LLMs之REFRAG:《REFRAG: Rethinking RAG based Decoding》的翻译与解读
LLMs之REFRAG:《REFRAG: Rethinking RAG based Decoding》的翻译与解读
导读:REFRAG 是一个专为解决 RAG 应用中长上下文处理效率低下问题而设计的创新解码框架。它通过使用一个轻量级编码器将冗长的检索上下文压缩为紧凑的“块嵌入”,并结合强化学习策略智能地保留关键信息,在不修改大模型主体结构的前提下,极大地缩短了输入序列,从而实现了高达30倍的首个令牌生成时间加速和显著的内存节省。该工作证明了针对特定场景(如RAG)进行专门优化是提升 LLM 系统效率的有效途径,为在延迟敏感和知识密集型应用中部署大语言模型提供了一个实用且可扩展的解决方案。
>> 背景痛点
● 长上下文的效率瓶颈:大型语言模型(LLM)在利用如检索增强生成(RAG)等技术处理外部知识时表现出色,但长上下文输入会带来显著的系统延迟(尤其是首个令牌生成时间 TTFT)和巨大的键值缓存(KV Cache)内存需求,这导致吞吐量下降,形成了知识丰富度与系统效率之间的根本矛盾。
● RAG场景的特殊性:现有的长上下文优化方法大多是通用的,而 RAG 场景具有其独特性。将 RAG 的延迟问题视为通用的 LLM 推理问题,忽视了几个关键方面。
● 低效的令牌分配:RAG 的上下文中包含了大量检索到的段落,但通常只有一小部分与用户查询直接相关。为所有上下文令牌分配计算和内存资源是极大的浪费。
● 冗余的计算开销:在 RAG 的检索和重排阶段,已经计算了段落的向量表示等信息,但在解码阶段这些信息被丢弃,导致了不必要的重复计算。
● 稀疏的注意力结构:由于检索结果为了保证多样性或经过了去重处理,不同段落间的语义相关性较低,导致注意力矩阵呈现出“块对角”(block-diagonal)的稀疏模式。这意味着跨段落的注意力计算大多是无效的。
>> 具体的解决方案
● 提出 REFRAG 框架:论文提出了一种名为 REFRAG (Rethinking RAG based Decoding) 的高效解码框架,专为 RAG 应用设计,旨在通过“压缩、感知和扩展”来显著改善延迟和内存使用。
● 上下文压缩机制:REFRAG 的核心在于不直接将检索到的段落原文作为解码器的输入,而是使用一个轻量级的编码器(如 RoBERTa)将每个段落(或文本块)压缩成一个单一的“块嵌入”(chunk embedding)。
● 混合式输入:解码器(如 LLaMA)接收的输入序列由两部分组成:原始用户问题的词元嵌入(token embeddings)和经过压缩的上下文块嵌入(chunk embeddings)。
● 选择性压缩与扩展:为了保留关键信息,框架引入了一个基于强化学习(RL)的轻量级策略网络。该网络负责判断哪些上下文块至关重要,需要以未压缩的原始词元形式保留,而其他次要的块则可以被压缩,从而在压缩率和信息保真度之间取得动态平衡。
>> 核心思路步骤
● 第一步:上下文分块与编码:将检索到的长上下文分割成固定大小的文本块(chunks)。然后,使用一个轻量级编码器模型(Menc)为每个文本块生成一个紧凑的“块嵌入”。这些嵌入可以被预先计算和缓存,以便在不同请求中复用。
● 第二步:对齐训练 (Continual Pre-training):为了让解码器能理解这些新的“块嵌入”,模型需要经过一个特殊的持续预训练(CPT)阶段。
●● 任务一:重构任务 (Reconstruction Task):首先,冻结解码器,只训练编码器和投影层,目标是让解码器能够根据块嵌入准确地重构出原始的文本块。这一步旨在将编码器的输出空间与解码器的输入空间对齐。
●● 任务二:课程学习 (Curriculum Learning):直接进行重构任务非常困难。因此,训练采用课程学习策略,从简单的任务(如重构一个块)开始,逐步增加难度(重构多个块),确保模型稳定学习。
●● 任务三:下一段落预测:在编码器与解码器对齐后,解冻所有参数,进行下一段落预测任务的训练,让模型学会利用压缩后的上下文来生成连贯的后续文本。
● 第三步:选择性压缩策略训练:使用强化学习来训练一个策略网络,该网络以最大化生成答案的质量(即最小化困惑度)为目标,学会智能地选择哪些上下文块应该被压缩,哪些应该被保留。
● 第四步:下游任务微调:经过预训练的 REFRAG 模型可以像普通 LLM 一样,在具体的下游任务(如 RAG 问答、长文档摘要)上进行微调,以适应特定应用的需求。
>> 优势
● 显著的性能加速:通过将长达数千个词元的上下文压缩成数量少得多的块嵌入,极大地缩短了解码器的输入序列长度,从而实现了首个令牌生成时间(TTFT)高达 30.85倍 的加速,比之前最优方法提升了 3.75倍。
● 无需修改模型架构:该方法无需对现有的解码器模型(如 LLaMA)进行内部结构修改,也不增加新的解码器参数,具有很强的通用性和易用性。
● 有效扩展上下文窗口:压缩技术使得模型在固有的位置编码限制下,能够“看到”远超其原始训练长度的上下文(例如扩展16倍),这在需要大量信息的任务中能带来准确率的提升。
● 缓存与复用:上下文块的嵌入可以被预先计算并缓存,对于频繁被检索到的文档,可以避免重复的编码计算,进一步提升效率。
● 同等延迟下性能更优:在相同的延迟预算下,REFRAG 能够处理比标准模型多得多的检索段落。这在检索结果质量不高(弱检索器)的场景下尤其有用,因为更多的上下文能帮助模型找到有用的信息,从而获得更高的准确率。
>> 结论和观点 (侧重经验与建议)
● 课程学习至关重要:消融实验明确表明,如果没有课程学习,直接训练模型处理复杂的重构任务会失败。从易到难的渐进式训练是模型成功收敛的关键。
● 重构预训练是基础:先进行重构任务的训练,再进行下一段落预测的训练,对于最终模型的性能至关重要。这确保了编码器和解码器之间的有效对齐。
● 强化学习策略的优越性:基于强化学习的选择性压缩策略,其性能显著优于随机选择或基于启发式规则(如基于困惑度)的方法。这证明了让模型自己学习判断信息重要性的价值。
● 压缩率存在上限:虽然压缩能带来巨大收益,但过高的压缩率(如64倍)会导致性能明显下降。研究表明,32倍的压缩率在保持竞争力的同时,能实现巨大的速度提升,这揭示了压缩率与信息损失之间的权衡。
● 解码器大小比编码器更重要:实验发现,增加解码器模型的规模(如从 7B 到 13B)对性能的提升,远大于增加轻量级编码器模型的规模。
