yolo识别手势释放忍术
前提概要
上次使用mediaPipe的方法分析每个手指的弯曲来实现结印的识别用很多不足,这次采用yolo的方式让它学习这些结印的图片,解决了上次出现的不可避免的包括遮挡等问题,理论上来说识别率会大大提升
yolo训练
这里采用的是通过最小的模型yolo11n来进行训练
使用labelimg进行图片的标注
终端上labelimg的启动代码如下
labelimg 图片路径 标签文件 存放路径
(标签文件直接用txt即可,每行代表一个标签,这样你使用labelimg的时候就可以快捷选择标签)
按w鼠标拖动用来画框
空格表示审核通过
a:上一张
d:下一张
注意:要先将格式改为yolo省的再去做转换
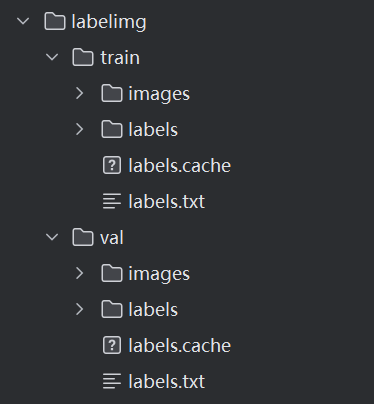
然后我们需要分出起码两个数据集,数量大的作为训练集,数量小的作为验证集(测试集我懒得搞了,一张张拍照再去框图太麻烦了)然后将文件划分成如下格式(cache不用管,那个是训练后自己生成的)
然后先创建一个yaml文件,内容如下,用来提示训练图片的位置和标签
# 数据集路径
train: ./labelimg/train/images
val: ./labelimg/val/images# 类别数量
nc: 12 # 根据您的结印类别数量修改# 类别名称
names: ['子', '丑', '寅', '卯', '辰', '巳', '午', '未','申', '酉', '戌', '亥'] # 替换为您的结印名称
训练代码如下(参数是deepseek告诉我的,我还没有研究透)
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('yolo11n.pt')model.train(data='hand.yaml',epochs=100, # 训练轮数imgsz=640, # 输入图像大小batch=16, # 批次大小(根据GPU内存调整)name='ninja_hand_signs', # 训练结果保存名称device='cuda', # 使用GPU训练,如果是CPU则改为'cpu'optimizer='AdamW', # 优化器lr0=0.001, # 初始学习率lrf=0.01, # 最终学习率momentum=0.937, # 动量weight_decay=0.0005, # 权重衰减warmup_epochs=3.0, # 热身轮数warmup_momentum=0.8, # 热身动量warmup_bias_lr=0.1, # 热身偏置学习率box=7.5, # 框损失权重cls=0.5, # 分类损失权重dfl=1.5, # DFL损失权重hsv_h=0.015, # 图像HSV-色调增强(分数)hsv_s=0.7, # 图像HSV-饱和度增强(分数)hsv_v=0.4, # 图像HSV-明度增强(分数)degrees=0.0, # 图像旋转(+/-度)translate=0.1, # 图像平移(+/-分数)scale=0.5, # 图像缩放(+/-增益)shear=0.0, # 图像剪切(+/-度)perspective=0.0, # 图像透视(+/-分数),0.0-0.001flipud=0.0, # 图像上下翻转(概率)fliplr=0.5, # 图像左右翻转(概率)mosaic=1.0, # 马赛克增强(概率)mixup=0.0, # 混合增强(概率)copy_paste=0.0, # 复制粘贴增强(概率))print("训练完成!")
