【大模型应用开发 6.LlamaIndex-Workflow】
目录
一、工作流(Workflow)简介
二、TextToSQL工作流设计
1.工作流功能:
2.工作流设计:
三、数据准备
1.遍历目录加载表格
2.生成文字表述
3.将上述表格存入SQLite数据库
四、构建基础工具
1.创建基于表的描述的向量索引
2.创建SQL查询器
3.创建Text2SQL提示词和输出结果解析器
4.创建自然语言回复模板
5.定义工作流
Ⅰ、TableRetrieveEvent 表检索结果事件
Ⅱ、TextToSQLEvent 文本转SQL事件
Ⅲ、初始化工作流
Ⅳ、retrieve_tables 检索相关表
Ⅴ、generate_sql 生成SQL语句
Ⅵ、generate_response 生成最终回答
Ⅶ、工作流执行
6.可视化工作流
7.完整代码
五、工作流管理框架的意义
世界上没有真正的感同身受,但你可以大概的给我讲一讲,因为我有一颗想尽力更懂你一点的心
—— 25.9.3
一、工作流(Workflow)简介
工作流顾名思义是对一系列工作步骤的抽象。
LlamaIndex 的工作流是事件(event)驱动的:
- 工作流由
step组成 - 每个
step处理特定的事件 step也会产生新的事件(交由后继的step进行处理)- 直到产生
StopEvent整个工作流结束
LlamaIndex Workflows:Workflows - LlamaIndex
二、TextToSQL工作流设计
1.工作流功能:
使用自然语言查询数据库,数据库中包含多张表
2.工作流设计:
① 用户输入自然语言查询 ——>
② 系统先去检索跟查询相关的表 ——>
③ 根据表的 Schema 让大模型生成 SQL ——>
④ 用生成的 SQL 查询数据库 ——>
⑤ 根据查询结果,调用大模型生成自然语言回复
三、数据准备
# 下载 WikiTableQuestions
# WikiTableQuestions 是一个为表格问答设计的数据集。其中包含 2,108 个从维基百科提取的 HTML 表格# !wget "https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip" -O wiki_data.zip
# !unzip wiki_data.zip1.遍历目录加载表格
data_dir:定位并表示 CSV 文件所在的目标目录路径,是后续查找 CSV 文件的 “基准目录”。
Path():pathlib 模块的核心类构造函数,用于创建路径对象,表示文件或目录的路径。支持跨平台路径处理(自动适配 Windows 的 \ 和 Unix 的 / 分隔符),提供丰富的路径操作方法(如查找文件、判断路径类型等),比传统的 os.path 模块更直观。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
*pathsegments | str/Path | 否 | 路径片段(可传入多个字符串或 Path 对象,自动拼接为完整路径)。例如 Path("data", "csv", "file.csv") 等价于 data/csv/file.csv(Unix)或 data\csv\file.csv(Windows) |
Path.exists():Python pathlib.Path 类的实例方法,用于检查当前路径对象(Path 对象)所对应的 文件或目录是否实际存在于系统中,返回布尔值 True(存在)或 False(不存在)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
follow_symlinks | bool | 可选参数,控制是否跟随符号链接(软链接): - True(默认):若路径是软链接,检查链接指向的目标文件 / 目录是否存在;- False:仅检查软链接本身是否存在(不关注目标)。 | 否 |
csv_files:存储目标目录下 所有 CSV 文件的完整路径(排序后),是后续循环处理 CSV 文件的 “文件清单”。
sorted():Python 内置函数,用于对可迭代对象(如列表、元组、字典)进行排序,返回一个新的排序后的列表(不修改原对象)。支持自定义排序规则(如按关键字、逆序等)。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
iterable | 可迭代对象 | 是 | 待排序的对象(如列表 [3,1,2]、元组 (3,1,2)、字典 {3: 'a', 1: 'b'} 等) |
key | 函数 | 否 | 排序的关键字函数(对每个元素应用该函数,根据返回值排序)。例如 key=lambda x: x[1] 表示按元素的第二个值排序 |
reverse | bool | 否 | 排序方向(False 表示升序,默认;True 表示降序) |
data_dir.glob():Python 中 pathlib.Path 类的方法(其中 data_dir 是 Path 对象,表示一个目录路径),用于在指定目录中搜索符合特定模式的文件或子目录,返回一个生成器(Generator),包含所有匹配的 Path 对象。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
pattern | str | 无默认值(必需) | 用于匹配文件 / 目录的模式字符串,支持通配符: - *:匹配任意数量的字符(不包含路径分隔符 / 或 \),如 *.csv 匹配所有 CSV 文件;- ?:匹配单个字符,如 file?.txt 匹配 file1.txt、fileA.txt 等;- **:递归匹配所有子目录(需放在路径分隔符之间),如 **/*.txt 匹配当前目录及所有子目录中的 TXT 文件;- [seq]:匹配序列中的任意单个字符,如 file[0-9].csv 匹配 file0.csv 到 file9.csv。 |
dfs:收集所有成功读取的 CSV 文件数据,是批量存储多个 CSV 内容的 “数据容器”。
df:临时存储单个 CSV 文件的内容,是循环中 “单个 CSV 数据的载体”。
pd.read_csv():pandas 库的核心函数,用于读取 CSV(逗号分隔值)文件并将其转换为 DataFrame 数据结构(表格型数据,包含行和列)。支持解析本地文件、网络文件或文件流,是处理结构化文本数据的常用工具。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
filepath_or_buffer | str/pathlib.Path/ 文件流 | 是 | 待读取的 CSV 文件路径(本地路径或 URL)、Path 对象或文件流(如 open() 返回的对象) |
sep | str | 否 | 字段分隔符(默认 ',',逗号),可指定其他分隔符(如 '\t' 表示制表符,';' 表示分号) |
header | int/list/None | 否 | 指定作为列名的行索引(默认 0,即第 1 行作为列名);None 表示无列名,列名会被设为 0,1,2... |
names | list | 否 | 自定义列名列表(当 header=None 时使用,长度需与数据列数一致) |
index_col | int/str/list/None | 否 | 指定作为行索引(index)的列(默认 None,自动生成整数索引);可传入列索引或列名 |
usecols | list/callable | 否 | 仅读取指定列(如 [0, 2] 表示第 1、3 列,['name', 'age'] 表示列名匹配的列) |
skiprows | int/list/callable | 否 | 跳过指定行数(int 表示跳过前 N 行;list 表示跳过指定索引的行;函数返回 True 则跳过该行) |
na_values | scalar/list/dict | 否 | 指定视为缺失值(NaN)的数值(如 ['NA', 'missing'] 表示这些字符串会被解析为缺失值) |
dtype | dict | 否 | 指定列的数据类型(如 {'id': int, 'price': float} 强制 id 列为整数,price 列为浮点数) |
parse_dates | bool/list/dict | 否 | 是否解析日期列(True 尝试解析所有列;list 指定列索引 / 列名;dict 自定义日期格式) |
nrows | int | 否 | 读取的最大行数(用于快速预览大文件,默认读取全部行) |
encoding | str | 否 | 文件编码格式(如 'utf-8'、'gbk',默认自动检测,解决中文乱码问题) |
列表.append():Python 列表(list)的内置方法,用于在列表末尾添加单个元素,并修改原列表(无返回值,直接操作原列表)。是动态扩展列表内容的基础方法。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
object | 任意类型 | 是 | 要添加到列表末尾的元素(可以是字符串、数字、列表、字典等任何 Python 对象) |
str():Python 内置函数,用于将任意对象转换为其字符串表示形式,返回一个新的字符串。适用于类型转换(如数字转字符串)、对象序列化(如自定义类实例转为可读字符串)等场景。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
object | 任意对象 | 否 | 要转换为字符串的对象(若不传入参数,默认返回空字符串 '') |
import pandas as pd
from pathlib import Pathfrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsdata_dir = Path(r"F:\AI_BigModel\appTest4\day4_LlamaIndex\WikiTableQuestions\csv\200-csv")
print("data_dir:", data_dir.exists())
csv_files = sorted([f for f in data_dir.glob("*.csv")])
print("length of csv_files:", len(csv_files))
dfs = []for csv_file in csv_files:print(f"processing file: {csv_file}") # 若打印了此句,说明csv_files非空try:df = pd.read_csv(csv_file)dfs.append(df)except Exception as e:print(f"Error parsing {csv_file}: {str(e)}") # 若有此输出,说明读取失败
print(f"成功读取的CSV文件数量:{len(dfs)}") # 若为0,说明所有文件读取失败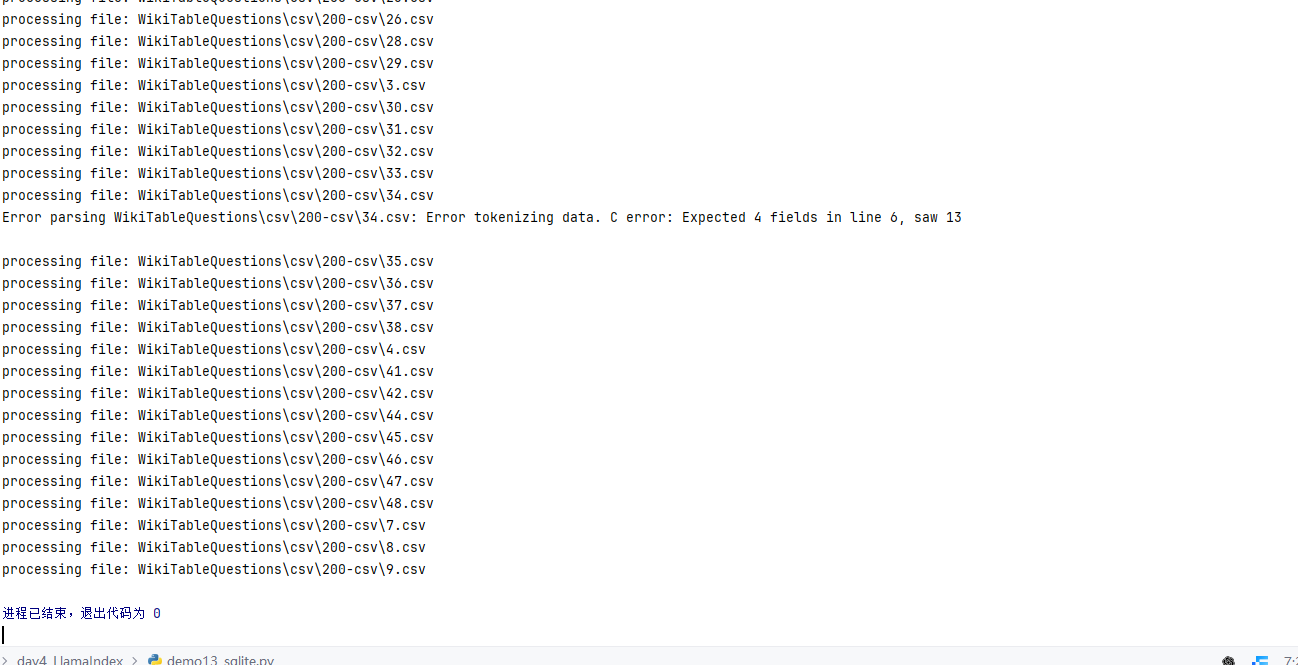
2.生成文字表述
为每个表生成一段文字表述(用于检索),保存在 WikiTableQuestions_TableInfo 目录
# 表格元信息生成代码简化流程
├─ 1. 依赖导入
│ ├─ LlamaIndex核心:ChatPromptTemplate、BaseModel、ChatMessage(提示与结构化定义)
│ └─ 系统工具:json(读写文件)、Path(路径匹配)、pandas(隐含,处理DataFrame)
│
├─ 2. 基础定义
│ ├─ TableInfo类:约束table_name(下划线、唯一)、table_summary(简洁描述)
│ ├─ 提示模板:构建user角色指令,指定JSON输出+表名去重规则
│ ├─ 存储配置:tableinfo_dir目录(存TableInfo的JSON文件)
│ └─ 工具函数:按索引匹配JSON文件,返回TableInfo/None/报错(重复文件)
│
├─ 3. 容器初始化
│ ├─ table_names集合(存已用表名,防重复)
│ └─ table_infos列表(存所有最终TableInfo对象)
│
├─ 4. 核心循环(遍历每个DataFrame)
│ ├─ 查已有元信息:调用工具函数,按索引找已生成的TableInfo
│ ├─ 分支处理:
│ │ ├─ 有已有信息:直接加入table_infos
│ │ └─ 无已有信息:
│ │ ├─ 取DataFrame前10行转CSV(作为大模型输入样本)
│ │ ├─ 大模型生成:调用structured_predict,确保表名唯一(循环重试)
│ │ ├─ 保存结果:生成JSON文件(索引+表名命名)
│ │ └─ 加入table_infos
│ └─ 统一汇总:当前TableInfo追加到table_infos
│
└─ 5. 结果输出 ├─ table_infos列表:含所有DataFrame的元信息 └─ tableinfo_dir目录:生成对应JSON文件(可复用)table_name:TableInfo 类中存储的表的唯一名称,需用下划线且无空格。
Field():在 Pydantic 模型中定义字段,支持数据约束(如数值范围、字符串长度)、默认值配置、别名、描述生成,实现自动数据校验(如输入负数时抛错)和序列化 / 反序列化(如 JSON 转模型)。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| default | Any | 否 | 字段默认值(若未传该参数,字段需显式赋值,否则抛错) |
| default_factory | Callable | 否 | 生成默认值的可调用对象(如lambda: datetime.now(),优先级高于default) |
| alias | str | 否 | 字段别名(序列化 / 反序列化时用,如user_name对应模型中的name) |
| description | str | 否 | 字段描述(用于生成文档或错误提示) |
| gt | Any | 否 | 数值类型专用:要求字段值「大于」该参数(如gt=0表示年龄 > 0) |
| le | Any | 否 | 数值类型专用:要求字段值「小于等于」该参数(如le=150表示年龄≤150) |
| min_length | int | 否 | 字符串 / 列表专用:要求长度≥该值 |