● RAG 需要专门优化:论文的核心观点是,不应将 RAG 视为一个通用的长上下文问题。深入利用 RAG 场景中独特的稀疏注意力结构,是实现数量级性能优化的关键所在。
目录
《REFRAG: Rethinking RAG based Decoding》的翻译与解读
Abstract
1、Introduction
1.1 Our Contributions
2 Model Architecture
Figure 1:The main design of REFRAG. The input context is chunked and processed by the light-weight encoder to produce chunk embeddings, which are precomputable for efficient reuse. A light-weight RL policy decide few chunks to expand. These chunk embeddings along with the token embeddings of the question input are fed to the decoder.图 1:REFRAG 的主要设计。输入上下文被分块并由轻量级编码器处理以生成分块嵌入,这些嵌入可预先计算以实现高效复用。轻量级强化学习策略决定扩展少量分块。这些分块嵌入与问题输入的标记嵌入一起被送入解码器。
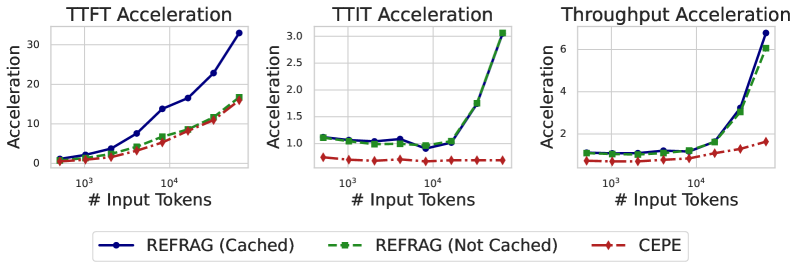
Figure 2:Empirical verification of inference acceleration of REFRAG with k=16.图 2:REFRAG 在 k=16 时推理加速的实证验证。
Conclusion
《REFRAG: Rethinking RAG based Decoding》的翻译与解读
| 地址 | https://arxiv.org/abs/2509.01092 |
| 时间 | 2025年9月1日 |
| 作者 | Meta Superintelligence Labs |
Abstract
| Large Language Models (LLMs) have demonstrated remarkable capabilities in leveraging extensive external knowledge to enhance responses in multi-turn and agentic applications, such as retrieval-augmented generation (RAG). However, processing long-context inputs introduces significant system latency and demands substantial memory for the key-value cache, resulting in reduced throughput and a fundamental trade-off between knowledge enrichment and system efficiency. While minimizing latency for long-context inputs is a primary objective for LLMs, we contend that RAG require specialized consideration. In RAG, much of the LLM context consists of concatenated passages from retrieval, with only a small subset directly relevant to the query. These passages often exhibit low semantic similarity due to diversity or deduplication during re-ranking, leading to block-diagonal attention patterns that differ from those in standard LLM generation tasks. Based on this observation, we argue that most computations over the RAG context during decoding are unnecessary and can be eliminated with minimal impact on performance. To this end, we propose REFRAG, an efficient decoding framework that compresses, senses, and expands to improve latency in RAG applications. By exploiting the sparsity structure, we demonstrate a 30.85 the time-to-first-token acceleration (3.75 improvement to previous work) without loss in perplexity. In addition, our optimization framework for large context enables REFRAG to extend the context size of LLMs by 16. We provide rigorous validation of REFRAG across diverse long-context tasks, including RAG, multi-turn conversations, and long document summarization, spanning a wide range of datasets. Experimental results confirm that REFRAG delivers substantial speedup with no loss in accuracy compared to LLaMA models and other state-of-the-art baselines across various context sizes. | 大型语言模型(LLM)在利用大量外部知识增强多轮对话和代理应用(如检索增强生成(RAG))中的响应方面展现出了非凡的能力。