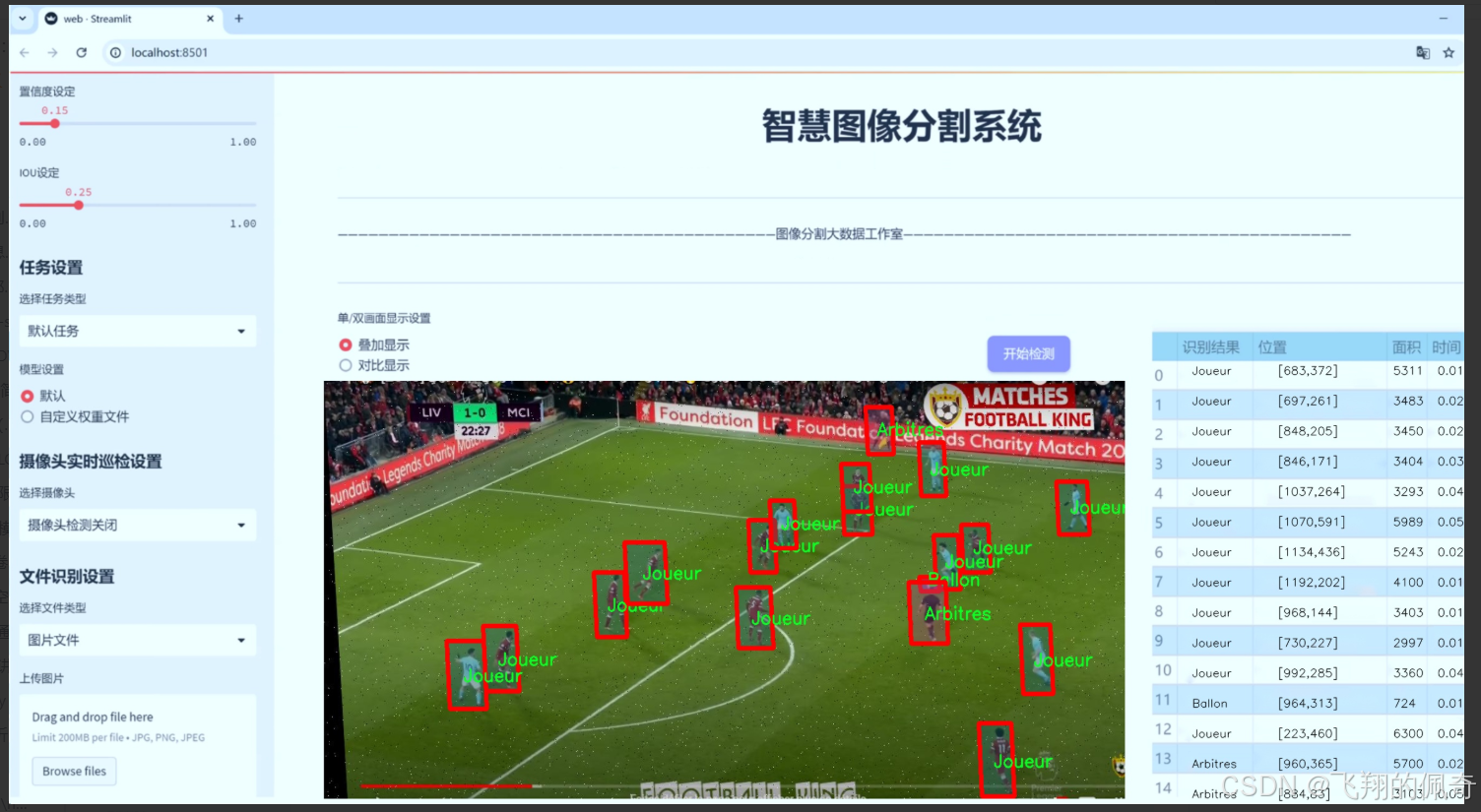
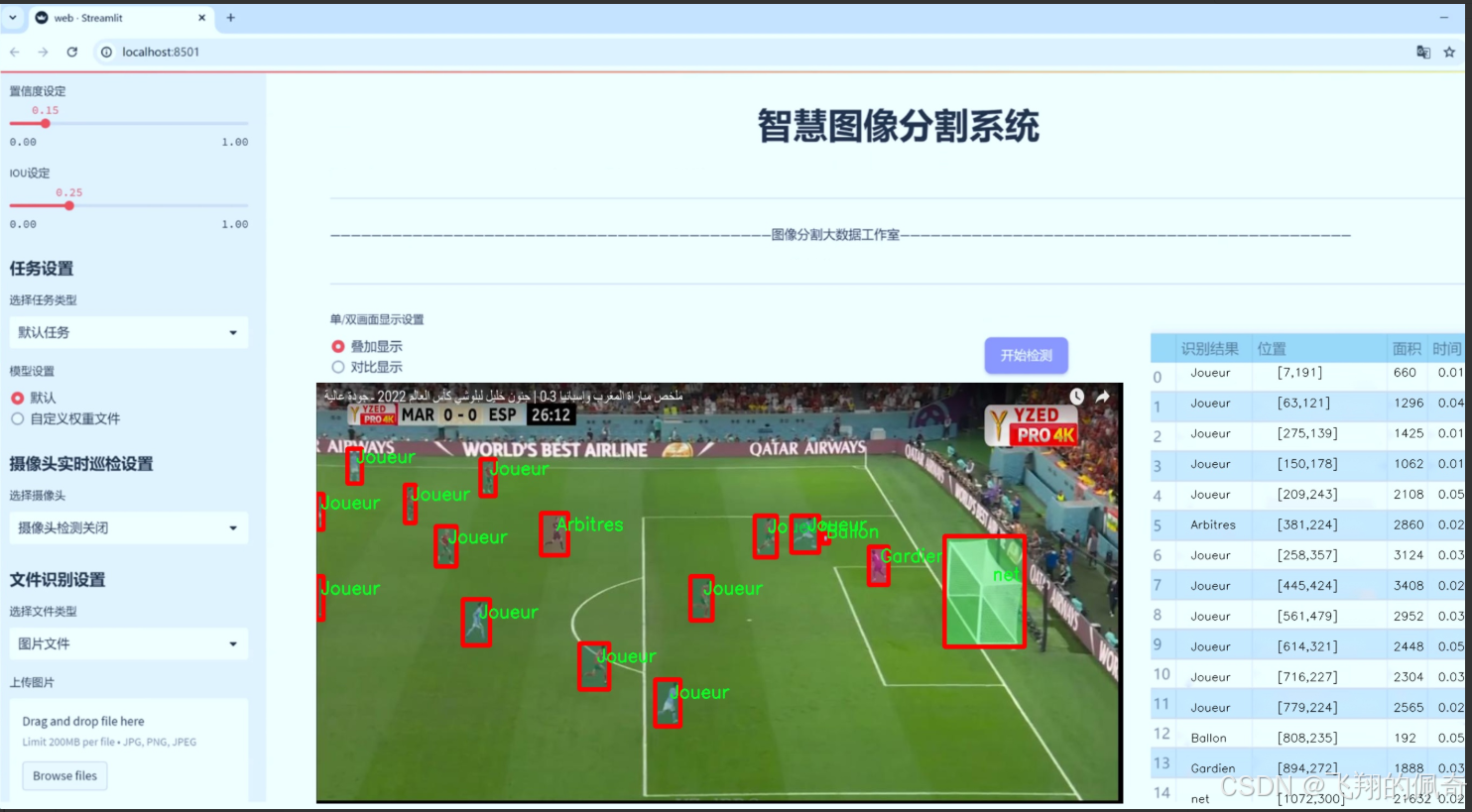
数据集信息
数据集信息展示
在本研究中,我们使用了名为“SoccerSee”的数据集,以改进YOLOv8-seg在足球场景中的分割性能。该数据集专门针对足球比赛的各种元素进行了标注,涵盖了多个关键类别,共计六个类别。这些类别分别是:球队(-Team2-)、裁判(Arbitres)、足球(Ballon)、守门员(Gardien)、球员(Joueur)以及球网(net)。这些类别的选择不仅反映了足球比赛的基本构成要素,也为训练和评估分割模型提供了丰富的上下文信息。
“SoccerSee”数据集的设计考虑到了足球场景的复杂性和多样性,旨在为计算机视觉任务提供高质量的训练样本。每个类别都经过精确的标注,确保模型能够在实际应用中有效识别和分割不同的对象。例如,球队的标注不仅包括球员的外观特征,还考虑了他们在场上的相对位置和动态行为;裁判的标注则关注于他们在比赛中的角色和动作,这对于理解比赛的进程至关重要。
足球作为一项全球广受欢迎的运动,其场景中的元素往往具有高度的动态性和复杂性。通过使用“SoccerSee”数据集,我们能够捕捉到比赛中快速变化的状态,例如球员的移动、球的轨迹以及裁判的判罚动作。这些信息的整合为YOLOv8-seg模型的训练提供了丰富的上下文,使其在分割任务中表现得更加精准和高效。
