【完整源码+数据集+部署教程】X片唇部实例分割系统源码和数据集:改进yolo11-swintransformer
背景意义
研究背景与意义
在计算机视觉领域,实例分割技术的迅速发展为图像理解和分析提供了新的可能性。尤其是在医疗、化妆品和人机交互等应用场景中,精确的唇部实例分割不仅可以提升图像处理的效率,还能为后续的分析和决策提供可靠的数据支持。近年来,YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,进一步提升了检测精度和速度,成为实例分割任务中的一项重要工具。
本研究旨在基于改进的YOLOv11模型,构建一个针对唇部的实例分割系统。该系统将专注于下唇和上唇两个类别的精确分割,以满足不同应用场景的需求。我们使用的120seg-Instance-Seg数据集包含1200张经过标注的唇部图像,涵盖了多种姿态和光照条件。这一数据集的设计不仅为模型训练提供了丰富的样本,还为后续的性能评估奠定了基础。
唇部的实例分割在多个领域具有重要的应用价值。例如,在医学影像分析中,精确的唇部分割可以帮助医生更好地识别和诊断相关疾病;在化妆品行业,唇部分割技术可以用于虚拟试妆和个性化推荐;在社交媒体和虚拟现实中,唇部识别和分割则可以提升用户体验。因此,基于YOLOv11的唇部实例分割系统的研究不仅具有理论意义,还具备广泛的实际应用前景。
通过本研究,我们希望能够提升唇部实例分割的准确性和效率,为相关领域的研究和应用提供新的技术支持。这将推动计算机视觉技术在实际场景中的应用,促进相关产业的发展与创新。
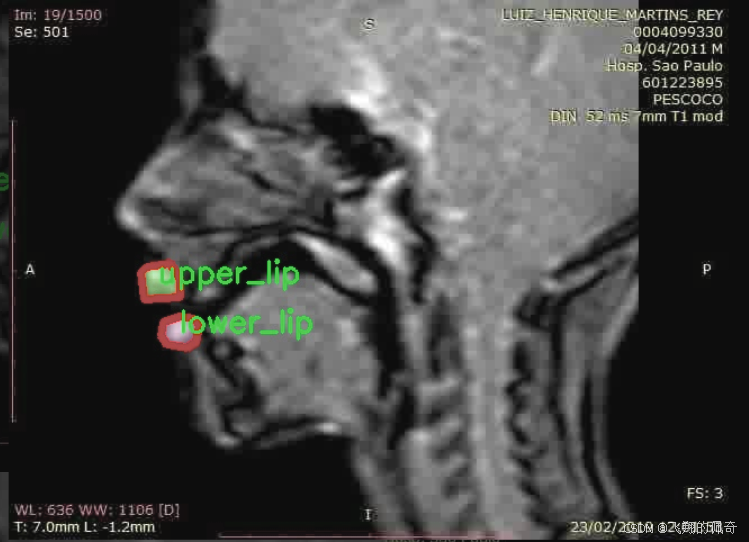
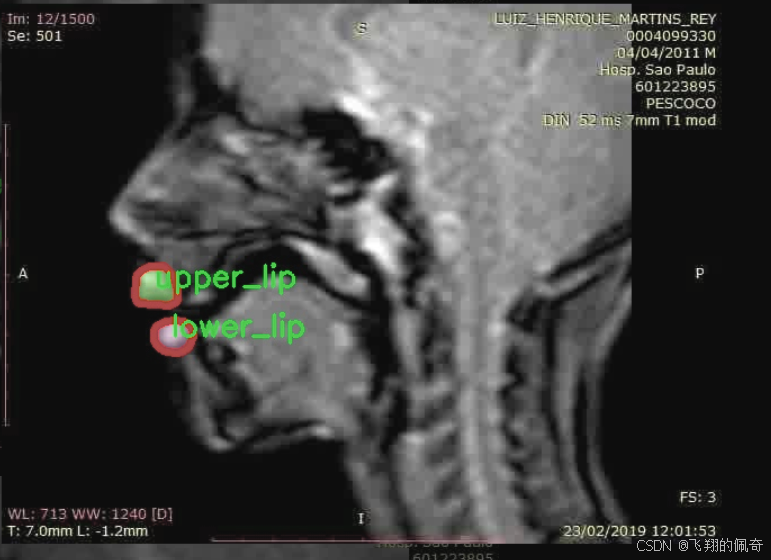
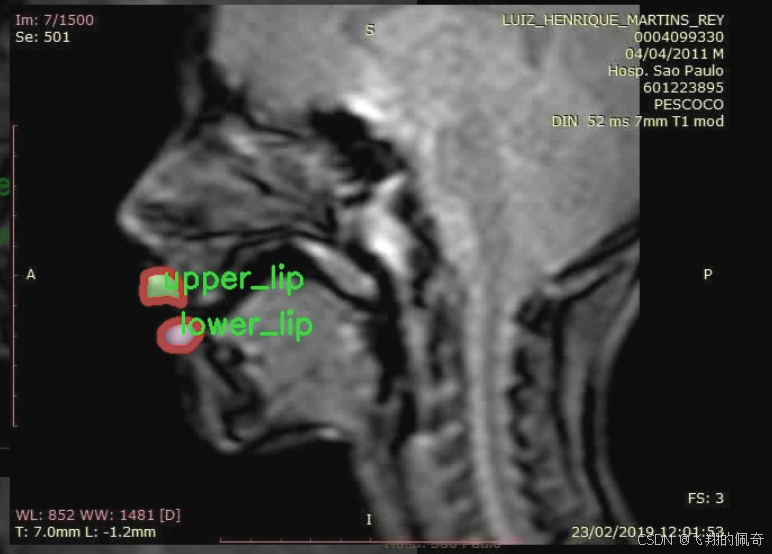
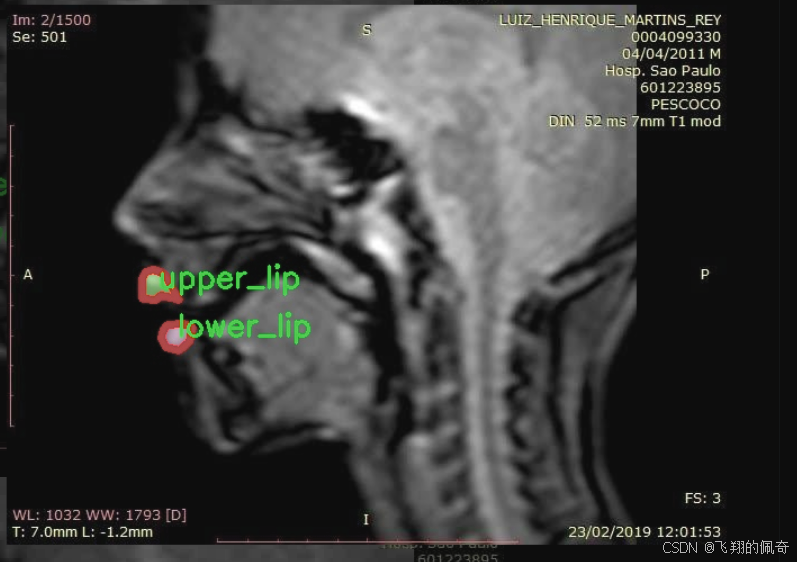
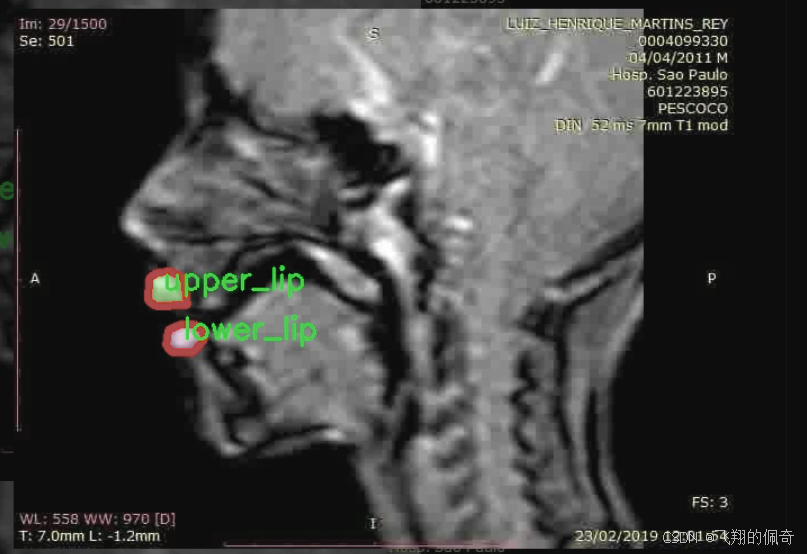
图片效果
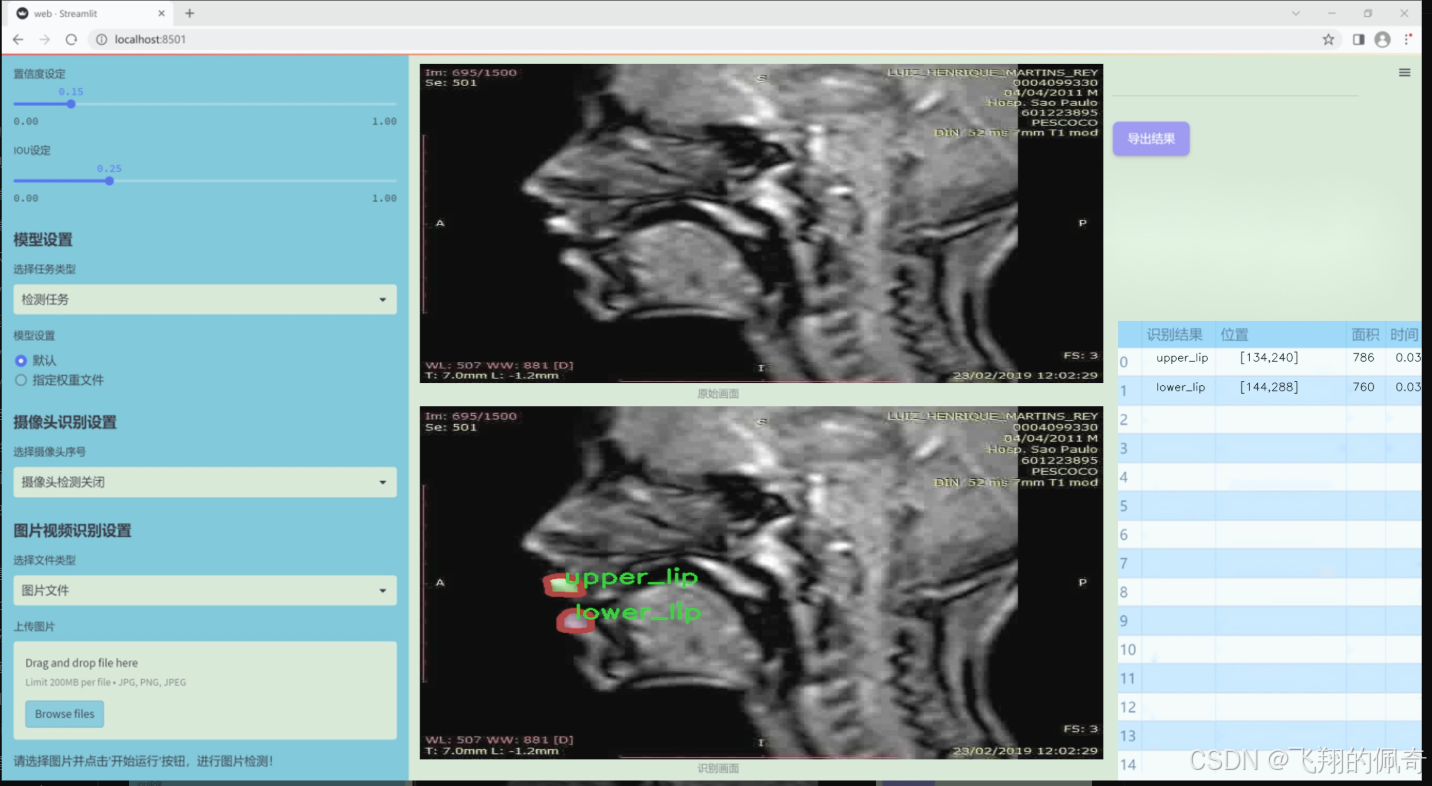
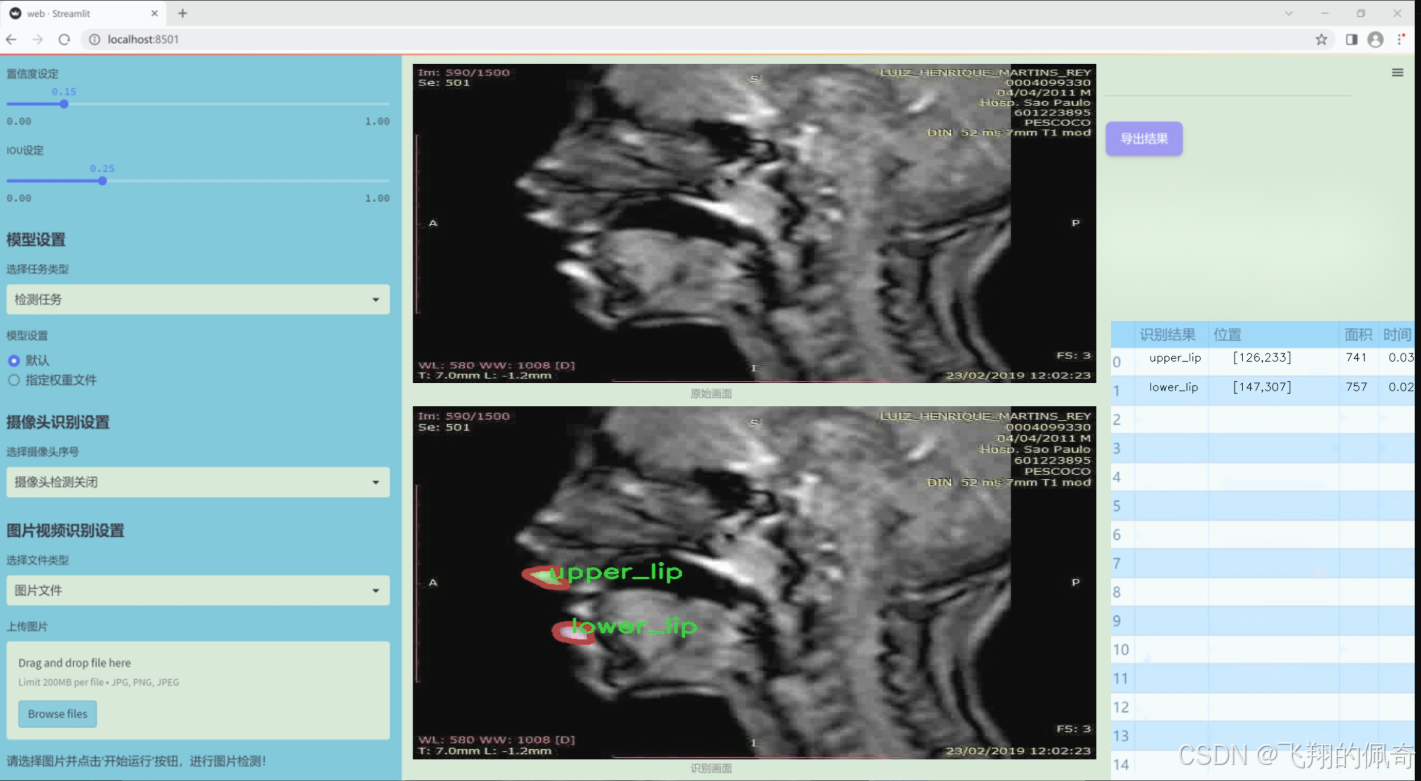
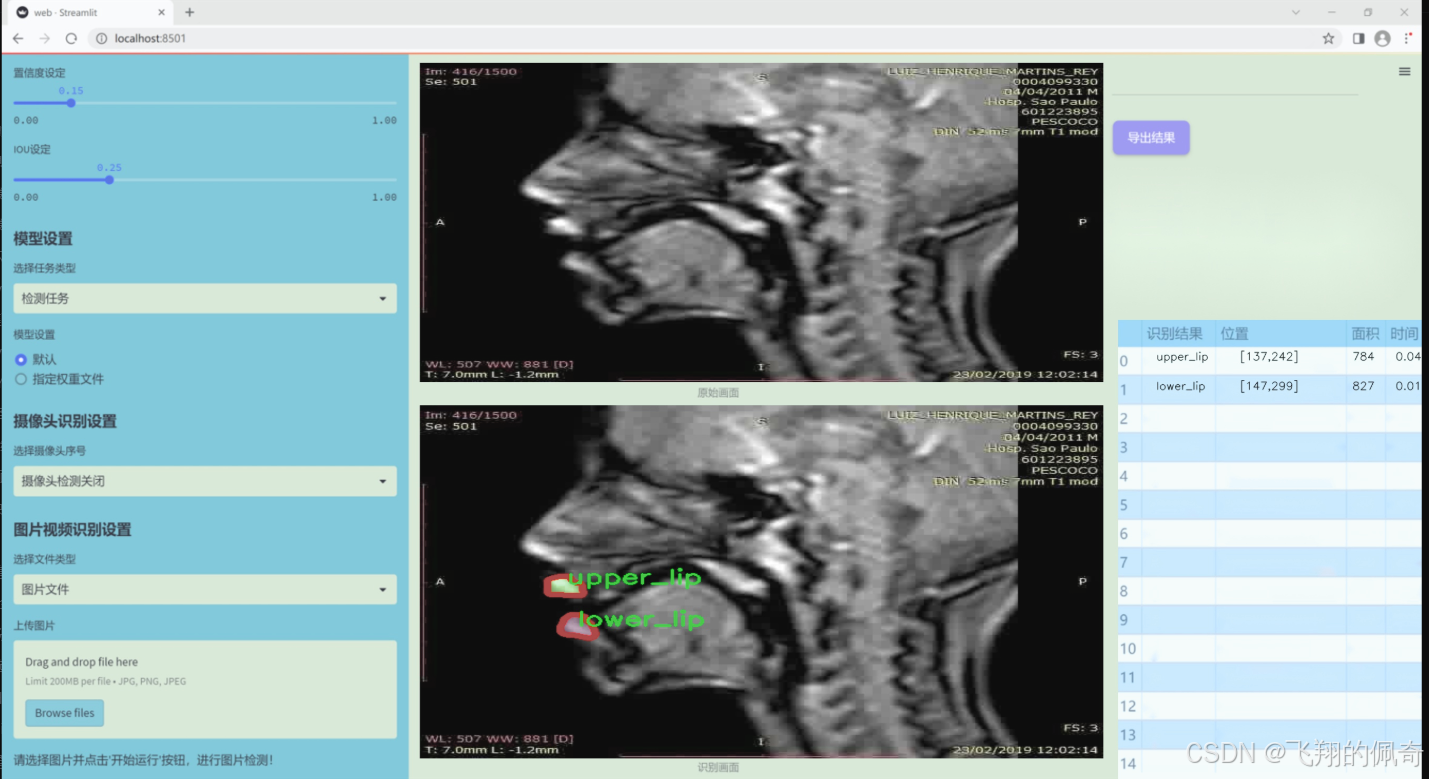