然而,处理长上下文输入会带来显著的系统延迟,并且需要大量的内存来存储键值缓存,从而导致吞吐量降低,并在知识丰富度和系统效率之间形成根本性的权衡。尽管减少长上下文输入的延迟是 LLM 的首要目标,但我们认为 RAG 需要专门考虑。在 RAG 中,LLM 上下文的大部分由检索到的拼接段落组成,其中只有很小一部分与查询直接相关。由于在重新排序期间的多样性或去重,这些段落往往语义相似度较低,导致注意力模式呈块对角线分布,这与标准 LLM 生成任务中的模式不同。基于这一观察,我们认为在解码过程中对 RAG 上下文的大部分计算都是不必要的,且可以消除这些计算,对性能影响极小。为此,我们提出了 REFRAG,这是一种高效的解码框架,通过压缩、感知和扩展来改善 RAG 应用中的延迟。通过利用稀疏结构,我们展示了 30.85 的首次标记生成时间加速(比之前的工作提高了 3.75 倍),且困惑度没有损失。此外,我们针对大上下文的优化框架使 REFRAG 能够将 LLM 的上下文大小扩展 16 倍。我们在包括 RAG、多轮对话和长文档摘要在内的各种长上下文任务上对 REFRAG 进行了严格的验证,涵盖了广泛的数据集。实验结果证实,与 LLaMA 模型和其他最先进的基线相比,REFRAG 在各种上下文大小下都能实现显著的速度提升,且精度没有损失。 |
1、Introduction
| Large Language Models (LLMs) have demonstrated impressive capabilities in contextual learning, leveraging information from their input to achieve superior performance across a range of downstream applications. For instance, in multi-turn conversations (Roller et al., 2021; Zhang et al., 2020), incorporating historical dialogue into the context enables LLMs to respond more effectively to user queries. In retrieval-augmented generation (RAG) (Guu et al., 2020; Izacard et al., 2022), LLMs generate more accurate answers by utilizing relevant search results retrieved from external sources. These examples highlight the power of LLMs to learn from context. However, it is well established that increasing prompt length for contextual learning leads to higher latency and greater memory consumption during inference (Yen et al., 2024). Specifically, longer prompts require additional memory for the key-value (KV) cache, which scales linearly with prompt length. Moreover, the time-to-first-token (TTFT) latency increases quadratically, while the time-to-iterative-token (TTIT) latency grows linearly with prompt length (Liu et al., 2025). As a result, LLM inference throughput degrades with larger contexts, limiting their applicability in scenarios demanding high throughput and low latency, such as web-scale discovery. Therefore, developing novel model architectures that optimize memory usage and inference latency is crucial for enhancing the practicality of contextual learning in these applications. | 大型语言模型(LLMs)在上下文学习方面展现出了令人瞩目的能力,能够利用输入中的信息在一系列下游应用中取得卓越表现。例如,在多轮对话中(Roller 等人,2021 年;Zhang 等人,2020 年),将历史对话纳入上下文能使 LLM 更有效地回应用户提问。在检索增强生成(RAG)中(Guu 等人,2020 年;Izacard 等人,2022 年),LLM 通过利用从外部来源检索到的相关搜索结果生成更准确的答案。这些例子凸显了 LLM 从上下文中学习的能力。然而,众所周知,为上下文学习增加提示长度会导致推理时的延迟增加和内存消耗增大(Yen 等人,2024 年)。具体而言,更长的提示需要更多的内存来存储键值(KV)缓存,其与提示长度呈线性关系。此外,首次生成标记的时间(TTFT)延迟呈二次方增长,而迭代生成标记的时间(TTIT)延迟则与提示长度呈线性增长(Liu 等人,2025 年)。因此,随着上下文的增大,LLM 的推理吞吐量会下降,这限制了它们在需要高吞吐量和低延迟的场景中的应用,例如网络规模的发现。因此,开发能够优化内存使用和推理延迟的新模型架构对于提高这些应用中上下文学习的实用性至关重要。 |
