C++三种对象实例化在栈或堆的区别
首先,要注意一下,后面说的是程序的栈和堆。
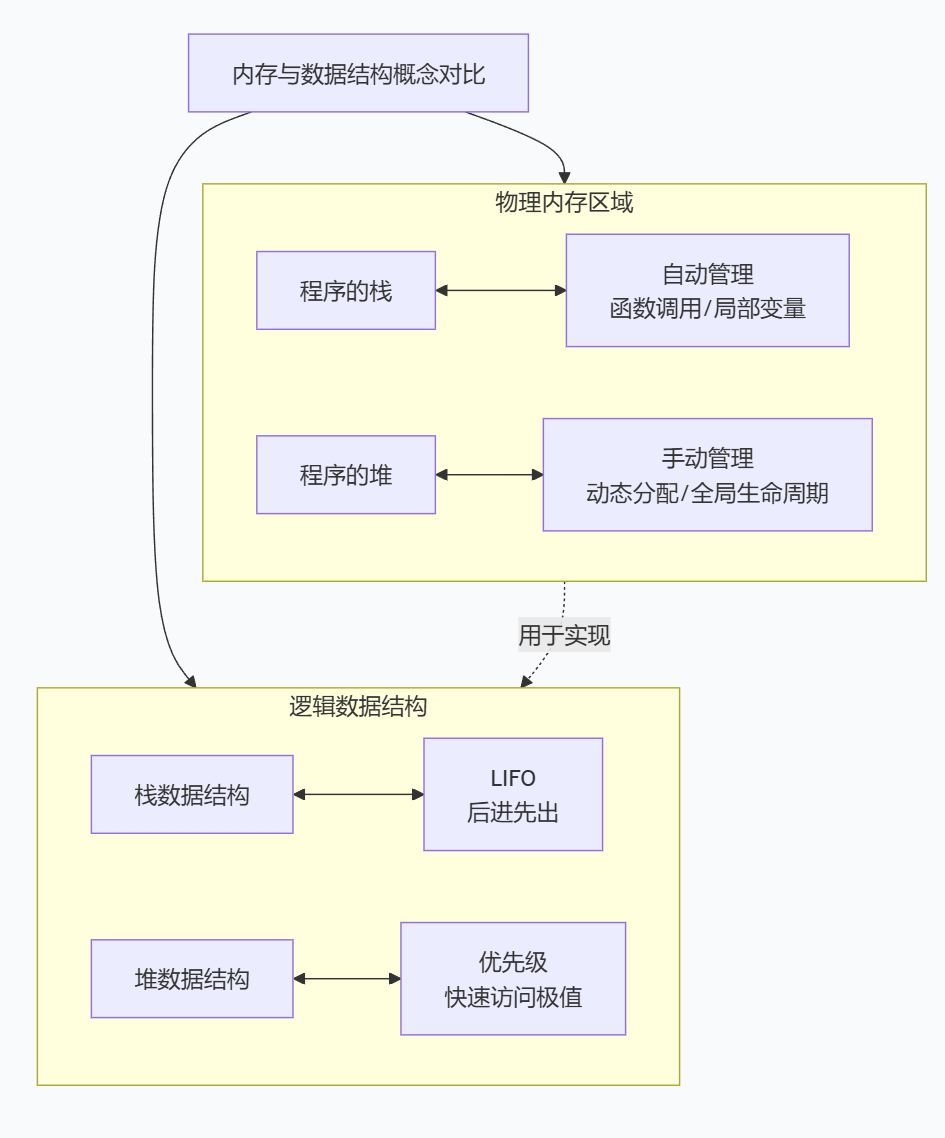
程序的堆栈是一个由系统自动管理的内存区域,是操作系统管理的内存区域,关乎“数据存在哪里”。而数据结构的堆栈是一种抽象的数据类型,是组织数据的逻辑方式,关乎“数据如何被访问”。这里要区分一下,我们常用前者来实现后者。
方式一:全部在栈上(推荐用于简单、生命周期短的对象)
void myFunction() {Dog myDog; // 1. 在栈上创建对象。调用构造函数。myDog.bark(); // 2. 使用对象本身访问成员
} // 3. 函数结束,栈帧弹出。myDog 的析构函数被自动调用,内存自动回收。
// 优点:绝对安全,无内存泄漏。性能高。
// 缺点:对象生命周期仅限于函数作用域内。无法用于多态。方式二:指针在栈,对象在堆(用于需要灵活控制生命周期或多态)
void myFunction() {Dog* myDogPtr = new Dog(); // 1. 在堆上创建对象,在栈上创建指针并指向它。myDogPtr->bark(); // 2. 使用指针(->)访问对象成员delete myDogPtr; // 3. 【必须手动】释放堆内存,调用析构函数。
} // 4. 函数结束,栈上的指针变量 myDogPtr 被自动销毁。
// 优点:对象生命周期由你控制,可以比函数更长久。可用于多态。
// 缺点:危险!容易忘记 delete 导致内存泄漏,或多次 delete 导致崩溃。方式三:现代C++的推荐方式(智能指针)
#include <memory>
void myFunction() {// 栈上的智能指针管理堆上的对象std::unique_ptr<Dog> myDogPtr = std::make_unique<Dog>();myDogPtr->bark();
} // 函数结束,栈上的 unique_ptr 被销毁,它会自动调用 delete 来清理它管理的堆上的 Dog 对象。
// 优点:兼具方式二的灵活性,又具备方式一的安全性(自动释放)。是现代C++的最佳实践。