| max_length | int | 否 | 字符串 / 列表专用:要求长度≤该值 |
| regex | str | 否 | 字符串专用:要求匹配指定正则(如regex=r"^1[3-9]\d{9}$"匹配手机号) |
table_summary:TableInfo 类中存储的表的简短、简洁的描述信息。
prompt_str:用于指导 LLM 生成表元信息的文本指令模板,包含格式规则和动态占位符。
prompt_tmpl:由 prompt_str 转换的 ChatPromptTemplate 实例,作为 LLM 的标准化提示对象。
ChatPromptTemplate():构建多轮对话场景的提示模板,支持定义「系统指令、用户输入、助手回复」等角色消息,可动态注入变量(如用户问题、对话历史),适配 ChatGLM、GPT 等聊天模型。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| messages | List[Tuple[str, str]] / List[BaseMessage] | 是 | 消息列表: - 格式 1(简化): (角色, 内容),角色可选system/user/assistant;- 格式 2(完整): [SystemMessage(content="..."), UserMessage(content="...")] |
| input_variables | List[str] | 否 | 模板中的动态变量名(如data_name、user_question),默认自动从messages中提取 |
| template_format | str | 否 | 模板语法格式,默认"f-string"(支持{变量名}),可选"jinja2" |
| validate_template | bool | 否 | 是否验证模板语法(如变量是否存在),默认True(语法错误时抛错) |
ChatMessage.from_str():LlamaIndex ChatMessage 类的静态方法,用于将纯文本字符串转换为结构化的 ChatMessage 对象。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
text | str | 要转换为 ChatMessage 内容的纯文本字符串(如提示模板 prompt_str) | 是 |
role | str | 消息发送者的角色,用于 LLM 区分指令来源,常见取值: - "user":用户指令(默认);- "assistant":助手回复;- "system":系统提示(定义 LLM 行为) | 否(默认值:"user") |
metadata | dict | 可选的消息元数据(如消息 ID、时间戳等),用于附加额外信息,通常无需手动配置 | 否(默认值:None) |
tableinfo_dir:存储表元信息 JSON 文件的目录路径字符串。
results_gen:Path.glob 返回的匹配 {idx}_* 模式的文件路径生成器。
results_list:由 results_gen 转换的文件路径列表,用于判断对应索引的表元信息文件是否存在。
list():Python 内置函数,用于创建空列表,或将可迭代对象(如元组、集合、字符串)转换为列表。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
iterable | 可迭代对象 | 需转换为列表的对象(如 (1,2,3)、"abc") | 否(默认创建空列表 []) |
open():Python 内置函数,用于打开文件并返回文件对象(file object),后续可通过该对象进行读 / 写操作。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
file | str/path | 要打开的文件路径(绝对路径或相对路径) | 是 |
mode | str | 打开模式(如 "r" 只读、"w" 写入、"a" 追加、"rb" 二进制读) | 否(默认 "r") |
encoding | str | 文件编码格式(如 "utf-8"、"gbk",文本模式下有效) | 否(默认依赖系统) |
errors | str | 编码错误处理方式(如 "strict" 报错、"ignore" 忽略) | 否(默认 "strict") |
newline | str | 换行符处理(如 None、"\n"、"\r\n") | 否(默认 None) |
closefd | bool | 是否关闭文件描述符(仅当 file 为文件描述符时生效) | 否(默认 True) |
集合.add():Python 集合(set)的方法,用于向集合中添加单个元素(集合自动去重,重复元素不会被添加)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
element | 任意可哈希类型 | 需添加到集合的元素(如 int、str、tuple) | 是 |
json.load():Python json 库的函数,用于从已打开的 JSON 文件对象中读取内容,并转换为 Python 原生数据类型(如字典、列表)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
fp | 文件对象 | 已通过 open() 打开的 JSON 文件对象(需为可读模式,如 "r") | 是 |
cls | 类 | 自定义解码器类(需继承 json.JSONDecoder,用于解析特殊格式) | 否 |
object_hook | 函数 | 自定义函数,用于将 JSON 对象(dict)转换为自定义 Python 对象 | 否 |
parse_float | 函数 | 自定义函数,用于解析 JSON 中的浮点数(如转换为 decimal.Decimal) | 否 |
parse_int | 函数 | 自定义函数,用于解析 JSON 中的整数(如转换为 int 或 float) | 否 |
parse_constant | 函数 | 自定义函数,用于解析 JSON 中的常量(NaN、Infinity、-Infinity) | 否 |
TableInfo.model_validate():Pydantic 模型(TableInfo 为自定义 Pydantic 类)的方法,用于验证输入数据是否符合模型定义的字段规则,并返回一个 TableInfo 实例(若验证失败则抛出异常)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
obj | dict / 对象 | 需验证的数据(通常为字典,键对应模型字段名,值为待验证数据) | 是 |
context | dict | 验证上下文(用于传递额外配置,如 loc 定位错误位置) | 否 |
strict | bool | 是否严格验证(True 时不允许额外字段,False 时忽略额外字段) | 否(默认 False) |
from_attributes | bool | 是否允许从对象属性而非字典键读取数据(如传入自定义对象时生效) | 否(默认 False) |
ValueError():Python 内置异常类,用于创建 “值错误” 异常实例,当传入的参数类型正确但值不符合预期时抛出(如 int("abc") 会触发 ValueError)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
msg | str | 异常提示信息(描述错误原因) | 否(默认空字符串) |
table_names:存储已生成表名的集合,用于确保表名唯一性。
table_infos:存储所有表的 TableInfo 实例的列表,汇总表的元信息。
df.head():Pandas DataFrame 的方法,用于获取 DataFrame 的前 N 行数据(默认前 5 行),常用于快速预览数据结构。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
n | int | 需返回的行数 | 否(默认 5) |
df.to_csv():Pandas DataFrame 的方法,用于将 DataFrame 数据保存为 CSV 文件,或返回 CSV 格式的字符串。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
path_or_buf | str / 文件对象 | 输出路径(字符串)或已打开的文件对象(若为 None,则返回 CSV 字符串) | 否(默认 None) |
sep | str | CSV 文件的字段分隔符(如 ","、"\t") | 否(默认 ",") |
index | bool | 是否将 DataFrame 的索引(index)写入 CSV 文件 | 否(默认 True) |
header | bool/list | 是否写入列名(True 写入、False 不写入;或传入列表自定义列名) | 否(默认 True) |
encoding | str | 文件编码格式(如 "utf-8"、"gbk") | 否(默认 "utf-8") |
mode | str | 写入模式(如 "w" 覆盖、"a" 追加) | 否(默认 "w") |
llm.structured_predict():LlamaIndex 中 LLM 实例(如 DashScope)的方法,根据指定的结构化输出类(如 TableInfo)和提示模板,生成符合该类字段规则的结构化结果(而非纯文本)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
output_cls | Pydantic 类 | 目标结构化输出类(如 TableInfo,需继承 Pydantic BaseModel) | 是 |
prompt_tmpl | ChatPromptTemplate | 提示模板(定义 LLM 的输入指令格式) | 是 |
**kwargs | 任意类型 | 用于格式化 prompt_tmpl 的动态参数(如 table_str、exclude_table_name_list) | 是(需匹配模板中的变量) |
llm | LLM 实例 | 可选,指定用于生成的 LLM(默认使用当前 llm 实例) | 否 |
.json():根据上下文,通常为 Pydantic 模型实例的方法,用于将模型实例转换为 JSON 格式的字符串(或字典);也可能是 HTTP 响应对象(如 requests.Response)的方法,用于解析响应内容为 Python 数据类型。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
exclude | set/list | 需排除的字段(如 {"id"},不包含该字段在 JSON 中) | 否 |
include | set/list | 需包含的字段(仅包含指定字段在 JSON 中) | 否 |
by_alias | bool | 是否使用字段的 alias(Pydantic 字段定义时的别名)作为 JSON 键 | 否(默认 False) |
indent | int | JSON 字符串的缩进空格数(用于格式化,如 2、4) | 否(默认 None,无缩进) |
ensure_ascii | bool | 是否确保非 ASCII 字符转义(True 转义,False 保留原字符) | 否(默认 True) |
json.dump():Python json 库的函数,用于将 Python 原生数据类型(如字典、列表)写入到已打开的文件对象中,生成 JSON 文件。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
obj | 可序列化对象 | 需写入的 Python 数据(如 dict、list,需符合 JSON 序列化规则) | 是 |
fp | 文件对象 | 已通过 open() 打开的文件对象(需为可写模式,如 "w") | 是 |
cls | 类 | 自定义编码器类(需继承 json.JSONEncoder,用于序列化特殊对象) | 否 |
indent | int | JSON 内容的缩进空格数(用于格式化,如 2、4) | 否(默认 None,无缩进) |
ensure_ascii | bool | 是否确保非 ASCII 字符转义(True 转义,False 保留原字符) | 否(默认 True) |
sort_keys | bool | 是否按字典键(key)排序后写入 | 否(默认 False) |
列表.append():Python 列表(list)的方法,用于将单个元素添加到列表的末尾,列表长度自动加 1。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
item | 任意类型 | 需添加到列表的元素(如 int、str、list、dict) | 是 |
from llama_index.core.prompts import ChatPromptTemplate
from llama_index.core.bridge.pydantic import BaseModel, Field
from llama_index.core.llms import ChatMessageclass TableInfo(BaseModel):"""Information regarding a structured table."""table_name: str = Field(..., description="table name (must be underscores and NO spaces)")table_summary: str = Field(..., description="short, concise summary/caption of the table")prompt_str = """
Give me a summary of the table with the following JSON format.- The table name must be unique to the table and describe it while being concise.