在数据集的构建过程中,研究团队注重多样性和代表性,确保数据集中的样本涵盖了不同的比赛场景、天气条件和时间段。这种多样性不仅增强了模型的泛化能力,还使其能够在各种实际应用场景中表现出色。此外,数据集的图像质量经过严格筛选,确保每一帧图像都具有足够的清晰度和细节,以便于模型学习。
为了进一步提升模型的性能,我们在训练过程中采用了数据增强技术,以模拟不同的环境变化和视觉效果。这些技术包括随机裁剪、旋转、颜色变换等,旨在增加训练样本的多样性,帮助模型更好地适应现实世界中的各种情况。
在模型评估阶段,我们将使用“SoccerSee”数据集中的独立测试集进行性能验证,以确保模型在真实场景中的应用效果。通过对比模型在不同类别上的分割精度,我们能够识别出模型的优势和不足之处,从而为后续的优化提供依据。
总之,“SoccerSee”数据集为改进YOLOv8-seg的足球场景分割系统提供了坚实的基础。通过对足球比赛中关键元素的细致标注和多样化的样本选择,该数据集不仅增强了模型的学习能力,也为未来的研究和应用奠定了良好的基础。随着模型性能的不断提升,我们期待在足球场景的自动分析和理解方面取得更大的突破。
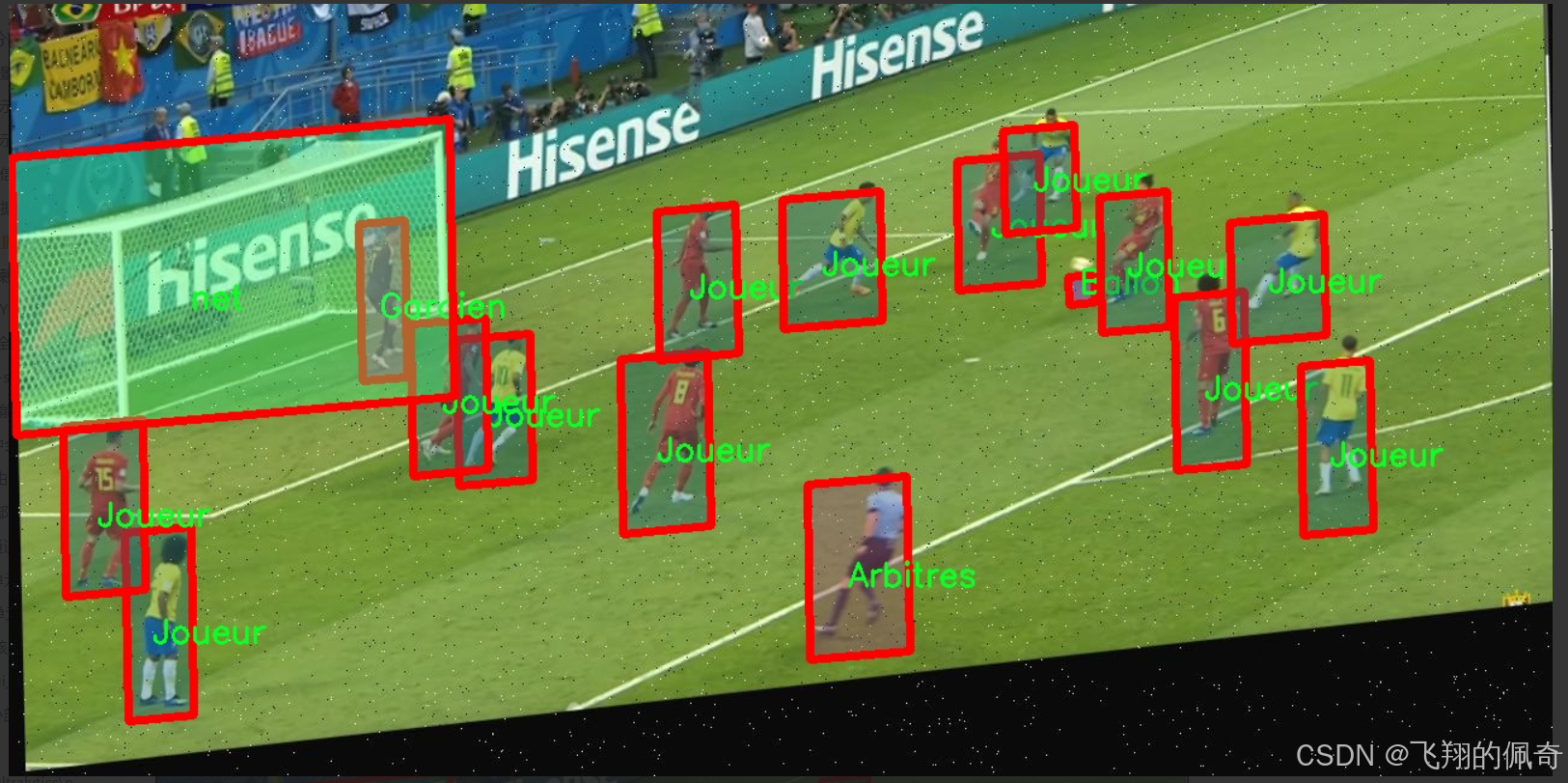
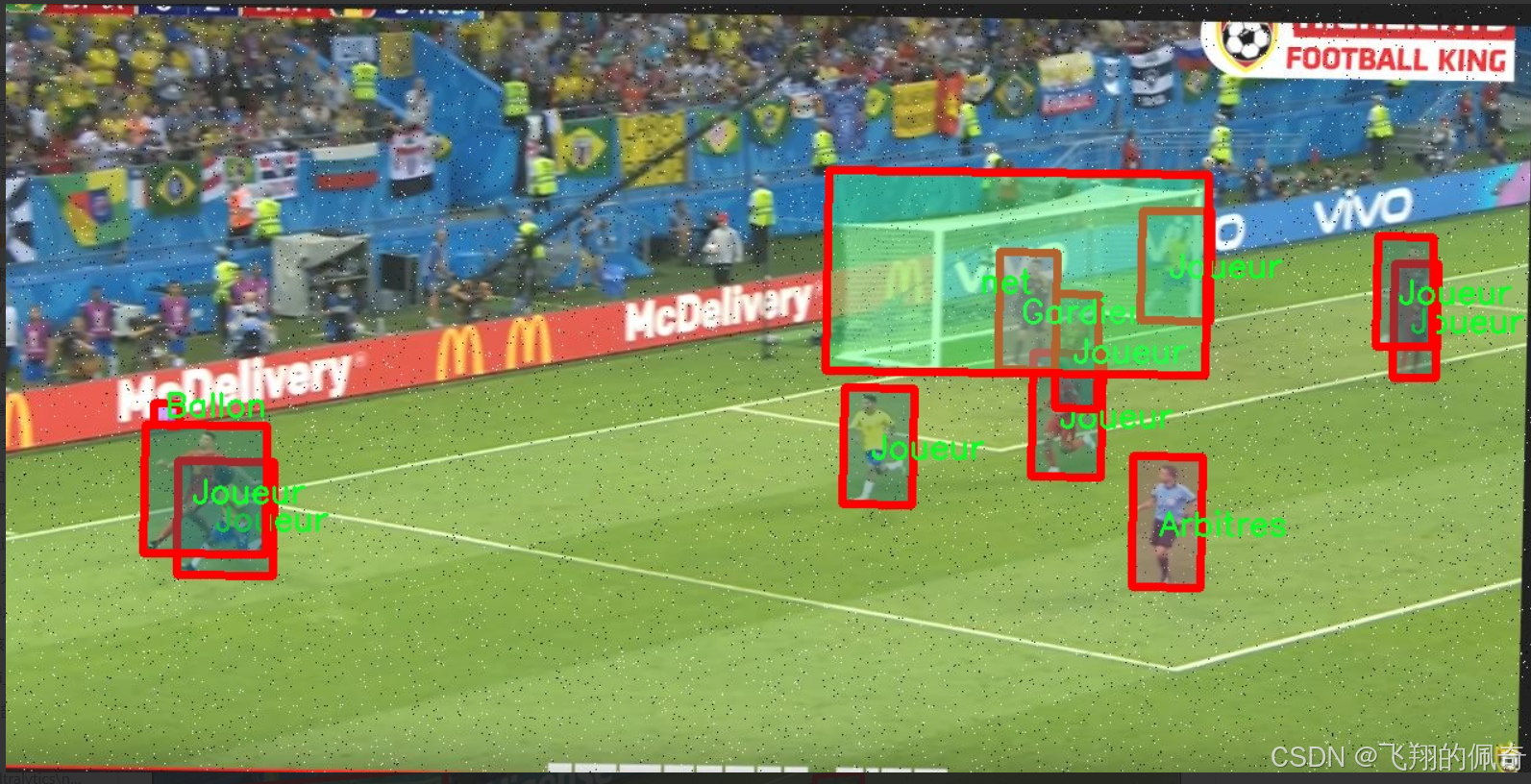