| Optimizing inference latency for LLMs with extensive context is an active area of research, with approaches ranging from modifying the attention mechanism’s complexity (Beltagy et al., 2020) to sparsifying attention and context (Child et al., 2019; Xiao et al., 2024; Jiang et al., 2024), and altering context feeding strategies (Yen et al., 2024). However, most existing methods target generic LLM tasks with long context and are largely orthogonal to our work. This paper focuses on RAG-based applications, such as web-scale search, with the goal of improving inference latency, specifically, the TTFT. We argue that specialized techniques exploiting the unique structure and sparsity inherent in RAG contexts can substantially reduce memory and computational overhead. Treating RAG TTFT as a generic LLM inference problem overlooks several key aspects: 1) Inefficient Token Allocation. RAG contexts often contain sparse information, with many retrieved passages being uninformative and reused across multiple inferences. Allocating memory/computation for all the tokens, as we show in this paper, is unnecessarily wasteful. 2) Wasteful Encoding and Other Information. The retrieval process in RAG has already pre-processed the chunks of the contexts, and their encodings and other correlations with the query are already available due to the use of vectorizations and re-rankings. This information is discarded during decoding. 3) Unusually Structured and Sparse Attention. Due to diversity and other operations such as deduplication, most context chunks during decoding are unrelated, resulting in predominantly zero cross-attention between chunks (see figure˜7). | 针对具有大量上下文的 LLM 优化推理延迟是一个活跃的研究领域,方法包括从修改注意力机制的复杂性(Beltagy 等人,2020 年)到稀疏化注意力和上下文(Child 等人,2019 年;Xiao 等人,2024 年;Jiang 等人,2024 年),以及改变上下文输入策略(Yen 等人,2024 年)。然而,大多数现有的方法针对的是具有长上下文的通用 LLM 任务,并且与我们的工作基本无关。本文重点关注基于 RAG 的应用,例如网络规模的搜索,旨在提高推理延迟,特别是 TTFT。我们认为,利用 RAG 上下文固有的独特结构和稀疏性,可以大幅减少内存和计算开销的专门技术是可行的。将 RAG TTFT 视为一般的 LLM 推理问题会忽略几个关键方面:1)不合理的标记分配。RAG 上下文通常包含稀疏信息,许多检索到的段落无用且在多次推理中重复使用。正如我们在本文中所展示的,为所有标记分配内存/计算是不必要的浪费。2)编码及其他信息的浪费。RAG 中的检索过程已经对上下文的片段进行了预处理,由于使用了向量化和重新排序,这些片段的编码以及它们与查询的其他关联信息已经可用,但在解码过程中却被丢弃。3)结构异常且稀疏的注意力机制。由于多样性以及去重等操作,解码过程中大多数上下文块之间互不相关,导致块之间的交叉注意力主要为零(见图 7)。 |
1.1 Our Contributions
| We propose REFRAG (REpresentation For RAG), a novel mechanism for efficient decoding of contexts in RAG. REFRAG significantly reduces latency, TTFT, and memory usage during decoding, all without requiring modifications to the LLM architecture or introducing new decoder parameters. REFRAG makes several novel modifications to the decoding process: Instead of using tokens from retrieved passages as input, REFRAG leverages pre-computed, compressed chunk