不连续页分配器补充
vmalloc流程
1. 背景:vmalloc() 要解决的问题
kmalloc()要求 虚拟地址连续,物理页也连续。大块内存分配可能失败。vmalloc()只保证 虚拟地址连续,物理内存可以由很多不连续的页拼接。
实现的关键就是:
- 在 vmalloc 区域 找一块空闲的虚拟地址。
- 分配若干物理页(可能不连续)。
- 建立虚拟地址 → 物理页的映射。
这三个步骤里,数据结构的角色就是:
**vmap_area**:负责管理 vmalloc 区域里的虚拟地址范围。**vm_struct**:描述一个具体的 vmalloc 内存块(和用户返回的addr对应)。
2. 关键数据结构解析
struct vmap_area
表示 vmalloc 区域中的一个虚拟地址段。
struct vmap_area {unsigned long va_start;unsigned long va_end;unsigned long flags;struct rb_node rb_node; /* address sorted rbtree */struct list_head list; /* address sorted list */struct llist_node purge_list; /* "lazy purge" list */struct vm_struct *vm;struct rcu_head rcu_head;
};
- 内核全局维护一棵红黑树和链表来管理所有的
vmap_area,保证虚拟地址分配不冲突。 - 每次
vmalloc()会新建一个vmap_area,挂到这棵树里。
struct vm_struct
表示 一个具体的 vmalloc 块,用户代码拿到的就是 vm_struct->addr。
struct vm_struct {struct vm_struct *next;void *addr;unsigned long size;unsigned long flags;struct page **pages;unsigned int nr_pages;phys_addr_t phys_addr;const void *caller;
};
**pages[]**** 是核心**:记录了 vmalloc 这片区域实际映射到哪些物理页。addr是vmap_area->va_start,两者一一对应。vm_struct通过vmap_area->vm与虚拟地址区间关联。
3. vmalloc() 的流程
以 vmalloc(size) 为例,流程大致是:
(1) 计算所需页数
nr_pages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;
(2) 在 vmalloc 区域找虚拟地址
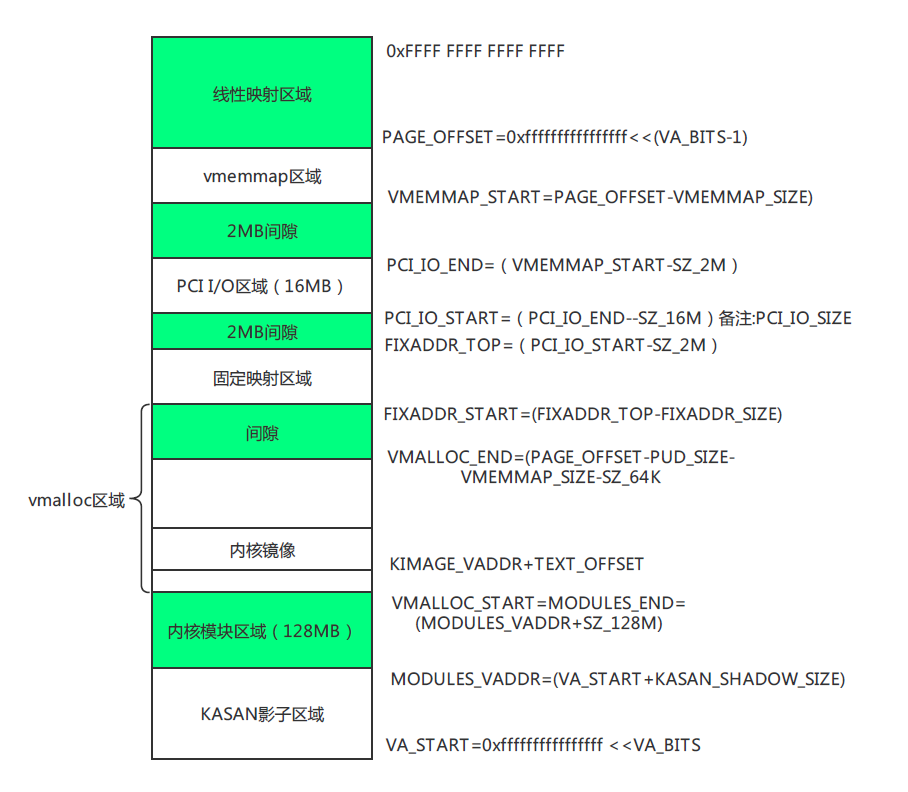
- 调用
alloc_vmap_area():- 通过 红黑树,在vmalloc区域中查找一块足够大的空闲虚拟地址区间;
- 建立一个新的
struct vmap_area,填好va_start/va_end; - 挂到全局红黑树/链表里。
这一步解决:虚拟地址空间的分配。
(3) 分配物理页
- 调用
alloc_page()(实际走伙伴系统),分配nr_pages个物理页。 - 这些页可能离散。
- 把它们存进
vm_struct->pages[]。
这一步解决:物理内存的获取。
(4) 建立映射
- 调用
map_vm_area()或更底层的vmap_page_range():- 遍历
pages[]; - 在页表里把
va_start ~ va_end的虚拟页,依次映射到对应的物理页。
- 遍历
这样,就实现了 虚拟地址连续 → 物理页不连续 的映射。
如何找到内核线程的页表?后面解释
(5) 返回给用户
vm_struct->addr = (void *)vmap_area->va_start- 返回给调用者。
调用者得到的是一段看起来“连续”的内存。
