O3.1 opencv高阶
一·扩展代码
逻辑
1. match.py
- 功能:实现模板匹配功能,且支持对旋转后的模板进行匹配。
- 读取原始图像(
image.jpg)和模板图像(tem.jpg),将原始图像转为灰度图。 - 对模板进行两种旋转处理(顺时针 90 度、逆时针 90 度)。
- 定义
findtemp函数:使用cv2.matchTemplate进行模板匹配,通过阈值(0.9)筛选匹配区域,并在原始图像上用红色矩形标记匹配结果。 - 分别对原始模板、两种旋转后的模板执行匹配,最终显示标记后的图像。
- 读取原始图像(
2. 旋转.py
- 功能:展示图像旋转的两种实现方法,用于生成旋转后的图像(可作为模板匹配的辅助工具)。
- 方法一:使用
np.rot90旋转图像,k=-1表示顺时针 90 度,k=1表示逆时针 90 度。 - 方法二:使用
cv2.rotate旋转图像,支持顺时针 90 度、逆时针 90 度、180 度三种旋转方式。 - 显示原始图像和旋转后的图像,便于直观查看旋转效果。
- 方法一:使用
3. 模板与多个对象匹配.py
- 功能:基础的多对象模板匹配实现,展示模板匹配的核心逻辑。
- 读取原始图像和模板图像,将原始图像转为灰度图。
- 使用
cv2.matchTemplate进行匹配,通过阈值筛选匹配区域,并用红色矩形标记所有符合条件的区域。 - 包含辅助代码:解释
np.where的返回值格式(用于获取匹配点坐标)和zip函数的打包 / 解包用法(用于处理坐标数据)。
三个文件的搭配关系
技术互补:
- 旋转.py提供图像旋转的基础方法(两种旋转函数),为match.py中 “对模板进行旋转后再匹配” 的功能提供了技术支持(
match.py中正是使用了np.rot90实现模板旋转)。 - 模板与多个对象匹配.py展示了模板匹配的核心流程(读取图像、匹配、筛选、标记),而match.py在此基础上扩展了 “旋转模板匹配” 的功能,是对基础模板匹配的进阶应用。
- 旋转.py提供图像旋转的基础方法(两种旋转函数),为match.py中 “对模板进行旋转后再匹配” 的功能提供了技术支持(
功能递进:
- 先通过旋转.py掌握图像旋转的方法,再通过模板与多个对象匹配.py理解基础模板匹配逻辑,最后结合两者,通过match.py实现更复杂的 “多方向模板匹配”(应对模板可能旋转的场景)。
代码复用:
- match.py中的模板匹配逻辑(如
cv2.matchTemplate、阈值筛选、矩形标记)与模板与多个对象匹配.py的核心代码高度相似,前者复用了后者的基础框架。 - match.py中的旋转逻辑(
np.rot90)直接来自旋转.py的 “方法一”,体现了代码功能的模块化复用。
- match.py中的模板匹配逻辑(如
综上,三个文件围绕 “图像旋转” 和 “模板匹配” 两个核心技术,从基础方法(旋转.py、模板与多个对象匹配.py)到综合应用(match.py),形成了递进式的功能搭配。
把我的样本图和第二张图进行比对找到和样本图相对的地方,进行采样
代码
match
import cv2
import numpy as npimg_rgb = cv2.imread("image.jpg")
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread("tem.jpg", 0)
h,w = template.shape[:2]
# 旋转模板图像
# 旋转 90 度,k=-1 表示顺时针旋转 90 度
rotated_image1 = np.rot90(template, k=-1)
# 旋转 90 度,k=1 表示逆时针旋转 90 度
rotated_image2 = np.rot90(template, k=1)
def findtemp(temp):# 使用模板匹配方法 cv2.matchTemplate 进行模板匹配res = cv2.matchTemplate(img_gray, temp, cv2.TM_CCOEFF_NORMED)# 设定匹配阈值threshold = 0.9# 获取匹配结果中所有符合阈值的点的坐标loc = np.where(res >= threshold)# 遍历所有匹配点for pt in zip(*loc[::-1]):# 在原图上绘制匹配区域的矩形框cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0, 0, 255), 1)
