Android音频学习(十七)——音频数据流转
上一节主要讲解了通过应用下发属性参数找到对应的output,output与playbackThread是一一对应的,AudioFlinger创建PlaybackThread后,通过mPlaybackThreads.add(*output, thread)将output 和 PlaybackThread 添加到键值对向量 mPlaybackThreads 中,由于 output 和 PlaybackThread 是一一对应的关系,因此拿到一个 output,就能遍历键值对向量 mPlaybackThreads 找到它对应的 PlaybackThread,可以简单理解 output为 PlaybackThread 的索引号或线程 id。
找到output后,就可以找到音频传递数据的个PlaybackThread线程,这个线程相当于一个中间角色,应用层进程将音频数据以匿名共享内存方式传递给PlaybackThread,而PlaybackThread也是以匿名共享内存方式传递数据给HAL层。下面重点看下AudioTrack与AudioFlinger的共享内存是如何创建并使用的。
上一章节讲到在createTrack时最终会调用到 track = new Track()创建track,Track继承于TrackBase,在TrackBase的构造函数中申请了一块共享内存
AudioFlinger::ThreadBase::TrackBase::TrackBase{size_t minBufferSize = buffer == NULL ? roundup(frameCount) : frameCount;// check overflow when computing bufferSize due to multiplication by mFrameSize.if (minBufferSize < frameCount // roundup rounds down for values above UINT_MAX / 2|| mFrameSize == 0 // format needs to be correct|| minBufferSize > SIZE_MAX / mFrameSize) {android_errorWriteLog(0x534e4554, "34749571");return;}minBufferSize *= mFrameSize;if (buffer == nullptr) {bufferSize = minBufferSize; // allocated here.} else if (minBufferSize > bufferSize) {android_errorWriteLog(0x534e4554, "38340117");return;}size_t size = sizeof(audio_track_cblk_t);if (buffer == NULL && alloc == ALLOC_CBLK) {// check overflow when computing allocation size for streaming tracks.if (size > SIZE_MAX - bufferSize) {android_errorWriteLog(0x534e4554, "34749571");return;}size += bufferSize;}if (client != 0) {mCblkMemory = client->heap()->allocate(size);if (mCblkMemory == 0 ||(mCblk = static_cast<audio_track_cblk_t *>(mCblkMemory->unsecurePointer())) == NULL) {ALOGE("%s(%d): not enough memory for AudioTrack size=%zu", __func__, mId, size);client->heap()->dump("AudioTrack");mCblkMemory.clear();return;}} else {mCblk = (audio_track_cblk_t *) malloc(size);if (mCblk == NULL) {ALOGE("%s(%d): not enough memory for AudioTrack size=%zu", __func__, mId, size);return;}}// construct the shared structure in-place.if (mCblk != NULL) {new(mCblk) audio_track_cblk_t();switch (alloc) { case ALLOC_CBLK:// clear all buffersif (buffer == NULL) {mBuffer = (char*)mCblk + sizeof(audio_track_cblk_t);memset(mBuffer, 0, bufferSize);} else {mBuffer = buffer;
#if 0mCblk->mFlags = CBLK_FORCEREADY; // FIXME hack, need to fix the track ready logic
#endif}......}mBufferSize = bufferSize;}client是在AudioFlinger中创建的:
client = registerPid(clientPid);
--->client = new Client(this, pid);
AudioFlinger::Client::Client(const sp<AudioFlinger>& audioFlinger, pid_t pid): RefBase(),mAudioFlinger(audioFlinger),mPid(pid)
{mMemoryDealer = new MemoryDealer(audioFlinger->getClientSharedHeapSize(),(std::string("AudioFlinger::Client(") + std::to_string(pid) + ")").c_str());
}
MemoryDealer是Android 提供的一个内存分配的工具类 ,用于管理内存堆,注意该类是不具备跨进程通信能力的,它仅在服务端工作。MemoryDealer的构造函数中,会创建一个MemoryHeapBase和一个SimpleBestFitAllocator对象。
MemoryDealer::MemoryDealer(size_t size, const char* name)
: mHeap(new MemoryHeapBase(size, 0, name)),
mAllocator(new SimpleBestFitAllocator(size))
{
}
MemoryHeapBase构造函数如下:
MemoryHeapBase::MemoryHeapBase(size_t size, uint32_t flags, char const * name): mFD(-1), mSize(0), mBase(MAP_FAILED), mFlags(flags),mDevice(nullptr), mNeedUnmap(false), mOffset(0)
