⚡ Linux sed 命令全面详解(包括参数、指令、模式空间、保持空间)
🧊 1. sed 简介
sed 是 Linux 提供的 流式编辑器(stream editor),用于批量编辑或处理文本文件。
它的强大之处在于 无需打开文件即可对文件内容进行复杂操作,适合自动化脚本和批量处理。
sed 命令高度抽象,学习难度堪比直接学一门小型的编程语言(这也是这篇博客为什么长原因之一),但是掌握后可大幅度提高效率,配合正则表达式,可实现黑客级的文本处理能力(这也是为什么你会看我这篇博客的原因之一)。
此外,强烈建议在学习 `sed` 之前,先熟悉 正则表达式(regex)。
正则表达式的相关内容,详见
[ regexp 正则表达式详解(以后有空更) ]
⚠️ 注意:本文提到的 sed 指的是 GNU sed,就是主流 Linux 系统中安装的 sed ,其他版本的 sed 命令的行为和参数可能不同
🍃 2. sed 用法
✏️ 2.1 基础用法
在命令行用 sed 预览文本修改后的内容:
sed [命令行参数] [脚本语句] [目标文件]也可以直接对文件进行修改:
sed -i [命令行参数] [脚本语句] [目标文件]如果是萌新建议在修改文件的同时备份文件,这样万一命令打错了还能抢救一下:
sed -i.bak [命令行参数] [脚本语句] [目标文件]或者将文件修改后另存为新文件:
sed [命令行参数] [脚本语句] [目标文件] > [新文件]
📂 2.2 脚本用法
可以从 sed 脚本文件中读取内容进行操作:
sed -f [命令行参数] [脚本文件] [目标文件]sed 脚本文件一般都是 .sed 后缀,文件内容是多条脚本语句,一般一条脚本语句占一行例如
/^$/d
s/foo/bar/g
$ s/$/123/
……
不过现实中这种用法一般很少见,较复杂的 sed 大多数都是写到 shell 脚本中,配合变量和函数使用的。
知道有这么一种用法就行了。
🔗 2.3 管道用法
sed 可以与管道结合,将其他命令输出作为输入进行处理:
[其他命令] | sed [命令行参数] [脚本语句]
这也是 sed 最常用的用法。
🏝️ 3. sed 概念
在介绍 sed 的各种参数、模式和语法之前,有必要先对 sed 中各种元素的概念进行一些澄清,否则容易导致后面的内容难以理解。没错,这篇文章的目的不是教读者去死记硬背一条条的 sed 命令,而是教读者理解 sed 的原理,以及每个参数的含义,让读者可以创造属于自己的 sed 命令。
📌 3.1 命令行参数和脚本语句
在上一章节 sed 用法中提到多种用法,但是大多数用法中都包含了命令行参数 和 脚本语句 这两个核心元素。
这里的 命令行参数 指的是控制 sed 行为的选项,一般前面都带 - 或 -- 。
这里的 脚本语句 指的是用 sed 脚本写的代码,一般都用 ' ' 包裹。
比如这条命令:
sed -E '2s/[0-9]*$/OK/' 22.txt这里我们先不关心这条命令的含义,而是把重点放在这条命令的结构上。这条命令用的是 sed 基础用法中的第一种,所以 -E 是命令行参数,'2s/[0-9]*$/OK/' 是脚本语句,22.txt是目标文件。
♻️ 3.2 内部循环
虽然 sed 处理速度很快,一个命令敲下去所有处理的结果会几乎同时打印出来,但是我们需要知道 sed 对输入的处理是按行处理的。sed 运行的时候内部有一个循环,每个循环只处理一行文本,处理完以后才会继续处理下一行,这个循环会从第一行开始到最后一行结束,在处理完所有内容后 sed 才会打印。而 sed 脚本语句的核心逻辑也是围绕这个内部循环展开的。
比如这条命令:
sed -E '2s/[0-9]*$/OK/; /OK$/d' 22.txt这条命令中有两条脚本语句,他们都被包在 ' ' 中,并且以 ; 分割。第一条语句是 2s/[0-9]*$/OK/ ,第二条语句是 /OK$/d 。在这里我们先不关心这两条脚本的含义,而是把重点放在他们执行的流程上。sed 在执行这条命令的时候会先对第一行执行 2s/[0-9]*$/OK/ 这条脚本语句,然后对第一行执行 /OK$/d 这条脚本语句;都执行完成后循环到第二行,先对第二行执行 2s/[0-9]*$/OK/ 这条脚本语句,再对第二行执行 /OK$/d 这条脚本语句;然后再循环到第三行,依次类推,直到所有行都执行过这两条脚本。最后在退出程序的时候再打印所有处理过的内容。
⚠️ 注意:不要理解为是sed先对所有行执行 2s/[0-9]*$/OK/; 这条命令,再对所有行执行 /OK$/d 这条命令。这实际上是错误的。特别时遇到复杂的 sed 脚本时,这么理解会导致实际结果和预期结果出入很大。
🗂️ 3.3 模式空间和保持空间
要理解模式空间和保持空间,我们需要结合上一小节讲到的内部循环,更深入的分析 sed 的执行流程。特别是 sed 处理每一行文本的流程。sed 的每次内部循环都会自动的从输入中读取一行,然后自动的把这行放入模式空间。之后 sed 的脚本语句会自动的在模式空间内对这行数据进行操作。操作完成后,默认sed 会自动的打印模式空间中(被脚本语句操作过)的内容,然后自动的清空模式空间,从输入中读取下一行,进入下一次内部循环。
模式空间实际上就是这么一个缓冲区,在每个内部循环中,用来存放临时从输入中读取的行,用来让 sed脚本对读取的行进行操作,最后用来输出的这么一个缓冲区。
保持空间实际上也是一个缓冲区,但是他和模式空间不同,里面的内容默认不会随着进入下一个循环而自动的清空(除非你手动添加清空的脚本)。他的功能就相当于模式空间的剪切板,可以将模式空间的内容展示剪切到保持空间,也可以在需要的使用从保持空间粘贴回模式空间。
🍞 4. sed 命令行参数
📝 4.1 输入参数
- -f scriptname: 前面第二章的 2.2 脚本用法 小节提到过这个参数,主要用于从 scriptname 脚本文件中读取 sed 脚本,知道有这么一种玩法就好。
- -s: 这个参数主要是为 sed 处理多文件的时候准备的。sed 默认的操作会将多文件输入当成是一个连续的输入流,导致sed 脚本指令无法正确匹配每个文件的首行和末行位置。加了 -s 参数以后 sed 会把多文件输入当成是多个输入流,然后 sed 的脚本指令就可以正确匹配到每个文件的首行和末行位置,效果:
