如何让 RAG 的检索精准度提升 80%?
如何让 RAG 的检索精准度提升 80%?一份系统性的优化指南
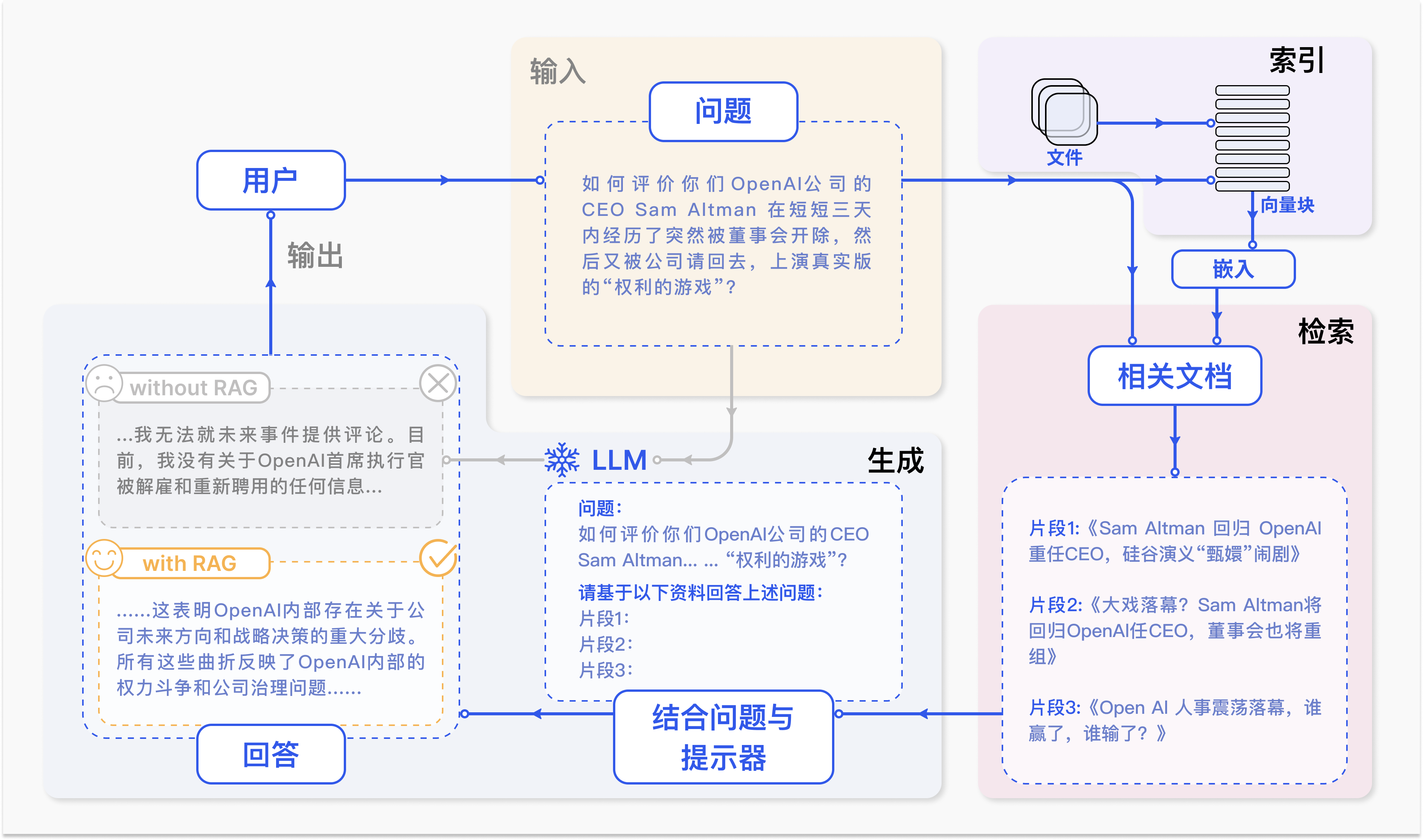
RAG(Retrieval-Augmented Generation,检索增强生成)几乎是大模型落地的“标配”,但不少朋友会遇到一个核心问题:检索不准,生成跑偏。
那么问题来了:RAG 的检索精准度,真的有可能提升 80% 吗?
