DAY16-新世纪DL(DeepLearning/深度学习)战士:Q(机器学习策略)1
本文参考文章0.0 目录-深度学习第一课《神经网络与深度学习》-Stanford吴恩达教授-CSDN博客
1.为什么需要ML策略
当你尝试优化一个深度学习系统时,你通常可以有很多想法可以去试,问题在于,如果你做出了错误的选择,你完全有可能白费6个月的时间,往错误的方向前进,在6个月之后才意识到这方法根本不管用。比如,我见过一些团队花了6个月时间收集更多数据,却在6个月之后发现,这些数据几乎没有改善他们系统的性能。所以,假设你的项目没有6个月的时间可以浪费,如果有快速有效的方法能够判断哪些想法是靠谱的,或者甚至提出新的想法,判断哪些是值得一试的想法,哪些是可以放心舍弃的。
2.正交化
正交化是将一组线性无关的向量通过特定变换转化为正交向量组的过程。正交向量组中任意两个向量的内积为零,这种性质在数学、物理和工程中具有广泛应用
正交化的概念是指,你可以想出一个维度,这个维度你想做的是控制转向角,还有另一个维度来控制你的速度,那么你就需要一个旋钮尽量只控制转向角,另一个旋钮,在这个开车的例子里其实是油门和刹车控制了你的速度。但如果你有一个控制旋钮将两者混在一起,比如说这样一个控制装置同时影响你的转向角和速度,同时改变了两个性质,那么就很难令你的车子以想要的速度和角度前进。然而正交化之后,正交意味着互成90度。设计出正交化的控制装置,最理想的情况是和你实际想控制的性质一致,这样你调整参数时就容易得多。可以单独调整转向角,还有你的油门和刹车,令车子以你想要的方式运动。
那么这与机器学习有什么关系呢?要弄好一个监督学习系统,你通常需要调你的系统的旋钮。
确保四件事情,首先,你通常必须确保至少系统在训练集上得到的结果不错,所以训练集上的表现必须通过某种评估,达到能接受的程度,对于某些应用,这可能意味着达到人类水平的表现,但这取决于你的应用,但是在训练集上表现不错之后,你就希望系统也能在开发集(验证集)上有好的表现,然后你希望系统在测试集上也有好的表现。在最后,你希望系统在测试集上系统的成本函数在实际使用中表现令人满意,比如说,你希望这些猫图片应用的用户满意。
在机器学习中,如果你可以观察你的系统,然后说这一部分是错的,它在训练集上做的不好、在开发集上做的不好、它在测试集上做的不好,或者它在测试集上做的不错,但在现实世界中不好,这就很好。必须弄清楚到底是什么地方出问题了,然后我们刚好有对应的旋钮,或者一组对应的旋钮,刚好可以解决那个问题,那个限制了机器学习系统性能的问题。
总而言之,你的一个旋钮需要做到只控制一个变量
3.单一数字评估指标
无论你是调整超参数,或者是尝试不同的学习算法,或者在搭建机器学习系统时尝试不同手段,你会发现,如果你有一个单实数评估指标,你的进展会快得多,它可以快速告诉你,新尝试的手段比之前的手段好还是差。我个人的理解是需要一个量化指标来评判优劣
比如说对于你的猫分类器,之前你搭建了某个分类器 A ,通过改变超参数,还有改变训练集等手段,你现在训练出来了一个新的分类器B,所以评估你的分类器的一个合理方式是观察它的查准率(precision)和查全率(recall)。
查准率和查全率的确切细节对于这个例子来说不太重要。但简而言之,查准率的定义是在你的分类器标记为猫的例子中,有多少真的是猫。所以如果分类器A 有95%的查准率,这意味着你的分类器说这图有猫的时候,有95%的机会真的是猫。