4. vmalloc() 与 vmap() 的关系
vmalloc()= 自动分配物理页 + 申请虚拟地址 + 调用 vmap 建立映射。vmap(pages[], nr_pages, ...)= 自己提供物理页数组,直接建立虚拟映射。
所以:
**vmalloc()**** 面向使用者**(只要给我一段内存);**vmap()**** 面向更底层**(我已有页,帮我拼接)。
5. 小结
vmalloc() 的机制可以归纳为三步:
- 地址管理:
vmap_area负责在 vmalloc 区域找一段空闲虚拟地址,并放到全局红黑树。 - 块描述:
vm_struct保存这段虚拟内存的元数据(起始地址、大小、物理页数组)。 - 页表映射:
把虚拟地址区间映射到vm_struct->pages[]里记录的实际物理页。
vfree释放过程
当 vfree() 被调用时:
- 根据
addr找到对应的vmap_area。 - 从红黑树和链表删除。
- 把物理页释放回伙伴系统。
- 延迟释放
vmap_area(放到purge_list,用 RCU 机制安全回收)。
linux中常用内存分配函数
用户态 vs 内核态
- 用户态 API:
malloc(),brk(),mmap()
这是 C 库(glibc)或系统调用提供的接口,进程使用。
本质上是通过 VMA 管理 + 缺页时分配物理页。 - 内核态 API:
alloc_pages(),kmalloc(),vmalloc()
这是 Linux 内核给自己用的内存分配器接口,驱动/内核子系统用。
本质上是 直接操作伙伴系统/SLAB/vmalloc 子系统。
各方法机制对比
| 接口 | 使用场景 | 内核实现方式 | 地址连续性 | 使用者 |
|---|---|---|---|---|
| malloc() | 用户程序最常用的内存申请 | glibc 封装,底层调用 brk()或 mmap()扩展堆/映射匿名页 | 用户虚拟地址连续(物理不一定连续) | 用户空间 |
| brk() | 扩展/收缩 heap(sbrk系统调用) | 修改进程的堆 VMA 边界,缺页时由 alloc_pages()分配物理页 | 用户虚拟地址连续(物理不一定连续) | 用户空间 |
| mmap() | 大块内存/文件映射/共享内存 | 创建新的 VMA,缺页时用 alloc_pages()或从文件读取到物理页 | 用户虚拟地址连续(物理不一定连续) | 用户空间 |
| alloc_pages() | 分配页粒度内存 | 伙伴系统分配 struct page | 物理连续,内核虚拟地址也连续(线性映射区) | 内核 |
| kmalloc() | 内核小块内存(字节/KB 级) | SLAB/SLUB 分配器,底层基于 alloc_pages() | 物理连续 + 内核虚拟连续 | 内核 |
| vmalloc() | 内核大块内存(MB 级) | 从 vmalloc 区找虚拟地址区间,分配不连续物理页(底层基于alloc_pages()),建立页表映射 | 虚拟地址连续,物理地址不连续 | 内核 |
关系梳理
- 用户空间
malloc()→ 封装,可能走brk()或mmap();brk()/mmap()→ 修改mm_struct和 VMA;- 缺页时 → 最终用
alloc_pages()分配物理页。
- 内核空间
alloc_pages()→ 最底层接口,直接伙伴系统;kmalloc()→ 面向小对象,使用slab分配器,底层用alloc_pages();vmalloc()→ 面向大块虚拟地址空间,物理页不连续。底层用alloc_pages()。
总结
- 用户态用
malloc()(底层 brk/mmap),本质是修改虚拟内存布局,缺页时通过 **伙伴系统 ****alloc_pages()**分配物理页; - 内核态直接用
alloc_pages()、kmalloc()(小块)、vmalloc()(大块,物理不连续)。
如何找到内核线程的页表?