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的X片唇部实例分割系统,所使用的数据集名为“120seg-Instance-Seg”。该数据集专注于唇部的实例分割任务,特别是下唇和上唇的精确识别与分割。数据集中包含两类主要对象,分别为“lower_lip”(下唇)和“upper_lip”(上唇),总类别数量为2。这一分类设计使得模型能够有效地学习和区分唇部的不同部分,从而提高分割的准确性和鲁棒性。
数据集的构建过程涉及多种图像采集技术,确保了样本的多样性和代表性。图像样本涵盖了不同光照条件、角度以及唇部的形态变化,以便于模型在实际应用中能够处理各种复杂情况。此外,数据集中的每一张图像都经过精确标注,确保下唇和上唇的轮廓清晰可辨。这种高质量的标注为模型的训练提供了坚实的基础,使其能够在分割任务中达到更高的性能。
在训练过程中,模型将利用这些标注信息进行特征学习,通过不断迭代优化其参数,以提高对唇部实例的识别和分割能力。随着训练的深入,模型将逐渐掌握如何在不同背景和条件下准确识别出下唇和上唇的边界。这一过程不仅有助于提升模型的分割精度,也为后续的应用提供了强有力的支持。
总之,“120seg-Instance-Seg”数据集为本项目提供了丰富的唇部实例分割样本,结合YOLOv11的先进算法,将推动唇部分割技术的发展,助力相关领域的研究与应用。
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MF_Attention(nn.Module):
“”"
自注意力机制的实现,参考Transformer模型。
“”"
def init(self, dim, head_dim=32, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False):
super().init()
# 设置每个头的维度self.head_dim = head_dim# 缩放因子self.scale = head_dim ** -0.5# 计算头的数量self.num_heads = num_heads if num_heads else dim // head_dimif self.num_heads == 0:self.num_heads = 1# 计算注意力的维度self.attention_dim = self.num_heads * self.head_dim# 定义线性层用于计算Q、K、Vself.