查全率就是,对于所有真猫的图片,你的分类器正确识别出了多少百分比。实际为猫的图片中,有多少被系统识别出来?如果分类器 A 查全率是90%,这意味着对于所有的图像,比如说你的开发集都是真的猫图,分类器 A 准确地分辨出了其中的90%。
所以关于查准率和查全率的定义,不用想太多。事实证明,查准率和查全率之间往往需要折衷,两个指标都要顾及到。你希望得到的效果是,当你的分类器说某个东西是猫的时候,有很大的机会它真的是一只猫,但对于所有是猫的图片,你也希望系统能够将大部分分类为猫,所以用查准率和查全率来评估分类器是比较合理的。
而当A的查全率比B好,B的查准率比A好时,两个指标的弊端就显现出来了,所以需要一个综合指标
在机器学习文献中,结合查准率和查全率的标准方法是所谓的 分数,
分数的细节并不重要。但非正式的,你可以认为这是查准率 P 和查全率 R 的平均值。正式来看,
分数的定义是这个公式:
4.满足和优化指标
要把你顾及到的所有事情组合成单实数评估指标有时并不容易,在那些情况里,我发现有时候设立满足和优化指标是很重要的。
还是猫分类器的例子,你比较注重准确度,但是现在还需要考虑运行时间,
你可以这么做,将准确度和运行时间组合成一个整体评估指标。所以成本,比如说,总体成本是 cost=accuracy-0.5*running Time,这种组合方式可能太刻意,只用这样的公式来组合准确度和运行时间,两个数值的线性加权求和。
你还可以做其他事情,就是你可能选择一个分类器,能够最大限度提高准确度,但必须满足运行时间要求,就是对图像进行分类所需的时间必须小于等于100毫秒。所以在这种情况下,我们就说准确度是一个优化指标,因为你想要准确度最大化,你想做的尽可能准确,但是运行时间就是我们所说的满足指标,意思是它必须足够好,它只需要小于100毫秒,达到之后,你不在乎这指标有多好,或者至少你不会那么在乎。所以这是一个相当合理的权衡方式,或者说将准确度和运行时间结合起来的方式。实际情况可能是,只要运行时间少于100毫秒,你的用户就不会在乎运行时间是100毫秒还是50毫秒,甚至更快。
所以更一般地说,如果你要考虑 N 个指标,有时候选择其中一个指标做为优化指标是合理的。所以你想尽量优化那个指标,然后剩下 N−1 个指标都是满足指标,意味着只要它们达到一定阈值,例如运行时间快于100毫秒,但只要达到一定的阈值,你不在乎它超过那个门槛之后的表现,但它们必须达到这个门槛。即定N-1变1
现在这些评估指标必须是在训练集或开发集或测试集上计算或求出来的。所以你还需要做一件事,就是设立训练集、开发集,还有测试集。
5.训练/开发/测试集划分
设立训练集,开发集和测试集的方式大大影响了你或者你的团队在建立机器学习应用方面取得进展的速度。
机器学习中的工作流程是,你尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,然后不断迭代去改善开发集的性能,直到最后你可以得到一个令你满意的成本,然后你再用测试集去评估。
开发集和测试集来自同一分布(这分布就是你的所有数据混在一起)。我的意思是这样,你们要记住,我想就是设立你的开发集加上一个单实数评估指标,这就是像是定下目标,然后告诉你的团队,那就是你要瞄准的靶心,因为你一旦建立了这样的开发集和指标,团队就可以快速迭代,尝试不同的想法,跑实验,可以很快地使用开发集和指标去评估不同分类器,然后尝试选出最好的那个。所以,机器学习团队一般都很擅长使用不同方法去逼近目标,然后不断迭代,不断逼近靶心。所以,针对开发集上的指标优化。
6.开发集和测试集的大小