embeddings as approximate representations, feeding these embeddings directly into the decoder. This approach offers three main advantages: 1) It shortens the decoder’s input length, improving token allocation efficiency; 2) It enables reuse of pre-computed chunk embeddings from retrieval, eliminating redundant computation; and 3) It reduces attention computation complexity, which now scales quadratically with the number of chunks rather than the number of tokens in the context. Unlike prior methods (Yen et al., 2024), REFRAG supports compression of token chunks at arbitrary positions (see figure˜1) while preserving the autoregressive nature of the decoder, thereby supporting multi-turn and agentic applications. This “compress anywhere” capability is further enhanced by a lightweight reinforcement learning (RL) policy that selectively determines when full chunk token input is necessary and when low-cost, approximate chunk embeddings suffice . As a result, REFRAG minimizes reliance on computationally intensive token embeddings, condensing most chunks for the query in RAG settings. We provide rigorous experimental validations of the effectiveness of REFRAG in continual pre-training and many real word long-context applications including RAG, multi-turn conversation with RAG and long document summarization. Results show that we achieve 30.75 × TTFT acceleration without loss in perplexity which is 3.75 × than previous method. Moreover, with extended context due to our compression, REFRAG achieves better performance than LLaMA without incurring higher latency in the downstream applications. | 我们提出了 REFRAG(用于 RAG 的表示),这是一种用于 RAG 中高效上下文解码的新机制。REFRAG 显著降低了解码过程中的延迟、TTFT(首次响应时间)和内存使用量,且无需对 LLM 架构进行修改或引入新的解码器参数。 REFRAG 对解码过程进行了几项创新性修改:它不使用检索到的段落中的标记作为输入,而是利用预先计算的、压缩的段落嵌入作为近似表示,直接将这些嵌入输入解码器。这种方法具有三个主要优势:1)缩短了解码器的输入长度,提高了标记分配效率;2)能够复用检索中预先计算的段落嵌入,避免了冗余计算;3)降低了注意力计算的复杂度,现在其复杂度与段落数量的平方成正比,而非上下文中的标记数量。与先前的方法(Yen 等人,2024 年)不同,REFRAG 支持在任意位置压缩标记段落(见图 1),同时保持了解码器的自回归特性,从而支持多轮对话和代理应用。这种“任意压缩”的能力通过一种轻量级的强化学习(RL)策略得到了进一步增强,该策略能够有选择地确定何时需要完整的分块标记输入,何时低成本的近似分块嵌入就足够了。因此,REFRAG 减少了对计算密集型标记嵌入的依赖,在 RAG 设置中为查询压缩了大部分分块。 我们提供了严格的实验验证,证明了 REFRAG 在持续预训练和许多现实世界的长上下文应用(包括 RAG、RAG 中的多轮对话和长文档摘要)中的有效性。结果表明,我们实现了 30.75 倍的 TTFT 加速,且困惑度没有损失,这比之前的方法快 3.75 倍。此外,由于我们的压缩带来了更长的上下文,REFRAG 在下游应用中实现了比 LLaMA 更好的性能,且没有增加更高的延迟。 |
2 Model Architecture
Figure 1:The main design of REFRAG. The input context is chunked and processed by the light-weight encoder to produce chunk embeddings, which are precomputable for efficient reuse. A light-weight RL policy decide few chunks to expand. These chunk embeddings along with the token embeddings of the question input are fed to the decoder.图 1:REFRAG 的主要设计。输入上下文被分块并由轻量级编码器处理以生成分块嵌入,这些嵌入可预先计算以实现高效复用。轻量级强化学习策略决定扩展少量分块。这些分块嵌入与问题输入的标记嵌入一起被送入解码器。