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)# 定义注意力的dropout层self.attn_drop = nn.Dropout(attn_drop)# 定义输出的线性层self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias)# 定义输出的dropout层self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):# 获取输入的批次大小、高度、宽度和通道数B, H, W, C = x.shapeN = H * W # 计算总的token数量# 计算Q、K、Vqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)q, k, v = qkv.unbind(0) # 分离Q、K、V# 计算注意力分数attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1) # 归一化attn = self.attn_drop(attn) # 应用dropout# 计算输出x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)x = self.proj(x) # 线性变换x = self.proj_drop(x) # 应用dropoutreturn x # 返回最终的输出
class MetaFormerBlock(nn.Module):
“”"
MetaFormer块的实现。
“”"
def init(self, dim,
token_mixer=nn.Identity, mlp=Mlp,
norm_layer=partial(LayerNormWithoutBias, eps=1e-6),
drop=0., drop_path=0.,
layer_scale_init_value=None, res_scale_init_value=None):
super().init()
# 归一化层self.norm1 = norm_layer(dim)# 令牌混合器self.token_mixer = token_mixer(dim=dim, drop=drop)# 路径丢弃self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()# 层缩放self.layer_scale1 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale1 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()# 第二个归一化层self.norm2 = norm_layer(dim)# MLP层self.mlp = mlp(dim=dim, drop=drop)self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.layer_scale2 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale2 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()def forward(self, x):# 进行维度转换x = x.permute(0, 2, 3, 1)# 第一部分:归一化 -> 令牌混合 -> 路径丢弃 -> 层缩放x = self.res_scale1(x) + \self.layer_scale1(self.drop_path1(self.token_mixer(self.norm1(x))))# 第二部分:归一化 -> MLP -> 路径丢弃 -> 层缩放x = self.res_scale2(x) + \self.layer_scale2(self.drop_path2(self.mlp(self.norm2(x))))return x.permute(0, 3, 1, 2) # 返回最终的输出,恢复维度
代码核心部分说明:
MF_Attention: 实现了自注意力机制,包含了Q、K、V的计算,以及注意力分数的归一化和输出的线性变换。
MetaFormerBlock: 实现了MetaFormer的基本结构,包含了归一化、令牌混合、MLP和残差连接的操作。通过组合这些操作来构建深度学习模型的基本单元。