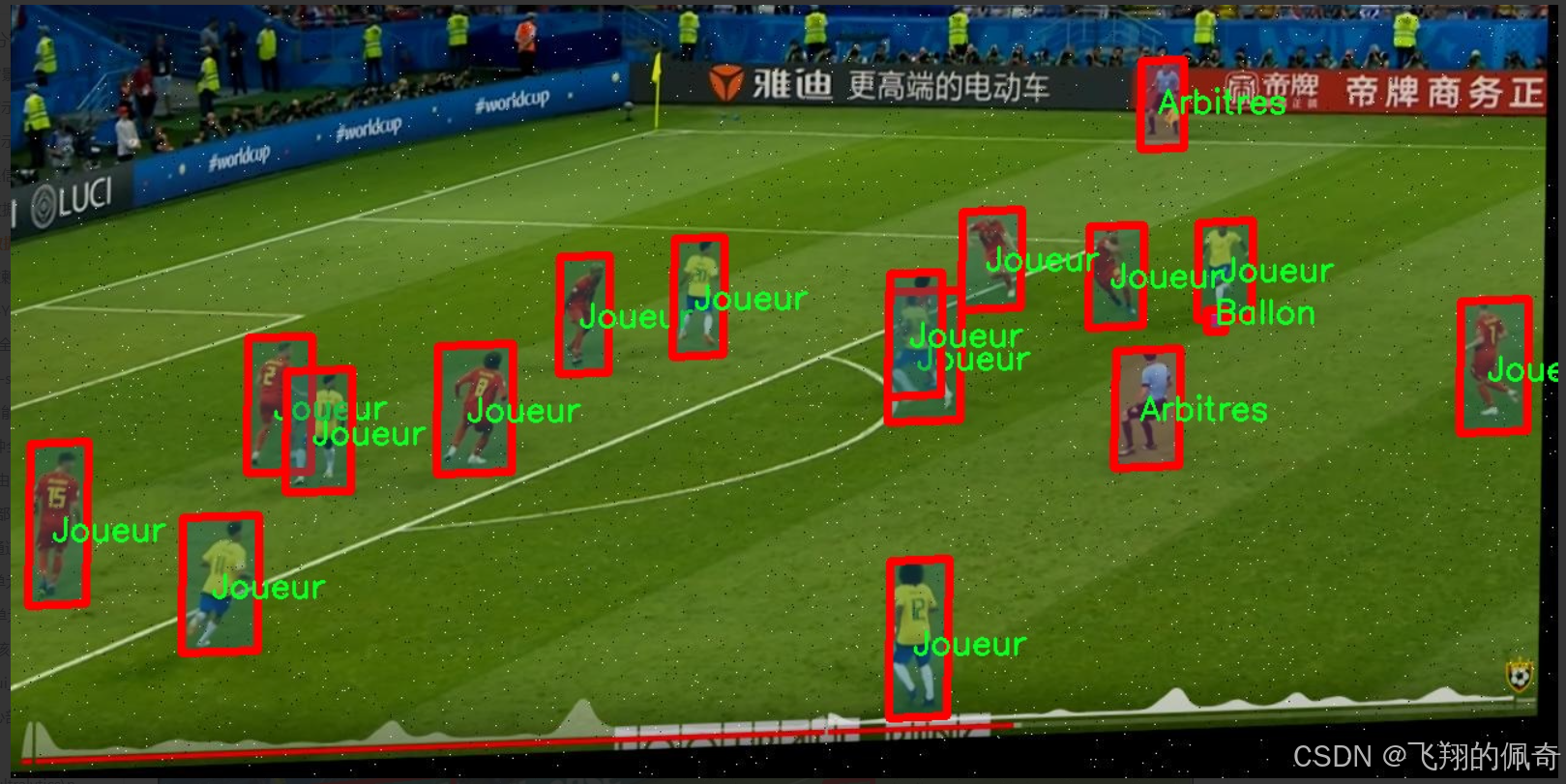
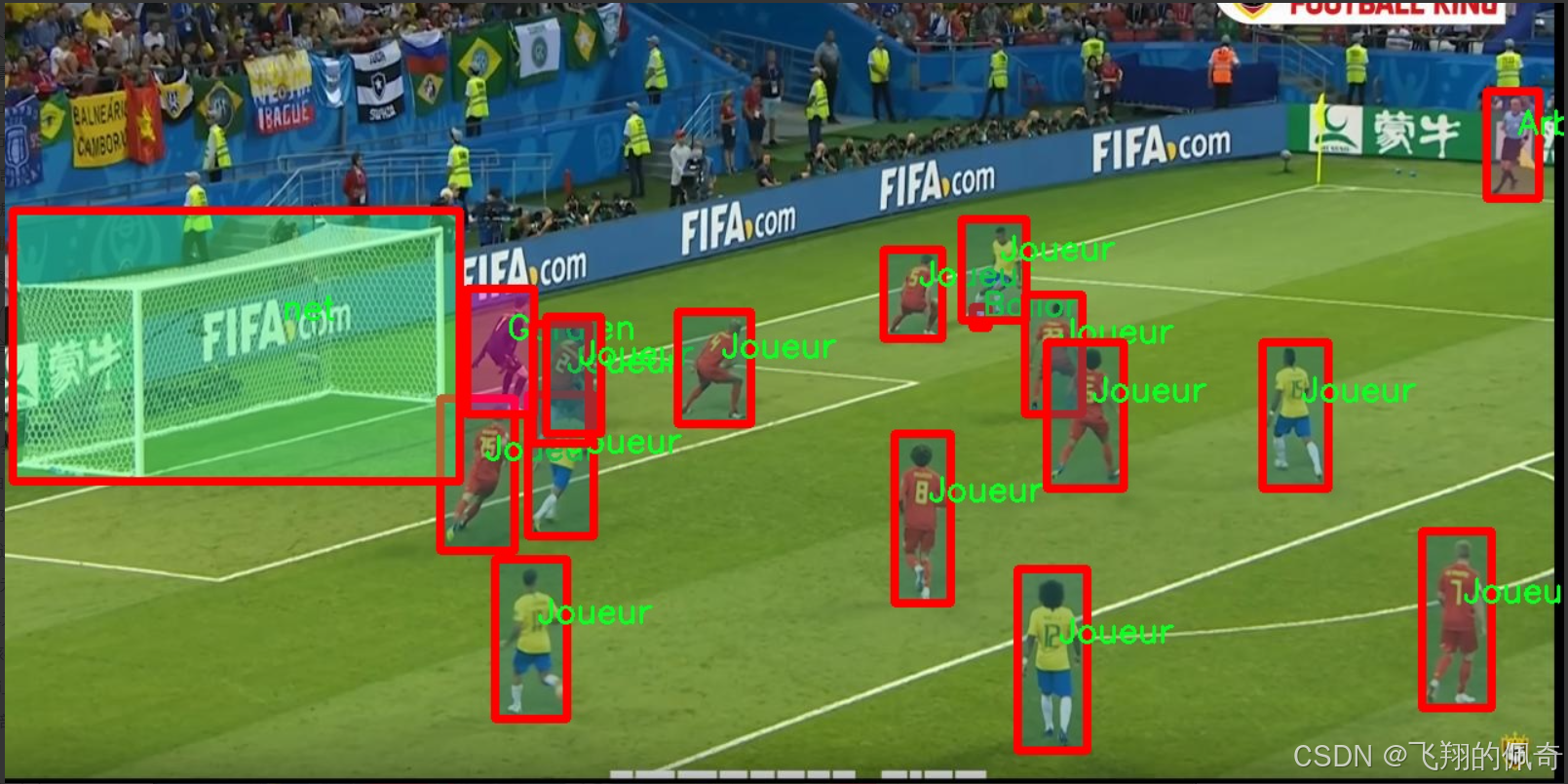
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
-- coding: utf-8 --
import cv2 # 导入OpenCV库,用于处理图像和视频
import torch # 导入PyTorch库,用于深度学习模型的操作
from ultralytics import YOLO # 从ultralytics库中导入YOLO类,用于加载YOLO模型
from ultralytics.utils.torch_utils import select_device # 导入选择设备的工具函数
选择计算设备,如果有可用的GPU则使用GPU,否则使用CPU
device = “cuda:0” if torch.cuda.is_available() else “cpu”
初始化参数字典
ini_params = {
‘device’: device, # 设备类型
‘conf’: 0.3, # 物体置信度阈值
‘iou’: 0.05, # 非极大值抑制的IOU阈值
‘classes’: None, # 类别过滤器
‘verbose’: False # 是否输出详细信息