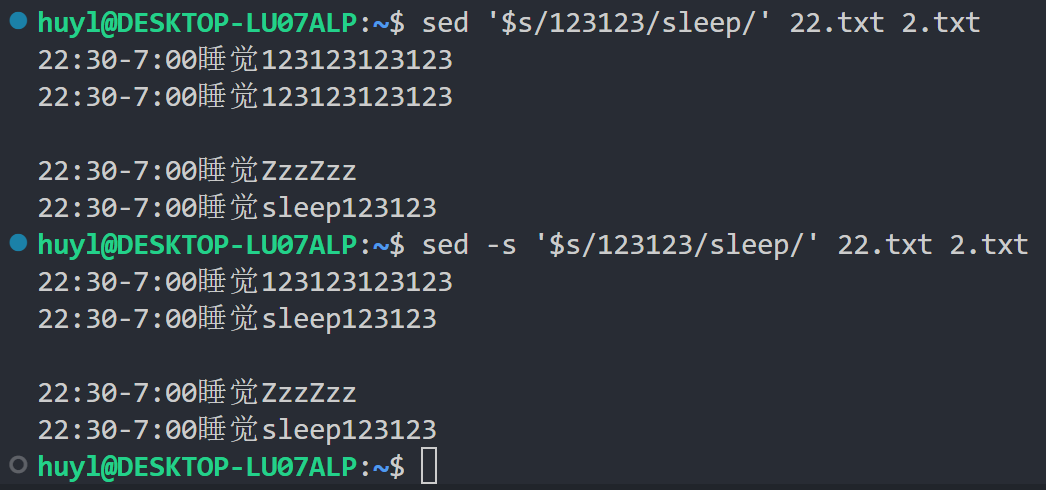
解释:这里看到不加 -s 参数 sed 识别不到 22.txt 的末行,只将 2.txt 末行的 123123 替换成 sleep;在加了 -s 参数以后,sed能识别到 22.txt 的末行,将 22.txt 和 2.txt 末行的 123123 都替换成了 sleep 。其实多写几条 sed 命令,每条处理一个文本,照样可以解决这个问题。
⚠️ 注意:在 sed 命令中同一个字符在不同的位置可能会表示不同的含义,这也是学习 sed 命令的过程中最痛苦的一点。比如上面的 $ 符号,在正则表达式中表示末行,在 sed 脚本指令中表示行末,而在输出中则表示行末的不可见字符。
- -e: 用于显示指定指令,增强 sed 脚本的可读性,同时也可以在通过这个参数,在一条 sed 命令里执行多条脚本语句,效果:
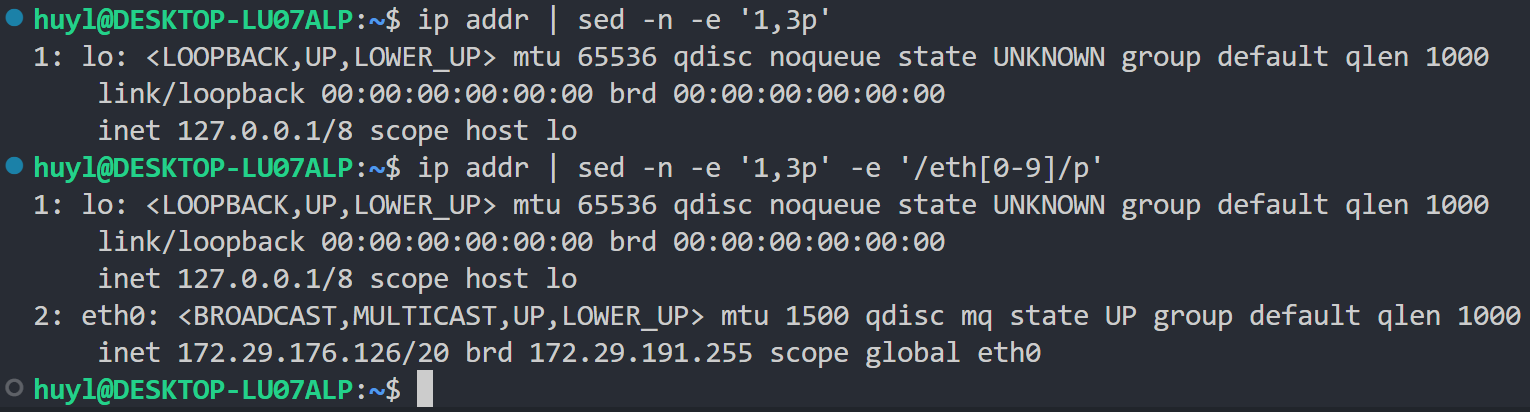
解释:这里第一个 sed 命令只执行了 '1,3p' 这条脚本语句,打印了1-3行;第二个 sed 命一共令执行了 '1,3p' 和 '/eth[0-9]/p' 两条脚本语句,打印了1-3行,同时还打印了匹配到正则表达式 eth[0-9] 的两行。-e 参数在一条命令中执行多条脚本语句的效果,和在一个 ' ' 中用 ; 来分割出多条脚本语句的效果相同,也就是说第二条命令等同于:
ip addr | sed -n '1,3p; /eth[0-9]/p'这种用 ; 来分割脚本语句的写法虽然更抽象,但是可以少打4个字符,效率更高。
- -E: sed 默认使用的正则表达式时BRE,加上这个参数可以设置成ERE,让你在打正则表达式的时候可以少打几个 \ 转义符号。效果:
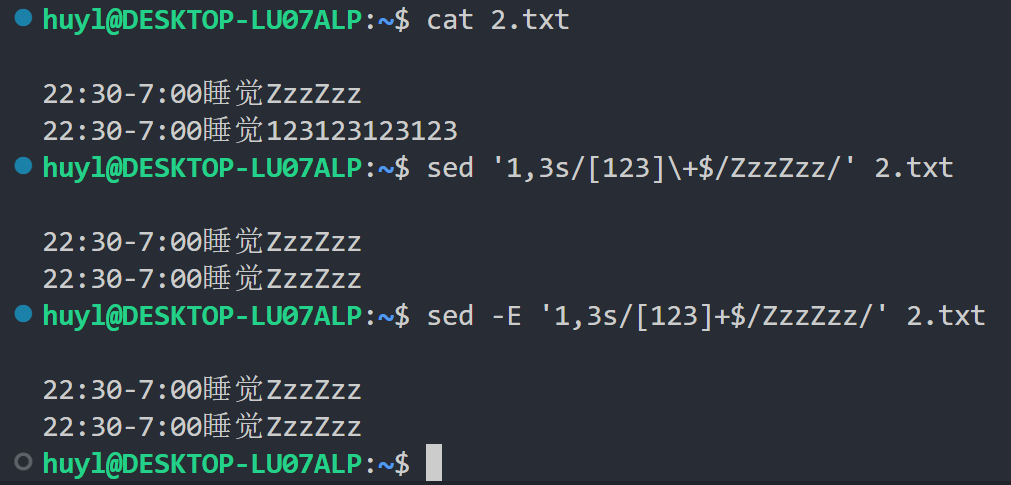
解释:BRE和ERE的区别就在于特殊字符需不需要用 \ 转义,比如上面第一条 sed 命令用的是 BRE ,[123]后面的 + 是特殊字符需要转义才能实现特殊功能。第二条 sed 命令用的是 ERE ,[123]后面的 + 不需要转义就能实现特殊功能。本文中为了演示更清楚有时候用的是 BRE, 但实战中推荐使用 ERE ,这样就不用背那些可恶的特殊字符了。
- -z: 将输入按照 NUL 字符( \0 )分割,而不是按照换行符分割。主要用于和 find -print0 配合使用,效果:

解释:可以看到 find -print0 输出的内容全部在同一行没有用换行符而是用 \0 这个不可见字符分割的。正常情况下 sed 会按照换行符来分割,把这串输出当作一行来处理,但是加了 -z 就会按照 \0 字符来分割,把这串输出当作多行来处理。所以最后匹配一到三行只匹配到了3个 txt 文件
🖨️ 4.2 输出参数
- -n: 之前的内部循环概念中提到,sed在每次循环结束后,就是每行处理完的时候,都会自动打印并清空依次模式空间的内容。这个参数就是让sed 在每次循环结束后不自动打印模式空间的内容。通常配合 sed 脚本指令中的 p 指令来实现选择性的打印结果。效果:
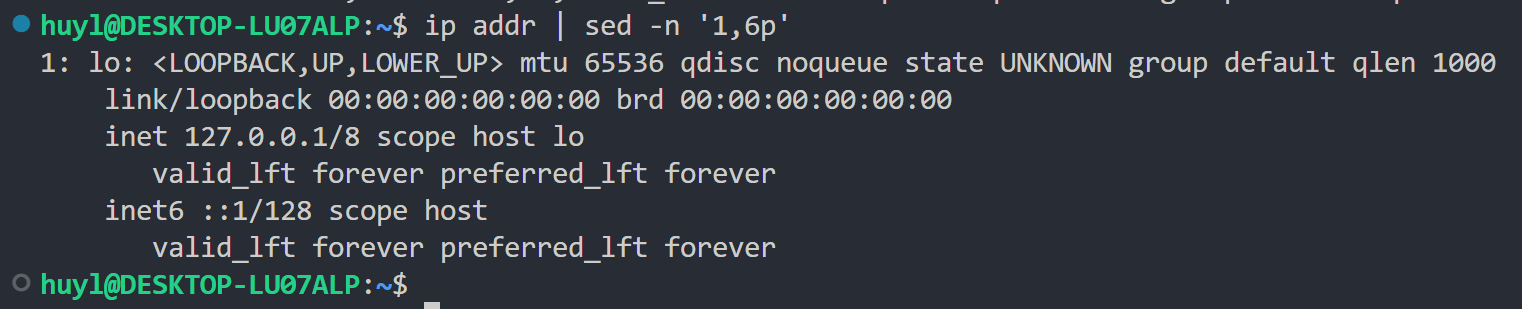
解释:这里用了 -n 命令行参数,配合 sed 脚本语句中的 p 指令,打印了 ip addr 输出信息的1-6行,其他内容不打印(不加 -n 会打印所有行内容)
- -l length : 这个参数由两个作用,第一个作用是用来限制打印的每行长度为 length(如果不适用这个参数默认是70个字符换行),第二个作用是将不可见字符(比如换行等)打印出来。这个参数和 p 指令有冲突,建议在 sed 脚本语句中使用 l 指令,并且配合 -n 参数使用。效果:
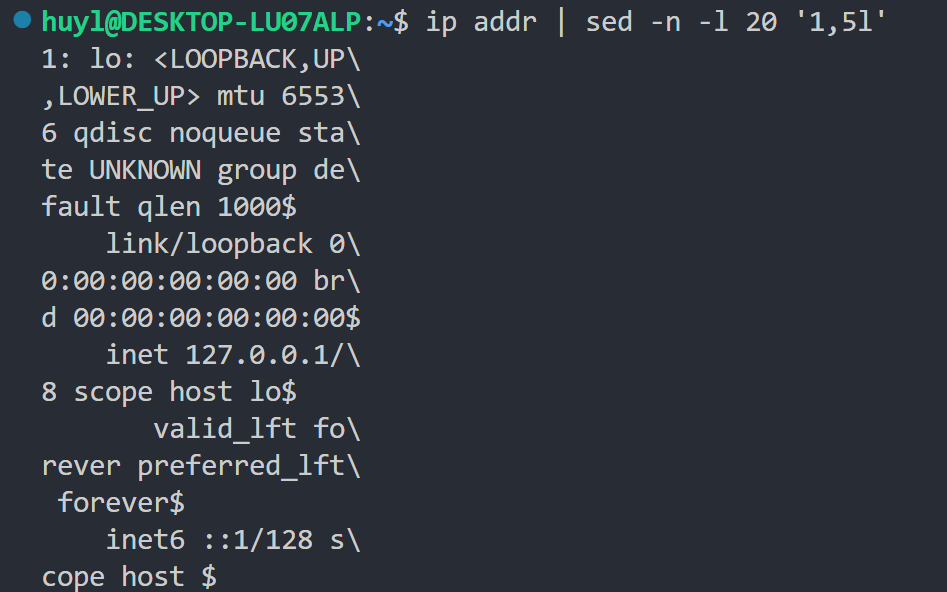
解释:这里打印了ip addr 的1-5行,但是打印输出每20个字符换一次行,这就是 -l 的第一个作用。在打印输出中可以清楚的看到 \ 换行符号和 $ 行尾符号,这些都是不可见字符,这就是 -l 的第二个作用。

解释:这里把 length 设置成 0 表示不限制换行字符,每行有多少字符打印多少字符,但是依然会将不可见字符打印出来(这里由于没限制换行所以没有 \ 换行符号了,只剩下 $ 行尾符号)。在特殊情况下,可以用来排查行尾的空格(比如第5行 host 后面还有一个空格)。
- --debug: 打印 sed 的调试信息,效果:
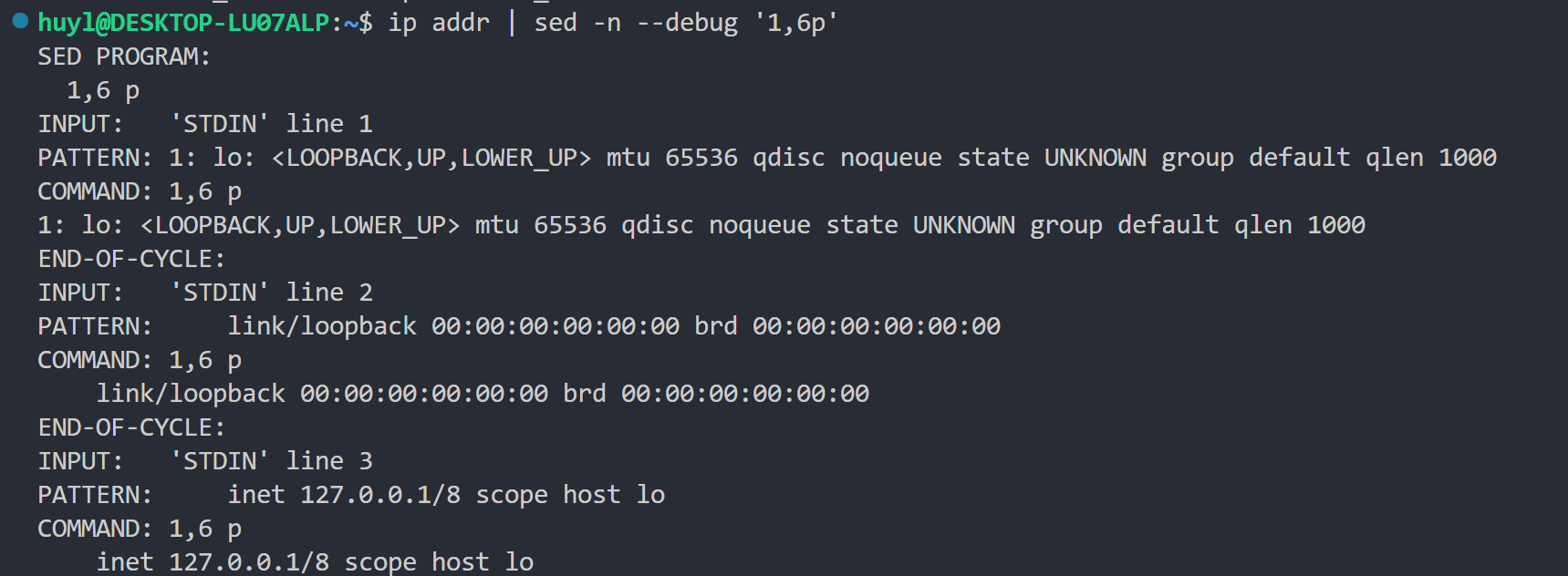
解释:这里可以看到,调试信息中每次循环的输入行(INPUT),执行的脚本指令(COMMAND),以及模式空间的内容(PATTERN),对于编写或理解复杂的 sed 脚本十分有用。
⚙️ 4.3 执行控制参数
- -i: 前面的第二章的 2.1 基础用法 小节提到过这个函数,用于直接修改文件内容,也可以在 -i 参数的后面添加后缀,让 sed 在修改的同时备份(推荐备份),效果:
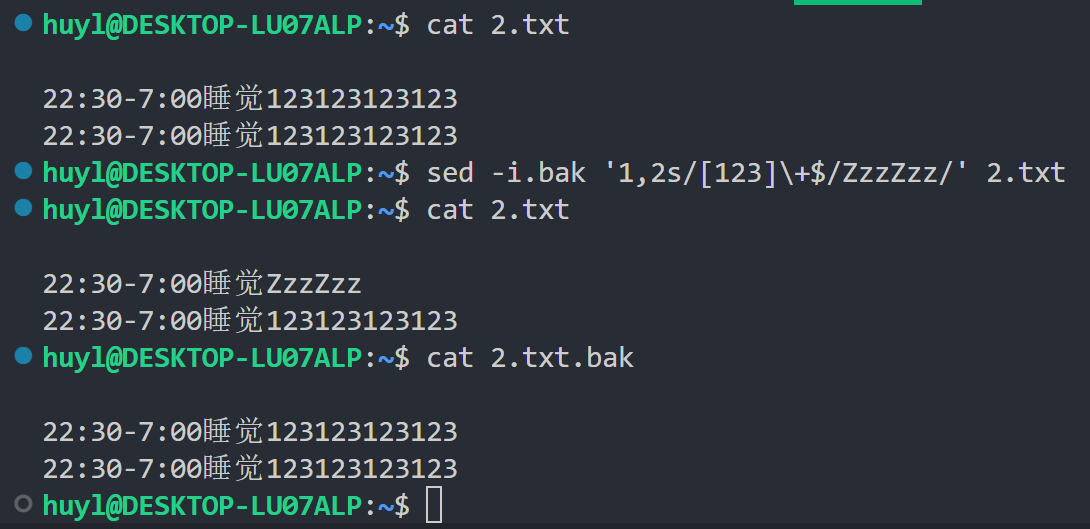
解释:这里先不管命令是什么意思,可以看到执行了带了 -i 参数的 sed 命令后 2.txt 的内容确实改变了,同时生成的备份文件 2.txt.bak 保存了修改之前的内容
- --follow-symlinks: 这个参数是给符号链接文件用的,通常配合 -i 一起使用,用于直接修改符号链接指向的文件。(不加这个参数,当目标文件时符号链接文件时,会直接修改符号链接文件而不是符号链接指向的文件)。
- --sandbox: sed 出于安全考虑设计了这个参数,加了这个参数后可以读写文件名的脚本指令,以及在 sed 脚本中执行 shell 命令的脚本指令,全部会被 sed 拒绝执行。
- -u: 这个参数可以用来取消缓冲区。之前内部循环的概念中为了方便理解,我提到每次循环结束 sed 会自动打印模式空间中的内容并清空模式空间。但实际情况下 sed 默认在每次循环结束时并不会直接打印模式空间,而是把模式空间中的内容取出来放到另一个缓冲区(既不是模式空间也不是保持空间)中,等到这个缓冲区满了再一次性输出。而加了这个参数以后 sed 会取消到这个缓冲区,真正的做到再每次循环结束时直接打印模式空间的内容。这个参数在实战中常常用于处理实时日志文件。