你可能听说过一条经验法则,在机器学习中,把你取得的全部数据用70/30比例分成训练集和测试集。或者如果你必须设立训练集、开发集和测试集,你会这么分60%训练集,20%开发集,20%测试集。在机器学习的早期,这样分是相当合理的,特别是以前的数据集大小要小得多。所以如果你总共有100个样本,这样70/30或者60/20/20分的经验法则是相当合理的。如果你有几千个样本或者有一万个样本,这些做法也还是合理的。
但在现代机器学习中,我们更习惯操作规模大得多的数据集,比如说你有1百万个训练样本,这样分可能更合理,98%作为训练集,1%开发集,1%测试集,我们用 D DD 和 T TT 缩写来表示开发集和测试集。因为如果你有1百万个样本,那么1%就是10,000个样本,这对于开发集和测试集来说可能已经够了。所以在现代深度学习时代,有时我们拥有大得多的数据集,所以使用小于20%的比例或者小于30%比例的数据作为开发集和测试集也是合理的。而且因为深度学习算法对数据的胃口很大,我们可以看到那些有海量数据集的问题,有更高比例的数据划分到训练集里。
那么测试集呢?要记住,测试集的目的是完成系统开发之后,测试集可以帮你评估投产系统的性能。方针就是,令你的测试集足够大,能够以高置信度评估系统整体性能。所以除非你需要对最终投产系统有一个很精确的指标,一般来说测试集不需要上百万个例子。对于你的应用程序,也许你想,有10,000个例子就能给你足够的置信度来给出性能指标了,也许100,000个之类的可能就够了,这数目可能远远小于比如说整体数据集的30%,取决于你有多少数据。
总结一下,在大数据时代旧的经验规则,这个70/30不再适用了。现在流行的是把大量数据分到训练集,然后少量数据分到开发集和测试集,特别是当你有一个非常大的数据集时。
7.什么时候该改变开发/测试集和指标
我们来看一个例子,假设你在构建一个猫分类器,试图找到很多猫的照片,你决定使用的指标是分类错误率。算法 A 和 B 分别有3%错误率和5%错误率。但我们实际试一下这些算法,算法 A 由于某些原因,把很多色情图像分类成猫了。如果你部署算法 A ,那么用户就会看到更多猫图,因为它识别猫的错误率只有3%,但它同时也会给用户推送一些色情图像,这是你的公司完全不能接受的,你的用户也完全不能接受。相比之下,算法 B 有5%的错误率,这样分类器就得到较少的图像,但它不会推送色情图像。所以从你们公司的角度来看,以及从用户接受的角度来看,算法 B 实际上是一个更好的算法,因为它不让任何色情图像通过。
所以当这种情况发生时,当你的评估指标无法正确衡量算法之间的优劣排序时,在这种情况下,原来的指标错误地预测算法A是更好的算法这就发出了信号,你应该改变评估指标了,或者要改变开发集或测试集。在这种情况下,你用的分类错误率指标可以写成这样:
是你的开发集例子数,用
表示预测值,其值为0或1,
这符号表示一个函数,统计出里面这个表达式为真的样本数,所以这个公式就统计了分类错误的样本。这个评估指标的问题在于,它对色情图片和非色情图片一视同仁,但你其实真的希望你的分类器不会错误标记色情图像。比如说把一张色情图片分类为猫,然后推送给不知情的用户,他们看到色情图片会非常不满。
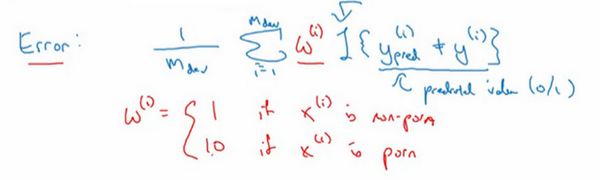
其中一个修改评估指标的方法是在原公式上加个权重项,即
,其中,如果
不是色情图片,则
=1,如果
是色情图片,则
可能就是10甚至100,这样你赋予了色情图片更大的权重,让算法将色情图分类为猫图时,错误率这个项快速变大。这个例子里,你把色情图片分类成猫这一错误的惩罚权重加大10倍。
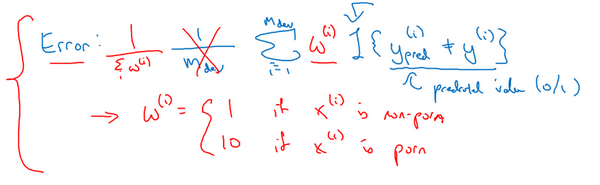