这个程序文件 metaformer.py 实现了一些用于构建 MetaFormer 模型的基本组件,主要包括各种层和模块,适用于深度学习中的图像处理任务。文件中使用了 PyTorch 框架,并且包含了一些常用的操作,如自注意力机制、激活函数、归一化等。
首先,文件定义了一些基础类。Scale 类用于通过元素乘法对输入进行缩放,可以选择是否训练这个缩放参数。SquaredReLU 和 StarReLU 是两种不同的激活函数,前者是对 ReLU 的平方,后者则是对 ReLU 输出进行缩放和偏置处理。
接下来,MF_Attention 类实现了标准的自注意力机制,类似于 Transformer 中的自注意力。它通过线性变换生成查询、键和值,并计算注意力权重,最后通过线性变换和 dropout 输出结果。
RandomMixing 类用于对输入进行随机混合,通过生成一个随机矩阵来实现。LayerNormGeneral 类是一个通用的层归一化实现,可以根据输入的形状灵活调整归一化的维度和参数。
SepConv 类实现了分离卷积,使用了逐点卷积和深度卷积的组合。Pooling 类实现了一种池化操作,主要用于 PoolFormer 模型。
Mlp 类定义了一个多层感知机(MLP),通常用于 MetaFormer 模型中,包含两个线性层和激活函数。ConvolutionalGLU 类实现了一种卷积门控线性单元(GLU),结合了卷积操作和激活函数。
MetaFormerBlock 和 MetaFormerCGLUBlock 类分别实现了 MetaFormer 的基本模块,前者使用标准的 MLP,后者使用卷积 GLU。它们都包含了归一化、混合和残差连接的操作,以增强模型的表达能力。
整个文件通过定义这些模块,提供了构建 MetaFormer 及其变种的基础,用户可以根据需要组合这些组件来实现不同的网络结构。每个模块都可以根据具体任务进行调整和优化,以适应不同的输入和需求。
10.4 FreqFusion.py
以下是经过简化和注释的核心代码部分,主要包括 FreqFusion 类及其相关方法。这个类实现了频率感知特征融合,用于密集图像预测。
import torch
import torch.nn as nn
import torch.nn.functional as F