{const size_t pagesize = getpagesize();size = ((size + pagesize-1) & ~(pagesize-1));int fd = ashmem_create_region(name == nullptr ? "MemoryHeapBase" : name, size);ALOGE_IF(fd<0, "error creating ashmem region: %s", strerror(errno));if (fd >= 0) {if (mapfd(fd, size) == NO_ERROR) {if (flags & READ_ONLY) {ashmem_set_prot_region(fd, PROT_READ);}}}
}先调用Ashmem提供的函数库函数ashmem_create_region()完成匿名内存的创建,接着调用mapfd将匿名内存映射至本进程(这里的本进程是AudioFlinger所在的system_server进程)。至此完成了前文实现共享内存的步骤1和步骤2。 SimpleBestFitAllocator负责记录MemoryHeapBase的分块(已经分配了多少块),辅助完成Allocation(继承自MemoryBase)的构造。
SimpleBestFitAllocator构造函数代码如下:
SimpleBestFitAllocator::SimpleBestFitAllocator(size_t size)
{size_t pagesize = getpagesize();mHeapSize = ((size + pagesize-1) & ~(pagesize-1));chunk_t* node = new chunk_t(0, mHeapSize / kMemoryAlign);mList.insertHead(node);
}创建一个chunk_t,插入mList,chunk_t大小是size/kMemoryAlign。后续随着AudioTrack的创建,会把chunk_t拆分成更小的chunk_t。
再回到TrackBase, client->heap()->allocate返回mCblkMemory,返回值类型是IMemory。
mBuffer = (char*)mCblk + sizeof(audio_track_cblk_t);这里的mBuffer则是传输音频数据的共享内存的首地址,为申请内存地址加上数据结构audio_track_cblk_t的偏址,
| |
| -------------------> mCblkMemory <--------------------- |
| |
+--------------------+------------------------------------+
| audio_track_cblk_t | FIFO |
+--------------------+------------------------------------+
^ ^
| |
mCblk mBuffer
以上为申请共享内存的流程,下面看下客户端和服务端是如何使用共享内存的。
首先看服务端:
在创建track对象时,调用其构造函数,将会创建服务端代理对象mAudioTrackServerProxy,它负责管理与同步匿名共享内存的使用,shareBuffer是应用下发的参数,为0是MODE_STREAM模式,mBuffer为以上介绍的共享内存地址,不为0则是MODE_STATIC模式,mBuffer为应用传过来的内存地址。
AudioFlinger::PlaybackThread::Track::Track:TrackBase{
...... if (sharedBuffer == 0) {mAudioTrackServerProxy = new AudioTrackServerProxy(mCblk, mBuffer, frameCount,mFrameSize, !isExternalTrack(), sampleRate);} else {mAudioTrackServerProxy = new StaticAudioTrackServerProxy(mCblk, mBuffer, frameCount,mFrameSize, sampleRate);}mServerProxy = mAudioTrackServerProxy;
......
}再看客户端
status_t AudioTrack::createTrack_l()
{
......sp<IAudioTrack> track = audioFlinger->createTrack(input,output,&status);sp<IMemory> iMem = track->getCblk();if (iMem == 0) {ALOGE("%s(%d): Could not get control block", __func__, mPortId);status = NO_INIT;goto exit;}......mAudioTrack = track;mCblkMemory = iMem; ......void *iMemPointer = iMem->unsecurePointer();if (iMemPointer == NULL) {ALOGE("%s(%d): Could not get control block pointer", __func__, mPortId);status = NO_INIT;goto exit;}......// Starting address of buffers in shared memory. If there is a shared buffer, buffers// is the value of pointer() for the shared buffer, otherwise buffers points// immediately after the control block. This address is for the mapping within client// address space. AudioFlinger::TrackBase::mBuffer is for the server address space.void* buffers;if (mSharedBuffer == 0) {buffers = cblk + 1;} else {// TODO: Using unsecurePointer() has some associated security pitfalls// (see declaration for details).// Either document why it is safe in this case or address the// issue (e.g. by copying).buffers = mSharedBuffer->unsecurePointer();if (buffers == NULL) {ALOGE("%s(%d): Could not get buffer pointer", __func__, mPortId);status = NO_INIT;goto exit;}}......if (mSharedBuffer == 0) {mStaticProxy.clear();mProxy = new AudioTrackClientProxy(cblk, buffers, mFrameCount, mFrameSize);} else {mStaticProxy = new StaticAudioTrackClientProxy(cblk, buffers, mFrameCount, mFrameSize);mProxy = mStaticProxy;}
......