如果你希望得到归一化常数,在技术上,就是对所有
求和,这样错误率仍然在0和1之间,即:
加权的细节并不重要,实际上要使用这种加权,你必须自己过一遍开发集和测试集,在开发集和测试集里,自己把色情图片标记出来,这样你才能使用这个加权函数。但粗略的结论是,如果你的评估指标无法正确评估好算法的排名,那么就需要花时间定义一个新的评估指标。这是定义评估指标的其中一种可能方式(上述加权法)。评估指标的意义在于,准确告诉你已知两个分类器,哪一个更适合你的应用。
处理机器学习问题时,应该把它切分成独立的步骤。一步是弄清楚如何定义一个指标来衡量你想做的事情的表现,然后我们可以分开考虑如何改善系统在这个指标上的表现。你们要把机器学习任务看成两个独立的步骤,用目标这个比喻,第一步就是设定目标。所以要定义你要瞄准的目标,这是完全独立的一步,这是你可以调节的一个旋钮。如何设立目标是一个完全独立的问题,把它看成是一个单独的旋钮,可以调试算法表现的旋钮,如何精确瞄准,如何命中目标,定义指标是第一步。
然后第二步要做别的事情,在逼近目标的时候,也许你的学习算法针对某个长这样的成本函数优化,,你要最小化训练集上的损失。你可以做的其中一件事是,修改这个,为了引入这些权重,也许最后需要修改这个归一化常数,
即:
再次,如何定义 J 并不重要,关键在于正交化的思路,把设立目标定为第一步,然后瞄准和射击目标是独立的第二步。换种说法,我鼓励你们将定义指标看成一步,然后在定义了指标之后,你才能想如何优化系统来提高这个指标评分。比如改变你神经网络要优化的成本函数 J 。
总体方针就是,如果你当前的指标和当前用来评估的数据和你真正关心必须做好的事情关系不大,那就应该更改你的指标或者你的开发测试集,让它们能更够好地反映你的算法需要处理好的数据。
个人理解就是通过更改指标(加权重)来过滤掉开发测试集中的杂质
8.为什么是人的表现
在过去的几年里,更多的机器学习团队一直在讨论如何比较机器学习系统和人类的表现
我们来看几个这样的例子,我看到很多机器学习任务中,当你在一个问题上付出了很多时间之后,所以 x 轴是时间,这可能是很多个月甚至是很多年。在这些时间里,一些团队或一些研究小组正在研究一个问题,当你开始往人类水平努力时,进展是很快的。但是过了一段时间,当这个算法表现比人类更好时,那么进展和精确度的提升就变得更慢了。也许它还会越来越好,但是在超越人类水平之后,它还可以变得更好,但性能增速,准确度上升的速度这个斜率,会变得越来越平缓,我们都希望能达到理论最佳性能水平。随着时间的推移,当您继续训练算法时,可能模型越来越大,数据越来越多,但是性能无法超过某个理论上限,这就是所谓的贝叶斯最优错误率(Bayes optimal error)。所以贝叶斯最优错误率一般认为是理论上可能达到的最优错误率,就是说没有任何办法设计出一个 x 到 y 的函数,让它能够超过一定的准确度
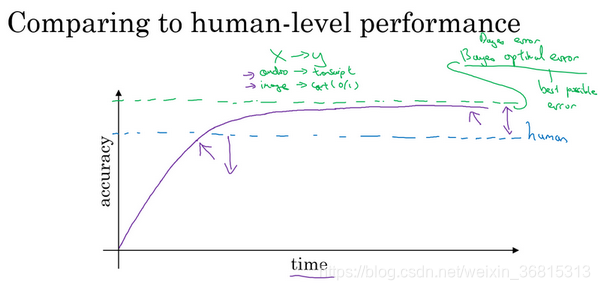
例如,对于语音识别来说,如果 x 是音频片段,有些音频就是这么嘈杂,基本不可能知道说的是什么,所以完美的准确率可能不是100%。或者对于猫图识别来说,也许一些图像非常模糊,不管是人类还是机器,都无法判断该图片中是否有猫。所以,完美的准确度可能不是100%。
而贝叶斯最优错误率有时写作Bayesian,即省略optimal,就是从 x 到 y 映射的理论最优函数,永远不会被超越。所以你们应该不会感到意外,这紫色线,无论你在一个问题上工作多少年,你永远不会超越贝叶斯错误率,贝叶斯最佳错误率。