“内核线程没有用户空间”就会怀疑:那页表怎么办?是不是有个“内核专用页表”?
其实 Linux 内核线程并不是共享一个“内核页表”,而是借用普通进程的页表。
1. 页表的基本事实
- 在 x86/ARM 等架构上,CPU 访问内存都要走页表转换。页表的基地址存放在控制寄存器(x86 的
CR3,ARM64 的TTBR0/TTBR1)。 - Linux 设计:所有进程的页表都包含了同一份内核态映射(高地址部分的 linear mapping、vmalloc 等)。
- 换句话说,每个进程的
mm_struct->pgd不同,但其中“内核地址区”是一致的。 - 所以,只要有一份用户进程的页表,就能保证内核地址区始终可用。
- 换句话说,每个进程的
2. 普通进程 vs 内核线程
普通用户进程
- 每个进程有自己的
mm_struct,里面有独立的pgd(页全局目录)。 - 切换进程时,调度器会把
mm->pgd加载到CR3。 - 这样用户态地址空间不同,但内核态地址映射相同。
内核线程
task_struct->mm = NULL,说明它没有独立的mm_struct和pgd。- 调度器在切换到内核线程时:
- 如果发现
mm == NULL,会把prev->active_mm借给内核线程,保存到next->active_mm。 - 并且在切换时 不会切换 CR3,继续使用原进程的页表。
- 如果发现
- 内核线程只在内核态执行,不会访问用户空间地址,所以根本不在意用户空间页表部分。
3. 也就是说:
- 每个内核线程并没有单独的页表。
- 它们 借用上一个普通进程的页表,只是用其中的内核映射部分。
- 这就是
task_struct->active_mm的意义。
4. “内核页表”的保存与使用
- 并不存在一个独立的“全局内核页表”。
- 取而代之:每个进程的页表都自带了内核映射部分。
- 内核线程调度时,就继续使用借来的页表的内核部分。
总结
内核线程没有独立的页表,它们不会切换到某个“内核专用页表”。调度到内核线程时,Linux 内核会让它们 借用上一个进程的页表(通过 active_mm),只使用其中的内核地址映射部分。由于所有进程的内核区页表一致,内核线程就能安全运行。
测试验证
代码实现
实现一个最小可运行的 内核模块 示例,专门用来测试 vmalloc() 申请和释放内存。代码如下:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/vmalloc.h> // vmalloc/vfree
#include <linux/kernel.h>#define VMALLOC_SIZE (1024 * 1024) // 申请 1MBstatic void *vmalloc_area = NULL;static int __init vmalloc_test_init(void)
{pr_info("vmalloc_test: module loaded\n");// 使用 vmalloc 申请一块连续虚拟地址的内存vmalloc_area = vmalloc(VMALLOC_SIZE);if (!vmalloc_area) {pr_err("vmalloc_test: vmalloc failed!\n");return -ENOMEM;}pr_info("vmalloc_test: allocated %d bytes at %pK\n",VMALLOC_SIZE, vmalloc_area);// 写入测试数据memset(vmalloc_area, 0xAA, VMALLOC_SIZE);pr_info("vmalloc_test: memory initialized with 0xAA\n");return 0;
}static void __exit vmalloc_test_exit(void)
{if (vmalloc_area) {vfree(vmalloc_area);pr_info("vmalloc_test: freed memory at %pK\n", vmalloc_area);}pr_info("vmalloc_test: module unloaded\n");
}module_init(vmalloc_test_init);
module_exit(vmalloc_test_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("congchp");
MODULE_DESCRIPTION("Simple vmalloc test module");obj-m += vmalloc_test.oall:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modulesclean:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean测试结果
dmesg结果:

/proc/vmallocinfo结果:

参考资料
- Professional Linux Kernel Architecture,Wolfgang Mauerer
- Linux内核深度解析,余华兵
- Linux设备驱动开发详解,宋宝华
- linux kernel 4.12