# 对原始模板和旋转后的模板进行匹配
findtemp(template)
findtemp(rotated_image1)
findtemp(rotated_image2)
# 显示最终结果图像
cv2.imshow('res.png', img_rgb)
cv2.waitKey(0)
模板与多个对象匹配
import cv2
import numpy as np
# 读取原始图像和模板图像
img_rgb = cv2.imread('image.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('tem.jpg', 0)
h, w = template.shape[:2]
# 使用模板匹配方法 cv2.matchTemplate 进行模板匹配
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
# 设定匹配阈值
threshold = 0.9
# 获取匹配结果中所有符合阈值的点的坐标
loc = np.where(res >= threshold) # (符合条件的行,符合条件的列)
# 遍历所有匹配点
for pt in zip(*loc[::-1]):# 在原图上绘制匹配区域的矩形框cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0, 0, 255), 1)
cv2.imshow('', img_rgb)
cv2.waitKey(0)# a = np.array([2,4,6,8,10])
# # b= np.array([[2,4,6,8,10]])
# # c= np.array([[2,4,6,8,10],[6,5,6,5,4]])
# d=np.where(a > 5)
# print(d)# zip(*iterables) 将多个可迭代对象(如列表、元组等)进行“解压”操作
# a = [1, 2, 3]
# b = [4, 5, 6]
# # 使用 zip 将它们按位置进行配对
# zipped = zip(a, b)
# print(list(zipped)) # 输出:[(1, 4), (2, 5), (3, 6)]
# #
# # # 假设我们已经有了一个打包好的 zip 对象
# zipped = zip(a, b)
# # 使用 * 运算符解包,得到转置的结果
# unzipped = zip(*zipped)
# print(list(unzipped)) # 输出:[(1, 2, 3), (4, 5, 6)]旋转
import cv2
import numpy as np
# 方法一
img = cv2.imread('../kele.png')
# 旋转 90 度,k=-1 表示顺时针旋转 90 度
rotated_image1 = np.rot90(img, k=-1)
# 旋转 90 度,k=1 表示逆时针旋转 90 度
rotated_image2 = np.rot90(img, k=1)cv2.imshow('yuantu', img)
cv2.imshow('rotated_image1', rotated_image1)
cv2.imshow('rotated_image2', rotated_image2)
cv2.waitKey(0)
cv2.destroyAllWindows()# 方法二
rotated_image = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE) # 顺时针90度
rotated_image1 = cv2.rotate(img, cv2.ROTATE_90_COUNTERCLOCKWISE) # 逆时针90度
rotated_image2 = cv2.rotate(img, cv2.ROTATE_180) # 旋转180度
cv2.imshow('shun90', rotated_image)
cv2.imshow('ni90', rotated_image1)
cv2.imshow('180', rotated_image2)
cv2.waitKey(0)效果

二·图像金字塔
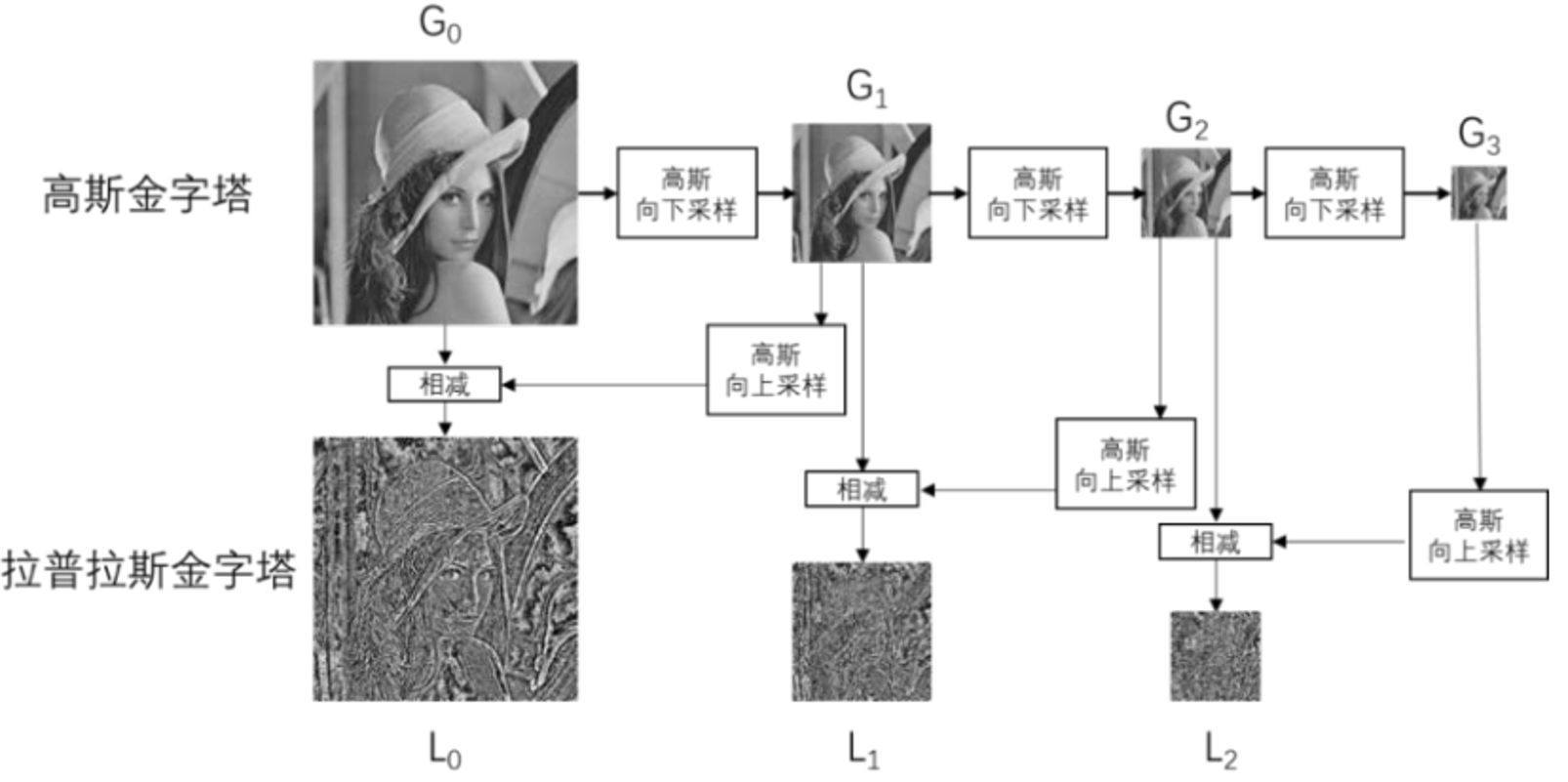
图像金字塔是什么?