- Do NOT output a generic table name (e.g. table, my_table).Do NOT make the table name one of the following: {exclude_table_name_list}Table:
{table_str}Summary: """prompt_tmpl = ChatPromptTemplate(message_templates=[ChatMessage.from_str(prompt_str, role="user")]
)tableinfo_dir = "WikiTableQuestions_TableInfo"import jsondef _get_tableinfo_with_index(idx: int) -> str:results_gen = Path(tableinfo_dir).glob(f"{idx}_*")results_list = list(results_gen)if len(results_list) == 0:return Noneelif len(results_list) == 1:path = results_list[0]with open(path, 'r') as file:data = json.load(file) return TableInfo.model_validate(data)else:raise ValueError(f"More than one file matching index: {list(results_gen)}")table_names = set()
table_infos = []
for idx, df in enumerate(dfs):table_info = _get_tableinfo_with_index(idx)if table_info:table_infos.append(table_info)else:while True:df_str = df.head(10).to_csv()table_info = llm.structured_predict(TableInfo,prompt_tmpl,table_str=df_str,exclude_table_name_list=str(list(table_names)),)table_name = table_info.table_nameprint(f"Processed table: {table_name}")if table_name not in table_names:table_names.add(table_name)breakelse:# try againprint(f"Table name {table_name} already exists, trying again.")passout_file = f"{tableinfo_dir}/{idx}_{table_name}.json"json.dump(table_info.dict(), open(out_file, "w"))table_infos.append(table_info)3.将上述表格存入SQLite数据库
# SQLite数据库写入代码简洁流程
├─ 1. 依赖导入
│ ├─ SQLAlchemy:create_engine(连库)、MetaData(管表结构)、Table/Column(定义表/字段)、String/Integer(字段类型)
│ └─ re(清洗列名)、pandas(隐含,处理DataFrame)
│
├─ 2. 工具函数
│ ├─ sanitize_column_name:特殊字符/空格转下划线(如“user name”→“user_name”)
│ └─ create_table_from_dataframe:
│ 1. 清洗df列名 → 2. 按df数据类型定SQL字段(object→String,其他→Integer)
│ 3. 建表(不存在则创建) → 4. 逐行插df数据到表,提交事务
│
├─ 3. 数据库配置
│ ├─ 创SQLite引擎:连接/创建wiki_table_questions.db(当前目录)
│ └─ 初始化元数据:MetaData()(管所有表结构)
│
├─ 4. 核心循环(遍历df)
│ ├─ 取表信息:_get_tableinfo_with_index(idx)→获合法表名
│ ├─ 打印日志:“Creating table: 表名”
│ └─ 执行写入:调用create_table_from_dataframe(df→数据库表)
│
└─ 5. 结果 └─ 生成wiki_table_questions.db,含N张表(N=df数量),表名/字段/数据与df匹配col_name:DataFrame 中原始的列名(可能包含特殊字符或空格),需要被清理为符合数据库命名规则的格式。
re.sub():Python re 模块的函数,用于根据正则表达式模式(pattern)在字符串中查找匹配项,并替换为指定内容(repl),返回替换后的新字符串。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
pattern | str / 正则对象 | 用于匹配的正则表达式模式(如 r"\W+" 匹配非单词字符) | 是 |
repl | str / 函数 | 替换内容: - 字符串:直接替换匹配项; - 函数:接收匹配对象,返回替换字符串 | 是 |
string | str | 被处理的原始字符串 | 是 |
count | int | 最大替换次数(默认 0 表示替换所有匹配项) | 否 |
flags | int | 正则匹配标志(如 re.IGNORECASE 忽略大小写) | 否 |
df:需要被写入数据库的 pandas 数据框,包含待存储的表格数据。
table_name:要在数据库中创建的表的名称(来自 tableinfo.table_name,即之前生成的唯一表名)。
engine: create_engine 创建的 SQLAlchemy 引擎对象,封装了数据库连接信息(此处连接 sqlite:///wiki_table_questions.db 数据库),是与数据库交互的核心通道。
metadata_obj:集中管理数据库的元数据(如表结构、列定义等),所有表的创建都会关联到该对象,便于统一维护表结构。
sanitized_columns:字典,键为 DataFrame 原始列名,值为经过 sanitize_column_name 清理后的列名(去除特殊字符、空格替换为下划线),用于后续重命名 DataFrame 列。
df.columns:DataFrame 的属性,返回包含所有列名的索引对象(如 Index(['name', 'age', ...]),用于遍历获取原始列名并进行清理。
df.rename():用于重命名 DataFrame 的列名或索引(index),返回重命名后的新 DataFrame(默认不修改原数据)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
mapper | dict / 函数 | 用于重命名的映射关系: - 字典: {旧名: 新名}(针对列或索引);- 函数:对每个名称进行转换 | 否 |
index | dict / 函数 | 专门用于重命名索引(优先级高于 mapper) | 否 |
columns | dict / 函数 | 专门用于重命名列名(优先级高于 mapper) | 否 |
inplace | bool | 是否直接修改原 DataFrame(True 不返回新对象,False 返回新对象) | 否(默认 False) |
level | int/str | 若索引是多层索引,指定要重命名的层级 | 否 |
Column():SQLAlchemy 中用于定义数据库表中 “列” 的类,指定列名、数据类型及约束(如主键、非空等)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
name | str | 列名(数据库中实际的列名称) | 是 |
type_ | SQLAlchemy 类型 | 列的数据类型(如 String、Integer、Float) | 是 |
primary_key | bool | 是否为主键(True 表示该列是主键) | 否(默认 False) |
nullable | bool | 是否允许为空(False 表示非空约束) | 否(默认 True) |
default | 任意类型 / 函数 | 列的默认值(可直接传值或调用函数生成) | 否 |
autoincrement | bool/str | 是否自增(True 或 "auto" 表示自增,仅适用于整数类型) | 否 |
zip():将多个可迭代对象(如列表、元组)中对应位置的元素打包成一个个元组,返回一个 zip 迭代器;若可迭代对象长度不同,以最短的为准。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
iterable1, iterable2, ... | 可迭代对象 | 需打包的多个可迭代对象(如列表、元组) | 是(至少一个) |
df.dtypes:DataFrame 的属性,返回每列的数据类型(如 object、int64 等),用于动态决定数据库表中对应列的类型(String 或 Integer)。
table:通过 Table(table_name, metadata_obj, *columns) 创建,定义了数据库表的结构(包含表名、关联的元数据、列定义),是后续创建表和插入数据的基础。
Table():SQLAlchemy 中用于定义数据库表结构的类,关联表名、元数据(MetaData)及列(Column 实例)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
name | str | 表名(数据库中实际的表名称) | 是 |
metadata | MetaData 实例 | 关联的元数据对象(用于管理表结构) | 是 |
*columns | Column 实例 | 表中包含的列(多个 Column 实例,用逗号分隔) | 是(至少一列) |
schema | str | 表所在的数据库 schema(如 PostgreSQL 中的 schema,默认 public) | 否 |
extend_existing | bool | 若表已存在,是否扩展其结构(添加新列) | 否(默认 False) |
create_engine():创建数据库连接引擎(Engine 实例),封装数据库连接信息,是 SQLAlchemy 与数据库交互的入口。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
url | str | 数据库连接 URL(格式:dialect+driver://user:password@host:port/dbname,如 sqlite:///test.db) | 是 |
echo | bool | 是否打印 SQL 执行日志(True 用于调试) | 否(默认 False) |
pool_size | int | 连接池大小(默认 5) | 否 |
max_overflow | int | 连接池允许的临时额外连接数(默认 10) | 否 |
pool_recycle | int | 连接超时回收时间(秒,默认 -1 表示不回收) | 否 |
Metadata():SQLAlchemy 中的元数据容器类,用于集中存储和管理数据库中的所有结构信息(如表、列、索引、外键等)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
bind | Engine 实例 | 关联的数据库引擎(可选,用于默认连接) | 否 |
schema | str | 默认的数据库 schema(适用于支持 schema 的数据库,如 PostgreSQL) | 否 |
engine.connect():从数据库引擎(Engine)获取一个 数据库连接对象(Connection),用于执行 SQL 语句、管理事务(提交 / 回滚)等数据库交互操作。连接对象是与数据库通信的直接通道,所有具体操作(如查询、插入)都通过它完成。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
close_with_result | bool | 若为 True,连接会在关联的结果对象(Result)关闭时自动关闭;默认 False | 否 |
echo | bool | 是否在当前连接中打印 SQL 执行日志(覆盖引擎的全局 echo 设置) | 否 |
execution_options | dict | 执行选项(如 isolation_level 事务隔离级别) | 否 |
engine.connect().execute():通过连接对象执行 SQL 语句或 SQLAlchemy 表达式(如 select()、insert()),返回一个 结果对象(Result),包含查询结果或执行状态(如影响行数)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
statement | str/ClauseElement | 要执行的内容: - 字符串:原始 SQL 语句(如 "SELECT * FROM users");- SQLAlchemy 表达式:如 table.insert().values(...)、select([table]) | 是 |
parameters | dict/tuple/list | 可选参数,用于参数化查询(防止 SQL 注入),如 {"name": "Alice"} | 否 |
engine.connect().commit():提交当前连接中的 事务(Transaction),将之前通过 execute() 执行的写操作(如插入、更新、删除)永久保存到数据库。若不调用 commit(),事务会在连接关闭时自动回滚,所有操作不会生效。
enumerate():遍历可迭代对象时,同时返回元素的索引和值,返回一个 enumerate 迭代器,格式为 (index, value)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
iterable | 可迭代对象 | 需遍历的对象(如列表、字符串) | 是 |
start | int | 索引的起始值(默认 0) | 否 |
# put data into sqlite db
from sqlalchemy import (create_engine,
# SQLAlchemy 中用于创建数据库连接引擎的核心函数,通过指定数据库 URL(如 sqlite:///test.db、mysql+pymysql://user:pass@host/db)初始化与数据库的连接通道,后续数据库操作(如查询、写入)均基于此引擎。MetaData,
# SQLAlchemy 的数据库元数据容器类,用于集中存储和管理数据库中的结构信息(如表、列、索引、外键等)。通过它可以统一创建、修改或查询数据库表结构,避免分散管理表定义。Table,
# 用于定义数据库表结构的类,需指定表名、关联的 MetaData 对象,以及表中的列(Column 实例)和其他属性(如主键、表注释等),是映射 “Python 类” 与 “数据库表” 的核心载体。Column,
# 用于定义数据库表中 “列” 的类,需指定列名、数据类型(如 String、Integer),还可配置列的约束(如主键 primary_key=True、非空 nullable=False、默认值 default=xxx 等),对应数据库表的列结构。String,
# SQLAlchemy 提供的字符串类型类,映射到数据库中的字符串类型(如 MySQL 的 VARCHAR、SQLite 的 TEXT),可通过参数指定长度(如 String(50) 表示最大长度 50)。Integer,
# SQLAlchemy 提供的整数类型类,映射到数据库中的整数类型(如 MySQL 的 INT、PostgreSQL 的 INTEGER),用于存储整数型数据(如 ID、数量等)。
)
import re# Function to create a sanitized column name
def sanitize_column_name(col_name):# Remove special characters and replace spaces with underscoresreturn re.sub(r"\W+", "_", col_name)# Function to create a table from a DataFrame using SQLAlchemy