事实证明,机器学习的进展直到你超越人类的表现之前一直很快,当你超越人类的表现时,有时进展会变慢。我认为有两个原因,为什么当你超越人类的表现时,进展会慢下来。一个原因是人类水平在很多任务中离贝叶斯最优错误率已经不远了,人们非常擅长看图像,分辨里面有没有猫或者听写音频。所以,当你超越人类的表现之后也许没有太多的空间继续改善了。但第二个原因是,只要你的表现比人类的表现更差,那么实际上可以使用某些工具来提高性能。一旦你超越了人类的表现,这些工具就没那么好用了。
9.可避免误差
我们讨论过,你希望你的学习算法能在训练集上表现良好,但有时你实际上并不想做得太好。你得知道人类水平的表现是怎样的,可以确切告诉你算法在训练集上的表现到底应该有多好,或者有多不好,让我告诉你是什么意思吧。
我们经常使用猫分类器来做例子,比如人类具有近乎完美的准确度,所以人类水平的错误是1%。在这种情况下,如果您的学习算法达到8%的训练错误率和10%的开发错误率,那么你也许想在训练集上得到更好的结果。所以事实上,你的算法在训练集上的表现和人类水平的表现有很大差距的话,说明你的算法对训练集的拟合并不好。所以从减少偏差和方差的工具这个角度看,在这种情况下,我会把重点放在减少偏差上。你需要做的是,比如说训练更大的神经网络,或者跑久一点梯度下降,就试试能不能在训练集上做得更好。

在这两种情况下,具有同样的训练错误率和开发错误率,我们决定专注于减少偏差的策略或者减少方差的策略。那么左边的例子发生了什么? 8%的训练错误率真的很高,你认为你可以把它降到1%,那么减少偏差的手段可能有效。而在右边的例子中,如果你认为贝叶斯错误率是7.5%,这里我们使用人类水平错误率来替代贝叶斯错误率,但是你认为贝叶斯错误率接近7.5%,你就知道没有太多改善的空间了,不能继续减少你的训练错误率了,你也不会希望它比7.5%好得多,因为这种目标只能通过可能需要提供更进一步的训练。而这边,就还(训练误差和开发误差之间)有更多的改进空间,可以将这个2%的差距缩小一点,使用减少方差的手段应该可行,比如正则化,或者收集更多的训练数据。

可避免偏差这个词说明了有一些别的偏差,或者错误率有个无法超越的最低水平,那就是说如果贝叶斯错误率是7.5%。你实际上并不想得到低于该级别的错误率,所以你不会说你的训练错误率是8%,然后8%就衡量了例子中的偏差大小。你应该说,可避免偏差可能在0.5%左右,或者0.5%是可避免偏差的指标。而这个2%是方差的指标,所以要减少这个2%比减少这个0.5%空间要大得多。而在左边的例子中,这7%衡量了可避免偏差大小,而2%衡量了方差大小。所以在左边这个例子里,专注减少可避免偏差可能潜力更大。
所以在这个例子中,当你理解人类水平错误率,理解你对贝叶斯错误率的估计,你就可以在不同的场景中专注于不同的策略,使用避免偏差策略还是避免方差策略。在训练时如何考虑人类水平表现来决定工作着力点。
10.理解人的表现(Understanding Human-level Performance)

假设你要观察这样的放射科图像,然后作出分类诊断,假设一个普通的人类,未经训练的人类,在此任务上达到3%的错误率。普通的医生,也许是普通的放射科医生,能达到1%的错误率。经验丰富的医生做得更好,错误率为0.7%。还有一队经验丰富的医生,就是说如果你有一个经验丰富的医生团队,让他们都看看这个图像,然后讨论并辩论,他们达成共识的意见达到0.5%的错误率。所以我想问你的问题是,你应该如何界定人类水平错误率?人类水平错误率3%,1%, 0.7%还是0.5%?