答案是:可以,但靠的不是单点技术突破,而是系统性、层次化的优化。
本文将拆解一个“组合拳”式的优化路径,从数据到检索、从查询到后处理,逐步提升效果。
本文较长,建议点赞收藏,以免遗失。更多AI大模型开发 学习视频/籽料/面试题 都在这>>Github<< >>Gitee<<
🎯 核心理念:精准度的本质公式
我们可以用一个简单的公式来理解:
精准度 = (相关性 × 完整性) ÷ 噪声
提升检索质量的过程,就是:
- 最大化相关性:让检索结果真正回答用户问题;
- 保证完整性:避免只检索到片面信息;
- 降低噪声:减少无关内容进入模型输入。
接下来,我们分四个环节展开。
① 夯实地基 —— 数据处理与索引优化(提升约 20-30%)
大家常说“垃圾进,垃圾出”,这在 RAG 里尤其明显。
-
分块策略革命
- 告别固定长度分块:容易割裂语义。
- 用 内容感知分块:按段落、标题、标记语言切分,保留上下文。
- 子块检索 + 父块扩展:检索时索引“小块”,召回后提供“大块”,既准又全。
-
数据清洗与丰富化
- 去除 HTML 标签、页脚广告等噪音。
- 注入元数据(作者、章节、时间等),方便后续过滤。
- 生成 假设性问题(Hypothetical Questions),作为数据块的“额外入口”,增强可检索性。
② 架设桥梁 —— 查询优化(提升约 15-20%)
用户输入的自然语言,往往并不是最佳检索指令。
-
查询扩展
- 同义词、缩写扩展(如 RAG → Retrieval-Augmented Generation → 检索增强生成)。
- LLM 重写,把模糊口语化的提问转化成更结构化的检索语句。
-
查询分解
- 复杂问题先拆解成多个子问题分别检索,再汇总结果。
- 例如:“对比 LlamaIndex 和 LangChain 的 RAG 优劣”,可分解成“LlamaIndex 的特点”“LangChain 的特点”“二者比较”。
③ 升级引擎 —— 检索策略进化(提升约 30-40%)
这是提升检索效果的“核心战场”。
-
混合搜索(Hybrid Search)
- 语义搜索擅长理解含义,但关键词搜索在术语、精确匹配上更可靠。
- 两者结合,用 RRF(倒数排序融合) 融合结果,往往能立刻提升 20% 以上效果。
-
图检索(Graph RAG)
- 构建知识图谱,利用实体与关系的连接来检索。
- 特别适合多步推理、复杂关系问题。
-
多路召回
- 启动多种检索策略(向量、BM25、图检索、元数据过滤等),再统一融合。
- 类似“集体智慧”,单一路径不够稳,多路结合更鲁棒。
④ 精雕细琢 —— 后处理与重排(提升约 10-20%)
即便检索到 TopK 结果,也要分优先级。
-
重排(Re-ranking)
- Bi-Encoder 检索快,但粗糙。
- Cross-Encoder 重排能捕捉深层语义交互,显著提升相关性判断。
-
信息压缩与整合
- 在交给 LLM 之前,先对文档做“预处理”:提取关键句子、总结核心信息,降低噪声输入。
✅ 实施路径建议
如果你要落地优化,可以分三步走:
-
基础盘(即刻见效,+30-40%)
- 内容感知分块
- 混合搜索(向量 + BM25 + RRF)
-
进阶盘(效果叠加,+20-30%)
- LLM 查询重写
- Cross-Encoder 重排
-
高级盘(复杂场景,+10-20%)
- Graph RAG
- 查询分解,多跳推理
- 构建系统化评估体系
最终效果:80% 的提升并非幻想,而是系统优化的自然结果。
🔚 总结
RAG 的优化不是“调一个参数”的事,而是 系统工程。
数据 → 查询 → 检索 → 重排,每一步都藏着巨大的改进空间。
一句话总结:
想让 RAG 真正好用,别只盯着模型,要先修炼“检索的内功”。