def create_table_from_dataframe(df: pd.DataFrame, table_name: str, engine, metadata_obj):# Sanitize column namessanitized_columns = {col: sanitize_column_name(col) for col in df.columns}df = df.rename(columns=sanitized_columns)# Dynamically create columns based on DataFrame columns and data typescolumns = [Column(col, String if dtype == "object" else Integer)for col, dtype in zip(df.columns, df.dtypes)]# Create a table with the defined columnstable = Table(table_name, metadata_obj, *columns)# Create the table in the databasemetadata_obj.create_all(engine)# Insert data from DataFrame into the tablewith engine.connect() as conn:for _, row in df.iterrows():insert_stmt = table.insert().values(**row.to_dict())conn.execute(insert_stmt)conn.commit()# engine = create_engine("sqlite:///:memory:")
engine = create_engine("sqlite:///wiki_table_questions.db")
metadata_obj = MetaData()
for idx, df in enumerate(dfs):tableinfo = _get_tableinfo_with_index(idx)print(f"Creating table: {tableinfo.table_name}")create_table_from_dataframe(df, tableinfo.table_name, engine, metadata_obj)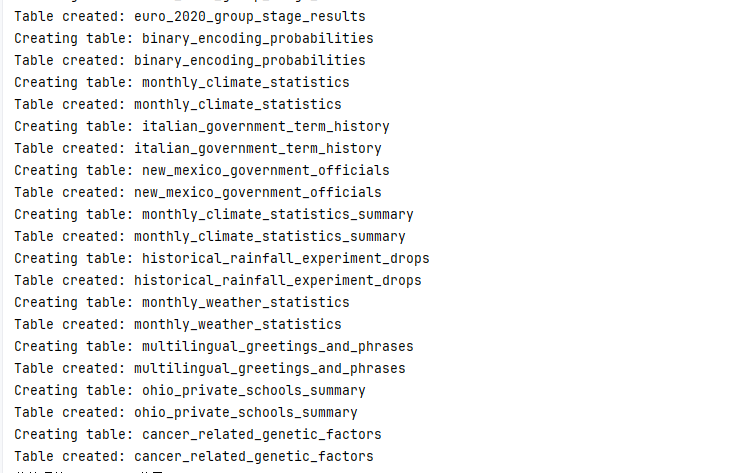
四、构建基础工具
1.创建基于表的描述的向量索引
ObjectIndex是一个 LlamaIndex 内置的模块,通过索引 (Index)检索任意 Python 对象- 这里我们使用
VectorStoreIndex也就是向量检索,并通过SQLTableNodeMapping将文本描述的node和数据库的表形成映射 - 相关文档:The Class - LlamaIndex
# 代码执行流程树形流程图
```
代码入口
├─ 1. 导入依赖模块
│ ├─ 1.1 系统基础模块:os(用于读取环境变量API_KEY)
│ ├─ 1.2 LlamaIndex核心模块:Settings、SQLDatabase、VectorStoreIndex
│ ├─ 1.3 LlamaIndex LLM模块:DashScope(大语言模型类)、DashScopeGenerationModels(模型枚举,如QWEN_MAX)
│ ├─ 1.4 LlamaIndex嵌入模块:DashScopeEmbedding(嵌入模型类)、DashScopeTextEmbeddingModels(嵌入模型枚举,如TEXT_EMBEDDING_V1)
│ └─ 1.5 LlamaIndex表对象模块:SQLTableNodeMapping(表→索引节点映射器)、ObjectIndex(表元信息向量索引)、SQLTableSchema(表结构描述类)
│
├─ 2. 全局模型配置(基于LlamaIndex的Settings)
│ ├─ 2.1 配置全局LLM
│ │ ├─ 输入1:模型名称(DashScopeGenerationModels.QWEN_MAX)
│ │ ├─ 输入2:API密钥(从环境变量os.getenv("DASHSCOPE_API_KEY")读取)
│ │ └─ 输出:Settings.llm(全局默认大语言模型实例)
│ └─ 2.2 配置全局嵌入模型
│ ├─ 输入1:模型名称(DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)
│ └─ 输出:Settings.embed_model(全局默认文本嵌入模型实例)
│
├─ 3. 初始化SQL数据库交互对象(SQLDatabase)
│ ├─ 输入:外部已创建的SQLAlchemy engine(如之前代码中的sqlite:///wiki_table_questions.db引擎)
│ └─ 输出:sql_database(LlamaIndex封装的SQL数据库交互对象,提供表结构查询、SQL执行等能力)
│
├─ 4. 构建表元信息核心组件
│ ├─ 4.1 生成表结构描述列表(table_schema_objs)
│ │ ├─ 输入:外部table_infos列表(含每张表的table_name和table_summary)
│ │ └─ 输出:SQLTableSchema实例列表(每个实例对应一张表,存储表名和表描述)
│ └─ 4.2 创建表元信息→索引节点映射器(table_node_mapping)
│ ├─ 输入:sql_database(依赖其获取表的底层结构信息)
│ └─ 输出:table_node_mapping(SQLTableNodeMapping实例,用于将SQLTableSchema转换为索引节点Node)
│
├─ 5. 构建表元信息向量索引(ObjectIndex)
│ ├─ 输入1:table_schema_objs(待索引的表元信息列表)
│ ├─ 输入2:table_node_mapping(表元信息→Node的映射器)
│ ├─ 输入3:VectorStoreIndex(底层向量索引类型,用于存储表元信息的嵌入向量)
│ └─ 输出:obj_index(ObjectIndex实例,存储所有表元信息的向量,支持相似度检索)
│
└─ 6. 创建表元信息检索器(obj_retriever)├─ 输入:obj_index(表元信息向量索引)├─ 配置:similarity_top_k=3(检索时返回与查询最相似的前3张表)└─ 输出:obj_retriever(Retriever实例,用于根据用户查询检索相关表元信息)
```Settings.llm:LlamaIndex 全局配置类 Settings 中的 “默认大语言模型(LLM)” 字段,存储 DashScope 实例(调用阿里云 DashScope 平台的 QWEN_MAX 模型)。
DashScope():LlamaIndex 中封装阿里云 DashScope 大语言模型的类,用于初始化 DashScope LLM 实例,支持文本生成、结构化输出等操作。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
model_name | str/DashScopeGenerationModels | 模型名称(如 DashScopeGenerationModels.QWEN_MAX、"qwen-max") | 是 |
api_key | str | DashScope 平台 API 密钥(用于身份验证,若环境变量已配置可省略) | 否(默认读取环境变量 DASHSCOPE_API_KEY) |
timeout | int | API 调用超时时间(单位:秒) | 否(默认 60) |
temperature | float | 生成文本的随机性(0~1,值越高越随机,0 为确定性输出) | 否(默认 0.7) |
max_tokens | int | 生成文本的最大 token 数 | 否(默认根据模型限制) |
Settings.embed_model:LlamaIndex 全局配置类 Settings 中的 “默认文本嵌入模型” 字段,存储 DashScopeEmbedding 实例(调用阿里云 DashScope 平台的 TEXT_EMBEDDING_V1 模型)。
DashScopeEmbedding():LlamaIndex 中封装阿里云 DashScope 文本嵌入模型的类,用于初始化嵌入模型实例,将文本转换为向量表示。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
model_name | str/DashScopeTextEmbeddingModels | 嵌入模型名称(如 DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1) | 否(默认 TEXT_EMBEDDING_V1) |
api_key | str | DashScope 平台 API 密钥(用于身份验证,若环境变量已配置可省略) | 否(默认读取环境变量 DASHSCOPE_API_KEY) |
timeout | int | API 调用超时时间(单位:秒) | 否(默认 60) |
batch_size | int | 批量处理文本的数量(一次调用处理的文本条数,默认 32) | 否 |
sql_database:LlamaIndex SQLDatabase 类的实例,是对 SQLAlchemy engine(数据库连接引擎)的 “封装对象”。
SQLDatabase():LlamaIndex 类,封装 SQL 数据库连接,提供获取表信息、执行 SQL 查询等基础操作,为 SQL 检索(SQLRetriever)提供底层支持。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
engine | SQLAlchemy Engine | SQLAlchemy 的 Engine 实例(封装数据库连接信息,如 SQLite、MySQL 连接) | 是 |
include_tables | list | 需包含的表名列表(仅处理这些表,默认包含所有表) | 否 |
exclude_tables | list | 需排除的表名列表(不处理这些表) | 否 |
view_support | bool | 是否支持数据库视图(True 时将视图视为表处理) | 否(默认 False) |
table_node_mapping:LlamaIndex SQLTableNodeMapping 类的实例,是 “SQL 表元信息” 与 “LlamaIndex 索引节点(Node)” 的映射器。
SQLTableNodeMapping():LlamaIndex 类,用于建立 SQL 表(SQLTableSchema)与索引节点(Node)的映射关系,将 SQL 表信息转换为可被 ObjectIndex 索引的节点。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
sql_database | SQLDatabase | SQLDatabase 实例(封装了数据库连接,用于获取表的元数据) | 是 |
node_parser | NodeParser | 节点解析器(用于将表信息分割为节点,默认无需额外配置) | 否 |
table_schema_objs:SQLTableSchema 实例的列表,每个实例对应一个数据库表,存储该表的 “核心元信息”。 context_str=t.table_sum
SQLTableSchema():LlamaIndex 类,用于定义 SQL 表的结构化 schema 信息,包含表名和表描述,供后续 SQL 检索时识别表的用途。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
table_name | str | SQL 表的实际名称(需与数据库中表名完全一致) | 是 |
context_str | str | 表的描述信息(如 “存储用户订单数据,包含订单号、金额、日期字段”) | 否(默认空字符串) |
schema | str | 表所在的数据库 schema(如 PostgreSQL 中的 schema,默认 public) | 否 |
obj_index:LlamaIndex ObjectIndex 类的实例,是 “SQL 表元信息的向量索引”,底层基于 VectorStoreIndex 实现。
ObjectIndex.from_objects():LlamaIndex ObjectIndex 类的静态方法,用于从一组结构化对象(如 SQLTableSchema)创建 ObjectIndex 实例,实现对象的索引化存储和后续检索。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
objects | list | 需索引的结构化对象列表(如 [SQLTableSchema1, SQLTableSchema2]) | 是 |
object_node_mapping | ObjectNodeMapping | 对象 - 节点映射器(如 SQLTableNodeMapping,用于将对象转换为索引节点) | 是 |
index_cls | 索引类 | 底层索引类型(如 VectorStoreIndex,用于存储对象的向量表示) | 是 |
embed_model | Embeddings | 嵌入模型(用于生成对象的向量,若 index_cls 需向量则必填) | 否(默认使用全局 Settings.embed_model) |
**kwargs | 任意类型 | 传递给 index_cls 的额外参数(如 vector_store 指定向量数据库) | 否 |
obj_retriever:ObjectIndex 转换而来的 “表元信息检索器”,属于 LlamaIndex Retriever 类的实例。
obj_index.as_retriever():LlamaIndex ObjectIndex 实例的方法,将 ObjectIndex(存储结构化对象如 SQLTableSchema 的索引)转换为检索器(Retriever),用于根据查询检索相关的对象。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
search_type | str | 检索类型(如 "similarity" 相似度检索、"mmr" 最大边际相关性检索) | 否(默认 "similarity") |
search_kwargs | dict | 检索参数(如 similarity_top_k=3 控制返回结果数量、filter 过滤条件) | 否 |
retriever_cls | 检索器类 | 自定义检索器类(需继承 BaseRetriever) | 否 |
import os
from llama_index.core import Settings
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
from llama_index.core.objects import (SQLTableNodeMapping,ObjectIndex,SQLTableSchema,
)
from llama_index.core import SQLDatabase, VectorStoreIndex# 设置全局模型
Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))
Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)sql_database = SQLDatabase(engine)table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [SQLTableSchema(table_name=t.table_name, context_str=t.table_summary)for t in table_infos
] # add a SQLTableSchema for each tableobj_index = ObjectIndex.from_objects(table_schema_objs,table_node_mapping,VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)2.创建SQL查询器
```markdown
# 代码执行流程树形流程图
```
代码入口
├─ 1. 导入依赖模块
│ ├─ 1.1 LlamaIndex检索器模块:SQLRetriever(用于执行SQL查询并返回结果的检索器类)
│ └─ 1.2 类型提示模块:typing.List(用于定义函数参数的列表类型,指定元素为SQLTableSchema)
│
├─ 2. 初始化SQL执行检索器(sql_retriever)
│ ├─ 输入:外部已创建的sql_database(LlamaIndex封装的SQL数据库交互对象,含数据库连接能力)
│ └─ 输出:sql_retriever(SQLRetriever实例,核心功能是接收SQL语句、执行数据库查询并返回结果)
│