是由一幅图像的多个不同分辨率的子图构成的图像集合。是通过一个图像不断的降低采样率产生的,最小的图像可能仅仅有一个像素点。图像金字塔的底部是待处理的高分辨率图像(原始图像),而顶部则为其低分辨率的近似图像。
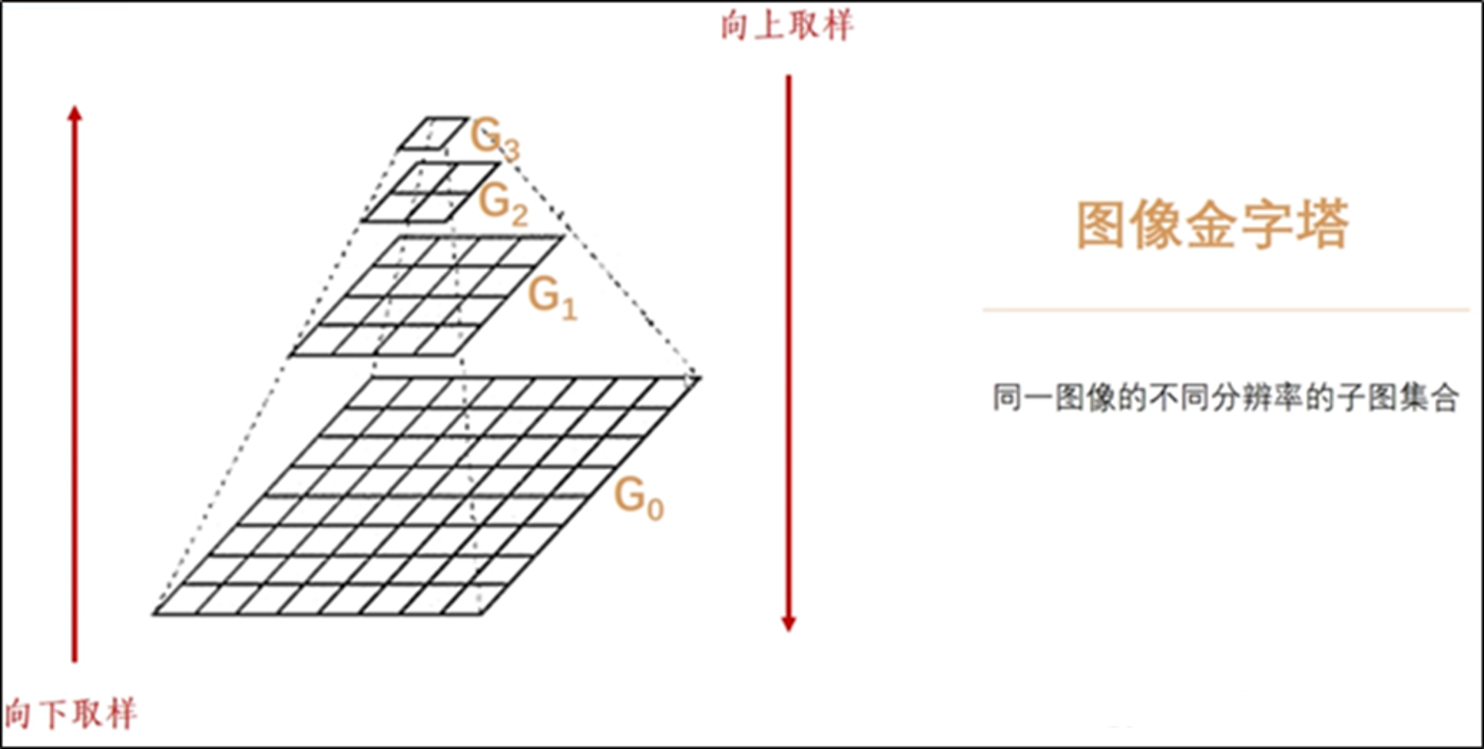
向下采样
向金字塔顶部移动时,图像的尺寸和分辨率都不断地降低。通常情况下,每向上移动一级,图像的宽和高都降低为原来的1/2。 做法:
1、高斯滤波
2、删除其偶数行和偶数列
OpenCV函数cv2.pyrDown()
图像金字塔作用
· 特征点提取(SIFT、HOG、ORB等) · 模板匹配 · 光流跟踪
逻辑
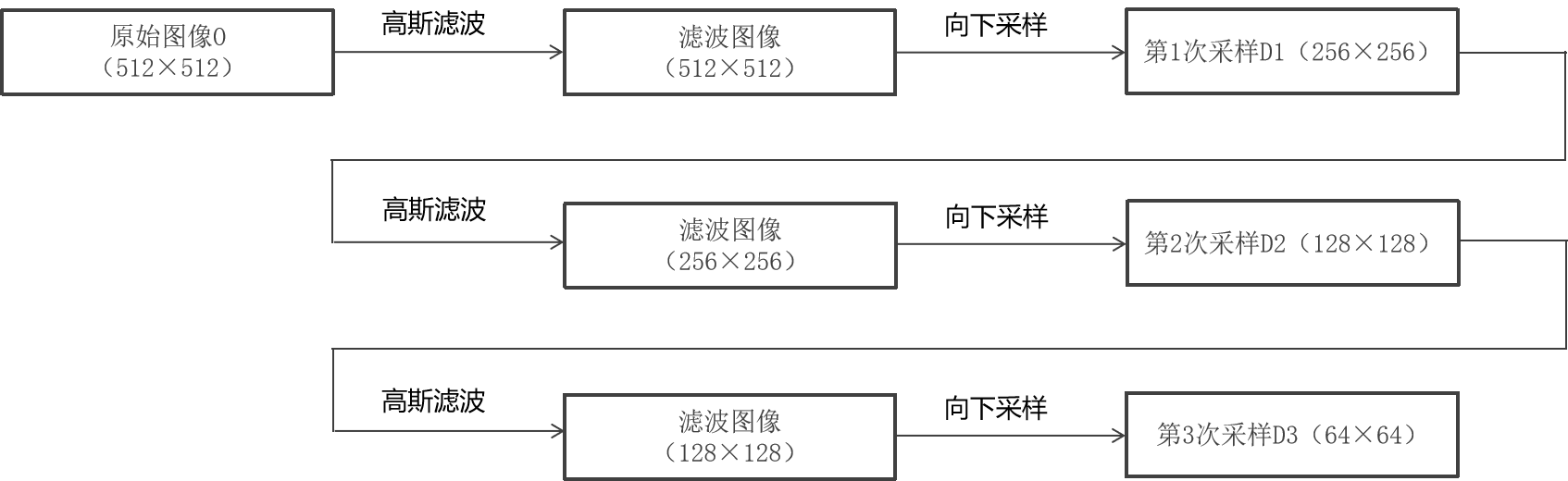
1. 高斯金字塔的下采样(图像缩小)
face = cv2.imread('face.png', cv2.IMREAD_GRAYSCALE) # 读取灰度图作为原始图像(G0)
face_down_1 = cv2.pyrDown(face) # 对G0下采样得到G1
face_down_2 = cv2.pyrDown(face_down_1) # 对G1下采样得到G2
- 下采样逻辑:
cv2.pyrDown()是高斯金字塔的核心操作,步骤为:- 对原始图像进行高斯模糊(去除高频信息,避免下采样时的锯齿);
- 去掉图像中所有偶数行和偶数列,使图像尺寸变为原来的 1/2(宽和高各减半)。
- 效果:
每一次下采样,图像尺寸缩小一半(如 G0→G1→G2),但会丢失部分细节,图像逐渐模糊。
2. 高斯金字塔的上采样(图像放大)
face_up_1 = cv2.pyrUp(face) # 对G0上采样得到G1'
face_up_2 = cv2.pyrUp(face_up_1) # 对G1'上采样得到G2'
- 上采样逻辑:
cv2.pyrUp()是下采样的逆操作,步骤为:- 在图像的偶数行和偶数列之间插入 0 值,使图像尺寸变为原来的 2 倍;
- 用与下采样相同的高斯核进行卷积(平滑处理),填充插入的 0 值。
- 注意:
上采样只是单纯放大尺寸,无法恢复下采样时丢失的细节,因此放大后的图像会比原始图像模糊。
3. 下采样后再上采样的局限性
# 对下采样后的图像(G1、G2)进行上采样
face_down_1_up = cv2.pyrUp(face_down_1) # G1上采样得到G1_up
face_down_2_up = cv2.pyrUp(face_down_2) # G2上采样得到G2_up
- 问题:
下采样时丢失的高频信息(细节)无法通过上采样恢复,因此face_down_1_up虽然尺寸与原始图像face相近,但会更模糊,无法复原原始图像。
4. 拉普拉斯金字塔(图像细节保留与复原)
为了保留下采样丢失的细节,引入拉普拉斯金字塔:
# 计算拉普拉斯金字塔层(L0、L1)
L0 = face - face_down_1_up[:face.shape[0], :face.shape[1]] # 原始图 - G1上采样(裁剪后)
L1 = face_down_1 - face_down_2_up[:face_down_1.shape[0], :face_down_1.shape[1]] # G1 - G2上采样(裁剪后)
- 拉普拉斯逻辑:
拉普拉斯金字塔的每一层(Li)是通过 当前高斯层(Gi)减去上一层高斯层上采样后的结果(Gi+1_up) 得到的,它记录了下采样过程中丢失的细节(高频信息)。- 裁剪操作(
[:shape])是为了处理上采样后尺寸可能与原始层不匹配的问题(确保像素尺寸一致)。
- 裁剪操作(
# 利用拉普拉斯金字塔复原图像
fuyuan = face_down_1_up[:face.shape[0], :face.shape[1]] + L0 # G1_up(裁剪) + L0 = 原始图
- 复原逻辑:
拉普拉斯层(L0)记录了 G0 到 G1 丢失的细节,因此将上采样后的 G1(G1_up)与 L0 相加,即可恢复原始图像 G0。这验证了拉普拉斯金字塔对细节的保留能力。
总结
代码的核心逻辑是:
- 高斯金字塔通过下采样缩小图像(丢失细节)和上采样放大图像(无法恢复细节);
- 拉普拉斯金字塔通过记录下采样丢失的细节(高频信息),实现了基于高斯金字塔的图像复原。
这种金字塔结构常用于图像融合、多分辨率分析等场景,通过不同尺度的图像信息进行处理。
代码
import cv2 #opencv读取的格式是BGR
import matplotlib.pyplot as plt #matplotlib读取的格式与opencv不同
import numpy as np # pip install numpy==1.26.4 -i
'''----------------高斯金字塔操作中的向下采样------------------'''