🌸 5. sed 脚本语句
🐝 5.1 sed 脚本语法
🧱 5.1.1 sed 脚本结构
单条脚本语句:
一般单条 sed 脚本语句会都按照以下结构出现
'[匹配地址] [脚本指令]'先是一对单引号,然后里面左边是匹配地址,右边是脚本指令,下面依次介绍:
- 单引号:判断是否是 sed 脚本语句的标志,单引号里面的往往是 sed 脚本语句
- 匹配地址:匹配地址用来限定 sed 脚本指令作用的范围,可以是行号(有多种形式)、特殊地址表示符号、正则表达式、行号和正则表达式相结合的混合地址,也可以省略。行号可以是单独的数字,也可以是两个数字中间加逗号表示的行号范围。如果是正则表达式需要用 / / 包裹,如果省略匹配地址,则默认匹配所有行。
- 脚本指令:脚本指令是 对匹配行执行的操作,可以单独使用,也可以结合正则表达式使用,但是一般情况下脚本指令不可省略。一般一条脚本语句出现一个脚本指令,不建议在一条脚本语句中放多个脚本指令(容易出现无法理解的奇怪现象)。
举个例子:

解释:在这里脚本语句 '5p' 的作用是打印 1.txt 的第五行内容。5 就是以行号形式呈现的匹配地址,表示单独行号,p 就是单独使用的 sed 脚本指令,表示打印
⚠️ 注意:这里需要指出,在 sed 脚本语句中,$ 如果出现在匹配地址中,则表示的是最后一行的行号。$ 符号属于以行号形式呈现的匹配地址,相当于数字。还有一个特别变态的语法,我不是很想提,但是很多高手会用,那就是 $! 这个东西。这个理解起来很困难,建议直接背,$! 属于以行号形式呈现的匹配地址,只要不是最后一行都会被匹配到。我这么说你可能不觉得变态,但是请看 $!N 这个东西,你说这个 ! 非逻辑到底是和 $ 结合的呢?还是和后面的 N 指令结合的呢?答案是和 $ 结合。为什么?我也不知道。
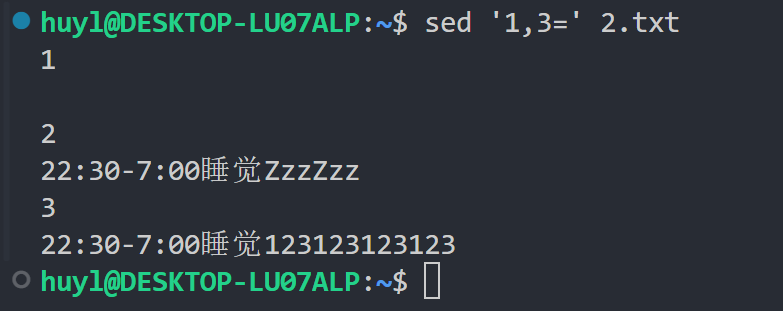
解释:在这里脚本语句 '1,3=' 的作用是打印 2.txt 的1-3 行并输出行号。 1,3 就是以行号形式呈现的匹配地址,表示第1到3行,= 就是单独使用的 sed 脚本指令,表示打印并输出行号。
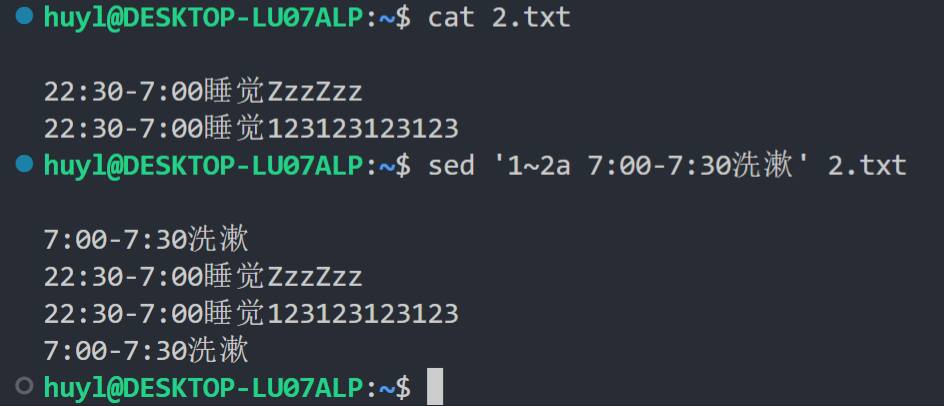
解释:这里的脚本语句中 '1~2a 7:00-7:30洗漱' 的作用是分别在1、3、5行后面追加 “7:00-7:30洗漱” 内容。1~2 就是以行号形式匹配的地址,表示从一开始每个两行进行依次匹配, a 7:00-7:30洗漱 就是单独使用的 sed 脚本命令,表示追加 “7:00-7:30洗漱” 内容。

解释:在这里脚本语句 '/[0-9]+:[0-9]+-[0-9]+:[0-9]+/p' 的作用是打印匹配正则表达式 [0-9]+:[0-9]+-[0-9]+:[0-9]+ 的行。/[0-9]+:[0-9]+-[0-9]+:[0-9]+/ 就是以正则表达式形式呈现的匹配地址,表示匹配形如 22:30-7:00 的字段,p 就是单独使用的 sed 脚本指令,表示打印。

解释:在这里脚本语句 ’1,/ZzzZzz/p' 的作用是打印,从第一行,到匹配正则表达式 ZzzZzz 的那行,中间的所有内容。1,/ZzzZzz/ 就是以行号和正则表达式相结合的混合地址形式呈现的匹配地址,1 表示第一行,/ZzzZzz/ 表示匹配形如 ZzzZzz 的字段。 p 就是单独使用的 sed 脚本指令,表示打印。这里第一行是空行,第二行有 ZzzZzz 所以最后就输出了第一第二行。
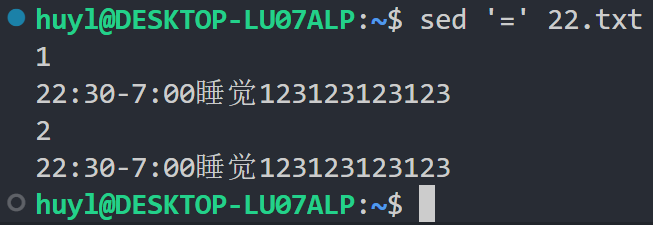
解释:在这里脚本语句 '=' 的作用就是打印所有行并输出行号。这里在脚本语句的左边没有看到任何行号或者正则表达式,所以就是省略的匹配行号,匹配的是输入的所有行。= 就是单独使用的脚本指令,表示打印并输出行号。

解释:在这里脚本语句 '1,3s/[123]+$/(:3[___]=/' 的作用就是将1到3行中以多个123结尾的内容替换成 (:3[___]=/ 。这里 1,3 就是以行号形式呈现的匹配地址,表示1到3行,s/[123]+$/(:3[___]=/ 就是结合正则表达式使用的脚本指令,表示匹配以多个123结尾的内容并替换成 (:3[___]=/ 。
多条脚本语句:
以上将的都是单条脚本语句的结构,也就是一条脚本语句一条脚本语句的执行, 在 sed 中也可以用 ; 分割的方法:在一个 ' ' 内通过 ; 符号可以写多条脚本语句,这些脚本语句会在一次内部循环中依次执行 。
举个例子:
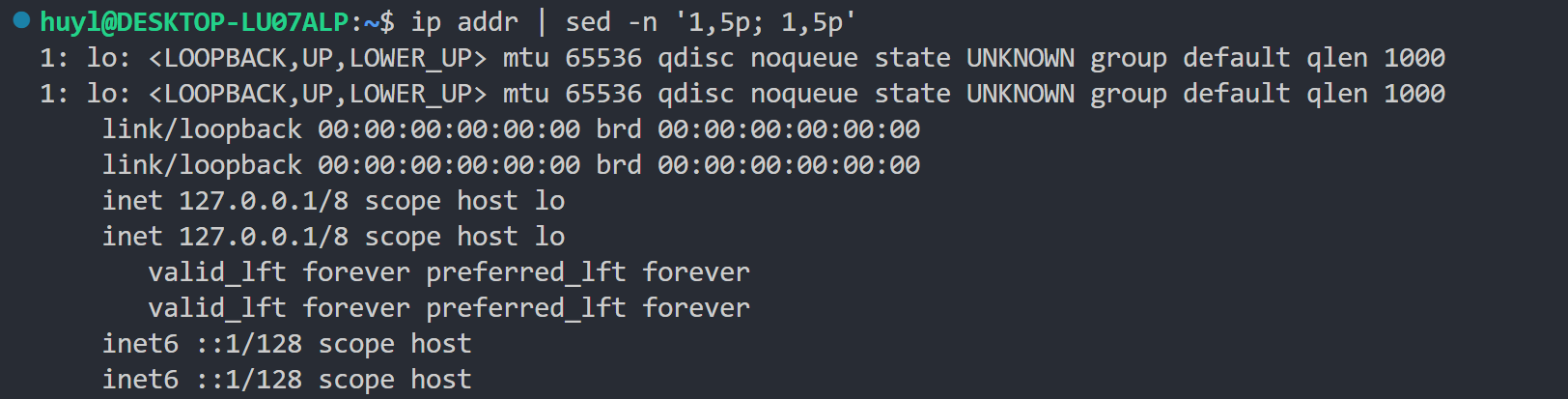
解释:在这里脚本语句 '1,5p; 1,5p' 是一个多条脚本语句,包含了两条脚本语句并用 ; 进行了分割。这两条脚本语句都是 1,5p 表示打印第1行到第5行。从执行的结果来看,每行打印了两次,而不是1-5行连续打印两遍。这就是 sed 的内部循环机制造成的,第一次循环的时候处理第一行,执行完 ; 前面的脚本语句,打印了第一行一次,然后又执行了 ; 后面的脚本语句,又打印了第一行一次,总共打印两次,然后再进入下一个内部循环处理第二行,以此类推直到处理完5行。
带大括号的多条脚本语句:
在 sed 脚本语句中,为了让同一个匹配地址执行多条脚本语句,有时候会出现带大括号的多条脚本语句,比如:
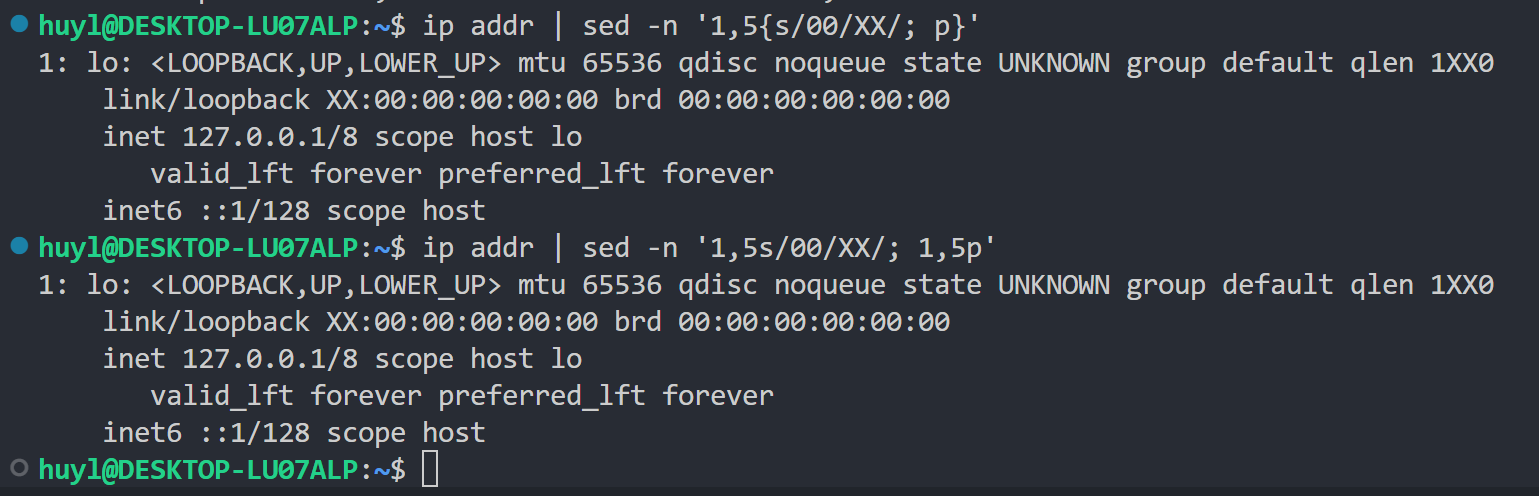
解释:在这里出现了带大括号的多条脚本语句 '1,5{s/00/XX/; p}',这条脚本语句会对1-5内容同时执行 s/00/XX/ 和 p 这两条脚本语句。由于这两条语句都是在内部循环中执行的,所以本质上上面这条命令和下面那条命令没有区别(唯一的区别就是可以让你少打几个字符)。
♻️ 5.1.2 sed 脚本逻辑
sed 脚本没有 if 之类的分支语法,也没有 while 之类的循环语法,但是sed 脚本指令中有一组特殊的指令叫做标签跳转指令, 这组指令可以使 sed 在多条脚本中进行跳转,利用这组特殊的指令可以模拟类似 if 分支,和 while 循环的逻辑。这种玩法在一些复杂的 sed 脚本会见到(敢这么玩的都是高手)。