└─ 3. 定义表上下文字符串生成函数(get_table_context_str)├─ 3.1 函数基础定义│ ├─ 函数名:get_table_context_str│ ├─ 参数:table_schema_objs(List[SQLTableSchema]类型,存储待处理的表元信息列表,每个元素含table_name和context_str)│ └─ 功能描述:将输入的表元信息列表转换为包含表结构+表描述的统一字符串│├─ 3.2 函数内部执行逻辑│ ├─ 3.2.1 初始化空列表(context_strs)│ │ └─ 用途:存储每张表的格式化上下文信息(表结构+可选描述)│ ││ ├─ 3.2.2 循环遍历表元信息(for table_schema_obj in table_schema_objs)│ │ ├─ 步骤1:获取单表结构信息(table_info)│ │ │ ├─ 输入:table_schema_obj.table_name(当前表的名称)│ │ │ ├─ 调用方法:sql_database.get_single_table_info()(通过数据库交互对象获取表的字段、类型等结构信息)│ │ │ └─ 输出:table_info(单表结构信息字符串,如“CREATE TABLE ...”格式)│ │ ││ │ ├─ 步骤2:判断并拼接表描述(若存在context_str)│ │ │ ├─ 条件:table_schema_obj.context_str不为空(当前表有描述信息)│ │ │ ├─ 操作1:创建表描述格式化字符串(table_opt_context)│ │ │ │ └─ 内容:" The table description is: " + table_schema_obj.context_str(包装表描述文本)│ │ │ ├─ 操作2:拼接表结构与表描述│ │ │ │ └─ 结果:table_info = 原table_info + table_opt_context(形成单表完整上下文)│ │ │ └─ 条件不满足:直接使用原table_info(仅含表结构)│ │ ││ │ └─ 步骤3:添加单表上下文到列表│ │ └─ 操作:context_strs.append(table_info)(将当前表的完整上下文存入列表)│ ││ └─ 3.2.3 合并列表为最终字符串│ ├─ 操作:"\n\n".join(context_strs)(用两个换行符分隔列表中各表的上下文,提升可读性)│ └─ 输出:合并后的统一字符串(含所有表的结构+描述信息,供后续LLM生成SQL时参考)│└─ 3.3 函数返回值└─ 最终输出:3.2.3步骤生成的“多表上下文统一字符串”
```
```sql_retriever:LlamaIndex SQLRetriever 类的实例,是 “执行 SQL 查询并返回结果” 的检索器对象。接收 SQL 语句(如 llm 生成的 sql),执行查询并返回数据库结果(如匹配的行数据),是后续 “SQL 执行→结果汇总” 流程的核心组件
SQLRetriever():LlamaIndex 类,用于从 SQLDatabase 中执行 SQL 查询并返回结果,支持结合 LLM 优化查询逻辑(如补全 SQL 语法)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
sql_database | SQLDatabase | SQLDatabase 实例(封装数据库连接,用于执行查询) | 是 |
llm | LLM 实例 | LLM 实例(用于优化 SQL 查询,如修复语法错误、补充字段) | 否(默认使用全局 Settings.llm) |
return_raw | bool | 是否返回原始查询结果(True 返回复合列表,False 返回格式化字符串) | 否(默认 False) |
max_results | int | 最大返回结果条数(限制查询结果数量) | 否(默认无限制) |
context_strs:空列表,用于存储每个表的 “格式化上下文字符串”。收集所有目标表的上下文信息,便于后续传递给 LLM(如生成 SQL 时,LLM 需通过该上下文理解表结构和用途)。
table_schema_objs:类型为 List[SQLTableSchema](SQLTableSchema 实例的列表),每个实例对应一个数据库表的 “核心元信息”。为函数提供 “待处理的表元信息列表”,函数通过它获取每个表的名称(table_schema_obj.table_name)和描述(table_schema_obj.context_str),进而生成表的完整上下文。
sql_database.get_single_table_info():LlamaIndex SQLDatabase 实例的方法,用于获取数据库中单个表的元信息(如字段名、字段类型、主键等),返回格式化的字符串。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
table_name | str | 目标表的名称(需与数据库中表名完全一致,区分大小写) | 是 |
include_schema | bool | 是否包含表的 schema 信息(如字段类型、约束) | 否(默认 True) |
table_schema_obj.context_str:存储对应表的简短描述信息。作为表的 “补充说明”,与表结构信息(table_info)合并后,帮助 LLM 理解表的用途(避免仅靠表结构无法判断表含义,导致生成错误 SQL)。
table_opt_context:将表描述(context_str)转换为更易读的格式,与表结构信息(table_info)合并,形成完整的表上下文(如 table_info + table_opt_context)。
table_info:提供表的 “底层结构信息”,与可选的表描述(table_opt_context)合并后,形成该表的完整上下文(table_info + table_opt_context)。
列表.append():Python 列表(list)的方法,用于将单个元素添加到列表的末尾,列表长度自动加 1。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
item | 任意类型 | 需添加到列表的元素(如 int、str、list、dict) | 是 |
str.join():Python 字符串(str)的方法,用于将可迭代对象(如列表、元组)中的元素用当前字符串连接,返回一个新字符串。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
iterable | 可迭代对象 | 需连接的元素集合(元素必须为字符串类型,或可隐式转换为字符串) | 是 |
from llama_index.core.retrievers import SQLRetriever
from typing import Listsql_retriever = SQLRetriever(sql_database)def get_table_context_str(table_schema_objs: List[SQLTableSchema]):"""Get table context string."""context_strs = []for table_schema_obj in table_schema_objs:table_info = sql_database.get_single_table_info(table_schema_obj.table_name)if table_schema_obj.context_str:table_opt_context = " The table description is: "table_opt_context += table_schema_obj.context_strtable_info += table_opt_contextcontext_strs.append(table_info)return "\n\n".join(context_strs)3.创建Text2SQL提示词和输出结果解析器
# 代码执行流程树形流程图
```
代码入口
├─ 1. 导入依赖模块
│ ├─ 1.1 LlamaIndex默认提示模板:DEFAULT_TEXT_TO_SQL_PROMPT(内置的文本转SQL基础提示模板,含生成SQL的指令逻辑)
│ ├─ 1.2 LlamaIndex提示模板类:PromptTemplate(用于创建/处理标准化提示模板的核心类)
│ └─ 1.3 LlamaIndex LLM响应类:ChatResponse(封装LLM聊天响应的对象类,含message.content等核心属性)
│
├─ 2. 定义SQL提取函数(parse_response_to_sql)
│ ├─ 2.1 函数基础定义
│ │ ├─ 函数名:parse_response_to_sql
│ │ ├─ 输入参数:chat_response(ChatResponse类型,LLM返回的原始响应对象)
│ │ ├─ 返回值:str类型(提取并清理后的纯SQL语句)
│ │ └─ 功能描述:从LLM的原始响应中提取有效SQL,剔除无关文本(如说明、模拟结果)
│ │
│ ├─ 2.2 函数内部执行逻辑
│ │ ├─ 步骤1:获取LLM原始响应文本
│ │ │ ├─ 操作:从chat_response.message.content中读取LLM输出的纯文本
│ │ │ └─ 输出:response(存储LLM原始响应文本的局部变量)
│ │ │
│ │ ├─ 步骤2:定位并截取"SQLQuery:"后的内容(保留SQL起始部分)
│ │ │ ├─ 子步骤1:查找"SQLQuery:"的起始索引(sql_query_start)
│ │ │ │ ├─ 操作:response.find("SQLQuery:"),返回子串索引(-1表示未找到)
│ │ │ │ └─ 输出:sql_query_start(索引值)
│ │ │ ├─ 子步骤2:若找到"SQLQuery:",截取后续内容
│ │ │ │ ├─ 条件:sql_query_start != -1(存在"SQLQuery:"标记)
│ │ │ │ ├─ 操作1:response = response[sql_query_start:](从标记处截取到字符串末尾)
│ │ │ │ ├─ 操作2:若截取后字符串以"SQLQuery:"开头,再剔除该标记(response = response[len("SQLQuery:"):])
│ │ │ │ └─ 输出:response(仅保留"SQLQuery:"后的内容)
│ │ │ └─ 条件不满足:response保持原始值(无"SQLQuery:"时不处理)
│ │ │
│ │ ├─ 步骤3:定位并截取"SQLResult:"前的内容(剔除SQL后续无关文本)
│ │ │ ├─ 子步骤1:查找"SQLResult:"的起始索引(sql_result_start)
│ │ │ │ ├─ 操作:response.find("SQLResult:"),返回子串索引(-1表示未找到)
│ │ │ │ └─ 输出:sql_result_start(索引值)
│ │ │ ├─ 子步骤2:若找到"SQLResult:",截取前序内容
│ │ │ │ ├─ 条件:sql_result_start != -1(存在"SQLResult:"标记)
│ │ │ │ ├─ 操作:response = response[:sql_result_start](从字符串开头截取到标记前)
│ │ │ │ └─ 输出:response(剔除"SQLResult:"及后续内容)
│ │ │ └─ 条件不满足:response保持步骤2处理后的值
│ │ │
│ │ └─ 步骤4:清理字符串并返回纯SQL
│ │ ├─ 操作:response.strip().strip("```").strip()(先去首尾空格,再剔除代码块标记```,最后再去空格)
│ │ └─ 输出:清理后的纯SQL语句(函数返回值)
│ │
│ └─ 2.3 函数最终输出:步骤4生成的纯SQL字符串
│
├─ 3. 创建预填充文本转SQL提示模板(text2sql_prompt)
│ ├─ 输入1:DEFAULT_TEXT_TO_SQL_PROMPT(基础文本转SQL模板)
│ ├─ 输入2:dialect参数值(来自外部engine.dialect.name,即当前数据库方言,如sqlite、mysql)
│ ├─ 核心操作:调用DEFAULT_TEXT_TO_SQL_PROMPT.partial_format()方法,预填充模板中的{dialect}占位符
│ └─ 输出:text2sql_prompt(PromptTemplate实例,含预填充方言的文本转SQL提示模板)
│
└─ 4. 打印提示模板的原始字符串(text2sql_prompt.template)├─ 操作:访问text2sql_prompt的template属性,获取填充方言后的模板纯文本└─ 输出:在控制台打印模板字符串(如含"dialect: sqlite"的文本转SQL指令,便于调试验证模板格式)
```response:存储 LLM 生成的 “原始文本内容”(字符串类型)。
chat_response.message.content:存储 LLM 生成的 “最终纯文本输出”。
sql_query_start:存储字符串 SQLQuery: 在 response 中的 “起始索引”(整数类型,未找到则为 -1)。定位 SQL 语句的 “开始位置”—— 若找到 SQLQuery:,则从该索引后截取内容,剔除 LLM 输出中 SQL 之前的多余文本。
str.find():Python 字符串(str)的方法,用于在字符串中查找子串的第一个匹配位置,返回子串的起始索引;若未找到则返回 -1。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
sub | str | 需查找的子串 | 是 |
start | int | 查找的起始位置(索引,默认从 0 开始) | 否(默认 0) |
end | int | 查找的结束位置(索引,默认到字符串末尾) | 否(默认 len(str)) |
str.startswith():Python 字符串(str)的方法,判断字符串是否以指定的前缀(子串)开头,返回 True 或 False。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
prefix | str/tuple | 前缀(可传入单个字符串,或多个字符串组成的元组,匹配任一即返回 True) | 是 |
start | int | 检查的起始位置(索引) | 否(默认 0) |
end | int | 检查的结束位置(索引) | 否(默认 len(str)) |
sql_result_start:存储字符串 SQLResult: 在 response 中的 “起始索引”(整数类型,未找到则为 -1)。定位 SQL 语句的 “结束位置”—— 若找到 SQLResult:,则截取到该索引前的内容,剔除 LLM 输出中 SQL 之后的模拟结果说明(避免将非 SQL 内容纳入最终执行语句)。
str.strip():Python 字符串(str)的方法,用于去除字符串首尾的指定字符(默认去除空格、换行符 \n、制表符 \t 等空白字符),返回新字符串。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
chars | str | 需去除的字符集合(如 "!@#" 去除首尾的 !、@、#) | 否(默认去除空白字符) |
text2sql_prompt:“文本转 SQL” 的预填充提示模板。为后续 LLM 生成 SQL 提供 “标准化指令模板”,已包含数据库方言信息,后续只需补充 {query_str}(用户查询)、{schema}(表结构)等动态变量即可调用。
DEFAULT_TEXT_TO_SQL_PROMPT:lamaIndex 框架内置的 “默认文本转 SQL 提示模板”,供文本转 SQL 场景的 “基础指令模板”,无需用户手动编写完整提示,通过 partial_format 或 format 方法补充动态参数即可复用,降低提示工程成本。
engine:负责管理数据库连接、执行 SQL 语句等底层交互。
engine.dialect:是 SQLAlchemy 中 “数据库方言” 的封装对象,用于适配不同数据库(如 SQLite、MySQL、PostgreSQL)的语法差异
engine.dialect.name:dialect 的 name属性,返回当前数据库方言
DEFAULT_TEXT_TO_SQL_PROMPT.partial_format():LlamaIndex 内置提示模板(DEFAULT_TEXT_TO_SQL_PROMPT,用于文本转 SQL)的方法,对模板中的部分变量进行预格式化(填充固定值),返回一个新的提示模板(剩余变量可后续填充)。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
**kwargs | 任意类型 | 需预填充的模板变量(如 dialect="sqlite",匹配模板中的 {dialect} 变量) | 是(需匹配模板中的部分变量) |
text2sql_prompt.template:存储 “填充部分变量后的纯文本模板字符串”。