}
class Web_Detector: # 定义检测器类
def init(self, params=None): # 构造函数
self.model = None # 初始化模型为None
self.params = params if params else ini_params # 使用提供的参数或默认参数
def load_model(self, model_path): # 加载模型的方法self.device = select_device(self.params['device']) # 选择计算设备self.model = YOLO(model_path) # 加载YOLO模型# 预热模型,确保模型在推理前已准备好self.model(torch.zeros(1, 3, 640, 640).to(self.device).type_as(next(self.model.model.parameters())))def predict(self, img): # 进行预测的方法results = self.model(img, **ini_params) # 使用YOLO模型进行预测return results # 返回预测结果def postprocess(self, pred): # 后处理方法results = [] # 初始化结果列表for res in pred[0].boxes: # 遍历预测结果中的每个边界框class_id = int(res.cls.cpu()) # 获取类别IDbbox = res.xyxy.cpu().squeeze().tolist() # 获取边界框坐标bbox = [int(coord) for coord in bbox] # 转换为整数result = {"class_name": self.model.names[class_id], # 类别名称"bbox": bbox, # 边界框"score": res.conf.cpu().squeeze().item(), # 置信度"class_id": class_id # 类别ID}results.append(result) # 将结果添加到列表return results # 返回处理后的结果列表
代码核心部分解释:
设备选择:根据是否有可用的GPU来选择计算设备,确保模型能够在最优的硬件上运行。
初始化参数:设置了一些默认参数,包括设备类型、置信度阈值等。
模型加载:通过load_model方法加载YOLO模型,并进行预热,确保模型在推理前准备好。
预测功能:predict方法使用加载的YOLO模型对输入图像进行预测,并返回结果。
后处理:postprocess方法对预测结果进行处理,提取类别名称、边界框、置信度等信息,并将其组织成字典形式返回。