class FreqFusion(nn.Module):
def init(self, channels, scale_factor=1, lowpass_kernel=5, highpass_kernel=3, **kwargs):
super().init()
hr_channels, lr_channels = channels
self.scale_factor = scale_factor
self.lowpass_kernel = lowpass_kernel
self.highpass_kernel = highpass_kernel
# 压缩高分辨率和低分辨率特征通道self.compressed_channels = (hr_channels + lr_channels) // 8self.hr_channel_compressor = nn.Conv2d(hr_channels, self.compressed_channels, 1)self.lr_channel_compressor = nn.Conv2d(lr_channels, self.compressed_channels, 1)# 内容编码器,用于生成低通和高通滤波器self.content_encoder = nn.Conv2d(self.compressed_channels,lowpass_kernel ** 2,kernel_size=3,padding=1)self.content_encoder2 = nn.Conv2d(self.compressed_channels,highpass_kernel ** 2,kernel_size=3,padding=1)def kernel_normalizer(self, mask, kernel):"""归一化卷积核,确保其和为1。"""mask = F.softmax(mask, dim=1) # 对mask进行softmax处理mask = mask / mask.sum(dim=(-1, -2), keepdims=True) # 归一化return maskdef forward(self, x):"""前向传播,接收高分辨率和低分辨率特征并进行融合。"""