from llama_index.core.prompts.default_prompts import DEFAULT_TEXT_TO_SQL_PROMPT
from llama_index.core import PromptTemplate
from llama_index.core.llms import ChatResponsedef parse_response_to_sql(chat_response: ChatResponse) -> str:"""Parse response to SQL."""response = chat_response.message.contentsql_query_start = response.find("SQLQuery:")if sql_query_start != -1:response = response[sql_query_start:]# TODO: move to removeprefix after Python 3.9+if response.startswith("SQLQuery:"):response = response[len("SQLQuery:") :]sql_result_start = response.find("SQLResult:")if sql_result_start != -1:response = response[:sql_result_start]return response.strip().strip("```").strip()text2sql_prompt = DEFAULT_TEXT_TO_SQL_PROMPT.partial_format(dialect=engine.dialect.name
)
print(text2sql_prompt.template)
4.创建自然语言回复模板
# 代码执行流程树形流程图
```
代码入口
├─ 1. 定义回答合成提示字符串(response_synthesis_prompt_str)
│ ├─ 核心用途:作为“基于SQL结果生成自然语言回答”的纯文本指令模板,指导LLM合成贴合查询的回答
│ ├─ 字符串组成结构
│ │ ├─ 固定指令:"Given an input question, synthesize a response from the query results.\n"(定义LLM任务目标)
│ │ ├─ 动态占位符1:"Query: {query_str}\n"(预留用户原始查询文本的填充位置)
│ │ ├─ 动态占位符2:"SQL: {sql_query}\n"(预留生成的SQL语句的填充位置)
│ │ ├─ 动态占位符3:"SQL Response: {context_str}\n"(预留SQL执行结果的填充位置)
│ │ └─ 回答输出标记:"Response: "(指定LLM生成回答的起始位置)
│ └─ 输出:response_synthesis_prompt_str(含固定指令+3个动态占位符的纯文本模板字符串)
│
├─ 2. 创建回答合成提示模板实例(response_synthesis_prompt)
│ ├─ 输入:response_synthesis_prompt_str(步骤1定义的纯文本模板字符串)
│ ├─ 核心操作:调用LlamaIndex的`PromptTemplate`类,将纯文本模板转换为框架可识别的标准化提示模板对象
│ └─ 输出:response_synthesis_prompt(`PromptTemplate`实例,支持后续通过`format_messages()`填充占位符,传递给LLM)
│
└─ 3. 初始化大语言模型(llm)├─ 核心类:LlamaIndex的`DashScope`类(用于调用阿里云DashScope平台的大语言模型)├─ 输入参数│ ├─ 参数1:`model_name`(模型名称)→ 取值为`DashScopeGenerationModels.QWEN_MAX`(指定使用QWEN_MAX模型)│ └─ 参数2:`api_key`(API密钥)→ 取值为`os.getenv("DASHSCOPE_API_KEY")`(从系统环境变量读取,避免硬编码)└─ 输出:llm(`DashScope`实例,作为后续生成回答的核心推理引擎,可通过`chat()`方法接收提示并返回响应)
```response_synthesis_prompt_str:指导大语言模型(LLM)根据查询、SQL 语句及 SQL 执行结果生成自然语言回答的纯文本提示模板字符串。
response_synthesis_prompt:由response_synthesis_prompt_str转换而来的 LlamaIndex PromptTemplate实例,是标准化的提示模板对象。
PromptTemplate():LlamaIndex 类,用于创建文本提示模板,定义 LLM 输入的格式(支持静态文本和动态变量,变量用 {} 包裹),便于复用和统一格式。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
template | str | 提示模板字符串(如 "请分析以下文本:{text}",{text} 为动态变量) | 是 |
input_variables | list | 模板中动态变量的名称列表(如 ["text"],需与 template 中的变量对应) | 否(默认自动从 template 中提取变量) |
output_parser | OutputParser | 输出解析器(用于将 LLM 输出转换为指定格式,如 StrOutputParser) | 否 |
DashScope():LlamaIndex 中封装阿里云 DashScope 大语言模型的类,用于初始化 DashScope LLM 实例,支持文本生成、结构化输出等操作。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
model_name | str/DashScopeGenerationModels | 模型名称(如 DashScopeGenerationModels.QWEN_MAX、"qwen-max") | 是 |
api_key | str | DashScope 平台 API 密钥(用于身份验证,若环境变量已配置可省略) | 否(默认读取环境变量 DASHSCOPE_API_KEY) |
timeout | int | API 调用超时时间(单位:秒) | 否(默认 60) |
temperature | float | 生成文本的随机性(0~1,值越高越随机,0 为确定性输出) | 否(默认 0.7) |
max_tokens | int | 生成文本的最大 token 数 | 否(默认根据模型限制) |
response_synthesis_prompt_str = ("Given an input question, synthesize a response from the query results.\n""Query: {query_str}\n""SQL: {sql_query}\n""SQL Response: {context_str}\n""Response: "
)
response_synthesis_prompt = PromptTemplate(response_synthesis_prompt_str,
)llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))5.定义工作流
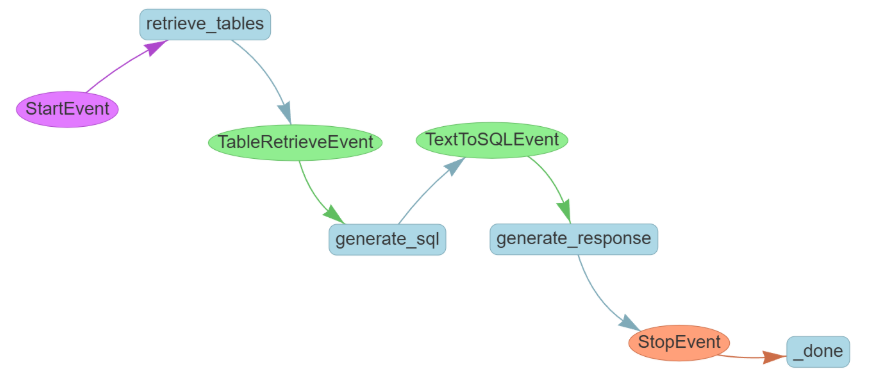
文本查询→检索相关表→生成 SQL→执行 SQL→生成回答
# TextToSQLWorkflow1 工作流流程
├─ 1. 依赖导入
│ ├─ Workflow框架核心:Workflow(基类)、StartEvent/StopEvent(起止事件)、step(步骤装饰器)、Context(上下文)、Event(事件基类)
│ └─ 工具函数(隐含):get_table_context_str(表信息格式化)、parse_response_to_sql(SQL提取)
│
├─ 2. 自定义事件定义(数据载体)
│ ├─ TableRetrieveEvent(表检索结果事件)
│ │ ├─ 字段:table_context_str(表上下文信息,含结构和描述)
│ │ └─ 字段:query(原始查询文本)
│ │
│ └─ TextToSQLEvent(文本转SQL事件)
│ ├─ 字段:sql(生成的SQL语句)
│ └─ 字段:query(原始查询文本)
│
├─ 3. 工作流类(TextToSQLWorkflow1)
│ ├─ 初始化(__init__):接收核心依赖
│ │ ├─ obj_retriever(表检索器)、text2sql_prompt(SQL生成提示)
│ │ ├─ sql_retriever(SQL执行器)、response_synthesis_prompt(回答生成提示)
│ │ └─ llm(大语言模型实例)
│ │
│ └─ 核心步骤(@step装饰,按顺序执行)
│ ├─ 步骤1:retrieve_tables(检索相关表)
│ │ ├─ 输入:StartEvent(含用户查询query)
│ │ ├─ 处理:调用obj_retriever.retrieve()获取相关表 → 格式化表上下文
│ │ └─ 输出:TableRetrieveEvent(table_context_str + query)
│ │
│ ├─ 步骤2:generate_sql(生成SQL语句)
│ │ ├─ 输入:TableRetrieveEvent(table_context_str + query)
│ │ ├─ 处理:用text2sql_prompt格式化提示 → LLM生成SQL → 提取纯SQL
│ │ └─ 输出:TextToSQLEvent(sql + query)
│ │
│ └─ 步骤3:generate_response(生成最终回答)
│ ├─ 输入:TextToSQLEvent(sql + query)
│ ├─ 处理:执行SQL获取结果 → 用response_synthesis_prompt格式化提示 → LLM生成回答
│ └─ 输出:StopEvent(含最终回答结果)
│
└─ 4. 工作流执行 ├─ 创建实例:workflow = TextToSQLWorkflow1(...)(传入所有依赖) ├─ 异步调用:定义async def main(),通过await workflow.run(query=...)启动工作流 └─ 启动循环:需用asyncio.run(main())执行(触发整个工作流流程)Ⅰ、TableRetrieveEvent 表检索结果事件
table_context_str:表检索结果的上下文信息字符串,将检索到的表信息传递给下一个步骤,确保 LLM 仅基于相关表生成 SQL,避免操作无关数据。
query:用户原始查询文本,表检索步骤基于该查询找到相关表后,将查询文本随表信息一同传递给下一个步骤,避免后续步骤丢失查询上下文。
# 事件:找到数据库中相关的表
class TableRetrieveEvent(Event):"""Result of running table retrieval."""table_context_str: strquery: strⅡ、TextToSQLEvent 文本转SQL事件
sql:存储 LLM 根据用户查询和相关表上下文生成的可执行 SQL 语句。将生成的 SQL 传递给下一个环节(如 SQLRetriever 执行查询),是连接自然语言与数据库操作的关键结果。
query:用户原始查询文本。保持工作流上下文连贯 —— 文本转 SQL 步骤基于该查询生成 SQL 后,将原始查询随 SQL 一同传递,确保后续 “生成最终回答” 时,LLM 能结合原始问题和 SQL 执行结果,输出贴合用户需求的自然语言回复,避免丢失查询上下文。
# 事件:文本转 SQL
class TextToSQLEvent(Event):"""Text-to-SQL event."""sql: strquery: strⅢ、初始化工作流
obj_retriever:表元信息检索器,根据用户查询(query)检索与查询最相关的表元信息(如 SQLTableSchema 实例),为后续生成 SQL 提供 “相关表范围”,避免操作无关表。
text2sql_prompt:文本转 SQL 提示模板,作为 LLM 生成 SQL 的指令模板,定义生成逻辑(如 “结合查询和表结构生成符合数据库方言的 SQL”),确保 SQL 语法正确且匹配查询需求。
sql_retriever:SQL 执行检索器,接收 LLM 生成的 SQL 语句,执行数据库查询并返回结果(如匹配的行数据),是连接 SQL 与数据库的核心组件。
response__synthesis_prompt:回答合成提示模板,作为 LLM 生成最终自然语言回答的指令模板,指导 LLM 结合用户查询、SQL 语句和 SQL 执行结果,生成贴合需求的回答。
llm:类初始化时接收的 “大语言模型实例”
*args:Python 中的 “可变位置参数”,用于接收任意数量的未命名参数(以元组形式存储)。
**kwargs:Python 中的 “可变关键字参数”,用于接收任意数量的命名参数(以字典形式存储)。
class TextToSQLWorkflow1(Workflow):"""Text-to-SQL Workflow that does query-time table retrieval."""def __init__(self,obj_retriever,text2sql_prompt,sql_retriever,response_synthesis_prompt,llm,*args,**kwargs) -> None:"""Init params."""super().__init__(*args, **kwargs)self.obj_retriever = obj_retrieverself.text2sql_prompt = text2sql_promptself.sql_retriever = sql_retrieverself.response_synthesis_prompt = response_synthesis_promptself.llm = llmⅣ、retrieve_tables 检索相关表
ctx:Context 类实例,由 @step 装饰器自动注入,是工作流步骤间传递 “全局状态、配置或临时数据” 的载体,用于框架内部管理步骤执行上下文
ev:StartEvent 类实例,工作流启动时的输入数据载体。检索相关表的 “查询依据”,确保检索到的表与用户需求匹配。
table_schema_objs:存储 “与用户查询相关的表的元信息”,为后续生成 “表上下文字符串” 提供数据源,每个 SQLTableSchema 实例包含 table_name(表名)和 context_str(表描述),是构建 table_context_str 的基础。
self.obj_retriever:表元信息检索器,根据用户查询匹配相关表,将用户查询转换为向量后,与 obj_index 中的表元信息向量比对,返回相似度最高的表元信息(table_schema_objs)。
table_context_str:“格式化的表上下文字符串”,包含与查询相关的表的 “结构信息 + 描述信息”。作为 “表信息载体” 传递给下一个步骤(generate_sql),供 LLM 理解相关表的结构和用途,确保生成的 SQL 语句能精准匹配表结构。
self.obj_retriever.retrieve():LlamaIndex 检索器(Retriever)的核心方法,用于根据输入的查询文本,从关联的索引(此处为存储表元信息的 ObjectIndex)中检索出与查询最相关的对象(当前场景中为 SQLTableSchema 实例,即表的元信息),返回这些相关对象的列表。其核心逻辑是通过文本相似度匹配(基于嵌入向量),筛选出与用户查询最相关的表,为后续生成 SQL 提供 “目标表范围”。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
query_str | str | 用户的原始查询文本(如 "What was the year that The Notorious B.I.G was signed to Bad Boy?"),作为检索的 “关键词”,用于匹配相关表元信息 | 是 |
get_table_context_str():将检索到的相关表的元信息(表结构 + 表描述)格式化为一个统一的字符串,便于后续传递给大语言模型(LLM)理解表的结构和用途。
TableRetrieveEvent():作为工作流中 “表检索步骤” 到 “生成 SQL 步骤” 的数据载体,传递表检索结果和原始查询,保持工作流上下文连贯。