这个程序文件model.py主要用于实现一个基于YOLO(You Only Look Once)模型的目标检测器,利用OpenCV和PyTorch库进行图像处理和深度学习模型的加载与推理。文件中包含了多个功能模块,具体说明如下。
首先,程序导入了必要的库,包括OpenCV用于图像和视频处理,PyTorch用于深度学习模型的操作,以及从QtFusion和ultralytics库中导入的相关类和函数。程序还导入了一个中文名称字典,以便在检测结果中使用中文类别名称。
接下来,程序设置了设备类型,优先使用GPU(如果可用),否则使用CPU。同时定义了一些初始化参数,包括物体置信度阈值、IOU阈值、类别过滤器等。
count_classes函数用于统计检测结果中每个类别的数量。它接收检测信息和类别名称列表,遍历检测信息,更新每个类别的计数,并最终返回一个按类别顺序排列的计数列表。
Web_Detector类继承自Detector类,构造函数中初始化了一些属性,包括模型、图像和类别名称。该类的主要功能包括加载模型、预处理图像、进行预测和后处理结果。
在load_model方法中,程序根据给定的模型路径加载YOLO模型,并将类别名称转换为中文。为了提高模型的运行效率,程序还进行了预热操作。
preprocess方法用于对输入图像进行预处理,简单地将原始图像保存并返回。
