AlexNet:点燃深度学习革命的「卷积神经网络之王」
大家好!今天我们要解锁一个改写AI历史的传奇网络——AlexNet!🎉 这个2012年横空出世的模型,以"碾压式"优势赢得ImageNet竞赛冠军,让深度学习正式进入公众视野。让我们像拆盲盒一样,一步步揭开它的神秘面纱吧!
🌍 一、AlexNet诞生的历史背景
📜 赛前困境(2012年前):
- 传统机器学习在图像识别上遇到瓶颈(准确率<75%)
- 手工设计特征(SIFT/HOG)耗时且效果有限
- 计算资源不足(GPU尚未普及)
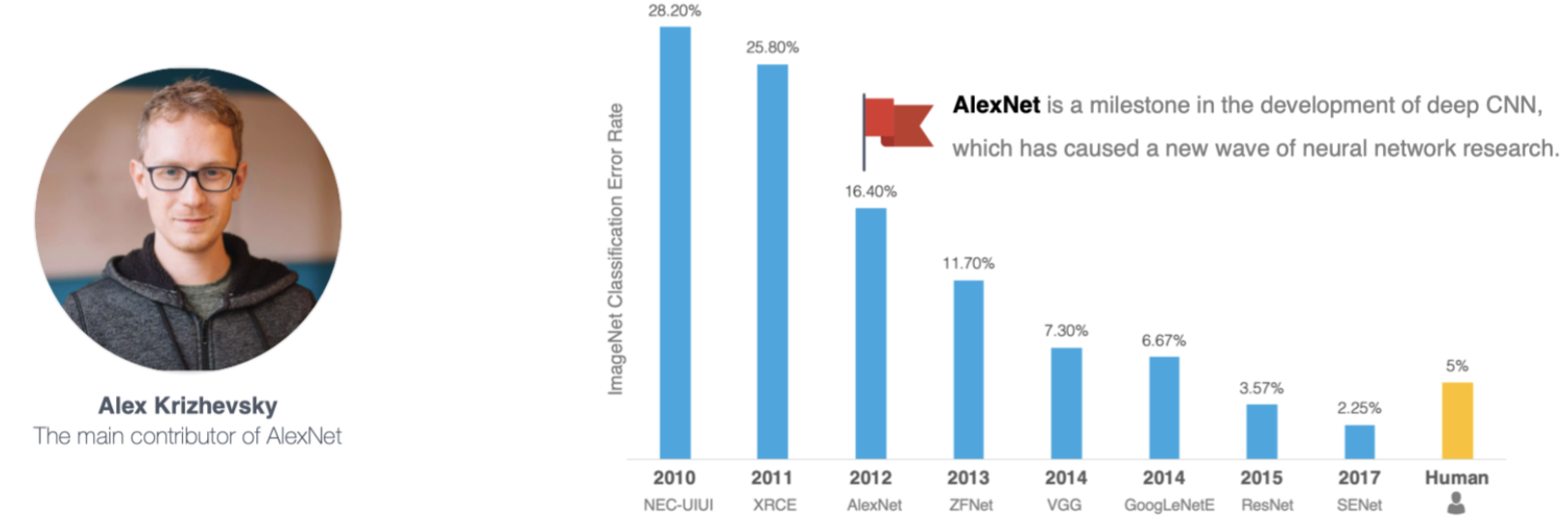
💥 2012年ImageNet竞赛:
- 任务:识别1000类物体(120万张训练图)
- AlexNet以top-5错误率15.3%(比第二名低10.8%)一战成名!
- 相当于让计算机从"近视眼"变成了"火眼金睛"👁️
二、AlexNet的五大创新点 🛠️
1. 🧠 使用ReLU激活函数:告别「梯度消失」!
- 传统问题:Sigmoid/Tanh函数在深层网络中容易出现梯度趋近于0,导致训练停滞(梯度消失)。
- AlexNet方案:采用 ReLU(Rectified Linear Unit):
f(x) = max(0, x)→ 训练速度提升6倍!
→ 解决了深层网络训练难的问题 ✅
2. 🛡️ Dropout:随机「罢工」的神经元
- 问题:全连接层参数太多(占AlexNet总参数95%!),容易过拟合。
- 解决方案:在训练时,随机丢弃50%神经元(Dropout率=0.5)
→ 迫使网络不依赖单个神经元,提升泛化能力 ✅
→ 相当于每次训练一个「子网络」,最终投票表决(集成学习)🤝
3. 📸 数据增强:用「脑补」扩充数据
AlexNet通过对训练图片做以下操作,数据量翻3倍:
- 随机裁剪(224x224窗口)
- 水平翻转(镜像)
- 颜色扰动(调整RGB通道强度)
4. ⚡ 双GPU并行训练:算力破局
- 2012年GPU还很弱(NVIDIA GTX 580仅3GB显存)。
- AlexNet创新性地将网络拆成两部分,分别在两块GPU上计算:
- Conv1、Conv2、Conv5在GPU1
- Conv1、Conv2、Conv5在GPU2
- Conv3、Conv4、全连接层跨GPU交互
→ 训练时间从CPU的几个月缩短到GPU的5~6天!