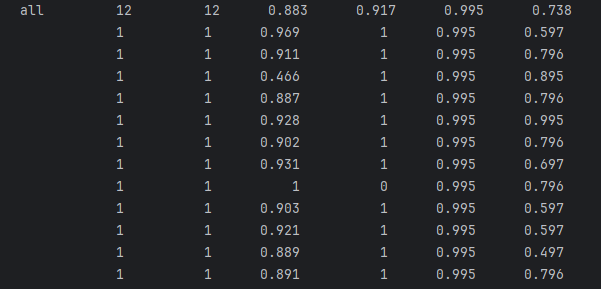
这时你就会生成一个文件:
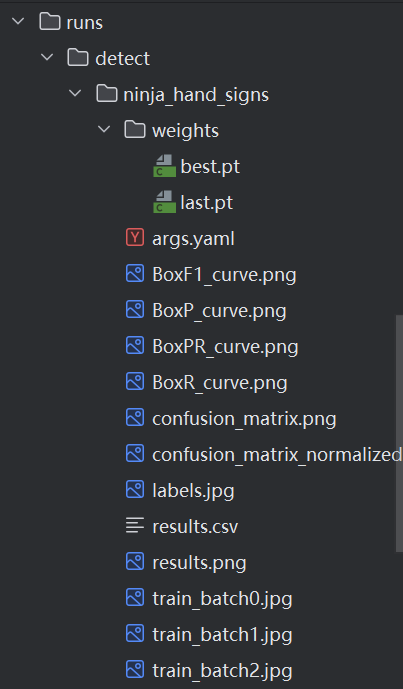
这里的best.pt就是你训练好权重的最优模型,last是最适合最后一张图的权重的模型
使用模型去识别忍术结印并播放动画
逻辑和mediaPipe的差不多(这里只识别了雷切的)
from ultralytics import YOLO
import cv2 as cv# 加载最佳模型
model = YOLO('./runs/detect/ninja_hand_signs/weights/best.pt')madura_list = []
leiqie = ["申","卯","丑"]
qianniao = ["子","午","申","午","卯"]
fenshenshu = ["未","巳","寅"]# 初始化时加载动画视频
leiqie_animation_cap = cv.VideoCapture("./pic/leiqie.mp4")# 打开摄像头
cap = cv.VideoCapture(0) # 0 表示默认摄像头while True:# 读取一帧ret, frame = cap.read()if not ret:breakheight, width = frame.shape[:2]# 使用YOLO模型进行预测results = model(frame, stream=True, conf=0.5) # 使用stream=True以提高效率# 遍历结果 (对于摄像头,通常每次一帧,所以这里通常只循环一次)for result in results:# 获取原始的OpenCV图像 (BGR)# orig_img = result.orig_img # 如果需要的话可以获取# 检查是否有检测到任何目标if result.boxes is not None:# 获取所有的边界框、置信度和类别IDboxes = result.boxes.xyxy.cpu().numpy() # 坐标confidences = result.boxes.conf.cpu().numpy() # 置信度class_ids = result.boxes.cls.cpu().numpy().astype(int) # 类别ID# 获取类别名称字典names = result.names# 遍历每一个检测到的目标for i, (box, conf, cls_id) in enumerate(zip(boxes, confidences, class_ids)):x1, y1, x2, y2 = boxlabel = names[cls_id]confidence = conf# 在图像上绘制框和标签cv.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)cv.putText(frame, f'{cls_id} {confidence:.2f}', (int(x1), int(y1) - 10),cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)# 打印检测到的信息到控制台# print(f"检测到目标 {i+1}: {label}, 置信度: {confidence:.2f}, 坐标: ({x1:.1f}, {y1:.1f}, {x2:.1f}, {y2:.1f})")if len(madura_list)==0 or madura_list[len(madura_list)-1]!=label:madura_list.append(label)print(madura_list)if madura_list[-3:] == leiqie:# 获取动画视频的下一帧ret_anim, anim_frame = leiqie_animation_cap.read()if ret_anim:# 调整动画帧尺寸anim_frame_resized = cv.resize(anim_frame, (width, height))frame = anim_frame_resizedcv.imshow('YOLO Real-Time Detection', frame)# 显示带检测结果的帧cv.imshow('YOLO Real-Time Detection', frame)# 按 'q' 键退出循环if cv.waitKey(1) & 0xFF == ord('q'):break# 释放资源
cap.release()
cv.destroyAllWindows()