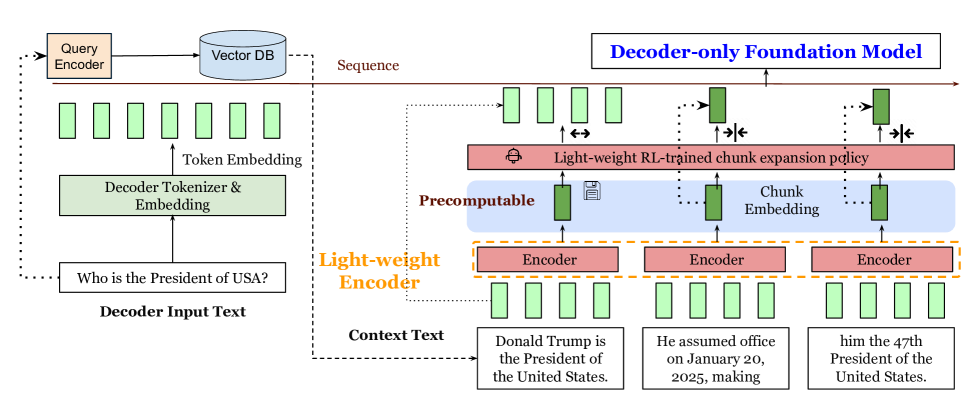
| We denote the decoder model as ℳdec and the encoder model as ℳenc. Given an input with T tokens x1,x2,…,xT, we assume that the first q tokens are main input tokens (e.g., questions) and the last s tokens are context tokens (e.g., retrieved passages in RAG). We have q+s=T. For clarity, we focus on a single turn of question and retrieval in this section. Model overview. Figure˜1 shows the main architecture of REFRAG. This model consists of a decoder-only foundation model (e.g., LLaMA (Touvron et al., 2023)) and a lightweight encoder model (e.g., Roberta (Liu et al., 2019)). When given a question x1,…,xq and context xq+1,…,xT and , the context is chunked into L≔sk number of k-sized chunks {C1,…,CL} where Ci={xq+k∗i,…,xq+k∗i+k−1}. The encoder model then processes all the chunks to obtain a chunk embedding for each chunk ��i=ℳenc(Ci). This chunk embedding is then projected with a projection layer ϕ to match the size of the token embedding of the decoder model, ��icnk=ϕ(��i). These projected chunk embeddings are then fed to the decoder model along with the token embeddings for the question to generate the answer y∼ℳdec({��1,…,��q,��1cnk,…,��Lcnk}) where ��i is the token embedding for token xi. In real applications (e.g., RAG), the context is the dominating part of the input (i.e., s≫q) and hence the overall input to the decoder will be reduced by a factor of ≃k. This architectural design leads to significant reductions in both latency and memory usage, primarily due to the shortened input sequence. Additionally, an RL policy is trained to do selective compression to further improve the performance which we will defer the discussion to section˜2. Next, we analyze the system performance gains achieved with a compression rate of k. | 我们将解码器模型记为 ℳdec,编码器模型记为 ℳenc。给定一个包含 T 个标记 x1,x2,...,xT 的输入,我们假设前 q 个标记是主要输入标记(例如,问题),后 s 个标记是上下文标记(例如,RAG 中检索到的段落)。我们有 q+s=T。为清晰起见,本节重点关注一轮问题和检索。 模型概述。图 1 展示了 REFRAG 的主要架构。该模型由一个仅解码器的基础模型(例如,LLaMA(Touvron 等人,2023))和一个轻量级编码器模型(例如,Roberta(Liu 等人,2019))组成。当给定一个问题 x1,...,xq 和上下文 xq+1,...,xT 时,上下文被分成 L ≔ sk 个大小为 k 的分块 {C1,...,CL},其中 Ci = {xq + k * i,...,xq + k * i + k - 1}。编码器模型接着处理所有分块以获取每个分块的分块嵌入,即 ��i=ℳenc(Ci)。然后,该分块嵌入通过投影层 ϕ 进行投影,以匹配解码器模型的标记嵌入大小,即 ��icnk=ϕ(��i)。这些投影后的分块嵌入与问题的标记嵌入一起被输入到解码器模型中,以生成答案 y∼ℳdec({��1,...,��q,��1cnk,...,��Lcnk}),其中 ��i 是标记 xi 的标记嵌入。在实际应用(例如 RAG)中,上下文是输入的主要部分(即 s≫q),因此解码器的整体输入将减少约 k 倍。这种架构设计主要由于输入序列缩短,从而显著降低了延迟和内存使用。此外,还训练了一个强化学习策略来进行选择性压缩以进一步提高性能,我们将在第 2 节中详细讨论。接下来,我们分析压缩率为 k 时系统性能的提升。 |