predict方法则是调用YOLO模型进行目标检测,返回检测结果。
postprocess方法负责对模型的输出结果进行后处理,提取每个检测框的信息,包括类别名称、边界框坐标、置信度和类别ID等,并将这些信息组织成字典形式,最终返回一个结果列表。
最后,set_param方法允许更新检测器的参数,以便在运行时调整检测行为。
整体来看,这个程序文件实现了一个完整的目标检测流程,从模型加载到图像预处理、预测和结果后处理,适用于基于YOLO的目标检测任务。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是一个基于YOLO(You Only Look Once)模型的目标检测和图像分割系统,旨在提供高效的图像处理和深度学习推理功能。程序由多个模块组成,每个模块负责特定的功能,包括用户界面样式定义、可变形卷积操作、特征提取、图像分割和目标检测。整体架构通过将不同的功能模块化,增强了代码的可维护性和可扩展性。
ui_style.py: 定义了Streamlit应用的样式和外观。
dcnv3_func.py: 实现了DCNv3(可变形卷积)操作的前向和反向传播。
revcol.py: 构建了一个特征提取网络,利用反向传播和特征融合技术。
init.py: 组织和导出与图像分割相关的类,简化模块的使用。
model.py: 实现了YOLO目标检测器,负责模型加载、图像预处理、预测和结果后处理。
文件功能整理表
文件路径 功能描述
C:\codeseg\codenew\code\ui_style.py 定义Streamlit应用的CSS样式和界面外观,提供美观的用户界面。
C:\codeseg\codenew\code\ultralytics\nn\extra_modules\ops_dcnv3\functions\dcnv3_func.py 实现DCNv3(可变形卷积)操作的前向和反向传播,支持深度学习模型的可变形卷积计算。
C:\codeseg\codenew\code\ultralytics\nn\backbone\revcol.py 构建特征提取网络,利用反向传播和特征融合技术,增强模型对复杂特征的提取能力。
C:\codeseg\codenew\code\ultralytics\models\yolo\segment_init_.py 组织和导出与图像分割相关的类,简化模块的使用,便于其他模块调用。
C:\codeseg\codenew\code\model.py 实现YOLO目标检测器,负责模型加载、图像预处理、目标检测预测和结果后处理。
这个表格总结了每个文件的主要功能,帮助理解整个程序的结构和各个模块之间的关系。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式