标签和跳转模拟分支逻辑
举个例子:
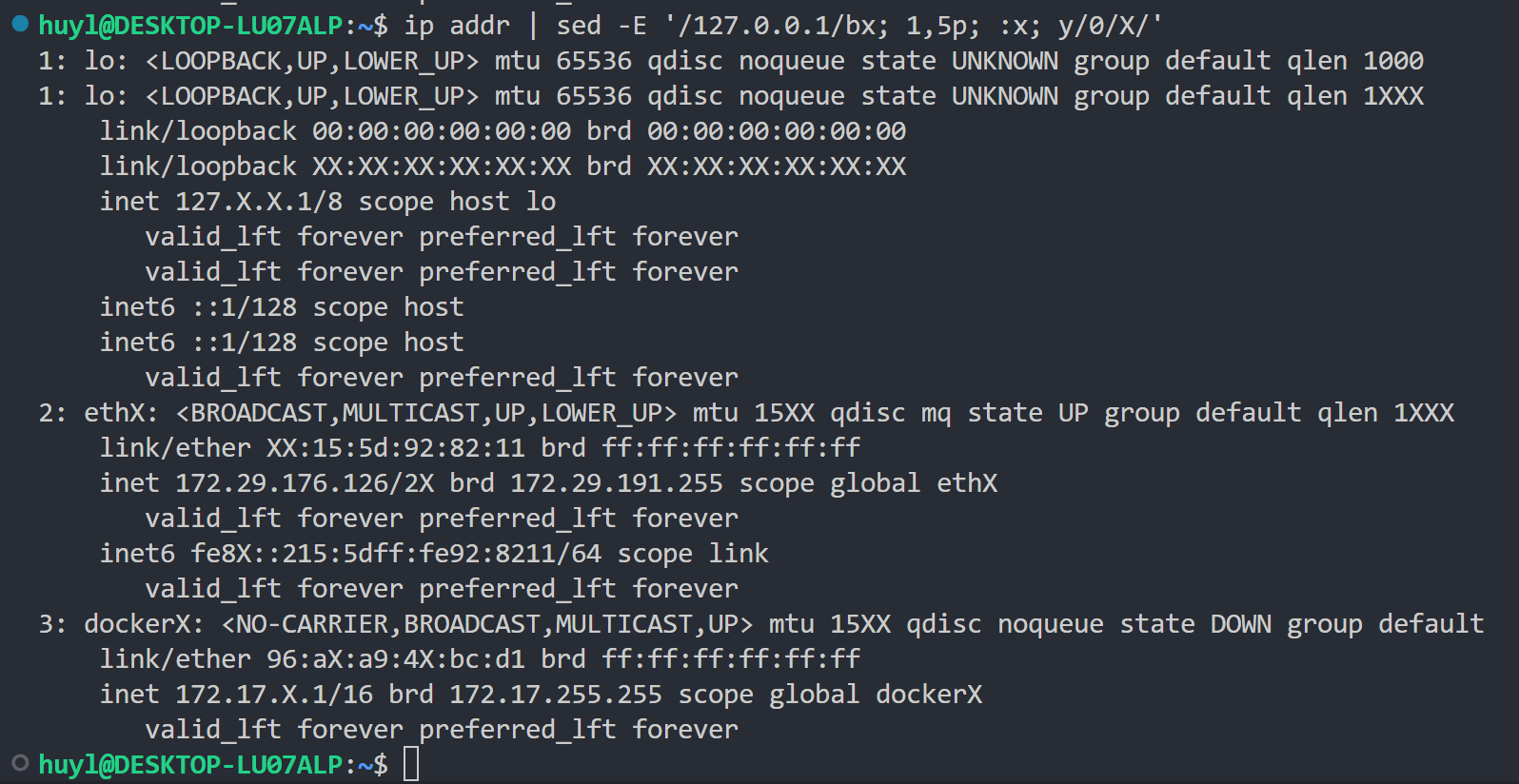
解释:这里的脚本语句 '/127.0.0.1/bx; 1,5p; :x; y/0/X' 是一个多条脚本语句,包含了4个脚本语句并用 ; 进行了分割。这里的逻辑是每次内部循环中先执行 /127.0.0.1/bx 这条语句匹配有没有127.0.0.1这个字段,如果匹配到了,忽略 1,5p 这条脚本语句,直接跳转到 :x 这条脚本语句,然后执行 y/0/X/ 这条语句把改行所有的 0 替换成 X,最后打印改行内容并清空模式空间;如果这次内部循环中 /127.0.0.1/bx 这条语句没有匹配到 127.0.0.1 这个字段,则执行 1,5p 这条脚本语句,判断这行是不是第1-5行,如果是就打印改行,不是就不打印,然后再执行 :x,这条语句就是个标签除了跳转不做任何操作,然后再执行 y/0/X 把该行所有的 0 替换成 X。所以我们看到的结果,第一次循环中第一行不包含 127.0.0.1 不跳转,先打印该行内容,然后再把 0 换成 X,第一次循环结束时 sed 再自动打印一次模式空间的内容(就是被替换后的改行),最后的结果就是第一行被替换前和被替换后各打印了一次。第二次循环同理。在第三次循环的时候匹配到 127.0.0.1 这个字段了,跳过 1,5p 这条脚本语句,直接执行 y/0/X 把该行所有的 0 替换成 X,然后再循环结束的时候sed 会自动打印一次模式空间的内容,最后的结果就是第三行只打印了一次被替换后的结果。第四行和第一行同理。第五行和第一行同理。再后面的循环超出1-5行无论有没匹配到 127.0.0.1,都只执行 y/0/X 替换命令了。这个就是利用标签和跳转模拟的分支逻辑。
标签与跳转实现模拟循环逻辑
举个例子:

解释:这里的脚本语句 ‘:x; N; /127.0.0.1/q; bx' 是一个多条脚本语句,包含了4个脚本语句并用 ; 进行了分割。这里的逻辑比较特殊,只进行了一次内部循环。首先第一次内部循环开始碰到 :x 这条脚本语句,什么都不做继续执行下一条脚本语句。 N 这条脚本语句只有一个指令, N 指令的作用是把下一行的内容提前放到这次循环的模式空间中,简单的说就是执行完 N 这条脚本语句后,模式空间内(一般情况下只有一行)有了两行的内容。然后继续执行 /127.0.0.1/q 这条脚本语句,在当前模式空间内匹配有没有 127.0.0.1 这个字段,如果匹配到了就执行 q 指令退出 sed 程序并打印模式空间的内容。但在此时模式空间内只有 ip addr 命令输出的前两行,没有匹配到 127.0.0.1 ,所以不执行 q 指令继续执行 bx 这条脚本语句。bx 这条脚本语句直接跳转回了 :x 这条脚本语句,没有进入下一次内部循环。然后执行 :x 这条脚本语句后面的 N 脚本语句,把第三行放到了模式空间内。由于第三行出现了 127.0.0.1 这个字段,直接导致后面的 /127.0.0.1/q 这条脚本语句执行了 q 指令,退出了 sed 程序并打印了模式空间的所有内容,也就是 ip addr 输出的前三行。这就是利用标签和跳转模拟的循环逻辑。
注意:
在利用标签和跳转模拟分支逻辑时很容易出现以下报错
sed: can't find label for jump to `x'这个报错的原因似乎是在 :x 前的脚本语句存在错误导致 :x 没有正确的被分析(可能时语法错误也可能是前后指令之间的冲突)。同时在利用标签和跳转模拟循环循环逻辑的时候也很容易出现死循环,导致程序卡死无法继续运行。所以要成功的模拟这两种逻辑需要对 sed 脚本指令和运行原理有着深刻的理解。
🗒️ 5.2 sed 脚本指令
✂️ 5.2.1 文本操作指令
d: 删除当前模式空间内的所有内容,并直接开启下一轮内部循环。效果:
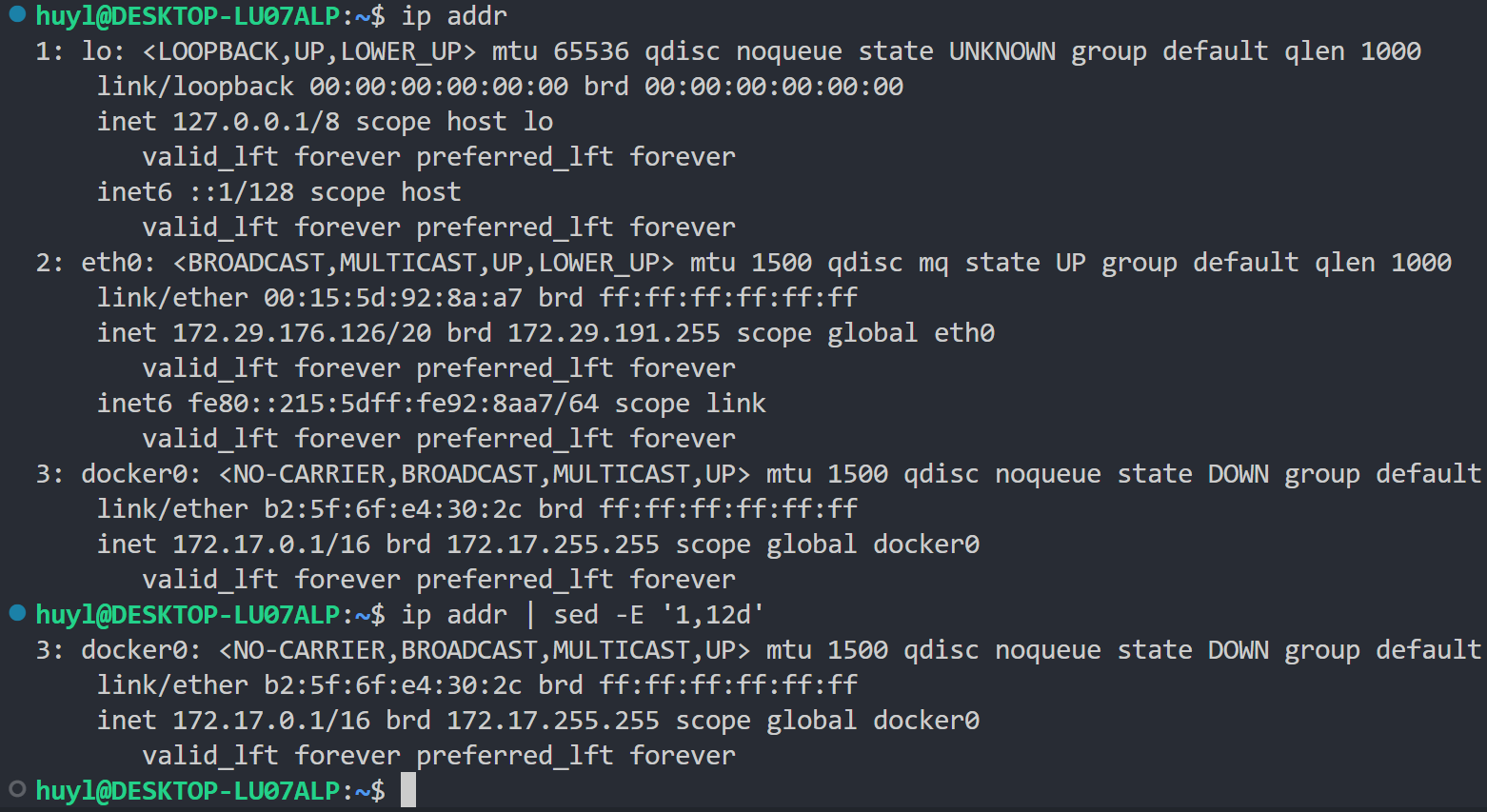
解释:这里通过 d 指令删除了 ip addr 输出中的第1到12行,所以最后打印的结果只有最后几行。实际上 d 命令在每次循环中都会判断当前行是不是第1-12行,是就删,然后进入下一次循环,不是就不删,继续走循环。如果删了模式空间里面就没有内容,sed 自动打印模式空间也就打不出东西。表面上看是删除了输出的第1到12行,但实际上确实和 sed 官方手册所说一样,是删除了当前模式空间的所有内容。
y/source-chars/dest-chars/: 这个指令可以对当前模式空间中的所有在 source-chars 中出现过的字符,逐个替换成 dest-chars 中的相应字符,效果:
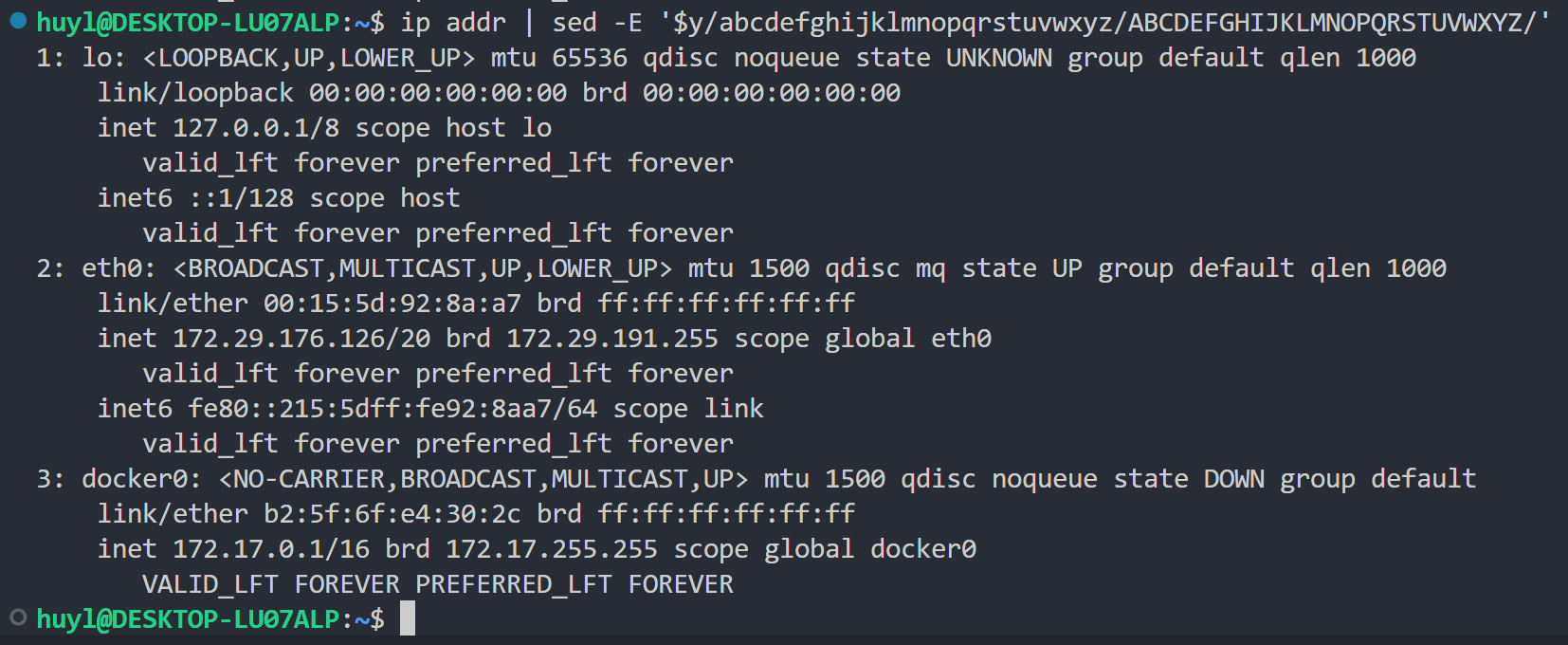
解释:这里通过 y/source-chars/dest-chars/ 指令将 ip addr 输出的最后一行从小写变成了大写。准确的来讲是将最后一行中出现的 abcdefghijklmnopqrstuvwxyz 字符逐个替换成了 ABCDEFGHIJKLMNOPQRSTUVWXYZ 。这里的 source-chars 是 abcdefghijklmnopqrstuvwxyz ,dest-chars 是 ABCDEFGHIJKLMNOPQRSTUVWXYZ 。这里的 $ 表示匹配最后一行的地址。
s/pattern/repl/[flag]: 这个指令有三个参数,pattern,repl,[flag],其中第三个参数是可选的。第一个参数一般是正则表达式,第二个参数是替换项,第三个参数是控制替换行为的标志位。这个指令的作用就是在模式空间中,把 pattern 正则表达式匹配到的内容,替换成替换项,替换行为根据 [flag] 标志位而变化。效果:
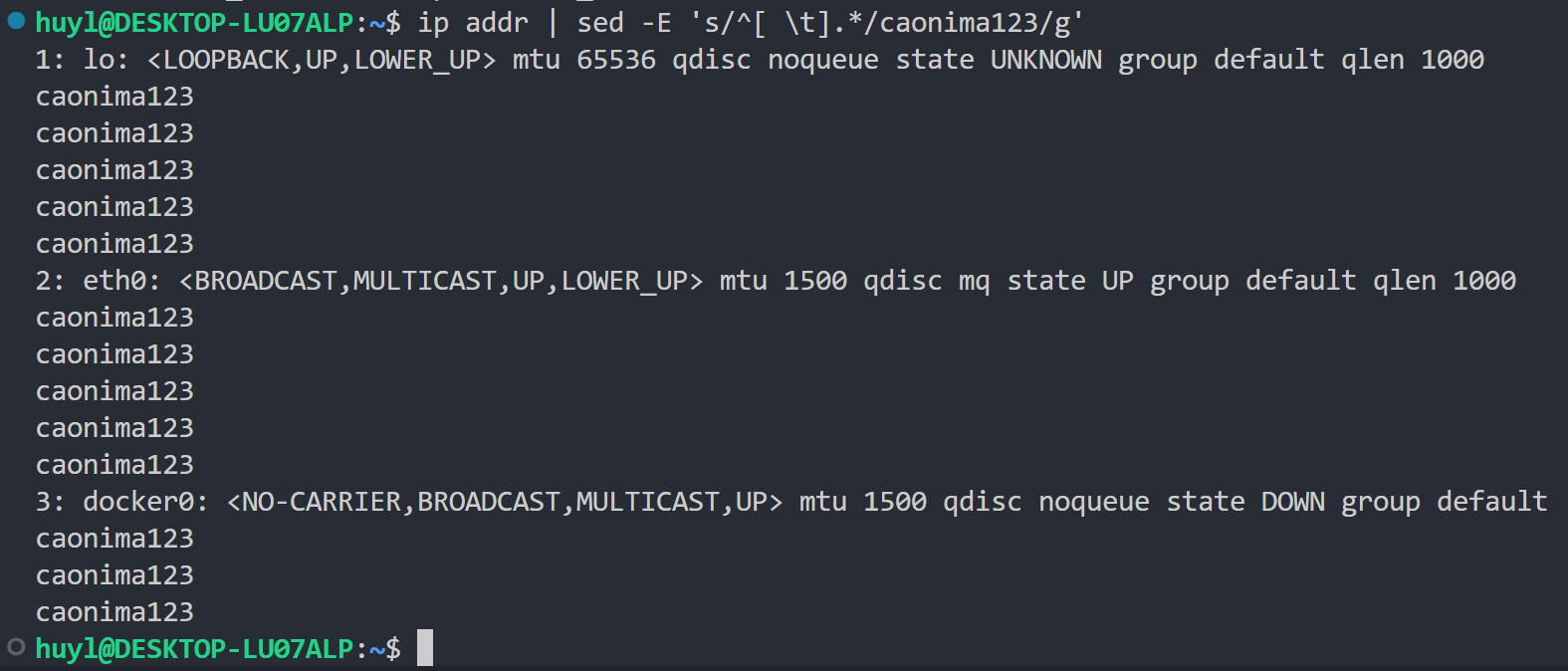
解释:这条命令中, s/pattern/repl/[flag] 指令的参数 pattern 为 ^[ \t].*, 表示匹配开头为空格或 TAB 键的行,参数 repl 为 caonima123 表示替换的内容,[flag] 为 g 表示全局替换。所以在输出的结果中所有开头为空格或TAB的行都被替换成了 caonima123。
[flag] 标志位可以为:
- g: 表示全局替换。替换模式空间中 每个匹配的子串,而不仅仅是第一个匹配(但如果s/pattern/repl/[flag] 指令前面有匹配地址,依然收到匹配地址的范围限制)。
- p: 表示替换成功后打印模式空间。通常配合
-n使用,避免重复打印。- 数字: 表示只替换第 N 次匹配。例如
s/foo/bar/2→ 替换每行的第二个匹配。- i: 表示匹配时忽略大小写。
- w filename: 表示替换成功时,把替换后的模式空间写入指定文件。
- e: 表示将替换结果作为 shell 命令执行。
- m: 启用“多行模式”,让
^和$匹配模式空间中每一行的开头和结尾,而不仅仅是整个模式空间的开头和结尾。- 省略:表示匹配时和替换后均不做任何额外操作。
这些标志位可以单独使用也可以组合使用。由于内容过多这里不一一展示效果。
a text: 这个指令简单来说就是在匹配地址的位置后面追加一行 text。准确来说就是可以在当前的模式空间后面追加一行,并写入text,让其在循环结束的时候和模式空间里的其他内容一起打印。效果:
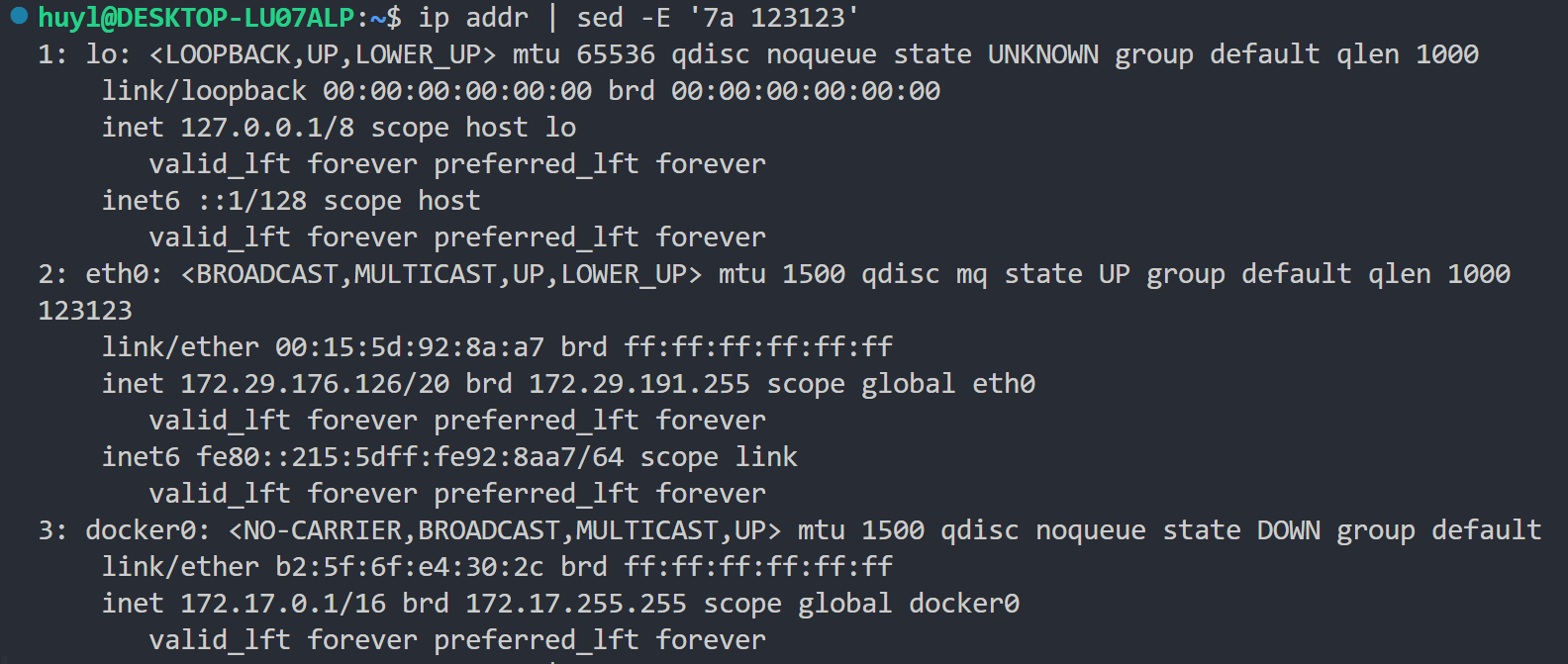
解释:这条 sed 命令中,a text 的参数 text 为123123,匹配地址是7所以是在第7行后面添加了一行123123。
i text: 这个指令和 a text 指令类似,只不过他是在匹配地址的位置前面添加一行。效果:
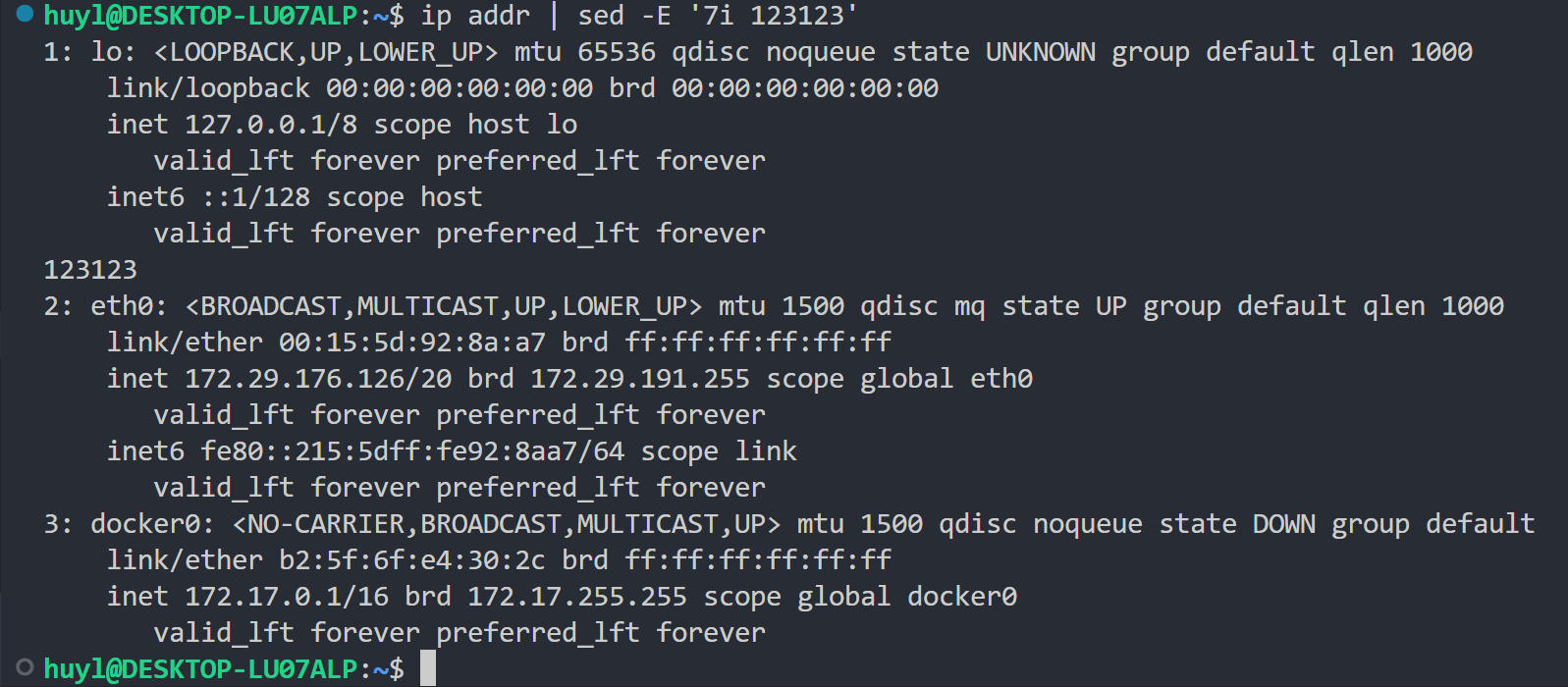
解释:上图就是最好的解释
c text: 这个指令会把匹配地址表示的那行直接替换成内容为 text 的新行。效果:
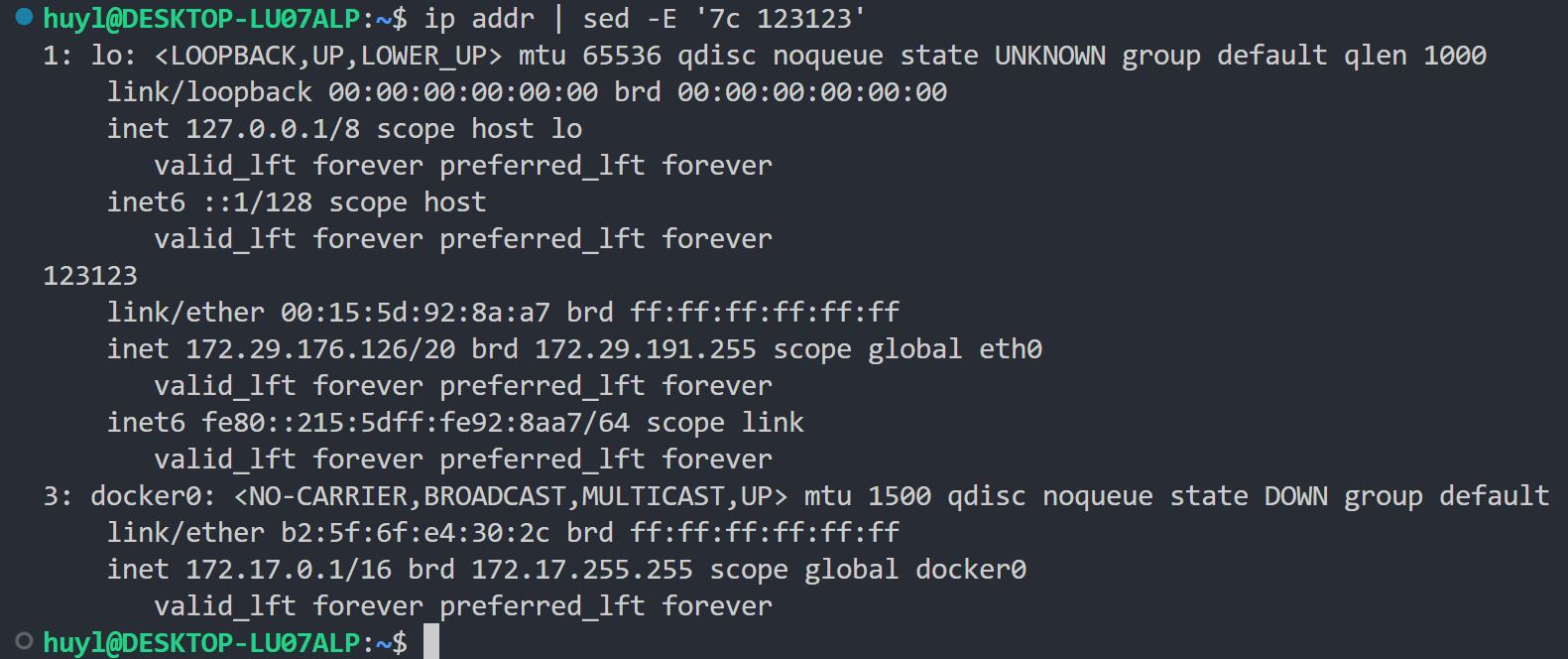
解释:上图就是最好的解释
🌊 5.2.2 输出控制指令
p: 输出当前模式空间内的所有内容,通常配合 -n 命令行参数一起,用于选择性的输出内容。效果:

解释:这里通过 p 指令打印了包含 loopbackp 这个词的行,p 指令是最常用的输出控制指令,必须掌握。
=: 这个指令简单的来说就是在每行前面输出行号,但是输出的方式不像 cat -n 那样好看,他是直接另起一行输出行号的。准确的来说就是在每次循环结束前,在模式空间前面添加一个新行用于显示行号,效果:
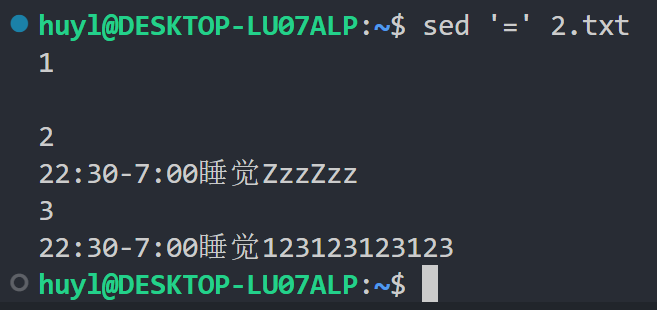
解释:这里没有写匹配地址所以匹配的是所有行, = 指令给 2.txt 的所有行都添加了行号,即使是空行。虽然不怎么美观,但是用来找匹配的东西在第几行,还是很清楚的。然后就可以把行号写道 sed 脚本中进行下一步操作了。
l: 这个指令作用是将模式空间的内容打印出来,但是会一起打印输出不可见字符,主要用于配合 -l length 命令行参数用于在输出中显示不可见字符。效果:
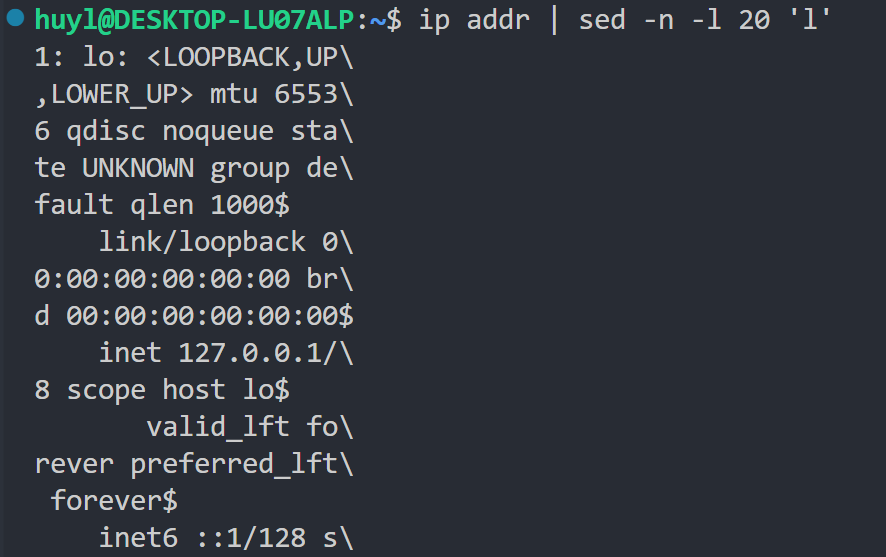
解释:这里通过 -n 、-l 和 l 指令的配合,以20个字符的长度分行显示 ip addr 的内容,并且将不可见的字符(比如表示行尾的$)也一起打印出来。
n: 这个指令做了3件事,输出模式空间内的所有内容,清空模式空间内的所有内容,然后把下一行行放入模式空间。 如果下一行没有内容了,就直接退出 sed 程序,不再处理任何指令和输入。简单的说就是在不进入下一个循环的情况下读取下一行内容。常用于配合 p 指令来选择性的输出内容。效果:
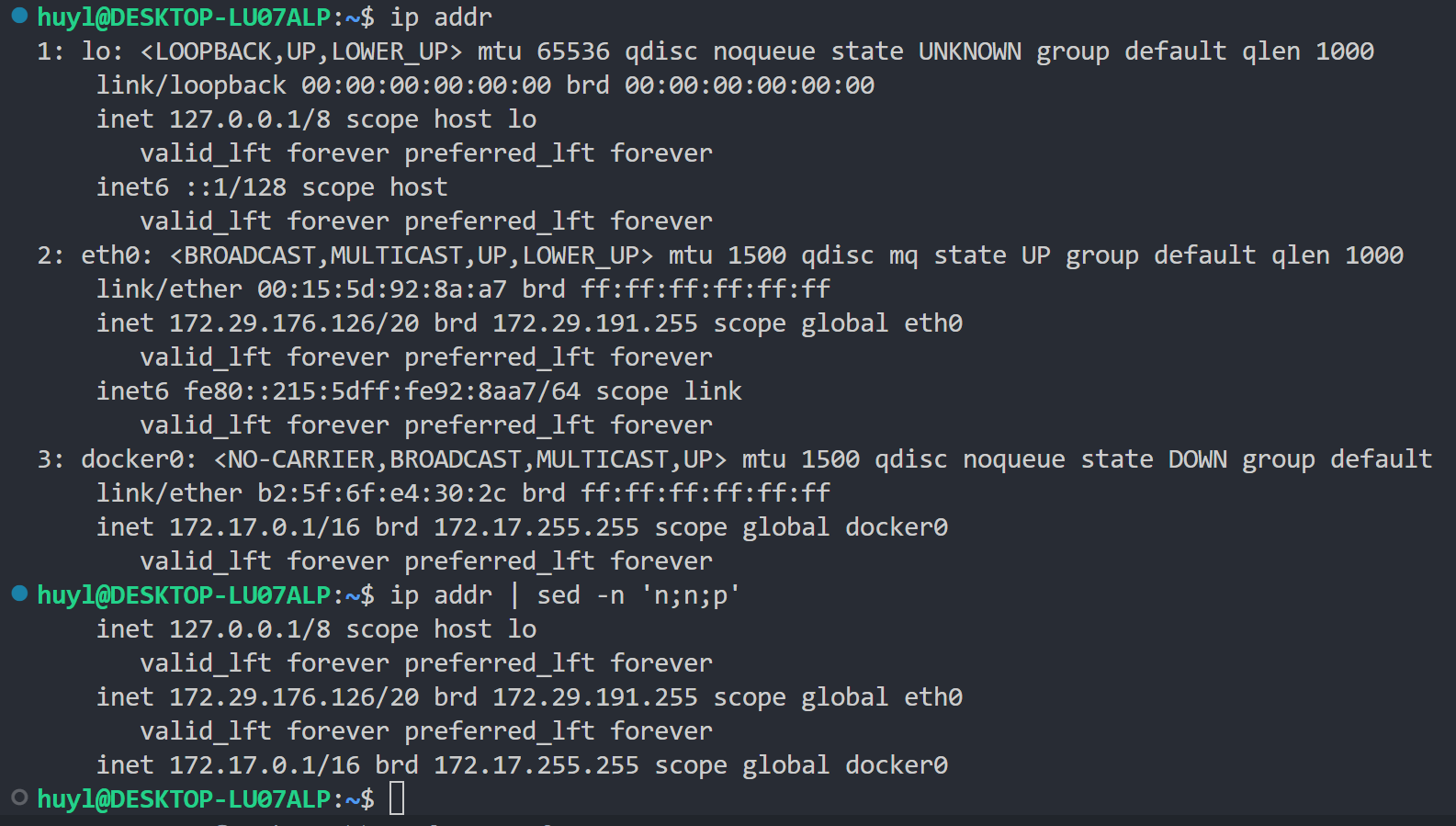
解释:这里我特意把 ip addr 的内容显示出来,能够更清楚的看到效果。在这里 'n;n;p' 是一个多条脚本语句,表示每隔3行输出一行。准确的来说在刚开始进行第一行的内部循环时,第一个 n 输出模式空间的第一含内容,清空模式空间并把第二行内容放入模式空间,但是由于 -n 命令行参数的作用,只有 p 指令才能正常输出,其他输出会被忽略。所以第一行看不到的。第二个 n 输出模式空间的第二行内容,清空模式空间并把第三行内容放进模式空间,但是由于 -n 的作用,所以第二行也是看不到的。然后 p 指令把模式空间的第三行内容输出到终端上,所以只能看到第三行内容。然后再进入下一次循环,以此类推就是每隔3行输出一行内容了。这里需要区分这里的 n 指令和 -n 命令行参数,这两者是两个不同的概念。
🗃️ 5.2.3 空间操作指令
N: 这个指令是 n 指令的变体,这个指令会把下一行的内容提前放到这次循环的模式空间中,不清空模式空间也不进入下一次循环,使模式空间中形成多行文本。是多行模式空间操作的核心指令。效果:
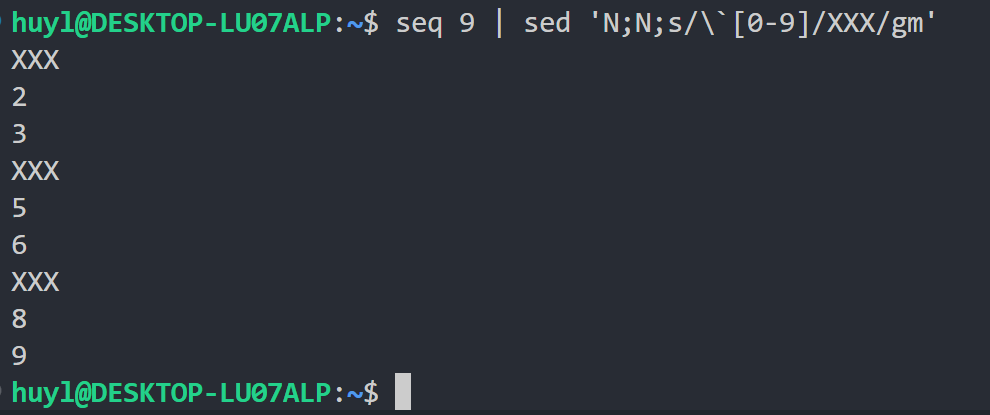
解释:这里执行的是一个多条脚本语句,从效果上来看,是用 seq 生成的序列作为输入,sed 将每3行的第一行替换成了XXX,然后输出。现在来进一步分析在这个多条脚本语句中 N 指令的作用。第一次循环开始,模式空间内只有第一行内容,这时碰到第一个N 指令,N 指令将第二行的内容提前放到了模式空间中,不打印不重开循环,这时模式空间内有两行内容了,再碰到第二个N 指令, N 指令将第三行的内容提前放到了模式空间中,,不打印不重开循环,这时模式空间内有三行内容了。然后碰到 s/\`[0-9]/XXX/gm 指令,这里 \`[0-9] 这个正则表达式表示匹配整个文本的开头接着数字的位置,\`匹配的不是每行行首而是整个文本的开头,所以当前模式空间内的三行只有第一行的开头被匹配到。XXX表示把匹配到的内容替换成XXX,gm表示全局替换,并开启多行模式,能够识别拥有多行的模式空间。所以 s/\`[0-9]/XXX/gm 指令执行过后在3行模式空间中只有第一行被替换成了XXX,然后进入下一次循环,一次类推就形成了每3行替换一次的效果。
P: 这个指令是 p 指令的变体,这个指令只打印模式空间的第一行内容,通常用于配合 N 参数处理多行模式空间。和 p 指令一样,也是通常和 -n 命令行参数一起使用。效果:
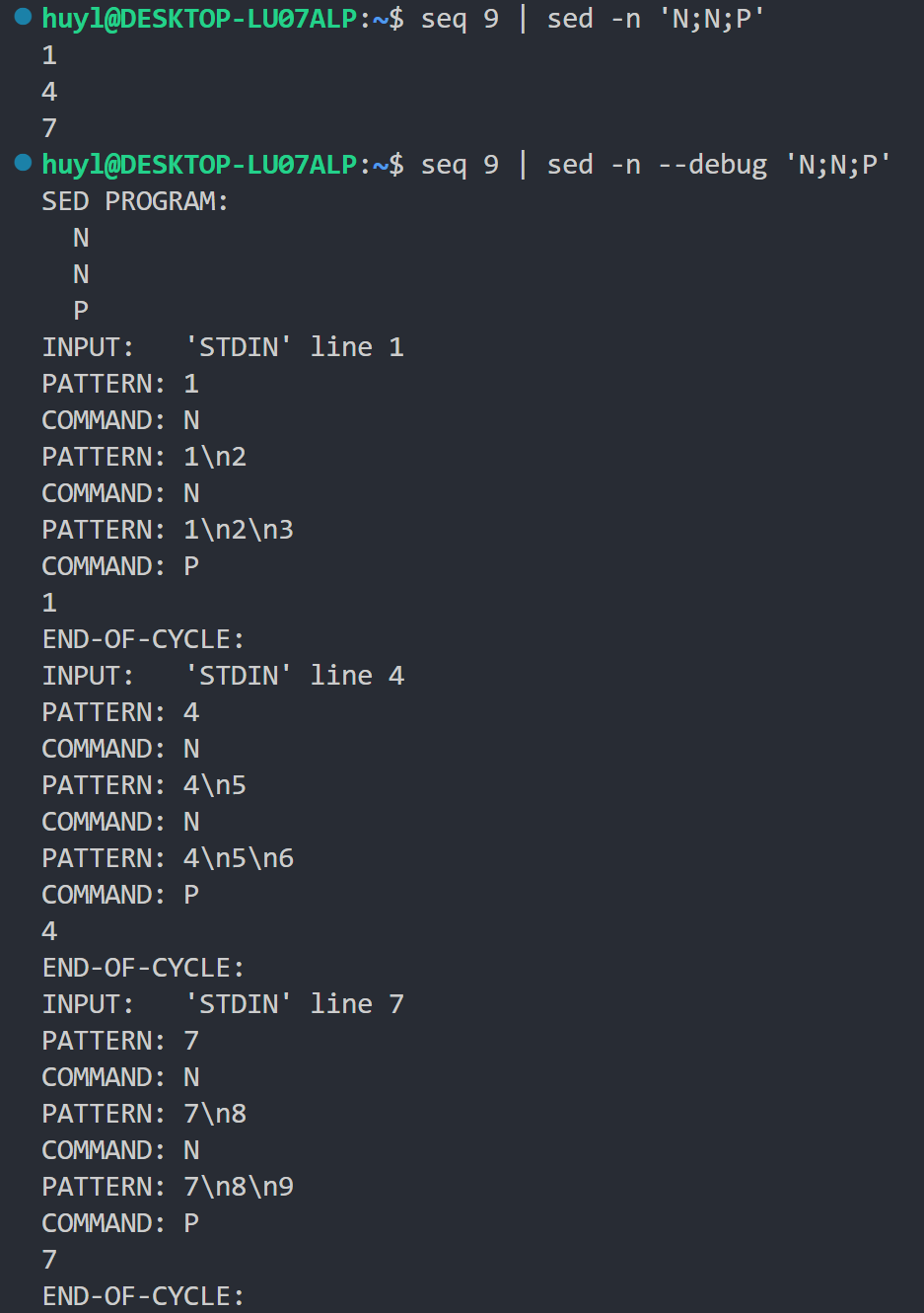
解释:和上面哪个例子的逻辑一样,每次循环中模式空间内有三行内容,但是每次只打印这三行中的第一行。这里同时贴出了 --debug 的版本,可以更清楚的看到 sed 内部循环的流程(知道我为什么把 --debug 命令行参数标红了吧)。