| Latency and throughput improvement. We evaluate three metrics: TTFT, the latency to generate the first token; TTIT, the time to generate each subsequent token; and Throughput, the number of tokens generated per unit time. Theoretical analysis (section˜9) shows that for short context lengths, our method achieves up to k× acceleration in TTFT and throughput. For longer context length, acceleration reaches up to k2× for both metrics. Empirically, as shown in figure˜2, with a context length of 16384 (mid-to-long context), REFRAG with k=16 achieves 16.53× TTFT acceleration with cache and 8.59× without cache1, both surpassing CEPE (2.01× and 1.04×, respectively), while achieving 9.3% performance (measured by perplexity) compared to CEPE (table˜1). We achieve up to 6.78× throughput acceleration compared to LLaMA, significantly outperforming CEPE. With k=32, TTFT acceleration reaches 32.99× compared to LLaMA (3.75× compared to CEPE) while maintaining similar performance to CEPE (see figure˜8 and table˜2). More detailed discussion on empirical evaluation is in section˜9. | 延迟和吞吐量的改进。我们评估了三个指标:TTFT(生成第一个标记的延迟)、TTIT(生成每个后续标记的时间)以及吞吐量(单位时间内生成的标记数量)。理论分析(第 9 节)表明,对于短上下文长度,我们的方法在 TTFT 和吞吐量方面实现了高达 k 倍的加速。对于较长的上下文长度,这两个指标的加速分别达到了 k² 倍。从经验来看,如图 2 所示,在上下文长度为 16384(中长上下文)的情况下,k = 16 的 REFRAG 在使用缓存时实现了 16.53 倍的 TTFT 加速,在不使用缓存时实现了 8.59 倍的加速,均超过了 CEPE(分别为 2.01 倍和 1.04 倍),同时性能(以困惑度衡量)与 CEPE 相比仅下降了 9.3%(见表 1)。与 LLaMA 相比,我们实现了高达 6.78 倍的吞吐量加速,显著优于 CEPE。当 k = 32 时,与 LLaMA 相比,TTFT 加速达到了 32.99 倍(与 CEPE 相比为 3.75 倍),同时性能与 CEPE 相当(见图 8 和表 2)。关于经验评估的更多详细讨论在第 9 节。 |
Figure 2:Empirical verification of inference acceleration of REFRAG with k=16.图 2:REFRAG 在 k=16 时推理加速的实证验证。
Conclusion
| In this work, we introduced REFRAG, a novel and efficient decoding framework tailored for RAG applications. By leveraging the inherent sparsity and block-diagonal attention patterns present in RAG contexts, REFRAG compresses, senses, and expands context representations to significantly reduce both memory usage and inference latency, particularly the TTFT. Extensive experiments across a range of long-context applications, including RAG, multi-turn conversations, and long document summarization, demonstrate that REFRAG achieves up to 30.85× TTFT acceleration (3.75× over previous state-of-the-art methods) without any loss in perplexity or downstream accuracy. Our results highlight the importance of specialized treatment for RAG-based systems and open new directions for efficient large-context LLM inference. We believe that REFRAG provides a practical and scalable solution for deploying LLMs in latency-sensitive, knowledge-intensive applications. | 在本研究中,我们提出了 REFRAG,这是一种专为 RAG 应用设计的新型高效解码框架。通过利用 RAG 上下文中固有的稀疏性和块对角注意力模式,REFRAG 对上下文表示进行压缩、感知和扩展,从而显著降低了内存使用量和推理延迟,尤其是 TTFT。在包括 RAG、多轮对话和长文档摘要在内的各种长上下文应用中进行的大量实验表明,REFRAG 实现了高达 30.85 倍的 TTFT 加速(比之前的最先进方法快 3.75 倍),同时在困惑度或下游准确性方面没有任何损失。我们的结果突显了针对基于 RAG 的系统进行专门处理的重要性,并为高效的大上下文 LLM 推理开辟了新的方向。我们相信,REFRAG 为在延迟敏感、知识密集型应用中部署 LLM 提供了一种实用且可扩展的解决方案。 |