# 下采样 是一种减小图像尺寸的方法,它通常涉及到降低图像的分辨率,即减少图像中像素的数量,从而使图像看起来更小。
# 上采样 是一种增大图像尺寸的方法,它通过插值和滤波技术来恢复图像的分辨率和细节,通常用于图像放大或者与下采样后的图像进行比较。
# resize函数 是一种通用的图像尺寸调整方法,它可以按照指定的目标尺寸来缩放图像,不涉及金字塔结构或者特定的滤波操作。# dst = cv2.pyrDown(src [,dst, dstsize [, borderType] ])
# dst:目标图像
# src:原始图像
# dstsize:目标图像的大小face = cv2.imread('face.png',cv2.IMREAD_GRAYSCALE)#G0
cv2.imshow('face',face)
cv2.waitKey(0)
face_down_1 = cv2.pyrDown(face)#下采样G1
cv2.imshow('down_1',face_down_1)
cv2.waitKey(0)
face_down_2 = cv2.pyrDown(face_down_1)#G2
cv2.imshow('down_2',face_down_2)
cv2.waitKey(0)
#高斯金字塔操作中的向上采样
# dst = cv2.pyrUp(src [,dst, dstsize [, borderType] ])
# dst:目标图像
# src:原始图像
# dstsize:目标图像的大小
face_up_1 = cv2.pyrUp(face)
cv2.imshow('up_1',face_up_1)#G1’
cv2.waitKey(0)
face_up_2 = cv2.pyrUp(face_up_1)
cv2.imshow('up_2',face_up_2)#G2‘
cv2.waitKey(0)
# # #对下采用后图像进行上采样,图像变模糊,无法复原
face_down_1_up = cv2.pyrUp(face_down_1)#下采样G1
face_down_2_up = cv2.pyrUp(face_down_2)#下采样G2cv2.imshow('down_1_up',face_down_1_up)
cv2.imshow('down_2_up',face_down_2_up)
cv2.waitKey(0)# # # 拉普拉斯金字塔
L0 = face - face_down_1_up
L1 = face_down_1 - face_down_2_upfuyuan = face_down_1_up + L0
cv2.imshow('L0',L0)
cv2.imshow('L1',L1)
cv2.waitKey(0)
cv2.imshow('fuyuan',fuyuan)
cv2.waitKey(0)
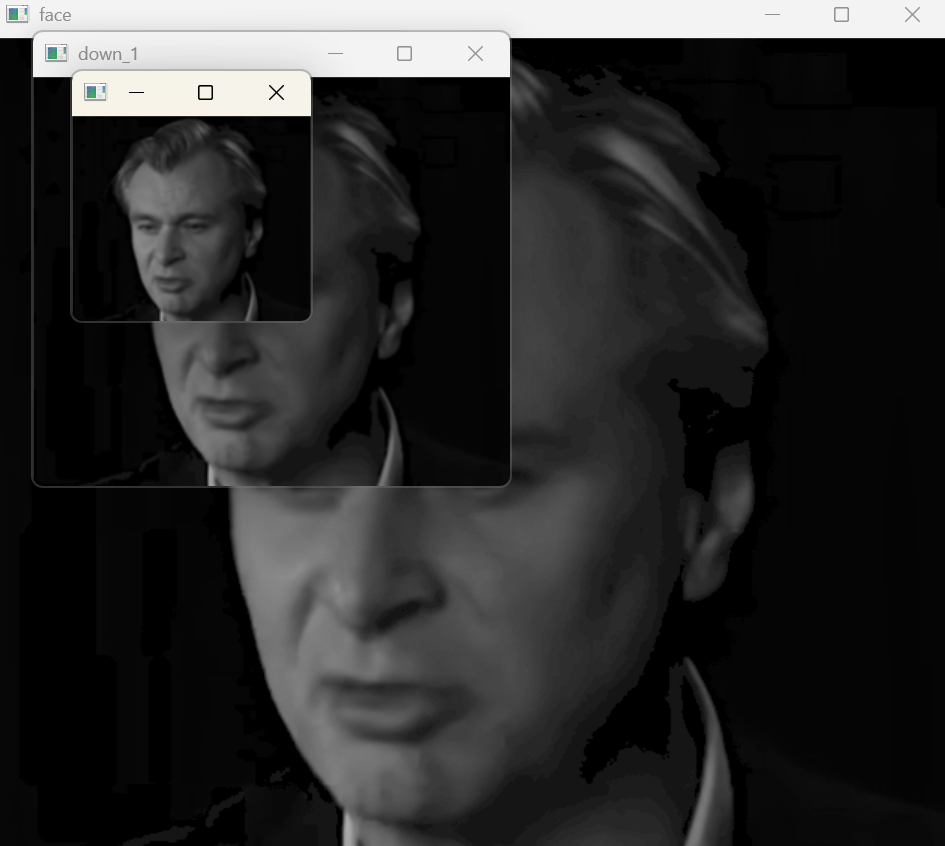
下采样效果
上采样
向上采样