要回答这个问题,请你记住,思考人类水平错误率最有用的方式之一是,把它作为贝叶斯错误率的替代或估计。
但这里我就直接给出人类水平错误率的定义,就是如果你想要替代或估计贝叶斯错误率,那么一队经验丰富的医生讨论和辩论之后,可以达到0.5%的错误率。我们知道贝叶斯错误率小于等于0.5%,因为有些系统,这些医生团队可以达到0.5%的错误率。所以根据定义,最优错误率必须在0.5%以下。我们不知道多少更好,也许有一个更大的团队,更有经验的医生能做得更好,所以也许比0.5%好一点。但是我们知道最优错误率不能高于0.5%,那么在这个背景下,我就可以用0.5%估计贝叶斯错误率。
本节要点是,在定义人类水平错误率时,要弄清楚你的目标所在,如果要表明你可以超越单个人类,那么就有理由在某些场合部署你的系统,也许这个定义是合适的。但是如果您的目标是替代贝叶斯错误率,那么这个定义(经验丰富的医生团队——0.5%)才合适。
现在来看看第二个例子,比如说你的训练错误率是1%,开发错误率是5%,这其实也不怎么重要,这种问题更像学术界讨论的,人类水平表现是1%或0.7%还是0.5%。因为不管你使用哪一个定义,你测量可避免偏差的方法是,如果用那个值,就是0%到0.5%之前,对吧?那就是人类水平和训练错误率之前的差距,而这个差距是4%,所以这个4%差距比任何一种定义的可避免偏差都大。所以他们就建议,你应该主要使用减少方差的工具,比如正则化或者去获取更大的训练集。
什么时候真正有效呢?
就是比如你的训练错误率是0.7%,所以你现在已经做得很好了,你的开发错误率是0.8%。在这种情况下,你用0.5%来估计贝叶斯错误率关系就很大。因为在这种情况下,你测量到的可避免偏差是0.2%,这是你测量到的方差问题0.1%的两倍,这表明也许偏差和方差都存在问题。但是,可避免偏差问题更严重。在这个例子中,我们在上一张幻灯片中讨论的是0.5%,就是对贝叶斯错误率的最佳估计,因为一群人类医生可以实现这一目标。如果你用0.7代替贝叶斯错误率,你测得的可避免偏差基本上是0%,那你就可能忽略可避免偏差了。实际上你应该试试能不能在训练集上做得更好。
总结一下我们讲到的,如果你想理解偏差和方差,那么在人类可以做得很好的任务中,你可以估计人类水平的错误率,你可以使用人类水平错误率来估计贝叶斯错误率。所以你到贝叶斯错误率估计值的差距,告诉你可避免偏差问题有多大,可避免偏差问题有多严重,而训练错误率和开发错误率之间的差值告诉你方差上的问题有多大,你的算法是否能够从训练集泛化推广到开发集

在这个例子中,一旦你接近0.7%错误率,除非你非常小心估计贝叶斯错误率,你可能无法知道离贝叶斯错误率有多远,所以你应该尽量减少可避免偏差。事实上,如果你只知道单个普通医生能达到1%错误率,这可能很难知道是不是应该继续去拟合训练集,这种问题只会出现在你的算法已经做得很好的时候,只有你已经做到0.7%, 0.8%, 接近人类水平时会出现。
而在左边的两个例子中,当你远离人类水平时,将优化目标放在偏差或方差上可能更容易一点。这就说明了,为什么当你们接近人类水平时,更难分辨出问题是偏差还是方差。所以机器学习项目的进展在你已经做得很好的时候,很难更进一步。
总结一下我们讲到的,如果你想理解偏差和方差,那么在人类可以做得很好的任务中,你可以估计人类水平的错误率,你可以使用人类水平错误率来估计贝叶斯错误率。所以你到贝叶斯错误率估计值的差距,告诉你可避免偏差问题有多大,可避免偏差问题有多严重,而训练错误率和开发错误率之间的差值告诉你方差上的问题有多大,你的算法是否能够从训练集泛化推广到开发集。