@stepdef retrieve_tables(self, ctx: Context, ev: StartEvent) -> TableRetrieveEvent:"""Retrieve tables."""table_schema_objs = self.obj_retriever.retrieve(ev.query)table_context_str = get_table_context_str(table_schema_objs)print("====\n" + table_context_str + "\n====")return TableRetrieveEvent(table_context_str=table_context_str, query=ev.query)Ⅴ、generate_sql 生成SQL语句
ctx:Context 类实例,由 @step 装饰器自动注入,是工作流步骤间传递 “全局状态、配置或临时数据” 的载体,用于框架内部管理步骤执行上下文
ev:StartEvent 类实例,工作流启动时的输入数据载体。检索相关表的 “查询依据”,确保检索到的表与用户需求匹配。
fmt_messages:格式化后的提示消息列表(通常为 ChatMessage 实例的列表),是传递给 LLM 的 “最终指令输入”。
text2sql_prompt:LlamaIndex 提示模板对象(PromptTemplate 或 ChatPromptTemplate 实例),专门用于指导大语言模型(LLM)将自然语言查询转换为符合数据库语法的 SQL 语句。
text2sql_prompt.format_messages():将提示模板中的动态占位符(如 {query_str}、{schema})替换为实际值,生成符合 LLM 输入格式的消息列表(通常为 ChatMessage 实例的列表),确保 LLM 能理解完整的指令和上下文。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
**kwargs | 键值对 | 用于填充模板中占位符的实际值,键需与模板中的占位符名称一致(如 query_str=用户查询、schema=表上下文) | 是 |
chat_response:大语言模型(LLM)调用返回的 ChatResponse 实例(LlamaIndex 框架中封装 LLM 响应的对象)。
llm.chat():向大语言模型(LLM)发送聊天消息,获取模型的响应(包含生成的文本内容),是与 LLM 交互的核心方法。在文本转 SQL 场景中,用于基于 fmt_messages 生成包含 SQL 语句的响应。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
messages | List[ChatMessage] | 聊天消息列表,每个元素为 ChatMessage 实例(包含角色 role 和内容 content),代表完整的对话上下文 | 是 |
temperature | float | 生成文本的随机性(0 表示确定性输出,1 表示高度随机),默认值由模型配置决定 | 否 |
stop | List[str] | 生成文本的停止符,当模型生成包含该字符串的内容时停止生成 | 否 |
TextToSQLEvent():工作流中 “生成 SQL 步骤” 到 “生成回答步骤” 的数据载体。
@stepdef generate_sql(self, ctx: Context, ev: TableRetrieveEvent) -> TextToSQLEvent:"""Generate SQL statement."""fmt_messages = self.text2sql_prompt.format_messages(query_str=ev.query, schema=ev.table_context_str)chat_response = self.llm.chat(fmt_messages)sql = parse_response_to_sql(chat_response)print("====\n" + sql + "\n====")return TextToSQLEvent(sql=sql, query=ev.query)Ⅵ、generate_response 生成最终回答
retrieved_rows:存储 SQL 语句执行后从数据库中获取的结果数据(通常是列表或类似结构,包含匹配的行记录)。
sql_retriever.retrieve():执行输入的 SQL 语句,从数据库中获取查询结果(如匹配的行数据),是连接 SQL 语句与数据库的核心方法。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
sql | str | 待执行的 SQL 语句(如 SELECT * FROM music_artists WHERE name = 'The Notorious B.I.G') | 是 |
params | dict | 可选参数,用于参数化查询(防止 SQL 注入),如 {"name": "The Notorious B.I.G"} | 否 |
str():将输入的对象转换为字符串类型,返回该对象的字符串表示形式,用于类型转换或格式化输出。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
obj | 任意类型 | 需要转换为字符串的对象 | 是 |
chat_response:大语言模型(LLM)调用返回的 ChatResponse 实例(LlamaIndex 框架中封装 LLM 响应的对象),存储 LLM 生成的最终自然语言回答。
llm.chat():向大语言模型(LLM)发送聊天消息,获取模型的响应(包含生成的文本内容),是与 LLM 交互的核心方法。在文本转 SQL 场景中,用于基于 fmt_messages 生成包含 SQL 语句的响应。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
messages | List[ChatMessage] | 聊天消息列表,每个元素为 ChatMessage 实例(包含角色 role 和内容 content),代表完整的对话上下文 | 是 |
temperature | float | 生成文本的随机性(0 表示确定性输出,1 表示高度随机),默认值由模型配置决定 | 否 |
stop | List[str] | 生成文本的停止符,当模型生成包含该字符串的内容时停止生成 | 否 |
StopEvent():创建一个 StopEvent 实例,作为工作流的 “终止信号”,用于结束工作流的执行,通常在完成所有步骤后返回,标记工作流正常结束。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
result | 任意类型 | 可选,存储工作流的最终结果(如生成的自然语言回答),供外部获取工作流输出 | 否 |
@stepdef generate_response(self, ctx: Context, ev: TextToSQLEvent) -> StopEvent:"""Run SQL retrieval and generate response."""retrieved_rows = self.sql_retriever.retrieve(ev.sql)print("====\n" + str(retrieved_rows) + "\n====")fmt_messages = self.response_synthesis_prompt.format_messages(sql_query=ev.sql,context_str=str(retrieved_rows),query_str=ev.query,)chat_response = llm.chat(fmt_messages)return StopEvent(result=chat_response)Ⅶ、工作流执行
workflow:一个完整的 “文本转 SQL 工作流” 对象,封装了从 “检索相关表” 到 “生成最终回答” 的全流程逻辑。接收用户查询后自动完成 “找表→生成 SQL→执行 SQL→生成回答” 的闭环,是整个文本转 SQL 功能的核心载体。
obj_retriever:表元信息检索器(Retriever 实例),由 ObjectIndex.as_retriever() 生成,用于根据用户查询匹配相关表。为后续生成 SQL 限定 “目标表范围”。
text2sql_prompt:文本转 SQL 的提示模板,用于格式化提示消息(fmt_messages),指导 LLM 结合用户查询和表上下文生成符合语法的 SQL 语句。
sql_retriever:依赖 sql_database(数据库连接对象)创建,用于执行 SQL 语句并返回结果。
response_synthesis_prompt:回答合成提示模板(PromptTemplate 实例),基于 response_synthesis_prompt_str 创建,包含 {query_str}、{sql_query}、{context_str} 等占位符。指导 LLM 结合用户查询、SQL 语句和 SQL 执行结果,生成自然语言回答。
llm:大语言模型实例
verbose:布尔类型参数(此处为 True),继承自LlamaIndex框架Workflow类的内置初始化参数,用于控制工作流执行过程中的日志输出详细程度。工作流会打印执行过程中的关键信息(如检索到的表上下文、生成的 SQL、查询结果等),便于调试和跟踪工作流执行状态;
async:定义异步函数(协程函数),这类函数的返回值是一个协程对象(coroutine),而非普通函数的返回值。异步函数内部可以使用 await 关键字暂停执行,等待其他异步操作完成,从而实现非阻塞的并发逻辑(如同时处理多个 I/O 任务时,避免因等待一个任务而阻塞整个程序)。
await:仅能在 async 定义的异步函数内部使用,用于暂停当前协程的执行,等待一个 “可等待对象”(如协程、Future、Task 等)完成,再恢复当前协程的执行。在等待期间,程序会将 CPU 控制权交还给事件循环,允许其他任务运行,实现 “非阻塞等待”(避免因等待 I/O 操作而浪费资源)。
response:存储工作流的最终输出,通过 str(response) 可打印最终回答文本,是用户查询的最终反馈。
workflow.run():启动工作流(如 TextToSQLWorkflow1 实例)并异步执行其内部所有步骤
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
query | str | 用户的原始查询文本(如 "What was the year that The Notorious B.I.G was signed to Bad Boy?"),是工作流执行的输入核心,所有步骤(检索表、生成 SQL 等)均基于此查询展开 | 是 |
**kwargs | 键值对 | 可选的额外输入参数,根据工作流定义可能包含其他上下文信息(如自定义配置、元数据等),具体取决于工作流类的设计 | 否 |
workflow = TextToSQLWorkflow1(obj_retriever,text2sql_prompt,sql_retriever,response_synthesis_prompt,llm,verbose=True,
)# 1. 确保导入 asyncio
import asyncio# 2. 定义 async main 函数,在内部 await workflow.run()
async def main():# 关键:在 async 函数内部调用 workflow.run(),并加 awaitresponse = await workflow.run(query="What was the year that The Notorious B.I.G was signed to Bad Boy?")print(str(response))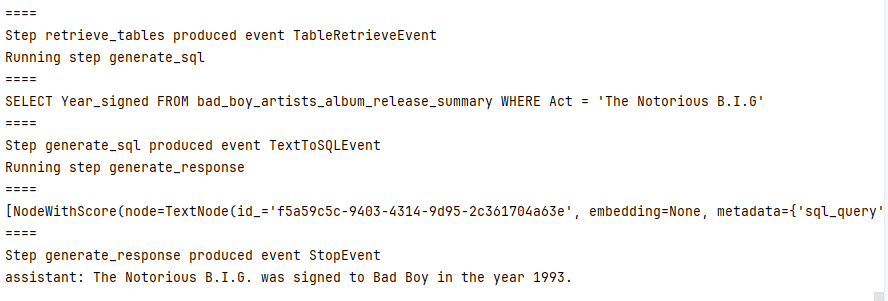
6.可视化工作流
清华源下载:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index-utils-workflow
draw_all_possible_flows():llama_index 工作流模块的辅助工具函数,用于将预定义的 Workflow 对象(包含节点、条件、执行逻辑)转换为直观的图形化流程图,自动解析并展示工作流中所有可能的执行路径(包括分支、循环、条件跳转等)。
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
workflow | Workflow 实例 | 是 | 待可视化的工作流对象,需包含完整的节点(Node)、条件(Condition)和执行逻辑定义(由 llama_index.workflow 模块创建) |
output_path | str | 否 | 流程图输出路径(含文件名),例如 "./workflow_flows.png"。若不指定,默认在内存中生成图像(需配合显示工具查看) |
format | str | 否 | 输出图像格式,支持 png、svg、pdf 等(依赖底层绘图库,默认 png) |
show_conditions | bool | 否 | 是否在图中显示分支条件的具体逻辑(如 if x > 0),默认 True(显示条件细节) |
show_node_details | bool | 否 | 是否显示节点的详细信息(如节点名称、输入输出参数),默认 False(仅显示节点名称,避免图过于复杂) |
layout | str | 否 | 流程图布局方式,支持 top_to_bottom(从上到下)、left_to_right(从左到右)、circular(环形),默认 top_to_bottom |
engine | str | 否 | 底层绘图引擎,可选 graphviz 或 mpl(matplotlib),默认 graphviz(需提前安装对应引擎) |
from llama_index.utils.workflow import draw_all_possible_flowsdraw_all_possible_flows(workflow=TextToSQLWorkflow1, filename="text_to_sql_table_retrieval.html"
)
7.完整代码
import osimport pandas as pd
from pathlib import Pathfrom llama_index.llms.dashscope import DashScope, DashScopeGenerationModelsdata_dir = Path(r"F:\AI_BigModel\appTest4\day4_LlamaIndex\WikiTableQuestions\csv\200-csv")
print("data_dir:", data_dir.exists())
csv_files = sorted([f for f in data_dir.glob("*.csv")])
print("length of csv_files:", len(csv_files))
dfs = []for csv_file in csv_files:print(f"processing file: {csv_file}") # 若打印了此句,说明csv_files非空try:df = pd.read_csv(csv_file)dfs.append(df)except Exception as e:print(f"Error parsing {csv_file}: {str(e)}") # 若有此输出,说明读取失败
print(f"成功读取的CSV文件数量:{len(dfs)}") # 若为0,说明所有文件读取失败from llama_index.core.prompts import ChatPromptTemplate
from llama_index.core.bridge.pydantic import BaseModel, Field
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessageclass TableInfo(BaseModel):"""Information regarding a structured table."""table_name: str = Field(..., description="table name (must be underscores and NO spaces)")table_summary: str = Field(..., description="short, concise summary/caption of the table")prompt_str = """\
Give me a summary of the table with the following JSON format.- The table name must be unique to the table and describe it while being concise.
