Github项目推荐:Made-With-ML 机器学习工程学习指南
项目地址:
https://github.com/GokuMohandas/Made-With-ML
Made-With-ML 项目的核心人物是 Goku Mohandas,他是一位充满热情的机器学习工程师和教育家,致力于弥合学术机器学习知识与实际生产系统之间的鸿沟。凭借在各行各业开发机器学习应用的丰富经验,Goku 在过去四年中帮助数十家财富 500 强企业和初创公司构建稳健的机器学习平台并推出高影响力应用。
Goku 在机器学习领域的历程源于一个敏锐的观察:虽然学习机器学习理论的资源层出不穷,但专注于实际生产的教育却存在显著空白。这一认识促使他创建了 Made-With-ML,这是一个综合性教育平台,旨在教导开发者如何在生产环境中负责任地运用机器学习创造价值。
文章目录
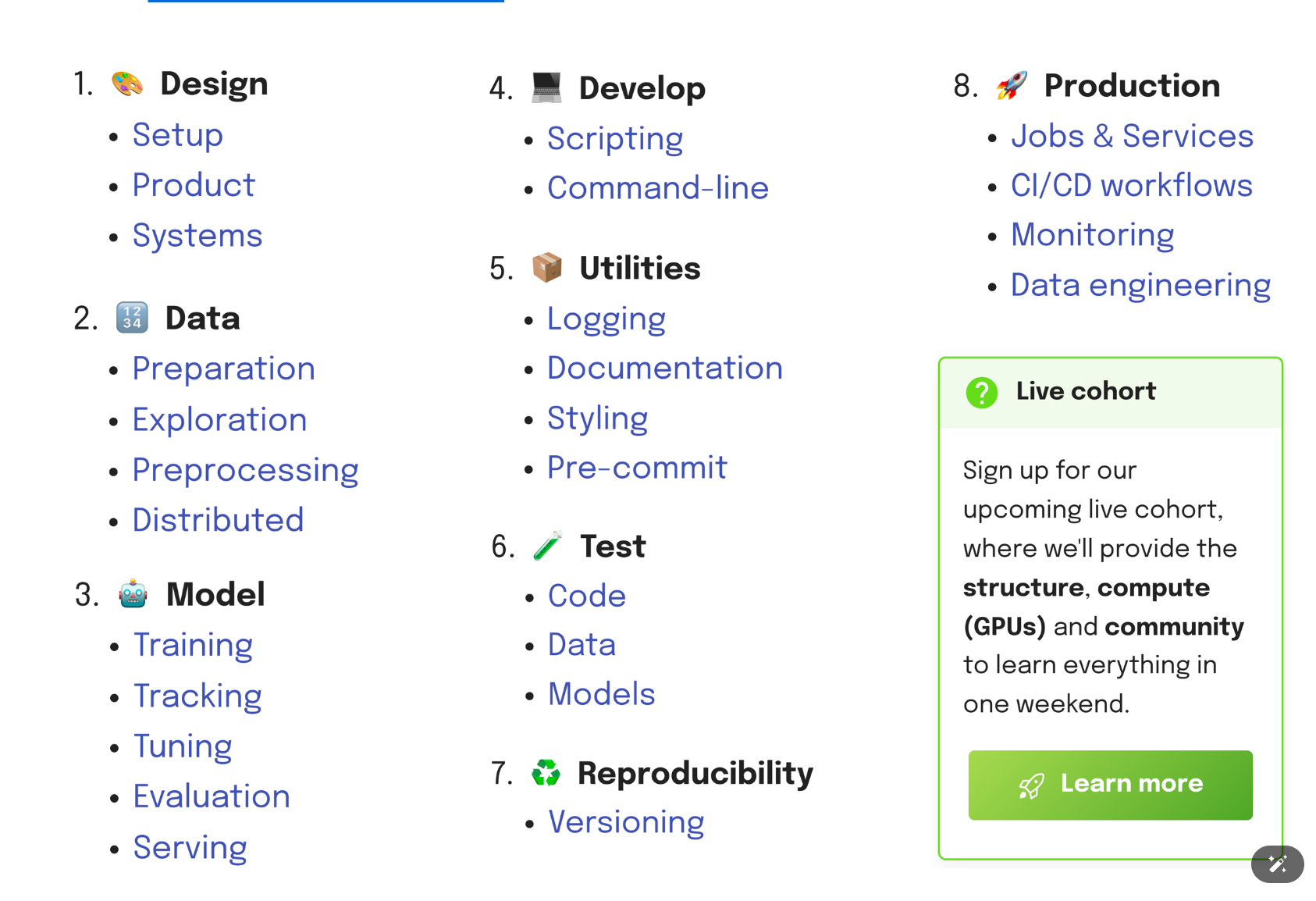
- 1 概述
- 1.1 适合人群
- 1.2 项目架构
- 1.3 生产部署
- 1.4 文档和测试
- 1.5 核心特性
- 1.5.1 端到端 ML 流水线
- 1.5.2 可扩展基础设施
- 1.5.3 MLOps 集成
- 1.6 入门指南
1 概述
欢迎使用 Made With ML,这是一个全面的代码库,教你如何从设计到部署构建生产级的机器学习应用。本项目既是教育资源,也是实践实施指南,将机器学习与软件工程最佳实践相结合。
Made With ML 是一个开源项目,指导开发者完成从初始实验到生产部署的完整机器学习生命周期。该项目旨在帮助你理解如何通过遵循行业最佳实践的全端到端系统,可靠地利用 ML 创造价值。
该代码库遵循明确的设计理念:先理解基本原理再实现,开发过程中贯彻软件工程最佳实践,构建可随需求扩展的架构。它旨在帮助你弥合原型与生产之间的差距,无需重写代码或基础设施。
1.1 适合人群
Made With ML 适合各类技术专业人士:
- 所有开发者:无论你是软件工程师、基础设施专家还是数据科学家,ML 都日益成为现代产品开发的关键组成部分。
- 大学毕业生:学习实用的行业技能,弥合大学课程与雇主期望之间的差距。
- 产品/管理人员:构建可靠 ML 驱动产品所需的技术基础,并对 ML 计划做出明智决策。
该项目结构灵活,支持不同的学习路径,无论你偏好交互式笔记本、简洁脚本还是生产就绪的部署配置。
1.2 项目架构
Made With ML 采用模块化架构,在组件间保持清晰接口的同时分离关注点。项目围绕几个关键领域组织:
- 核心 ML 流水线
机器学习流水线在 madewithml/ 目录中实现,每个模块处理 ML 工作流的特定方面:
- data.py
- models.py
- train.py
- tune.py
- evaluate.py
- predict.py
- serve.py
数据处理 (data.py):使用 Ray Datasets 处理文本数据的加载、清洗和预处理,实现可扩展处理。
模型架构 (models.py):实现基于 BERT 的微调 LLM,配备自定义分类头。
训练 (train.py):使用 Ray Train 进行分布式训练,集成 MLflow 用于实验跟踪。