hr_feat, lr_feat = x # 拆分输入特征compressed_hr_feat = self.hr_channel_compressor(hr_feat) # 压缩高分辨率特征compressed_lr_feat = self.lr_channel_compressor(lr_feat) # 压缩低分辨率特征# 生成低通和高通滤波器mask_lr = self.content_encoder(compressed_hr_feat) + self.content_encoder(compressed_lr_feat)mask_hr = self.content_encoder2(compressed_hr_feat) + self.content_encoder2(compressed_lr_feat)# 归一化卷积核mask_lr = self.kernel_normalizer(mask_lr, self.lowpass_kernel)mask_hr = self.kernel_normalizer(mask_hr, self.highpass_kernel)# 使用卷积核对特征进行处理lr_feat = F.conv2d(lr_feat, mask_lr) # 低分辨率特征处理hr_feat = F.conv2d(hr_feat, mask_hr) # 高分辨率特征处理return hr_feat + lr_feat # 返回融合后的特征
示例用法
freq_fusion = FreqFusion(channels=(64, 32))
output = freq_fusion((high_res_feature, low_res_feature))
代码注释说明:
类定义:FreqFusion 类继承自 nn.Module,用于实现频率感知特征融合。
初始化方法:init 方法中定义了高分辨率和低分辨率特征的通道压缩,以及低通和高通滤波器的卷积层。
卷积核归一化:kernel_normalizer 方法用于对生成的卷积核进行归一化处理,确保其和为1,以便在后续的卷积操作中不会改变特征的整体能量。
前向传播:forward 方法接收高分辨率和低分辨率特征,进行压缩、生成滤波器、归一化,并最终融合特征。
该代码的核心逻辑是通过频率感知的方法,将不同分辨率的特征进行融合,以提高图像预测的效果。