通常将图像的宽度和高度都变为原来的2倍。这意味着,向上采样的结果图像的大小是原始图像的4倍。因此,要在结果图像中补充大量的像素点。对新生成的像素点进行赋值的行为,称为插值。 做法:
1、插值
2、高斯滤波
通过以上分析可知,向上采样和向下采样是相反的两种操作。但是,由于向下采样会丢失像素值,所以这两种操作并不是可逆的。也就是说,对一幅图像先向上采样、再向下采样,是无法恢复其原始状态的;同样,对一幅图像先向下采样、再向上采样也无法恢复到原始状态

拉普拉斯金字塔
为了在向上采样是能够恢复具有较高分辨率的原始图像,就要获取在采样过程中所丢失的信息,这些丢失的信息就构成了拉普拉斯金字塔。 也是拉普拉斯金字塔是有向下采样时丢失的信息构成。
拉普拉斯金字塔的定义:

还是刚才的代码
# 拉普拉斯金字塔 - 修正形状不匹配问题
# 将上采样后的图像裁剪到与原始图像相同的尺寸
L0 = face - face_down_1_up[:face.shape[0], :face.shape[1]]
# 将上采样后的图像裁剪到与face_down_1相同的尺寸
L1 = face_down_1 - face_down_2_up[:face_down_1.shape[0], :face_down_1.shape[1]]fuyuan = face_down_1_up[:face.shape[0], :face.shape[1]] + L0 # 同样需要裁剪上采样图像
cv2.imshow('L0', L0)
cv2.imshow('L1', L1)
cv2.waitKey(0)
cv2.imshow('fuyuan', fuyuan)
cv2.waitKey(0)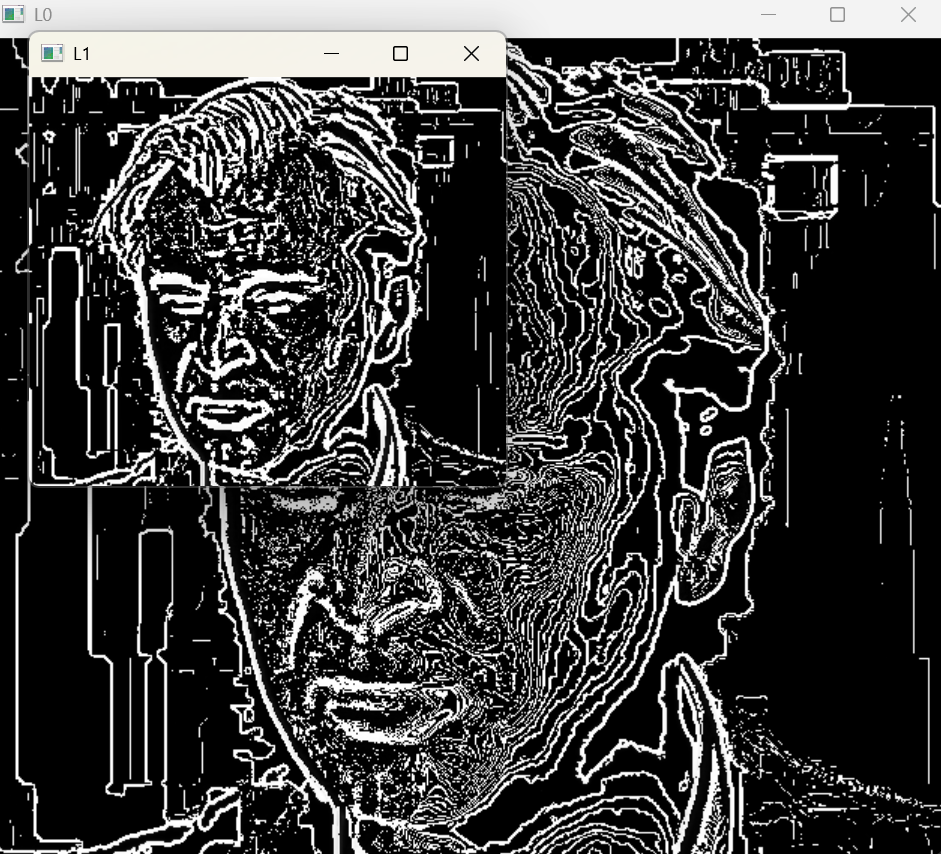
图像直立方图
直方图:是图像中像素强度分布的图形表达方式。
直方图的作用:例如视频中。通过标记帧和帧之间显著的边缘和颜色的统计变化,来检测视频中场景的变换。

灰度值在0 - 255范围之间总共 256 个值,可以将我们的范围划分为子部分(称为bins),例如:

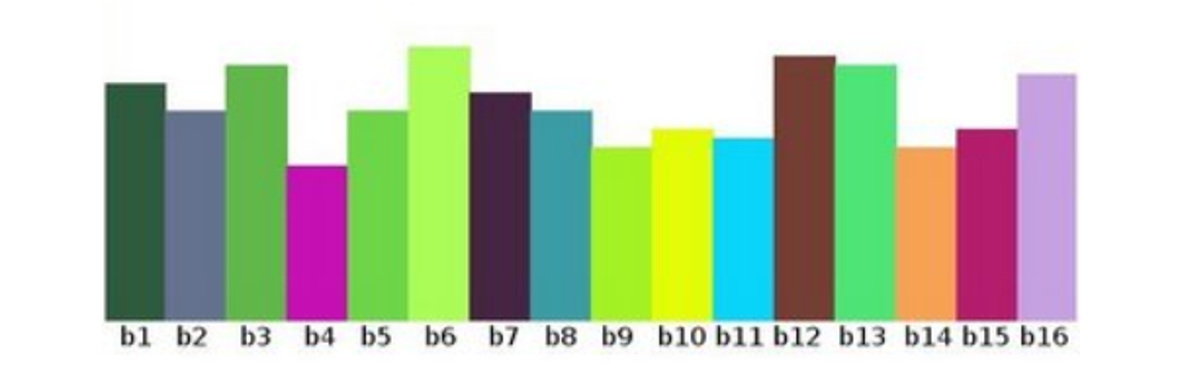
逻辑
1. 灰度图直方图(基础)
phone = cv2.imread('phone.png', cv2.IMREAD_GRAYSCALE) # 读取灰度图
a = phone.ravel() # 将二维图像转为一维数组(每个元素是像素的灰度值)
plt.hist(a, bins=256) # 用matplotlib绘制直方图
plt.show()
- 逻辑:先读取灰度图像,将其扁平化为一维数组(便于统计),然后用