超参数调优 (tune.py):使用 Ray Tune 自动化超参数优化。
评估 (evaluate.py):在保留数据集上提供全面的模型评估。
预测 (predict.py):支持批处理和实时模型推理。
服务 (serve.py):使用 Ray Serve 将模型部署为生产就绪服务。
1.3 生产部署
deploy/ 目录包含生产部署所需的一切:
- 集群配置:定义计算资源和环境依赖的 YAML 文件。
- 作业:训练、调优和评估任务的工作负载定义。
- 服务:生产推理端点的模型服务配置。
这种分离确保你的 ML 工作负载可以在不同环境中一致运行,从本地开发到云端生产。
1.4 文档和测试
项目在 docs/ 目录中包含全面文档,在 tests/ 中包含稳健的测试框架,涵盖:
- 代码测试:所有核心功能的单元和集成测试。
- 数据测试:数据集质量和预处理管道的验证。
- 模型测试:行为测试,确保模型性能满足要求。
这种对测试的承诺确保了可靠性,并使框架更容易扩展到你的用例。
1.5 核心特性
1.5.1 端到端 ML 流水线
Made With ML 实现了完整的机器学习流水线,带你从原始数据到部署模型:
- 数据处理:使用 BERT 进行自定义分词,清洗和预处理文本数据。
- 模型训练:通过分布式训练微调预训练语言模型。
- 超参数调优:自动找到最佳模型配置。
- 评估:在保留数据上严格测试模型性能。
- 服务:将模型部署为可扩展的生产服务。
该流水线设计为模块化和可扩展,允许你为特定用例自定义组件,同时保持整体架构。
1.5.2 可扩展基础设施
项目利用 Ray 进行分布式计算,使你能够:
- 从单台笔记本电脑扩展到大型集群,无需更改代码。
- 使用 Ray Data 高效处理大型数据集。
- 跨多个工作节点和 GPU 并行训练模型。
- 通过自动扩展和负载均衡服务模型。
这种基础设施灵活性意味着你可以从小规模开始,随需求增长而扩展,同时保持相同的代码库。
1.5.3 MLOps 集成
Made With ML 集成关键 MLOps 组件,创建生产就绪系统:
- 实验跟踪:MLflow 用于跟踪实验、参数和模型工件。
- CI/CD:GitHub Actions 工作流用于自动化测试和部署。
- 模型注册表:模型版本和元数据的集中存储。
- 监控:内置日志记录和指标收集,用于模型性能监控。
这些集成确保你的 ML 系统在生产环境中可靠、可重复且可维护。
该项目设计为在本地和 Anyscale 等云平台上均可运行。你可以在笔记本电脑上开始开发,然后无缝迁移到生产级计算环境,无需更改代码。
1.6 入门指南
Made With ML 根据你的学习风格提供多种入门方式:
- 交互式学习
从 Jupyter notebook 开始,交互式了解核心 ML 工作负载。这种方法非常适合理解概念并以动手方式实验不同参数。
- 基于脚本的开发
转到 madewithml/ 目录中的简洁 Python 脚本,按照软件工程最佳实践实现相同的工作负载。这是开发生产就绪代码的理想选择,包含适当的测试、文档和版本控制。
- 生产部署
使用 deploy/ 目录中的部署配置大规模运行你的 ML 工作负载。这包括设置集群环境、计算配置和用于持续模型改进的 CI/CD 管道。