5. 🧩 局部响应归一化(LRN)与重叠池化
- LRN:模仿生物神经的「侧抑制」机制,增强特征间对比度(后被BatchNorm取代)
- 重叠池化:池化窗口(3x3)> 步长(2)→ 保留更多空间信息 ✅
三、网络结构详解 🧱
AlexNet共8层:5层卷积 + 3层全连接(输出1000类概率)。以下是逐层解析👇
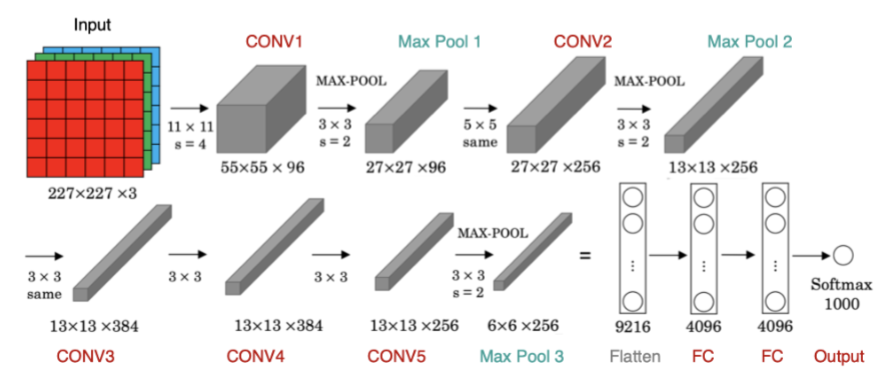
📊 各层参数表(输入224x224x3图像)
层名 | 操作类型 | 核心参数 | 输出尺寸 |
|---|---|---|---|
Conv1 | 卷积+ReLU+LRN+池化 | 96个11x11核,步长4 | 55x55x96 |
Pool1 | 最大池化 | 3x3核,步长2(重叠) | 27x27x96 |
Conv2 | 卷积+ReLU+LRN+池化 | 256个5x5核,分组卷积(2组GPU) | 27x27x256 |
Pool2 | 最大池化 | 3x3核,步长2 | 13x13x256 |
Conv3 | 卷积+ReLU | 384个3x3核 | 13x13x384 |
Conv4 | 卷积+ReLU | 384个3x3核 | 13x13x384 |
Conv5 | 卷积+ReLU+池化 | 256个3x3核 | 13x13x256 |
Pool3 | 最大池化 | 3x3核,步长2 | 6x6x256 |
FC6 | 全连接+ReLU+Dropout | 4096神经元 | 4096 |
FC7 | 全连接+ReLU+Dropout | 4096神经元 | 4096 |
FC8 | 全连接+Softmax | 1000神经元(对应类别) | 1000 |
💡 关键细节:
- 分组卷积:受限于GPU显存,Conv2/4/5在2块GPU上分组计算(后由VGG/ResNet取消)
- 参数量:约6000万!其中FC6就占3700万
四、代码实战:用PyTorch实现AlexNet 👨
import torch
import torch.nn as nnclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # Conv1nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Pool1nn.Conv2d(96, 256, kernel_size=5, padding=2), # Conv2nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Pool2nn.Conv2d(256, 384, kernel_size=3, padding=1), # Conv3nn.ReLU(inplace=True),nn.Conv2d(384, 384, kernel_size=3, padding=1), # Conv4nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1), # Conv5nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Pool3)self.classifier = nn.Sequential(nn.Dropout(0.5), # Dropout层nn.Linear(256 * 6 * 6, 4096), # FC6nn.ReLU(inplace=True),nn.Dropout(0.5), # Dropout层nn.Linear(4096, 4096), # FC7nn.ReLU(inplace=True),nn.Linear(4096, num_classes), # FC8)def forward(self, x):x = self.features(x)x = torch.flatten(x, 1) # 展平特征图x = self.classifier(x)return x# 示例:创建模型并打印
model = AlexNet()
print(model)五、AlexNet的影响:深度学习时代的「火种」 🔥
- 推动硬件革命:GPU成为深度学习训练标配
- 启发后续模型:
•VGGNet:用更小的3x3卷积堆叠更深网络
•GoogLeNet:引入Inception模块
•ResNet:残差连接解决千层网络训练问题 ✅
3.技术平民化:开源代码+论文公开,引爆AI社区参与热情 🎉
🌟 历史意义:AlexNet证明了「数据 + 算力 + 算法」是AI发展的铁三角!
六、总结 💎
AlexNet的成功并非偶然,而是创新技术 + 工程突破的完美结合:
- 技术面:ReLU、Dropout、数据增强解决训练难题
- 工程面:双GPU并行、重叠池化榨干硬件性能
- 影响力:点燃深度学习十年黄金期,催生CV、NLP、RL等领域大模型
✨ 关注我,下期将带来更现代的ResNet残差网络解析!别忘了点赞收藏哦~ 👍🌟