plt.hist统计每个灰度值(0-255)的像素数量,生成 256 个条柱的直方图,直观展示图像的明暗分布。
2. 用 OpenCV 计算直方图(灰度图)
python
运行
phone_hist = cv2.calcHist([phone], [0], None, [16], [0, 256]) # 计算直方图
plt.plot(phone_hist) # 绘制曲线形式的直方图
plt.show()
cv2.calcHist参数解析:[phone]:输入图像(需用列表包裹)[0]:通道索引(灰度图只有 1 个通道,索引为 0)None:不使用掩膜(统计整幅图)[16]:将 0-255 分为 16 个区间(BINS=16)[0, 256]:像素值范围
- 逻辑:将灰度值范围压缩为 16 个区间,用曲线展示每个区间的像素数量分布,比 256 个条柱更简洁。
3. 彩色图的三通道直方图
img = cv2.imread('phone.png') # 读取彩色图(BGR格式)
color = ('b', 'g', 'r') # 对应BGR通道
for i, col in enumerate(color):histr = cv2.calcHist([img], [i], None, [256], [0, 256]) # 分别计算每个通道的直方图plt.plot(histr, color=col) # 用对应颜色绘制曲线
plt.show()
- 逻辑:彩色图有 B、G、R 三个通道,循环计算每个通道的直方图(256 个区间),并以对应颜色绘制曲线,展示三通道的像素分布差异(例如红色通道亮部多说明图像偏红)。
4. 掩膜(mask)的应用
- 掩膜逻辑:
- 掩膜是一张与原图同尺寸的黑白图,白色区域(255)表示 “需要统计的区域”,黑色区域(0)表示 “忽略的区域”。
- 通过
cv2.bitwise_and可直观看到掩膜截取的效果(只保留中间区域)。 - 计算直方图时传入 mask 参数,最终结果仅反映掩膜白色区域的像素分布,用于分析图像局部的明暗特征。
总结
代码从基础到进阶展示了直方图的用法:
- 全图灰度分布 → 2. 压缩区间的简洁展示 → 3. 彩色图的通道差异 → 4. 局部区域的精准分析(掩膜)。
直方图的核心作用是反映像素值的分布规律,可用于图像增强、阈值分割等后续处理的依据。
直立图代码
#$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
'''------------------直方图---------------------------------'''