这个程序文件 FreqFusion.py 实现了一种频率感知特征融合的方法,主要用于密集图像预测任务。代码中使用了 PyTorch 框架,定义了一个名为 FreqFusion 的神经网络模块,旨在通过高频和低频特征的融合来提高图像的重建质量。
首先,文件中导入了必要的库,包括 PyTorch 的核心模块和一些函数。接着,定义了一些初始化函数,例如 normal_init 和 constant_init,用于初始化神经网络的权重和偏置。resize 函数用于调整输入张量的大小,支持不同的插值模式,并在必要时发出警告。
接下来,hamming2D 函数用于生成二维 Hamming 窗口,这在后续的特征融合过程中可能会用到。FreqFusion 类是整个程序的核心,包含了多个参数和子模块,用于处理高分辨率和低分辨率特征的融合。
在 init 方法中,初始化了一些卷积层和参数,包括用于压缩高分辨率和低分辨率特征的卷积层、用于生成低通和高通滤波器的卷积层等。该类还支持特征重采样、残差连接等功能,允许用户根据需要选择是否使用这些功能。
init_weights 方法用于初始化网络中卷积层的权重,确保模型在训练开始时具有良好的初始状态。kernel_normalizer 方法用于对生成的掩码进行归一化处理,以确保其在后续操作中的有效性。
forward 方法是模型的前向传播过程,它接收高分辨率和低分辨率特征,并根据配置选择是否使用检查点机制来节省内存。_forward 方法则是实际的计算过程,包括特征的压缩、掩码的生成以及高频和低频特征的融合。
在 _forward 方法中,首先对输入的高分辨率和低分辨率特征进行压缩,然后根据是否使用半卷积和其他配置生成相应的掩码。通过对掩码的处理,最终得到融合后的高分辨率特征和低分辨率特征的输出。
此外,LocalSimGuidedSampler 类实现了一个偏移生成器,用于在特征融合过程中生成采样偏移。它根据输入特征的相似性计算偏移,并使用这些偏移对特征进行重采样,以提高融合效果。
最后,compute_similarity 函数用于计算输入张量中每个点与其周围点的余弦相似度,帮助评估特征之间的相似性。
总体而言,这个程序实现了一种复杂的特征融合机制,通过频率域的处理来提升图像重建的效果,适用于计算机视觉中的密集预测任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