- Do NOT output a generic table name (e.g. table, my_table).Do NOT make the table name one of the following: {exclude_table_name_list}Table:
{table_str}Summary: """
prompt_tmpl = ChatPromptTemplate(message_templates=[ChatMessage.from_str(prompt_str, role="user")]
)llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))tableinfo_dir = "WikiTableQuestions_TableInfo"
print(f"元信息目录是否存在:{os.path.exists(tableinfo_dir)}") # 若输出False,会报错import jsondef _get_tableinfo_with_index(idx: int) -> str:results_gen = Path(tableinfo_dir).glob(f"{idx}_*")results_list = list(results_gen)if len(results_list) == 0:return Noneelif len(results_list) == 1:path = results_list[0]with open(path, 'r') as file:data = json.load(file)return TableInfo.model_validate(data)else:raise ValueError(f"More than one file matching index: {list(results_gen)}")table_names = set()
table_infos = []
for idx, df in enumerate(dfs):table_info = _get_tableinfo_with_index(idx)if table_info:table_infos.append(table_info)else:while True:df_str = df.head(10).to_csv()table_info = llm.structured_predict(TableInfo,prompt_tmpl,table_str=df_str,exclude_table_name_list=str(list(table_names)),)table_name = table_info.table_nameprint(f"Processed table: {table_name}")if table_name not in table_names:table_names.add(table_name)breakelse:# try againprint(f"Table name {table_name} already exists, trying again.")passout_file = f"{tableinfo_dir}/{idx}_{table_name}.json"json.dump(table_info.dict(), open(out_file, "w"))table_infos.append(table_info)# put data into sqlite db
from sqlalchemy import (create_engine,MetaData,Table,Column,String,Integer,
)
import re# Function to create a sanitized column name
def sanitize_column_name(col_name):# Remove special characters and replace spaces with underscoresreturn re.sub(r"\W+", "_", col_name)# Function to create a table from a DataFrame using SQLAlchemy
def create_table_from_dataframe(df: pd.DataFrame, table_name: str, engine, metadata_obj):# Sanitize column namessanitized_columns = {col: sanitize_column_name(col) for col in df.columns}df = df.rename(columns=sanitized_columns)# Dynamically create columns based on DataFrame columns and data typescolumns = [Column(col, String if dtype == "object" else Integer)for col, dtype in zip(df.columns, df.dtypes)]# Create a table with the defined columnstable = Table(table_name, metadata_obj, *columns)# Create the table in the databasemetadata_obj.create_all(engine)# Insert data from DataFrame into the tablewith engine.connect() as conn:for _, row in df.iterrows():insert_stmt = table.insert().values(**row.to_dict())conn.execute(insert_stmt)conn.commit()# engine = create_engine("sqlite:///:memory:")
engine = create_engine("sqlite:///wiki_table_questions.db")
metadata_obj = MetaData()
for idx, df in enumerate(dfs):tableinfo = _get_tableinfo_with_index(idx)print(f"Creating table: {tableinfo.table_name}")create_table_from_dataframe(df, tableinfo.table_name, engine, metadata_obj)print(f"Table created: {tableinfo.table_name}")print(f"待处理的DataFrame数量:{len(dfs)}") # 应与CSV文件数量一致,若为0则无后续输出import os
from llama_index.core import Settings
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
from llama_index.core.objects import (SQLTableNodeMapping,ObjectIndex,SQLTableSchema,
)
from llama_index.core import SQLDatabase, VectorStoreIndex# 设置全局模型
# Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))
Settings.embed_model = DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V1)sql_database = SQLDatabase(engine)table_node_mapping = SQLTableNodeMapping(sql_database)
table_schema_objs = [SQLTableSchema(table_name=t.table_name, context_str=t.table_summary)for t in table_infos
] # add a SQLTableSchema for each tableobj_index = ObjectIndex.from_objects(table_schema_objs,table_node_mapping,VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)from llama_index.core.retrievers import SQLRetriever
from typing import Listsql_retriever = SQLRetriever(sql_database)def get_table_context_str(table_schema_objs: List[SQLTableSchema]):"""Get table context string."""context_strs = []for table_schema_obj in table_schema_objs:table_info = sql_database.get_single_table_info(table_schema_obj.table_name)if table_schema_obj.context_str:table_opt_context = " The table description is: "table_opt_context += table_schema_obj.context_strtable_info += table_opt_contextcontext_strs.append(table_info)return "\n\n".join(context_strs)from llama_index.core.prompts.default_prompts import DEFAULT_TEXT_TO_SQL_PROMPT
from llama_index.core import PromptTemplate
from llama_index.core.llms import ChatResponsedef parse_response_to_sql(chat_response: ChatResponse) -> str:"""Parse response to SQL."""response = chat_response.message.contentsql_query_start = response.find("SQLQuery:")if sql_query_start != -1:response = response[sql_query_start:]# TODO: move to removeprefix after Python 3.9+if response.startswith("SQLQuery:"):response = response[len("SQLQuery:"):]sql_result_start = response.find("SQLResult:")if sql_result_start != -1:response = response[:sql_result_start]return response.strip().strip("```").strip()text2sql_prompt = DEFAULT_TEXT_TO_SQL_PROMPT.partial_format(dialect=engine.dialect.name
)
print(text2sql_prompt.template)response_synthesis_prompt_str = ("Given an input question, synthesize a response from the query results.\n""Query: {query_str}\n""SQL: {sql_query}\n""SQL Response: {context_str}\n""Response: "
)
response_synthesis_prompt = PromptTemplate(response_synthesis_prompt_str,
)llm = DashScope(model_name=DashScopeGenerationModels.QWEN_MAX, api_key=os.getenv("DASHSCOPE_API_KEY"))from llama_index.core.workflow import (Workflow,StartEvent,StopEvent,step,Context,Event,
)# 事件:找到数据库中相关的表
class TableRetrieveEvent(Event):"""Result of running table retrieval."""table_context_str: strquery: str# 事件:文本转 SQL
class TextToSQLEvent(Event):"""Text-to-SQL event."""sql: strquery: strclass TextToSQLWorkflow1(Workflow):"""Text-to-SQL Workflow that does query-time table retrieval."""def __init__(self,obj_retriever,text2sql_prompt,sql_retriever,response_synthesis_prompt,llm,*args,**kwargs) -> None:"""Init params."""super().__init__(*args, **kwargs)self.obj_retriever = obj_retrieverself.text2sql_prompt = text2sql_promptself.sql_retriever = sql_retrieverself.response_synthesis_prompt = response_synthesis_promptself.llm = llm@stepdef retrieve_tables(self, ctx: Context, ev: StartEvent) -> TableRetrieveEvent:"""Retrieve tables."""table_schema_objs = self.obj_retriever.retrieve(ev.query)table_context_str = get_table_context_str(table_schema_objs)print("====\n" + table_context_str + "\n====")return TableRetrieveEvent(table_context_str=table_context_str, query=ev.query)@stepdef generate_sql(self, ctx: Context, ev: TableRetrieveEvent) -> TextToSQLEvent:"""Generate SQL statement."""fmt_messages = self.text2sql_prompt.format_messages(query_str=ev.query, schema=ev.table_context_str)chat_response = self.llm.chat(fmt_messages)sql = parse_response_to_sql(chat_response)print("====\n" + sql + "\n====")return TextToSQLEvent(sql=sql, query=ev.query)@stepdef generate_response(self, ctx: Context, ev: TextToSQLEvent) -> StopEvent:"""Run SQL retrieval and generate response."""retrieved_rows = self.sql_retriever.retrieve(ev.sql)print("====\n" + str(retrieved_rows) + "\n====")fmt_messages = self.response_synthesis_prompt.format_messages(sql_query=ev.sql,context_str=str(retrieved_rows),query_str=ev.query,)chat_response = llm.chat(fmt_messages)return StopEvent(result=chat_response)workflow = TextToSQLWorkflow1(obj_retriever,text2sql_prompt,sql_retriever,response_synthesis_prompt,llm,verbose=True,
)# 1. 确保导入 asyncio
import asyncio# 2. 定义 async main 函数,在内部 await workflow.run()
async def main():# 关键:在 async 函数内部调用 workflow.run(),并加 awaitresponse = await workflow.run(query="What was the year that The Notorious B.I.G was signed to Bad Boy?")print(str(response))asyncio.run(main())from llama_index.utils.workflow import draw_all_possible_flowsdraw_all_possible_flows(workflow=TextToSQLWorkflow1, filename="text_to_sql_table_retrieval.html"
)
五、工作流管理框架的意义
当遇到以下情况:
step的执行顺序有逻辑分支
step的执行有循环
step的执行可以并行一个
step的触发条件依赖前面若干step的结果,且它们之间可能有循环或者并行
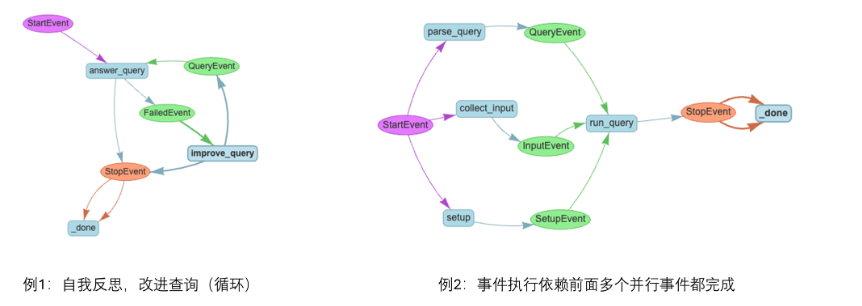
工作流管理框架的意思是便于将单个事件的处理逻辑和事件之间的执行顺序独立开