D: 这个指令是 d 指令的变体,这个指令做了2件事,删除模式空间的第一行,然后开启下一个循环,通常用于配合 N 参数处理多行模式空间,来实现经典的滚动窗口模式。效果:
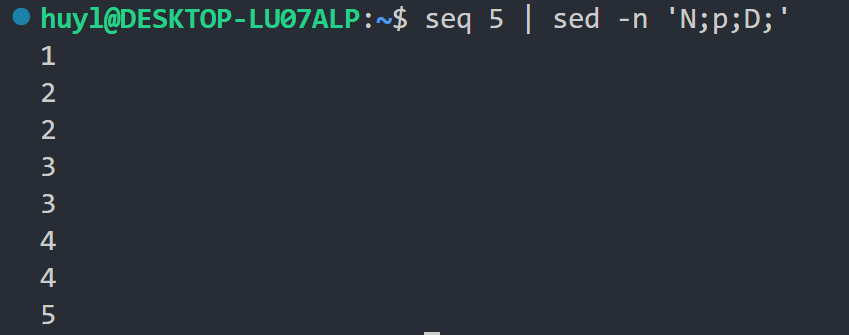
解释:这里分别打印了12,23,34,45,等于把 sed 5 的输出按照两个字符的长度滚动了一遍。在第一次循环的时候,模式空间只有1,N 指令执行完后模式空间有12了,p 指令将12打印了出来,然后 D 指令再删除了1,开启第二次循环。这时模式空间中只有2了,N指令执行完后模式空间有23了,p 指令将23打印了出来,然后D指令再删除了2,开启第三次循环,依次类推,直到打印出45
h: 这个指令的作用是复制模式空间的内容到保持空间,通常配合 g 指令、x 指令来实现保持空间剪切板的作用。效果:
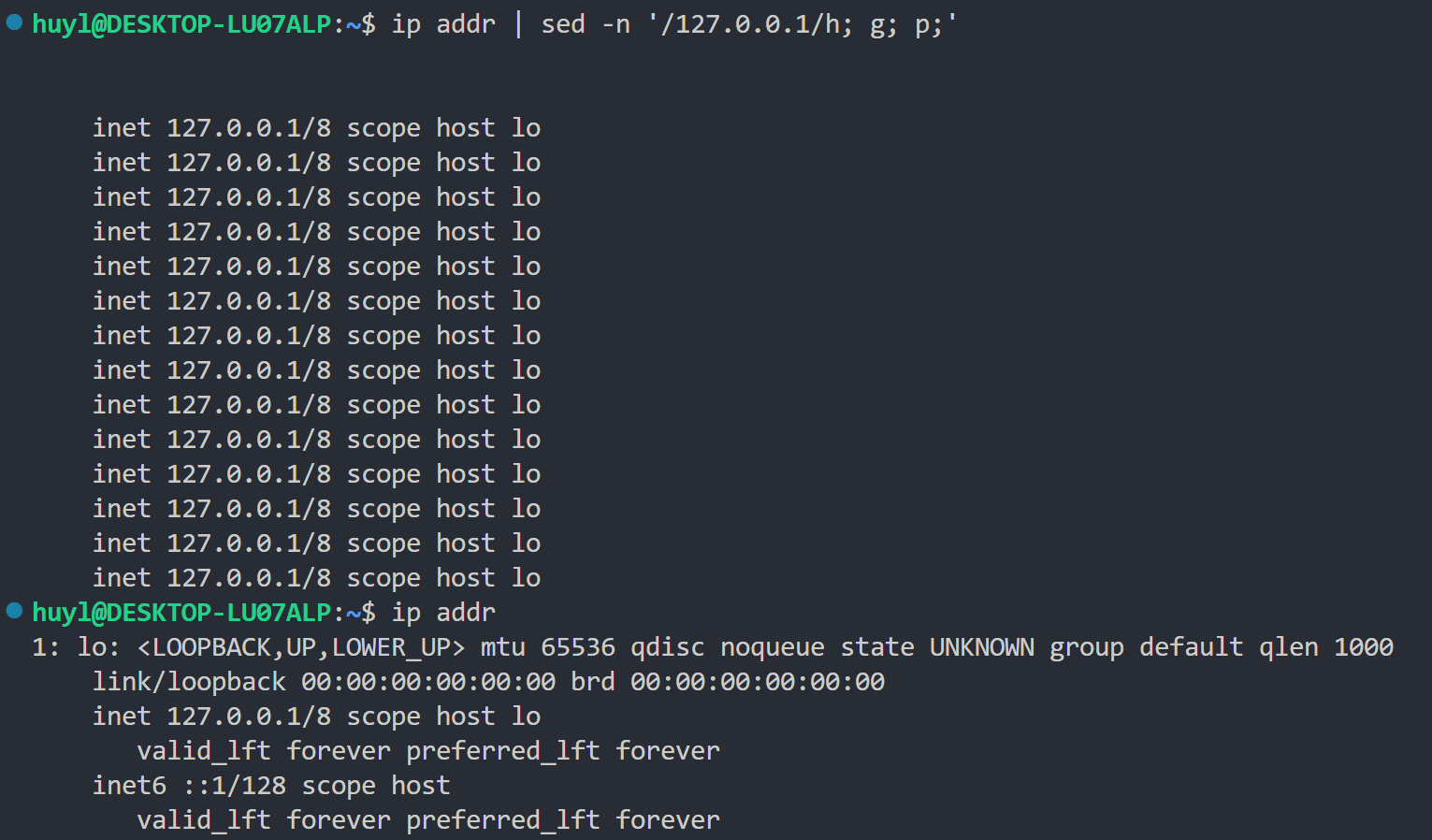
解释:这里用到了多条脚本语句 '/127.0.0.1/h; g; p;' 。虽然输出有点奇怪但是依然可以作为例子类分析 h 指令的作用。首先第一次循环的时候先执行 /127.0.0.1/h 这条脚本指令,匹配 127.0.0.1 这段字符,如果匹配到了就将这行复制到保持空间,但是 ip addr 的第一行没有 127.0.0.1 字段,所i不复制,保持空间依然是空的,然后执行 g 指令,g 指令的作用是将保持空间内容覆盖到模式空间,因为保持空间内容为空所以覆盖后模式空间内容也为空。最后执行 p 指令,打印模式空间的所有内容,模式空间为空所以打印了个寂寞。然后是第二次循环,依然没有再第二行发现 127.0.0.1 所以继续打印寂寞。然后是第三行,因为第三行出现了127.0.0.1 字段所以 h 指令将第三行复制到了保持空间,然后执行 g 指令,g 指令将保持空间内的第三行覆盖到模式空间,等于没覆盖,模式空间还是第三行,最后 p 指令打印了模式空间内的第三行。所以第三行是有内容的。然后是第四次循环,因为第四行没有匹配到 127.0.0.1 字段,所以 h 指令不进行操作,但是保持空间内依然残留着上次循环的第三行内容,执行 g 指令的时候,g 指令将保持空间内的第三行内容覆盖了模式空间的第四行内容,然后 p 指令打印了模式空间被覆盖后的第三行内容。所以第四行也是有内容的,但是是第三行的内容,以此类推,由于后面行都没有 127.0.0.1 字段,所以都变成了第三行。这个就是保持空间的剪切板作用,这个例子就像你剪切板没清空一直再 Ctrl+v 一样。不过对于一般人来说要理解模式空间就已经很困难了,会玩保持空间的也都是高手。
g: 这个指令会将保持空间的内容覆盖到模式空间,效果参见前面的 h 指令效果。
H: 这个指令会将模式空间的内容追加到保持空间,效果:
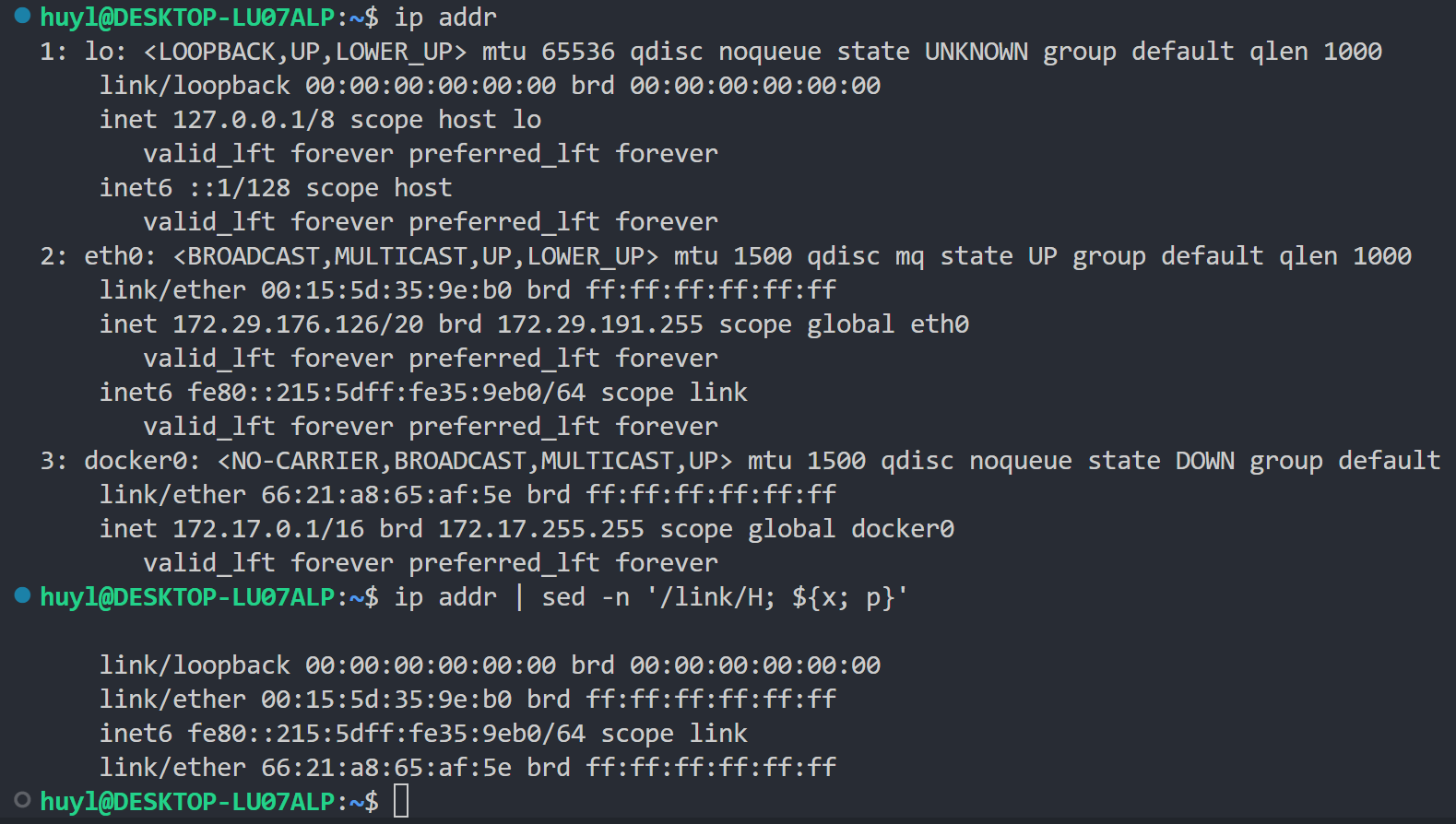
解释:这里用到了多条脚本语句 '/link/H; ${x; p}' ,第一条语句表示用 H 指令对匹配到的含有 link 字符的行放到保持空间,第二条语句 ${x; p} 等同于 $x; $p,表示在匹配到最后一行的时候先通过 x 指令交换保持空间和模式空间的内容,此时模式空间是最后一行,而保持空间里的内容是所有匹配到 link 字符的行,然后在交换完成后再通过 p 指令打印模式空间里的内容,即打印所有匹配到 link 字符的行,这样就出现了上图所显示的类似 grep 的效果。需要注意的是这里结果中多出了一个空行,这时因为 H 指令的追加特性。H 指令追加内容之前会默认加一个 \n 换行符,比如追加 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 这条语句的时候,H 指令会把它自动改成 \n link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ,从而使他不会和保持空间内原来的内容挤在同一行。但在这里保持空间内原来没有内容,所以 H 指令添加的 \n 就i自成一行,导致结果多出一个空行。要避免这种现象可以第一次使用 h 指令或 x 指令之后再使用 H 指令。(当然如果你不在乎这点瑕疵大可不必再加一个 h 指令或 x 指令的逻辑分支)
G: 这个指令会将保持空间的内容追加到模式空间,效果:
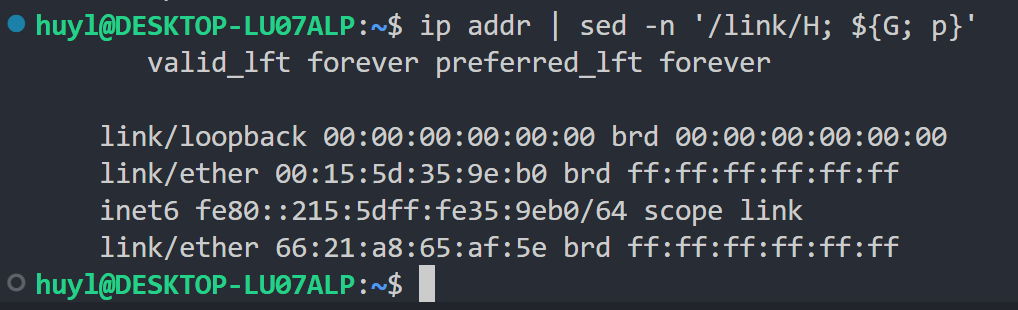
解释:这里我用了和上面 H 指令展示效果时几乎相同的 sed 命令,但是把脚本指令中的 x 指令换成了 G 指令。从结果上相比,比上面那个多出了 ip addr 的最后一行。因为 G 的效果是追加,而不是替换,所以最后一行还在。
x: 这个指令会交换模式空间与保持空间的内容。效果参见前面的 H 指令的效果。
z: 这个指令在执行的时候会清空模式空间的所有内容,但是和 d 指令不同的式,他不会进入下一次循环。可以让使用者在一次循环中更精密地操作模式空间。效果:
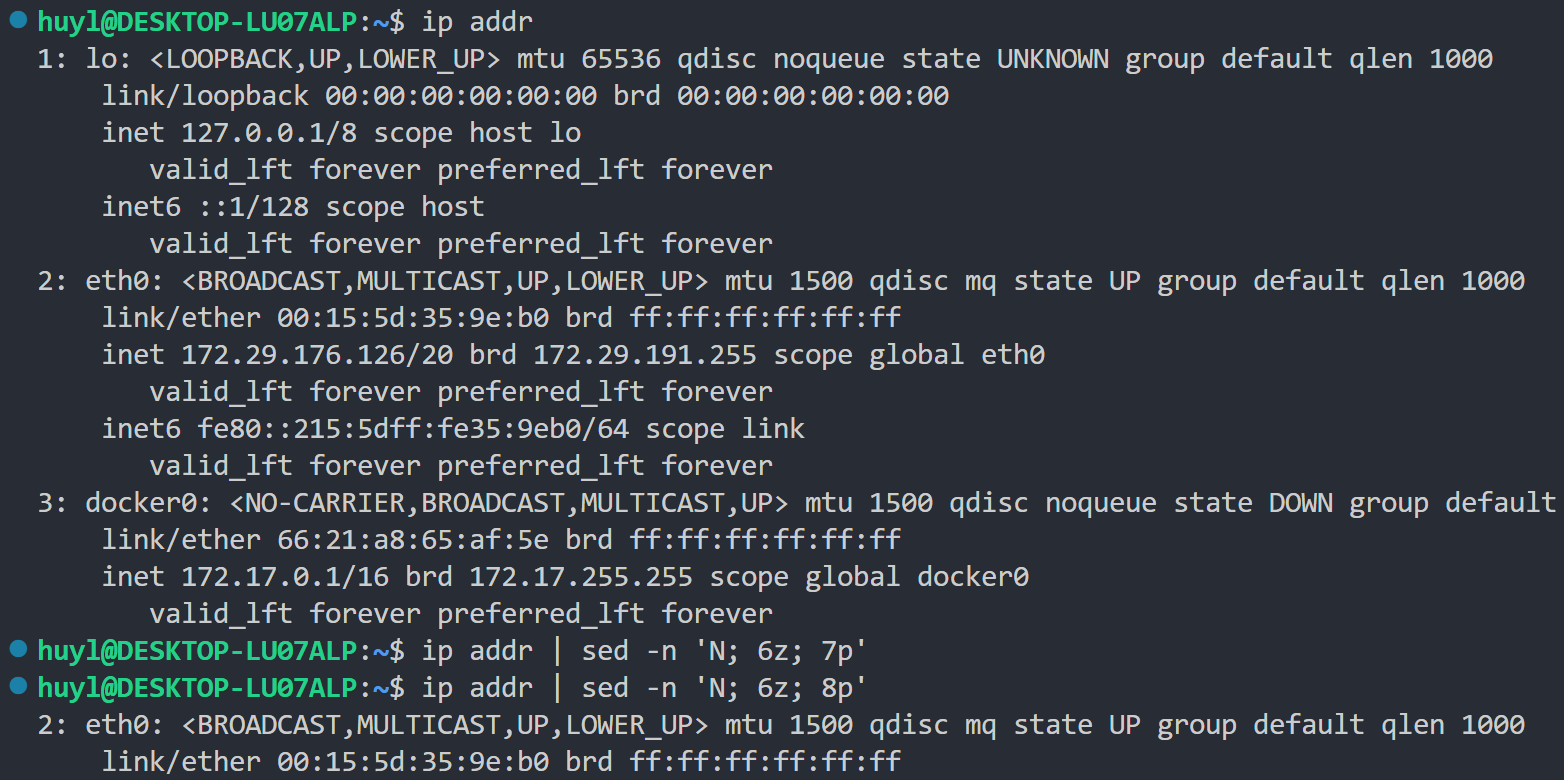
解释:这里执行了两次 sed 命令,用到了两个多条脚本语句 'N; 6z; 7p' 和 'N; 6z; 8p',可以看到。我们先看第二个 sed 命令也就是 'N; 6z; 8p' 这个多条脚本语句。这里 N 把下一行内容追加到模式空间,但在第三次循环(为什么是第三次而不是第六次,那是因为 N 一次性把两行装进了模式空间,所以在输入中读到第六行的时候实际只执行了3次循环)的时候触发了 z 指令,清空了模式空间的内容,然后再到第4次循环的时候 N 又放了两行到模式空间,所以 p 指令最后打印的只有两行数据。我们再来看第一个 sed 命令,照例来说结果应该是打印一行内容,但这里什么都没打印。这里有一个坑,在执行第四次循环的时候,读取的行号是7,模式空间内有第7行,但是多行脚本中的 N 又读取了一行放到模式空间,这时读取的行号从7变成了8,模式空间内有第7行和第8行,而到后面执行 7p 指令的时候由于行号是8所以没有匹配到,简单地说就是由于N的使用导致行号的变化范围是2,4,6,8……,其中奇数行号都被跳过无法匹配到了。所以7p不是打印了空,而是根本没有执行。相反,如果把7p 放到 N前面就能正常打印出第7行的内容了