11.超越人的表现(Surpassing Human-level Performance)
假设你有一个问题,一组人类专家充分讨论辩论之后,达到0.5%的错误率,单个人类专家错误率是1%,然后你训练出来的算法有0.6%的训练错误率,0.8%的开发错误率。所以在这种情况下,可避免偏差是多少?这个比较容易回答,0.5%是你对贝叶斯错误率的估计,所以可避免偏差就是0.1%。你不会用这个1%的数字作为参考,你用的是这个差值,所以也许你对可避免偏差的估计是至少0.1%,然后方差是0.2%。和减少可避免偏差比较起来,减少方差可能空间更大。
但现在我们来看一个比较难的例子,一个人类专家团和单个人类专家的表现和以前一样,但你的算法可以得到0.3%训练错误率,还有0.4%开发错误率。现在,可避免偏差是什么呢?现在其实很难回答,事实上你的训练错误率是0.3%,这是否意味着你过拟合了0.2%,或者说贝叶斯错误率其实是0.1%呢?或者也许贝叶斯错误率是0.2%?或者贝叶斯错误率是0.3%呢?你真的不知道。但是基于本例中给出的信息,你实际上没有足够的信息来判断优化你的算法时应该专注减少偏差还是减少方差,这样你取得进展的效率就会降低。还有比如说,如果你的错误率已经比一群充分讨论辩论后的人类专家更低,那么依靠人类直觉去判断你的算法还能往什么方向优化就很难了。所以在这个例子中,一旦你超过这个0.5%的门槛,要进一步优化你的机器学习问题就没有明确的选项和前进的方向了。这并不意味着你不能取得进展,你仍然可以取得重大进展。但现有的一些工具帮助你指明方向的工具就没那么好用了。
要达到超越人类的表现往往不容易,但如果有足够多的数据,已经有很多深度学习系统,在单一监督学习问题上已经超越了人类的水平。
12.改善你的模型的表现 (Improving your model performance)
想要让一个监督学习算法达到实用,基本上希望或者假设你可以完成两件事情。首先,你的算法对训练集的拟合很好,这可以看成是你能做到可避免偏差很低(训练错误率-贝叶斯错误率)。还有第二件事你可以做好的是,在训练集中做得很好,然后推广到开发集和测试集也很好,这就是说方差(开发错误率-训练错误率)不是太大。
如果你想提升机器学习系统的性能,建议看看训练错误率和贝叶斯错误率估计值之间的距离,让你知道可避免偏差有多大。换句话说,就是你觉得还能做多好,你对训练集的优化还有多少空间。然后看看你的开发错误率和训练错误率之间的距离,就知道你的方差问题有多大。换句话说,你应该做多少努力让你的算法表现能够从训练集推广到开发集,算法是没有在开发集上训练的。
如果你想用尽一切办法减少可避免偏差,我建议试试这样的策略:比如使用规模更大的模型,这样算法在训练集上的表现会更好,或者训练更久。使用更好的优化算法,比如说加入momentum或者RMSprop,或者使用更好的算法,比如Adam。你还可以试试寻找更好的新神经网络架构,或者说更好的超参数。这些手段包罗万有,你可以改变激活函数,改变层数或者隐藏单位数,虽然你这么做可能会让模型规模变大。或者试用其他模型,其他架构,如循环神经网络和卷积神经网络。
另外当你发现方差是个问题时,你可以试用很多技巧,包括以下这些:收集更多数据,因为收集更多数据去训练可以帮你更好地推广到系统看不到的开发集数据。尝试正则化,包括 L2 正则化,dropout正则化或者我们在之前课程中提到的数据增强。同时你也可以试用不同的神经网络架构,超参数搜索,看看能不能帮助你,找到一个更适合你的问题的神经网络架构。