}
先通过getCblk就是获取服务端TrackBase的mCblkMemory成员,即共享内存的总管理,再通过unsecurePointer获取分配内存映射的首地址,首地址是一个audio_track_cblk_t成员,所以buffer的地址要+1。
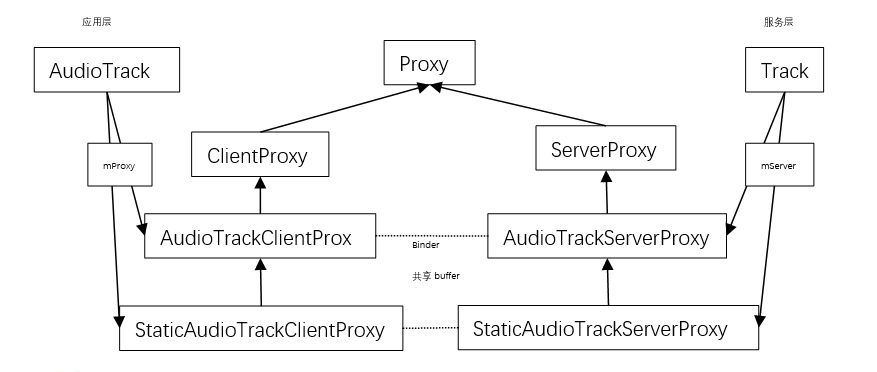
clientProxy与ServerProxy之间通信方式是Binder通信IPC,他们通信的内容就是匿名共享内存的信息,怎么写入,写入到哪个地方等;音频数据读写走的是下面的匿名共享内存buffer。
应用层往共享内存写数据:
应用下发write方法时调用obtainbuffer(),该方法主要是获取可写入数据的剩余空间地址,并更新指针便于下次写入。
ssize_t AudioTrack::write(const void* buffer, size_t userSize, bool blocking)
{...while (userSize >= mFrameSize) {audioBuffer.frameCount = userSize / mFrameSize;status_t err = obtainBuffer(&audioBuffer,blocking ? &ClientProxy::kForever : &ClientProxy::kNonBlocking);if (err < 0) {if (written > 0) {break;}if (err == TIMED_OUT || err == -EINTR) {err = WOULD_BLOCK;}return ssize_t(err);}size_t toWrite = audioBuffer.size;memcpy(audioBuffer.i8, buffer, toWrite);buffer = ((const char *) buffer) + toWrite;userSize -= toWrite;written += toWrite;releaseBuffer(&audioBuffer);}...
}再看服务端,应用写入数据前会调用start()方法,该方法调用mAudioTrack的start,即调用到服务端的track->start方法,该方法首先将track加入到队列中,然后给AudioFlinger的PlaybackThread线程发送消息,让PlaybackThread线程开始播放,就会调用PlaybackThread线程的主函数AudioFlinger::PlaybackThread::threadLoop

在threadLoop中,调用了threadLoop_mix和threadLoop_write。
如果是DirectOutputThread,则不需要混音,把数据直接拷贝到curBuf,即mSinkBuffer中即可。
void AudioFlinger::DirectOutputThread::threadLoop_mix()
{size_t frameCount = mFrameCount;int8_t *curBuf = (int8_t *)mSinkBuffer;// output audio to hardwarewhile (frameCount) {AudioBufferProvider::Buffer buffer;buffer.frameCount = frameCount;status_t status = mActiveTrack->getNextBuffer(&buffer);if (status != NO_ERROR || buffer.raw == NULL) {// no need to pad with 0 for compressed audioif (audio_has_proportional_frames(mFormat)) {memset(curBuf, 0, frameCount * mFrameSize);}break;}memcpy(curBuf, buffer.raw, buffer.frameCount * mFrameSize);frameCount -= buffer.frameCount;curBuf += buffer.frameCount * mFrameSize;mActiveTrack->releaseBuffer(&buffer);}mCurrentWriteLength = curBuf - (int8_t *)mSinkBuffer;mSleepTimeUs = 0;mStandbyTimeNs = systemTime() + mStandbyDelayNs;mActiveTrack.clear();
}如果是MixThread,则需要先进行混音,调用mAudio->process,下一章再具体说明。
void AudioFlinger::MixerThread::threadLoop_mix()
{// mix buffers...mAudioMixer->process();mCurrentWriteLength = mSinkBufferSize;// increase sleep time progressively when application underrun condition clears.// Only increase sleep time if the mixer is ready for two consecutive times to avoid// that a steady state of alternating ready/not ready conditions keeps the sleep time// such that we would underrun the audio HAL.if ((mSleepTimeUs == 0) && (sleepTimeShift > 0)) {sleepTimeShift--;}mSleepTimeUs = 0;mStandbyTimeNs = systemTime() + mStandbyDelayNs;//TODO: delay standby when effects have a tail}最后,再通过threadLoop_write将数据写入到HAL层,再到驱动,最后通过音频接口硬件输出声音,这一步流程后续再详细说明。