# cv2.calcHist(images,channels,mask,histSize,ranges) 计算图像的直方图,用于表示图像中像素灰度级别的分布情况.
# images: 原图像图像格式为 uint8 或 float32。当传入函数时应 用中括号 [] 括来例如[img]
# channels: 表示传入的图像通道数。如果输入图像是灰度图它的值就是 [0]。
# 如果是彩色图像 的传入的参数可以是 [0][1][2] 它们分别对应着 BGR。
# mask: 掩模图像。统计整幅图像的直方图就把它为None。但是如果你想统计图像某一部分的直方图,你就制作一个掩模图像并使用它。
# histSize:BINS的数目。也需用中括号括来 (分成多少个区间)
# BINS :上面的直方图显示了每个像素值的像素数,即从0到255。即您需要256个值才能显示上述直方图。
# 但是请考虑一下,如果您不需要单独查找所有像素值的像素数,而是在像素值间隔内查找像素数,
# 该怎么办?例如,您需要找到介于 0 到 15 之间的像素数,然后是 16 到 31、32到47...、240 到 255。
# 您只需要 16 个值来表示直方图。
# 因此,只需将整个直方图拆分为 16 个子部分,每个子部分的值就是其中所有像素计数的总和。
# 这每个子部分都称为"BIN"。在第一种情况下,条柱数为256(每个像素一个),而在第二种情况下,它只有16。BINS 在 OpenCV 文档中由术语histSize表示。
# ranges: 像素值范围常为 [0 256]
phone = cv2.imread('phone.png',cv2.IMREAD_GRAYSCALE)
# 将图像转换为一维数组
a = phone.ravel()
# 这里使用了 numpy 的 ravel 函数,将多维数组拉成一维数组。
# 绘制直方图
plt.hist(a, bins=256) # 使用 matplotlib 的 hist 函数绘制直方图。
# 参数解释:
# - a:一维数组,即图像的像素值组成的数组。
# - bins=256:指定直方图的条数,即灰度级的数量。
plt.show()
# # 显示直方图
phone_hist = cv2.calcHist([phone],[0],None,[16],[0,256])
plt.plot(phone_hist)#使用calcHist的值绘制曲线图
plt.show()img=cv2.imread('phone.png')
color=('b','g','r')
for i,col in enumerate(color):histr=cv2.calcHist([img],[i],None,[256],[0,256])plt.plot(histr,color=col)
plt.show()# #
# # #什么是mask?掩膜,ps pr
# # #mask参数如何使用? mask为掩模图像,先来看一下mask效果
phone = cv2.imread('phone.png',cv2.IMREAD_GRAYSCALE)
cv2.imshow('phone',phone)
cv2.waitKey(0)
mask = np.zeros(phone.shape[:2],np.uint8) #创建黑白图像,用于制作mask
mask[50:350,100:470] = 255
cv2.imshow('mask',mask)
cv2.waitKey(0)
# #
# # cv2.bitwise_and():对图像(灰度图像或彩色图像均可)每个像素值进行二进制“与”操作,1&1=1,1&0=0,0&1=0,0&0=0
# # bitwise_and(src1, src2, dst=None, mask=None)参数:
# # src1、src2:为输入图像或标量,标src1和src2相与。
# # dst:可选输出变量,如果需要使用非None则要先定义,且其大小与输入变量相同
# # mask:图像掩膜,可选参数,用于指定要更改的输出图像数组的元素,mask为0的值,src1和src2相与的值都为0.
# # 非0的值,为src1和src2相与的值。
Phone_mask = cv2.bitwise_and(phone,phone,mask=mask)
cv2.imshow('phone_mask',Phone_mask)
cv2.waitKey(0)
# # # # #
phone_hist_mask = cv2.calcHist([phone],[0],mask,[256],[0,256])
plt.plot(phone_hist_mask)#使用calcHist的值绘制曲线图
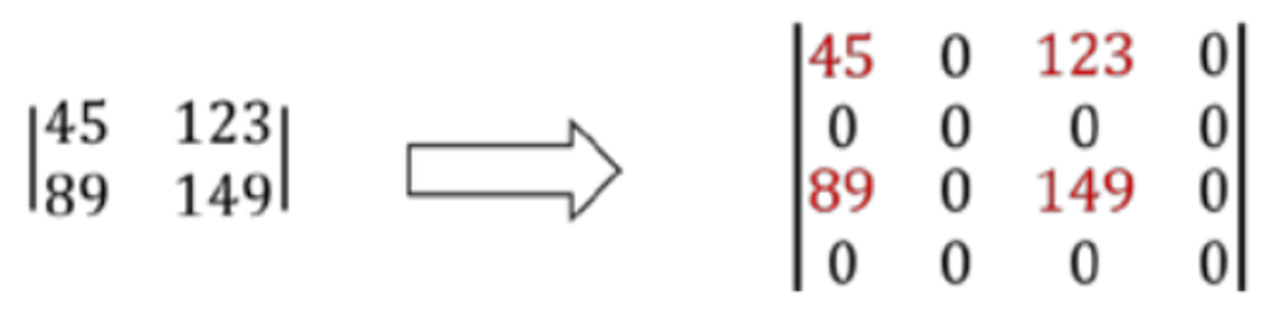
plt.show()当进行两个图像的按位与操作时,实际上是将这两个图像在同一位置上的像素值视为二进制数,然后进行按位与运算。在你的例子中,图像1某个区域的像素值为25,图像2同一区域的像素值为36,我们需要将这两个值转换为二进制形式,然后进行按位与运算。
具体步骤如下:
1. 转换为二进制: - 25的二进制表示为:00011001 - 36的二进制表示为:00100100
2. 按位与运算: - 对应位上的值如果都是1,则结果位上的值为1;否则为0。 - 对于25和36,按位与运算的结果为:00000000(每个位上至少有一个0)
3. 转换回十进制: - 按位与运算的结果00000000转换为十进制为:0 因此,图像1的像素值为25与图像2的像素值为36进行按位与操作的结果为0。