ip addr | sed -n '7p; N; 6z;'这里逻辑比较乱,我讲的可能不是很清楚,建议手动试一下,或者直接跳过。
🔁 5.2.4 标签跳转指令
q: 打印模式空间的所有内容,然后退出 sed 程序,不再处理任何指令或输入。高手常用来作为循环脚本的退出点。效果:
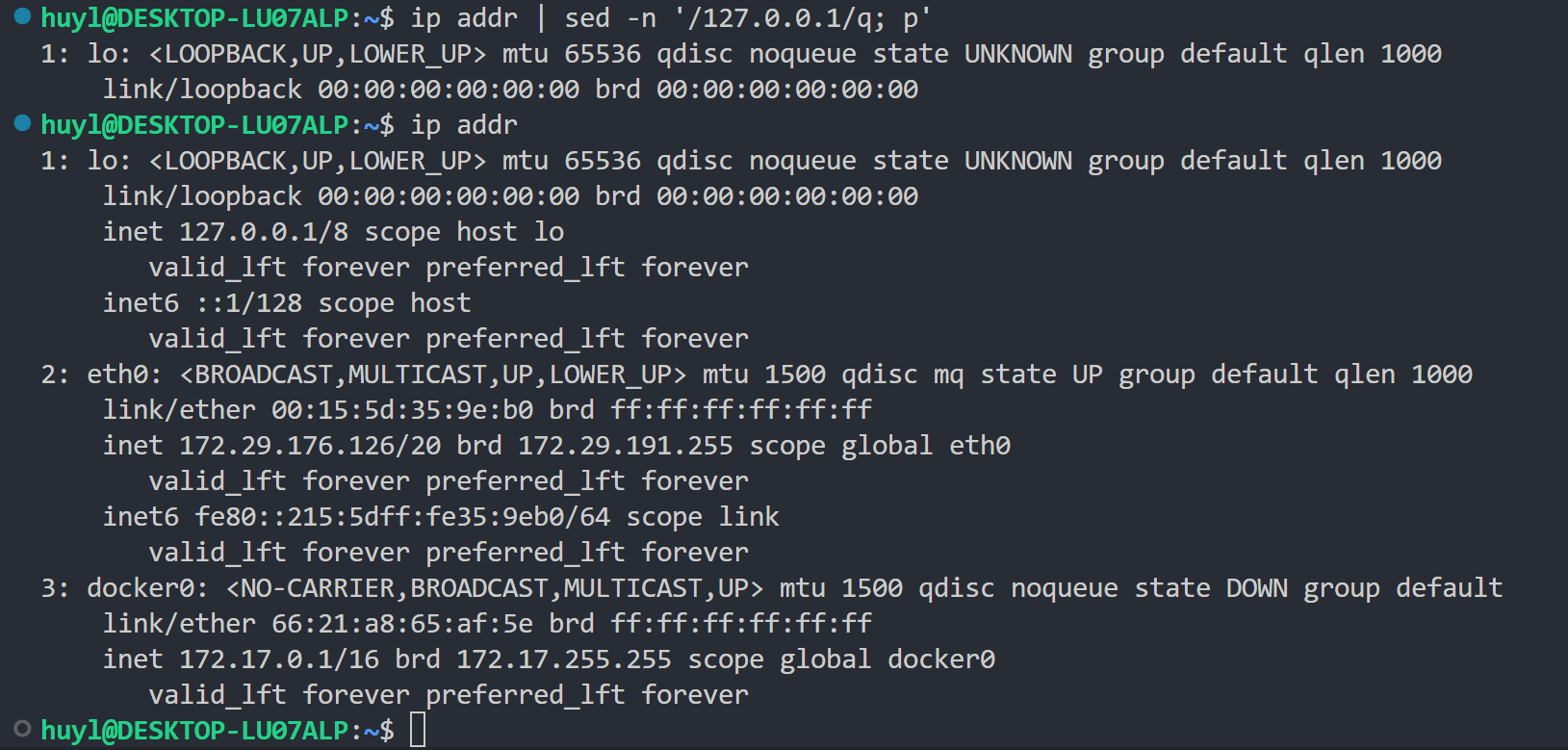
解释:这里用了多条脚本语句 ’/127.0.0.1/q; p' 表示匹配到 127.0.0.1 字段就退出 sed 程序,没匹配到就继续打印内容,从结果上可以看见,第一第二行都没匹配到都被打印出来了,第三行匹配到退出了 sed 程序,后面的内容也都全部没打印了。
Q: 这个指令是 q 指令的变体,退出 sed 脚本,不打印任何内容,不再处理任何指令或输入。效果:

解释:这里特意和 q 指令做了对比,这样可以更直观的感受”不打印任何内容“的意思。这里特意不用 -n 和 p 的组合,因为在 -n 和 p 的组合下打不打印东西不由 Q 和 q 说了算由 p 说了算,这种情况下 Q 和 q 的效果没有任何区别。
: label: 该指令用于定义标签,主要配合 b label 指令或 t label 指令使用效果详见 5.1.2 sed 脚本逻辑。
b label: 该指令用于无条件的跳转到标签,主要配合 : label 指令使用,效果详见 5.1.2 sed 脚本逻辑。
t label: 通常配合 s 指令使用,实现条件跳转(匹配替换成功后跳转),效果:
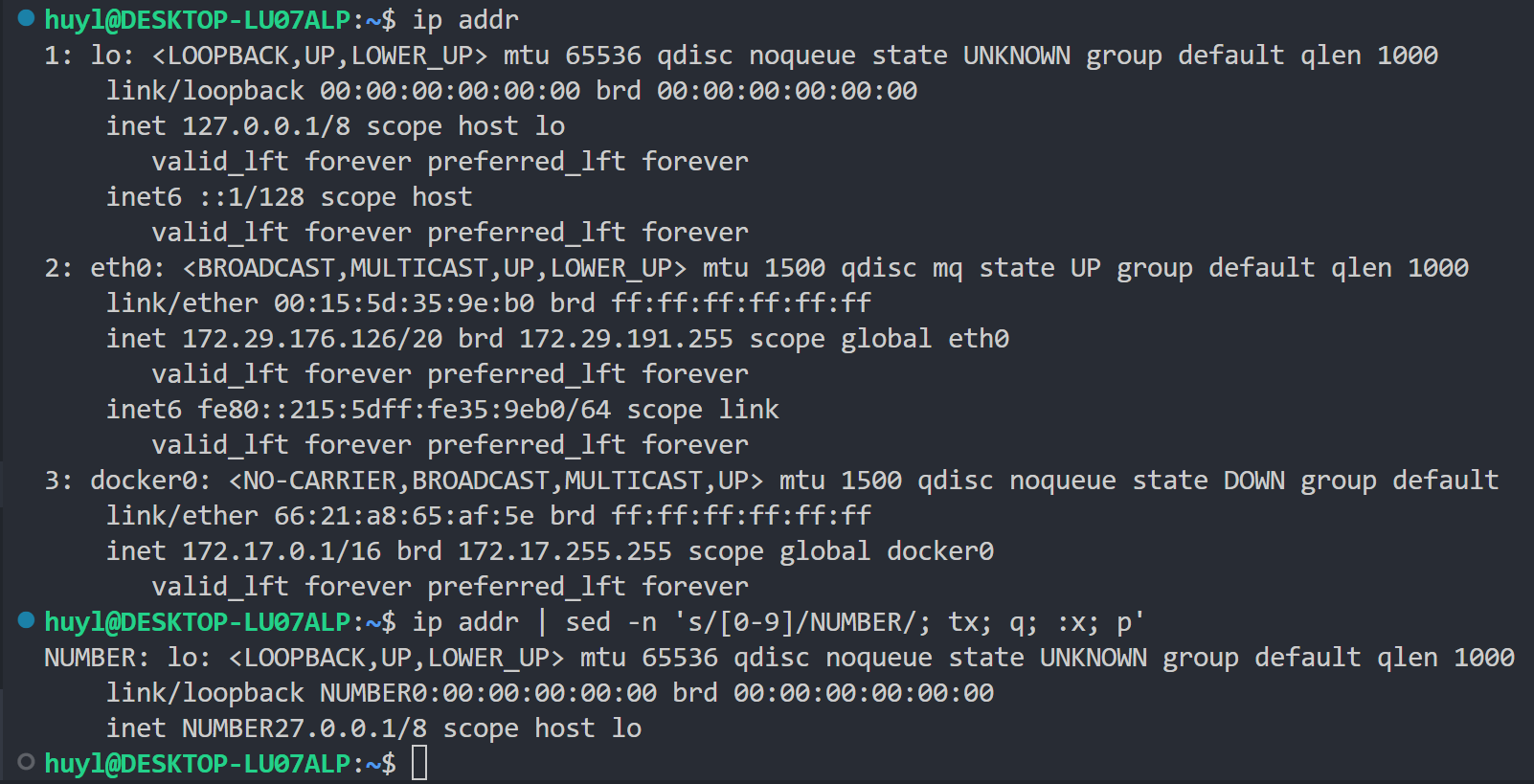
解释:这里用了多条脚本语句 's/[0-9]/NUMBER/; tx; q; :x;p',表示匹配带有数字的行并把第一个匹配到的数字替换成 NUMBER ,同时,如果匹配替换成功,执行 tx 指令跳转到 :x 去执行 p 指令,也就是打印替换后那行内容;如果没匹配到没有替换到,则不跳转继续执行 q 指令就是退出程序。从结果可以看到 ip addr 前三行都有数字,并且第一个数字都被成功匹配替换成了 NUMBER,并打印了出来,第四行没有数字没有被匹配到所以直接执行了 q 指令退出了程序。
T label: 通常配合 s 指令使用,实现条件跳转(匹配替换失败后跳转),效果:
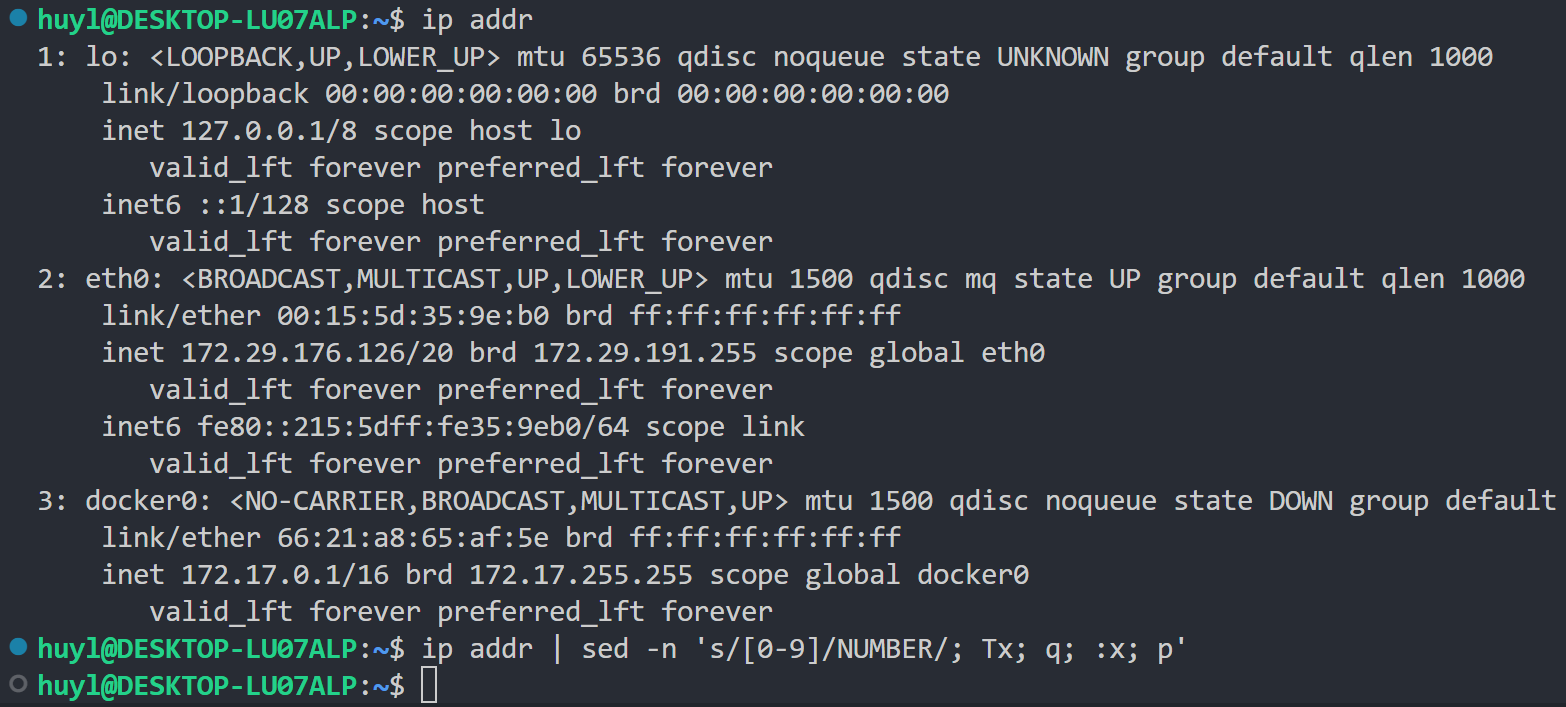
解释:T label 指令的逻辑和 t label指令相反,这里用了几乎和上面的例子相同的 sed 命令,只是把其中的 tx 改成了 Tx,在这里这个多条脚本语句表示匹配带有数字的行并把第一个匹配到的数字替换成 NUMBER ,如果匹配失败,执行 tx 指令跳转到 :x 去执行 p 指令,也就是打印没有被替换的那行内容;如果匹配替换成功,则不跳转继续执行 q 指令就是退出程序。从结果看第一行就匹配成功退出程序里,所以什么都没打印。
📂 5.2.5 文件操作指令
F: 打印当前输入文件的文件名。效果:

解释:这里是一个多条脚本语句,'${p; F}' 表示先匹配最后一行,然后打印最后一样,然后再打印当前输入的文件名。这条脚本语句等同与 '$p; $F'
r filename: 这个指令会做两件事,读取 filename 文件的全部内容,在内部循环结束的时候将文件的全部内容插入到打印输出的内容后面。通常用于把一份文件插入到另一份文件中。效果:
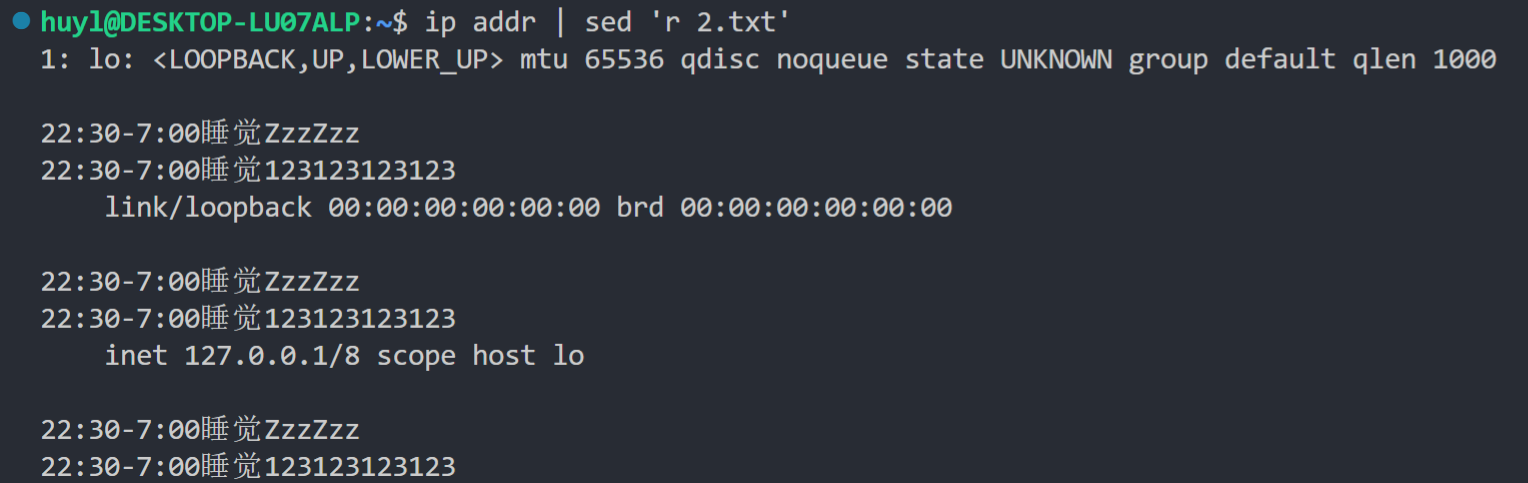
解释:可以看到,如果 r 指令前面不加匹配地址的话,在输出的结果中 ip addr 每行后面都跟了 2.txt 文件的全部内容
R filename: 这个指令是 r 指令的变体,每次调用这个指令的时候,只读取 filename 文件一行内容,并在内部循环结束的时候将这行内容插入到打印输出的内容后面。通常用于流式合并两个文件。效果:
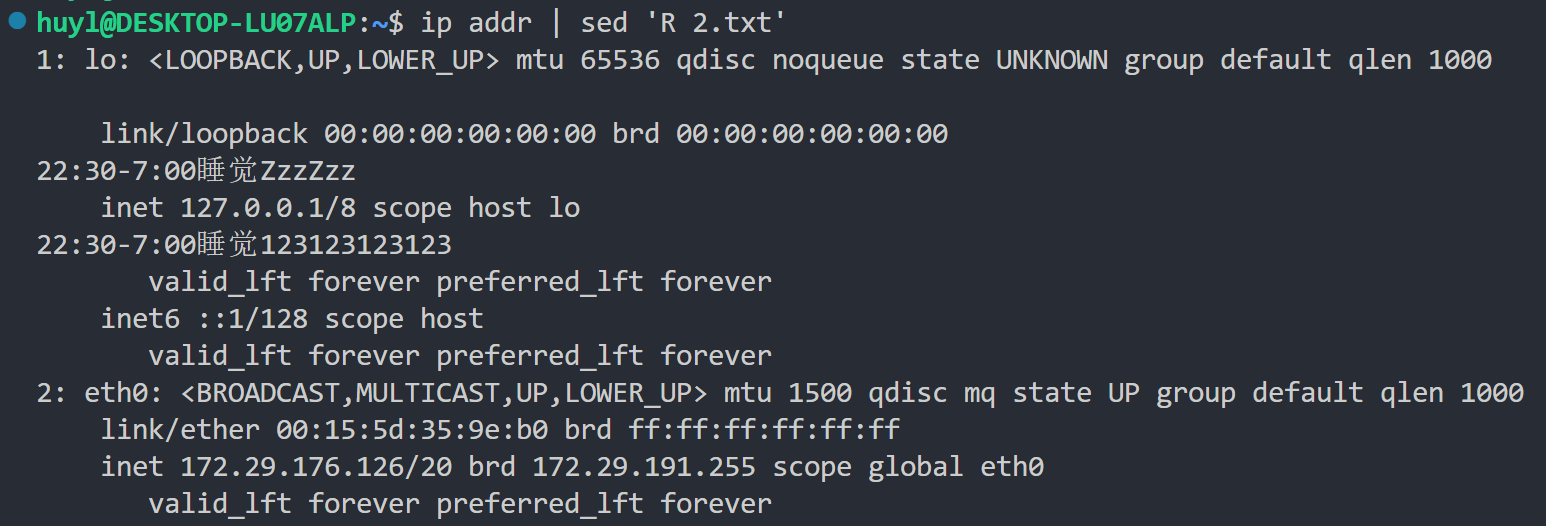
解释:可以看到,如果 R 指令前面不加匹配地址的话,在输出的结果中 ip addr 第一行后面跟了 2.txt 的第一行,ip addr 第二行后面跟了 2.txt 的第二行,ip addr 第三行后面跟了 2.txt 的第三行。再往后面 2.txt 里面没内容了,所以就都是 ip addr 的内容。
w filename: 这个指令在执行的时候会将整个模式空间内的内容,写入 filename 文件中。效果:
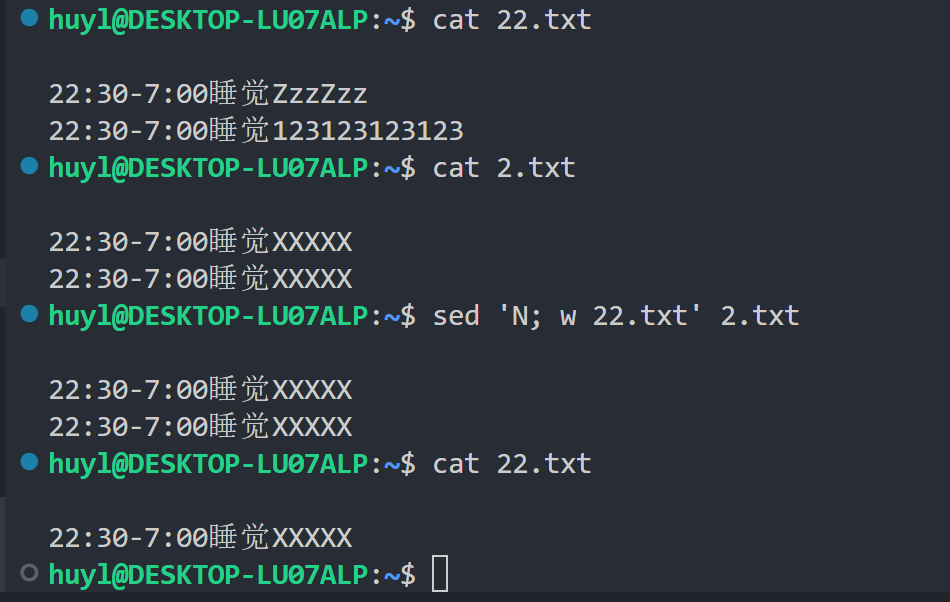
解释:这条 sed 脚本语句是多条脚本语句,在执行 w 指令之前模式空间内有两行内容,所以最后写入22.txt 文件中的只有两行,这就是“整个模式空间的内容”的意思
W filename: 这个指令式 w 指令的变体,在执行的时候只会将模式空间的一行内容写入 filename 文件中。效果:
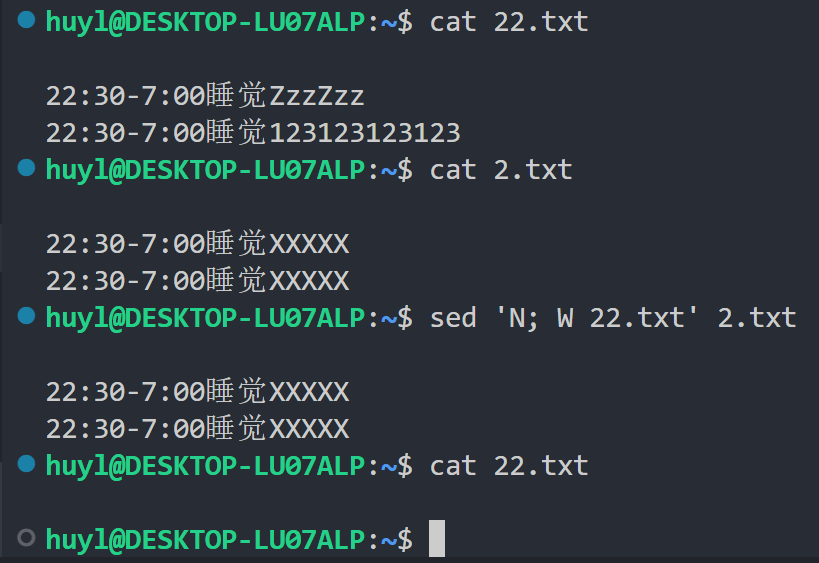
解释:这里也是多条脚本语句,在执行 W 指令之前模式空间内有两行内容,但最后写入22.txt 文件中的只模式空间的第一行。这就是“模式空间的第一行内容”的意思
🎁 5.2.6 特殊操作指令
e command: e 指令是一个非常强大但又非常危险的指令,玩的好是大神,玩不好是破坏神。他允许 sed 在修改文件的过程的时候,在系统中执行 shell 命令。e 指令一般有3种用法,分别是单独使用,把shell 命令作为 command 参数使用,作为 s 指令的 flag 使用。接下来依次介绍。
首先是单独使用的用法,当 e 指令单独使用的时候,会将模式空间的内容当成 shell 命令执行。效果:
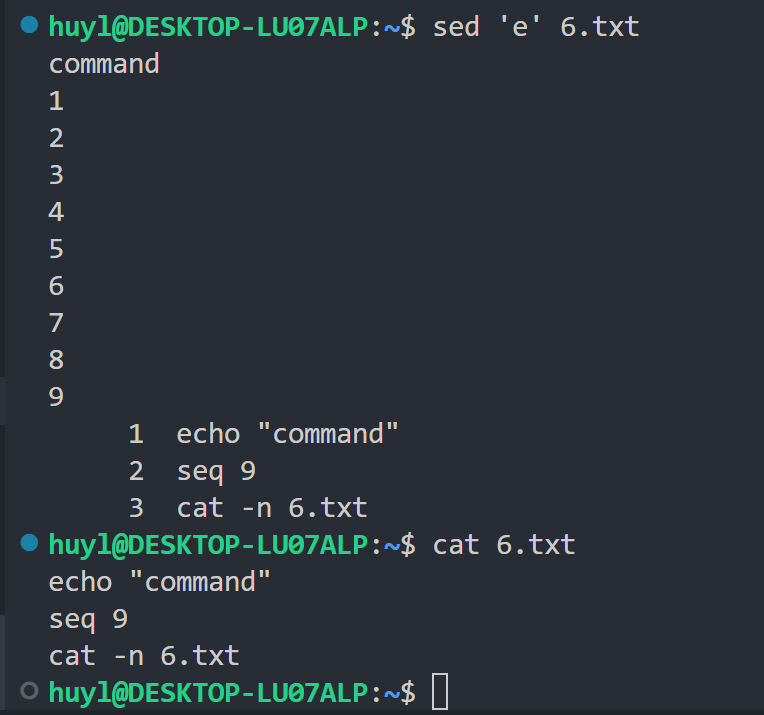
解释:可以看到 sed 将 6.txt 的每行内容当成是 shell 命令依次执行了。在这种用法中,不需要 6.txt 是 .sh 后缀,也不需要 6.txt 第一行是 #!/bin/bash,甚至不需要 6.txt 具有可执行权限,只需要 6.txt 具有可读权限,sed 就能执行它。非常的强大。
然后是把 shell 命令作为 command 参数使用的用法,在这种用法中 e 指令会做两件事,第一件是让系统执行 command 中的 shell 命令,第二件是把 shell 命令执行的输出重新写回模式空间(如果你用了 -i 命令行参数,模式空间最后会被直接写入文件中,所以一般不建议 -i 和 e 一起用)。效果:
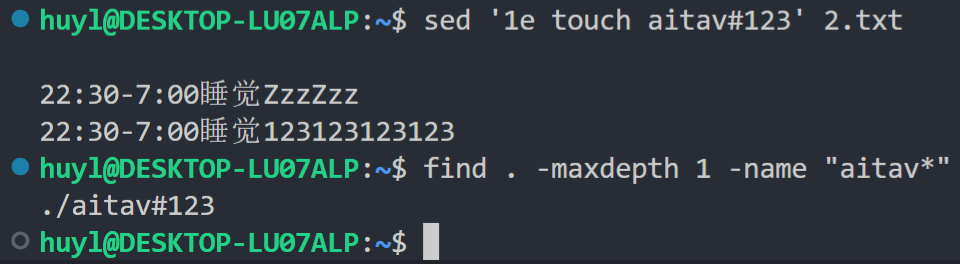
解释:这里用 e 指令的 e command 形式执行 shell 命令创建了一个新文件
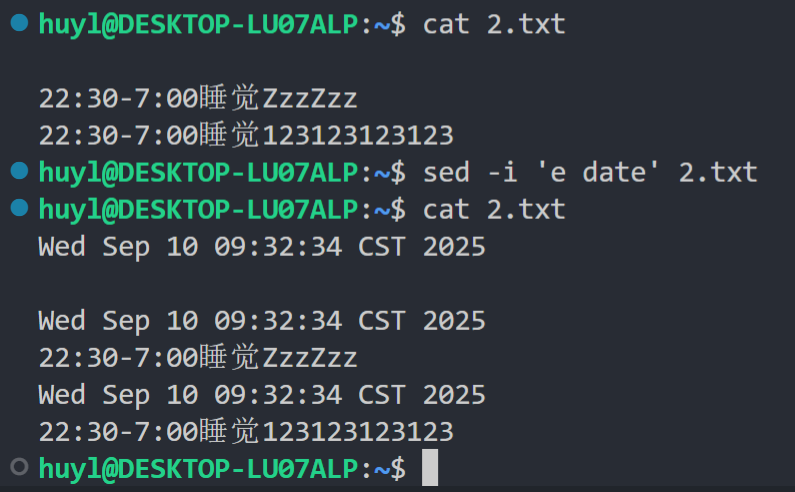
解释:这就是 -i 命令行参数和 e 指令一起使用的后果。
最后是作为 s 指令的 flag 使用的用法,个人觉得是 e 指令中最实用的玩法。效果:
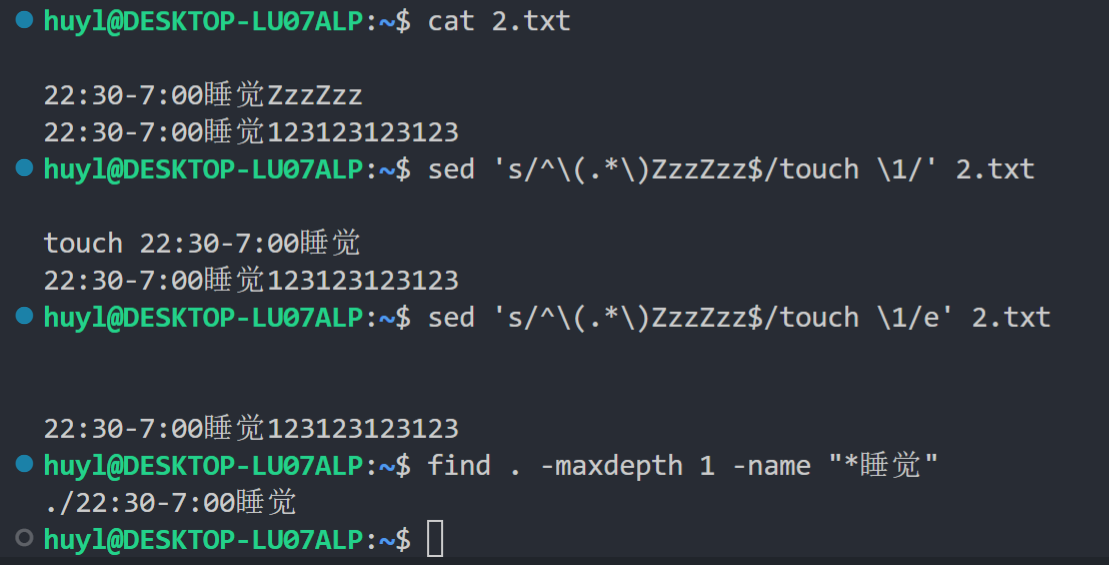
解释:这里这条命令:
sed 's/^\(.*\)ZzzZzz$/touch \1/e' 2.txt显示匹配以 ZzzZzz 结尾的行,然后把该行开头添加 touch 并去掉 ZzzZzz 形成一条 shell 命令,最后再用 e 指令执行这条命令,创建了 22:30-7:00睡觉 的文件。至于 \(.*\) 以及 \1 是什么意思,这些都是正则表达式的语法,这里不方便展开,更多详见 [ regexp 正则表达式详解(以后有空更)]
在 sed 中执行 shell 命令可能会对 sed 正在操作的文件造成影响,比如在 e 指令中再添加 sed 命令来修改正在修改的文件(套娃),会造成无法预测的结果。所以要想真正会玩 e 指令,还需要对Linux文件管理子系统和文件结构有深刻的认识
#: 这个指令用于在 sed 脚本中添加注释,虽然大部分情况下看不懂的人加了注释还是会看不懂。效果如下:
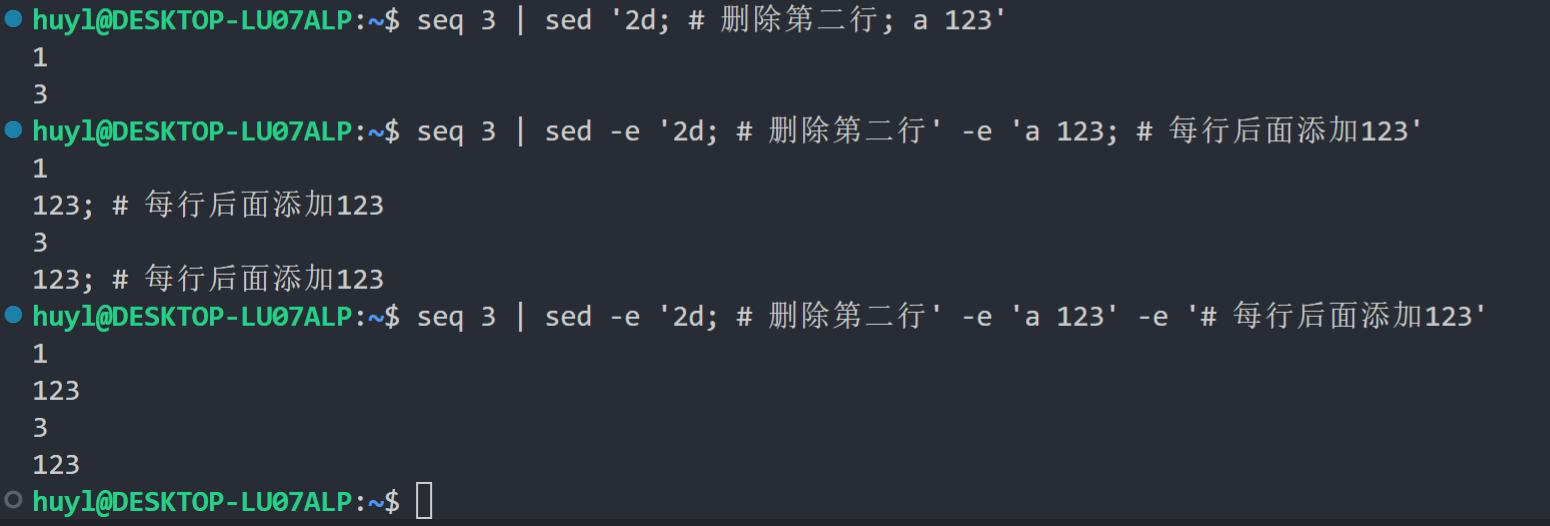
解释:# 后面的内容会被当成注释,并且不会被执行。和 a 指令一样,这个时候就显示出 -e 命令行参数的重要性了。(你是故意的还是不小心?我是故意的!)
🌀 6. 经典模板
sed 里面有很多经典模板,比如用 sed 实现的计算器,或者用 sed 实现的滑动窗口等等。这里就介绍一个我个人比较喜欢的模板,还没学废的朋友,可以细品一下。
6.1 🔄 滑动窗口
代码示例:
sed -n 'h; :x; $b; N; /^\(.*\)\n\1$/{g; bx}; $b; P; D' file.txt
效果:
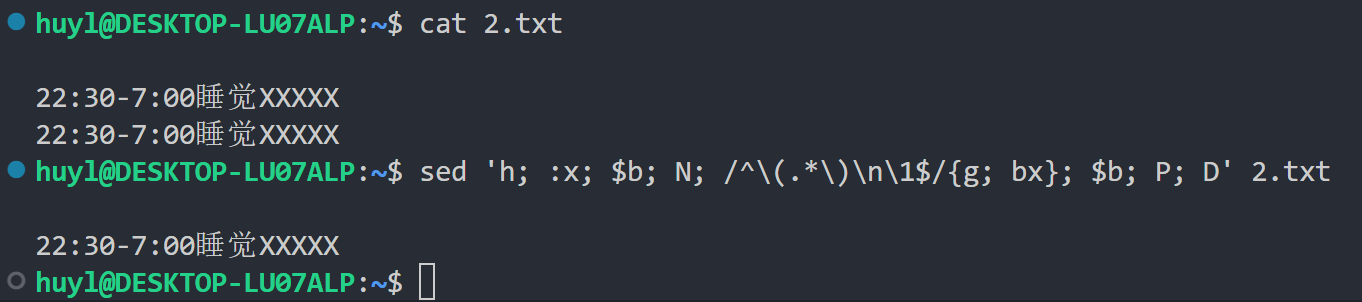
解释:
这段代码的效果是以两行为窗口长度对文本进行处理,如果发现由连续重复的行则删除其中一行。其中的删除重复行的操作可以替换成任何你喜欢的操作,这个模板用的好甚至可以处理实时日志。其中用到的指令解释如下:
h:把当前模式空间(第一行)复制到保持空间
:x: 设置标签 x
$b: b 指令的特殊用法,如果下一行时最后一行则退出当前内部循环(注意这里不是指 :x 和 bx 构成的循环)
N: 追加下一行到模式空间
/^\(.*\)\n\1$/ { g; bx }: 如果两行相同,用保持空间覆盖模式空间,然后跳回 x
$b: 如果下一行时最后一行则退出当前内部循环
P:打印模式空间第一行D:删除模式空间第一行,循环处理剩余行
🍗 7. 注意事项
7.1 🔒 sed修改只读文件
sed 的 -i 命令行参数可以使 sed 具有修改只读文件的能力,比如:
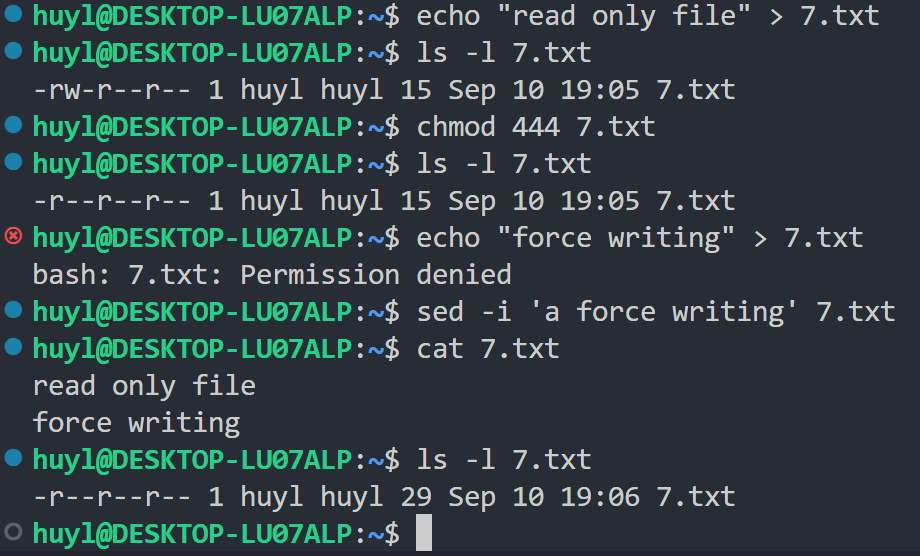
从这里可以看到对于只读文件,echo是写不进去的,但是 sed 可以写进去,这是因为 -i 命令行参数会创建一个 临时文件 ,然后在这个 临时文件 上操作,操作完成以后再将 临时文件 重命名回原文件。本质上是进行文件的替换,而不是文件的写入。文件替换操作的结果受 目录权限 控制,而不是文件本身的权限。所以就会出现这一个神奇的现象,也算是一个某些特殊情况下可能会派上用场的小技巧。
7.2 ⚠️ sed空文件追加文本失败
当一个文件是 touch 出来的,使用 sed 命令对这个文件进行任何的文本追加都会失败。比如:
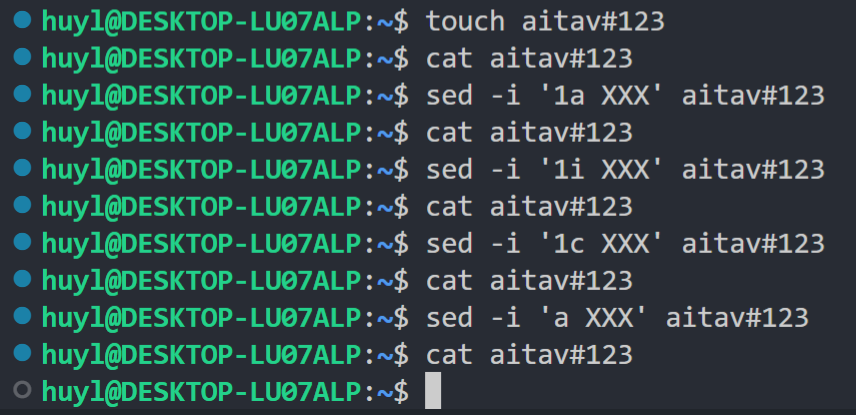
这时因为 sed 里面的核心逻辑都是围绕着行来的,按行读取按行输出,而这个 touch 出来的文件连行都没有,所以 sed 读不到东西改不了东西。那 touch 出来的文件要怎么用 sed 修改呢? echo 一点内容进去就行了,比如:
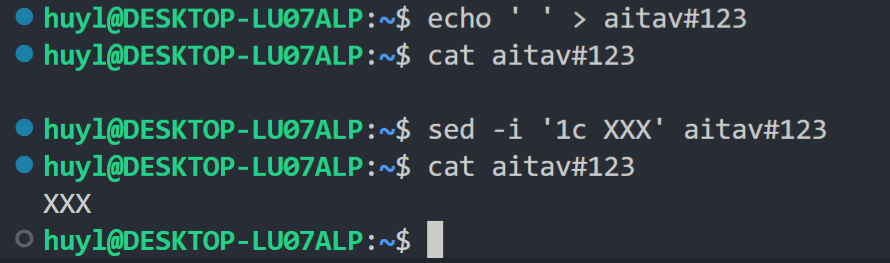
7.3 💥 重定向 > 导致文件清空问题
sed在使用时候需要特别注意重定向后面的文件,比如:
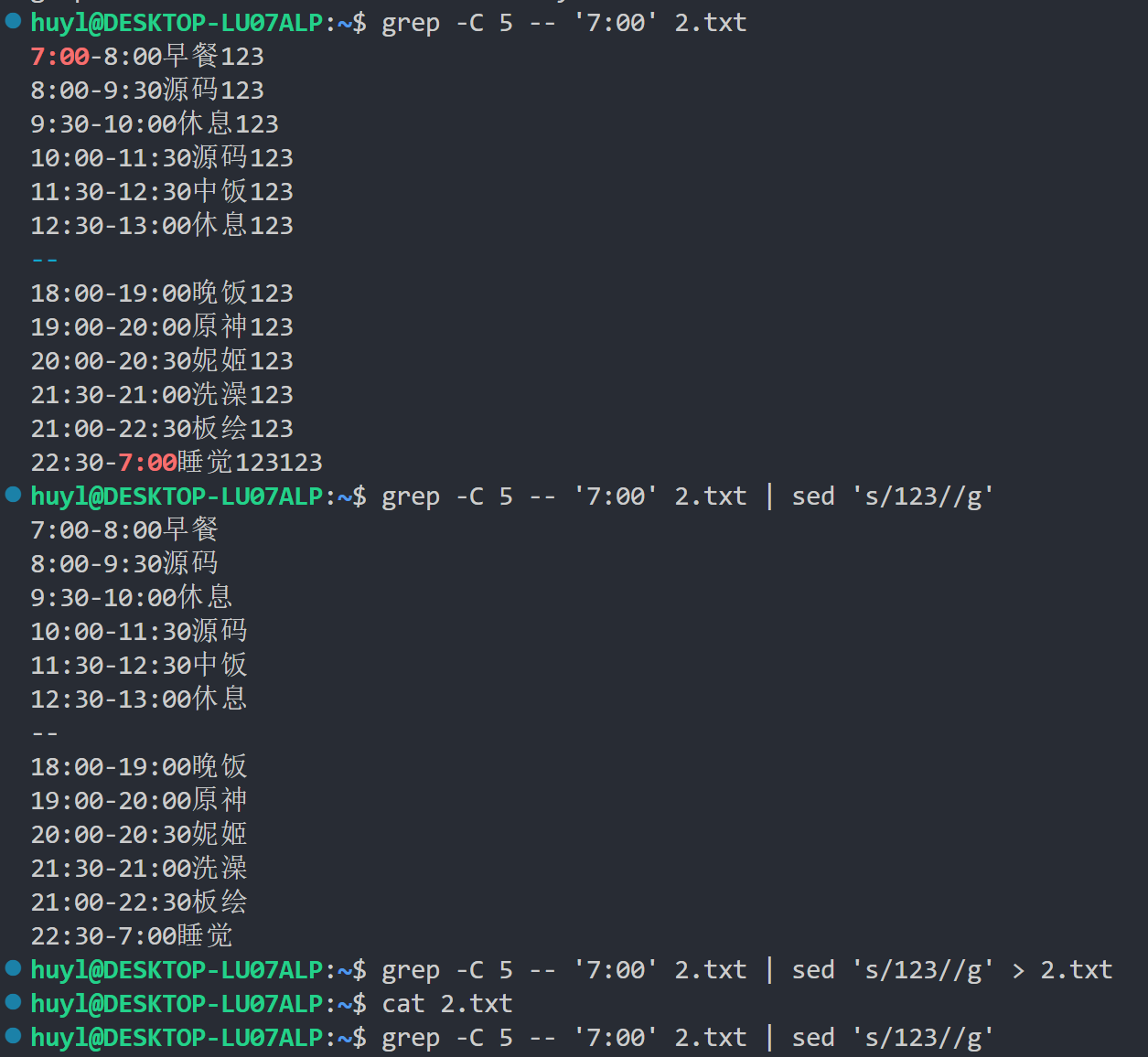
这里可以看到这个笨笨的Linux玩家在执行了
grep -C 5 -- '7:00' 2.txt | sed 's/123//g' > 2.txt这条命令以后,2.txt 文件被清空的现象。
这是由于 Shell 会在执行命令之前,先解析重定向符号 ">" 。而重定向一旦解析,目标文件立即被清空,不管后续命令用不用它。也就是说这条命令 grep 读到的其实是个空文件,然后sed输出的也是个空文件。最后空文件又被重定向到了 2.txt,所以再次浏览 2.txt 里面自然空空如也。
同理以下这条命令也会清空文件:
sed 's/123//g' 2.txt > 2.txt所以备份是个好习惯,玩 sed 的时候一定要养成。
📖 8. 参考资料
GNU sed 手册:详细介绍了 sed 的功能、语法和示例,适合深入学习。
https://www.gnu.org/software/sed/manual/sed.html
sed info 页面:提供了 sed 的详细文档,包括命令、选项和示例。
https://www.gnu.org/software/sed/manual/sed.info
sed man 手册:适用于 Linux 系统的 sed 使用手册,包含命令和选项的简要说明。
https://man7.org/linux/man-pages/man1/sed.1.html